
Les contenus liés au tag Pascal
Afficher sous forme de : Titre | FluxGTC: 200 mm² pour le petit GPU Pascal ?
GTC: Tesla P100: débits PCIe et NVLink mesurés
GTC: Nvidia DGX-1: 8 Tesla P100 pour 129.000$
GTC: Nvidia Tesla P100: 10 Tflops, HBM2...
GTC: Deep-learning : +70% pour Pascal
Les spécifications de la GeForce GTX 1070 (maj)
Dossier: Nvidia GeForce GTX 1080, le premier GPU 16nm en test !
Nvidia annonce les GeForce GTX 1080 et 1070
330mm² pour le GP104
GTC: Nvidia annonce CUDA 8, prêt pour Pascal
Tile rendering pour Maxwell et Pascal ?
Nouvelle Nvidia Titan X: GP102, 11 Tflops, 480 Go/s
Dossier: GeForce GTX 1070 8 Go et GTX 1060 6 Go : les cartes d'Asus et Gainward en test face aux Founders Edition de Nvidia
Nvidia annonce la GeForce GTX 1060 6 Go (maj)
GTX 1070: 3 GPC, juste devant la GTX 980 Ti
Les spécifications de la GeForce GTX 1070 (maj)



Mise à jour du 19/05 : correction de l'actualité suite à la confirmation des spécifications de l'interface mémoire de la GTX 1070.
Nvidia a mis en ligne les spécifications principales de la GeForce GTX 1070 alors que précédemment seule sa puissance de calcul avait été communiquée. Nous découvrons donc qu'elle sera équipée de 1920 unités de calcul, soit de 75% d'unités actives sur le GP104. Nvidia annonce par ailleurs une fréquence de base de 1506 MHz et turbo de 1683 MHz, ce qui indique bien que les hautes fréquences ne seront pas réservées à la GeForce GTX 1080. Enfin, la limite de consommation de 150W est confirmée. Rappelons que Nvidia annonce des performances supérieures à celles de la GTX Titan X et donc de la GTX 980 Ti, ce qui ne paraît pas insensé sur base de ces spécifications.

Ces spécifications basiques ne sont cependant pas suffisantes pour cerner précisément la GeForce GTX 1070. Deux grandes inconnues subsistent à l'heure actuelle.
Premièrement, Nvidia pourrait avoir désactivé une partie des ROP, du cache L2 et de son interface mémoire interne, comme pour la GeForce GTX 970. Cela réduirait la largeur effective du bus mémoire de 256-bit à 224-bit et seuls 7 des 8 Go de GDDR5 seraient accessibles à pleine vitesse. Certes vous nous direz que sur la page de spécifications de la GTX 1070 Nvidia mentionne une bande passante de 256 Go/s qui correspond bien à un bus mémoire de 256-bit. Rappelons cependant que sur ce point Nvidia ne communique pas la vraie spécifications sur la page de la GeForce GTX 970 , et mentionne une bande passante de 224 Go/s alors qu'elle est en pratique limitée à 196 Go/s (183 Gio/s). Le doute subsiste donc.
Une inconnue subsiste, nous ne pouvons pas savoir comment Nvidia désactive les 640 unités de calcul. Elles correspondent à 5 SM et il est donc possible que Nvidia désactive un GPC complet (avec un rasterizer) ou répartisse les SM désactivés dans les 4 GPC du GPU de manière à conserver les 4 rasterizers. Il est possible également qu'il y ait sur ce point de la variabilité entre les GTX 1070 commercialisées.
Si Nvidia réparti les SM désactivés, le fillrate pourra atteindre 60 pixels par cycle (4 par SM restants) contre 64 pour la GTX 1080 et le débit de triangles rendus restera de 4 par cycle, comme sur la GTX 1080. Et bien entendu, dans la même situation mais si le nombre de ROP était limité à 56, le fillrate serait lui aussi limité à 56 pixels par cycle.
Si par contre Nvidia désactive un GPC complet, le fillrate sera limité à 48 pixels par cycle (16 par GPC restants) et le débit de triangles rendus chutera à 3 par cycle.
Nous avons représenté dans le tableau de spécifications deux possibilités extrêmes par rapport à ces deux points qui restent en suspens, à savoir le nombre de ROP et leur impact ainsi que l'organisation de SM actifs et leur impact. Précisons que ces deux points ne sont pas liés et que les spécifications réelles pourront être intermédiaires :

Alors, la GeForce GTX 1070 sera-t-elle au top ?
Dossier : Nvidia GeForce GTX 1080, le premier GPU 16nm en test !
Nvidia ouvre le bal du 16/14 nm avec une GeForce GTX 1080 destinée à conserver sa domination sur le haut de gamme. Quels gains attendre de cette première puce de nouvelle génération ?
[+] Lire la suite

Nvidia annonce les GeForce GTX 1080 et 1070
C'est officiel, le futur haut de gamme de Nvidia sera la GeForce GTX 1080. Au menu des fréquences très élevées pour surpasser la GTX 980 Ti de +/- 20%. Sa petite soeur, la GeForce GTX 1070 sera lancée dans la foulée.

Au cours d'un évènement organisé à Austin, au Texas, Jen-Hsun Huang, le CEO de Nvidia, vient de lever un coin du voile sur sa future carte graphique haut de gamme, la GeForce GTX 1080. Première déclinaison grand public basée sur l'architecture Pascal et le 16nm FinFET de TSMC, elle est annoncée comme plus performante qu'un SLI de GeForce GTX 980 ou encore qu'une GTX Titan X.
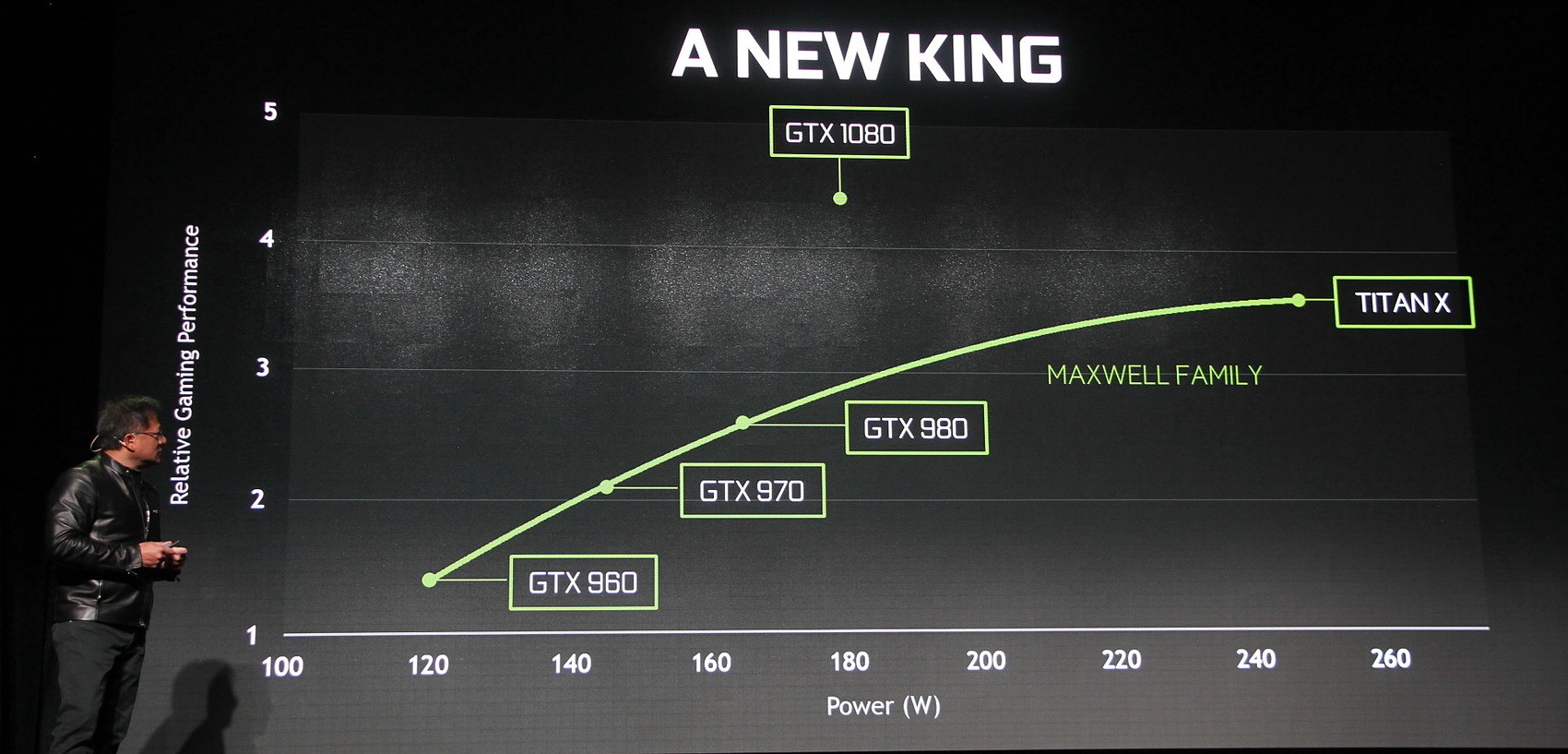
Sans annoncer de résultats clairs et concrets pour ses performances, ils viendront plus tard, Nvidia expose sur un graphique ses performances approximatives et sa consommation. Nous pouvons y découvrir des performances plus que doublées par rapport à une GTX 970 ou encore un gain de près de 20% par rapport à une GTX Titan X ou par rapport à une GTX 980 Ti. Un niveau qui est atteint avec une consommation de 180W à comparer aux 160W d'une GTX 980 et aux 250W des GTX Titan X et 980 Ti.


Pour atteindre ces performances, les fréquences de ce GPU de 7.2 milliards de transistors font un bond énorme. Pour cette GTX 1080, Nvidia annonce une puissance de calcul de 9 Tflops avec un GPU équipé de 2560 unités de calcul FP32, ce qui pointe vers une fréquence GPU Boost par défaut de 1750 MHz. La mémoire GDDR5X de 8 Go est de son côté cadencée à 2.5 GHz. Avec overclocking en air cooling, Nvidia parle de plus de 2.1 GHz pour le GPU et de 2.75 GHz pour la mémoire.
Pour la GeForce GTX 1070 il est question de 6.5 TFlops mais aucune information n'est communiquée sur le nombre d'unités de calcul actives. Nvidia se contente d'indiquer qu'elle sera plus performante qu'une GTX Titan X.
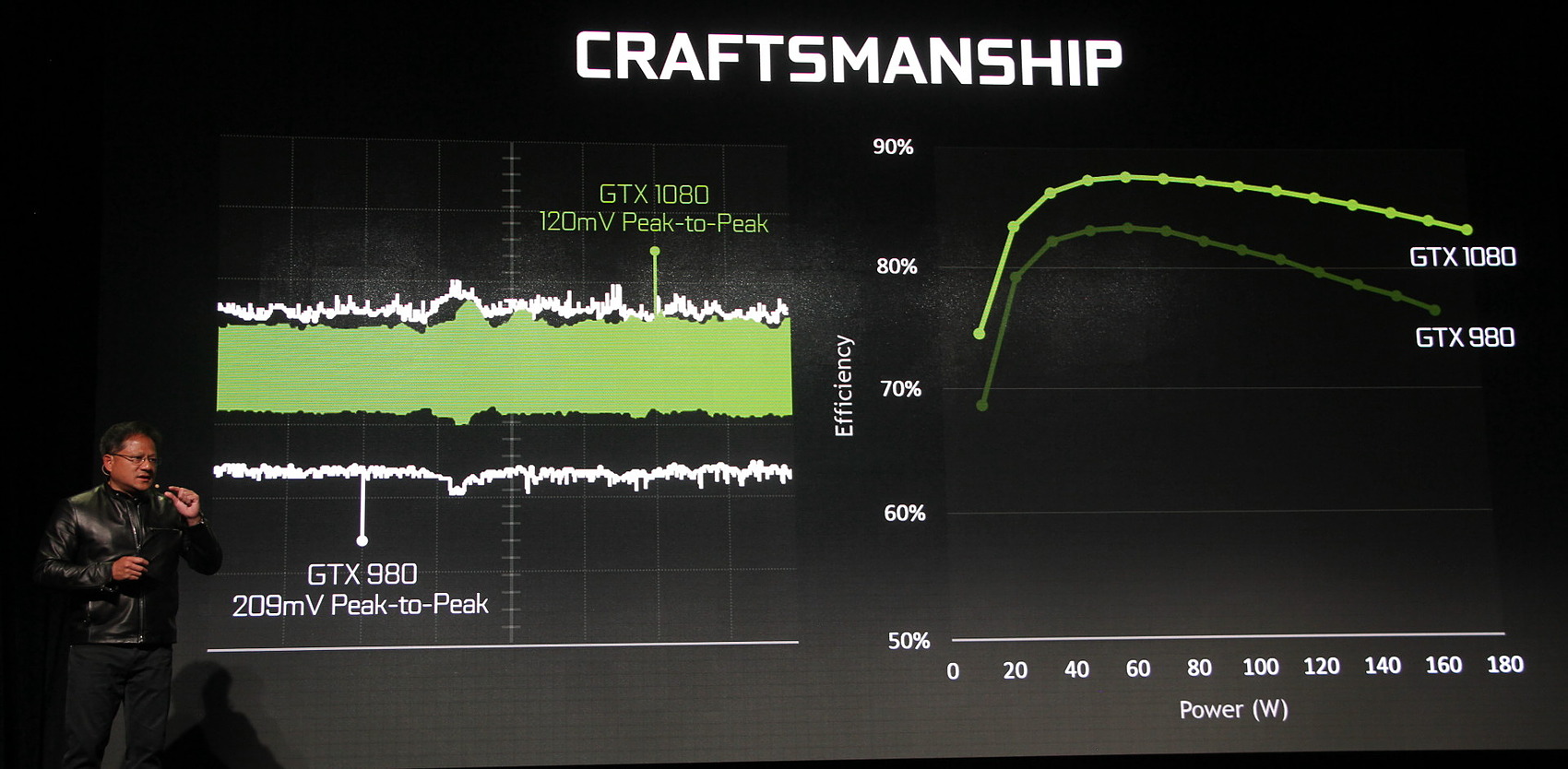
Seul point technique abordé : l'alimentation du GPU. Celle-ci aurait été particulièrement travaillée au niveau du GPU et de son étage d'alimentation pour stabiliser et maximiser le rendement de celui-ci. De quoi permettre de meilleures performances à TDP donné.
La GeForce GTX 1080 sera commercialisée à partir du 27 mai au tarif de 599$ soit à peu près 650 pour les cartes partenaires. Du côté de la GeForce GTX 1070, il faudra patienter jusqu'au 10 juin mais elle sera plus abordable avec un ticket d'entrée à 379$, soit à peu près 420, encore une fois pour les cartes partenaires.
Si nous insistons sur ce point c'est parce que Nvidia a décidé de revoir à la hausse le tarif du design de référence, qualifié de "Founders Edition". Proche des designs actuels mais avec un aspect plus angulaire, il est annoncé encore plus efficace. Il faudra par contre compter 699$ et 449$ pour les GTX 1080 et 1070 habillées de la sorte.
330mm² pour le GP104
Si nous avions entrevu lors de la GTC le GP106, un petit GPU de 200mm² environ, Nvidia prépare également un GP104 un peu plus gros. Un forumeur en avait déjà posté une photo sur Chiphell il y'a une dizaine de jours, alors accompagné de GDDR5 8 Gbps, il a de nouveau fait son apparition sur ce même forum .


Les clichés permettent d'estimer une taille de l'ordre de 330mm², à comparer aux 398mm² d'un GM204 (GTX 970/980). De quoi embarquer avec le doublement de la densité permis par le 16nm TSMC aux alentours de 8,5 milliards de transistors, le GM200 (GTX 980 Ti/Titan X) en embarquant pour rappel 8 milliards dans 601mm².
On notera sur la photo que la puce est très récente puisque le marquage fait état d'une production début avril. L'auteur de la fuite précise que le bus mémoire est 256-bit et que 8 Go équiperont les cartes, respectivement avec de la GDDR5X pour la GTX 1080 et de la GDDR5 pour la GTX 1070. Wait & See !
GTC: Nvidia annonce CUDA 8, prêt pour Pascal
Comme souvent, l'arrivée d'une nouvelle architecture est associée à une révision majeure de CUDA, l'environnement logiciel de Nvidia destiné au calcul massivement parallèle. Ce sera évidemment le cas pour les GPU Pascal qui pourront profiter dès cet été d'un CUDA 8 taillé sur mesure. Au menu : un support plus évolué de la mémoire unifiée, un profilage plus efficace et un compilateur plus rapide.

La principale nouveauté de CUDA 8 sera le support complet de l'architecture Pascal et particulièrement du GP100 qui équipe l'accélérateur Tesla P100. Déjà introduit avec CUDA 7.5 pour permettre aux développeurs de s'y préparer, le support de la demi-précision (FP16) sera finalisé et pourra permettre des gains conséquents pour les algorithmes qui peuvent s'en contenter. Dans le cas du GP100, CUDA 8 ajoutera évidemment le pilotage des accès mémoire à travers les liens NVLink.
La plus grosse évolution est cependant à chercher du côté de la mémoire unifiée qui va faire un bond en avant avec Pascal, ou tout du moins avec le GP100 puisque nous ne sommes pas certains que les autres GPU Pascal en proposeront un même niveau de support. Si vous avez l'impression qu'on vous a annoncé le support de cette mémoire unifiée avec chaque nouveau GPU, ne vous inquiétez pas, vous n'avez pas rêvé, nous avons la même impression.
Elle est en fait supportée depuis CUDA 6 pour les GPU Kepler et Maxwell mais de façon limitée, que nous pourrions qualifier d'émulée. Pour ces GPU, l'espace de mémoire unifié est en fait dédoublé dans la mémoire centrale et dans la mémoire physiquement associée au GPU. L'ensemble logiciel CUDA se charge de piloter et de synchroniser ces deux espaces mémoires pour qu'ils n'en représentent qu'un seul du point de vue du développeur. De quoi faciliter sa tâche mais au prix de sérieuses limitations : la zone de mémoire unifiée ne peut dépasser la quantité de mémoire rattachée au GPU, le CPU et le GPU ne peuvent y accéder simultanément et de nombreuses synchronisations systématiques sont nécessaires pour forcer la cohérence entre les copies CPU et GPU de cette mémoire.
Pour proposer un support plus avancé de la mémoire unifiée, des modifications matérielles étaient nécessaires au niveau du GPU, ce qui explique pourquoi nous estimons possible que cela soit spécifique au GP100. Tout d'abord l'extension de l'espace mémoire adressable à 49-bit pour permettre de couvrir l'espace de 48-bit des CPU ainsi que la mémoire propre à chaque GPU du système. Ensuite la prise en charge des erreurs de page qui permet d'éviter les coûteuses synchronisations systématiques. Si un kernel essaye d'accéder à une page qui ne réside pas dans la mémoire physique du GPU, il va produire une erreur qui va permettre suivant les cas soit de rapatrier localement la page en question, soit d'y accéder directement à travers le bus PCI Express ou un lien NVLink.
La cohérence peut ainsi être garantie automatiquement, ce qui permet aux CPU et aux GPU d'accéder simultanément à la zone de mémoire unifiée. Sur certaines plateformes, la mémoire allouée par l'allocateur de l'OS sera par défaut de la mémoire unifiée, et il ne sera plus nécessaire d'allouer une zone mémoire spécifique. Nvidia indique travailler à l'intégration de ce support avec Red Hat et la communauté Linux. Par ailleurs, CUDA 8 étend également le support de la mémoire unifiée à Mac OS X.

Ce support plus avancé de la mémoire unifiée va faciliter le travail des développeurs et surtout rendre plus abordable leurs premiers pas sur les GPU tout en maintenant un relativement bon niveau de performances. Tout du moins si le pilote et le runtime CUDA font leur travail correctement puisque c'est à ce niveau que tout va se jouer. A noter que les développeurs plus expérimentés conservent la possibilité de gérer explicitement la mémoire.
Parmi les autres nouveautés, Nvidia introduit une première version de la librairie nvGRAPH (limitée au mono GPU) qui fournit des routines destinées à accélérer certains algorithmes spécifiques au traitement des graphes. Traiter rapidement les opérations sur ces structures mathématique prend de plus en plus d'importance, que ce soit pour les moteurs de recherche, la publicité ciblée, l'analyse des réseaux ou encore la génomique. Faciliter l'exécution de ces opérations sur le GPU est donc important pour leur ouvrir la porte à de nouveaux marchés potentiels.
Une autre évolution importante est à chercher du côté des outils de profilages qui vont dorénavant fournir une analyse des dépendances. De quoi par exemple permettre de mieux détecter que les performances sont limitées par un kernel qui bloque le CPU trop longtemps. Ces outils revus prennent également en compte NVLink et la bande passante utilisée à ce niveau.
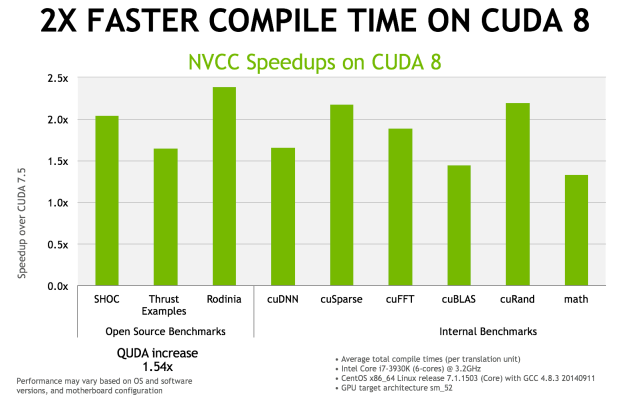
Enfin, le compilateur NVCC 8.0 a reçu de nombreuses optimisations pour réduire le temps de compilation. Nvidia annonce qu'il serait réduit de moitié, voire plus, dans de nombreux cas. Ce compilateur étend également le support expérimental des expressions lambda de C++11.
La sortie de CUDA 8.0 est prévue pour le mois d'août mais une release candidate devrait être proposée dès le mois de juin.