
Les contenus liés au tag Intel
Afficher sous forme de : Titre | FluxIntel lance de nouveaux SSD NAND 3D
Nouvelle extension vectorielle ARMv8-A SVE
AMD continue de gagner des parts de marché GPU
Intel Custom Foundry prend une licence ARM !
Microsoft capitule sur le support de Skylake
Coffee Lake en 28W et 45W pour 2018



Un extrait de roadmap d'Intel a été publié ces derniers jours sur le forum d'Anandtech . On y voit apparaître pour la première fois Coffee Lake dont nous avions appris l'existence durant l'été.
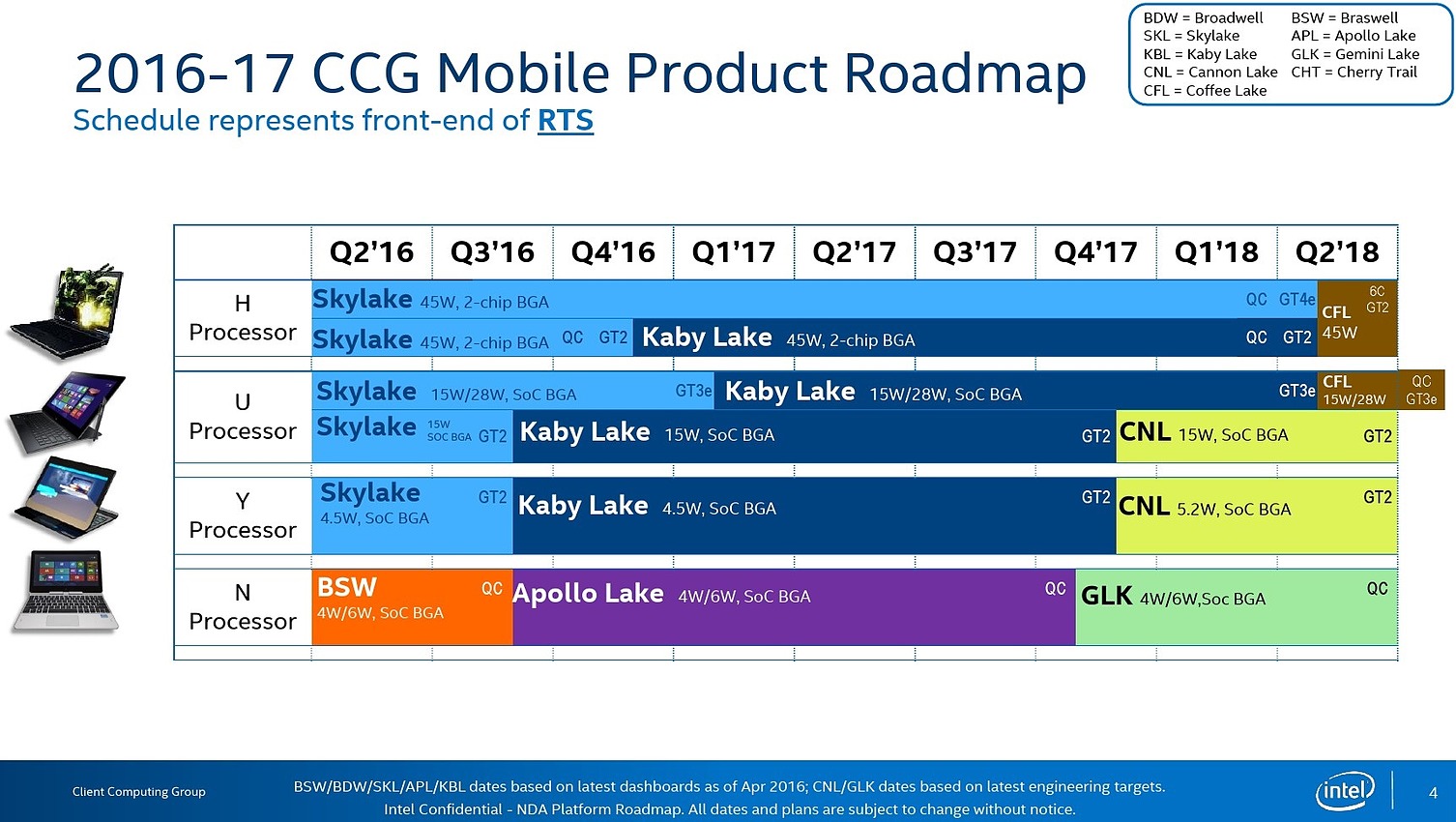
Pour rappel, Intel propose aujourd'hui Kaby Lake, sa troisième itération sur le process 14 nm, uniquement pour les modèles 15 et "4.5" watts (les gammes U et Y). Lors de l'annonce, Intel avait indiqué que les versions Desktop ainsi que les versions quad cores mobiles et équipées du cache L4 seraient annoncées en janvier. Cette roadmap d'avril semble alignée sur ce point, même si l'on note qu'une version quad core GT2 (sans mémoire L4 embarquée) en 45W (gamme H) était prévue pour le 4eme trimestre. On verra si cette version aura été repoussée également à janvier.
Cannon Lake, fabriqué en 10nm, est prévu pour la toute fin de l'année 2017, uniquement là aussi sur les gammes 15 et "5.2" watts à l'image de Kaby Lake aujourd'hui.
En ce qui concerne Coffee Lake, il s'agira d'une quatrième itération en 14nm, prévue pour le second trimestre 2018. On le retrouvera à la fois dans les gammes U et H, pour les dies 15/28W et les 45W. Plusieurs surprises de ce côté, d'abord le fait qu'Intel proposerait des puces 15/28W quad core avec Coffee Lake. Ce serait un changement majeur, les quad core étant réservés jusqu'ici au TDP supérieur côté mobile (45W).
Et comme nous l'avions entendu a l'époque, pour le plus haut de gamme (45W), Intel augmentera là aussi le nombre de coeurs passant (enfin) à 6. Il est là aussi intéressant de noter que si le GT3e est bien présent sur le segment en dessous, dans les gammes H le GT4e est aux abonnés absents, aussi bien pour Kaby Lake que Coffee Lake. Il faut dire que même côté Skylake, si les modèles Iris Pro 580/GT4e ont été annoncés, en pratique leur disponibilité dans des PC portables est proche du néant.
Après un Broadwell-H très en retard et la situation actuelle autour des Skylake-H (qui fâche parmi ses clients les plus visibles comme Apple qui avait utilisé les modèles Iris Pro Quad Core dans ses Macbook Pro), on peut se demander si Intel ne jette tout simplement pas l'éponge sur ces SKUs pour ses deux prochaines générations...
Brix Gaming UHD chez Gigabyte
Gigabyte vient de lancer un nouveau mini-PC dans sa gamme Brix, le Brix Gaming UHD. Nous avions déjà entrevu rapidement ce modèle au Computex.



Visuellement, il s'agit d'une tour à base carrée (11cm de côté pour 22cm de hauteur) avec un coin aplati dans lequel on retrouvera la connectique de la carte mère, à savoir deux ports USB 3.0, deux ports USB 3.1 (un Type-A et un Type-C), un connecteur Gigabit Ethernet, les prises audio et deux connecteurs pour les antennes WiFi. A gauche de ces ports, on retrouvera ceux de la carte graphique, à savoir un HDMI et trois Mini DP.
Sur son site, Gigabyte met en avant l'existence de deux modèles, un en Core i5 et l'autre en Core i7 de génération Skylake. On aura donc au choix un Core i5-6300HQ (2.3/3.2 GHz) ou un Core i7-6700HQ (2.6/3.5 GHz). Pour le reste les caractéristiques sont identiques avec une carte mère utilisant le chipset HM170 d'Intel disposant de deux slots SO-DIMM DDR4.

La conception interne est assez originale puisque la carte mère est placée en diagonale dans le boîtier tandis que la carte graphique, une GTX 950 avec 4 Go de GDDR5, est placée sur un coin du boîtier. Il s'agit d'une carte MXM placée sur un PCB custom. Ce dernier est relié par deux câbles à la carte mère pour faire passer le signal PCI Express. La carte graphique est surplombée par un radiateur biseauté.
Sur la carte mère, on retrouve deux slots M.2 2280, reliés respectivement au chispet et au CPU, ainsi qu'un slot PCIe M.2 dans lequel est placée la carte WiFi Intel 8260 (ac). On pourra aussi placer deux disques SATA 2.5 pouces, un derrière la carte graphique, et l'autre dans le coin opposé à côté du radiateur processeur.
Le refroidissement est assuré par un ventilateur unique en 92mm qui aspire l'air par le bas et le fait traverser le boîtier pour sortir par le haut.
Ce design de Gigabyte a le mérite d'être original, même si il n'est pas sans nous rappeler, au moins dans l'idée de sa carte mère en diagonale le Mac Pro.
Gigabyte annonce un prix public autour de 949 euros pour la version Core i7, sans préciser clairement la disponibilité qui devrait arriver dans les prochaines semaines.
Intel se sépare de l'Intel Security Group
 Intel vient d'annoncer un partenariat avec un fond d'investissement privé, TPG Capital, pour rendre indépendant McAfee, plus connu récemment sous le nom d'Intel Security Group depuis 2014.
Intel vient d'annoncer un partenariat avec un fond d'investissement privé, TPG Capital, pour rendre indépendant McAfee, plus connu récemment sous le nom d'Intel Security Group depuis 2014.
La nouvelle entité reprendra le nom de McAfee et sera détenue à 51% par TPG Capital, et à 49% par Intel. L'investissement de TPG est de 1.1 milliard de dollars, mais la société ajoute la création de deux milliards de dette pour la nouvelle entité, une dette qui sera gérée par Intel.
Le montage financier - en plusieurs étapes - est un peu compliqué mais permet à Intel de dire dans son communiqué de presse que la société recevra 3.1 milliards de dollars en cash pour la transaction. Un moyen pour Intel de sauver la face puisque pour rappel, Intel avait payé 7.7 milliards de dollars pour s'offrir McAfee en 2010.

Mais comme le pointent nos confrères de Forbes , si l'on met de côté l'édition d'une nouvelle dette, la valeur à la vente de la société n'est en réalité que de 2.2 milliards, a peine plus d'un quart de ce que valait McAfee au moment de son rachat par Intel !
Déjà peu compréhensible à l'époque, ce rachat aura été au final très coûteux pour la firme de Santa Clara. L'annonce met aussi en perspective les relations tendues entre Intel et John McAfee ces derniers jours. L'image du fondateur de McAfee ne collait pas vraiment à celle d'Intel qui avait tout fait pour s'éloigner du nom, en renommant la société Intel Security Group en 2014.
Avec la volonté d'Intel de redonner le nom original à la nouvelle société indépendante, on comprend mieux pourquoi Intel avait annoncé son opposition à la volonté de John McAfee de renommer sa nouvelle société "John McAfee Global Technologies". Ce dernier a déposé une plainte à New York la semaine dernière pour trancher la question.
Intel lance les Kaby Lake 2C
C'est l'été dernier qu'Intel avait annoncé un changement de stratégie. Durant des années, la firme de Santa Clara s'est tenu au Tick-Tock : lancer un nouveau process de fabrication une année (un Tick), et lancer l'année suivante une nouvelle architecture (un Tock). Un cycle de deux années (parfois étendu de quelques mois) qui se répétait depuis l'introduction du système dans les années 2000.

La version classique du packaging utilisée par Intel pour ses SoC mobiles U (15W)
Après un passage au 14nm difficile qui nous avait valu un "Haswell Refresh", Intel avait annoncé que son process 10nm serait repoussé à fin 2017 (il aurait du être introduit cette année) et que l'on aurait droit pour 2016 à un nouvelle entrant, Kaby Lake, une version "optimisée". La stratégie passante ainsi de "Process-Architecture" à "Process-Architecture-Optimisation".

La version compacte du packaging utilisée par Intel pour ses SoC mobiles Y ("4.5W")
Lors de l'annonce des résultats financiers au second trimestre l'année dernière, le CEO d'Intel Brian Krzanich avait décrit Kaby Lake comme "bâti sur les fondations de la micro architecture Skylake" mais "avec des améliorations clefs de performances". Nous pensions à l'époque qu'Intel ne ferait possiblement évoluer que son GPU.

Aujourd'hui on en sait enfin un peu plus. Intel annonce Kaby Lake comme la septième génération de processeurs Core et lance aujourd'hui six modèles de processeurs dont le "TDP" varie entre 4.5 et 15W. En pratique il s'agit des SoC deux coeurs (avec Hyper Threading) destinés aux PC portables légers (type Macbook/Ultrabook et 2-in-1). Le lancement des autres versions (mobiles 4C, avec Iris Graphics, et les versions desktop) se fera en janvier.

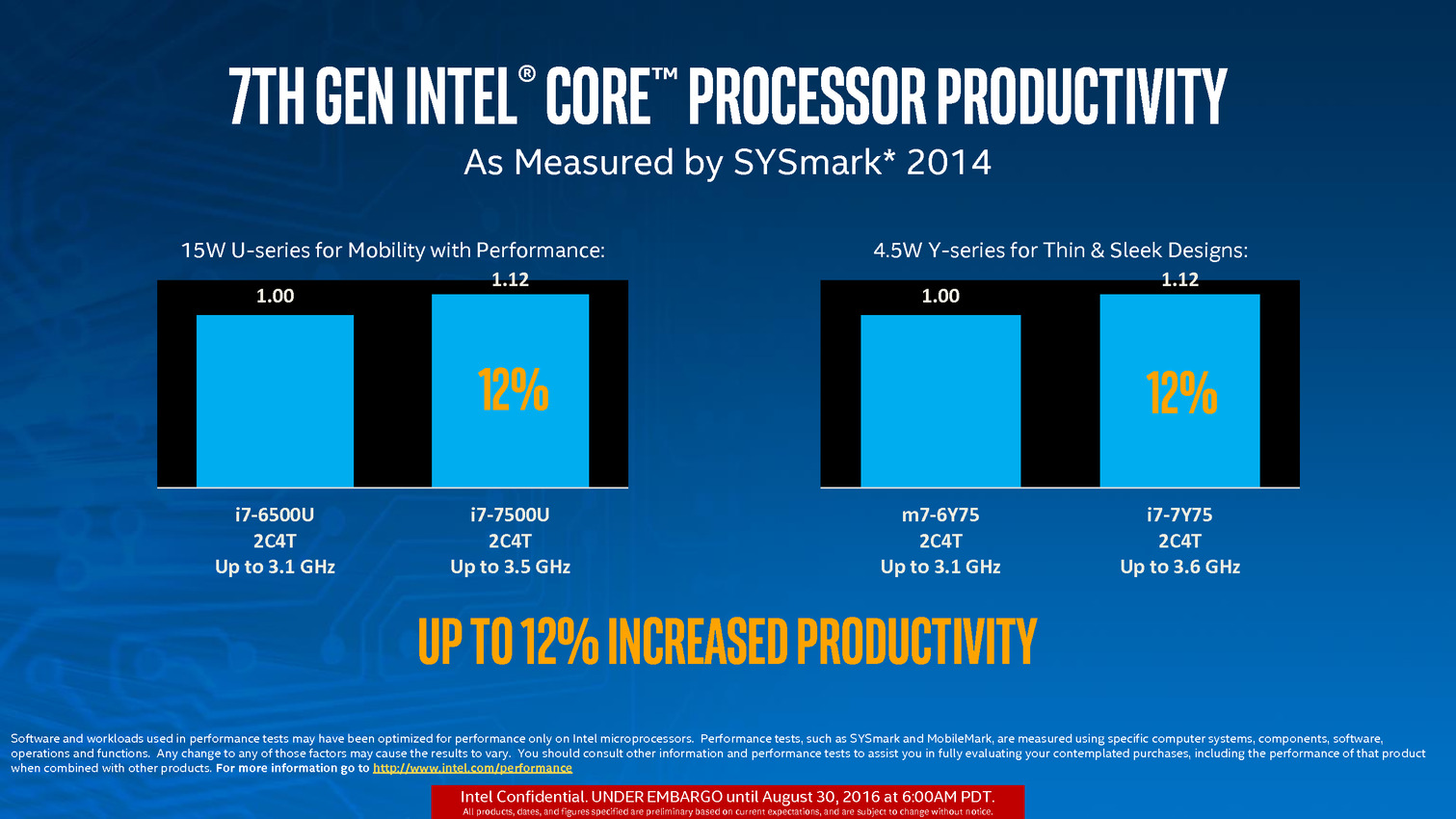
La plus grosse nouveauté mise en avant par Intel est l'évolution de son process de fabrication, le constructeur le qualifiant de 14nm+ (faisant echo aux 16FF+ de TSMC par exemple). Intel indique avoir amélioré la géométrie de son process, au niveau de la forme des "fins" (les ailettes qui constitue les transistors FinFET) et aussi du canal. La société annonce 12% d'amélioration de performances (sans préciser à quel niveau) ce qui est assez vague.
En effet, au fil de l'exploitation d'un process, sa fiabilité, son rendement, et incidemment ses performances évoluent. Etant donné les difficultés rencontrées par Intel au début de l'exploitation du 14nm, il est difficile de juger réellement ce que ce chiffre représente, et s'il s'agit vraiment d'une évolution par rapport à la production ayant eu lieu par exemple ces derniers mois, ou s'il s'agit tout simplement de l'évolution naturelle, lié au débogage et à l'exploitation du process.

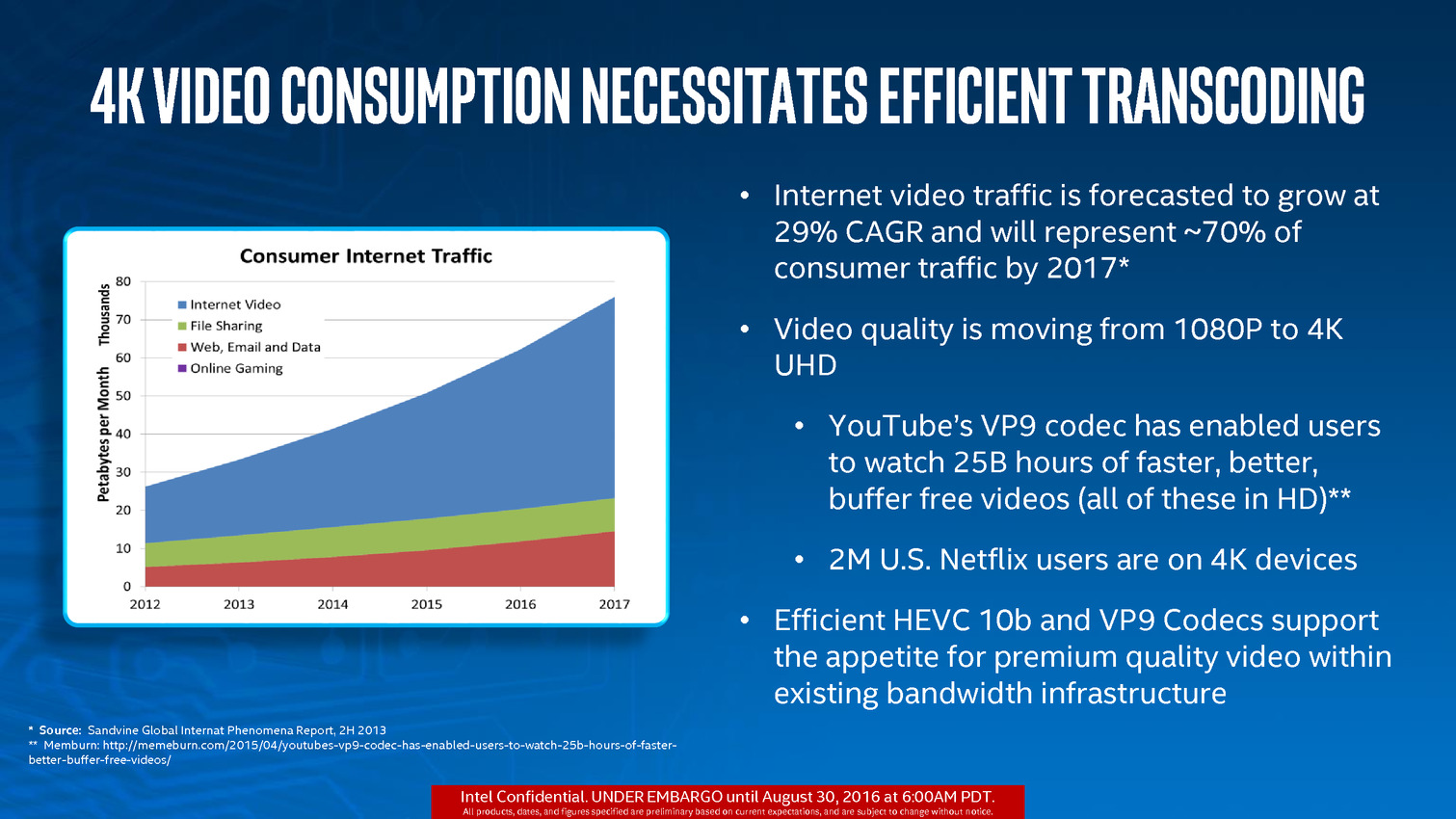
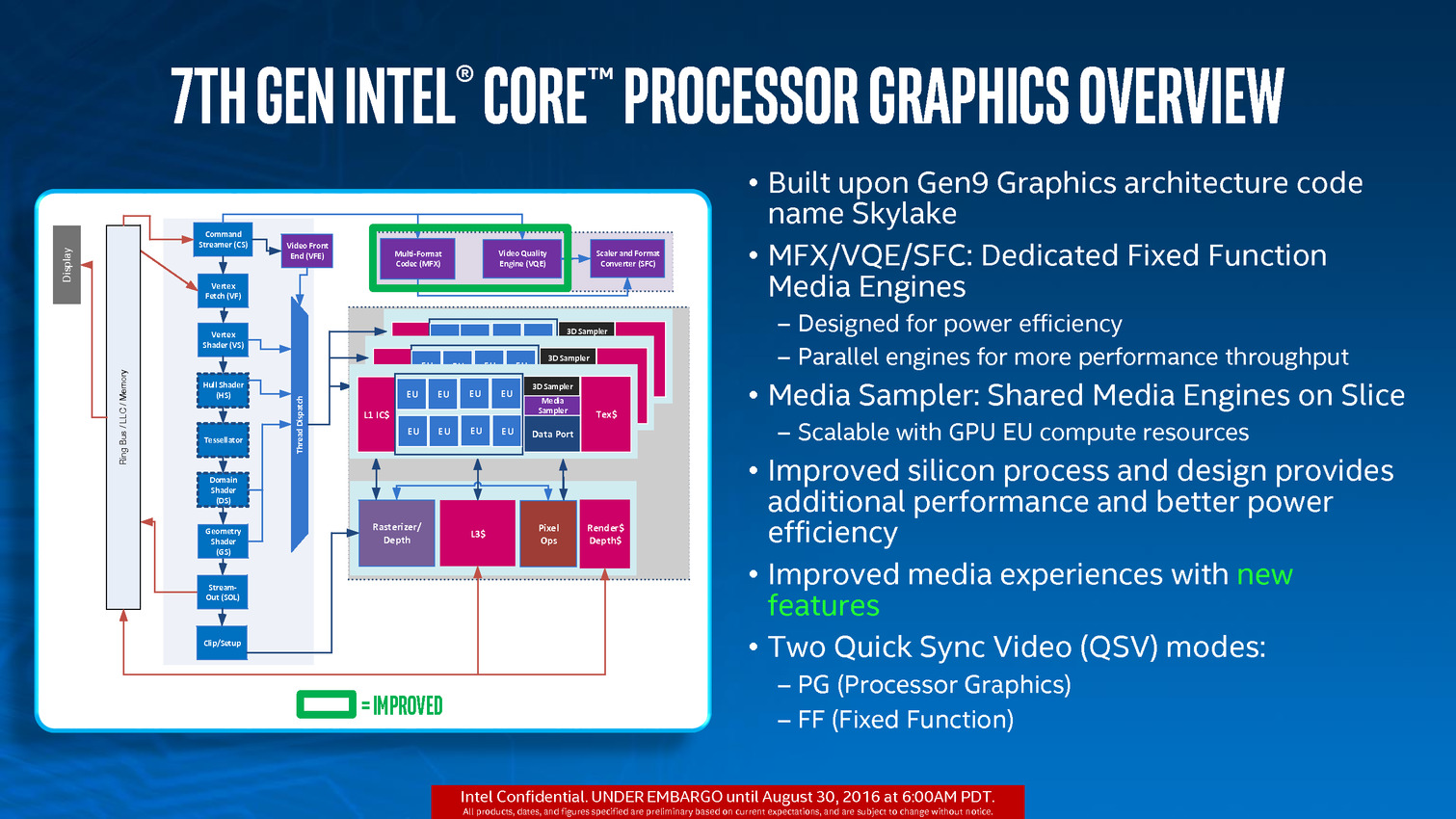
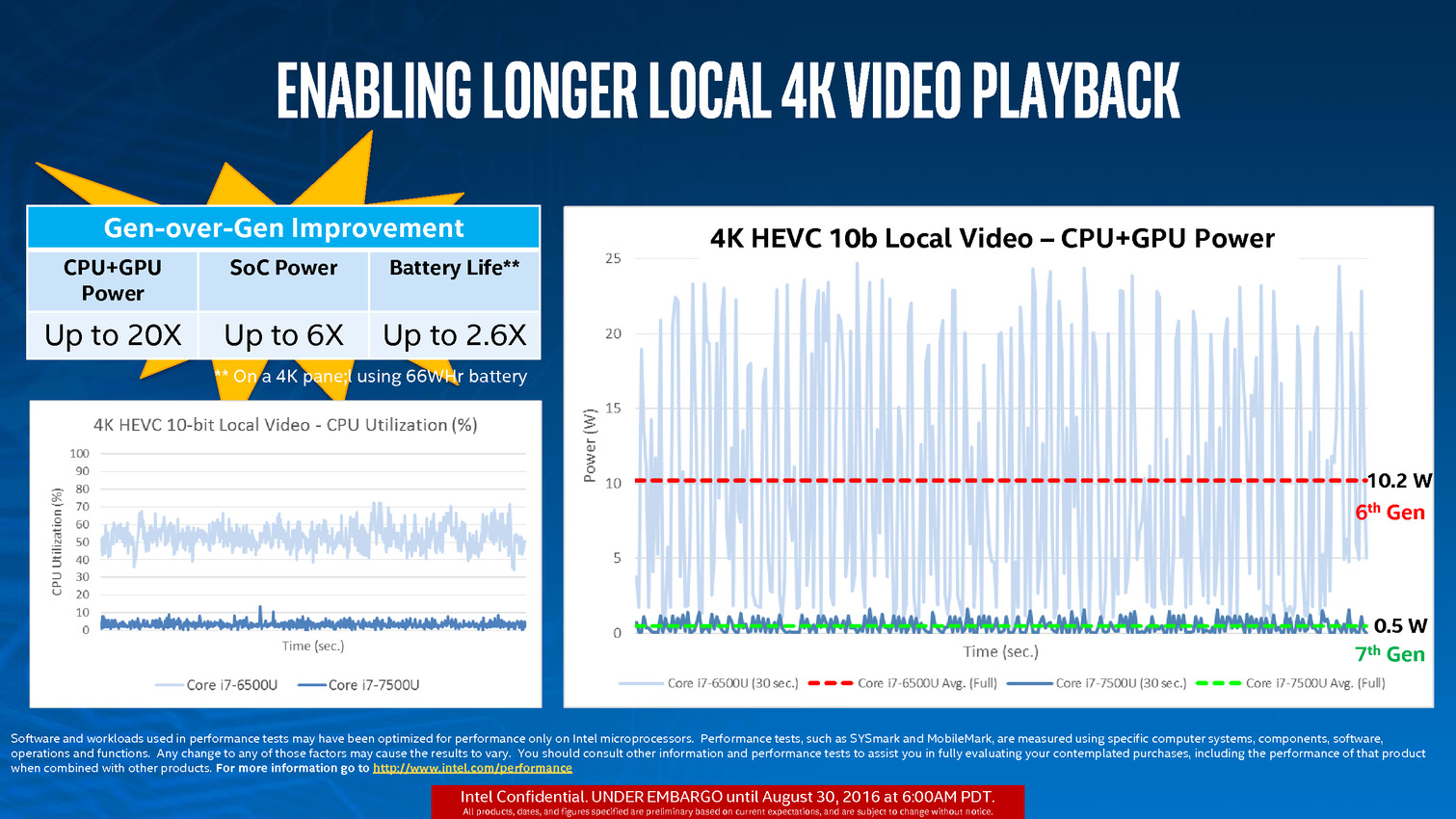
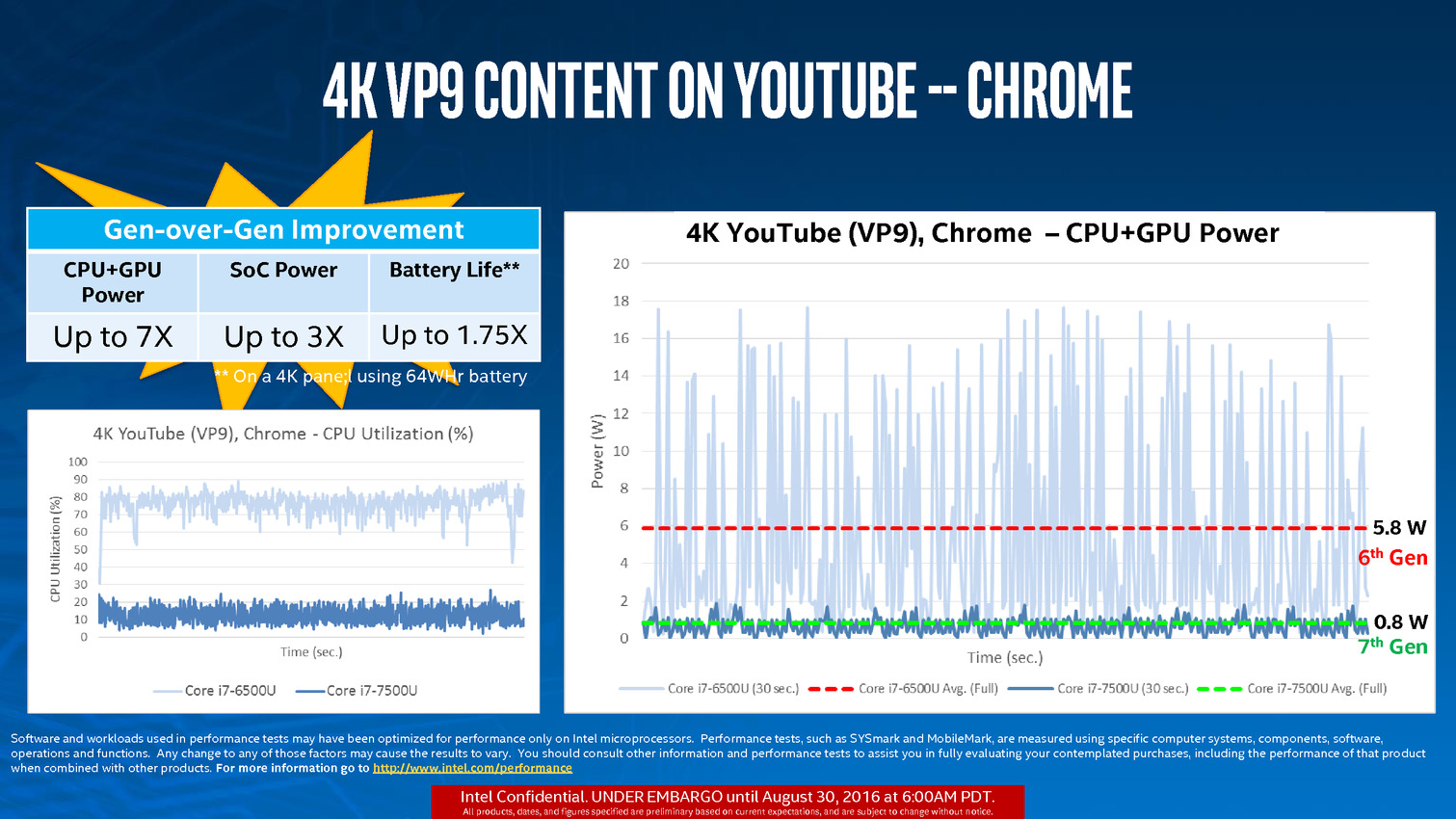
L'autre nouveauté concerne le "Media Block", la partie du GPU qui regroupe les fonctions de décodage et d'encodage vidéo. Si Skylake avait ajouté le décodage vidéo HEVC (H.265), il n'était effectif que pour le profil "Main". Le profil "Main 10" (vidéos encodées avec 10 bit par composante), qui sera utilisé pour les Blu-Ray UHD par exemple n'était par contre pas pris en charge. C'est désormais corrigé, le Media Block de Kaby Lake décode désormais le HEVC "Main 10". On notera également l'arrivée du décodage de VP9, le codec de Google en 8 et 10 bit (un décodage "partiel" de VP9 était disponible précédemment, comme pour le HEVC Main 10 mais il était insuffisant en pratique).

En plus du décodage, l'encodage HEVC est lui aussi possible en "Main 10", ainsi qu'en VP9. L'encodage H.264 (AVC) profite d'une amélioration de performances sur l'une de ses composantes.
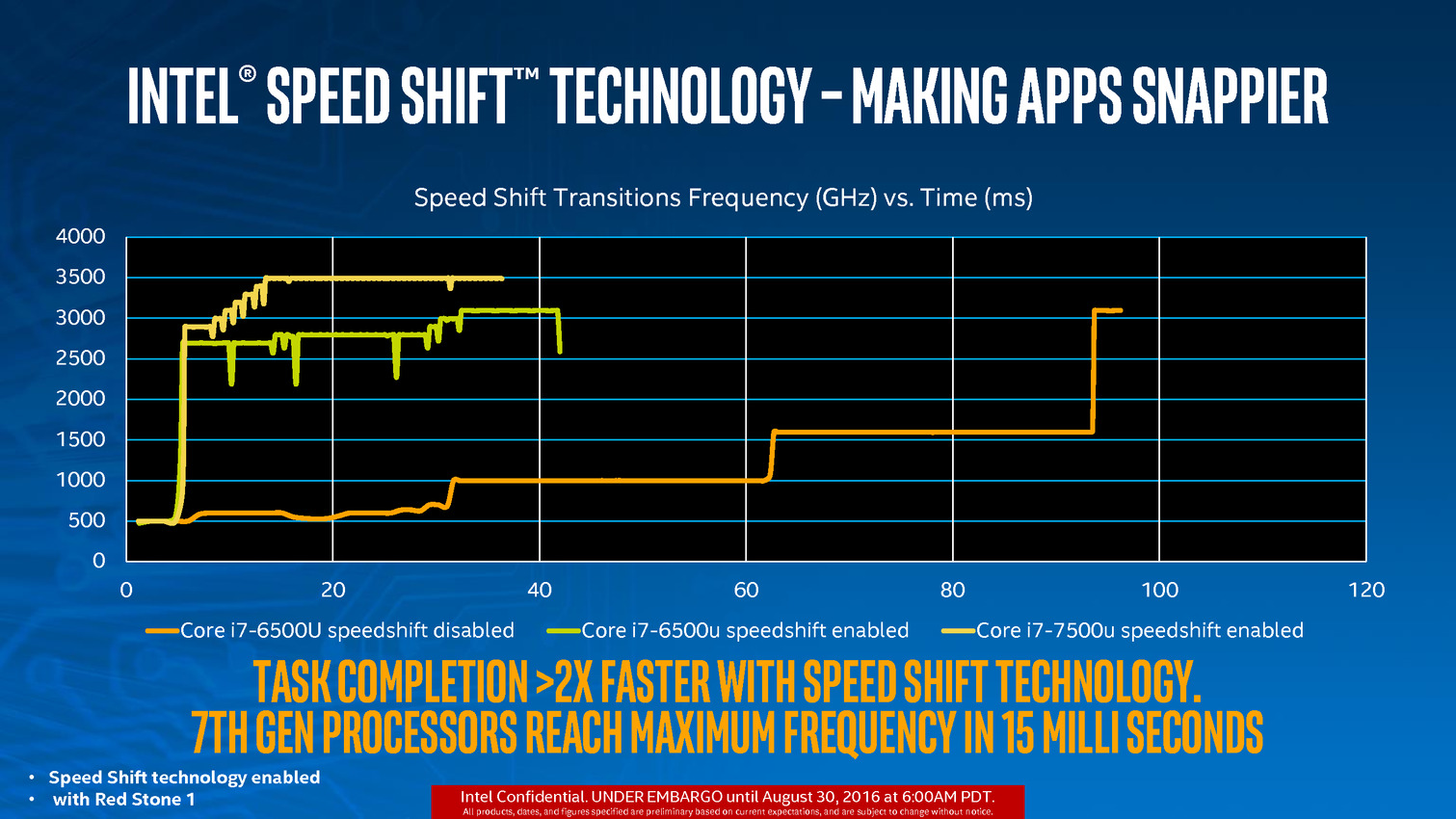
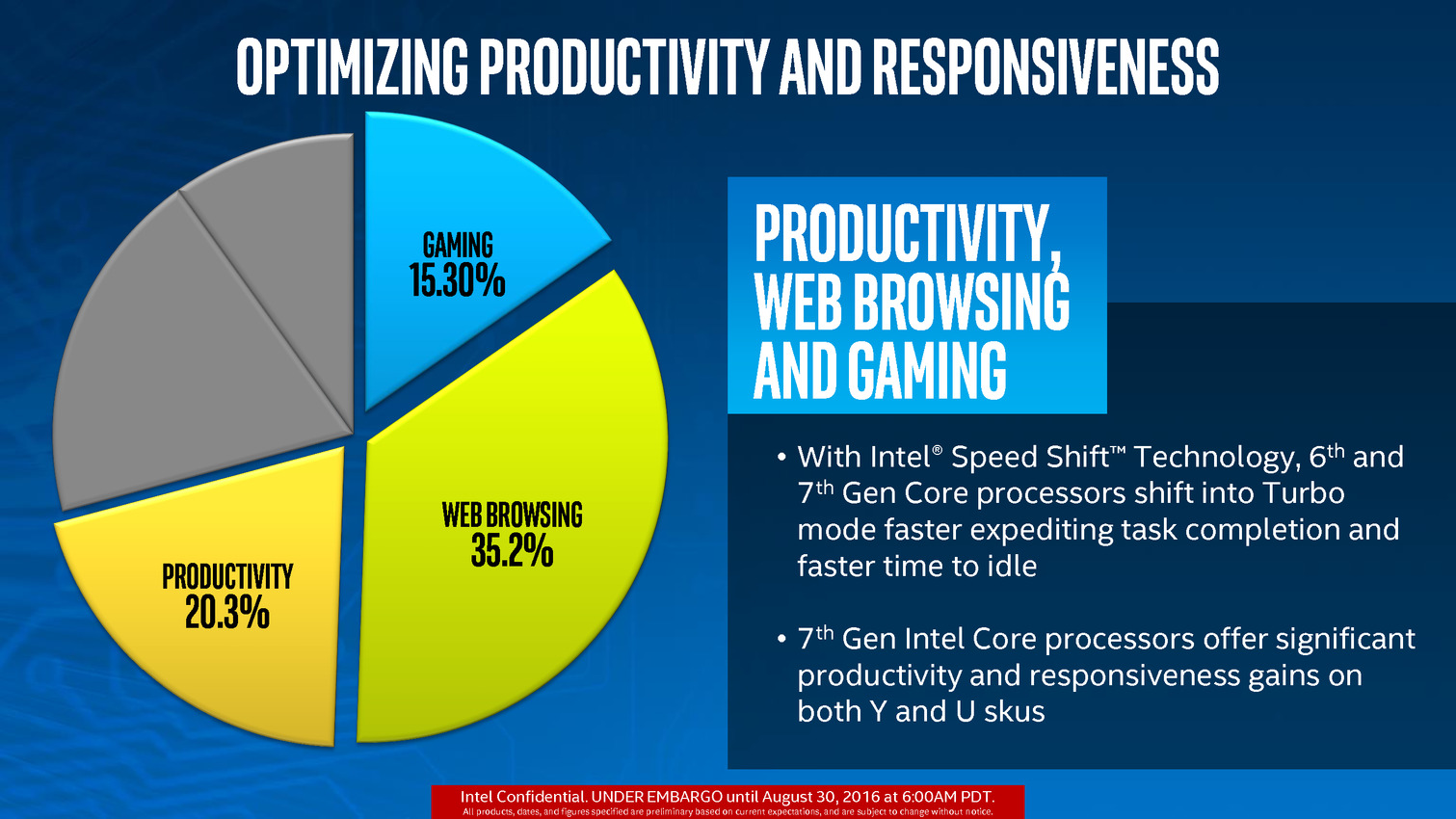
Dernier point, Intel parle d'une meilleure réactivité du Turbo en mode Speed Shift, permettant d'atteindre la fréquence Turbo maximale plus rapidement qu'auparavant. On passerait ainsi de 35ms à 15ms pour atteindre cette fréquence maximale.
Et... c'est tout ! Il n'y a en effet aucun autre changement architectural pour Kaby Lake, que ce soit au niveau du GPU ou du CPU. Intel met a profit son process pour faire monter les fréquences, ce qui rappellera aux plus anciens les "speed bump" qu'introduisait auparavant le constructeur. Sur le modèle Core i7 15 watts, la fréquence turbo maximale augmente ainsi de 400 MHz, ce qui se traduit par 12 à 19% d'avantage dans les benchmarks sélectionnés par Intel pour sa présentation.
Pour récapituler, voici les six références lancées ainsi que celles qu'elles remplacent :
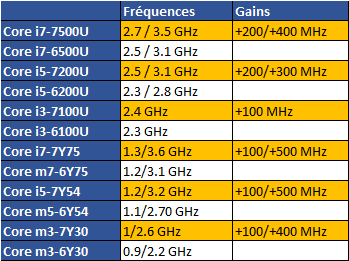
On notera des gains de 100 à 400 MHz sur les fréquences Turbo pour les modèles U (15 Watts) et jusque 500 MHz sur les modèles Y (avec un "TDP" de 4.5 Watts), ce qui n'est pas négligeable même si l'on rappellera que ces derniers ne tiennent pas leur fréquence Turbo maximale en charge prolongée. Sur ces derniers, on notera qu'Intel fait disparaitre ses nomenclatures Core m5 et m7, remplacées par Core i5 et i7 ! Le Core m3 continue par contre d'exister.
Cette absence de changements conséquents pousse le constructeur à être créatif, comparant dans sa présentation les performances de Kaby Lake à une plateforme mobile datant de cinq ans. Un discours marketing qui aura du mal a cacher la réalité : cette septième génération est avant tout un "speed bump" légèrement amélioré de Skylake. Si l'on apprécie les gains de fréquences annoncés, il faudra attendre le mois de janvier, probablement autour du CES, pour voir en pratique ce que le constructeur proposera comme gains de fréquences pour sa plateforme desktop.
Vous pouvez retrouver la présentation "performance" fournie par Intel ci dessous :










Ainsi que la présentation plus générale :





















Hot Chips : M1, SVE, Parker, InFo et Skylake !
La conférence Hot Chips qui se tenait la semaine dernière a donné lieu a d'autres annonces intéressantes que nous avons essayé de regrouper dans cette actualité !
Rajouter des tiers de mémoire côté serveur
On avait déjà noté un peu plus tôt la volonté de rajouter de la mémoire HBM à divers endroits, et même la volonté de Samsung de travailler sur une version moins onéreuse, mais l'on rajoutera ce slide issu d'une présentation d'AMD qui rappelle les objectifs de la société côté serveurs, prenant pour le coup l'exemple du big data
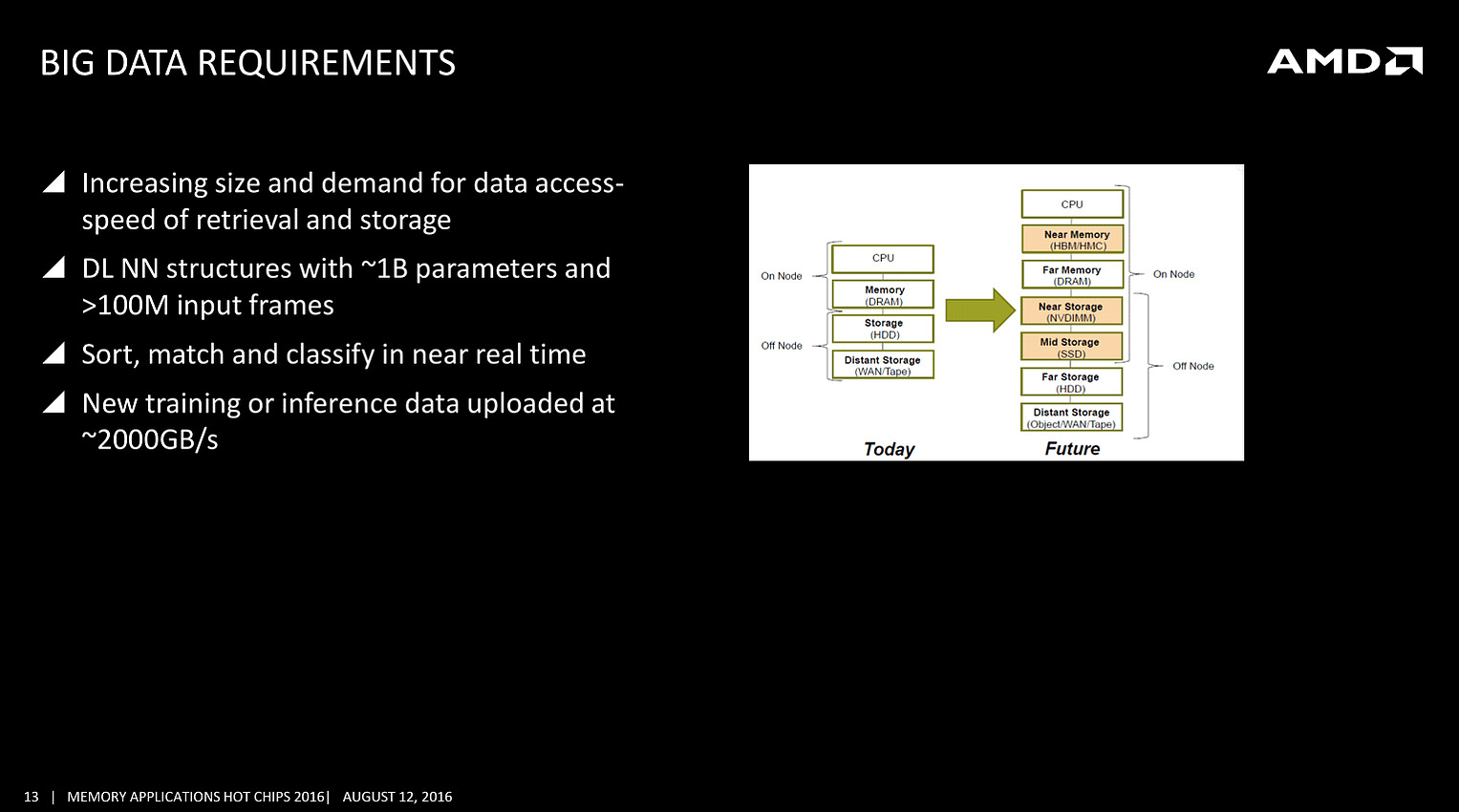
On s'attardera sur le graphique à droite qui pointe l'ajout d'une mémoire intermédiaire côté CPU, type HBM ou HMC (AMD misera plutôt sur la HBM pour les déclinaisons serveurs de Zen), et aussi l'utilisation de NVDIMM pour s'intercaler avant un SSD. Il faudra attendre encore un peu pour voir comment seront déclinées ces technologies, mais il est intéressant de noter la manière dont les avancées côté mémoire sont mises en avant, parfois un peu trop tôt comme l'a fait Intel avec 3D XPoint, dans toute l'industrie.
Quelques détails de plus sur SVE
Chez ARM, outre une présentation de Bifrost côté GPU dont on vous avait déjà parlé, l'annonce principale concernait SVE, la nouvelle extension vectorielle introduite par la société.
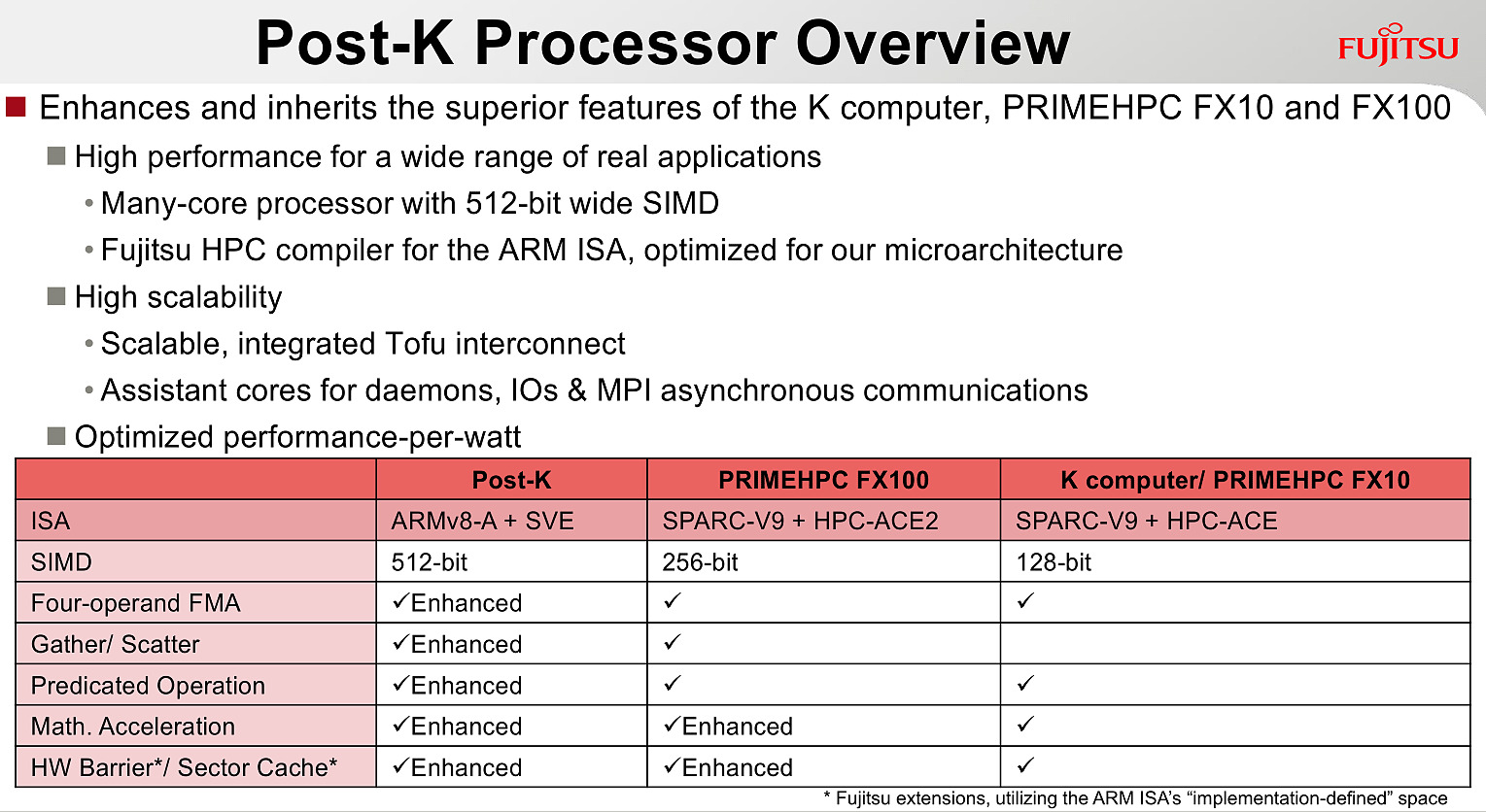
Le premier partenaire annoncé par ARM est Fujitsu, qui mettra au point des processeurs ARMv8 avec extension SVE pour le futur supercalculateur japonais Post-K. Fujitsu a donné quelques détails, indiquant par exemple que les unités vectorielles auraient une largeur de 512 bits sur ses puces.


Chez ARM, le constructeur présente plusieurs benchmarks assez théoriques, on notera surtout sur les barres grises les améliorations qui ont été effectuées côté auto-vectorisation, c'est a dire la capacité du compilateur à utiliser des instructions vectorielles pour extraire du parallélisme. ARM devrait proposer dans les semaines qui viennent des patchs pour les différents compilateurs open source, incluant LLVM et GCC.
Le Samsung M1, un timide premier pas
La particularité de l'écosystème d'ARM est que les partenaires peuvent soit utiliser des coeurs "clefs en main", développés par ARM (les gammes Cortex, comme par exemple le Cortex A57), ou créer leurs propres implémentations de l'architecture ARM (qui restent compatibles, tout en étant différentes, à l'image des processeurs d'AMD et d'Intel qui diffèrent bien que restant compatibles). Plusieurs sociétés disposent de licences "architecture" qui permettent de créer ces puces, Apple étant jusqu'ici la société la plus à la pointe sur armv8 même si de nombreuses sociétés proposent tour à tour leurs architectures.

Parmi les nouveaux venus, il y a Samsung qui s'est lancé lui aussi dans le design d'une architecture armv8 custom pour ses Exynos M1. A la tête du projet, on retrouve Brad Burgess qui était architecte chez AMD pour les Bobcat. Il aura même été rejoint un court instant par Jim Keller (K8 chez AMD, A7 chez Apple, puis Zen chez AMD), qui n'est cependant pas resté très longtemps chez Samsung et qui n'aura probablement pas eu un grand impact. Le projet aura nécessité trois années, et en soit arriver a produire quoique ce soit du premier coup en un temps si court est un exploit.
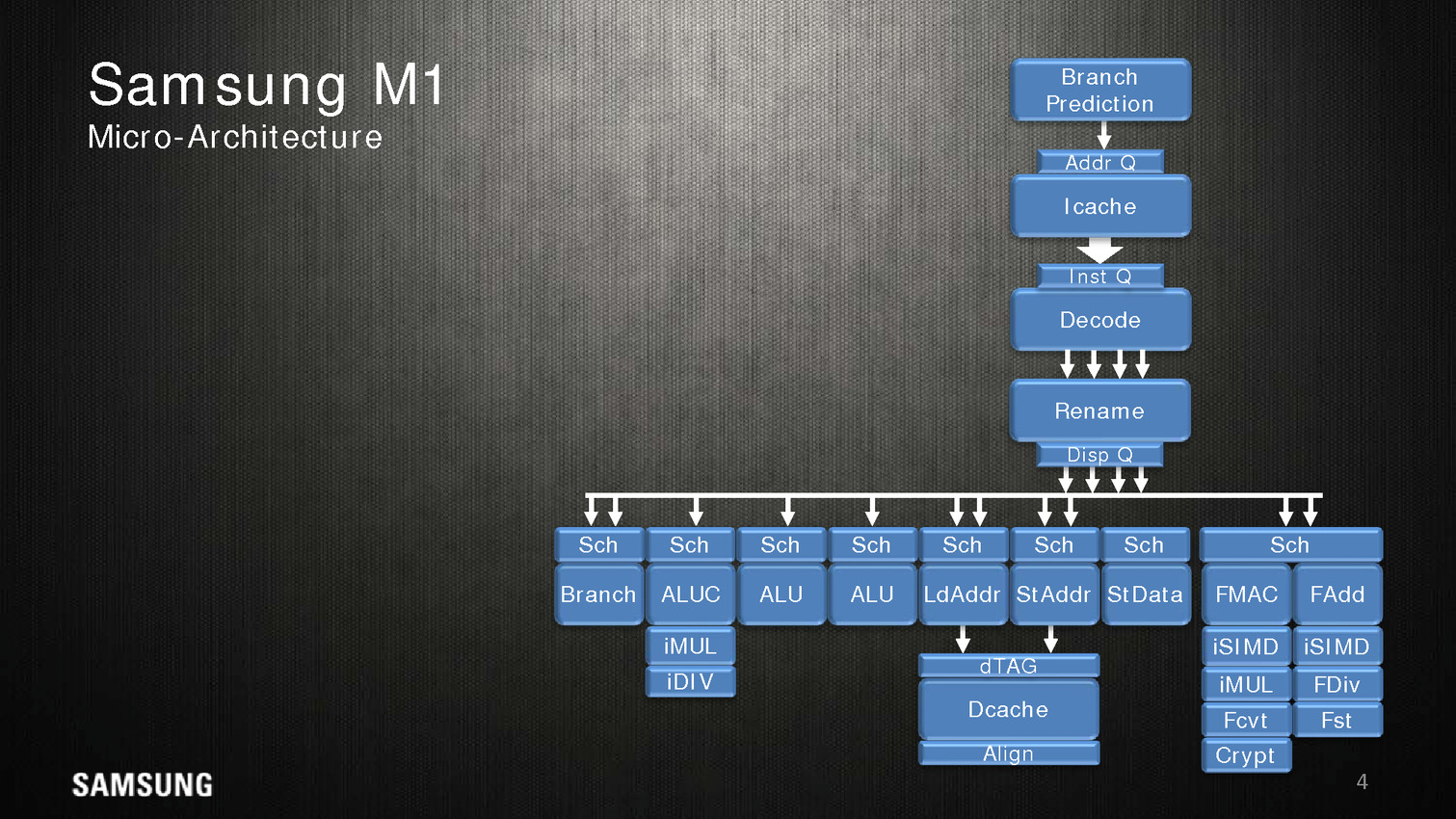
Côté architecture, Samsung indique utiliser un perceptron (un réseau de neurones simple) au niveau de ses mécanismes de prédiction de branches. Deux branches sont considérées par cycle, mais il est difficile d'estimer quoique ce soit sur l'éventuelle efficacité.
Quatre instructions peuvent être décodées/dispatchées par cycle aux unités d'exécutions qui sont regroupées sur sept files. On note deux files dédiées aux écritures mémoires, trois aux opérations mathématiques simple (avec un port sur lequel sont ajoutés les multiplications/divisions) et une aux branchements. Les opérations en virgules flottantes sont regroupées séparément avec un scheduler unique pour deux files. Samsung annonce 5 cycles pour effectuer une opération FMA.
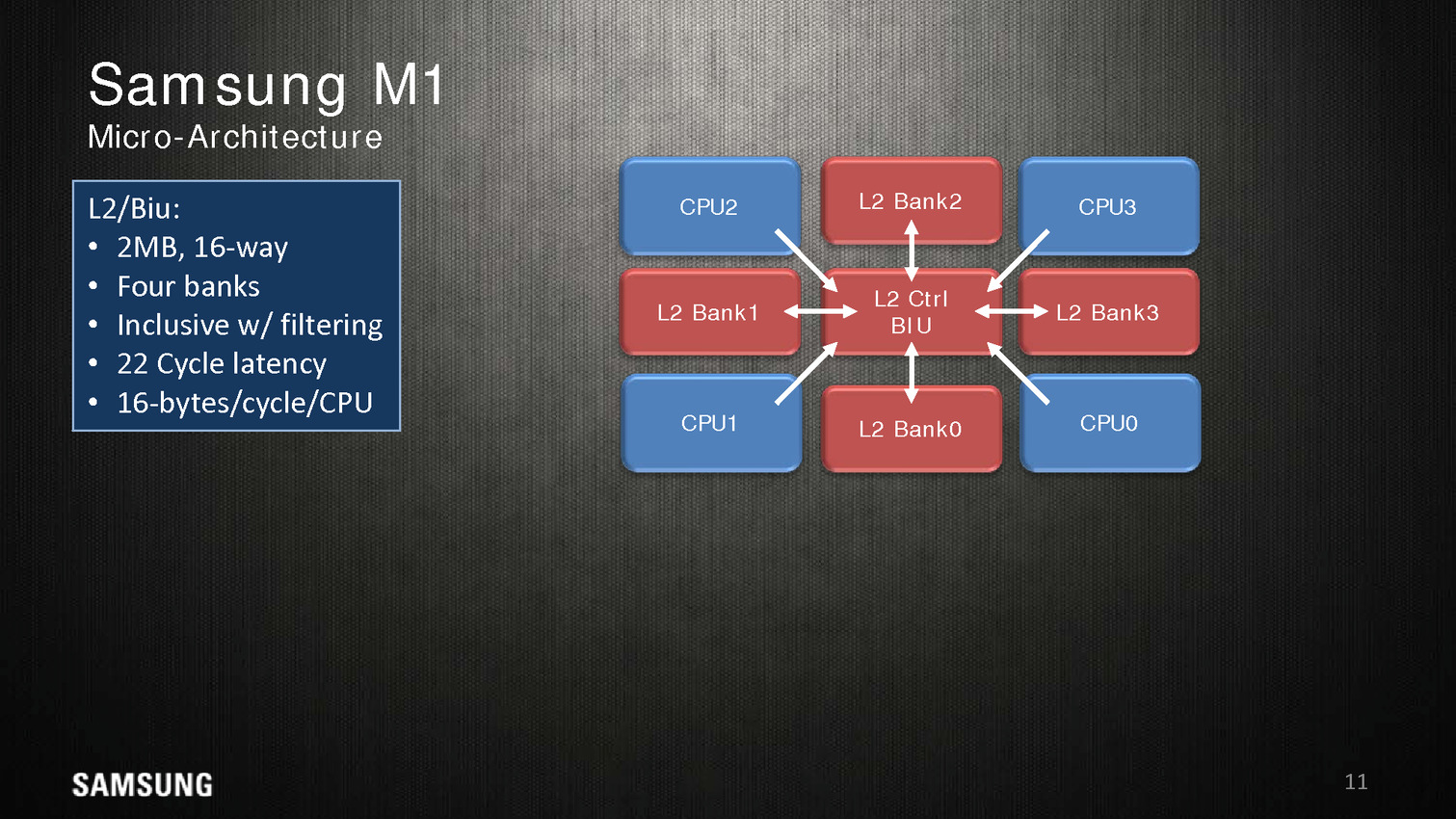
Dans une configuration quatre coeurs, le M1 dispose de 2 Mo de cache L2 coupé en quatre blocs, les coeurs accèdent au L2 via une interface commune. On appréciera aussi les schémas très spécifiques que propose Samsung, pas vraiment avare de détails techniques.

Reste qu'en pratique, les benchmarks mis en avant par Samsung ne sont pas forcément très convaincants. Avec 200 MHz de plus, sur un coeur, un M1 propose 10% de performances en plus qu'un Cortex A57 à consommation égale, ce qui est tout de même très peu. Samsung fait beaucoup mieux sur les opérations mémoires (c'est relativement facile, on l'a évoqué de nombreuses fois, les contrôleurs mémoires ARM ne sont pas particulièrement véloces/adaptés aux hautes performances), mais n'en tire pas particulièrement profit hors des benchmarks théoriques.
La présentation se termine en indiquant que ce n'est qu'un premier pas pour Samsung et que d'autres designs sont en cours d'élaboration. En soit si les performances ne vont pas révolutionner le monde des SoC ARM, Samsung a au moins une base de travail qu'ils pourront faire évoluer par la suite. A condition évidemment que Samsung continue d'investir sur le sujet dans les années à venir !
Les curieux pourront retrouver la présentation en intégralité ci dessous :














Parker/Denver 2 : design asymétrique
Nvidia était également présent à Hot Chips, donnant quelques détails sur son futur SoC baptisé Parker. Ce dernier est annoncé comme crée spécifiquement pour le marché automobile avec des fonctionnalités dédiées à ce marché. On ne sait pas si le constructeur le déclinera en d'autres versions plus génériques.

Les détails techniques ne sont pas particulièrement nombreux, on notera côté SoC que l'encodage 4K est désormais accéléré à 60 FPS, que l'on peut contrôler jusque trois écrans en simultanée, et que le contrôleur mémoire passe sur 128 bits (contre 64 précédemment). Côté GPU, Parker utilisera une version dérivée de son architecture Pascal.



C'est du côté CPU que les choses sont les plus originales, après avoir utilisé son architecture Denver sur les TK1, puis être revenu aux Cortex A57 sur les TX1, Nvidia propose une architecture asymétrique avec deux coeurs "Denver 2" (sur lesquels aucun détail n'aura été donné, à part un gain performance/watts de 30% donné sans précision sur les process comparés) et quatre coeurs Cortex A57. Ce n'est pas la première fois que l'on voit des configurations originales, durant Hot Chips, le taiwannais MediaTek présentait un SoC 10 coeurs avec quatre coeurs Cortex A53 à 1.4 GHz, quatre coeurs Cortex A53 à 2 GHz, et deux coeurs Cortex A72 à 2.5 GHz !
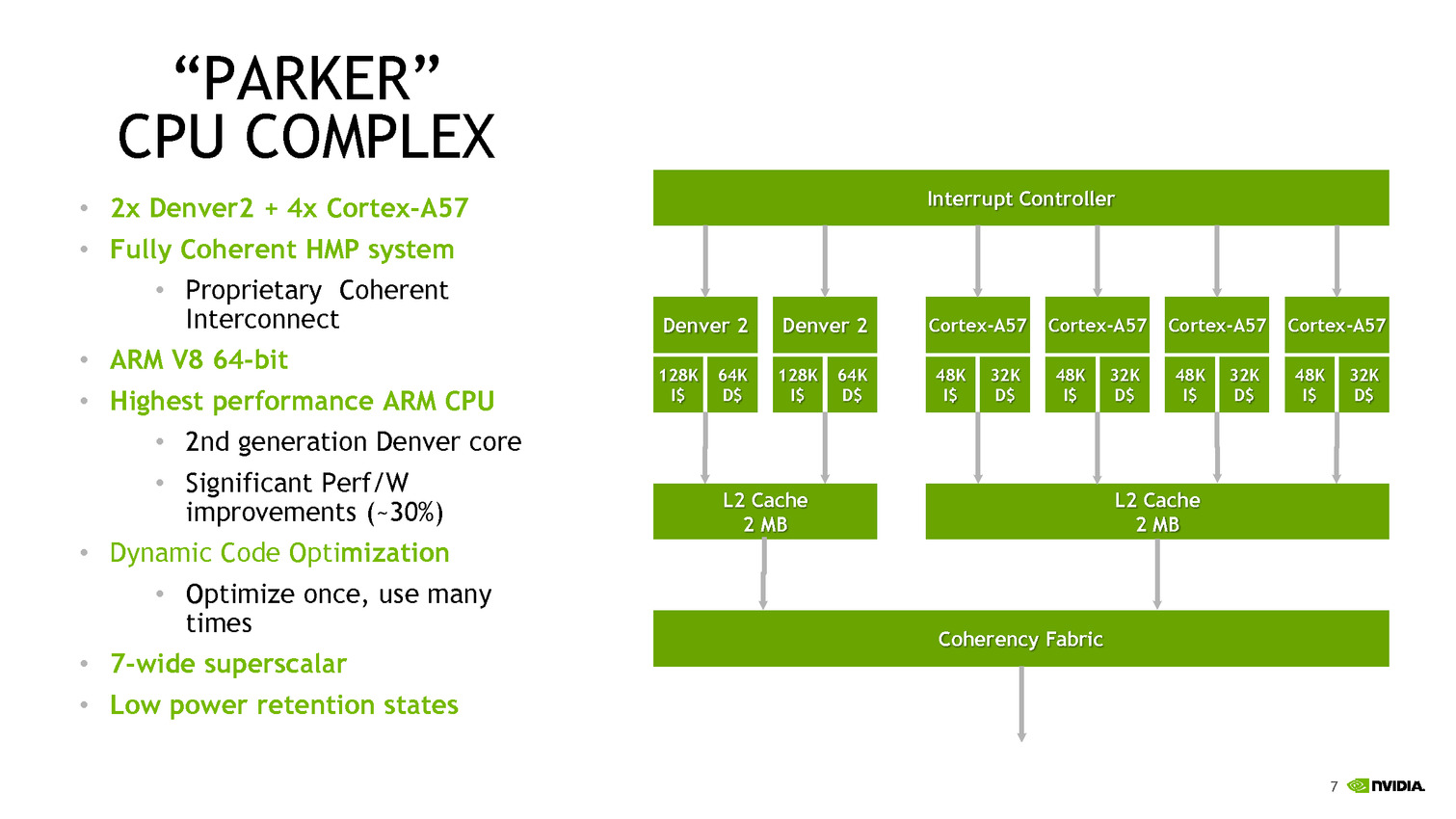
Dans le cas de MediaTek, l'idée est de proposer différentes options à différents niveaux de consommation. Pour ce qui est de Nvidia, le choix est différent, le Cortex A57 étant "haute performance" contrairement aux A53 de MediaTek. Il faut dire surtout que le marché visé, l'automobile, n'a pas les mêmes contraintes de consommation que le marché mobile. Reste que Nvidia se doit de gérer cette asymétrie avec un scheduler qui doit décider sur quel coeur placer les threads, ce qui n'est pas particulièrement simple. On notera que chaque groupe de coeurs dispose de son propre cache L2 de 2 Mo.
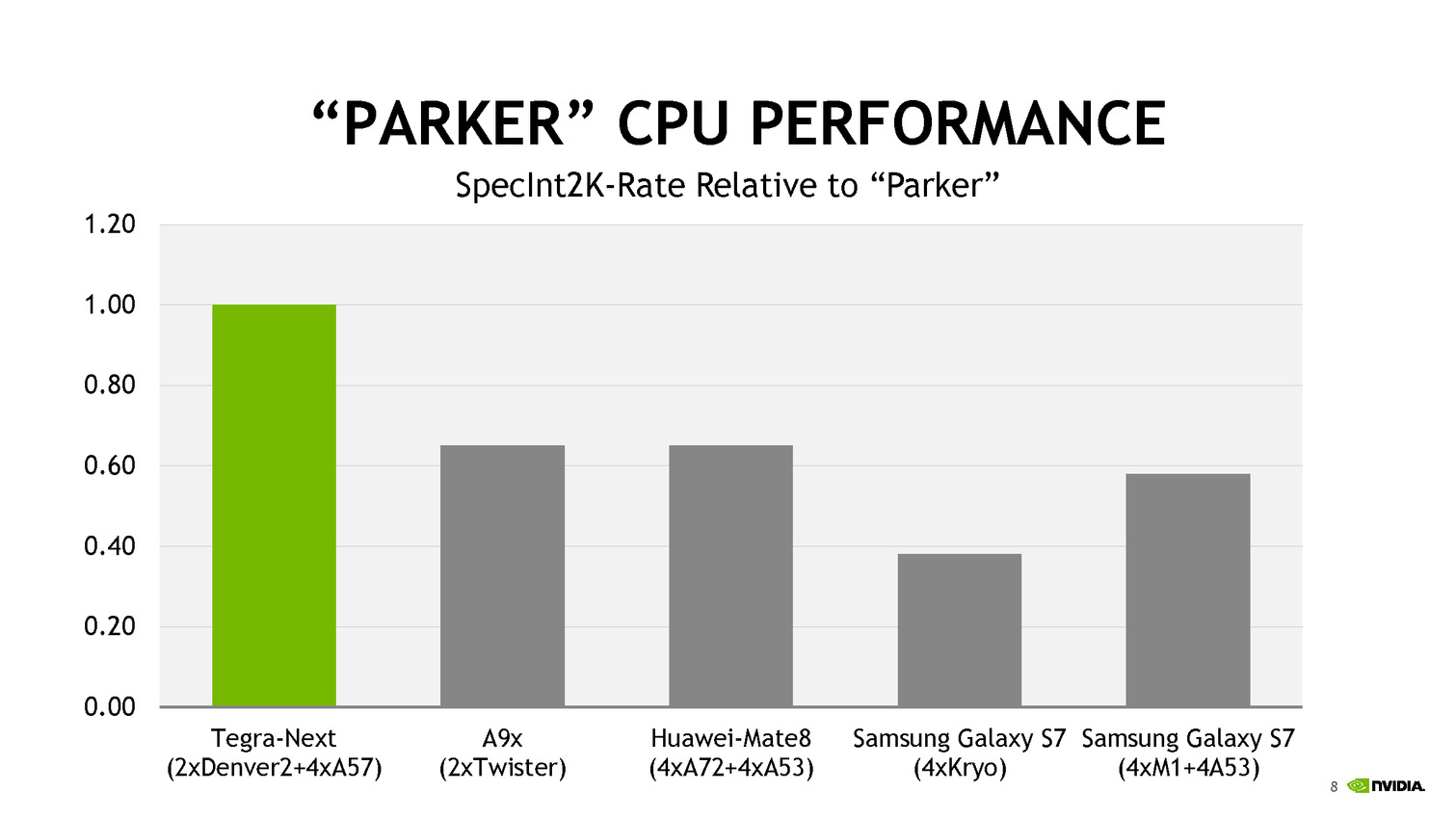
Côté performances, Nvidia avec ses 6 coeurs se présente comme moitié plus rapide qu'un A9X d'Apple en deux coeurs. Le graphique mélangeant des puces à TDP différents (on y retrouve des puces pour smartphones et pour tablettes), on admettra que la comparaison n'est pas faite à TDP identique.
TSMC parle de ses packages InFo
Une des nouveautés présentées cette année par TSMC est la disponibilité d'un nouveau type de packaging, l'InFo-WLP. L'idée est de permettre de relier plusieurs dies en les "moulant" dans un substrat commun très fin qui contient également les interconnexions entre les puces. Il s'agit d'une version à cout beaucoup plus faible que les interposer (utilisés par exemple par AMD pour Fiji).
La présentation de TSMC est dédiée aux interconnexions entre les puces, et présente une puce 16nm reliant un SOC à une puce mémoire avec une bande passante de 89.6 Go/s sur 256 bits, le tout avec une consommation très réduite.
En plus de la solution présentée qui évoque le cas simple d'une puce mémoire et d'un Soc, TSMC évoque la solution comme permettant un jour de relier également plusieurs dies de logique, par exemple des groupes de coeurs séparés, pour réduire le coût de fabrication des puces (qui augmentent exponentiellement avec la taille des dies).
































La présentation est technique mais reste intéressante, l'InFo-WLP ouvre des opportunités supplémentaires pour réaliser des produits qui mélangent processeur et mémoire. Le coût réduit et la finesse de l'interconnexion fait qu'on pourrait retrouver assez rapidement cette technique utilisée, y compris sur le marché mobile. Les prochains SoC d'Apple pourraient par exemple utiliser un tel package.
Et Skylake !
Juste avant la présentation de Zen, Intel proposait aussi une présentation de son architecture Skylake, lancée l'année dernière. Si la majorité du contenu est déjà connu, on aura noté un détail intéressant : un diagramme sur les unités d'exécution de Skylake. On rappellera que l'année dernière durant l'IDF, Intel nous avait promis plus de détails sur le sujet, sans jamais nous les donner !
Pour rappel, voici la répartition sur Haswell :
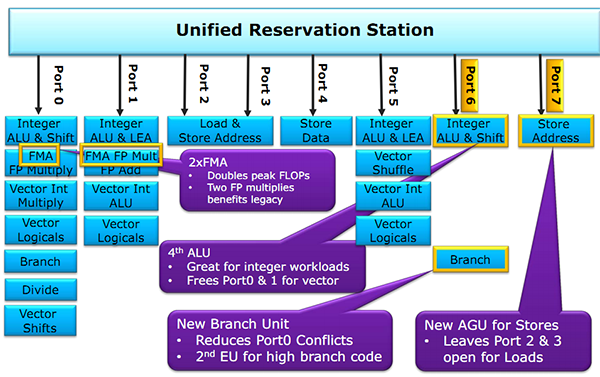
Récapitulatif des ports/unités d'exécution sur Haswell
Un an après, voici enfin un diagramme similaire pour Skylake :
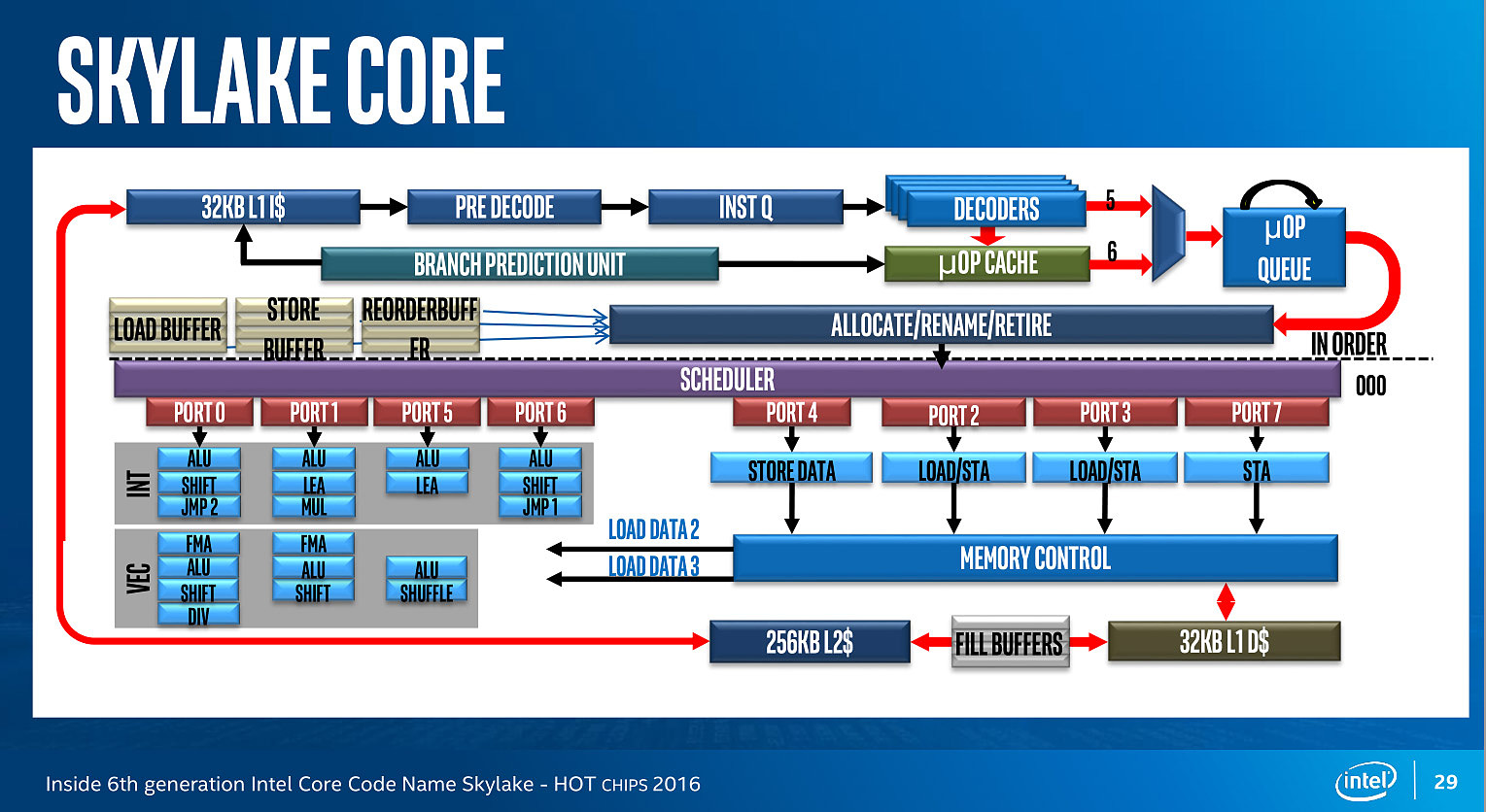
Conformément à ce que nous avaient indiqué les ingénieurs d'Intel l'année dernière, le nombre d'unité a bel et bien augmenté. Le nombre de ports reste constant, à 8, mais l'on compte... une nouvelle unité. Sur le port 1, Intel a en effet ajouté une unité de shift vectorielle. Pour le reste, la répartition reste similaire à celle d'Haswell. Un mystère enfin élucidé !