
Les contenus liés au tag Pascal
Afficher sous forme de : Titre | FluxPour quand les GPU Pascal et Polaris ?
CES: Drive PX 2: Tegra et Pascal au pilotage
Pascal sera produit en 16nm chez TSMC
Nvidia Pascal: le FP16 pour doubler les Tflops
GTC: Quelques détails de plus sur le GPU Pascal
GTC: 200 mm² pour le petit GPU Pascal ?



Il y 3 mois, lors du CES, Jen-Hsun Huang avait présenté le Drive PX 2, le nouveau boîtier dédié à la conduite autonome de Nvidia qui embarque entre autre deux GPU Pascal. Seul petit problème c'est alors un prototype équipé de GM204 Maxwell et non de GPU Pascal qu'avait présenté Jen-Hsun Huang, en oubliant de préciser ce détail, ce qui n'avait pas manqué de susciter la polémique.

Le CEO de Nvidia a profité de la GTC pour rectifier cela en affichant cette fois le "vrai" Drive PX 2 équipé des nouvelles puces Pascal. Le module était ensuite visible dans la zone d'exposition de la GTC mais Nvidia avait malheureusement pris soin de le positionner de manière à ce que les GPU ne soient pas clairement visibles. Nous pouvions cependant les apercevoir suffisamment pour obtenir un second angle de vue pour confirmer la taille de la puce.


Sur la photo où Jen-Hsun Huang présente le Drive PX 2, nous mesurons à peu près 200 mm², alors que sur les autres photos nous sommes plutôt à 205 mm². Suffisamment proche pour pouvoir estimer la taille de ce GPU Pascal (GP106 ?) à +/- 200 mm² en 16nm.
Les spécifications de ce GPU ne sont pas encore connues, tout ce que nous savons est qu'il atteint 4 TFlops dans la configuration qui a été retenue pour le Drive PX 2 et qu'il semble équipé d'un bus mémoire de 128-bit vu la bande passante annoncée de 80 Go /s et malgré la présence de 8 puces 32 bits. De quoi imaginer par exemple un plus gros GPU Pascal grand public (GP102 ? GP104 ?) qui pourrait doubler tout cela. 350 à 400 mm² en 16nm, 8 TFlops et un bus mémoire GDDR5X 256-bit pourrait correspondre à ce que nous prépare Nvidia.
GTC: Tesla P100: débits PCIe et NVLink mesurés
Lors d'une session de la GTC consacrée à GPUDirect, qui regroupe les techniques de communications entre GPU et avec d'autres éléments d'un système, nous avons pu en apprendre un peu plus sur les performances du GP100 au niveau de ses voies de communication.
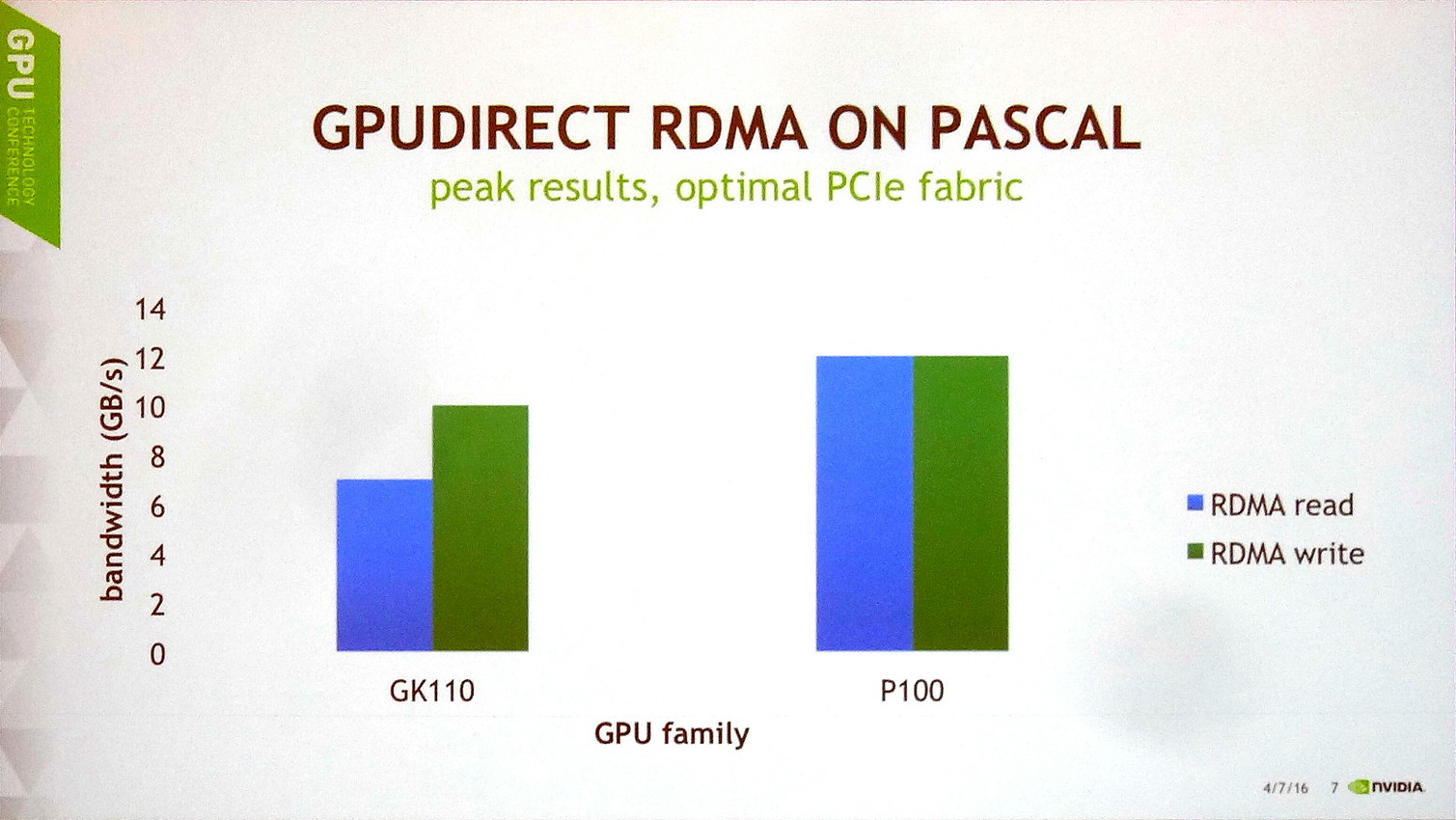
Il y a tout d'abord des progrès au niveau du PCI Express. Nvidia explique que les GPU Kepler et Maxwell souffraient de quelques limitations et devaient se contenter d'à peu près 10 Go/s en écriture et de 7 Go/s en lecture. Cela change avec Pascal dont le tissu PCI Express est dorénavant optimal pour une interface 16x 3.0, ce qui lui permet d'atteindre 12 Go/s dans les deux sens, soit à peu près le maximum théorique.
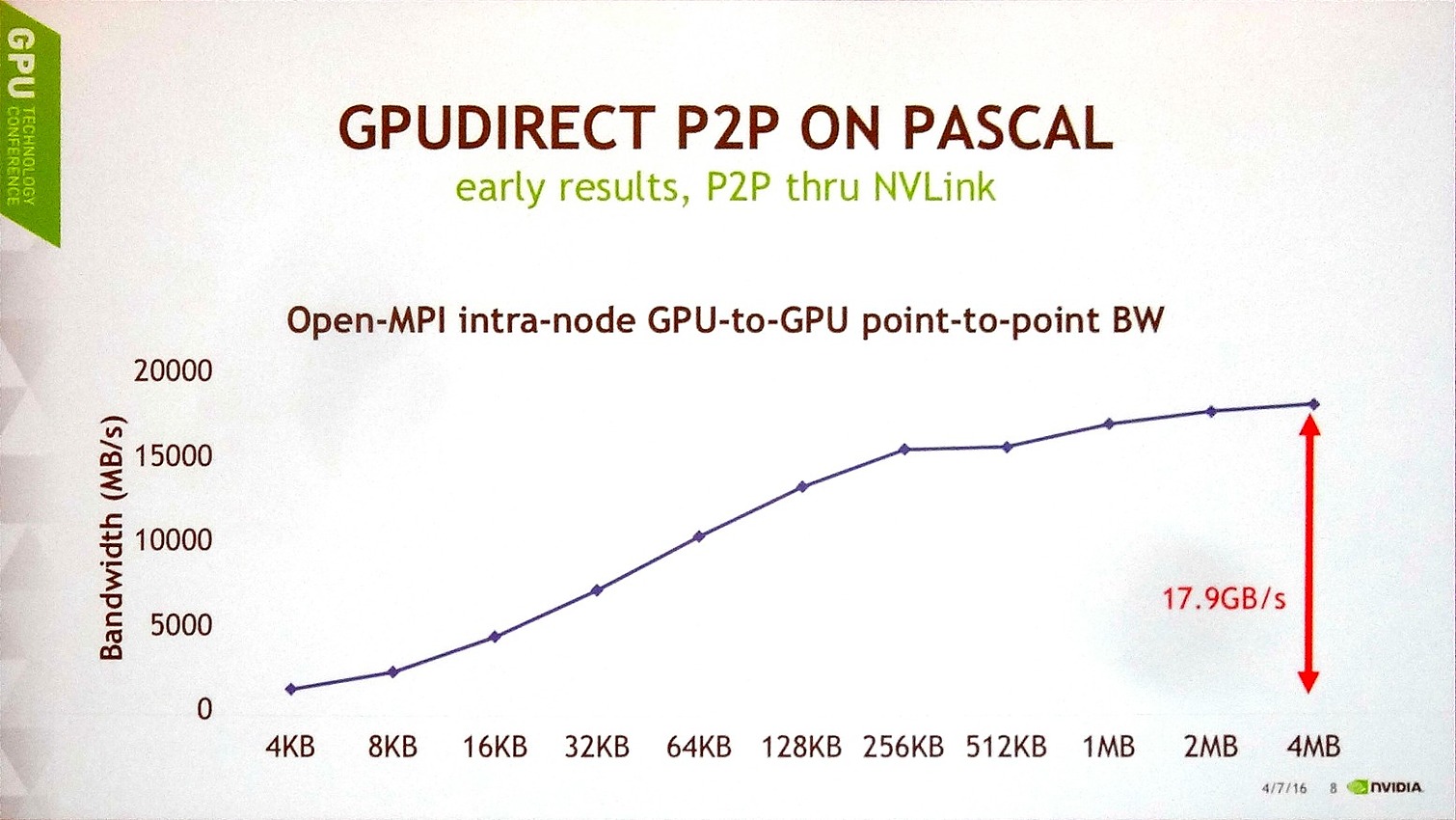
Ensuite, Nvidia a publié les premiers chiffres de débits obtenus pour les liens NVLink en communication point-à-point entre 2 GP100, tout en précisant que toutes les optimisations n'avaient pas encore été mises en place. Pour ce test, un seul lien NVLink est ici exploité et le transfert est unidirectionnel.
Avec des blocs de 4 Mo, le GP100 parvient à monter à 17.9 Go/s, ce qui est plutôt pas mal compte tenu du fait que l'interface est spécifiée à 20 Go/s dans chaque direction. Le débit reste supérieur à 15 Go/s avec des blocs de 256 Ko, mais plonge rapidement sous cette valeur, ce qui est un résultat attendu pour toute voie de communication compte tenu du surcoût par transfert. Ces premiers résultats sont donc plutôt encourageants et Nvidia explique qu'ils sont obtenus grâce à l'intégration de moteurs de copies pour chaque lien NVLink.
GTC: Nvidia DGX-1: 8 Tesla P100 pour 129.000$
Lors de la keynote d'ouverture de la GTC, Jen-Hsun Huang ne s'est pas contenté d'annoncer l'accélérateur Tesla P100, mais a également dévoilé un nouveau serveur qui sera commercialisé sous sa propre marque : le DGX-1. Orienté deep learning, ce supercalculateur embarque pas moins de 8 Tesla P100 pour un tarif de 129.000$ HTVA.

On n'est jamais aussi bien servi que par soi-même. C'est probablement ce qu'a dû se dire Nvidia pour accélérer la disponibilité du Tesla P100 sur un marché qui peut prendre du temps à bouger de lui-même, d'autant plus quand la compétition est rude et quand la plateforme change significativement. Après quelques expériences avec les serveurs GRID VCA (Visual Computing Appliance) et Quadro VCA, Nvidia propose ainsi un supercalculateur orienté vers le deep learning, un domaine en pleine explosion et pour lequel l'architecture Pascal a été optimisée.
Le DGX-1 est un serveur 3U capable d'atteindre 170 Tflops FP16, mode de calcul basse précision qui peut être exploité par les algorithmes de deep learning. Il atteint également 85 Tflops en FP32 et 42 Tflops en FP64 grâce à l'intégration de GPU Pascal. De quoi permettre à Nvidia de mettre en avant un gain de 75x au niveau de la vitesse d'entrainement d'un réseau de neurones artificiels par rapport à un serveur qui se conterait de CPU classiques.

Ce supercalculateur très dense embarque pas moins de 8 accélérateurs Tesla P100, chacun équipé de 16 Go de mémoire HBM2. Ceux-ci sont pilotés par 2 Xeon E5-2698 v3 (16 coeurs à 2.3 GHz), chacun associé à 256 Go de DDR4 2133. Nvidia a également opté pour un stockage plutôt costaud avec 4 SSD de 1.92 To en RAID 0. De quoi pouvoir prendre en charge de larges datasets. Si le DGX-1 est relativement compact au vu de la puissance de calcul qu'il embarque, il n'est par contre pas léger avec 60 kg sur la balance, ce qui s'explique en partie par l'alimentation et le refroidissement qui sont prévus pour encaisser 3200W, dont 2400W rien que pour les 8 Tesla P100.
Nvidia a bien entendu prévu le DGX-1 pour profiter pleinement de la connectique NVLink. Pour rappel, chaque GPU GP100 intègre 4 de ces liens qui offrent chacun une bande passante bidirectionnelle de 40 Go/s . Voici la topologie qui a été retenue et que Nvidia nomme NVLink Hybrid Cube Mesh :
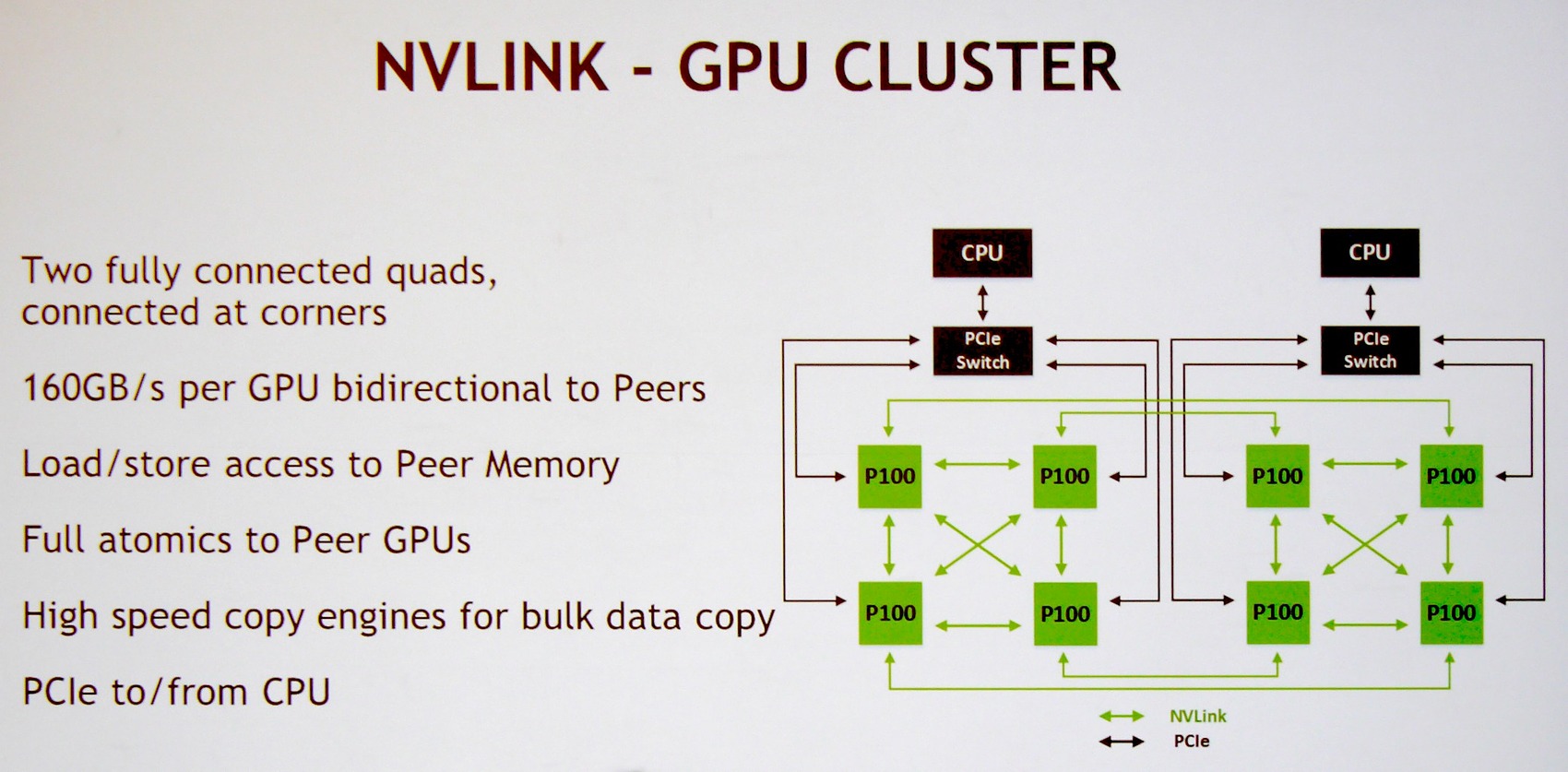
Assez logiquement 4 Tesla P100 sont reliés à chaque CPU via des liens PCI Express qui passent par un switch. Ensuite ces 4 GPU sont reliés entre eux via 3 de leurs liens NVLink. Enfin, leur quatrième lien est exploité pour les relier à l'un des GPU du second groupe de 4 Tesla P100. Il y aura donc quelques limitations au niveau de la communication entre ces 2 groupes de Tesla P100, mais elle est maintenue possible par cette topologie.
Nvidia annonce une disponibilité dès le mois de juin pour le DGX-1, ce qui semble très rapide, même si dans un premier temps cela ne concernera que les Etats-Unis. Il faudra en effet attendre le troisième trimestre pour une disponibilité plus globale.
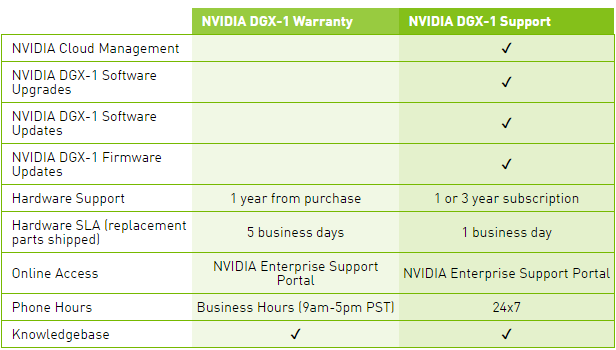
Le tarif communiqué par Nvidia monte à pas moins de 129.000$ HTVA, et ce pour le package basique, Warranty, qui n'inclus aucune mise à jour pour la suite logicielle, ce qui est étrange compte tenu de l'évolution très rapide et continuelle de ses outils dédiés au deep learning. Pour avoir accès à ces mises à jour, il faudra ajouter une cotisation annuelle pour passer au package Support.
Une politique tarifaire qui nous laissent penser que l'accélérateur Tesla P100 seul sera commercialisé à un prix très élevé. Nous ne serions pas étonnés de voir Nvidia atteindre la barre symbolique des 10.000$.
GTC: Nvidia Tesla P100: 10 Tflops, HBM2...
Comme prévu, Jen-Hsun Huang, le CEO de Nvidia, a levé un coin du voile concernant le premier produit Pascal, l'accélérateur Tesla P100. Au menu : 15 milliards de transistors, 10 Tflops, HBM2, 4 Mo de L2

Le Tesla P100 est un nouvel accélérateur dédié au calcul massivement parallèle qui embarque un GPU GP100, auquel nous faisions référence précédemment en tant que Pascal, nom de code de son architecture. Il s'agit bel et bien d'un nouveau monstre de puissance. Pour cette première utilisation de procédé de fabrication 16nm FinFET Plus, Nvidia n'a pas eu peur de concevoir un énorme GPU et le GP100 intègre pas moins de 15.3 milliards de transistors répartis sur 610 mm². A comparer aux 8 milliards de transistors de l'actuel GM200 qui mesure également 600 mm².
De quoi pouvoir pousser la puissance de calcul vers le haut mais surtout intégrer de nouvelles fonctionnalités avant tout dédiées au monde du HPC telles que la connectique NVLink qui offre une bande passante combinée de 160 Go/s.



Le Tesla P100 se présente sous la forme d'un module au format mezzanine qui revient à superposer 2 PCB, avec un ou plusieurs connecteurs entre ceux-ci. Sur le Tesla P100 il s'agit de 2 connecteurs de 400 broches qui vont permettre de proposer la connectique NVLink. Ce format facilite également l'intégration dans les serveurs et la mise en place d'un refroidissement performant ce qui permet à Nvidia de pousser le TDP à 300W.

Concernant la puissance brute du Tesla P100, Nvidia annonce 10.6 Tflops avec GPU Boost en FP32, la précision classique, un gain de 60% par rapport aux 6.6 Tflops de la Titan X. L'architecture Pascal dans cette implémentation supporte également la double précision en demi-vitesse, soit 5.3 Tflops, un nouveau bond en avant par rapport au record actuel : 2.6 Tflops pour le GPU Hawaii d'AMD des FirePro W9100 et S9170. Dans l'autre sens, Pascal supporte également la demi-précision, le FP16, et peut alors monter à 21.2 Tflops.
A quelle configuration de GPU pourrait correspondre tout cela ? Au départ, nous supposions que le nombre d'unités de calcul passerait de 3072 sur le GM200 à 4608 sur le P100, réparties dans 36 blocs d'unités de calcul (SMP ?), ce qui aurait permis assez facilement d'augmenter à peu près toutes les capacités brutes du GPU de 50%. Il n'en est cependant rien et les changements sont plus profonds au niveau de l'architecture. Il s'agit ainsi pour le Tesla P100 de 3584 unités de calcul réparties dans 56 blocs de 64, mais le GP100 continent physiquement 60 de ces blocs.
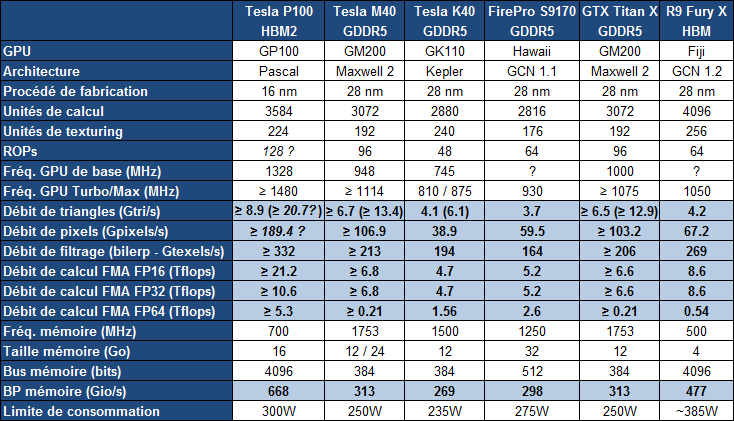
Le gain de puissance de calcul brute provient ainsi principalement d'une hausse de la fréquence du GPU (+/- 1.5 GHz) alors que le GPU computing devrait profiter de cette organisation en plus petits blocs d'unités de calcul, mais également des autres évolutions de l'architecture Pascal, pour gagner en efficacité.
Sur ce point, Nvidia se contente de parler d'une augmentation de la taille du fichier registre. Au total le GM200 embarque +/- 6 Mo de registres, ce qui correspond à 256 Ko par SMM ou encore à 512 registres 32-bit par unités de calcul. Le GP100 passe à 15 Mo de registres, ce qui implique une augmentation de 100%, soit 256 Ko par SMP ou encore 1024 registres 32-bit par unité de calcul. De quoi permettre de maintenir un meilleur taux d'occupation des unités de calcul, particulièrement en double précision.
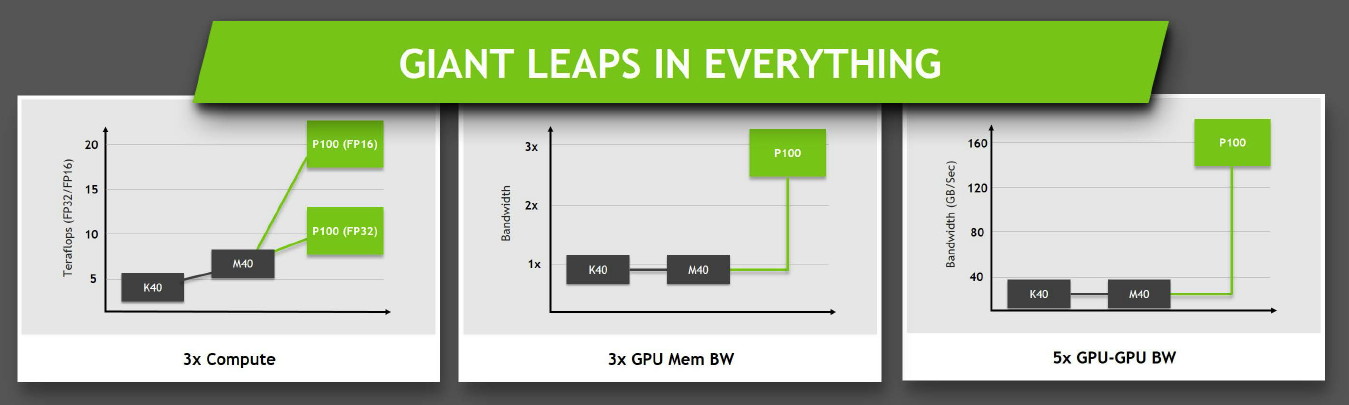
Le cache L2 passe de son côté de 3 à 4 Mo alors que l'interface mémoire est large de 4096-bit en HBM2. Nvidia annonce une bande passante de 720 Go/s pour les 16 Go de mémoire HBM2 CoWoS, le nom donné par TSMC à sa technologie 2.5D, similaire à celle employée par AMD pour son GPU Fiji.
Ce passage à la mémoire HBM2, associé à NVLink, à la puissance de calcul en hausse et au support de la précision FP16 permet au Tesla P100 d'afficher une progression conséquente sur différents plans par rapport à ses prédécesseurs.
Jen-Hsun Huang a terminé le chapitre consacré à Pascal en déclarant que la production en volume avait débuté et que son propre serveur basé sur le Tesla P100 serait commercialisé à partir du mois de juin. Il est probablement raisonnable de s'attendre à une nouvelle GeForce Titan d'ici là, mais sera-t-elle basée sur le GP100 ?
GTC: Deep-learning : +70% pour Pascal
Au détour d'une présentation consacrée à ses outils spécifiques au deep learning, soit à l'apprentissage progressif par un réseau de neurones artificiels, Nvidia a débuté le teasing concernant les performances de sa future architecture Pascal :
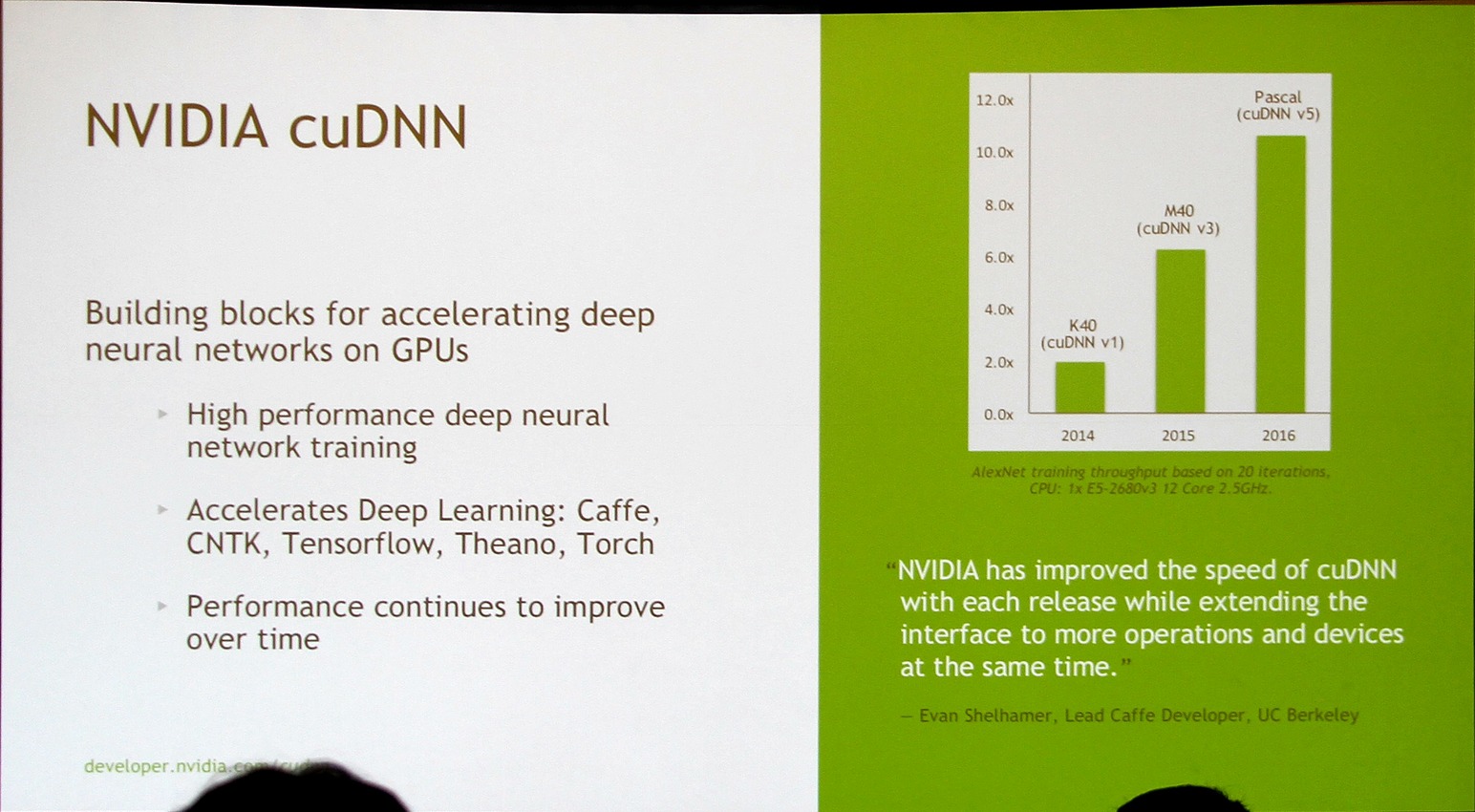
Nvidia fait évoluer régulièrement sa librairie cuDNN (CUDA Deep Neural Network) et en propose des évolutions majeures pour ses nouvelles architectures GPU. Ces évolutions vont d'ailleurs de pair pour booster les performances : cuDNN v1 avec une Tesla K40 (GK110) a doublé les performances par rapport aux précédentes solutions et cuDNN v3 avec une Tesla M40 (GM200) sous architecture Maxwell les a plus que triplées (6.25X).
Le deep learning étant l'une des priorités principales de Nvidia avec les performances en jeu, Pascal va bien entendu pousser la barre encore plus haut dans ce domaine. Il est ainsi question de 10.5X, soit +70% par rapport au GM200, pour un GPU Pascal indéterminé associé à cuDNN v5.
Difficile cependant de juger des performances globales de ce GPU Pascal sur base de ce seul chiffre puisqu'il reste bien entendu à savoir dans quelle proportion ces gains proviennent d'une augmentation de la puissance brute du GPU ou d'optimisations de l'architecture spécifiques au deep learning. Nous devrions en apprendre un peu plus dans le courant de la semaine.