
Les contenus liés aux tags Samsung et TSMC
Afficher sous forme de : Titre | FluxASML confirme les retards sur l'EUV
L'A9 d'Apple produit par Samsung et TSMC
Pascal sera produit en 16nm chez TSMC
Nvidia client de Samsung Foundry
Un Cortex-A57 16nm fonctionnel chez TSMC
Hot Chips : M1, SVE, Parker, InFo et Skylake !



La conférence Hot Chips qui se tenait la semaine dernière a donné lieu a d'autres annonces intéressantes que nous avons essayé de regrouper dans cette actualité !
Rajouter des tiers de mémoire côté serveur
On avait déjà noté un peu plus tôt la volonté de rajouter de la mémoire HBM à divers endroits, et même la volonté de Samsung de travailler sur une version moins onéreuse, mais l'on rajoutera ce slide issu d'une présentation d'AMD qui rappelle les objectifs de la société côté serveurs, prenant pour le coup l'exemple du big data
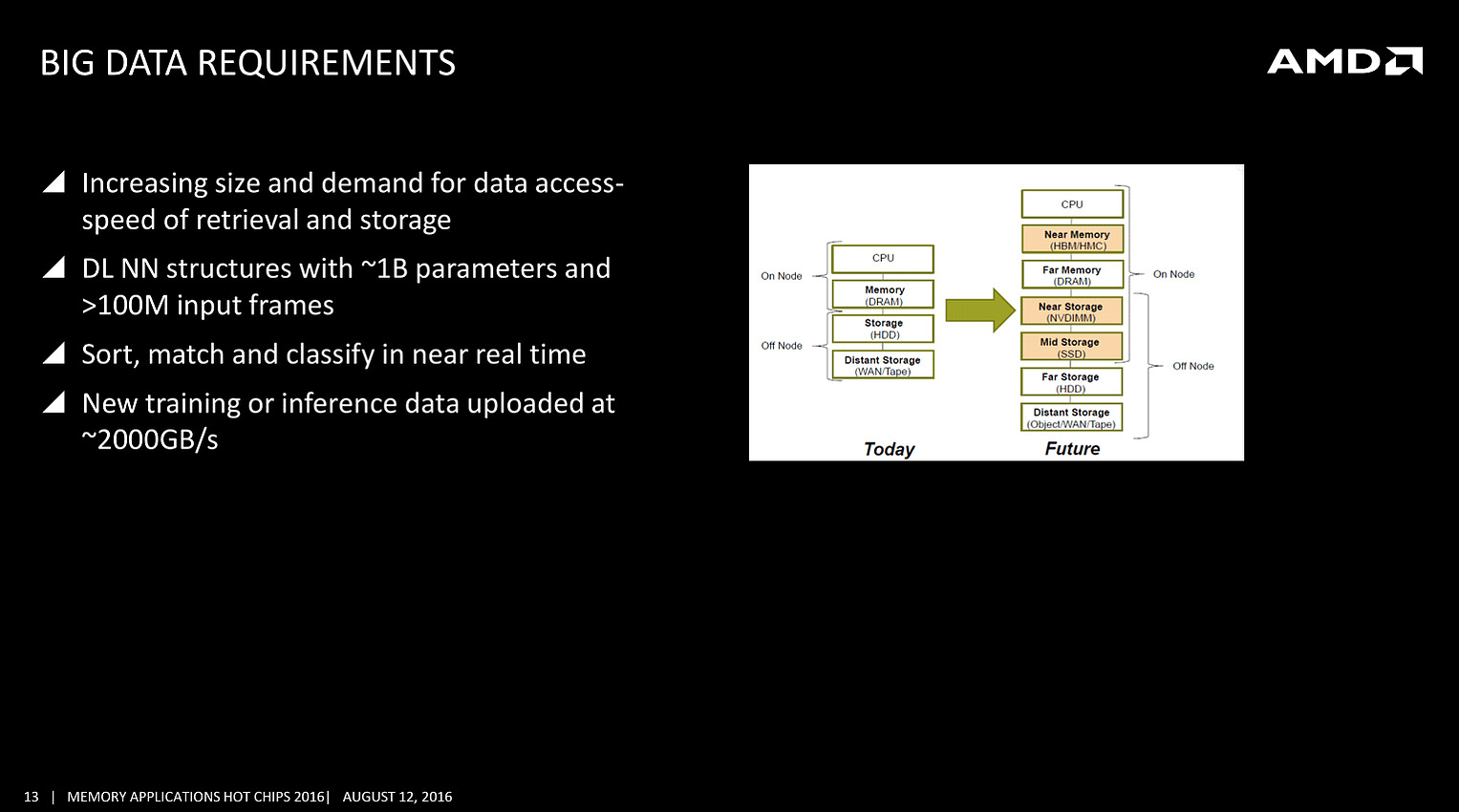
On s'attardera sur le graphique à droite qui pointe l'ajout d'une mémoire intermédiaire côté CPU, type HBM ou HMC (AMD misera plutôt sur la HBM pour les déclinaisons serveurs de Zen), et aussi l'utilisation de NVDIMM pour s'intercaler avant un SSD. Il faudra attendre encore un peu pour voir comment seront déclinées ces technologies, mais il est intéressant de noter la manière dont les avancées côté mémoire sont mises en avant, parfois un peu trop tôt comme l'a fait Intel avec 3D XPoint, dans toute l'industrie.
Quelques détails de plus sur SVE
Chez ARM, outre une présentation de Bifrost côté GPU dont on vous avait déjà parlé, l'annonce principale concernait SVE, la nouvelle extension vectorielle introduite par la société.
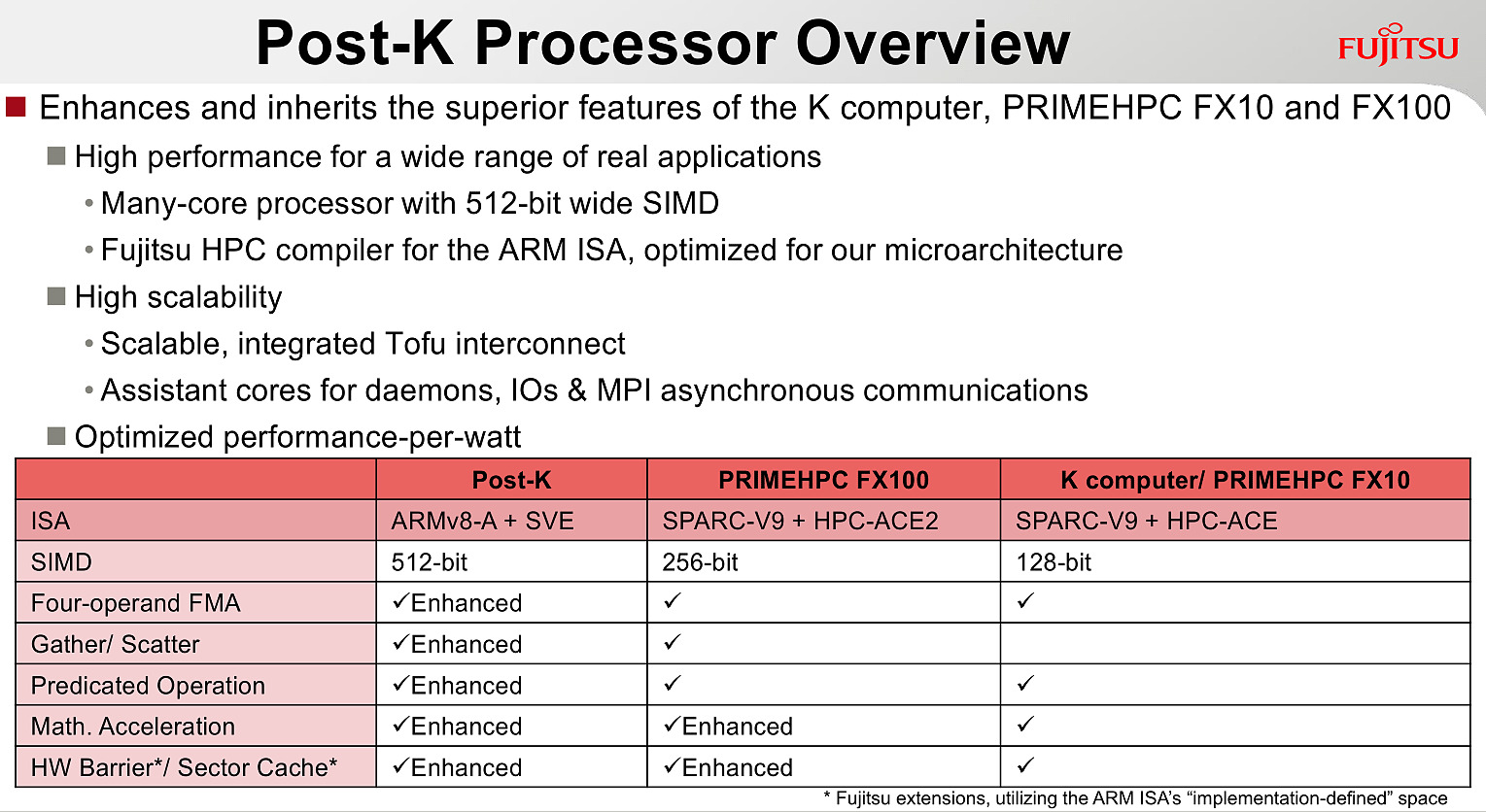
Le premier partenaire annoncé par ARM est Fujitsu, qui mettra au point des processeurs ARMv8 avec extension SVE pour le futur supercalculateur japonais Post-K. Fujitsu a donné quelques détails, indiquant par exemple que les unités vectorielles auraient une largeur de 512 bits sur ses puces.


Chez ARM, le constructeur présente plusieurs benchmarks assez théoriques, on notera surtout sur les barres grises les améliorations qui ont été effectuées côté auto-vectorisation, c'est a dire la capacité du compilateur à utiliser des instructions vectorielles pour extraire du parallélisme. ARM devrait proposer dans les semaines qui viennent des patchs pour les différents compilateurs open source, incluant LLVM et GCC.
Le Samsung M1, un timide premier pas
La particularité de l'écosystème d'ARM est que les partenaires peuvent soit utiliser des coeurs "clefs en main", développés par ARM (les gammes Cortex, comme par exemple le Cortex A57), ou créer leurs propres implémentations de l'architecture ARM (qui restent compatibles, tout en étant différentes, à l'image des processeurs d'AMD et d'Intel qui diffèrent bien que restant compatibles). Plusieurs sociétés disposent de licences "architecture" qui permettent de créer ces puces, Apple étant jusqu'ici la société la plus à la pointe sur armv8 même si de nombreuses sociétés proposent tour à tour leurs architectures.

Parmi les nouveaux venus, il y a Samsung qui s'est lancé lui aussi dans le design d'une architecture armv8 custom pour ses Exynos M1. A la tête du projet, on retrouve Brad Burgess qui était architecte chez AMD pour les Bobcat. Il aura même été rejoint un court instant par Jim Keller (K8 chez AMD, A7 chez Apple, puis Zen chez AMD), qui n'est cependant pas resté très longtemps chez Samsung et qui n'aura probablement pas eu un grand impact. Le projet aura nécessité trois années, et en soit arriver a produire quoique ce soit du premier coup en un temps si court est un exploit.
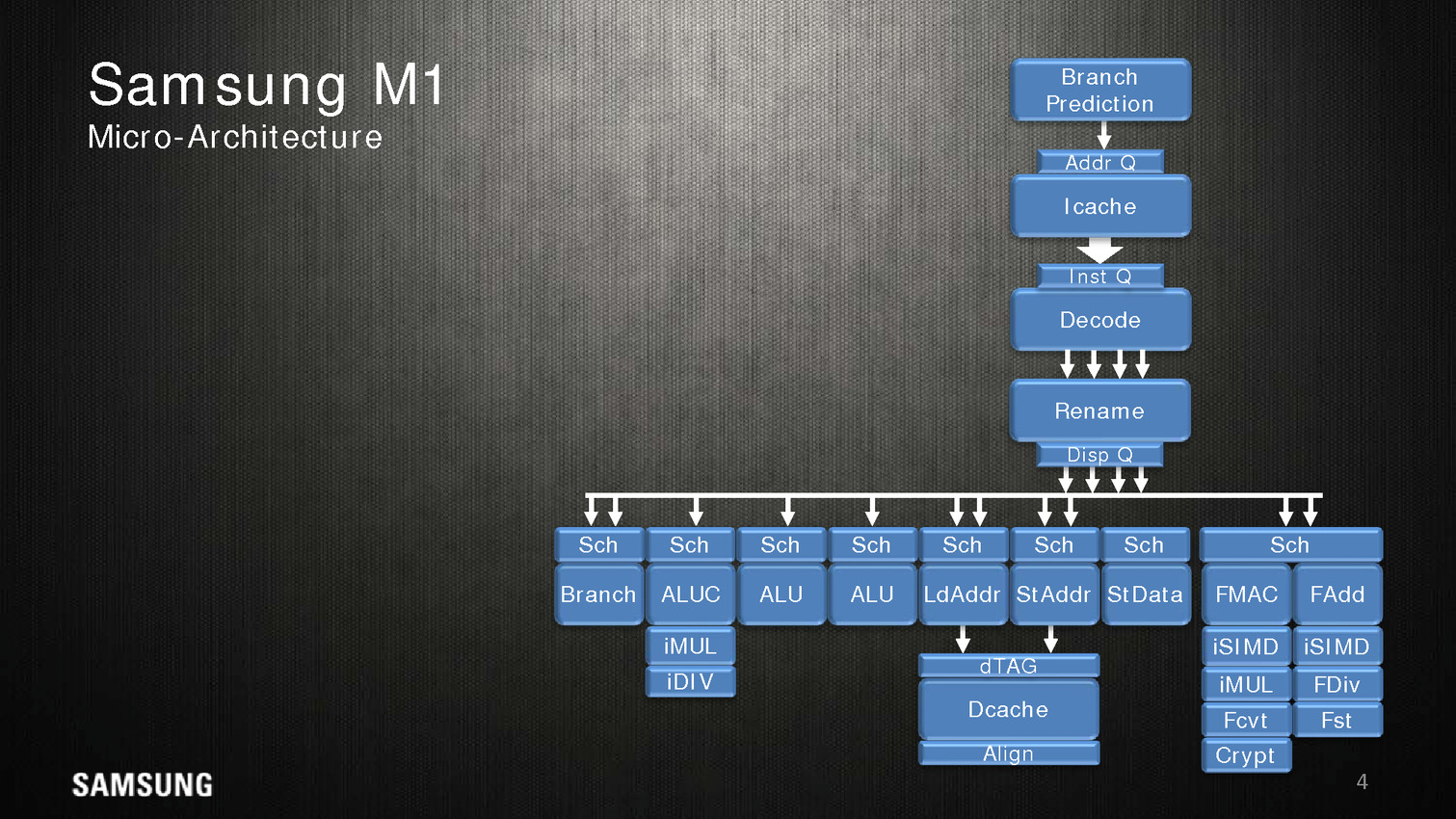
Côté architecture, Samsung indique utiliser un perceptron (un réseau de neurones simple) au niveau de ses mécanismes de prédiction de branches. Deux branches sont considérées par cycle, mais il est difficile d'estimer quoique ce soit sur l'éventuelle efficacité.
Quatre instructions peuvent être décodées/dispatchées par cycle aux unités d'exécutions qui sont regroupées sur sept files. On note deux files dédiées aux écritures mémoires, trois aux opérations mathématiques simple (avec un port sur lequel sont ajoutés les multiplications/divisions) et une aux branchements. Les opérations en virgules flottantes sont regroupées séparément avec un scheduler unique pour deux files. Samsung annonce 5 cycles pour effectuer une opération FMA.
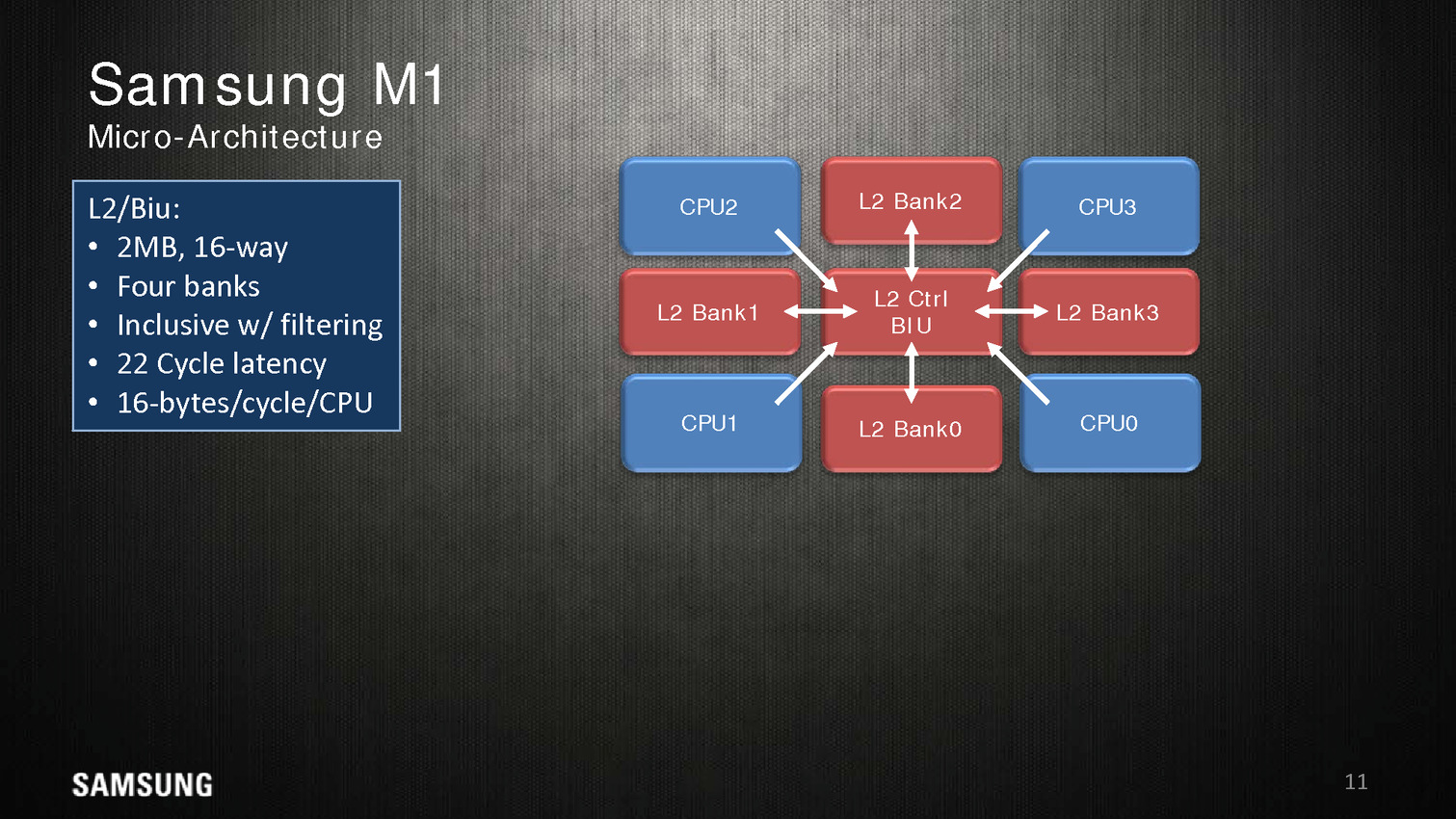
Dans une configuration quatre coeurs, le M1 dispose de 2 Mo de cache L2 coupé en quatre blocs, les coeurs accèdent au L2 via une interface commune. On appréciera aussi les schémas très spécifiques que propose Samsung, pas vraiment avare de détails techniques.

Reste qu'en pratique, les benchmarks mis en avant par Samsung ne sont pas forcément très convaincants. Avec 200 MHz de plus, sur un coeur, un M1 propose 10% de performances en plus qu'un Cortex A57 à consommation égale, ce qui est tout de même très peu. Samsung fait beaucoup mieux sur les opérations mémoires (c'est relativement facile, on l'a évoqué de nombreuses fois, les contrôleurs mémoires ARM ne sont pas particulièrement véloces/adaptés aux hautes performances), mais n'en tire pas particulièrement profit hors des benchmarks théoriques.
La présentation se termine en indiquant que ce n'est qu'un premier pas pour Samsung et que d'autres designs sont en cours d'élaboration. En soit si les performances ne vont pas révolutionner le monde des SoC ARM, Samsung a au moins une base de travail qu'ils pourront faire évoluer par la suite. A condition évidemment que Samsung continue d'investir sur le sujet dans les années à venir !
Les curieux pourront retrouver la présentation en intégralité ci dessous :














Parker/Denver 2 : design asymétrique
Nvidia était également présent à Hot Chips, donnant quelques détails sur son futur SoC baptisé Parker. Ce dernier est annoncé comme crée spécifiquement pour le marché automobile avec des fonctionnalités dédiées à ce marché. On ne sait pas si le constructeur le déclinera en d'autres versions plus génériques.

Les détails techniques ne sont pas particulièrement nombreux, on notera côté SoC que l'encodage 4K est désormais accéléré à 60 FPS, que l'on peut contrôler jusque trois écrans en simultanée, et que le contrôleur mémoire passe sur 128 bits (contre 64 précédemment). Côté GPU, Parker utilisera une version dérivée de son architecture Pascal.



C'est du côté CPU que les choses sont les plus originales, après avoir utilisé son architecture Denver sur les TK1, puis être revenu aux Cortex A57 sur les TX1, Nvidia propose une architecture asymétrique avec deux coeurs "Denver 2" (sur lesquels aucun détail n'aura été donné, à part un gain performance/watts de 30% donné sans précision sur les process comparés) et quatre coeurs Cortex A57. Ce n'est pas la première fois que l'on voit des configurations originales, durant Hot Chips, le taiwannais MediaTek présentait un SoC 10 coeurs avec quatre coeurs Cortex A53 à 1.4 GHz, quatre coeurs Cortex A53 à 2 GHz, et deux coeurs Cortex A72 à 2.5 GHz !
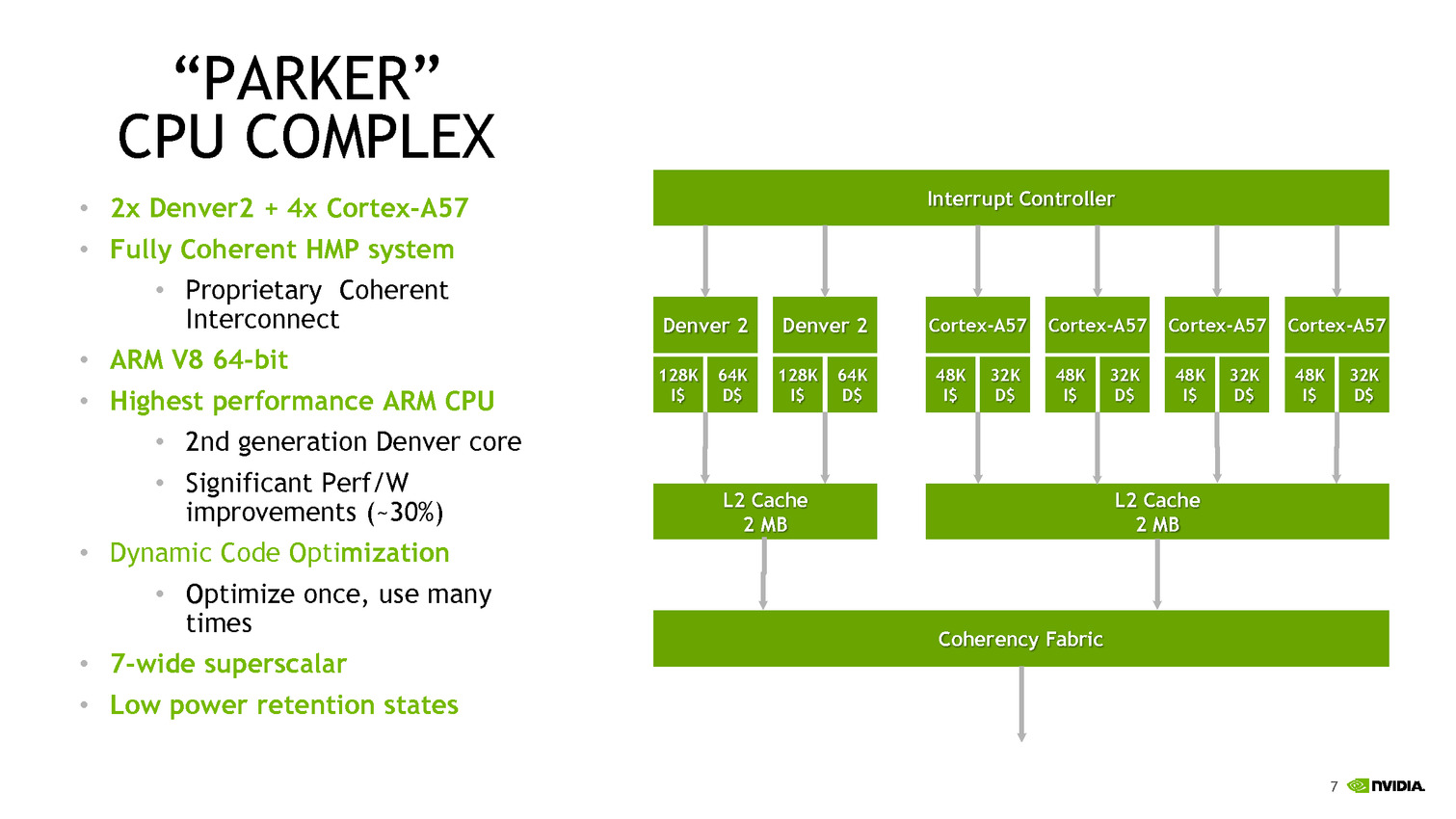
Dans le cas de MediaTek, l'idée est de proposer différentes options à différents niveaux de consommation. Pour ce qui est de Nvidia, le choix est différent, le Cortex A57 étant "haute performance" contrairement aux A53 de MediaTek. Il faut dire surtout que le marché visé, l'automobile, n'a pas les mêmes contraintes de consommation que le marché mobile. Reste que Nvidia se doit de gérer cette asymétrie avec un scheduler qui doit décider sur quel coeur placer les threads, ce qui n'est pas particulièrement simple. On notera que chaque groupe de coeurs dispose de son propre cache L2 de 2 Mo.
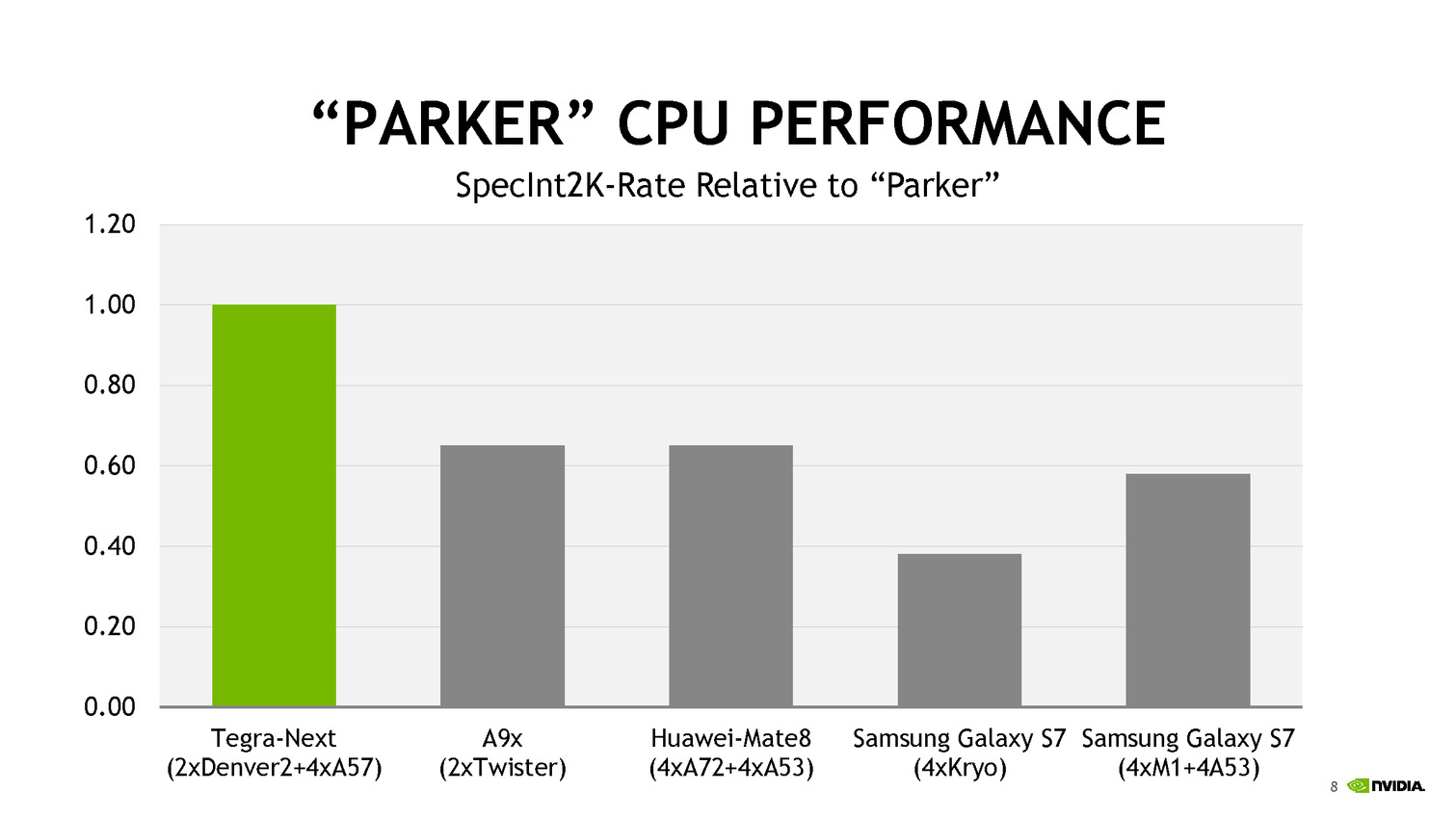
Côté performances, Nvidia avec ses 6 coeurs se présente comme moitié plus rapide qu'un A9X d'Apple en deux coeurs. Le graphique mélangeant des puces à TDP différents (on y retrouve des puces pour smartphones et pour tablettes), on admettra que la comparaison n'est pas faite à TDP identique.
TSMC parle de ses packages InFo
Une des nouveautés présentées cette année par TSMC est la disponibilité d'un nouveau type de packaging, l'InFo-WLP. L'idée est de permettre de relier plusieurs dies en les "moulant" dans un substrat commun très fin qui contient également les interconnexions entre les puces. Il s'agit d'une version à cout beaucoup plus faible que les interposer (utilisés par exemple par AMD pour Fiji).
La présentation de TSMC est dédiée aux interconnexions entre les puces, et présente une puce 16nm reliant un SOC à une puce mémoire avec une bande passante de 89.6 Go/s sur 256 bits, le tout avec une consommation très réduite.
En plus de la solution présentée qui évoque le cas simple d'une puce mémoire et d'un Soc, TSMC évoque la solution comme permettant un jour de relier également plusieurs dies de logique, par exemple des groupes de coeurs séparés, pour réduire le coût de fabrication des puces (qui augmentent exponentiellement avec la taille des dies).
































La présentation est technique mais reste intéressante, l'InFo-WLP ouvre des opportunités supplémentaires pour réaliser des produits qui mélangent processeur et mémoire. Le coût réduit et la finesse de l'interconnexion fait qu'on pourrait retrouver assez rapidement cette technique utilisée, y compris sur le marché mobile. Les prochains SoC d'Apple pourraient par exemple utiliser un tel package.
Et Skylake !
Juste avant la présentation de Zen, Intel proposait aussi une présentation de son architecture Skylake, lancée l'année dernière. Si la majorité du contenu est déjà connu, on aura noté un détail intéressant : un diagramme sur les unités d'exécution de Skylake. On rappellera que l'année dernière durant l'IDF, Intel nous avait promis plus de détails sur le sujet, sans jamais nous les donner !
Pour rappel, voici la répartition sur Haswell :
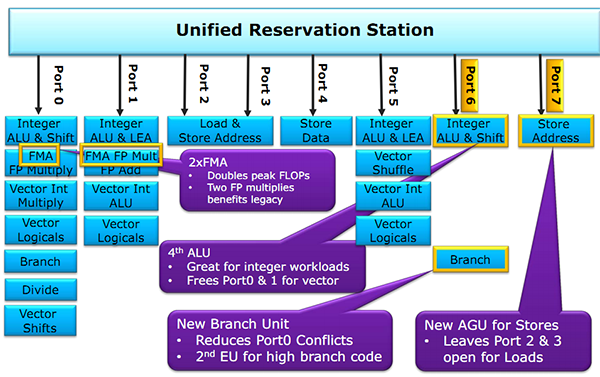
Récapitulatif des ports/unités d'exécution sur Haswell
Un an après, voici enfin un diagramme similaire pour Skylake :
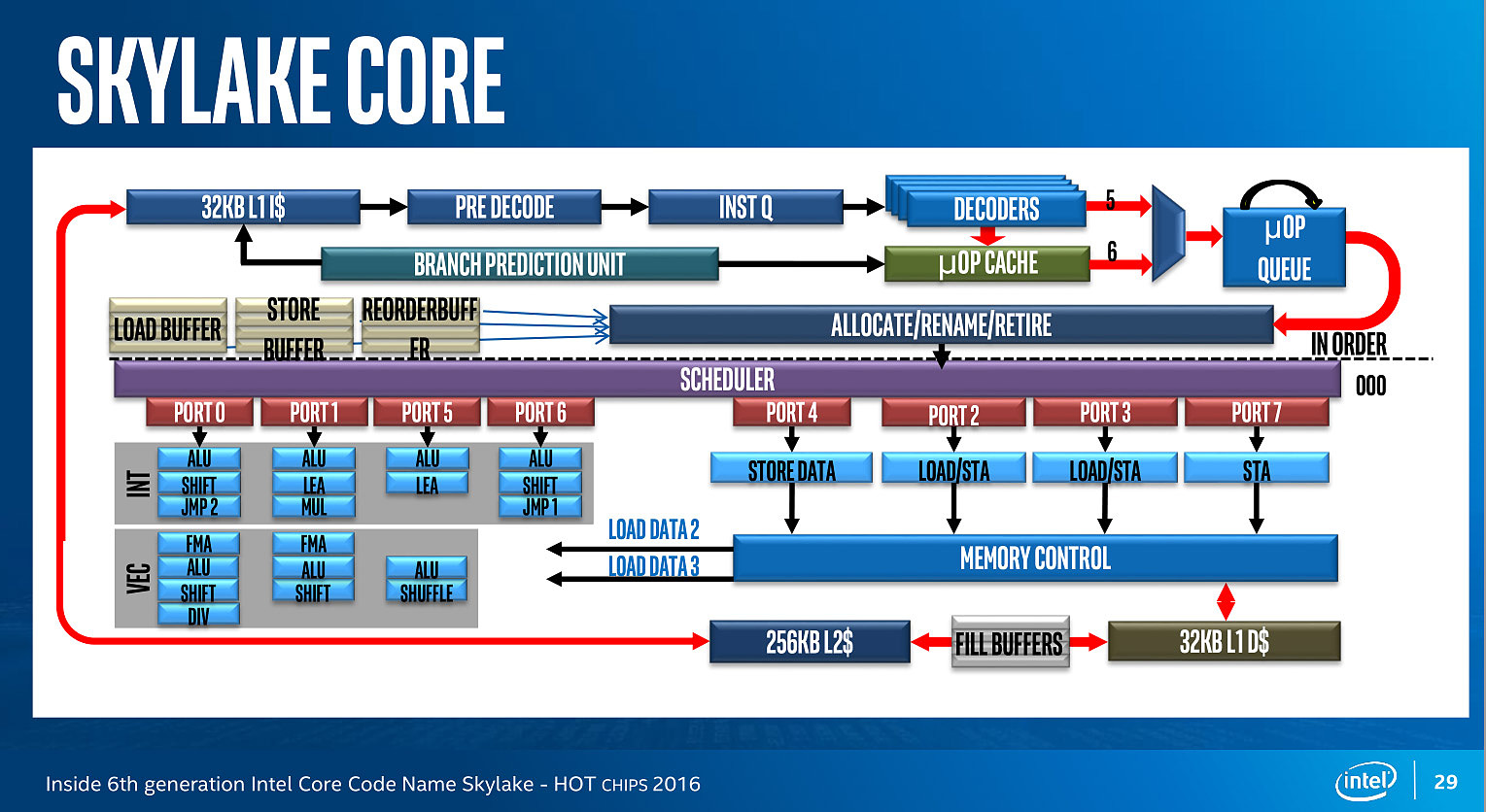
Conformément à ce que nous avaient indiqué les ingénieurs d'Intel l'année dernière, le nombre d'unité a bel et bien augmenté. Le nombre de ports reste constant, à 8, mais l'on compte... une nouvelle unité. Sur le port 1, Intel a en effet ajouté une unité de shift vectorielle. Pour le reste, la répartition reste similaire à celle d'Haswell. Un mystère enfin élucidé !
Intel Custom Foundry prend une licence ARM !
 ARM l'a confirmé par un post de blog : Intel Custom Foundry, l'activité fabrication tiers d'Intel, est désormais détentrice d'une licence ARM Artisan pour le 10nm !
ARM l'a confirmé par un post de blog : Intel Custom Foundry, l'activité fabrication tiers d'Intel, est désormais détentrice d'une licence ARM Artisan pour le 10nm !
Il faut rappeler qu'Intel est plutôt un cas à part dans le monde des semi-conducteurs, étant l'une des rares sociétés à disposer de ses propres usines, utilisées quasi uniquement pour la production de ses propres puces. La plupart des autres acteurs du marché ont migré vers la séparation de l'activité design d'un côté (on parle de sociétés fabless, c'est le cas dans le monde du GPU avec AMD et Nvidia), et de l'autre la fabrication dans des sociétés tierces spécialisées (on parle de foundry, la plus connue étant TSMC qui fabrique des puces pour de multiples clients).
Avec la difficulté de la mise au point des nouveaux process de fabrication, qui n'a fait qu'empirer ces dernières années, il est de plus en plus complexe pour une société à elle seule de justifier l'investissement nécessaire pour faire évoluer sans cesse ses usines. Qui plus est, la réduction de la taille des transistors fait que la capacité des usines augmente d'année en année, et qu'il faut disposer de très larges volumes de puces à produire, au risque de voir ses usines tourner à vide.
Un casse tête qui aura poussé plusieurs sociétés à se séparer de leurs usines (pour des raisons différentes) d'abord AMD en 2009 (créant GlobalFoundries) et plus récemment IBM (dont l'activité fabrication à été rachetée elle aussi par GlobalFoundries).
Depuis quelques années, en plus de fabriquer ses propres puces dans ses usines, Intel a décidé d'entrer très timidement, en 2010, sur le marché des fondeurs tiers en ouvrant son process à de petites sociétés qui n'étaient pas en concurrence directe avec ses produits (le premier client était Achronix, designer de FPGA en 22nm). D'autres clients ont suivi, principalement sur les FPGA, le client le plus connu d'Intel ayant été Altera... même si au final Intel aura décidé de racheter son client à la mi-2015 !
Pour Intel, la nécessité d'ouvrir ses usines est un casse tête. D'un côté, la société tente d'être présent sur tout les marchés, en déclinant le x86 - technologie "maison" sur laquelle la concurrence est limitée - à toutes les sauces et avec un soupçon de recyclage, que ce soit avec des produits serveurs spécialisés comme les Xeon Phi basés sur des Pentium pour leur première génération, ou les Quark dédiés à l'embarqué et utilisant une architecture de 486 datant d'une bonne vingtaine d'années !
Si l'envie de la société d'être présente sur tous les marchés est là, en pratique les succès ne sont pas systématiquement au rendez vous, Intel ayant par exemple massivement raté le marché des smartphones. Cumulé à la baisse continue des ventes sur le marché historique des PC, l'ouverture des usines à des clients tiers se dessine de plus en plus comme une nécessité pour Intel, même si l'avouer semble impossible à la société, qui continuait donc d'envoyer des signaux mitigés aux possibles futurs clients de son activité fabrication.
Avec l'annonce d'aujourd'hui, les choses sont - peut être - en train de changer puisque la prise de licence ARM par Intel est tout sauf anodine. Ce n'est pas la première fois qu'Intel fabriquera des SoC ARM, on l'avait vu avec Altera qui utilisait un core ARM dans un usage très spécifique.
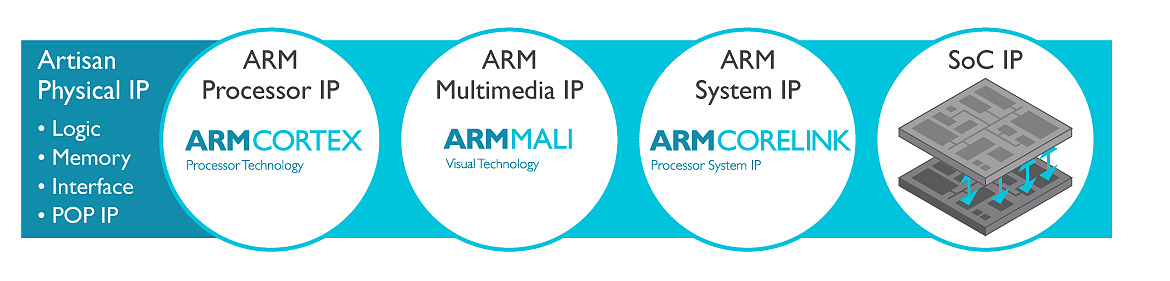
La licence Artisan Physical IP inclut en effet toutes les briques nécessaires pour la création de puces ARM de tout types. Il s'agit de tous les blocs de base avec des bibliothèques haute densité et haute performance de transistors logiques,et également tout le nécessaire pour les différents types de mémoire. La licence inclut surtout POP IP, qui est pour rappel l'idée qui fait le succès d'ARM : permettre l'utilisation de blocs interchangeables et compatibles pour créer des puces custom. Ainsi un client peut choisir d'utiliser des coeurs CPU dessinés par ARM (les gammes Cortex) ou créer ses propres coeurs (c'est le cas d'Apple et plus récemment de Nvidia), de choisir un GPU (que ce soit les Mali d'ARM, ou les populaires PowerVR d'Imagination Technologies), et également de choisir son fournisseur pour les interconnexions.
Concrètement, Intel va donc "porter" ces bibliothèques d'ARM aux particularités de son futur process 10 nm, ce qui permettra aux partenaires d'ARM de porter à leur tour - s'ils le souhaitent - leurs blocs POP IP. ARM et Intel travailleront conjointement pour le portage de deux futurs blocs CPU ARM Cortex-A (probablement un autre successeur 10nm de l'A72, voir l'annonce de l'A73 en 10nm lui aussi), la déclinaison que l'on retrouve dans les smartphones et tablettes.
Faut il y voir un virage pour Intel ? Fabriquer des puces ARM pour smartphones, ce qu'ils feront pour LG (nouveau client annoncé dans la foulée) va forcément à l'encontre des ambitions internes d'Intel d'imposer le x86 sur mobile. Car si un peu plus tôt dans l'année Intel avait décidé d'annuler sa nouvelle génération de SoC pour smartphones (Broxton et SoFIA), le constructeur continuait en interne à travailler sur les générations suivantes tout en essayant de développer dans l'intérim son activité modem (Intel aurait possiblement gagné le marché du modem du prochain iPhone). A l'heure où ARM augmente ses ambitions pour aller attaquer le marché juteux des serveurs, on peut se demander jusqu'où ira réellement l'ouverture d'Intel.

Un futur CPU ARMv8 24 coeurs de Qualcomm
En fabriquant des puces concurrentes, Intel s'ouvre à des comparaisons directes qui pourraient être assez défavorables à ses architectures x86, assez peu adaptées à la basse consommation. L'avantage supposé du process d'Intel, s'il existe, ne pourra plus jouer en la faveur de ses propres solutions pour compenser un éventuel déficit architectural. La structure de marges d'Intel, là aussi très différente de celle des fondeurs tiers, posera là aussi rapidement problème.
Qui plus est, en obtenant la licence Artisan d'ARM, Intel va devoir partager tous les détails techniques, y compris les plus secrets, de son process en ce qui concerne les règles et les dimensions exactes des transistors, ce qui va l'exposer là aussi à une comparaison directe avec les autres acteurs installés du milieu (comme TSMC et Samsung). Il faudra un peu de temps pour mesurer les conséquences concrètes de tout cela, car cet accord ne concerne que le 10nm, un process pour rappel en retard et qui n'est prévu chez Intel que pour la fin de l'année 2017 en version mobile. Les dernières nouvelles du 10nm, sur lequel Intel ne communique pas, n'étaient pour rappel pas particulièrement rassurantes avec l'arrivée possible sur sa roadmap de puces 14nm... pour 2018.
L'EUV possiblement pour le 7nm ?
Le site SemiWiki nous rapporte quelques informations sur l'état de la fabrication EUV, en provenance de la conférence SPIE Advanced Lithography qui se tient actuellement à San José.
Lors de la même conférence l'année dernière, les nouvelles étaient pour rappel plutôt bonnes (voir le lien pour un rappel complet sur la fabrication des processeurs et l'importance capitale de l'EUV !) et l'on espérait une introduction en cours de process pour le 10nm, et une introduction complète à 7nm. Malheureusement, on le rappelait en janvier, TSMC avait calmé les ardeurs en indiquant qu'il faudrait attendre le 5nm pour une éventuelle introduction de cette technologie.

SemiWiki confirme certains chiffres donnés lors de la dernière conférence aux investisseurs de TSMC, à savoir que la machine avait atteint sur une période de quatre semaines une production de 518 wafers/jour, un niveau encore largement insuffisant. Intel a partagé également quelques chiffres, un peu inférieurs à ceux de TSMC, à savoir entre 2000 et 3000 wafers par semaine (285-428 par jour).
On notera quand même que le taux de disponibilité des scanners de la société ASML a augmenté, passant de 55 à 70% chez TSMC (Intel rapportant une disponibilité identique) ! On notera que s'il est question d'une introduction en début de node à 5nm, TSMC laisse la porte ouverte pour le 7nm si jamais des progrès étaient effectués. Intel de son côté n'a pas donné d'information. Samsung envisagerait l'introduction à 7nm selon les présentations, sans plus de précisions.
Si la question de la disponibilité est importante, celle de la puissance de la source lumineuse l'est encore plus. Après avoir été limité à 40 watts l'année dernière, les machines actuellement en évaluation chez TSMC disposent désormais de sources 80 watts. C'est mieux, mais cela reste loin des 250 watts promis par ASML pour fin 2015. Les dernières prédictions sont désormais de 250 watts en 2016-2017, et au delà en 2018-2019, des plages particulièrement larges.
Atteindre les 250 watts de puissance permettrait d'augmenter significativement la cadence de production, atteignant 170 wafers/heure en théorie. ASML a effectué des démonstrations que TSMC et Intel semblent juger prometteuses de 185 et 200 watts. Reste à les voir en production, bien évidemment. Les challenges de cette technologie restent complexes et ne se limitent pas à ces deux points cruciaux, la question des défauts dans les masques est elle aussi importante même si là aussi TSMC et Intel ont visiblement noté quelques progrès. Vous pouvez retrouver plus de détails sur ces points dans l'article de SemiWiki .
L'ITRS prépare l'après loi de Moore
C'est la section actualité de la très sérieuse revue scientifique Nature qui l'affirme : la loi de Moore est arrivée à son terme. Énoncée en 1965 par Gordon Moore, l'un des cofondateurs d'Intel, il s'agit d'une observation par laquelle la quantité de transistors dans les circuits intégrés doublait à peu près tous les ans. Une observation transformée en loi pour prédire que cette cadence pouvait être extrapolée pour les années à venir.
En 1975, la loi avait été révisée pour prendre la forme que l'on connaît actuellement, à savoir un doublement des transistors tous les deux ans. L'importance de la loi de Moore allait cependant au-delà de la simple prédiction puisqu'elle prenait en compte les coûts de fabrication : l'observation se fait sur les puces ayant le coût par transistor le plus faible (tentant donc de prendre en compte les questions de yields et de défauts en fonction de la taille des puces).
Plus qu'une prédiction, la loi de Moore a servie, particulièrement chez Intel, de guide au fil des années, prédisant à l'avance les budgets en nombre de transistors alloués aux ingénieurs, et poussant vers l'avant la nécessité d'investir dans de nouveaux process de fabrications, la fameuse stratégie du Tick-Tock poussée d'abord en interne par Pat Gelsinger au début des années 2000 avant d'être utilisée publiquement pour décrire les générations à venir.
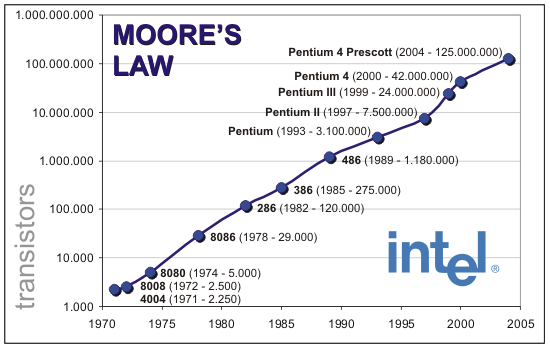
De manière intéressante, au-delà d'Intel, c'est toute l'industrie du semi-conducteur qui s'est mise d'accord autour de la loi de Moore, à savoir non seulement les fondeurs, mais aussi et surtout les fournisseurs d'outils. Le besoin de coordination entre tous les acteurs aura conduit à l'élaboration d'une roadmap, d'abord appelée National Technology Roadmap for Semiconductors dès 1993, avant d'être renommée sous sa forme actuelle, l'International Technology Roadmap for Semiconductors (ITRS).
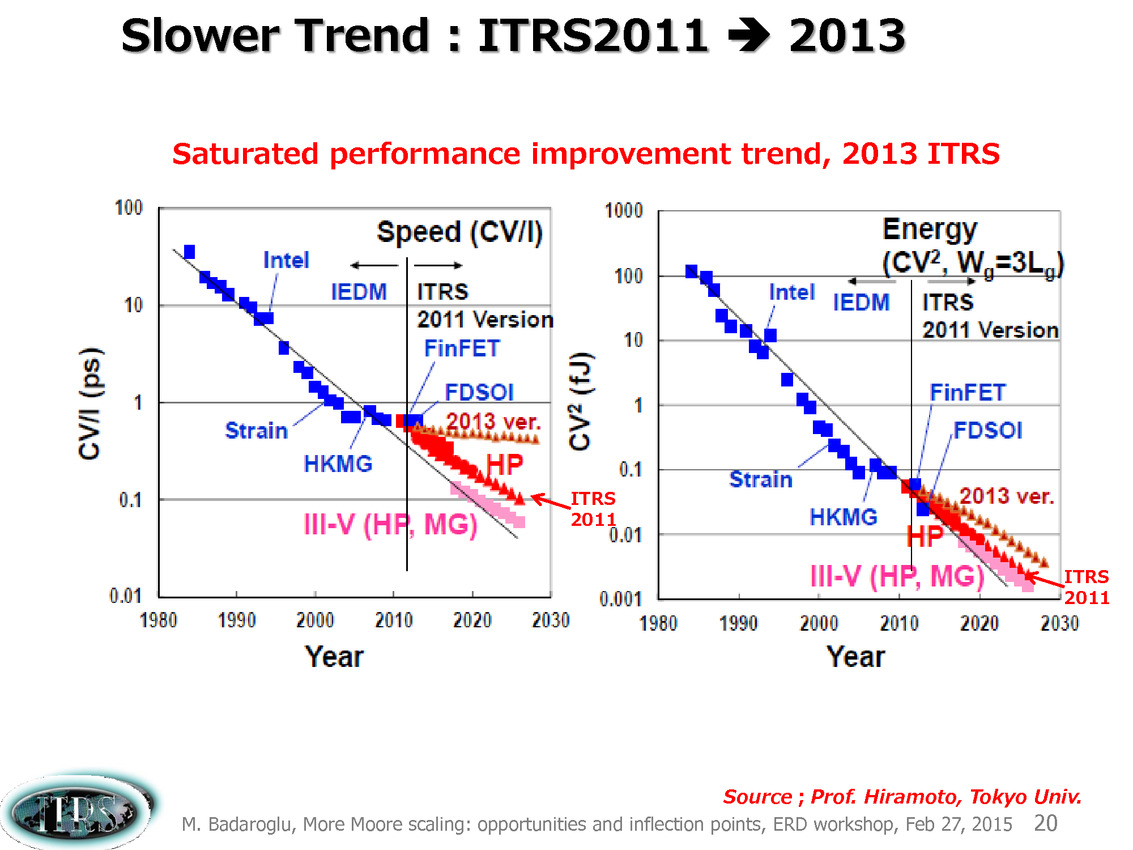
Le rôle joué par cette roadmap, dont la dernière version a été publiée en 2013 aura été particulièrement important ces dernières années où, passé le 90nm, les challenges techniques ont contraint à des changements d'approches importants. L'augmentation des performances par la fréquence, méthode classique aura atteint un plateau à cause de l'augmentation de la consommation, poussant dans le commerce les stratégies de multiplication des coeurs que l'on connaît. Le rôle de la roadmap, au-delà de la concertation, est de s'assurer de trouver des pistes pour continuer la cadence de réduction des coûts/augmentation des transistors de la loi de Moore.
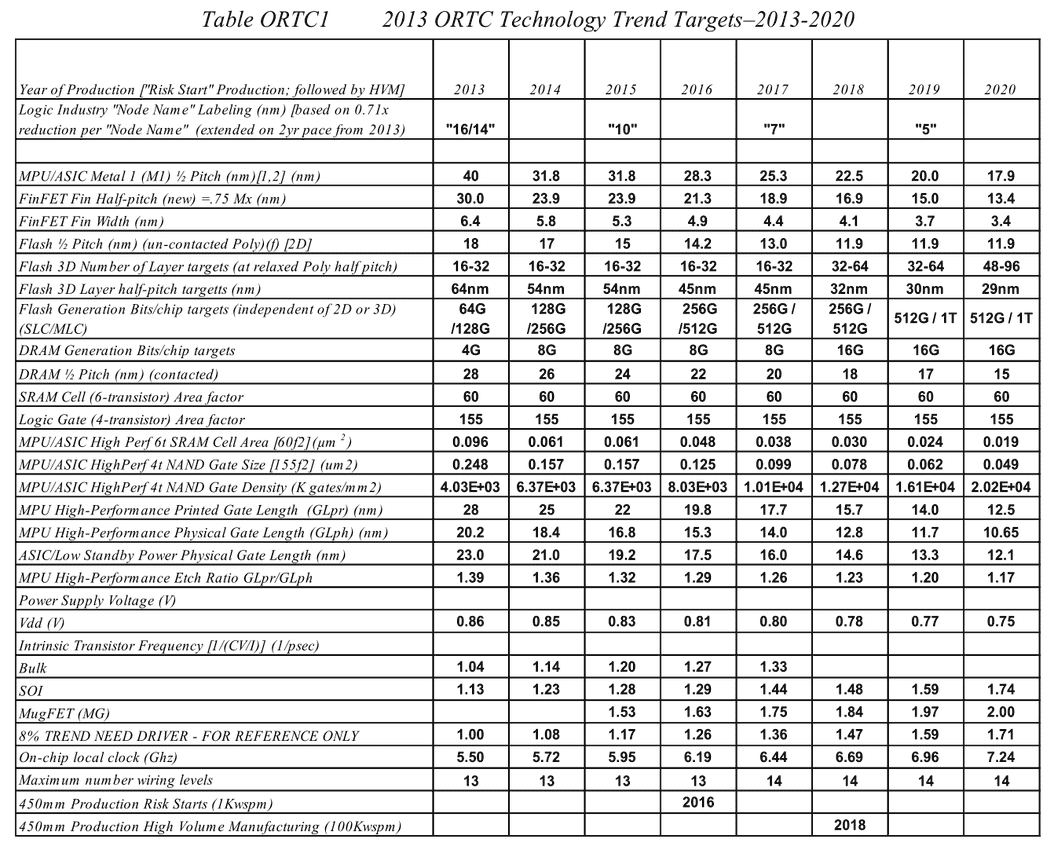
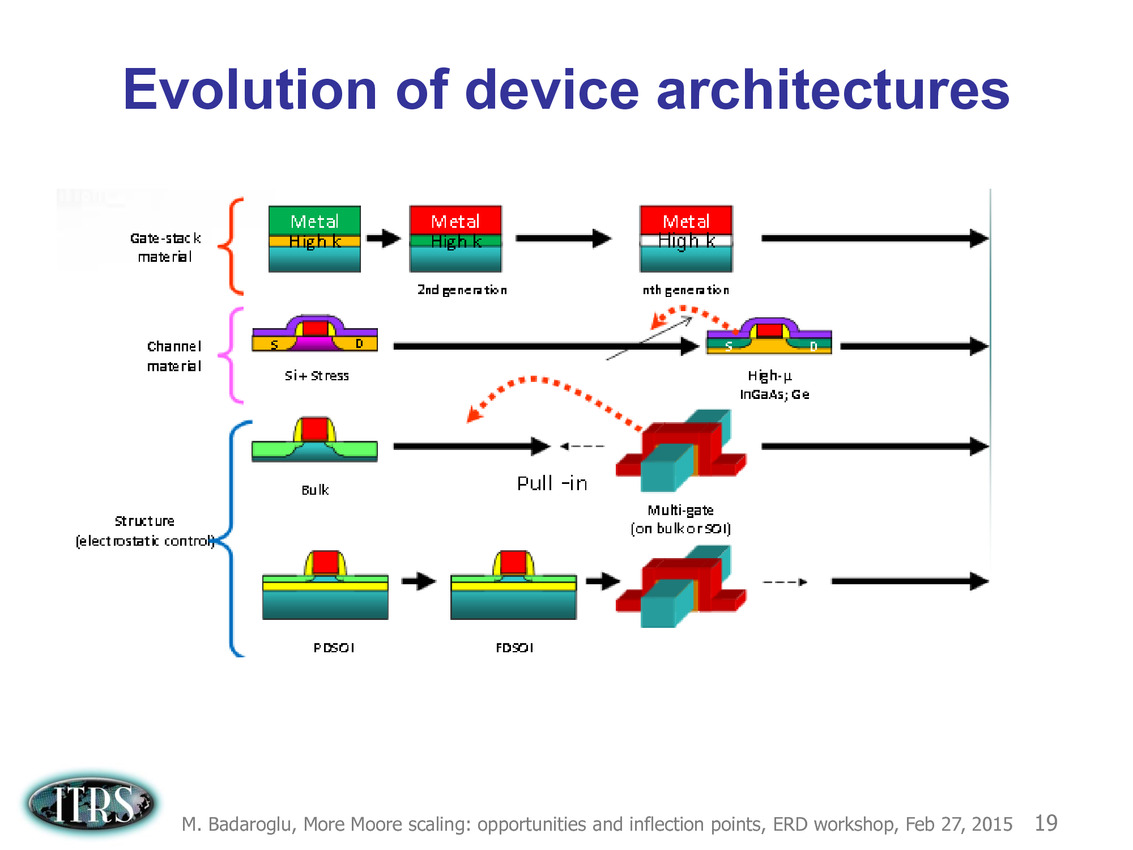
La dernière roadmap ci-dessus donnait des grandes lignes sur la manière de mettre à l'échelle les différents composants des transistors. Après les difficultés autour du 90nm, l'industrie est passé progressivement de la règle dite de la mise à l'échelle géométrique (on réduit tout dans des proportions identiques, le nom du node indiquant en général la taille de la porte) à celle de la mise à échelle par équivalence (equivalent scaling).
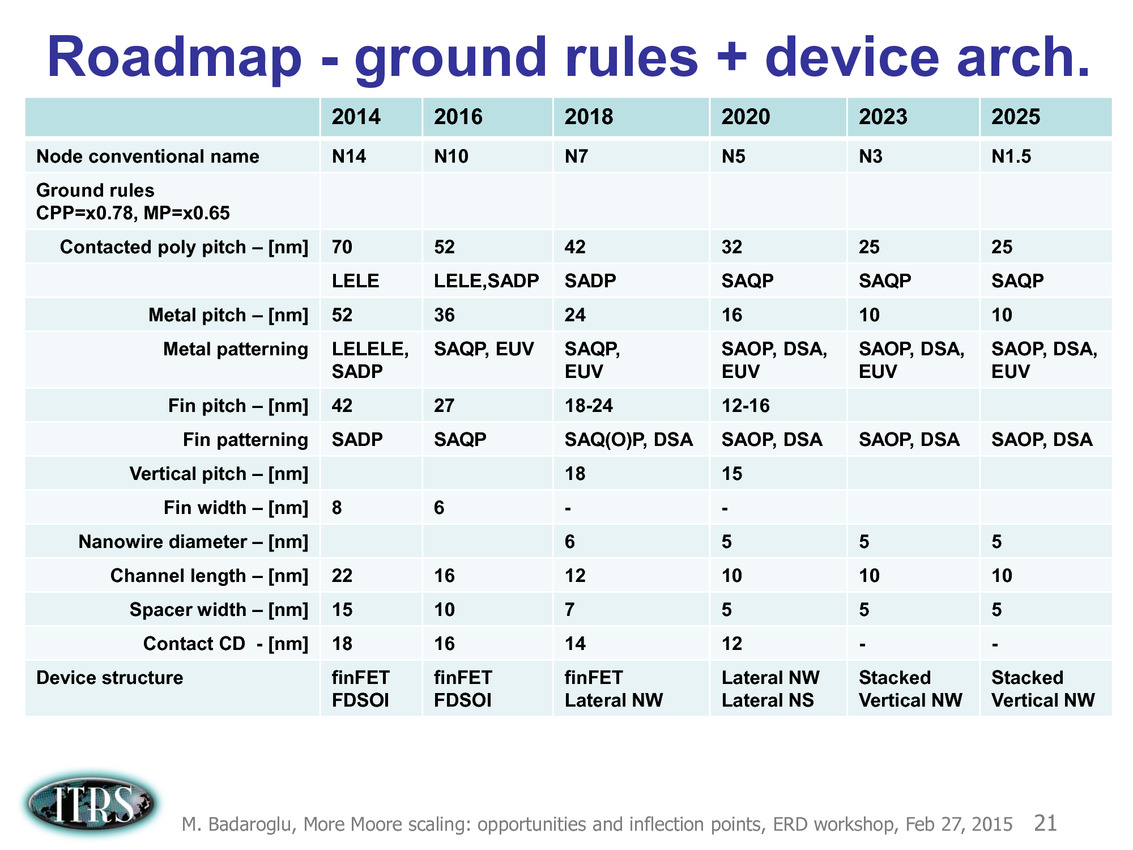
Etant donné que différentes parties composant les puces posent des problèmes différents, des règles d'équivalences ont été mises au point pour permettre de continuer a atteindre les buts de réduction des coûts/augmentation de densité imposé par la loi de Moore (on peut voir sur le tableau la couche d'interconnexion M1 et l'écart minimal entre deux transistors FinFET, en passant par des estimations des tailles de blocs fondamentaux comme la SRAM).
Pour 2016, la roadmap annonçait par exemple de la SRAM 6 transistors (6T) haute performance en 10nm autour de 0.048 µm2, ce qui n'est pas très éloigné de ce que présentait Samsung il y a une dizaine de jours de cela. En pratique cependant, on notera qu'on est globalement assez en retard sur la roadmap qui prévoyait des débuts de production à petite échelle en 10nm en 2015 (Risk Start dans la roadmap, suivi de HVM, fabrication en volume). Chez TSMC par exemple, la production risque est prévue pour la fin 2016 avec une production en volume pour 2017. Intel prévoit ses puces en volume pour 2017 également.
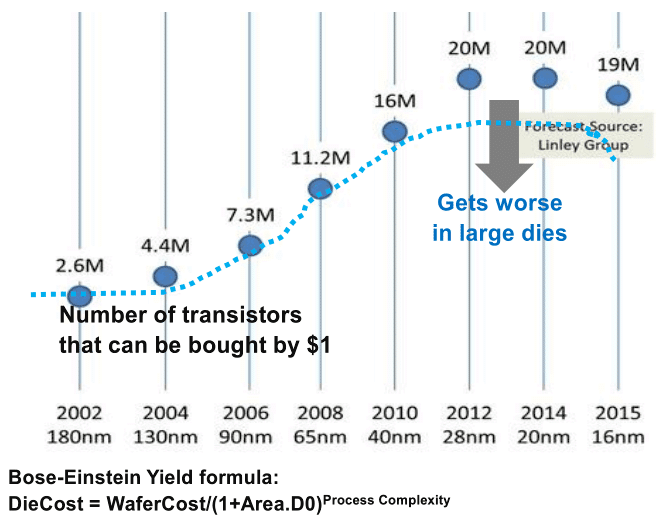
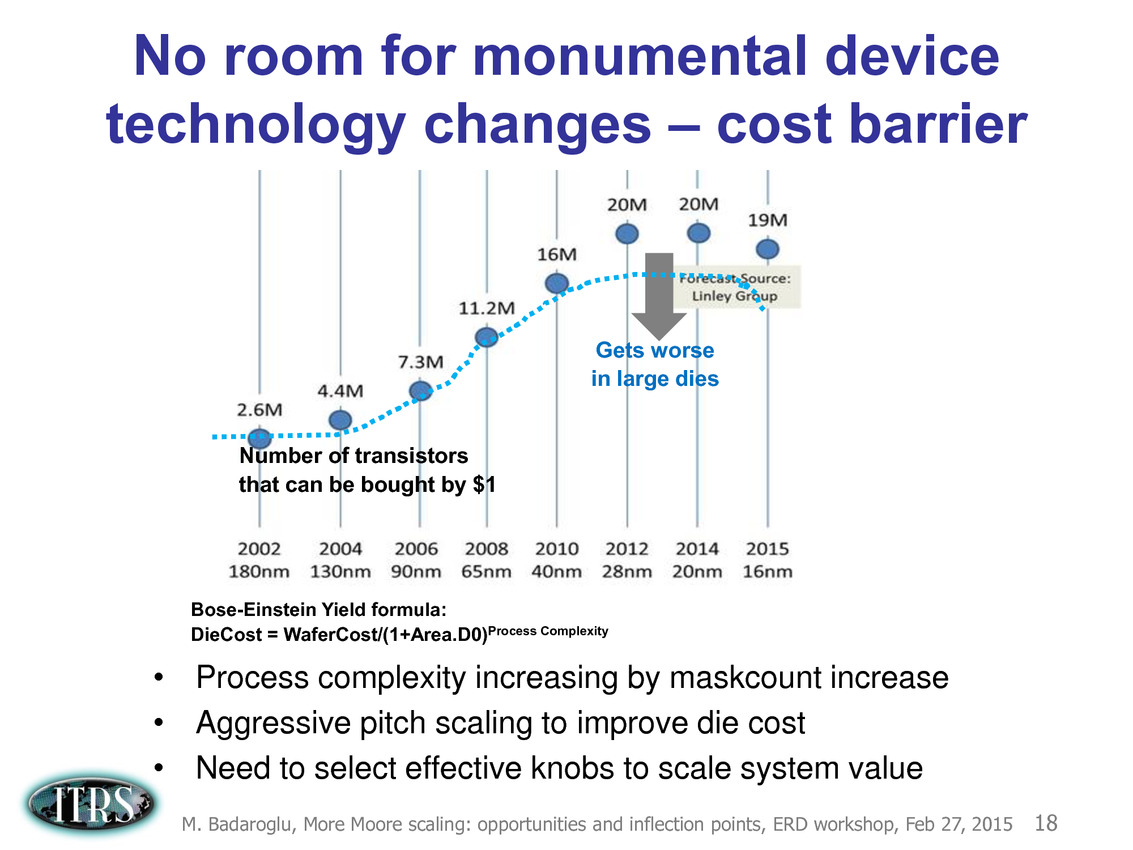
Évidemment depuis 2013 les choses se sont un peu plus compliquées et l'absence de roadmap en provenance de l'ITRS n'a pas forcément aidé. En pratique, la réduction des coûts s'est arrêtée, avec même un retour en arrière à 16nm signant de facto la fin de la loi de Moore, comme on peut le voir sur cette estimation ci-dessus tirée d'une présentation de l'ITRS en février 2015.
L'absence de nouvelle roadmap en provenance de l'ITRS aura même donné lieu à des divergences d'interprétations fortes, Intel titillant ses concurrents sur la question de la densité théorique. TSMC et Samsung ont fait pour rappel le choix de conserver un BEOL (Back End of Line, la partie basse d'une puce qui sert à l'interconnexion des transistors) commun entre le 20 et le 16nm pour accélérer la cadence de mise en production. En pratique chez TSMC, malgré le BEOL commun, le half pitch M1 reste tout de même dans les clous à 32nm (entre 40 et 31.8 sur la roadmap).
La densité pratique reste de toute manière très différente de ce que peuvent proposer des formules grossières comme celle utilisée par Intel (qui multipliait le pitch M1 par le pitch entre deux portes), qui pour exploiter les FinFET aura fait le choix d'utiliser pour certains de ses transistors critiques des structures plus larges composées de plusieurs fins (dans des proportions non négligeables même si la proportion exacte est rarement évoquée de manière précise par Intel).
Cumulé a de multiples autres détails (différents types de blocs sont présents avec des densités différentes, de la SRAM aux blocs plus ou moins critiques) il est impossible de tirer grand-chose de la théorie. L'écart entre un Core M Broadwell 14nm fabriqué par Intel (82mm2 pour 1.3 milliards de transistors) et un A8 fabriqué par TSMC en 20nm (89 mm2 pour 2 milliards de transistors) montre qu'il est difficile de comparer quoique ce soit à moins de prendre deux puces strictement identiques. Cela aura été possible pour l'A9 d'Apple, dont la superficie atteint 96mm2 chez Samsung contre 104.5mm2 chez TSMC.

Le mois prochain, l'ITRS devrait donc enfin communiquer une nouvelle roadmap qui d'après Nature tirera définitivement un trait sur la question de la loi de Moore comme moteur d'évolution unique. D'après Nature, la prochaine roadmap se concentrera sur les applications pratiques, allant du smartphones aux puces serveurs et regardera les applications pratiques, que ce soit au niveau circuits d'alimentations, des capteurs nécessaires, ou d'autres blocs de siliciums répondant à des besoins particuliers.
La véritable question est de savoir ce que comportera réellement cette roadmap qui serait rebaptisée d'après Nature International Roadmap for Devices and Systems, abandonnant même le mot transistor !
Ce que l'on sait, c'est que la réorganisation de l'ITRS en 2014 s'est faite autour de groupes de travaux, avec notamment un groupe baptisé « More Moore » pour évoquer les pistes techniques pour les prochains nodes, dont vous pouvez retrouver ci-dessous la dernière présentation datant de février 2015.



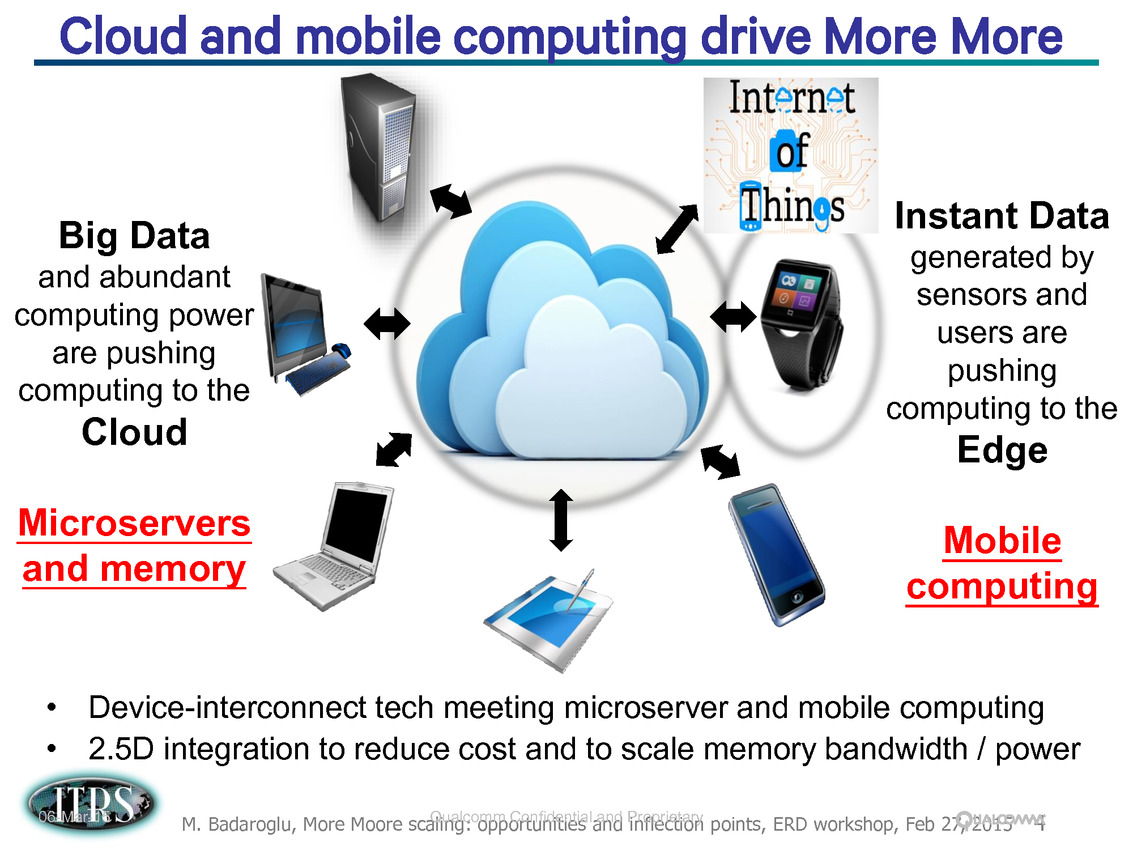
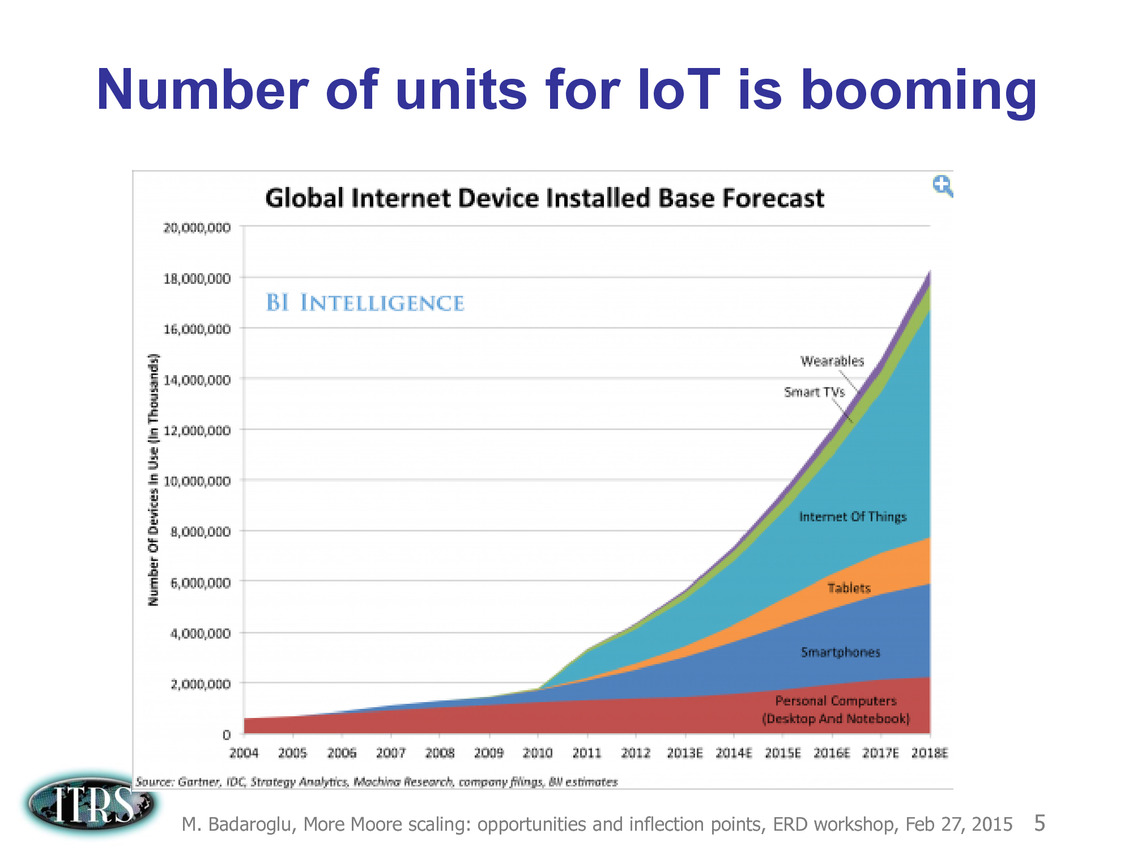

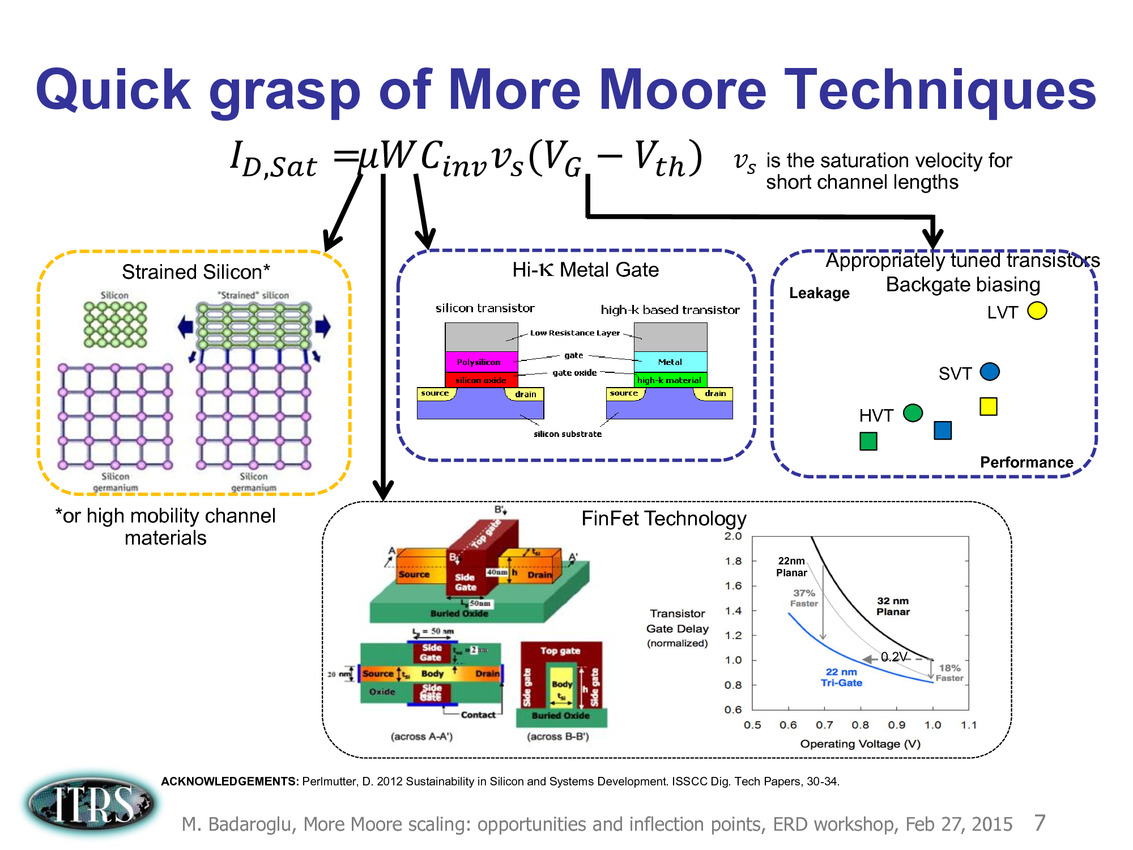
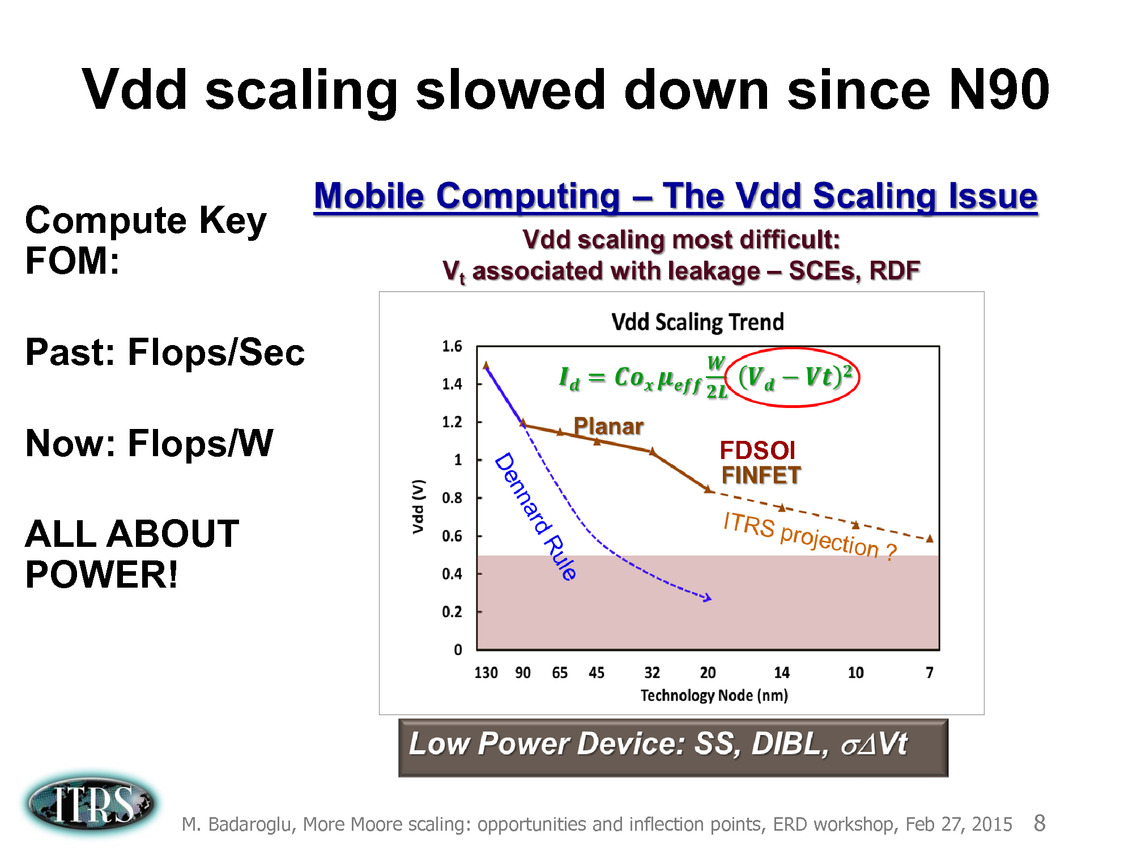
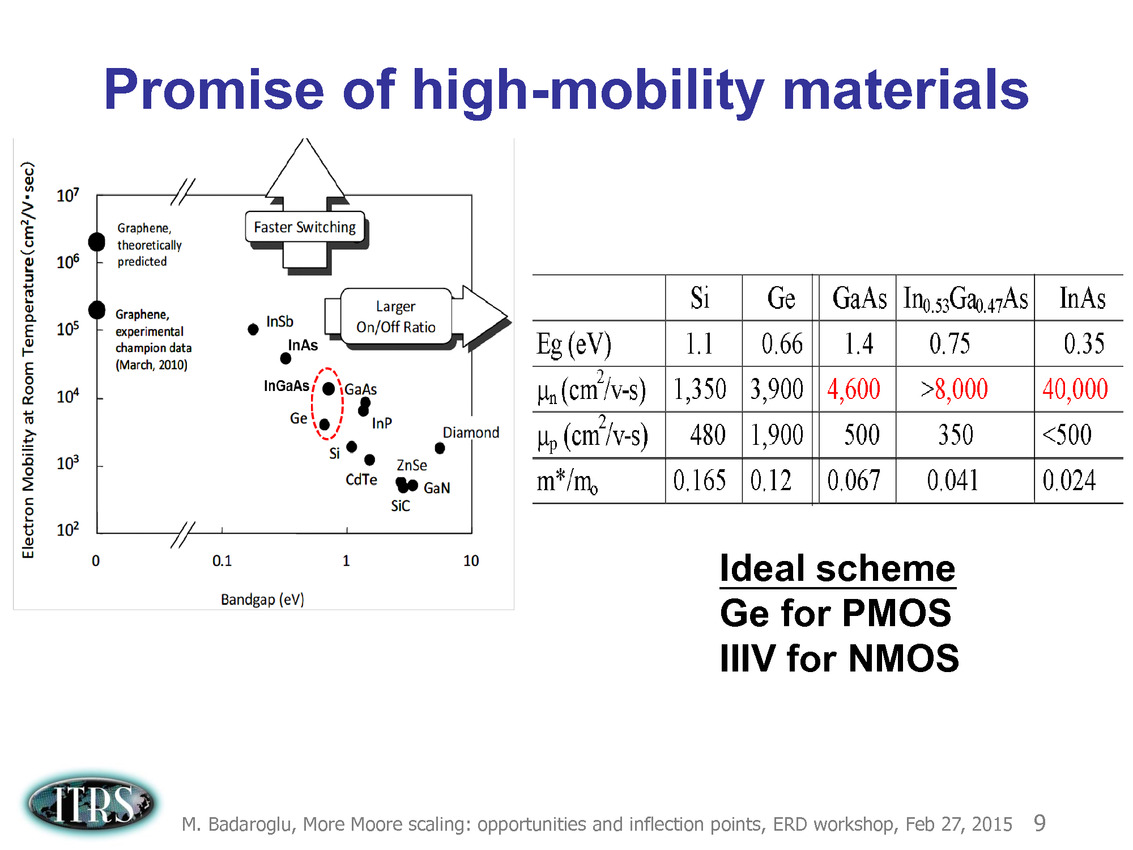
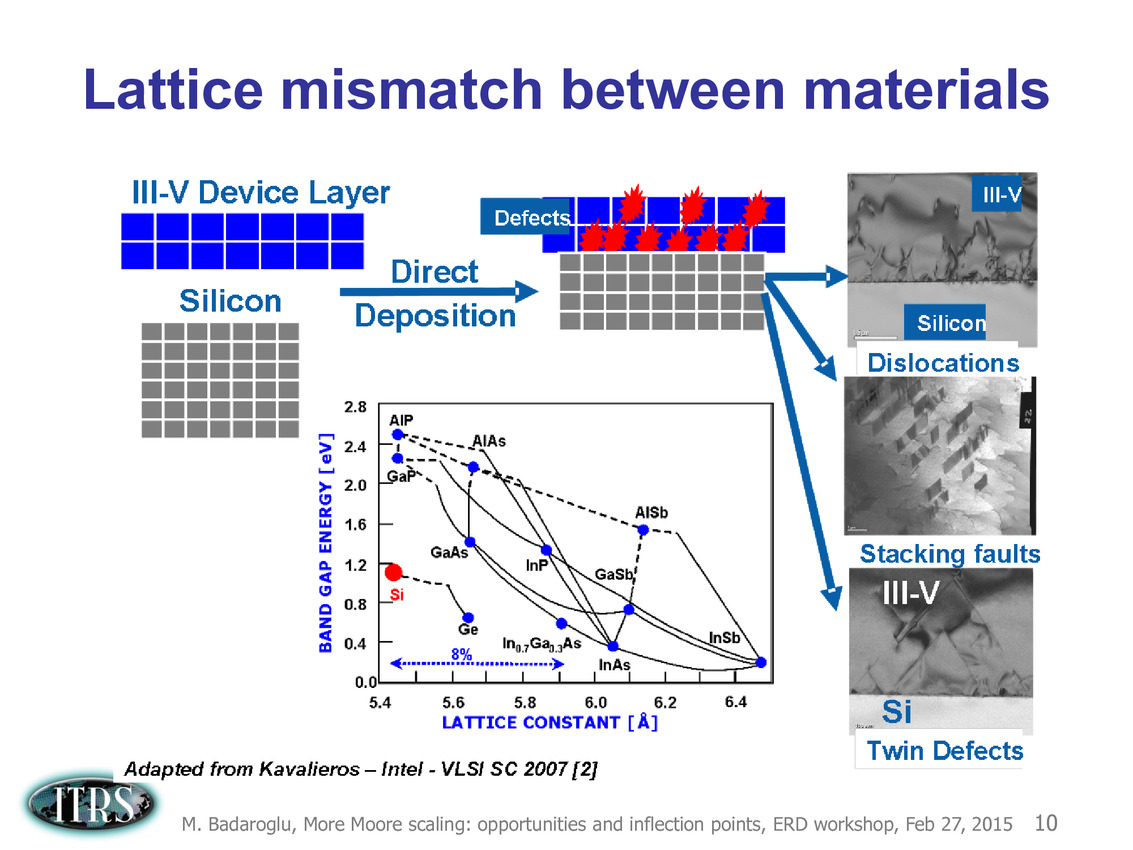
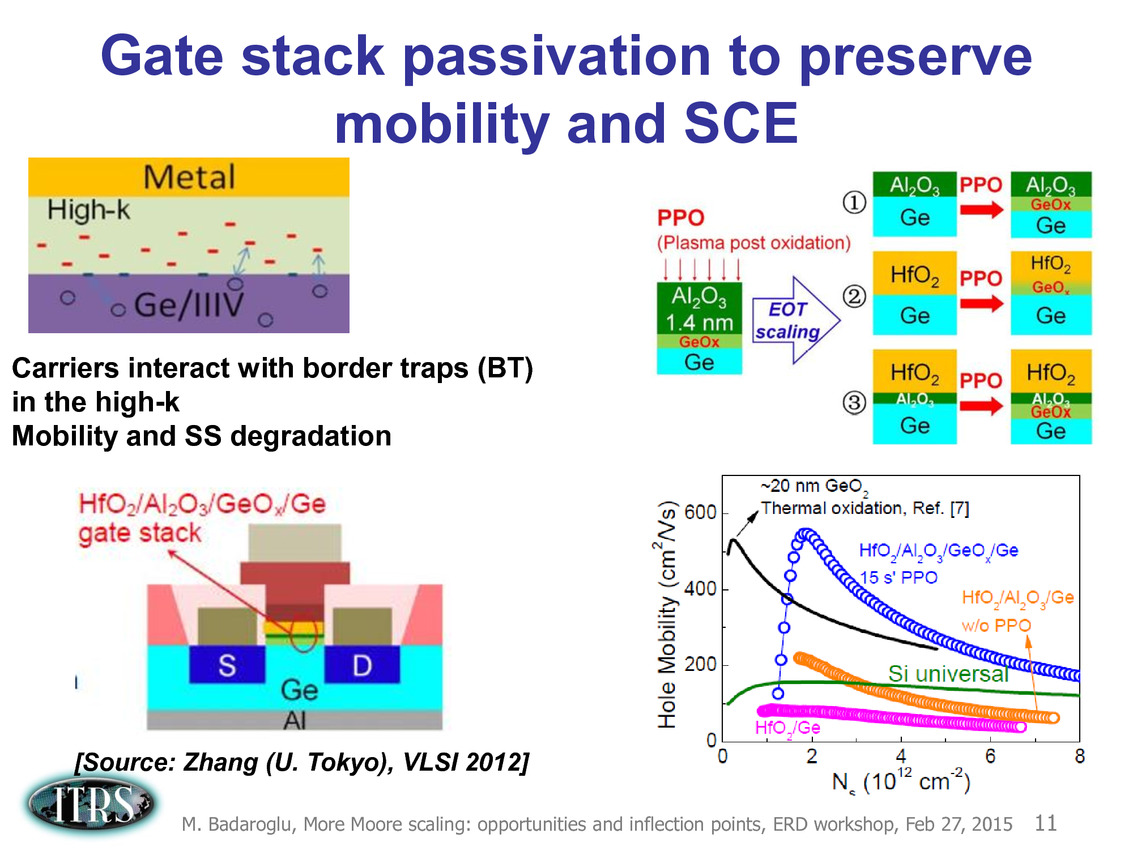
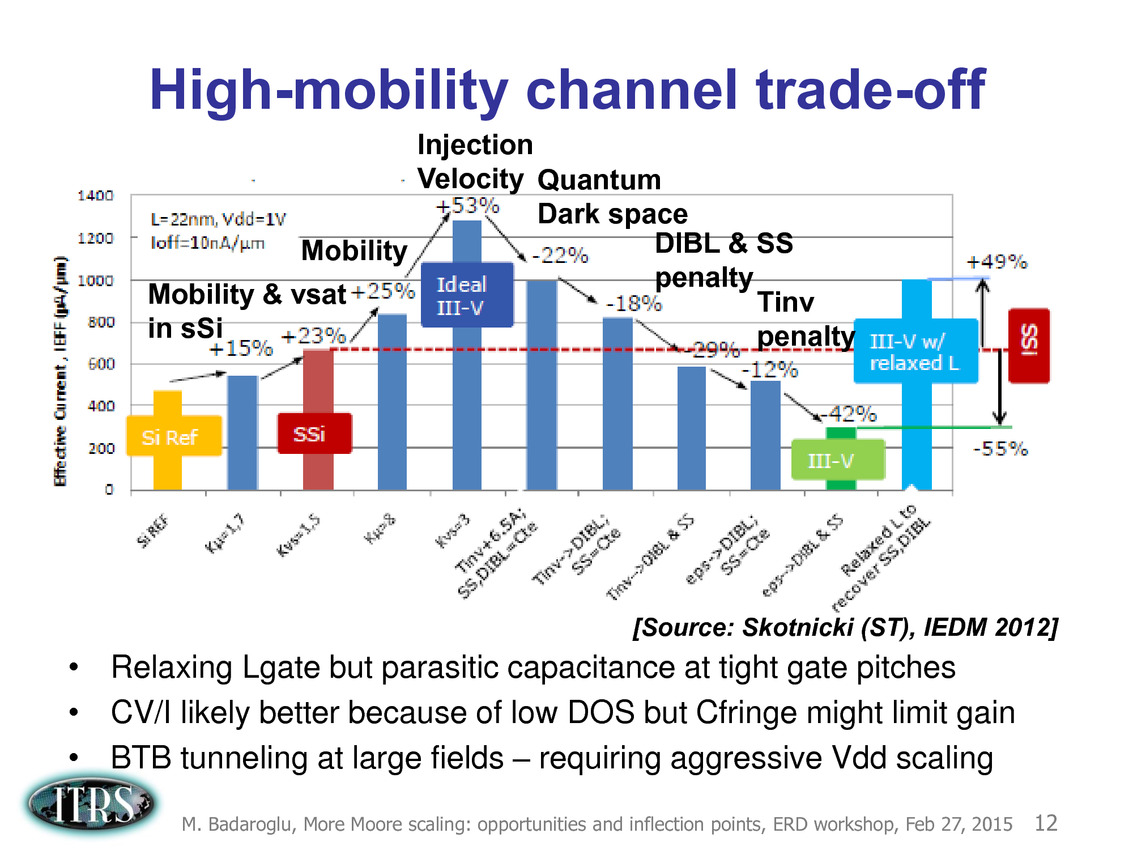
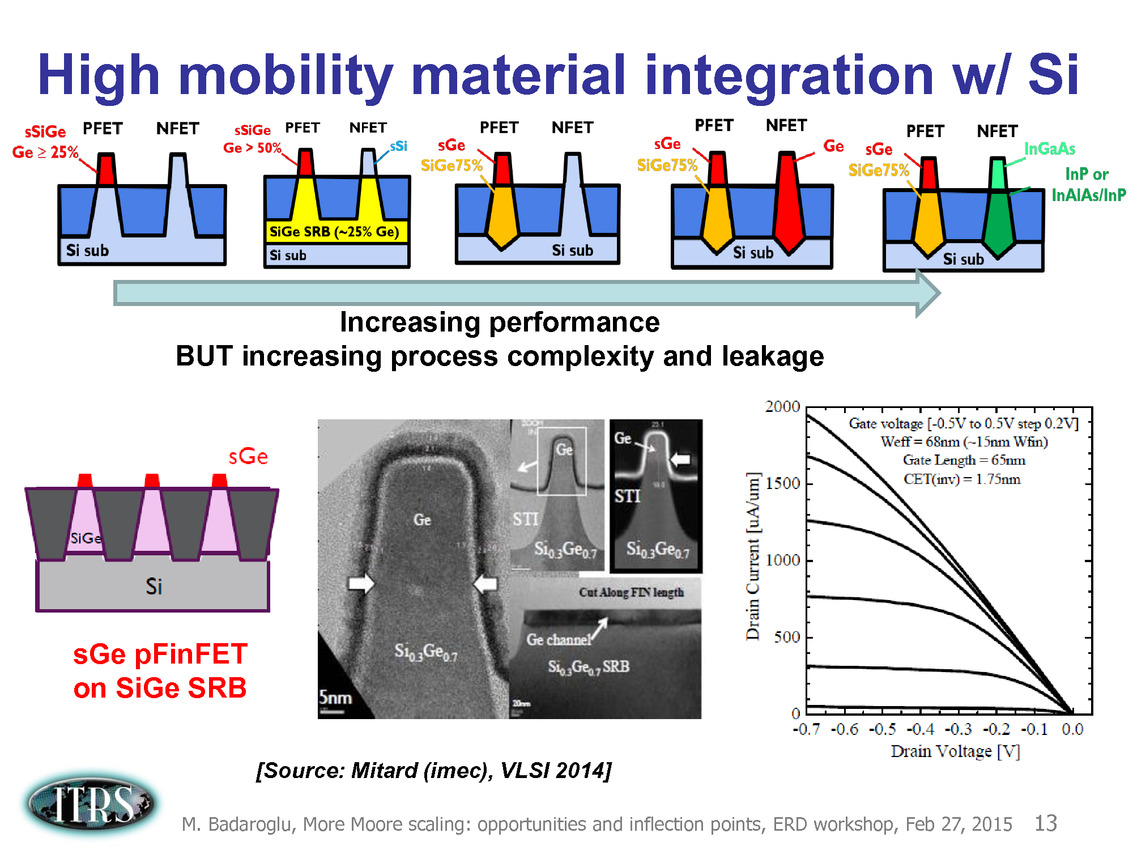

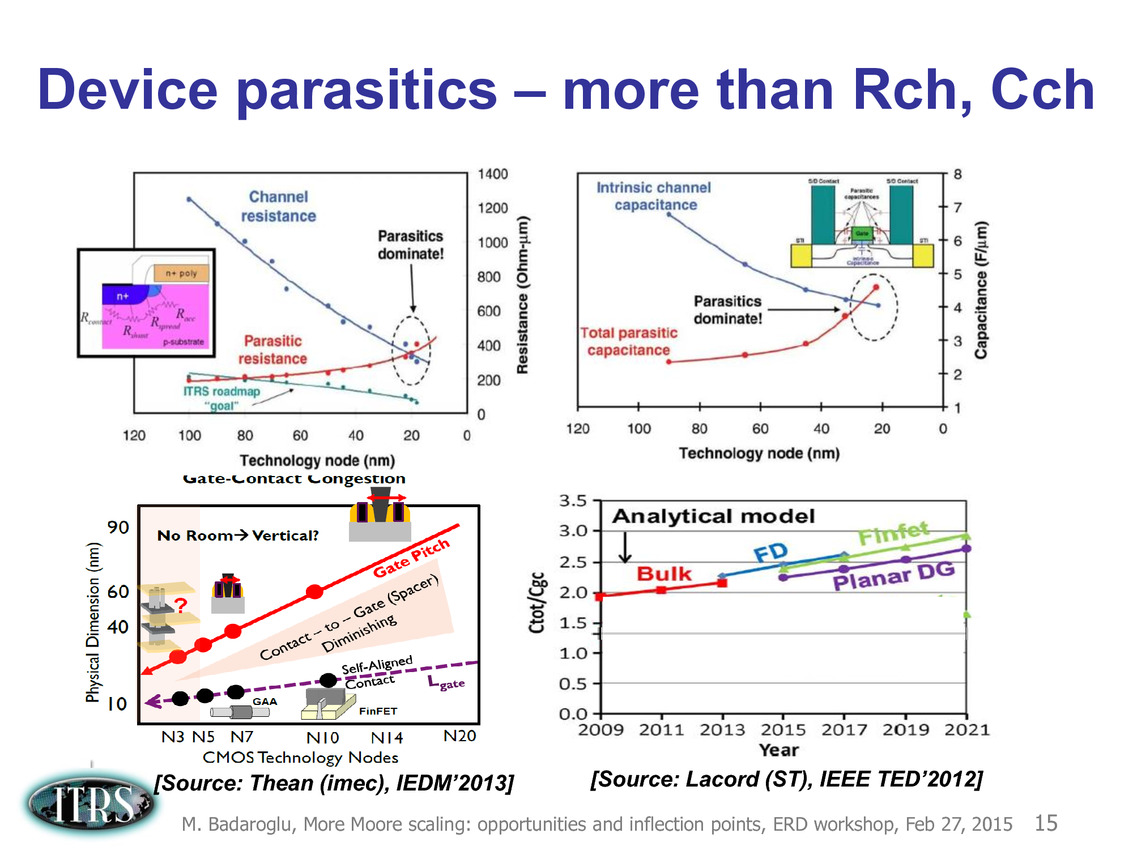
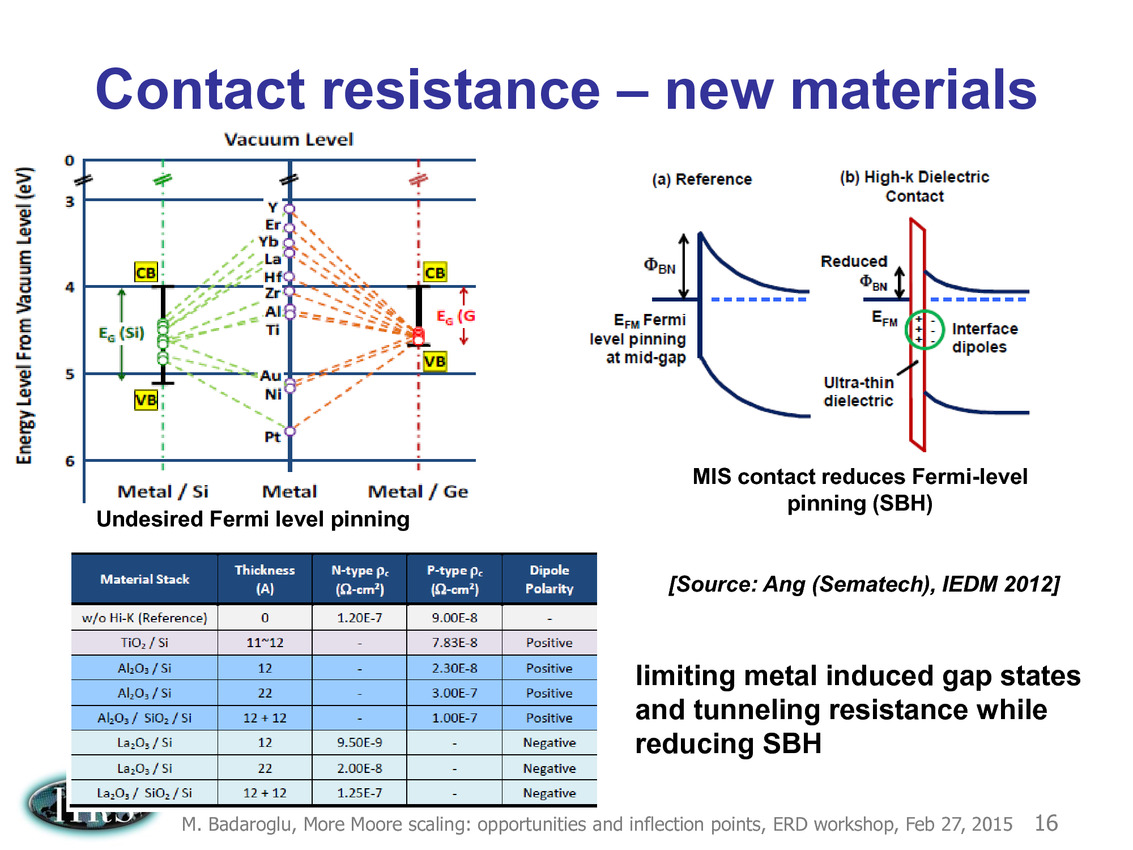
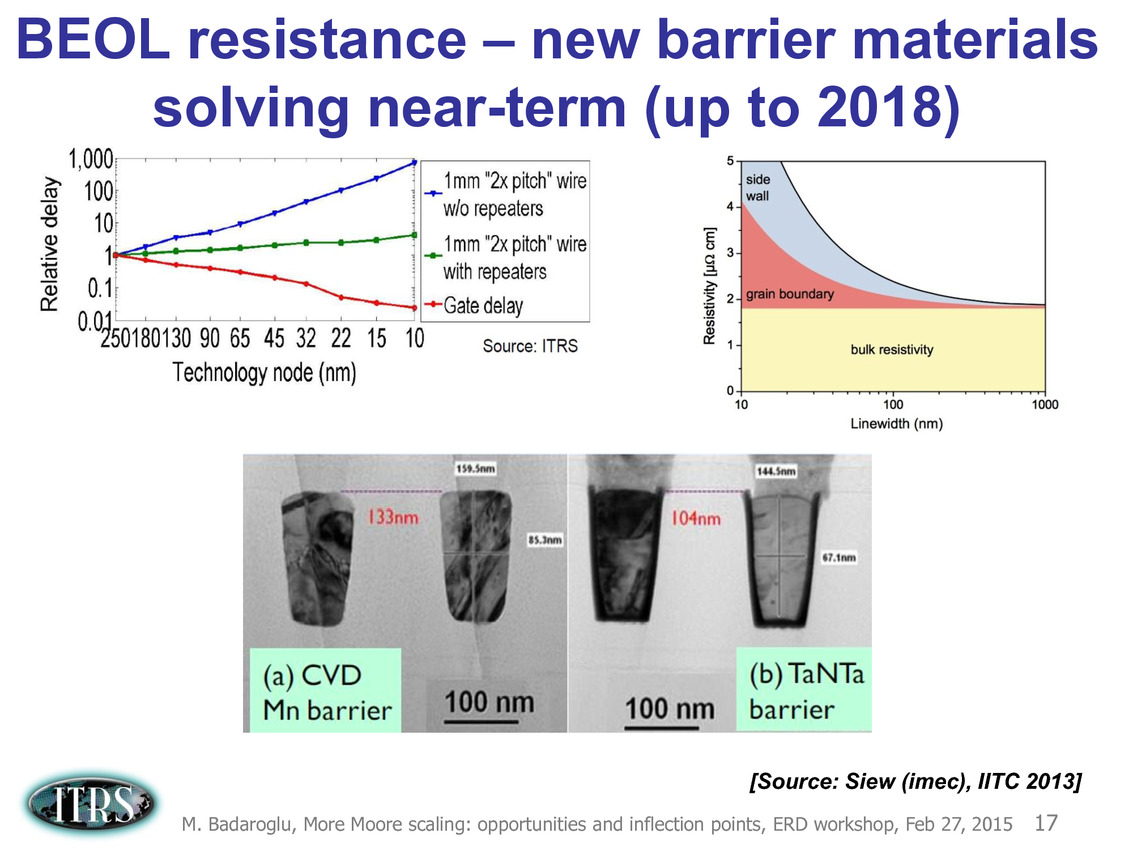
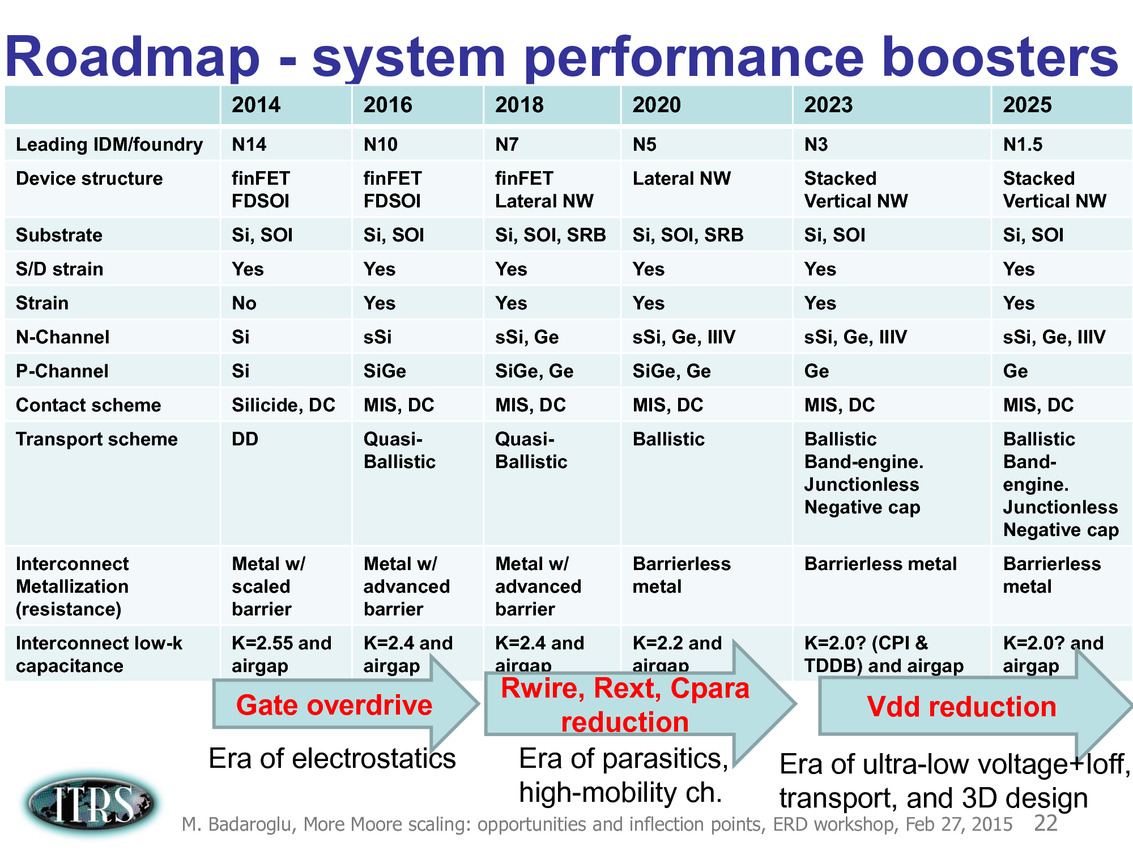
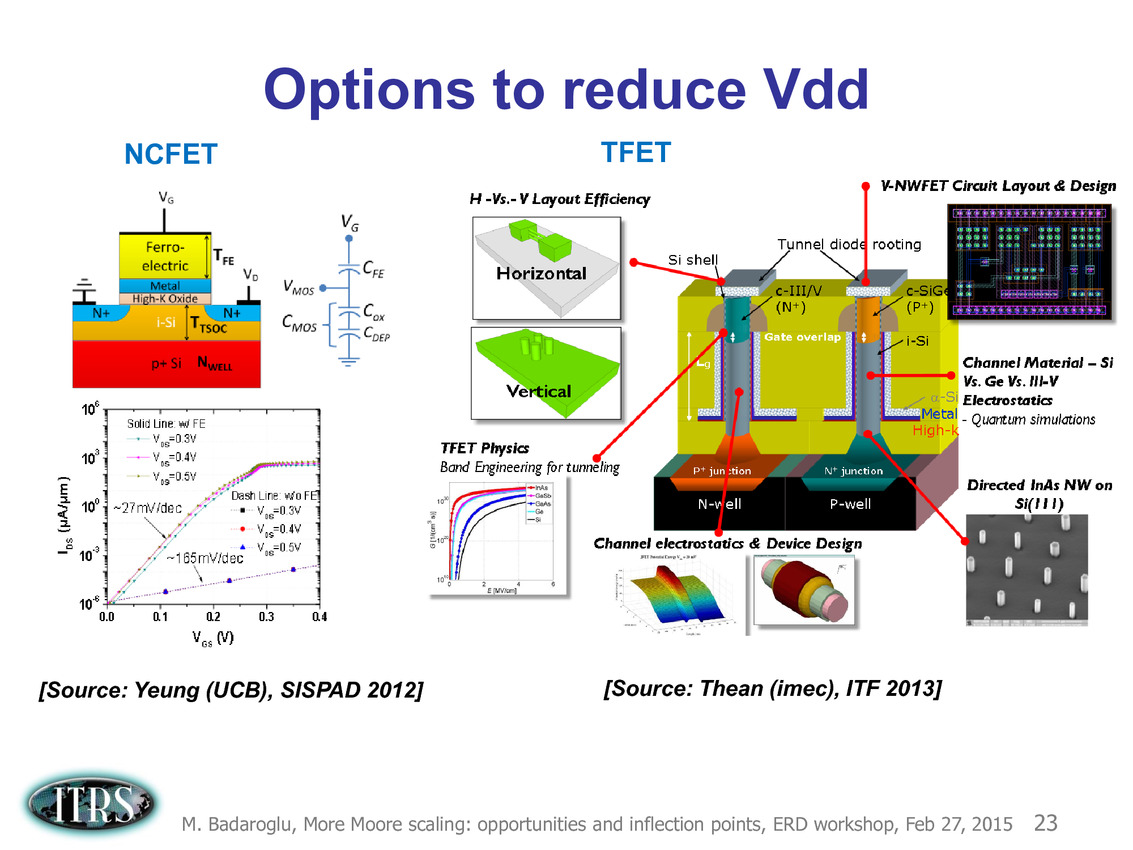
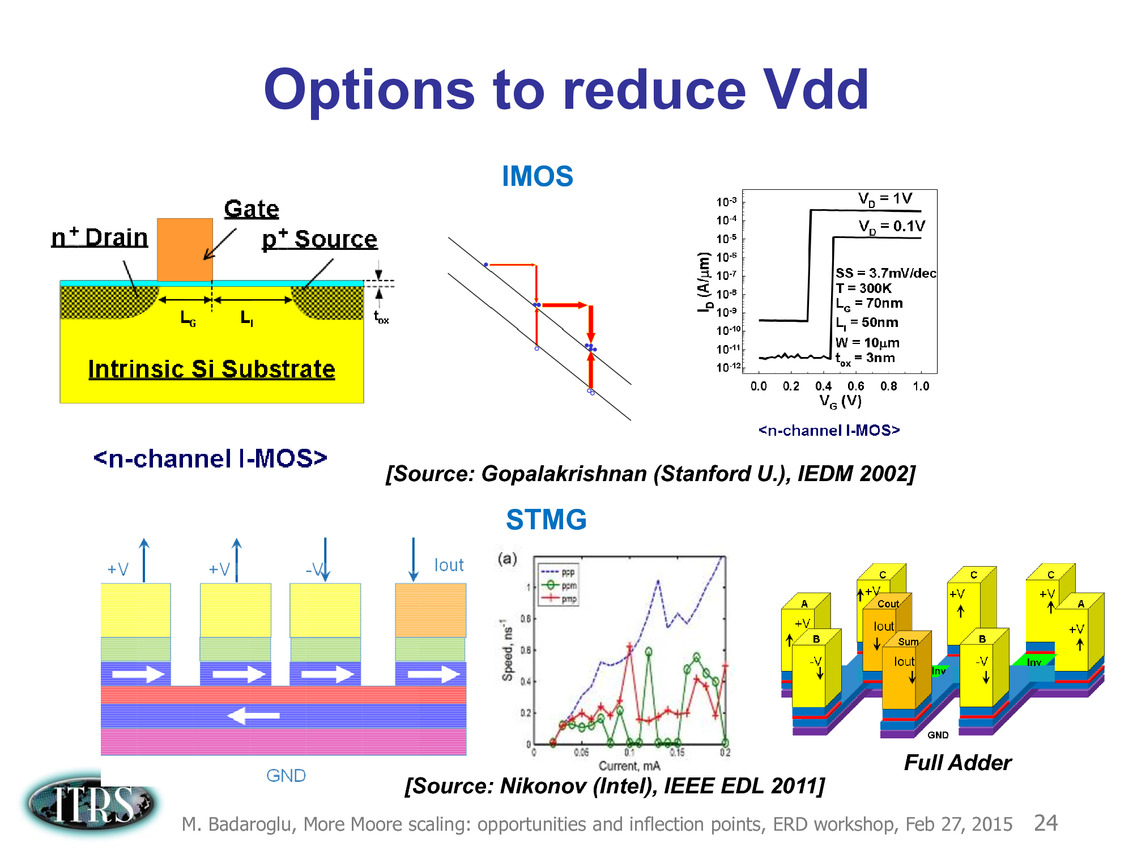
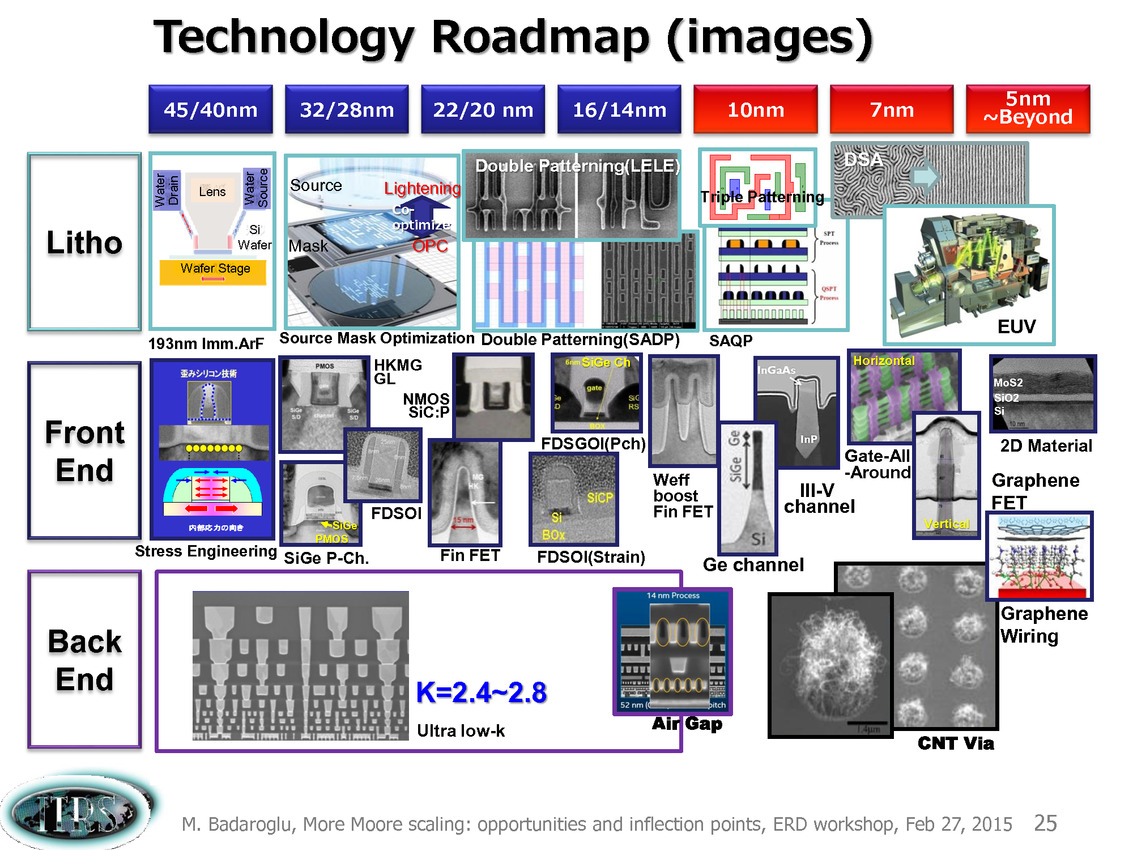

Une présentation intéressante qui évoque de multiples pistes et où l'on trouve un début de roadmap que nous avons remis ci-dessous :
En pratique, après l'ère de la mise à l'échelle géométrique, et l'ère des équivalences, l'ITRS évoque l'ère du "3D Power Scaling" dont les meilleurs représentants sont la NAND 3D ou des technologies comme la mémoire HBM. Des techniques complexes à appliquer aux puces logiques même si la présentation évoque quelques pistes et alternatives.
On attendra donc le mois prochain pour en savoir un peu plus !
AMD valide le 14nm LPP de GloFo
GlobalFoundries vient d'annoncer dans un communiqué qu'il avait livré à AMD des puces fonctionnelles gravées avec le process 14nm LPP (Low Power Plus), la version la plus avancée du procédé de fabrication Samsung 14nm FinFet (l'Apple A9 utilisant le 14nm LPE Low Power Early) qui est pour rappel également déployé chez GF.

Le fondeur précise qu'AMD a "taped out" plusieurs produit chez GF en 14nm LPP et qu'il est actuellement en train de valider les échantillons produit. Il semble donc qu'un premier produit ai été validé, GF parlant de "silicon success". AMD indique au passage qu'il compte utiliser le process 14nm LPP sur des produits CPU, APU mais aussi GPU. Jusqu'alors les GPU AMD étaient comme ceux de Nvidia fabriqués par TSMC, mais sachant qu'AMD a toujours des engagements contractuels sur des volumes avec GF qu'il peine à remplir il est logique qu'il favorise ce dernier si le process est à la hauteur. On devrait donc avoir droit en 2016 à une bataille d'architecture entre AMD et Nvidia combinée à une bataille de fondeurs avec d'un côté le 16nm FinFET+ de TSMC et de l'autre le 14nm LPP de Samsung/GlobalFoundries !
GlobalFoundries indique que le 14nm LPP a été qualifié au cours du troisième trimestre pour la production, cette dernière va débuter au cours de ce quatrième trimestre et arrivera à plein débit en 2016, sans plus de précision. Difficile pour le moment de savoir quand les premières puces AMD produites en 14nm LPP seront lancées en 2016, mais il serait étonnant que ce soit avant le second trimestre côté GPU et le dernier trimestre côté CPU. Vivement !