
Les contenus liés au tag GTC
Afficher sous forme de : Titre | FluxGTC: Le futur de Tegra: CUDA, Logan, Parker
GTC: GPU: Maxwell puis Volta et DRAM stacking
GTC: CUDA s'ouvre officiellement à Python
GTC: Nvidia GPU Technology Conference 2013
GTC: GeForce GRID: jouer depuis le cloud
GTC: 5W Pour Tegra 4 et 1W pour Tegra 4i ?



Lorsque nous avions rencontré Nvidia pour parler de l'architecture des Tegra 4 et 4i, il y a un point que le concepteur de ces SoC a catégoriquement refusé d'aborder : la consommation en charge et le TDP. Des chiffres délicats à avancer et à assumer puisque de toute évidence, la consommation maximale de Tegra 4 sera supérieure à celle de Tegra 3. Ceci n'étant bien entendu pas incompatible avec un rendement énergétique supérieur et avec une consommation en baisse lors de scénarios de types charge faible.

Lors d'une présentation dédiée aux investisseurs qui a suivi la keynote principale de la GTC, Jen-Hsun Huang, CEO de Nvidia, a avancé des chiffres concernant les TDP des futurs SoC : 5W pour Tegra 4 et 1W pour Tegra 4i. Deux chiffres relativement faibles, voire très faibles dans le cas du Tegra 4i qui intègre pour rappel 4 Cortex-A9 r4, un GPU relativement véloce et un modem 4G/LTE.
Pour comprendre ces chiffres, il faut cependant savoir que la définition du TDP est à géométrie variable, comme nous l'avions expliqué en nous intéressant de plus près au SDP d'Intel. Globalement le TDP représente la capacité de refroidissement nécessaire pour garantir le bon fonctionnement du composant. Historiquement cela représentait sa limite haute de consommation, mais progressivement, le fait de pouvoir fonctionner à une fréquence réduite pour éviter une surchauffe a été intégré à la définition même de "bon fonctionnement". Ajoutez-y les modes turbo et la prise en compte de l'inertie thermique et vous comprendrez qu'il devient difficile d'interpréter l'impact exact du TDP sur la consommation et sur les performances.
Les chiffres de 5W et de 1W avancés par Nvidia représentent ainsi probablement la capacité de dissipation nécessaire pour les variantes les moins gourmandes de Tegra 4 et de Tegra 4i. Des chiffres qui permettent de se faire une idée des types de designs et de formats qui pourront accueillir ces composants. De quoi confirmer que Tegra 4 est plutôt adapté à une tablette alors que Tegra 4i pourra être intégré facilement dans des smartphones compacts.
Difficile de dire par contre quel sera le niveau de performances soutenu autorisé par ces TDP puisqu'il est probable, comme c'est le cas pour la plupart des SoC actuels, que les Tegra 4 et 4i soient autorisés à consommer plus que cette valeur, jusqu'à atteindre une certaine température et voir leurs fréquences réduites. En plus de ces TDP, soit de la capacité de dissipation requise, il serait ainsi intéressant de connaître la capacité de dissipation conseillée par Nvidia pour pouvoir tirer le meilleur de ces SoC en termes de performances, notamment en ce qui concerne le jeu qui représente l'une des tâches les plus gourmandes qu'ils auront à exécuter.

Enfin, notez que le CEO de Nvidia a précisé le timing de l'entrée en production des périphériques qui intégreront ces futurs SoC : Q2 2013 pour Shield, les tablettes et les superphones Tegra 4, Q4 2013 pour les tablettes Tegra 4 + modem i500 et enfin Q1 2014 pour les smartphones Tegra 4i (i500 intégré).
GTC: GRID VCA: Nvidia et la virtualisation
Lors de la GTC 2012, Nvidia avait dévoilé les solutions VGX et GeForce GRID dédiées à la virtualisation des GPU respectivement dans les domaines de l'entreprise et du jeu PC en parlant autant de solutions tout-en-un que de composants et de couches logicielles. Un petit peu floue, la stratégie de Nvidia a été simplifiée et réorganisée autour de la marque GRID, ce qui a impliqué plusieurs changements de noms :
GRID for Gaming englobe tout ce qui concerne le cloud gaming
GRID for Enterprise englobe tout ce qui concerne la virtualisation en entreprise
GRID K1 et GRID K2 représentent les noms des 2 premiers accélérateurs graphiques
GRID VGX est le nom de la couche de virtualisation : hyperviseur + VDI
GRID K1 intègre pas moins de 4 GPU GK107 mais se contente d'un TDP de 130W. Ces GPU sont partiellement castrés et seule la moitié de leurs unités de calcul sont actives, soit 192 par GPU et 768 au total. Chacun est équipé de sa propre mémoire de 4 Go.
GRID K2 est de son côté basé sur 2 GPU GK104, plus véloces. Le TDP passe à 225W (avec une option à 250W) et si la mémoire est également de 4 Go par GPU, ils disposent par contre chacun de 1536 unités de calcul, pour un total de 3072, et sont ainsi adaptés au cloud gaming en plus de la virtualisation graphique en entreprise.
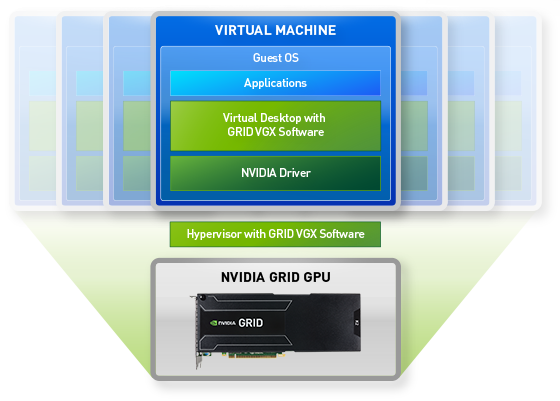
L'an passé, Nvidia annonçait que l'hyperviseur GRID VGX était capable de profiter des 32 accès concurrents possibles sur chaque GPU Kepler pour supporter un nombre très élevé d'utilisateurs, soit une centaine sur GRID K1. En pratique, VGX sous cette forme n'est cependant pas encore prêt. L'infrastructure de bureaux virtuels (VDI) maison est par contre fonctionnelle et actuellement exploitée avec une solution temporaire (1.0) moins évoluée qui consiste à dédier un GPU à chaque machine virtuelle. En d'autres termes, un seul utilisateur par GPU est supporté. La solution VGX complète (2.0) est cependant en cours de finalisation et sera déployée dès qu'elle aura été validée. Rappelons que la VDI de Nvidia profite de l'encodeur vidéo intégré dans les GPU Kepler pour sortir directement de ceux-ci un flux h.264 qui n'a plus qu'à être transféré vers le poste client, un avantage important en terme d'efficacité.
Ce point étant fait, passons à la nouveauté présentée lors de la GTC 2013 : GRID VCA pour Visual Computing Appliance. GRID VCA est un serveur de virtualisation dédié aux réseaux internes et le premier produit tout-en-un qui sera commercialisé par Nvidia. Il s'agit en quelque sorte de la transformation en produit fini Nvidia d'une variante de GRID for Enterprise prévue pour les applications graphiques lourdes (Autodesk, 3dsmax etc.) avec une licence Quadro USM (User-Selectable Machines) qui active les optimisations des pilotes pour les applications professionnelles ainsi que le support de CUDA. Intégré dans le réseau local, ce serveur permet à n'importe quel poste client de se transformer en station de travail.

Au niveau matériel, GRID VCA est un serveur 4U qui repose sur une plateforme Intel 2P, deux Xeon 8 cores / 16 threads (dont le modèle exact n'est pas précisé par Nvidia), 384 Go de mémoire et 8 cartes GRID K2 (soit 16 GPU GK104 chacun équipé de 4 Go de mémoire vidéo). Une configuration moins musclée est également proposée et se contente d'un seul Xeon, de 192 Go de mémoire et de 4 cartes GRID K2.
Actuellement, la configuration maximale peut supporter jusqu'à 16 utilisateurs alors que la configuration réduite se contente de 8 utilisateurs en simultané. Dès que l'hyperviseur GRID VGX aura été validé et déployé, ces limites seront bien entendu revues à la hausse à travers une mise à jour logicielle.
A partir de la fin du printemps ou du début de l'été, GRID VCA équipé de 8 GRID K2 sera commercialisé au tarif de 39.900$ alors que la version qui se contente de 4 GRID K2 sera proposée à 24.900$. Outre le matériel, il faudra s'acquitter annuellement d'une licence logicielle Nvidia qui reviendra à 4.800$ pour la première configuration et à 2.400$ pour la seconde. Cette licence comprend l'utilisation de la couche logicielle Nvidia (virtualisation et VDI), toutes les mises à jour, la maintenance et un support complet.
Nvidia qui dispose ici d'une solution unique sur le marché, ne compte bien entendu pas s'arrêter là et si ces premiers serveurs de virtualisation graphique trouvent leur public, la famille GRID VCA s'agrandira progressivement. Nous pouvons ainsi supposer qu'une version équipée en GPU GK11x pour profiter de toutes les évolutions de CUDA est au programme.
GTC: FaceWorks: rendu de visage réaliste
Au début de la keynote d'ouverture de la GTC, le CEO de Nvidia, Jen-Hsun Huang, a présenté une nouvelle démo technologique plutôt impressionnante. Elle s'attaque à une tâche complexe : le rendu du visage humain.

Si la partie graphique est très évoluée, il est question de pixels shaders de plus de 8000 instructions pour l'éclairage qui prend en compte la diffusion sous-cutanée ou encore la réflexion partielle sur la transpiration, c'est la représentation des mouvements et des micro-mouvements qui représente ici le challenge. Dénommée FaceWorks, la technologie de Nvidia a été développée en collaboration avec l'Institute for Creative Technology de l'USC et se base sur des prototypes de systèmes de capture de mouvements extrêmement précis (au dixième de millimètre).
Ceux-ci génèrent une quantité énorme de données : Nvidia parle de 32 Go pour une poignée d'expression. Impossible pour un GPU de travailler sur une telle base. FaceWorks consiste à organiser les composantes de ces expressions sous forme de textures, de les compresser et de détecter les similitudes avec d'autres expressions pour en supprimer les données superflues. Avec une perte de fidélité limitée, Nvidia parvient à passer de 32 Go à 400 Mo de données et rend ainsi leur utilisation viable.
Pour observer la qualité de l'animation du visage, nous vous conseillons de jeter un coup d'il au segment de la keynote qui concerne FaceWorks, avec un visage rendu et animé en temps réel sur une GeForce GTX Titan. Notez pour l'anecdote qu'AMD ne manquera probablement pas de faire remarquer à Nvidia que son personnage manque de cheveux !
GTC: CUDA on ARM: Tegra 3 + Tesla K20
En plus des plateformes CUDA on ARM destinées à simuler de futurs SoC que ce soit pour une utilisation de type périphérique mobile grand public ou de type micro-serveur, des développements se font également autour d'accélérateurs très puissants tels que les Tesla K20.
C'est le cas chez l'européen PRACE qui développe des systèmes dédiés au supercomputing et s'intéresse à CUDA on ARM depuis quelques temps. En collaboration avec le Barcelona Supercomputing Center, PRACE est en train de mettre au point une plateforme ARM équipée en GK110 : Pedraforca v2. Celle-ci est composée d'une carte mini-ITX sur laquelle prend place un module Q7 Tegra 3 dont 4 des lignes PCI Express 2.0 sont connectées à un switch PLX PCI Express 3.0 sur lequel vont venir se greffer un accélérateur Tesla K20 et une carte contrôleur InfiniBand 40 Gbps.

Cette plateforme a la particularité de ne pas rechercher la complémentarité entre les cores CPU et GPU. Grossièrement, le but est d'utiliser le SoC ARM uniquement pour activer un système CUDA plus ou moins indépendant. C'est la raison pour laquelle le Tesla K20 est associé à un contrôleur InfiniBand sur un même switch PCI Express 3.0 : ils peuvent ainsi communiquer très rapidement avec les accélérateurs d'autres nuds en ignorant autant que possible la communication avec les SoC et leurs mémoires.
Les développeurs de Pedraforca v2 sont bien conscients qu'une telle approche n'est pas une solution de remplacement générale à un système CUDA classique et se contentera de répondre avantageusement à un sous-ensemble de problématiques : si un problème massivement parallèle peut être résolu sans CPU, autant réduire l'encombrement et la consommation de celui-ci.
Une telle solution permet par ailleurs de simuler le comportement de futurs GPU haut de gamme qui pourraient intégrer un ou plusieurs cores ARMv8 Denver pour gagner en indépendance. De quoi commencer à préparer des algorithmes qui leur seront adaptés ?
GTC: CUDA on ARM: Kayla, Tegra 3 et GK208
Nvidia l'a enfin confirmé, CUDA arrivera enfin dans les SoC Tegra avec Logan. Cela ne veut pas dire pour autant que CUDA sur plateforme ARM doit attendre. Il s'agit d'un point important de la stratégie de Nvidia pour son futur autant dans le monde professionnel que grand public. C'est la raison pour laquelle, depuis quelques temps déjà, Nvidia s'est associé à SECO pour proposer un kit de développement dénommé CARMA. Pour 529, la plateforme propose un connecteur Q7 qui reçoit un SoC Tegra 3 (T30 à 1.3 GHz) et un connecteur MXM sur lequel prend place une Quadro 1000M de génération Fermi (GF108 avec 96 cores).

Tout cela va évoluer à partir du mois de mai, d'une part avec une couche logicielle qui supportera Ubuntu 12.04 et CUDA 5.0, et d'autre part avec la plateforme KAYLA, toujours développée en partenariat avec SECO, et qui existera en 2 versions : connecteur MXM ou PCI Express (câblés en 4x dans les 2 cas). Si nous aurions pu supposer que le SoC passerait en version Tegra 4, c'est bel et bien le Tegra 3 T30 qui reste exploité pour la simple et bonne raison que ses successeurs ne disposent plus de liens PCI Express. La différence (unique ?) entre les 2 cartes concerne les GPU supportés. La version PCI Express en supporte un large choix et la version MXM est annoncée être équipée d'un GPU Kepler de next generation.
Nvidia indique à ce sujet que ce GPU dispose de 2 SMX (384 cores), supporte les compute capabilities 3.5 (Dynamic Parallelism etc.) et est très proche du niveau de fonctionnalité du futur SoC Logan. Nous apprenons ainsi que le GPU de cette plateforme et celui de Logan disposent d'un processeur de commande plus évolué que sur les premiers GPU de la génération Kepler, dérivé de celui du GK110 (Tesla K20 et GTX Titan).
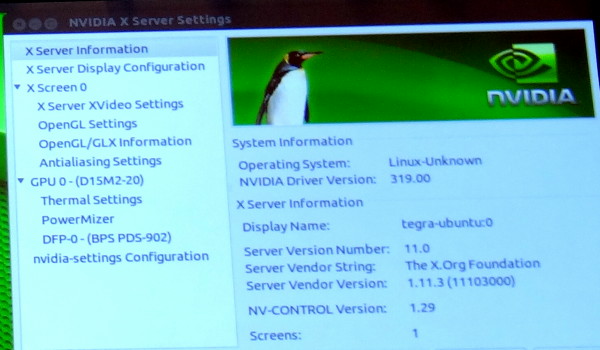
De toute évidence ce GPU est ainsi le GK208 qui prendra place dans les GeForce 700 d'entrée de gamme. Une supposition renforcée par un panneau de contrôle des pilotes Linux que Nvidia a malencontreusement oublié de masquer pendant quelques secondes et qui fait référence à un nom de code produit : D15M2-20. Cela correspond à la famille GeForce 700 desktop (D12 = GeForce 400, D13 = GeForce 500, D14 = GeForce 600 ).

Cette plateforme CUDA on ARM continuera bien entendu à évoluer, tout d'abord avec CUDA 5.5 qui intégrera un compilateur CUDA pour l'architecture ARM, et plus tard avec l'arrivée de Logan et de Parker.
Correction du 01/07/2013: le nom du GPU que nous pensions être GK117 est en réalité GK208.