
Les contenus liés au tag GTC
Afficher sous forme de : Titre | FluxGTC: Nvidia Tesla P100: 10 Tflops, HBM2...
GTC: Deep-learning : +70% pour Pascal
GTC: Multi-Res Shading, pas que pour la VR ?
GTC: VKCPP et NVK pour simplifier Vulkan
Nvidia Pascal: le FP16 pour doubler les Tflops
GTC: Supermicro premier sur le Tesla P100 ?



Supermicro exposait à la GTC un prototype non fonctionnel de serveur 1U à base de Tesla P100. Celui-ci est prévu pour embarquer 4 de ces accélérateurs ainsi qu'une configuration bi-Xeon et une carte graphique ou un autre accélérateur au format PCI Express 16x. Le fabricant taiwanais explique que le nouveau format de type mezzanine et les liens NVLink ont demandé pas mal de travail lors de la conception du serveur.

C'est notamment le cas au niveau du refroidissement qui est un challenge évident compte tenu de la consommation qui monte à 300W par Tesla P100 alors que la densité progresse compte tenu de la compacité de cette solution. Supermicro a ainsi décidé de placer ces 4 accélérateurs, surmontés d'imposants radiateurs, côte à côte juste après l'entrée d'air frais, ce qui permet de les refroidir tous de la même manière.

Supermicro précise que certains concurrents ont opté pour une autre organisation, avec par exemple un "carré" de Tesla P100, et que d'après ses essais, il y a beaucoup de risques que les GPU les plus éloignés de l'entrée d'air en souffrent, par exemple en atteignant plus rapidement leur limite de température.
Malgré l'état de la solution exposée, Supermicro nous a confirmé être très proche de la finalisation de ce serveur et s'attendre à être le premier sur le marché, tout du moins si Nvidia ne tarde pas à livrer les Tesla P100.
GTC: Tesla P100: débits PCIe et NVLink mesurés
Lors d'une session de la GTC consacrée à GPUDirect, qui regroupe les techniques de communications entre GPU et avec d'autres éléments d'un système, nous avons pu en apprendre un peu plus sur les performances du GP100 au niveau de ses voies de communication.
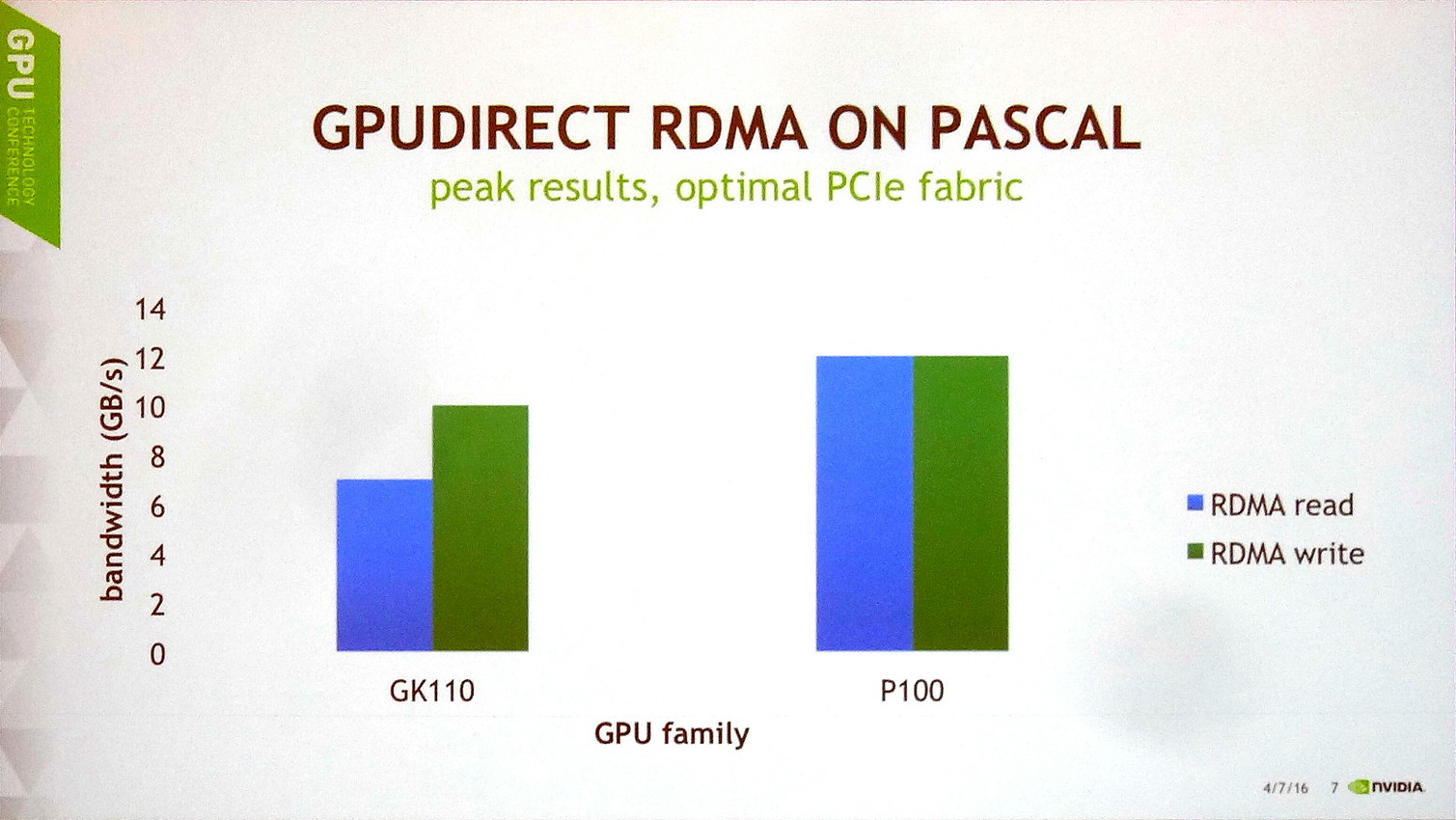
Il y a tout d'abord des progrès au niveau du PCI Express. Nvidia explique que les GPU Kepler et Maxwell souffraient de quelques limitations et devaient se contenter d'à peu près 10 Go/s en écriture et de 7 Go/s en lecture. Cela change avec Pascal dont le tissu PCI Express est dorénavant optimal pour une interface 16x 3.0, ce qui lui permet d'atteindre 12 Go/s dans les deux sens, soit à peu près le maximum théorique.
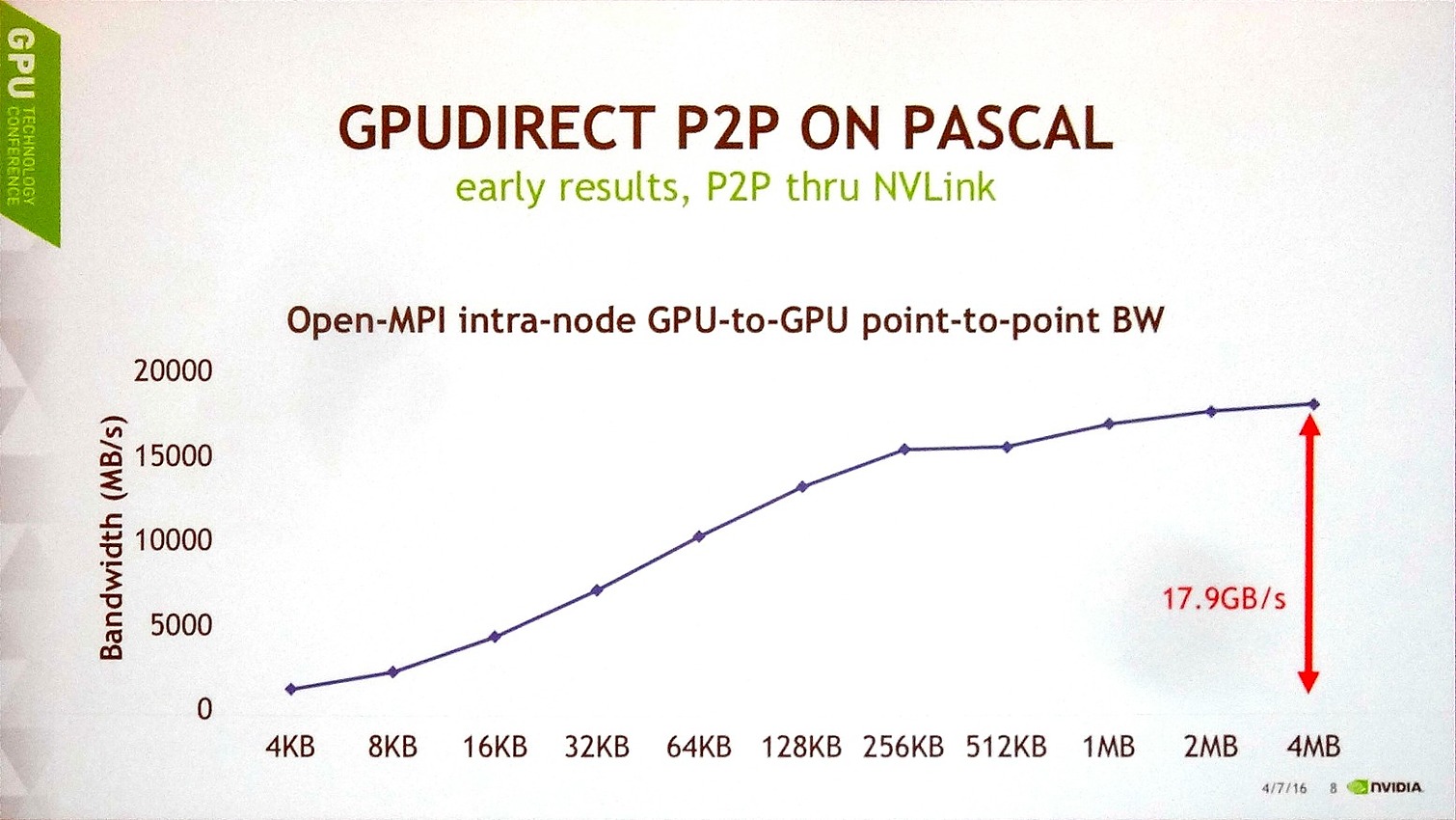
Ensuite, Nvidia a publié les premiers chiffres de débits obtenus pour les liens NVLink en communication point-à-point entre 2 GP100, tout en précisant que toutes les optimisations n'avaient pas encore été mises en place. Pour ce test, un seul lien NVLink est ici exploité et le transfert est unidirectionnel.
Avec des blocs de 4 Mo, le GP100 parvient à monter à 17.9 Go/s, ce qui est plutôt pas mal compte tenu du fait que l'interface est spécifiée à 20 Go/s dans chaque direction. Le débit reste supérieur à 15 Go/s avec des blocs de 256 Ko, mais plonge rapidement sous cette valeur, ce qui est un résultat attendu pour toute voie de communication compte tenu du surcoût par transfert. Ces premiers résultats sont donc plutôt encourageants et Nvidia explique qu'ils sont obtenus grâce à l'intégration de moteurs de copies pour chaque lien NVLink.
GTC: HBM 2 SK Hynix : quelques détails
Bien que Nvidia ait dans un premier temps opté pour la mémoire HBM 2 de Samsung, de toute évidence parce qu'elle est la première disponible, SK Hynix avait comme chaque année fait le déplacement à la GTC. L'occasion de poser quelques questions au fabricant.

Concernant l'estimation de la disponibilité de cette mémoire, nous n'en saurons pas plus par rapport aux dernières rumeurs qui parlent du troisième trimestre. SK Hynix nous a par contre confirmé que ce serait bien le module 4Hi de 4 Go qui serait lancé en premier lieu, suivi par la version 8Hi de 8 Go et enfin par la version 2Hi de 2 Go. Le fabricant nous a expliqué que cette organisation de la production n'est par contre en rien liée à des challenges supplémentaires pour passer à 8 couches de DRAM ou pour condenser les canaux dans le cas de la version 2Hi. Ces choix auraient été effectués uniquement par rapport aux commandes fermes qui lui ont été passées.
Cette arrivée tardive de la version 2 Go, que l'on pourrait plutôt imaginer pour les solutions d'entrée de gamme démontre une fois de plus que ce type de technologie va prendre du temps à apparaître sur ce segment.
A noter que concernant la différence de consommation en passant d'un module 4Hi à 8Hi, SK Hynix n'a pas voulu communiquer de nombre précis mais après insistance nous a indiqué qu'il s'agissait d'un nombre à un chiffre, et que la différence n'aurait ainsi qu'un impact limité au vu de la consommation des GPU haut de gamme qui y seront associés. Ce ne serait donc pas un frein pour doubler la mémoire d'un Tesla P100 par exemple.
La mémoire HBM 2 Samsung exploitée par Nvidia sur le Tesla P100 a la particularité d'être de hauteur identique à celle du GPU GP100, ce qui facilite le refroidissement de l'ensemble. Pour cela, l'épaisseur de la dernière couche de DRAM a été adaptée à celle du GPU en prenant en compte tous les éléments de la chaîne d'assemblage, comme vous pouvez l'observer ci-dessous (le spacer est en fait la dernière couche de DRAM) :

Pour la mémoire HBM 2, et contrairement à la HBM 1, SK Hynix fait de même et propose une production personnalisée avec épaisseur variable des modules. Pour le fabricant ce n'est pas un souci dans un premier temps puisque cette mémoire correspond de toute manière à des commandes spécifiques. Par contre à l'avenir, SK Hynix s'attend à ce que le JEDEC standardise ce point ou tout du moins en limite les variantes à 2 ou 3 chaînes de production.
GTC: Nvidia DGX-1: 8 Tesla P100 pour 129.000$
Lors de la keynote d'ouverture de la GTC, Jen-Hsun Huang ne s'est pas contenté d'annoncer l'accélérateur Tesla P100, mais a également dévoilé un nouveau serveur qui sera commercialisé sous sa propre marque : le DGX-1. Orienté deep learning, ce supercalculateur embarque pas moins de 8 Tesla P100 pour un tarif de 129.000$ HTVA.

On n'est jamais aussi bien servi que par soi-même. C'est probablement ce qu'a dû se dire Nvidia pour accélérer la disponibilité du Tesla P100 sur un marché qui peut prendre du temps à bouger de lui-même, d'autant plus quand la compétition est rude et quand la plateforme change significativement. Après quelques expériences avec les serveurs GRID VCA (Visual Computing Appliance) et Quadro VCA, Nvidia propose ainsi un supercalculateur orienté vers le deep learning, un domaine en pleine explosion et pour lequel l'architecture Pascal a été optimisée.
Le DGX-1 est un serveur 3U capable d'atteindre 170 Tflops FP16, mode de calcul basse précision qui peut être exploité par les algorithmes de deep learning. Il atteint également 85 Tflops en FP32 et 42 Tflops en FP64 grâce à l'intégration de GPU Pascal. De quoi permettre à Nvidia de mettre en avant un gain de 75x au niveau de la vitesse d'entrainement d'un réseau de neurones artificiels par rapport à un serveur qui se conterait de CPU classiques.

Ce supercalculateur très dense embarque pas moins de 8 accélérateurs Tesla P100, chacun équipé de 16 Go de mémoire HBM2. Ceux-ci sont pilotés par 2 Xeon E5-2698 v3 (16 coeurs à 2.3 GHz), chacun associé à 256 Go de DDR4 2133. Nvidia a également opté pour un stockage plutôt costaud avec 4 SSD de 1.92 To en RAID 0. De quoi pouvoir prendre en charge de larges datasets. Si le DGX-1 est relativement compact au vu de la puissance de calcul qu'il embarque, il n'est par contre pas léger avec 60 kg sur la balance, ce qui s'explique en partie par l'alimentation et le refroidissement qui sont prévus pour encaisser 3200W, dont 2400W rien que pour les 8 Tesla P100.
Nvidia a bien entendu prévu le DGX-1 pour profiter pleinement de la connectique NVLink. Pour rappel, chaque GPU GP100 intègre 4 de ces liens qui offrent chacun une bande passante bidirectionnelle de 40 Go/s . Voici la topologie qui a été retenue et que Nvidia nomme NVLink Hybrid Cube Mesh :
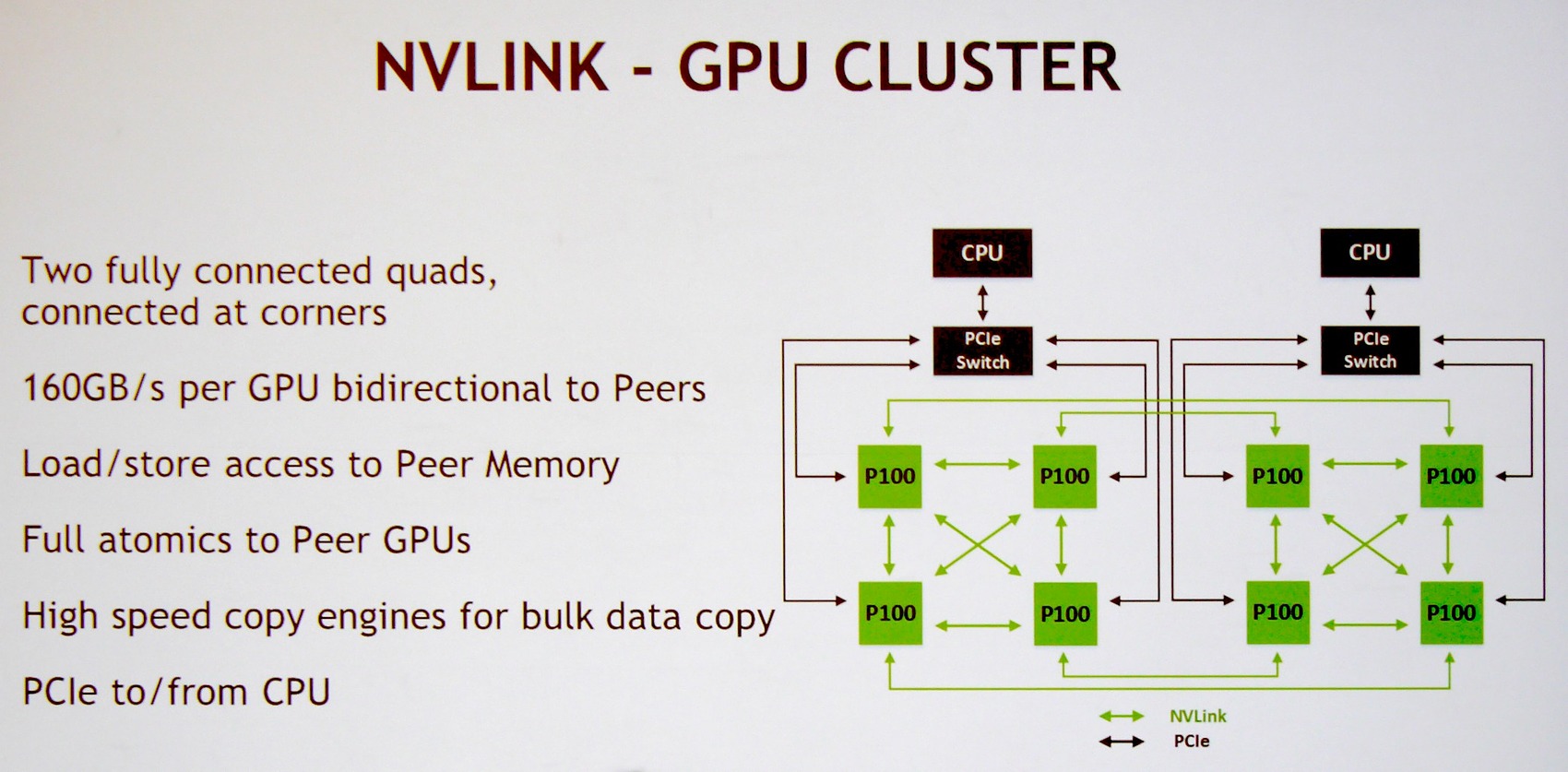
Assez logiquement 4 Tesla P100 sont reliés à chaque CPU via des liens PCI Express qui passent par un switch. Ensuite ces 4 GPU sont reliés entre eux via 3 de leurs liens NVLink. Enfin, leur quatrième lien est exploité pour les relier à l'un des GPU du second groupe de 4 Tesla P100. Il y aura donc quelques limitations au niveau de la communication entre ces 2 groupes de Tesla P100, mais elle est maintenue possible par cette topologie.
Nvidia annonce une disponibilité dès le mois de juin pour le DGX-1, ce qui semble très rapide, même si dans un premier temps cela ne concernera que les Etats-Unis. Il faudra en effet attendre le troisième trimestre pour une disponibilité plus globale.
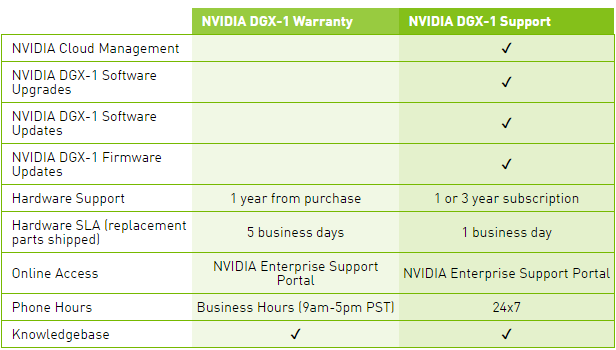
Le tarif communiqué par Nvidia monte à pas moins de 129.000$ HTVA, et ce pour le package basique, Warranty, qui n'inclus aucune mise à jour pour la suite logicielle, ce qui est étrange compte tenu de l'évolution très rapide et continuelle de ses outils dédiés au deep learning. Pour avoir accès à ces mises à jour, il faudra ajouter une cotisation annuelle pour passer au package Support.
Une politique tarifaire qui nous laissent penser que l'accélérateur Tesla P100 seul sera commercialisé à un prix très élevé. Nous ne serions pas étonnés de voir Nvidia atteindre la barre symbolique des 10.000$.
GTC: N'attendez pas de GeForce en GP100 !
Si le GP100 a fait les gros titres de la GTC, il est désormais presque certain en ce qui nous concerne qu'il n'y aura pas de GeForce l'utilisant, hormis peut-être une Titan mais même à ce niveau rien n'est moins sûr. Ce GPU de plus de 15 milliards de transistors fait de nombreux compromis totalement orientés vers le calcul haute performance et qui n'ont pas spécialement d'intérêt dans le cadre du rendu temps réel pour les jeux vidéo. C'est par exemple le cas de la double précision ou encore des liens NVLink.
Par ailleurs, le marché du GPU computing et surtout le potentiel énorme du deep learning sont des éléments suffisamment importants pour justifier de la part de Nvidia d'enfin investir dans la production d'une puce spécifique au marché professionnel.

Sur la GTC, Nvidia a systématiquement refusé de répondre à toute question concernant les dérivés grand public du GP100 et de la Tesla P100. Même au niveau des cartes Quadro. De quoi donner du poids à l'impression que le GP100 pourrait être dédié au GPU computing, voire même n'offrir aucune sortie vidéo pour se concentrer sur la connectique NVLink.
C'est en fait une supposition que nous faisons depuis quelques temps et qui de toute évidence est en train de se concrétiser. Bien que nous n'ayons pas pu en avoir la confirmation officielle de Nvidia, plusieurs sources externes nous ont confirmé que notre intuition était correcte et qu'il n'y aura donc pas de GeForce basée sur le premier gros GPU Pascal.
Cela ne veut pas dire que Nvidia abandonne les joueurs, bien au contraire ! Un GPU dédié, clairement orienté haut de gamme serait en cours de finalisation et devrait être annoncé sous peu d'après nos informations. Celui-ci devrait se contenter de GDDR5 ou de GDDR5X et exploiter la totalité de ses transistors pour les besoins du rendu temps réel.
Face au coût très élevé de la mémoire HBM et de son interposer, ainsi que de la production limitée qui en découle, Nvidia aurait fait le choix pragmatique de développer deux solutions haut de gamme en parallèle. Affaire à suivre.