
Les contenus liés aux tags Nvidia et AMD
Afficher sous forme de : Titre | FluxVentes iGPU / GPU : marché en berne, AMD recule
Nouveaux pilotes AMD et Nvidia
Computex: AMD vs Nvidia au Computex? Match reporté
AMD Fiji chez DICE et GTX 980 Ti en approche
[MAJ] GDC: D3D12: AMD parle des gains GPU
Pour quand les GPU Pascal et Polaris ?



A moins d'être en hibernation depuis quelques mois, vous savez probablement que l'année 2016 sera marquée par l'arrivée de deux nouvelles architectures GPU, avec d'un part Polaris chez AMD et de l'autre Pascal chez Nvidia. Ces architectures ont en commun l'utilisation de nouveaux procédés de fabrication, que ce soit le 14nm LPP chez Samsung / GlobalFoundries ou le 16nm FinFET+ chez TSMC, qui combinés avec les nouvelles mémoires (HBM2, GDDR5X) et les raffinements architecturaux promettent un gain important en terme de performances.

Côté AMD, Polaris a été évoqué officiellement à l'occasion du CES en ce début d'année. L'accent a notamment été mis sur un saut historique de la performance par watt, et deux puces seraient prévues, Polaris 10 et Polaris 11. L'une est prévue pour des livraisons à compter de mi-2016, il s'agit d'une puce de relativement petite destinée aux PC compacts et aux portables et qui sera associée à de la GDDR5. L'autre, plus grosse, serait destinée au haut de gamme et pourrait faire appel à la HBM2 mais aucun détail n'a été donné pour ce qui est de la date de commercialisation.

Chez Nvidia, Pascal fait les titres depuis longtemps puisqu'il en a été question dès la GPU Technology Conference qu'il a organisé en 2014. Le GTC 2015 en mars dernier a été l'occasion de quelques précisions, Nvidia mettant en avant une puissance de calcul par watt doublée (et même quadruplée grâce au FP16) ainsi qu'une capacité et une bande passante mémoire en forte hausse grâce à la mémoire 3D (la HBM2 en pratique). Lors du CES, Nvidia n'a évoqué Pascal que pour le Drive PX2 et n'en a pas fait de démonstration contrairement à son concurrent : il faudra probablement attendre le GTC 2016 en avril prochain, ou au mieux la GDC qui a lieu mi-mars, pour qu'il en dévoile plus.
A quelle date faut-il s'attendre à voir débarquer ces GPU ? De part et d'autre c'est le grand secret, sauf pour l'entrée de gamme chez AMD, autant pour ne pas donner d'indication à son (unique) concurrent que pour de ne pas impacter négativement les ventes de la génération actuelle. Ces derniers jours une "roadmap" établie sur la base de rumeurs et autres déductions, remplie de points d'interrogations et publiée à l'origine sur un site japonais a fait le tour de nombreux sites sans que les pincettes de rigueur soient de mise, voire parfois en laissant penser qu'il s'agissait d'une véritable roadmap. Il était notamment question sur ce document d'un premier gros GPU Pascal, GP100, lancé en avril lors de la GTC puis d'un second GPU, GP104, qui aurait fait son apparition en juin au Computex sous la forme d'une GeForce GTX 1080.
On ne peut malheureusement pas accorder de crédit à ces informations. Il faut bien admettre que Nvidia comme AMD gardent bien le secret pour la génération à venir, et les seules bribes d'informations qui nous parviennent laissent plutôt à penser que leur disponibilité interviendra au troisième trimestre, alors qu'initialement nous comptions plutôt sur le second trimestre. Mais il est tout à fait possible que l'un ou l'autre masque au maximum son jeu pour avoir un effet de surprise lors du lancement qui ne serait pas sans retombées commerciales positives wait & see !
AMD + Nvidia en multi GPU sous DX12
Nous vous en parlions en mai dernier, DirectX 12 ajoute un support explicit du multi-GPU, laissant aux développeurs la possibilité de contrôler eux-mêmes le multi-GPU. A l'époque, une première démonstration sous l'Unreal Engine 4 combinait un GPU et un iGPU, le premier se chargeant du gros du rendu alors que le post-processing et l'affichage était pris en charge par l'iGPU. Dans la démonstration, on obtenait un gain de performance de 10%, avec comme désavantage une augmentation de la latence du rendu qui passait de 28 à 45ms.

Oxyde a fourni à AnandTech une version alpha de son bench DirectX 12, basé sur le moteur de son jeu Ashes of the Singularity. Cette dernière va plus loin puisqu'il s'agit cette fois d'effectuer alternativement le rendu sur l'une ou l'autre des GPU intégré dans le système. Si ce rendu alternatif nécessite toujours deux GPU de performances proches pour être pertinent, l'avantage de ne plus passer par le SLI ou le CrossFire est que l'on n'est plus limité par les associations imposées par les constructeurs au sein de leur propre gamme, et que l'association d'un GPU AMD et d'un GPU Nvidia DirectX 12 est possible !

En pratique les gains sont bels et bien là, et étonnamment les plus importants sont enregistrés en couplant une R9 Fury X et une GTX 980 Ti avec selon que l'une ou l'autre soit utilisée en GPU primaire +64 à +75% en 2560x1440 contre +66% en ajoutant une Fury à une Fury X, ou +46% en couplant une Titan X à une GTX 980 Ti. En 3840*2160 les gains les plus importants sont obtenus en ajoutant une 980 Ti à une Fury X (+66%), l'inverse gagnant nettement moins (+40%).
Un autre test sur des GPU plus anciens montre par contre que le GPU primaire peut avoir un impact encore plus grand, ainsi si on adjoint à une HD 7970 une GTX 680, on obtient un gain de 55%. Par contre si les positions des cartes sont inversées alors les performances baissent de 40% !
Ces résultats sont donc très intéressants et montrent le potentiel immense qu'offre une API donnant le contrôle aux développeurs. Reste que ce sont bien eux qui auront la main, et vu le marché relativement faible du multi GPU, il n'est pas certain que beaucoup exploitent comme Oxyde cette possibilité offerte par l'API. Il ne faut pas oublier non plus qu'au-delà des performances, d'un point de vue qualitatif une association AMD/Nvidia en AFR pourrait poser problème du fait de petites différences au niveau du filtrage des textures ou de l'anti-aliasing.
Les GTX 900 supportent-elles correctement DirectX 12 ?
Comme à chaque introduction de nouvelle API graphique, la question du support optimal de Direct3D 12 par les cartes graphiques du moment se pose. Ashes of the Singularity, le premier benchmark issu d'un jeu compatible avec cette API, ne met pas réellement en avant les GeForce GTX 900 qui souffriraient d'une mauvaise gestion de l'Async Compute. Explications.
Oxide, le développeur d'Ashes of the Singularity et qui est par ailleurs plutôt proche d'AMD, a sorti il y a quelques semaines un benchmark qui découle de son futur jeu et qui a la particularité de supporter autant DirectX 11 que DirectX 12. Le but premier de la démonstration est de mettre en avant l'intérêt de la nouvelle API de Microsoft pour réduire le surcoût CPU et multiplier le nombre d'unités en action à l'écran, mais d'autres aspects de DirectX 12 sont également de la partie. C'est le cas de l'Async Compute, technique sur laquelle nous allons revenir et qui permet de gagner des performances en exploitant mieux le GPU.
Les premiers résultats publiés, par exemple chez nos confrères de PCPerspective sont loin d'avoir été flatteurs pour les GeForce :
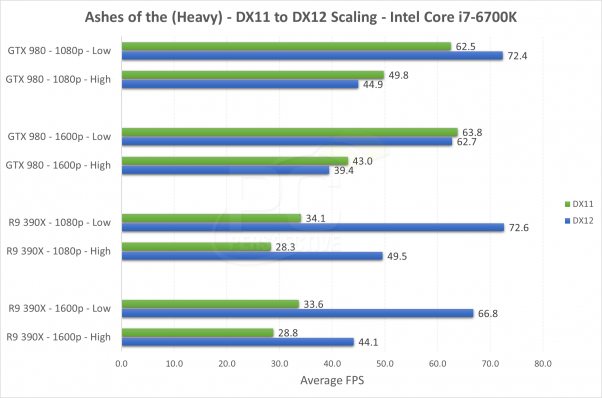
Dans cet exemple, qui se concentre sur les performances dans la partie la plus lourde du benchmark, la GeForce GTX 980 a un net avantage sur la Radeon R9 390X en DirectX 11, ce qui est lié aux pilotes Nvidia qui ont été particulièrement bien optimisés. La situation s'inverse par contre dans le mode DirectX 12 où les performances explosent pour la Radeon alors qu'elles progressent peu voire régressent pour la GeForce.
La réaction de Nvidia ne s'est pas fait attendre et son service de communication s'en est pris sans ménagement à ce benchmark :
The alpha benchmark will run a series of pre-selected scenes and will give you a score at the end to show how well your system ran that series of scenes. The game looks intriguing, but this alpha benchmark is primarily useful to understand how your system runs a series of scenes from the alpha version of Ashes of Singularity.
We believe there will be better examples of true DirectX 12 performance and we continue to work with Microsoft on their DX12 API, games and benchmarks. The GeForce architecture and drivers for DX12 performance is second to none when accurate DX12 metrics arrive, the story will be the same as it was for DX11.
Nvidia entend donc balayer du revers de la main les résultats de ce benchmark qualifié d'alpha et d'inexact et affirmer que l'architecture et les pilotes des GeForce lui permettront de dominer autant dans DirectX 12 que dans DirectX 11.
Nvidia aime également rappeler aux journalistes que toutes les démonstrations de Microsoft ont été faites sur des GeForce. En pratique, cela ne veut cependant rien dire du tout, ces choix sont politiques plus que techniques, notamment parce que Microsoft avait à cur de se détacher de l'API Mantle dont DirectX 12 s'est inspiré.
Entre un Nvidia plutôt de mauvaise foi et un AMD qui crie victoire et veut laisser penser que les Radeon vont gagner des points avec DirectX 12, il peut être difficile de savoir quoi penser et il y a eu pas mal d'agitation sur certains forums.
Probablement en concertation avec AMD mais également avec Nvidia, Oxide a finalement communiqué fin août quelques explications sur le forum d'Overclock.net, tout d'abord ici et là .
En voici les extraits principaux :
Personally, I think one could just as easily make the claim that we were biased toward Nvidia as the only 'vendor' specific code is for Nvidia where we had to shutdown async compute. By vendor specific, I mean a case where we look at the Vendor ID and make changes to our rendering path. Curiously, their driver reported this feature was functional but attempting to use it was an unmitigated disaster in terms of performance and conformance so we shut it down on their hardware. As far as I know, Maxwell doesn't really have Async Compute so I don't know why their driver was trying to expose that.
I suspect that one thing that is helping AMD on GPU performance is D3D12 exposes Async Compute, which D3D11 did not. Ashes uses a modest amount of it, which gave us a noticeable perf improvement. It was mostly opportunistic where we just took a few compute tasks we were already doing and made them asynchronous, Ashes really isn't a poster-child for advanced GCN features.
Our use of Async Compute, however, pales with comparisons to some of the things which the console guys are starting to do. Most of those haven't made their way to the PC yet, but I've heard of developers getting 30% GPU performance by using Async Compute. Too early to tell, of course, but it could end being pretty disruptive in a year or so as these GCN built and optimized engines start coming to the PC. I don't think Unreal titles will show this very much though, so likely we'll have to wait to see.
AFAIK, Maxwell doesn't support Async Compute, at least not natively. We disabled it at the request of Nvidia, as it was much slower to try to use it then to not.
Whether or not Async Compute is better or not is subjective, but it definitely does buy some performance on AMD's hardware. Whether it is the right architectural decision for Maxwell, or is even relevant to its scheduler is hard to say.
P.S. There is no war of words between us and Nvidia. Nvidia made some incorrect statements, and at this point they will not dispute our position if you ask their PR. That is, they are not disputing anything in our blog. I believe the initial confusion was because Nvidia PR was putting pressure on us to disable certain settings in the benchmark, when we refused, I think they took it a little too personally.
Grossièrement, Oxide explique avoir dû modifier le moteur de rendu d'Ashes of the Singularity pour désactiver l'Async Compute sur les GeForce qui supportaient très mal cette fonctionnalité alors qu'elle apporterait un gain sur les Radeon, malgré son utilisation très basique. Oxide en profite pour lancer une pique à Nvidia qui aurait tenté de faire pression pour que le benchmark soit modifié à son avantage.
Il y a quelques jours, Oxide est revenu sur le sujet à travers ce post :
Regarding Async compute, a couple of points on this. First, though we are the first D3D12 title, I wouldn't hold us up as the prime example of this feature. There are probably better demonstrations of it. This is a pretty complex topic and to fully understand it will require significant understanding of the particular GPU in question that only an IHV can provide. I certainly wouldn't hold Ashes up as the premier example of this feature.
We actually just chatted with Nvidia about Async Compute, indeed the driver hasn't fully implemented it yet, but it appeared like it was. We are working closely with them as they fully implement Async Compute. We'll keep everyone posted as we learn more.
Oxide tient à rappeler qu'il ne s'agit que d'une première exploitation de l'Async Compute, qu'il y en aura probablement de meilleures démonstrations et que c'est un sujet complexe dont la bonne maîtrise devra se faire avec la coopération d'AMD et de Nvidia. De toute évidence, Oxide s'est mis d'accord avec Nvidia au sujet de cette communication pour apaiser les esprits en renvoyant le problème vers des pilotes toujours en chantier.
Que ce soit vrai ou pas il s'agit évidemment de la meilleure réponse que pouvait apporter Nvidia pour éviter de ne voir cette polémique sortir du verre d'eau pour prendre de l'ampleur. Ce n'est cependant pas suffisant pour éviter que nous ne nous posions quelques questions.
Direct3D 12 : rappelsAvant de rentrer dans le vif du sujet, il est important de rappeler certains points, notamment parce que dans la fourmilière qu'est le net, nous pouvons lire à peu près tout et n'importe quoi au sujet de Direct3D 12. Une confusion qui est liée à un manque de communication claire de la part de Microsoft et des différents fabricants de GPU. Direct3D 12 est l'API graphique bas niveau de DirectX 12, inspirée par l'API Mantle d'AMD. Sa finalisation a pris de nombreux mois pendant lesquels tous les acteurs de l'industrie se sont concertés pour en ajuster les spécifications et le comportement. Plus qu'une concertation il s'agit en fait d'un lobbying intense compte tenu de l'importance stratégique que représente une nouvelle API graphique. Microsoft, dans son rôle d'arbitre, a essayé de prendre en compte les demandes de chacun tout en veillant bien entendu à ses propres intérêts.
Avec Windows 10, de nouveaux niveaux de fonctionnalités graphiques ont fait leur apparition : 12_1 et 12_0. Contrairement à ce que leur numérotation peut laisser penser et à ce qui s'est passé auparavant avec les niveaux 10_x ou 11_x, ceux-ci ne sont pas liés à Direct3D 12. Ils sont également disponibles sous Direct3D 11. Seules les GeForce GTX 900 (et le GPU de Skylake) supportent le niveau 12_1 mais cela n'implique en rien que ces GPU supportent plus ou moins bien Direct3D 12 qu'un autre GPU. Ces fonctionnalités supplémentaires n'ont aucun lien avec une API graphique de bas niveau. Elles permettront éventuellement de mettre en place des effets graphiques plus complexes et/ou plus performants, autant dans Direct3D 11 que dans Direct3D 12.
Alors qu'est-ce qui définit un bon support de l'API Direct3D12 ou D3D12 en abrégé ? La seule réponse simple est probablement "que le GPU puisse traiter efficacement ce que lui demande de faire le développeur". Le principe d'une API de plus bas niveau et de transférer plus de flexibilité et de contrôle à ce dernier, en partie à l'image de ce qui se fait sur console, ce qui a de nombreux avantages en termes de surcoûts CPU et d'exploitation des CPU multithreads. Mais encore faut-il que le GPU soit lui aussi assez flexible pour traiter efficacement de nouvelles façons d'organiser le rendu 3D.
Les TiersL'un des niveaux de support importants pour D3D12 est le Resources Binding Tier. Grossièrement il s'agit d'un paramètre exposé par la GPU pour indiquer le nombre d'éléments qui peuvent être exploités par le pipeline de rendu 3D : textures, buffers en tous genres, constantes Plus le Tier est élevé (1, 2 ou 3), moins le développeur doit se soucier des différentes limites. Toutes les Radeon récentes (GCN) supportent le Tier 3 alors que les GeForce Maxwell et Kepler se contentent du Tier 2.
Contrairement au niveau de fonctionnalité, le Resources Binding Tier 3 indique un meilleur support de D3D12 que le Tier 2. Mais est-ce que cela fait une grosse différence en pratique ? Probablement pas. Si un développeur a besoin de plus que ce qu'offre le Tier 2, il pourra en général mettre en place un jeu de chaises musicales avec les ressources disponibles. C'est un peu plus contraignant et il peut y avoir un impact sur les performances mais rien n'est impossible.
Nvidia aurait d'ailleurs probablement pu trouver des astuces pour proposer un support du Tier 3, quitte à implémenter directement dans les pilotes un tel jeu de chaises musicales. Mais stratégiquement cela n'aurait eu aucun sens. D'une part le grand public n'entendra jamais parler de cette différence entre Tiers et d'autre part se contenter du Tier 2 permet de forcer les développeurs à rester dans un cadre optimal pour les performances de ses GPU. L'existence du Tier 2 est donc en quelque sorte une victoire pour le lobbying de Nvidia auprès de Microsoft.
Le Multi EngineD'autres spécificités de D3D12 font partie du cur de l'API. Mais bien que dans ce cas de figure leur support soit inévitable, il n'y a pas d'obligation de résultat de la part de Microsoft, l'implémentation matérielle qui en découle étant laissée à l'appréciation des fabricants de GPU. C'est le cas du Multi Engine dont l'Async Compute découle. Une fonctionnalité dévoilée relativement tard par Microsoft et dont nous vous avions déjà parlé ici et que Microsoft documente là .
Grossièrement le Multi Engine permet aux développeurs de prendre le contrôle sur la synchronisation entre différentes tâches et dans certains cas d'exécuter ces tâches simultanément ou en concomitance. Et sur ce point Microsoft a repris exactement la structure qu'AMD avait mise en place avec son API Mantle. Une victoire cette fois pour AMD qui a dessiné le Multi Engine en suivant les contours de l'architecture de ses GPU.
De quoi s'agit-il ? A la base de leur moteur D3D12, les développeurs créent des Command Queues qui sont des files d'attente dans lesquelles vont prendre place des listes de commandes de rendu qui seront exécutées séquentiellement par le GPU pour créer la représentation 3D de la scène. La 10ème liste de commandes à y prendre place devra toujours attendra que les 9 autres aient été exécutées par le GPU avant d'être traitée.
Mais avec D3D12, il est possible d'exploiter plusieurs Command Queues, ce qui permet par exemple de faire traiter certaines tâches en priorité mais aussi en parallèle. L'exemple le plus simple concerne le contrôle direct sur le multi-GPU, une Command Queue pouvant être attribuée à chaque GPU du système si le développeur se charge de répartir le travail de cette manière.

Tout comme Mantle, D3D12 définit 3 types de Command Queues : Copy, Compute et Graphics. Copy peut recevoir toutes les commandes liées aux déplacements de données (avec conversion de formats dans certains cas) telles que le streaming des textures ou encore le transfert au CPU d'une tâche traitée par le GPU. Compute y ajoute les commandes de calcul et de tout ce qui y est lié alors que Graphics supporte l'ensemble des commandes de D3D12.
Graphics est un superset de Compute qui est un superset de Copy. Il est donc possible de n'exploiter qu'une seule Command Queue de type Graphics, cela correspond d'ailleurs à ce qui se passe avec les anciennes API. Exploiter différents types de ces files d'attente peut permettre de gérer différents niveaux de priorité, par exemple exploiter le temps GPU non-utilisé par le rendu 3D pour faire du GPU Computing en arrière-plan.

Mais ce n'est pas tout et nous en arrivons enfin au point qui nous intéresse : l'exécution concomitante (concurrency). Même si le système ne contient qu'un seul GPU, les développeurs peuvent segmenter le travail entre plusieurs Command Queues dans le but de permettre au GPU de les traiter en même temps, en concomitance. De quoi espérer des gains de performances.
Cela implique un travail important pour les développeurs qui vont devoir faire pas mal de profilage pour déterminer ce qui a du sens dans le cadre d'un traitement concomitant. Par exemple si deux commandes de rendu saturent les unités de calcul, il n'y a aucun intérêt à essayer de les traiter en parallèle par rapport à une exécution en série classique. Par contre si une partie du rendu sature les unités de calcul alors qu'une autre sature l'interface mémoire, l'intérêt est évident et le gain de performances peut être substantiel.
C'est à cette sous-possibilité du Multi Engine qu'AMD fait référence en parlant de l'Async Compute. Une terminologie poussée par le service communication d'AMD que nous estimons d'ailleurs très mal choisie puisqu'il est possible de traiter deux tâches de manière asynchrone sans que cela ne se fasse en parallèle.
Exploiter plusieurs Command Queues en vue d'un traitement concomitant implique également que les développeurs s'assurent de la robustesse de leur code. Ils doivent notamment prévoir des barrières de synchronisation là où elles sont nécessaires en prenant en compte l'inconnue liée aux futurs GPU (cet aspect inexistant sur console permet d'y faire quelques raccourcis). Ces barrières (fences) peuvent avoir un coût important en termes de performances et il faut donc faire en sorte de les utiliser avec parcimonie pour que l'ensemble soit bénéfique. Entendez par là que l'intérêt est plutôt d'essayer de traiter tout le post processing en parallèle du rendu de la scène que de calculer la position d'une particule en même temps que le rendu d'un brin d'herbe.
C'est à peu près ce qu'AMD nous avait répondu au mois de mars :
HFR: Let's say developers do an amazing job with fences and barriers in D3D12 to get the most of current GPUs, running tasks concurrently in an optimal fashion. What happens with future GPUs when paradigms and bottlenecks move ? What is optimal for current GPUs might move close to bad cases for future architectures. Will you have room to tweak fences in the drivers to align tasks in a different fashion ? Or would you advise developers not to optimize too deeply and simply try to combine mostly compute intensive with mostly memory intensive tasks ?
AMD: At the moment we're recommending the latter. Micro-optimising is probably not worth it and carries pitfalls; in particular the cost of fences is not insignificant. If applications can do their best efforts to use a couple of fences per frame to line up a few fairly obviously dissimilar workloads, we expect that to provide the majority of the benefit for minimal application effort and acceptable risk in the future.
Par ailleurs, dans bien des cas, ce traitement concomitant va impliquer une augmentation de la latence, ce qui pourra ne pas être adapté à tous les types de jeux. Par exemple le calcul du post processing pour une image donnée ne peut pas débuter avant la fin du rendu de la scène et ne sera donc traité qu'en même temps que le rendu de l'image suivante. Cela augmente quelque peu la latence par rapport à un traitement en série classique mais au profit d'un débit plus élevé.
De quoi sont capables les GPU ?Les GPU disposent tous d'un processeur de commande qui en est en quelque sorte la porte d'entrée. C'est par là que passent toutes les commandes qu'ils vont devoir exécuter et il peut bien entendu y avoir des différences importantes d'un GPU à l'autre. Des processeurs de commandes plus évolués vont pouvoir accepter un débit de commandes plus élevé, gérer plusieurs files d'attente ou encore essayer de dégager du parallélisme.
Il est difficile de savoir précisément ce dont sont capables les processeurs de commandes des GPU. Il s'agit généralement d'une zone d'ombre très peu décrite par AMD et Nvidia qui se contentent de simplifications grossières. Voici ce qu'AMD et Nvidia nous avaient indiqué au mois de mars :
Chez AMD :
Tous les GPU GCN supportent l'exécution concomitante Graphics/Compute/Copy mais il y a des limitations pour les GPU GCN 1.0 (Tahiti, Pitcairn, Cape Verde, Oland) par rapport à la synchronisation des tâches de type Copy.
En plus d'un processeur de commande graphique principal, tous les GPU GCN intègrent des Asynchronous Compute Engines (ACE) qui peuvent traiter les tâches Compute en concomitance et des DMA engines qui font de même avec les tâches Copy. Le nombre d'ACE par GPU peut varier ainsi que le nombre de files d'attentes par ACE. Plus il y a d'ACE, plus il y a de tâches qui peuvent être traitées en parallèle. Plus il y a de files d'attente, plus les ACE ont de flexibilité pour trouver une tâche à exécuter sans conflit de synchronisation avec une autre.
Cette structure à base d'ACE et de files d'attente permet de maximiser l'utilisation du GPU lorsque les tâches Compute sont petites et nombreuses. Cela a été mis en place avant tout dans l'optique du calcul professionnel mais cette approche autorise également le traitement concomitant dans le cadre du rendu 3D avec D3D12 et de multiples Command Queues même si dans ce cas un seul ACE aurait probablement été suffisant.
-Tahiti, Pitcairn, Cape Verde, Oland: 1 processeur Graphics + 2 ACE avec 1 file d'attente chacun
-Bonaire: 1 processeur Graphics + 2 ACE avec 8 files d'attente chacun
-Hawaii, Tonga et Fiji: 1 processeur Graphics + 8 ACE avec 8 files d'attente chacun
Quelques slides d'AMD permettent d'illustrer de manière simplifiée ce concept de traitement concomitant :



A gauche, un GPU basique qui ne supporterait aucun traitement concomitant : il alterne entre les tâches. Au milieu, un GPU qui souffrirait de la même limitation (AMD parle-t-il de Maxwell 2 ?) mais ferait appel à la préemption pour permettre à une tâche de passer devant une autre. Enfin à droite un GPU GCN capable de prendre en charge plusieurs flux de tâches en concomitance.
Chez Nvidia :
Pour tous ses GPU récents, Nvidia parle d'un seul gros processeur de commandes. Dans le cas des GPU Fermi et Kepler (sauf GK110/GK210), ils se contentent par ailleurs d'une seule file d'attente. Aucun traitement concomitant des tâches n'est donc possible. Si de multiples Command Queues sont exploitées par le moteur graphique, elles seront exécutées séquentiellement.
Les GK110/GK210 et les GPU Maxwell 1 (GM107/GM108) intègrent un processeur de commandes plus évolué avec une technologie baptisée Hyper-Q qui permet de supporter 32 files d'attente, mais uniquement dans un mode purement Compute. Les GK110/GK210 supportent par ailleurs 2 DMA Engines, mais ils sont réservés aux déclinaisons Quadro/Tesla. Hyper-Q permet d'exécuter des tâches de type Compute en concomitance mais il est peu probable que cela soit exploité en dehors du pilote CUDA.
Avec les GPU Maxwell 2 (GM200/GM204/GM206), Nvidia nous a indiqué avoir fait sauter toutes ces limitations. Tout d'abord, le second DMA Engine est bien actif sur les déclinaisons GeForce. Mais surtout, quand Hyper-Q est actif, une des 32 files d'attente peut être de type Graphics. Au niveau de l'implémentation logicielle, Nvidia nous a précisé en mars qu'un traitement concomitant complet de tous les types de tâches était supporté sous Direct3D 12 pour les GPU Maxwell 2.
-GeForce Fermi, Kepler et Maxwell 1 : 1 processeur de commandes avec 1 file d'attente Graphics
-GeForce Maxwell 2 : 1 processeur de commandes avec 32 files d'attente 1 Graphics + 31 Compute
Rectification d'AMDTout cela c'était en mars. Quelques mois plus tard et probablement avec un peu d'expérience sur les nouvelles API, il y a quelques rectifications à faire. Tout d'abord du côté d'AMD qui a discrètement modifié sa façon de présenter les ACE lors des dernières présentations liées au GPU Fiji.

[ Fiji en juin ] [ Fiji en août ]
AMD ne parle plus de 8 ACE pour son GPU Fiji mais bien de 4 ACE + 2 HWS (Hardware Scheduler). Interrogé sur ce que cela signifiait, AMD nous a indiqué qu'un ACE pouvait être vu comme un processeur de commandes multitâche qui se charge de la sélection/préemption des tâches à travers ses files d'attente, de la distribution des tâches vers les unités de calcul et de l'exécution des commandes de synchronisation. Or seuls 4 ACE en sont capables ou ont été configurés de manière à l'être.
AMD explique que les 4 autres sont exploités pour soulager le CPU dans la gestion de l'ordonnancement des files d'attentes et des tâches sur les 4 ACE principaux, notamment dans le cadre de la virtualisation. AMD y fait dorénavant référence en tant que Hardware Schedulers (HWS). Nous ne savons cependant pas pourquoi AMD parle de 2 HWS et non de 4. Nos questions supplémentaires à ce sujet n'ont pas trouvé de réponse et nous ne savons pas si Tonga et Hawaii ont été configurés de la sorte ou si c'est spécifique à Fiji. Nous sommes cependant tentés de penser que c'est bel et bien le cas au vu de l'annonce récente du support matériel de la virtualisation sur des FirePro basées sur Hawaii.
Dans le cadre de D3D12, cette rectification de la part d'AMD ne fait aucune différence mais témoigne de la zone d'ombre que représentent les processeurs de commandes des GPU.
et silence chez NvidiaSi D3D12 impose de supporter de multiples Command Queues, il n'y a pas d'obligation au niveau de l'implémentation matérielle et du support du traitement concomitant. Au vu des résultats des GeForce GTX 900 dans Ashes of the Singularity et des déclarations d'Oxide, il était logique de se demander si les GPU Maxwell supportaient réellement ce que Nvidia nous avait affirmé en mars au niveau de leur processeur de commandes.
Nous avons donc questionné Nvidia sur le sujet dès le 31 août, qui nous a indiqué que nous recevrions une réponse dans la journée tous les jours de la semaine passée. Mais aucune réponse ne nous est parvenue jusqu'ici ce qui signifie qu'il n'est pas simple pour Nvidia d'en rédiger une. De quoi nous laisser penser que les GPU Maxwell 2 souffrent au mieux de sérieuses limitations pour exploiter le traitement concomitant des tâches. Après l'histoire du bus mémoire limité de la GeForce GTX 970, cela commencerait à faire beaucoup d'imprécisions techniques dans la communication de Nvidia
Quelques réflexionsLa première déclaration d'Oxide mentionne que les GPU Maxwell 2 ne supportent pas nativement l'exécution simultanée de tâches Compute et Graphics et que Nvidia expose malgré tout le support des "Async Shaders" qui seraient émulés. Cela expliquerait pourquoi les performances sont mauvaises et Oxide aurait travaillé avec Nvidia pour mettre en place un mode spécial qui évite d'utiliser les "Async Shaders" mais qui est moins performant que le premier mode sur GPU AMD. Mais ce qu'indique Oxide ne nous semble pas tout à fait correct.
D'après notre compréhension des spécifications de D3D12, Async Shaders n'en est pas une fonctionnalité de D3D12 que l'on peut ou pas exposer. C'est un concept mis en avant par le marketing technique d'AMD et qui représente une des possibilités qui découle de l'utilisation du Multi Engine et des multiples Command Queues dont le support est obligatoire.
Le problème qu'a pu rencontrer Oxide est probablement légèrement différent, mais il s'agit de spéculation de notre part. Par exemple il se peut tout simplement que les GPU Maxwell 2, comme tous les autres GPU Nvidia et comme le permet D3D12, exécutent séquentiellement les multiples Command Queues accusant alors le surcoût des barrières de synchronisation sans profiter du traitement concomitant.
Une autre possibilité est que les GPU Maxwell 2 alternent entre des listes de commandes de différentes Command Queues en souffrant à chaque fois d'un lourd changement d'état, toujours sans profiter du moindre traitement concomitant. Enfin, il est possible que les GPU Maxwell 2 exécutent bel et bien différents types de tâches en concomitance mais en accusant un surcoût important et une faible efficacité, ce qui rend l'opération néfaste sur le plan des performances.
Dans tous les cas, c'est probablement indirectement qu'Oxide a dû faire en sorte d'éviter ces écueils, probablement en repassant sur un modèle à base d'une seule Command Queue ou en mettant en place un système simplifié de barrières de synchronisation exclusivement destiné à forcer un traitement séquentiel.
Cela pourrait laisser penser que Nvidia n'a pas tout dit en indiquant que les GPU Maxwell 2 sont capables d'effectuer un traitement concomitant avec le support matériel d'une file d'attente Graphics associée à 31 files d'attentes de type Compute. Plusieurs éléments peuvent d'ailleurs aller dans ce sens.
Nvidia nous a par exemple expliqué dès le mois de mars que pour sa version de l'Asynchronous Timewarp, technique destinée à réduire la latence ressentie en réalité virtuelle, aucune exécution concomitante n'est mise ne place. Nvidia fait appel à la préemption avec un changement de contexte. Cela a un coût, mais il n'est payé qu'une seule fois puisque le rendu de l'image est interrompu totalement le temps de traiter le Timewarp. AMD fait de son côté appel au traitement concomitant avec une priorité plus élevée pour les threads du Timewarp mais Nvidia se justifie en expliquant qu'il est préférable de dédier tout le GPU à son exécution pour le traiter le plus rapidement possible.
Par ailleurs, la documentation technique liée à Hyper-Q nous laisse apercevoir que Nvidia propose pour ses cartes Tesla une surcouche logicielle appelée MPS (Multi Process Service) qui permet de combiner ensemble les tâches Compute de plusieurs process de manière à pouvoir les exécuter en concomitance. Sans cela, chaque process représente un contexte GPU distinct et aucune concomitance n'est possible entre tâches issues de process différents. Si les différents types de Command Queues sont considérés par le pilote de la même manière que des process différents, il est possible qu'une telle surcouche logicielle soit également nécessaire pour profiter du traitement concomitant sous D3D12 et éviter de lourds changements de contextes. Il pourrait alors y avoir un coût CPU et des limitations au niveau du GPU.
Bien entendu il est également possible que tout ceci soit lié à un malentendu suite à des pilotes qui ne seraient pas encore au point du côté de Nvidia. Mais cela nous paraît peu probable face au silence de Nvidia et au fait que ce spécialiste du GPU et des techniques de rendu à eu de très nombreux mois pour se préparer et n'ignorait pas que ce point allait prendre un aspect compétitif important.
Les Radeon vont-elles avoir l'avantage sous Direct3D 12 ?Vous l'aurez compris, il est très probable que les GeForce GTX 900 basées sur l'architecture Maxwell de seconde génération souffrent de limitations qui les empêchent de profiter du Multi Engine de Direct3D 12 pour proposer un support efficient de l'exécution concomitante de tâches. Ces GeForce pourraient ainsi passer à côté de certains gains de performances.
A l'inverse, les Radeon semblent disposer d'une architecture bien adaptée pour en profiter et proposer différentes optimisations sur le plan des performances. De quoi peut-être gagner quelques points de compétitivité. Une démonstration technique d'AMD à laquelle nous avions pu assister en mars permettait de gagner 17% alors que sur console certains développeurs tireraient déjà des gains allant jusqu'à 30%.
Difficile cependant de savoir ce qu'en feront en pratique les développeurs sur PC, puisque ce sont eux qui auront en général le dernier mot. La situation est plus complexe que sur console et AMD nous a par exemple admis dès le mois de mars ne s'attendre qu'à des utilisations basiques dans un premier temps, notamment parce que des optimisations trop poussées sur les GPU actuels pourraient avoir un coût prohibitif au niveau des synchronisations ou être contreproductives dans le futur.
Par ailleurs, tous les types de rendus ne seront pas de bons candidats pour en profiter et en attendant sa prochaine génération de GPU, il ne fait aucun doute que Nvidia essaiera de se démarquer d'une autre manière dans les premiers jeux Direct3D 12, par exemple avec des effets graphiques spécifiques aux fonctionnalités supplémentaires des GPU Maxwell 2.
Dans l'immédiat, il serait utile que Nvidia documente clairement ce dont sont capables ses GPU sur ce point, ce qui permettrait au passage de comprendre en partie les possibilités d'optimisations éventuelles au niveau des pilotes. Il est par contre peut-être difficile pour l'égo de la société de communiquer des détails qui pourraient venir confirmer un avantage de la concurrence.
IDF: Samsung lancera sa HBM en 2016
Lors de l'IDF, Samsung a annoncé qu'il allait lancer en 2016 de la mémoire HBM. Pour rappel ce type de mémoire a été co-développée par AMD et Hynix et est devenu un standard ratifié par le Jedec, il a fait sa première apparition sur les R9 Fury X.
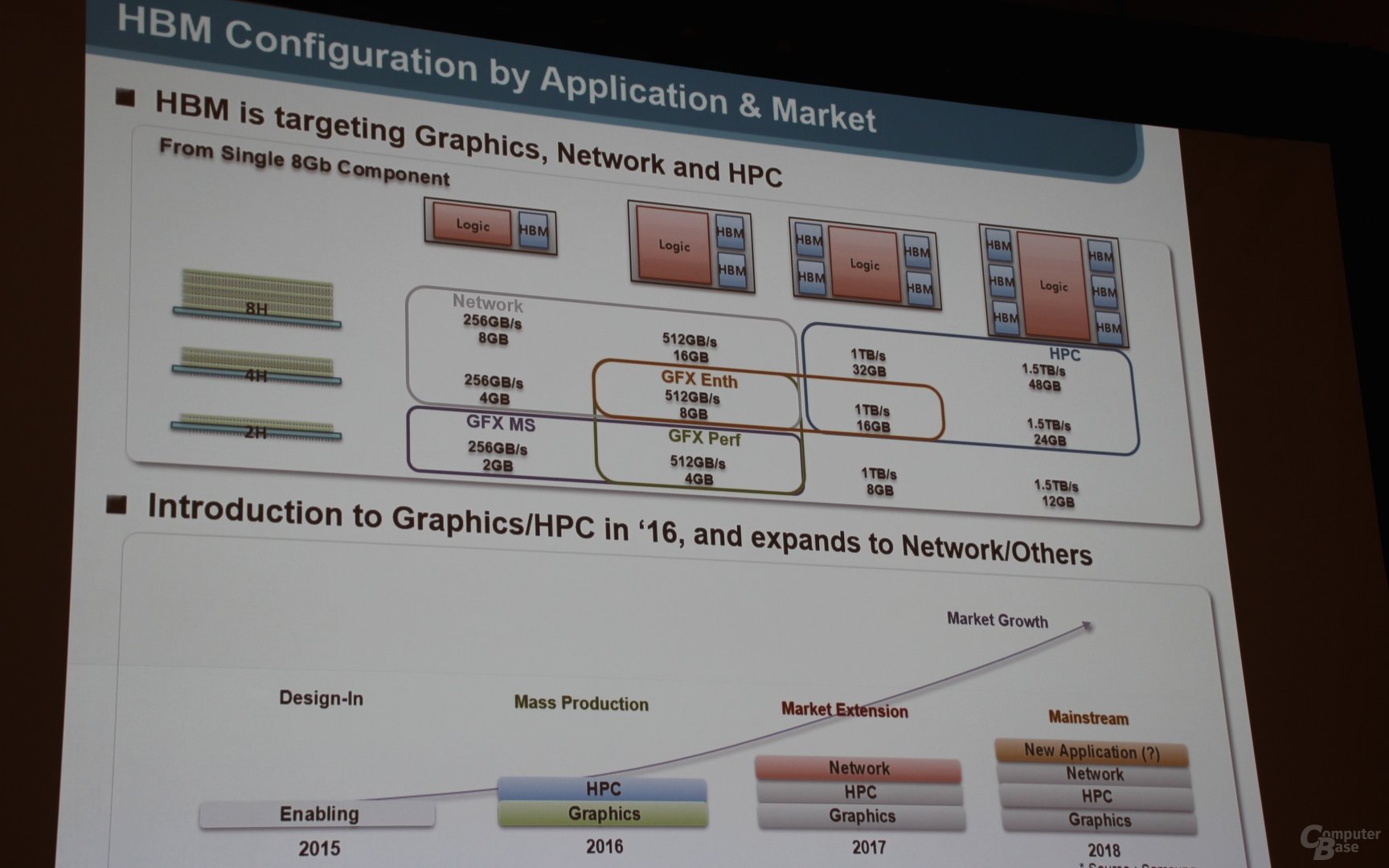
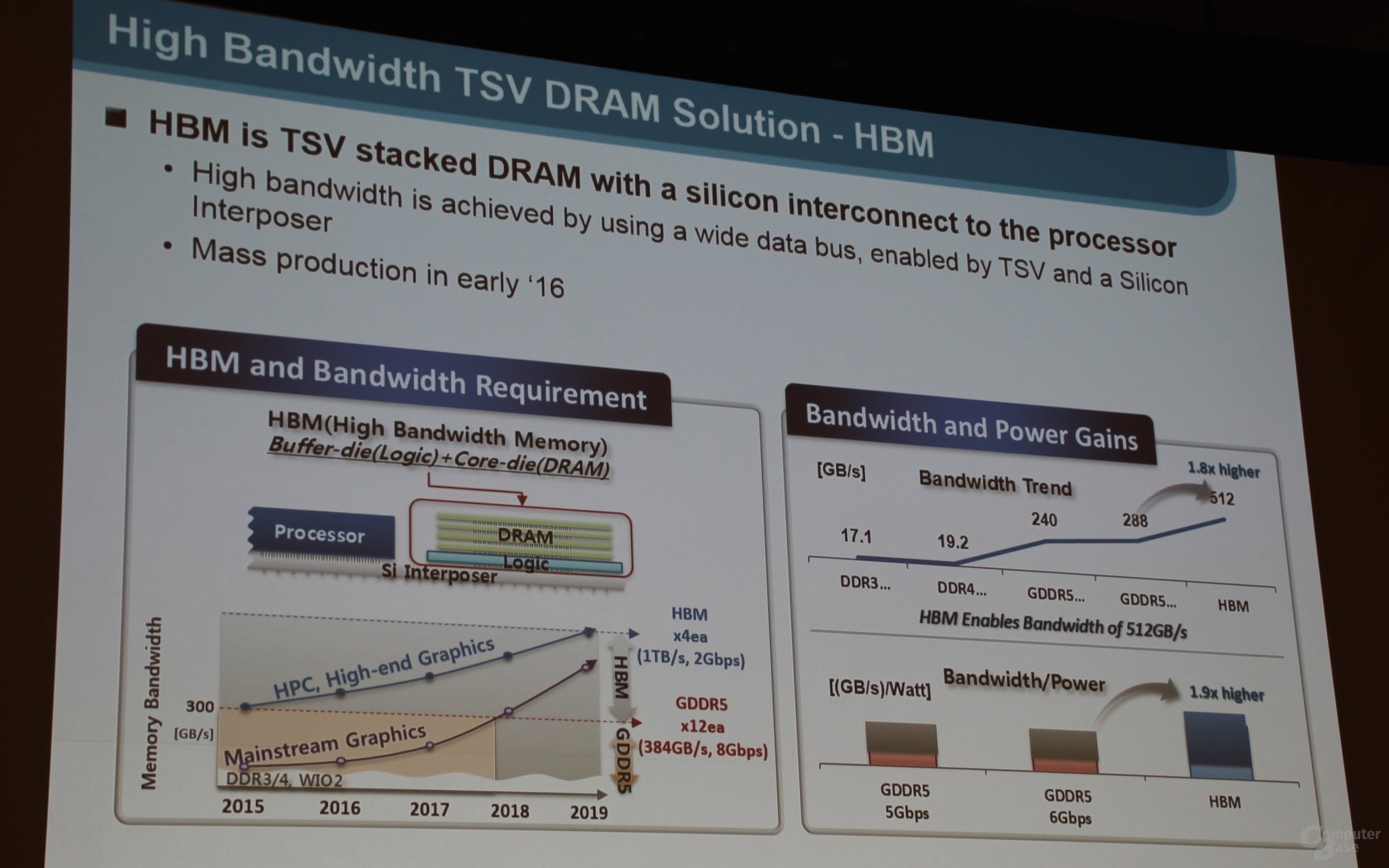
A l'instar de la seconde génération de HBM Hynix prévue également pour l'an prochain, la HBM de Samsung sera basée sur des dies de 8 Gb qui seront empilés par 2, 4 ou 8 au sein de puces capables de fournir une bande passante de 256 Go /s chacune.
Cela permettra d'envisager de nombreuses configurations, de 2 Go à 256 Go /s à 48 Go à 1.5 To /s, les GPU haut de gamme devant probablement se "contenter" de 8 à 16 Go à 1 To /s, une bande passante doublée par rapport à la Fury X qui devrait être la bienvenue avec le passage des GPU au 14/16nm.
Alors que certaines rumeurs indiquaient qu'AMD allait avoir les faveurs d'Hynix en ce qui concerne l'approvisionnement en HBM de seconde génération du fait de leur passif, l'arrivée de Samsung sur ce marché devrait donc faire les affaires de Nvidia qui prévoit également d'utiliser ce type de mémoire avec sa prochaine architecture Pascal.
Marché GPU : Nvidia 82%, AMD 18%
Pour faire suite à notre news d'hier concernant le marché du GPU, les chiffres de Mercury Research donnant le détail des parts de marché au niveau des GPU additionnels pour PC de bureau sont désormais connus pour le second trimestre. Avec 18% des ventes, AMD est à un niveau historiquement bas, Nvidia étant désormais à un niveau qu'on peut qualifier d'Intelien.
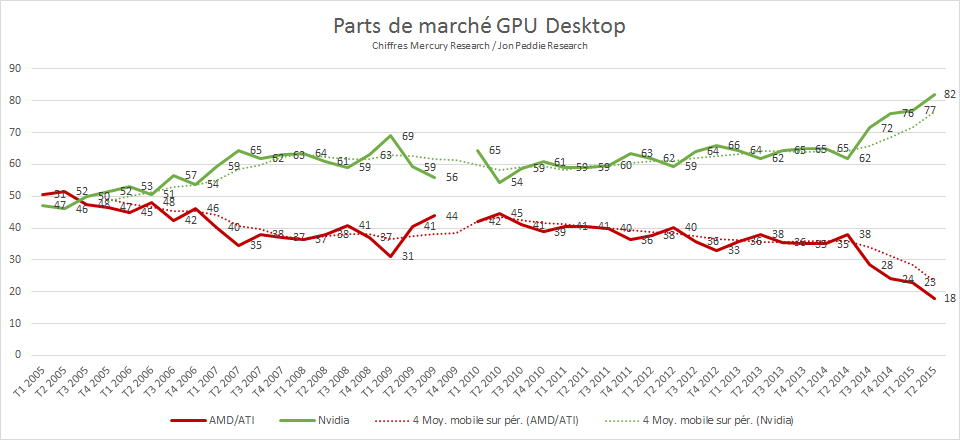
Il y a dix ans, les deux acteurs étaient au coude à coude, avant une longue période durant laquelle AMD évoluait entre 35 et 45% du marché. Depuis le troisième trimestre 2014 qui a connu l'arrivée des GPU Maxwell GM204 (GTX 970/980), AMD a vu ses ventes diminuer de manière régulière.