| |
| |
| Nvidia GeForce GTX 1080, le premier GPU 16nm en test ! Cartes Graphiques Publié le Mardi 24 Mai 2016 par Damien Triolet URL: /articles/948-1/nvidia-geforce-gtx-1080-premier-gpu-16nm-test.html Page 1 - Introduction  Après plus de 4 ans de bons et loyaux services auprès de nos GPU, le procédé de fabrication 28 nm de TSMC va progressivement tirer sa révérence pour laisser place à son propre 16 nm FinFET ainsi qu'au 14 nm de Samsung et GlobalFoundries, pour le plus grand bonheur des joueurs. Ce bond technologique va permettre à AMD et Nvidia de proposer des cartes graphiques plus intéressantes que ce soit en termes de fonctionnalités, de performances et / ou de rendement énergétique. Si AMD a communiqué le premier sur ses GPU Polaris fabriqués en 14 nm, c'est Nvidia qui débarque le premier sur le marché avec un GPU de la génération Pascal dédié aux joueurs : le GP104. En plus d'introduire le 16 nm de TSMC, il inaugure également l'utilisation de la mémoire GDDR5X qui permet de pousser la bande passante vers le haut sans faire exploser la consommation des modules. Ce GP104 s'inscrit directement dans la lignée des précédents GM204 et GK104 dans le sens où il ne s'agit pas encore du plus gros GPU que Nvidia proposera sur cette génération. Il arrivera plus tard, probablement l'an prochain. En attendant, cela ne va pas empêcher ce relativement petit GP104 de facilement prendre les devants face aux précédents ténors que sont les GeForce GTX 980 Ti et GTX Titan X. La première carte graphique à l'embarquer est donc un modèle très haut de gamme, positionné comme tel par Nvidia. Même si cela fera une nouvelle fois grincer quelques dents, ce positionnement est logique, d'autant plus qu'à ce niveau de performances la concurrence est inexistante. La GeForce GTX 1080 est annoncée à un tarif débutant à 599$ (670) alors que le modèle de référence que nous allons vous présenter, et qui sera le premier disponible à partir du 27 mai, se négociera à partir de 699$, soit 790 TTC en tarif officiel en Europe ! Pour rappel voici les tarifs de lancements des GeForce GTX x80 depuis 10 ans :
Mais à ce tarif, que vous propose exactement Nvidia ? Pour l'introduction de sa nouvelle architecture Pascal auprès des joueurs, Nvidia reprend la même approche que lors du lancement de la génération Maxwell. Le premier GPU à intégrer la famille GeForce est ainsi une puce de taille moyenne : le GP104. Après le GP100 dédié aux accélérateurs Tesla, il s'agit de la seconde puce Nvidia produite par TSMC sur le procédé de fabrication 16 nm FinFET Plus. (FF+). Après plus de 4 ans de GPU fabriqués en 28 nm chez le même TSMC, le passage au 16 nm FF+ représente une évolution significative qui permet de nouveaux compromis plus avantageux en termes de consommation énergétique, de performances et de fonctionnalités. Les choix de Nvidia pour ce GP104 peuvent se résumer en deux points : hautes fréquences et optimisations orientées vers la réalité virtuelle.  Le GP104 et sa mémoire GDDR5X.
Le GP104 et sa mémoire GDDR5X.Avant de rentrer dans les détails de son architecture, un petit rappel s'impose pour situer le GP104 parmi les GPU récents :
La taille maximale que les outils de productions actuels autorisent tourne autour des 600 mm², raison pour laquelle elle correspond aux plus gros GPU tels que le GP100. Avec 314 mm², le GP104 est donc bien un GPU de taille moyenne qui s'inscrit directement dans la lignée des GK104 (GTX 680) et GM204 (GTX 980). Comme nous allons le voir, un GPU de ce calibre en 16 nm exploite la même enveloppe thermique que le GM204 (180 W), ce qui laisse de la place pour un plus gros GPU basé sur les mêmes technologies mais destiné à une enveloppe thermique de 250W des GeForce GTX x80 Ti ou GTX Titan. Ce sera à priori un GPU différent du GP100, peut-être un futur GP102. Le passage au 16 nm permet évidemment de faire exploser la densité de transistors par rapport au 28 nm. Il ne faut cependant pas se fier à ces chiffres qui sont plus des noms commerciaux des procédés de fabrication que des mesures de la géométrie qui définissent leur densité. Ainsi, contrairement à ce qui a pu être vrai par le passé, le 16 nm ne permet pas de tripler le nombre de transistors par mm² par rapport au 28 nm. Ces technologies sont très complexes et la densité réelle est déterminée par de nombreux paramètres qui dépassent le cadre de cet article. Voici les densités relevées sur les GPU Nvidia les plus récents :
La densité est un petit peu plus élevée sur les plus gros GPU, probablement parce qu'une partie des E/S (entrées/sorties, I/O) à faible densité est identique et représente moins d'espace en proportion alors qu'à l'inverse ils intègrent en général plus de mémoire qui représente des structures plus denses. Entre le GP104 et le GM204, la densité progresse d'environ 75%. Mais cela ne veut pas dire que le GP104 embarque 75% de transistors en plus. Probablement en partie pour faire face aux coûts de production par wafer, et donc par mm², qui sont en hausse sur le 16 nm, Nvidia n'exploite à peu près que la moitié de ce gain potentiel de transistors et se contente d'une puce 20% plus petite. GP104 : SM, Pascal G et Pascal TPour comprendre l'architecture du GP104, quelques rappels s'imposent concernant la manière dont Nvidia schématise l'organisation interne de ses GPU. A un niveau élevé, ils se composent de un ou plusieurs GPC (Graphics Processing Cluster). Chacun contient un rasterizer chargé de projeter les primitives et de le découper en pixels. A l'intérieur de ces GPC, nous retrouvons un ou plusieurs TPC (Texture Processor Cluster). Ne vous fiez pas à ce nom, vestige de précédentes architectures, le TPC est aujourd'hui décrit comme la structure qui représente le Polymorph Engine, nom donné à l'ensemble des petites unités fixes dédiées au traitement de la géométrie (chargement des vertices, tessellation etc.). Enfin, au plus bas niveau, ces TPC intègrent un ou plusieurs SM (Streaming Multiprocessor) qui représentent le coeur de l'architecture. C'est à leur niveau que prennent place les unités de calcul, les unités de texturing, les registres ou encore la mémoire partagée utile au GPU computing. A noter que pour les GPU Kepler et Maxwell, Nvidia a mis de côté le TPC pour simplifier leur représentation schématique. Un seul SM est présent par TPC pour l'ensemble de ces GPU, il n'y avait donc pas de raison de faire une distinction entre ces deux structures. A l'intérieur d'un SM Maxwell ou Pascal, nous retrouvons une mémoire partagée (contrôlée par le développeur) et plusieurs partitions organisées en paires. Chaque partition contient entre autres sa propre logique d'ordonnancement, ses registres, une unité 32-bit vectorielle 32-way pour les instructions simples (qui représente 32 cores en termes marketing) et une unité SFU vectorielle 8-way pour certaines instructions complexes. Chaque paire de partitions partage 4 unités de texturing et un cache L1 de 24 Ko. Pour représenter les différents SM, nous avons modifié des diagrammes de Nvidia de façon à nous rapprocher de la réalité, au mieux de nos connaissances actuelles des différentes architectures : 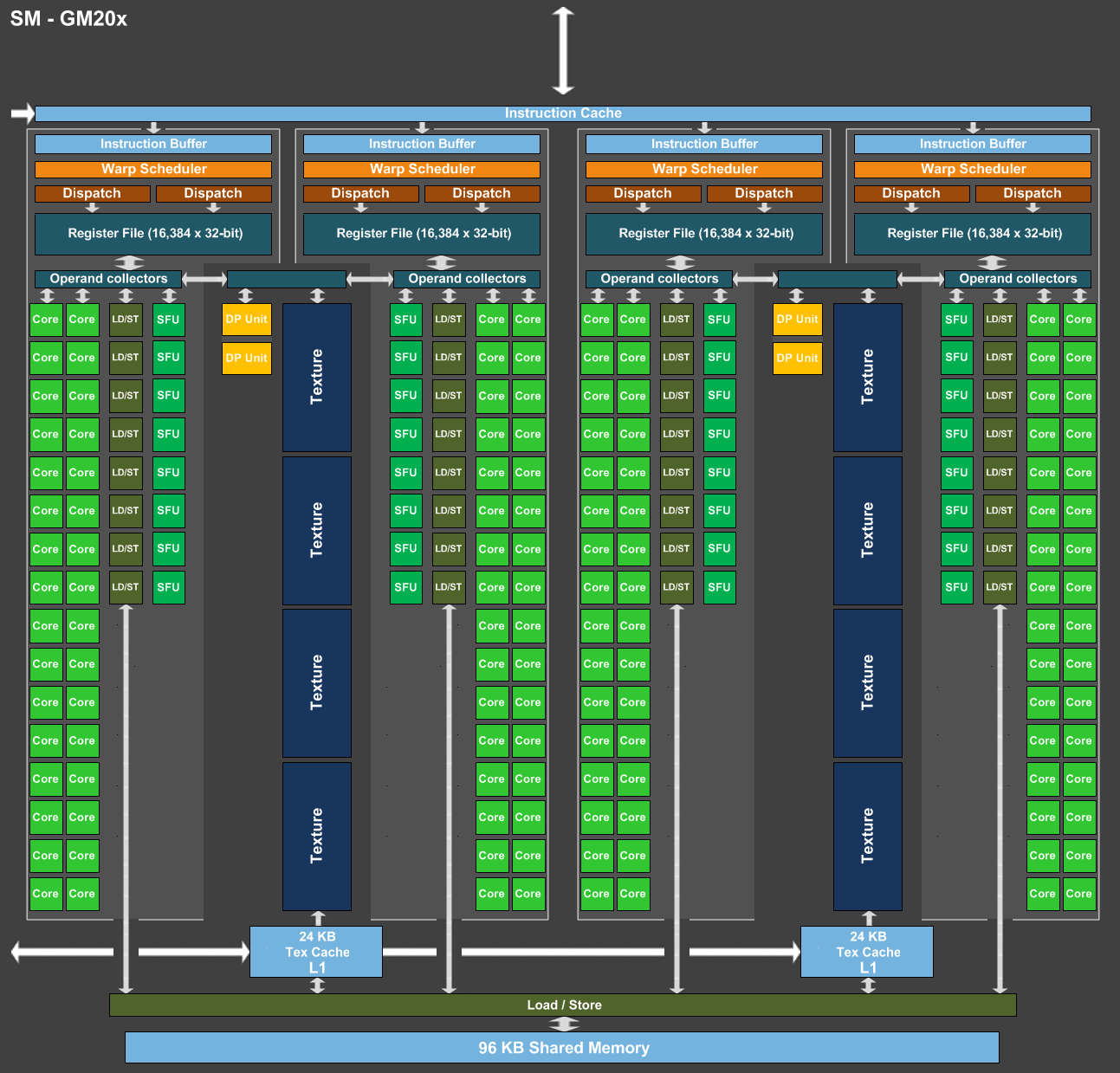 [ SM - GM20x ] [ SM - GP104 ] [ SM - GP100 ] Comment se compare le SM de Pascal au SM de Maxwell ? Une question à laquelle il est à la fois simple et complexe de répondre puisque nous avons en fait affaire à 2 architectures Pascal différentes que nous qualifierons, en l'absence de mieux, de Pascal G comme GeForce dans le cas du GP104 et de Pascal T comme Tesla dans le cas du GP100. Pour Pascal G, c'est simple, le SM est fonctionnellement identique à celui des GPU Maxwell 2 (GM20x). Lorsque Nvidia a dévoilé l'architecture Pascal et le GP100, nous avons par contre pu découvrir une refonte importante du SM : il voit sa taille divisée par deux mais gagne de nombreuses unités de calcul en double précision (FP64) et profite de fichiers registres deux fois plus importants (128 Ko au lieu de 64 Ko par partition). La mémoire partagée des SM du GP100 passe de 96 à 64 Ko mais elle n'est associée qu'à deux partitions au lieu de 4 ce qui indique en réalité une augmentation relative de 33%. Ces représentations des architectures sont avant tout des vues d'esprit conçues par le département de marketing technique. Ainsi il est probablement correct de voir les choses sous un angle plus simple et d'imaginer un SM doté de 4 partitions pour Pascal T mais avec une mémoire partagée étendue à 128 Ko et une bande passante doublée. Il devait cependant être tentant de privilégier une communication technique sur 60 (petits) SM plutôt que sur 30 (gros) SM pour mettre en avant le GP100 dans le monde du GPU computing. Quoi qu'il en soit, Pascal T et Pascal G diffèrent sur plusieurs points. Tout d'abord, la puissance de calcul en double précision correspond à la moitié de la simple précision sur la première alors qu'elle chute à un débit de 1/32ème sur la seconde. Ensuite la quantité de mémoire disponible par partition est doublée sur Pascal T, ce qui permet de maintenir une bonne occupation des unités de calcul lorsque des programmes complexes sont exécutés (et qui ont par exemple besoin de beaucoup de registres). Deux points peu importants dans le cadre du jeu vidéo et qui justifient donc cette différence au niveau des architectures du GP100 et du GP104. Enfin, il y a au niveau des SM une troisième différenciation importante que nous n'avons pas encore abordée : le calcul en demi-précision ou FP16. Les unités de calcul 32-bit de Pascal T supportent un ensemble d'instructions supplémentaires qui au lieu d'une opération 32-bit regroupent 2 opérations de type FP16. De quoi potentiellement doubler la puissance de calcul pour les algorithmes qui peuvent se contenter d'une précision limitée (c'est le cas du deep learning) et quand le compilateur parvient à profiter pleinement de ce type d'instructions. Certains ont pu penser que cela implique un support généralisé de la demi-précision pour les GPU Pascal, pour booster les performances et/ou réduire l'empreinte énergétique. C'est un compromis que font certains GPU mobiles, y compris les Tegra de Nvidia, mais il n'en est rien ici. Le support du FP16 pour Pascal T est spécifique au GPU computing et par conséquent n'est pas présent sur Pascal G. GP104 : quelques unités de plus et un bond en fréquenceAprès avoir passé en revue le coeur de l'architecture Pascal G, il est temps de se pencher sur le GP104 dans son ensemble. Voici le traditionnel schéma communiqué par Nvidia : 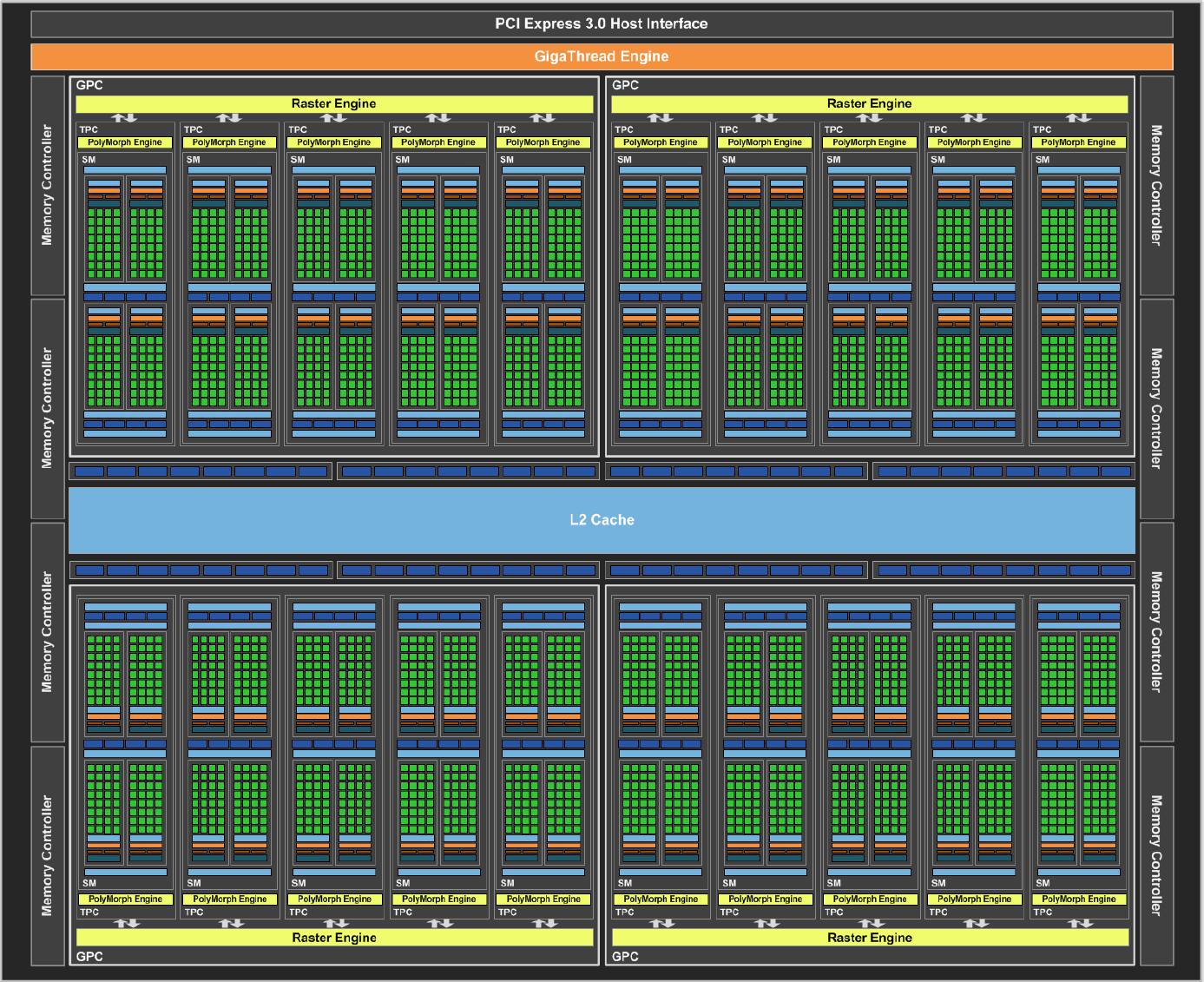 Nous pouvons y observer 4 GPC contenant chacun 5 SM. Une organisation interne proche de celle du GM204, lui aussi équipé de 4 GPC mais qui se contentent de 4 SM. Chaque SM de ces GPU intègre 128 unités de calcul 32-bit (les "cores"), ce qui nous en donne un total de 2560 pour le GP104 contre 2048 pour le GM204, une progression de 25%. Les unités de texturing, 8 par SM, progressent dans la même proportion. Pour le reste nous retrouvons un même cache L2 de 2 Mo ainsi qu'un même ensemble de 64 ROP associés à un bus mémoire de 256-bit réparti sur 8 contrôleurs 32-bit. Voici pour comparaisons les spécificités de quelques GPU :
25% d'unités de calcul et de texturing en plus, aucune augmentation du nombre de ROP ou de la largeur de l'interface mémoire Vu comme ça le GP104 et cette première exploitation du 16 nm n'impressionne pas réellement. C'est cependant sans compter sur un point crucial : les fréquences ! 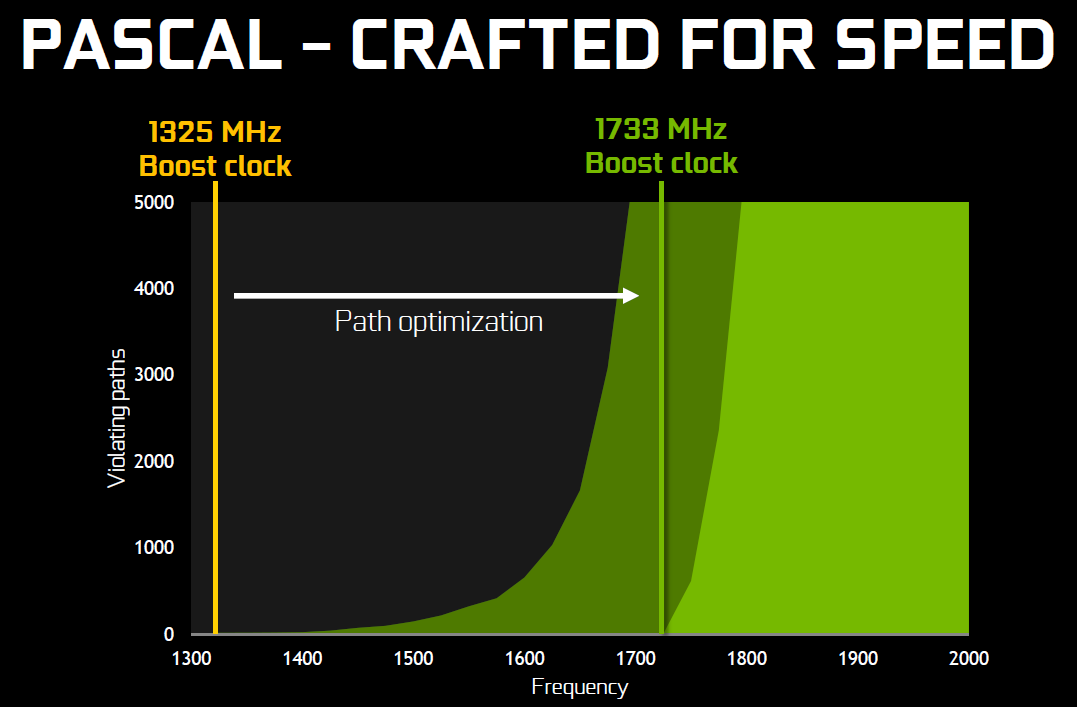 Nvidia nous avait indiqué ne pas avoir travaillé particulièrement les fréquences du GP100, qui profite simplement des gains automatiques liés au 16 nm, mais il en va tout autrement pour le GP104. Nvidia explique avoir passé en revue le moindre circuit du GPU pour retravailler tout point faible qui entravait la montée en fréquence. De quoi pouvoir proposer une fréquence turbo de référence de 1733 MHz sur la GTX 1080 soit un bond énorme de 40% par rapport aux 1216 MHz du GM204 qui équipe la GTX 980. Et cela tout en laissant une marge d'overclocking similaire puisqu'il est aisé d'atteindre plus de 2 GHz avec le GP104 ! Si nous combinons les +25% d'unités de calcul et les +40% en fréquence, cela nous donne cette fois une progression bien plus intéressante de la puissance brute par rapport au GM204 : +75%. Reste un bus mémoire limité à 256-bit, mais là aussi Nvidia pousse la fréquence en retravaillant les circuits de ses interfaces et en ayant recours à un nouveau type de mémoire : la GDDR5X.  Alors que la GDDR5 plafonne à 8 Gbps, la GDDR5X est prévue pour évoluer progressivement de 10 à 16 Gbps. Pour atteindre un tel débit la GDDR5X supporte un nouveau mode de transfert des données de type QDR permettant de doubler à fréquence égale le débit avec en contrepartie un prefetch et des accès qui sont également doublés à 16n et 512 bits. Deux points qui ne sont pas de réels problèmes pour les GPU alors qu'ils peuvent profiter d'un bus plus rapide avec une fréquence réduite pour les cellules mémoires, ce qui est bénéfique sur le plan de la consommation. Sur la GTX 980, le GM204 est associé à de la GDDR5 7 Gbps, mais sur la GTX 1080, le GP104 profite des premiers modules GDDR5X 10 Gbps, un gain de 42%. Et ce n'est pas tout, le passage au 16 nm permet à Nvidia de complexifier son système de compression sans perte du framebuffer. Plus spécifiquement, c'est le codage différentiel pour les couleurs, également appelé compression delta, qui progresse à nouveau. Pour rappel, son principe de base consiste à ne pas enregistrer directement la couleur mais sa différence par rapport à une autre qui fait office de repère. Ce n'est bien entendu utile que quand l'écart entre deux couleurs est suffisamment faible, de manière à ce que cette information représente moins de bits que la couleur en elle-même.  Pascal améliore tout d'abord la compression 2:1, dans le sens où elle s'enclenche dans plus de cas. Ensuite, un nouveau mode de compression 4:1 fait son apparition et est exploité quand le différentiel de couleur est très faible. Enfin, un mode 8:1 permet de combiner la compression classique des blocs de 2x2 pixels de couleur identique avec la compression delta 2:1. 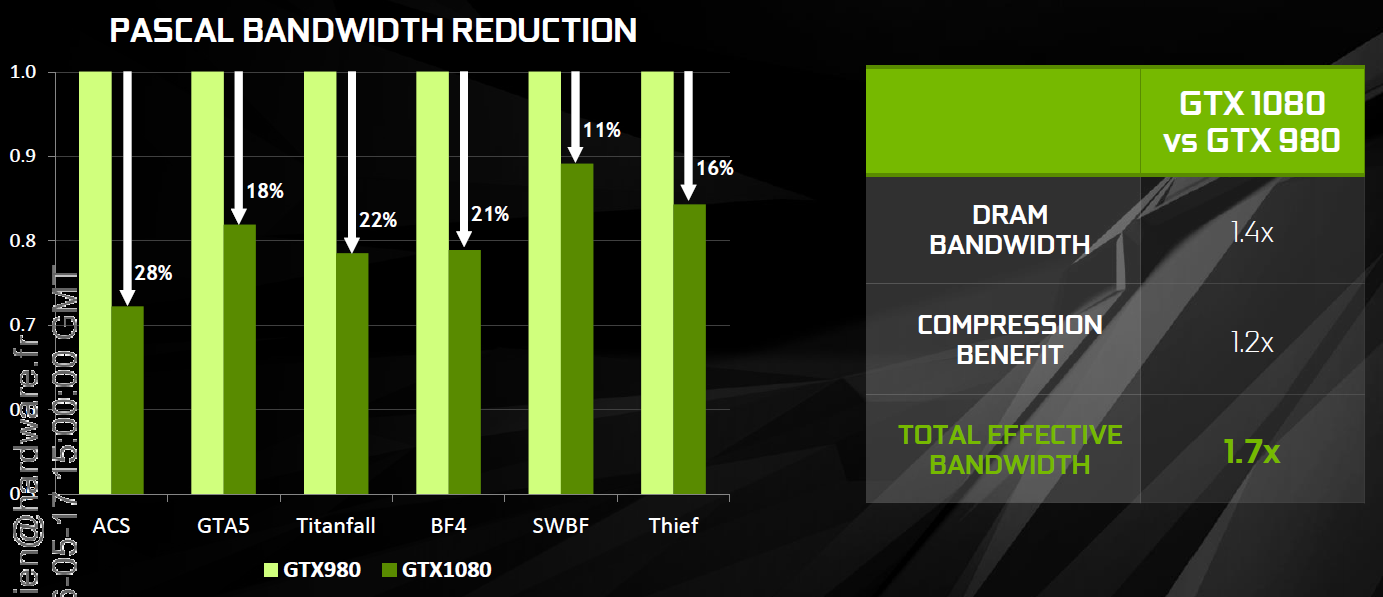 Les outils de Nvidia mettent en avant une réduction significative de la bande passante mémoire nécessaire par image par rapport aux GPU Maxwell, ce qui transformerait ces optimisations en augmentation de 20% de la bande passante effective. Couplée à la GDDR5X 10 Gbps, le GP104 de la GTX 1080 profiterait ainsi d'une progression totale de sa bande passante effective de 70%, ce qui permet de maintenir l'équilibre par rapport à sa puissance de calcul. Pour démontrer que sa technologie a réellement un impact en jeu, Nvidia fourni des screenshots de Project Cars sur lesquels les zones compressées sont représentées en fushia :  [ Sans compression ] [ Sur GPU Maxwell ] [ Sur GPU Pascal ] A noter que cette amélioration de la compression sans perte permet également de retenir plus de données dans le cache L2 et de réduire la taille de certains transferts entre ce dernier et les SM, ce qui peut profiter aux performances. Nous vous en avons déjà parlé à plusieurs reprises, notamment ici, DirectX 12 ou encore Vulkan supportent plusieurs files de commandes, ce qui ouvre la voie à plusieurs types d'optimisations. A la base de leur moteur, les développeurs créent des Command Queues qui sont des files d'attente dans lesquelles vont prendre place des listes de commandes de rendu qui, sur les API classiques, seront exécutées séquentiellement par le GPU pour créer la représentation 3D de la scène. La 10ème liste de commandes à y prendre place devra toujours attendra que les 9 autres aient été exécutées par le GPU avant d'être traitée. Mais avec les API récentes et leur support du Multi Engine, il est possible d'exploiter plusieurs Command Queues de types graphics, compute ou copy, ce qui permet par exemple de faire traiter certaines tâches en priorité mais aussi en parallèle. Sur ce point Microsoft et Khronos ont repris exactement la structure qu'AMD avait mise en place avec son API Mantle. Une victoire pour AMD qui a dessiné le Multi Engine en suivant les contours de l'architecture de ses GPU. Son service de marketing technique en a profité pour communiquer énormément sur le sujet en mettant en avant des gains de performances sous la bannière Async Compute ou calcul asynchrone.  Illustration du Multi Engine de DirectX 12. Dans cet exemple extrême les performances progressent de 50%. Pourquoi un gain de performances ? Imaginez que deux commandes de rendu saturent les unités de calcul, il n'y a aucun intérêt à essayer de les traiter en parallèle par rapport à une exécution en série classique. Par contre si une partie du rendu sature les unités de calcul alors qu'une autre sature l'interface mémoire, l'intérêt de l'exécution concomitante est évident et le gain de performances peut être substantiel. C'est à cette sous-possibilité du Multi Engine qu'AMD fait référence en parlant de l'Async Compute. Une terminologie que nous estimons cependant très mal choisie puisqu'il est possible de traiter deux tâches de manière asynchrone sans que cela ne se fasse en parallèle et inversement. Comme nous l'avons vu avec Ashes of the Singularity, le premier jeu Direct3D 12 à exploiter cette possibilité, si les Radeon parviennent à en tirer en bénéfice, il n'en est rien pour les GeForce Kepler et Maxwell. Les Radeon disposent d'un processeur de commande plutôt évolué, associé à des ACE (Asynchronous Compute Engines), capable de prendre en charge automatiquement et efficacement plusieurs files de commandes. Malheureusement, il en va différemment pour les GeForce dont le processeur de commandes ne gère plusieurs files efficacement qu'en mode compute pur. Dès que du rendu 3D est impliqué, cela se complique. Nvidia explique que les GPU Maxwell sont capables de prendre en charge 32 files dont une peut être de type graphics mais ne peuvent pas gérer automatiquement la répartition des ressources. En d'autres termes, par défaut, ces GPU vont les exécuter en alternance tout en souffrant des commandes de synchronisation. Il est par contre possible de définir statiquement, via un profil de jeu, une répartition de ces ressources. Par exemple : 12 SM peuvent être attribués à un file et 4 à une autre. C'est en pratique peu efficace puisqu'un partage fixe correspond rarement aux charges instantanées traitées par le GPU. 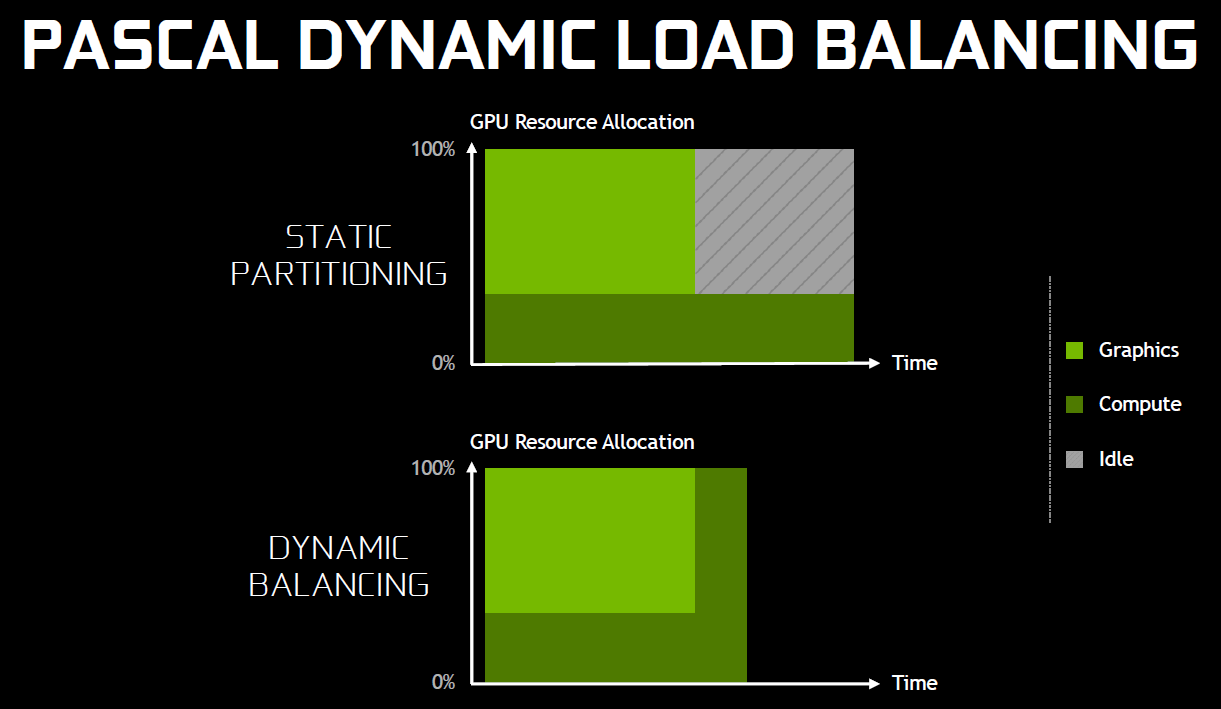 Avec les GPU Pascal, Nvidia a fait évoluer quelque peu son processeur de commande pour permettre au GPU de piloter dynamiquement cette attribution des SM. Une petite évolution dont nous ne sommes pas certains de la portée réelle. Nous n'avons par exemple pas noté de gain dans Ashes of the Singularity. Certes nous pouvons observer que la petite baisse de performance de 1-2% (liée aux commandes de synchronisation qui pilotent "Async Compute"), notée sur Maxwell avec de précédents pilotes, a disparu. Nous pouvons même observer un gain de 1-2% avec certains paramètres graphiques, mais vous conviendrez que c'est loin d'être convainquant. Nvidia admet que dans ce jeu l'amélioration est anecdotique mais promet que dans d'autres titres à venir des gains plus importants devraient être mesurables. Nous vérifierons bien entendu cela dès que possible. Ceci étant dit, nous estimons que notre précédente analyse reste d'actualité. Le principe de base sur lequel repose la tentative d'exécution concomitante des tâches est que le GPU n'exploite pas à 100% ses différents types d'unités. Le gain potentiel est donc lié au taux d'utilisation de chaque unité. Plus il est élevé, moins le gain peut être important, d'autant plus qu'avoir recours à l'exécution concomitante implique de mettre en place de coûteuses barrières de synchronisation. Si les GeForce ont de base un meilleur taux d'utilisation de leurs unités que les Radeon, il y a moins de raison de chercher une synergie entre les exécutions de différentes tâches. Un autre élément à prendre en compte est que l'architecture des GeForce depuis plusieurs générations a décentralisé plusieurs aspects du pipeline graphique qui prennent place dans les SM. C'est le cas du traitement de la géométrie par exemple ou encore du transfert des pixels vers les ROP. Par conséquent, répartir les SM entre deux tâches ne permet pas à l'une d'elle d'exploiter la puissance géométrique ou le fillrate inutilisés par l'autre. Même la puissance de calcul est difficilement attribuable à une tâche donnée. Au vu de son architecture, il nous semble que pour réellement profiter de l'exécution concomitante, les GeForce Pascal devraient exécuter ces multiples tâches à l'intérieur de chaque SM et non leur attribuer un certain nombre de SM entiers, que ce soit dynamiquement ou pas. C'est assez différent pour les Radeon, dont l'architecture semble gérer ces tâches multiples bien plus finement. La préemption progresseUn autre aspect d'Async Compute représente la possibilité de traiter des tâches en alternance de manière désynchronisée et éventuellement en priorité. Pour cela, il faut interrompre et mettre en pause le travail en cours du GPU pour passer sur une autre tâche, c'est la préemption. Cela permet de supporter un environnement multitâche sur GPU, mais également d'exécuter le time warping dans le cadre de la VR. Cette technique consiste pour rappel, juste avant chaque rafraîchissement de l'écran, à déformer la dernière image terminée sur base des informations de positionnement les plus récentes. De quoi simuler le point de vue réel et réduire la latence perçue. 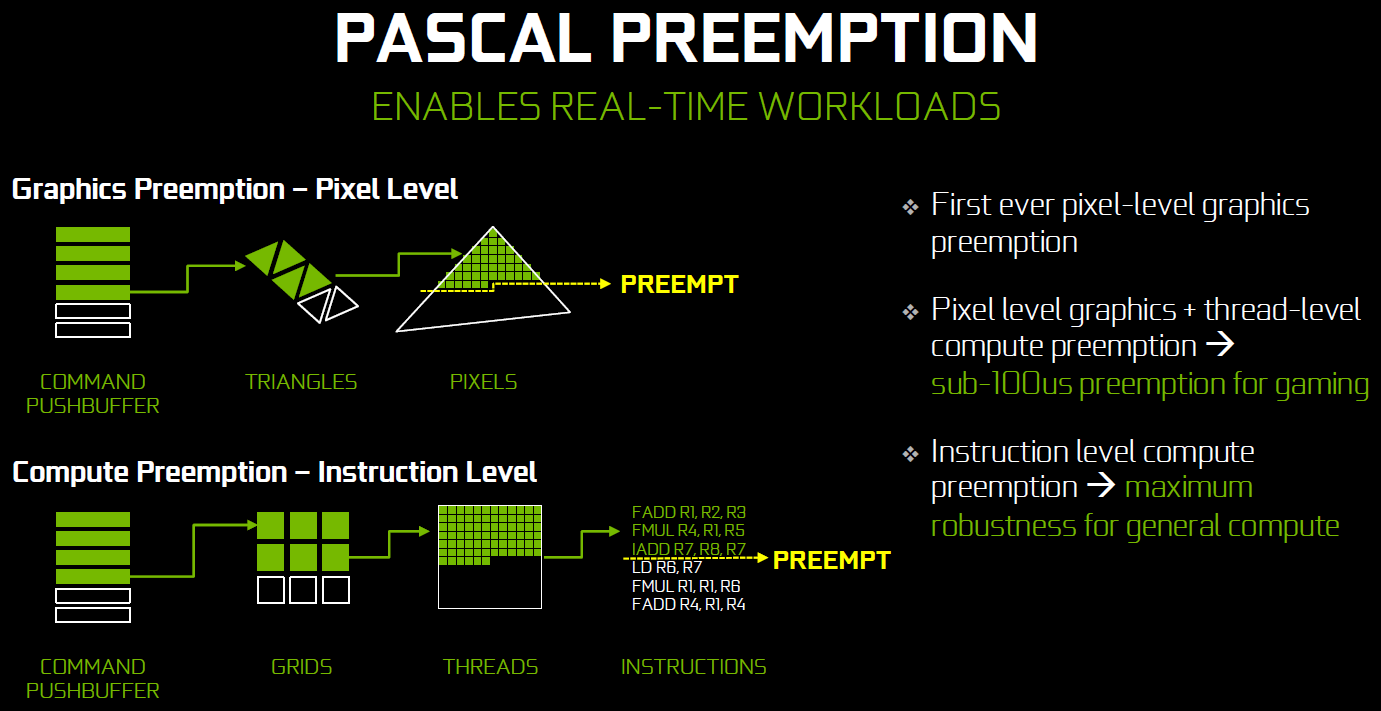 Peu loquace en détails concernant l'exécution concomitante, Nvidia met par contre fortement en avant les améliorations apportées à la préemption qui permet sur Pascal de stopper plus rapidement une tâche en cours pour passer à une autre. Les GPU Pascal peuvent faire de la préemption au niveau du pixel en mode graphics et au niveau du thread en mode compute. Les GPU Maxwell et les Radeon ne peuvent le faire que par triangle par exemple. De quoi réduire quelque peu la latence dans le cadre de la VR et du time warping.  [ Time warping sur Maxwell ] [ et sur Pascal ] Dans cet exemple, un GPU Pascal ne doit pas lancer la time warping aussi tôt qu'un GPU Maxwell, ce qui augmente les performances et réduit la latence en utilisant des données de positionnement plus récentes. Rappelons que dans certains cas, un triangle peu représenter un temps de rendu très élevé, notamment lorsqu'une image entière est plaquée sur 1 ou 2 triangles en vue de recevoir un effet de post processing très gourmand. Sur les GPU autres que Pascal, quand le time warping intervient à ce très mauvais moment, il est possible qu'il ne puisse pas être exécuté avant l'affichage à moins de prendre une marge de sécurité énorme. Nvidia précise par ailleurs que le délai pour le changement de tâches a été réduit à moins de 100 µs une fois la tâche en cours terminée, soit une fois que les pixels ou les threads sur lesquels le GPU a commencé à travailler sont terminés. En mode CUDA pur, les GPU Pascal peuvent aller plus loin et faire de la préemption au niveau le plus bas possible : celui des instructions. Dans ce cas, dès que la commande est passée, le GPU s'interrompt immédiatement et transfère le tout en mémoire. Bien plus d'informations doivent être conservées, telles que tous les registres de tous les threads en vol, ce qui peut avoir un coût plus important. Une possibilité à ne pas utiliser pour alterner en permanence entre deux tâches par exemple. Avec les GPU Maxwell, Nvidia a introduit une fonctionnalité dénommée Multi Projection Acceleration. Elle est à la base de VXGI et VXAO ainsi que du Multi-Resolution Shading qui permet d'optimiser les performances en VR en réduisant la résolution sur les côtés. Le moteur de projection multiple de Maxwell était cependant limité dans le sens où toutes les projections devaient se faire à partir du même point de vue (le VXAO et le VXGI représentant une approche particulière qui peut s'y rattacher). 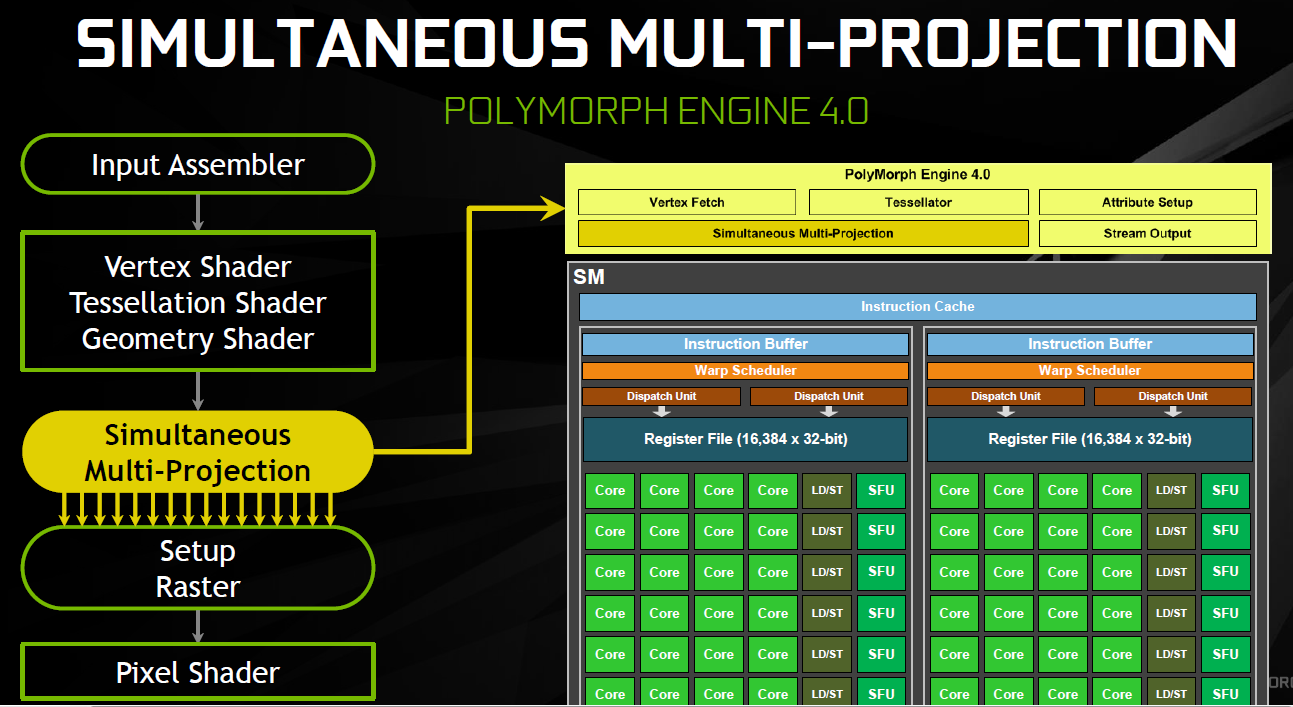 Présent en partie dans le Polymorph Engine et en partie dans le Rasterizer, le SMPE (Simultaneous Multi Projection Engine) des GPU Pascal va plus loin. Cette unité est capable de générer plusieurs projections du flux de géométrie jusqu'à 16, voire jusqu'à 32 dans le cas d'un rendu stéréoscopique. Quelle utilité ? Le meilleur exemple est un rendu VR simple : au lieu de calculer séparément l'image pour chaque oeil, la géométrie peut n'être traitée qu'une fois et projetée ensuite directement, en une seule passe, dans les 2 images. Le SMPE se charge automatiquement de tout cela et de dédoubler les triangles qui doivent l'être. Suivant la complexité de la géométrie, des vertex shaders, de la tessellation, les gains peuvent être plus ou moins conséquents. Cela ne change par contre rien au niveau du calcul des pixels. Mais le SMPE ne s'arrête pas là et permet également de faire du Lens Matched Shading. Grossièrement il s'agit d'aller encore plus loin que le Multi Resolution Shading en utilisant plusieurs viewports pour simuler une image incurvée qui se rapproche le plus possible de l'image qui sera affichée après déformation pour être adaptée à la lentille. Voici ce que cela donne en image :  [ Rendu classique ] [ Lens Matched Shading ] Sur la seconde image, on peut deviner à travers la silhouette de l'image rendue les 4 viewports. En retenant une haute qualité, 33% de pixels en moins sont calculés pour un résultat final identique ou très proche après déformation. De base, dans le cas de l'Oculus Rift par exemple, des images de 2.1 MPixels sont déformées (warping) pour pouvoir être vue correctement à travers les lentilles du casque. Après cette déformation, la résolution effective n'est plus que de 1.4 MPixels et le SMPE autorise donc un débit effectif de pixels 50% supérieur.  De quoi autoriser des gains conséquents en VR mais il faudra pour cela un support spécifique de la part des applications. A noter qu'il est possible d'utiliser plus de 4 viewports pour simuler un écran incurvé plus précis, mais cela apporte peu de bénéfices par rapport au coût engendré. Exploiter plus de 4 viewports pourra par contre avoir plus de sens dans le cadre des CAVE (cave automatic virtual environment) ou des dômes. L'autre utilité concerne les écrans larges incurvés ainsi que les systèmes surrounds inclinés de manière à simuler un tel écran incurvé comme c'est généralement le cas. Actuellement, le rendu se fait assez naïvement en faisant comme si le système d'affichage était une surface plane, ce qui implique un champ de vision trop étroit et des erreurs de projections qui s'amplifient aux extrémités.  [ Rendu surround classique ] [ et avec correction du champ de vision ] Le SMPE permet d'opérer une projection différente pour chaque écran ou pour chaque zone de l'écran large incurvé de manière à ce que le champ de vision soit correct par rapport à l'angle d'inclinaison et par rapport à la position de l'utilisateur. Nvidia prépare un utilitaire qui permettra de configurer ces systèmes. Avec le GP104, Nvidia fait évoluer son interface SLI qui n'avait pas réellement bougé depuis très longtemps. Sur les GPU précédents, le frame pacing qui permet de lisser l'affichage des images en multi-GPU pour améliorer la fluidité, atteignait ses limites en très hautes résolutions. Le débit du lien SLI imposait une latence trop élevée pour les images en 4K ou en surround. C'est une des raisons pour lesquels AMD a abandonné son lien CrossFire au profit du PCI Express, et c'est ce qui fait que les Radeon s'en tiraient un petit peu mieux que les GeForce alors que ces dernières avaient un petit avantage en 1080p ou en 1440p. Nvidia estime que se baser uniquement sur le PCI Express n'est pas une solution qui lui permette de garantir un résultat optimal et donc plutôt que d'abandonner ses connecteurs SLI, ses ingénieurs les ont améliorés.  La première mise à jour concerne la fréquence de ce bus spécial qui passe de 400 à 650 MHz. Pour profiter de cette fréquence et donc de ce débit plus élevé, il faudra par contre un pont SLI compatible qualifié de HB pour High Bandwidth. Certains ponts "durs" à LED actuels en sont capables, mais les ponts souples par exemple ne le sont pas. Ils restent compatibles avec les GTX 10x0 mais la connexion SLI sera alors limitée à 400 MHz. La seconde mise à jour concerne la combinaison des 2 connections SLI pour doubler la bande passante qui est alors multipliée par 3.25x en combinaison avec les nouveaux ponts !  Nvidia propose pour l'occasion de nouveaux ponts SLI HB dans 3 formats qui correspondent à 3 options d'espacement des slots PCIE. Ses partenaires devraient également en proposer de nouveaux. Tous ces ponts sont limités au 2-way SLI. Les SLI 3-way et 4-way ont en effet besoin du second connecteur SLI pour connecter tous les GPU entre eux et ne peuvent donc pas combiner deux connecteurs pour augmenter la bande passante. Si Nvidia a opté pour cette approche c'est en fait suite à une décision relativement importante : l'abandon des modes 3-way et la 4-way. Alors qu'il est déjà devenu difficile de convaincre les développeurs de faire l'effort de supporter correctement le bi-GPU, Nvidia a dû réaliser qu'aller plus loin n'a plus beaucoup de sens alors que ça demande beaucoup de ressources en terme de support et de validation. Par défaut il n'y aura donc plus que le SLI 2-way de supporté à partir des GeForce GTX 1000. Il restera par contre possible de mettre en place un troisième GPU dédié à PhysX. Pas totalement fou non plus face aux records sous 3DMark et consorts, Nvidia proposera une interface à travers de laquelle les utilisateurs pourront demander une clé pour débloquer le 3-way et le 4-way. Le support sera limité au bon vouloir des développeurs et la fluidité ne profitera alors pas des améliorations apportées à Pascal. Nvidia communique un exemple d'amélioration avec la nouvelle interface SLI :  On peut observer, en bleu, que les micro-saccades sont nettement réduites avec un nouveau pont double canal à 650 MHz, par rapport à un ancien pont simple canal à 400 MHz, en noir. Il manque malheureusement les configurations intermédiaires, à savoir le simple canal à 650 MHz ou le double canal à 400 MHz.  D'après ce tableau de Nvidia, le simple canal à 650 MHz serait nécessaire pour garantir la fluidité au-delà du 1440p à 60 Hz, alors que le double canal 650 MHz serait nécessaire en 4K, 5K et Surround (mais la résolution n'est pas précisée, probablement en 3x1440p). Aucune précision n'est donnée concernant le double canal 400 MHz, une solution pourtant plus économique puisqu'elle permet de recycler de "vieux" ponts mais qui n'en est en fait pas supportée officiellement. Fast Sync, un nouveau type de compromisPour les joueurs qui recherchent une absence de tearing avec un faible niveau de latence à travers un niveau de fps très élevé, qui va au-delà de ce que permet le taux de rafraîchissement de leur écran, G-Sync ou pas, Nvidia a développé une nouvelle alternative au VSync OFF et VSync ON. Appelé Fast Sync, ce nouveau mode est en fait une variante du triple buffering mais implémentée en partie en hardware. Nvidia le nomme différemment d'une part pour des raisons marketing, d'autre part pour se démarquer de la confusion qui peut exister entre les types de triple buffering (le "vrai" et le render ahead) et enfin parce que le moteur d'affichage du GPU a été légèrement adapté pour le prendre en charge nativement. Traditionnellement, deux buffers sont utilisés lors du rendu : le front buffer et le back buffer. Le GPU effectue le rendu dans le back buffer et une fois terminé il devient le front buffer qui est lu par le moteur d'affichage et envoyé vers l'écran. L'ancien front buffer devient le nouveau back buffer et le GPU travaille sur l'image suivante. Cette inversion des deux buffers se fait soit instantanément en VSync OFF, ce qui cause un décalage entre les images (le tearing), soit de manière synchronisée avec le taux de rafraîchissement de l'écran en VSync ON, ce impose des temps d'attente qui limitent les performances et augmentent la latence. 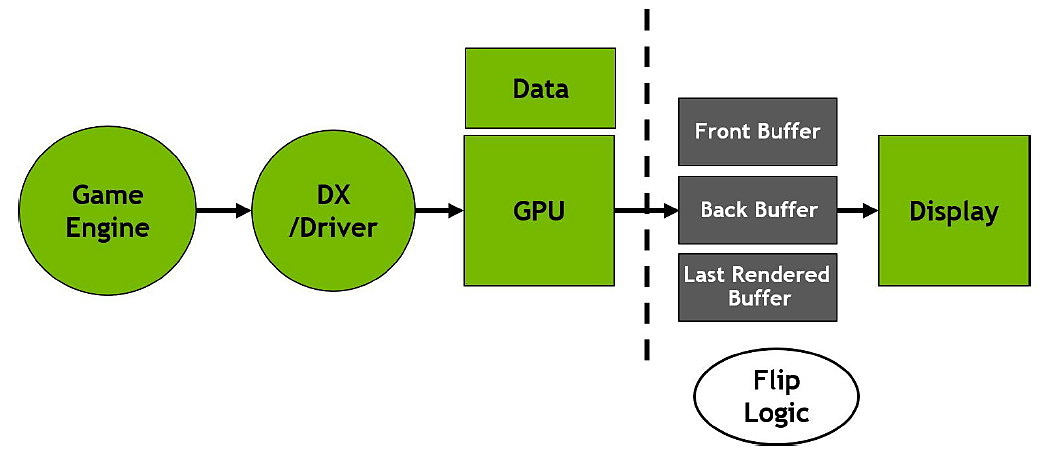 Pour Fast Sync, Nvidia découple totalement le pipeline de rendu de l'affichage en insérant un troisième buffer appelé last rendered buffer, soit le buffer qui contient la dernière image rendue. Le GPU peut alors calculer les images aussi vite qu'il le veut en alternant entre le back buffer et le last rendered buffer alors que le moteur d'affichage fera la transition entre ce dernier et le front buffer pour se caler sur le taux de rafraîchissement. De quoi permettre de se rapprocher à haut fps de la faible latence du mode VSync OFF tout en évitant le tearing comme en VSync ON. En contrepartie, avec un framerate légèrement supérieur au taux de rafraîchissement on risque d'avoir un affichage moins fluide car certaines images calculées peuvent être sautées à l'affichage, dans ce cas et sur ce point le VSync ON est supérieur. La solution idéale reste bien entendu la fréquence de rafraîchissement variable (G-SYNC ou Adaptive-Sync / FreeSync) sur un écran permettant de monter à 120/144 Hz, ce qui permet tout en se passant de tearing d'éviter les problèmes de fluidité quand le framerate varie tout en ayant une latence similaire au VSync OFF tant que ce dernier ne dépasse pas la fréquence de rafraîchissement maximale. Côté latence, voici par exemple ce que cela donne selon Nvidia sur une section de 20s de Counter-Strike Global Offensive : 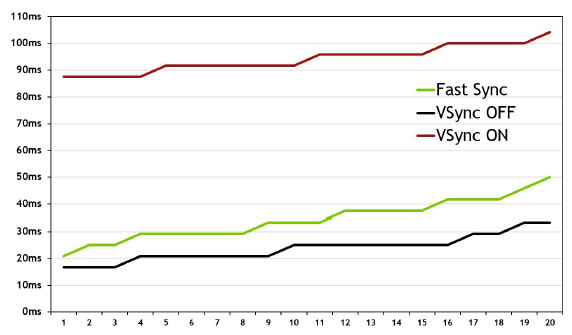 Le framerate et le taux de rafraîchissement ne sont pas précisés, il est probable qu'il s'agisse du cas le plus favorable à savoir un écran 60 Hz et un framerate dépassant allègrement la centaine de fps, un écran 120/144 Hz permettrait déjà de réduire fortement la latence en Vsync ON. Nvidia explique que ce découplage du pipeline de rendu avec le moteur d'affichage va permettre différentes innovations dans le futur, mais sans donner plus de détails. Un moteur vidéo et d'affichage revuLe GP104 reprend les capacités de prise en charge du GM204 au niveau du HDR. Les moteurs d'affichage de ces GPU supportent le HDMI 2.0b nécessaire pour prendre en charge les formats de couleurs 10-bit et 12-bit jusqu'en 4K, ainsi que les standards BT.2020 et le SMPTE 2084. Selon Nvidia il n'y a donc pas de différence sur ce point, mais le support logiciel n'est pas encore totalement là côté GeForce. Le GP104 y ajoute le support du décodage des vidéo HDR 10-bit et 12-bit jusqu'en 4K 60 Hz ainsi que l'encodage mais cette fois limité au HDR 10-bit. De quoi autoriser le streaming en HDR vers la console Shield. Par ailleurs, bien qu'il n'ait actuellement été certifié que pour le DisplayPort 1.2, le GP104 et les GTX 1080 supportent le DP 1.3 ainsi que le DP 1.4 qui vont permettre de transporter les metadatas nécessaires au HDR. Nvidia indique travailler avec les développeurs de jeux vidéo pour l'intégration du support de l'affichage HDR qui demande notamment de revoir l'algorithme de tone mapping. Cela devrait arriver rapidement dans Obduction, The Witness, Lawbreakers, Rise of the Tomb Raider, Paragon, The Talos Principle et Shadow Warrior 2. Voici un récapitulatif des capacités des moteurs d'affichages et video du GM204 et du GP104. A noter que nous précisons ici le type de GPU puisque cela peut varier au sein d'une même génération : le GM206 supporte par exemple le décodage du HEVC. 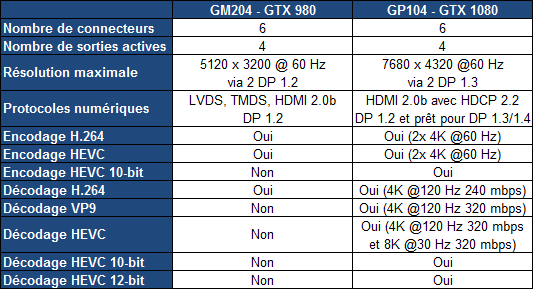 Page 6 - Spécifications et Direct3D 12 # Spécifications 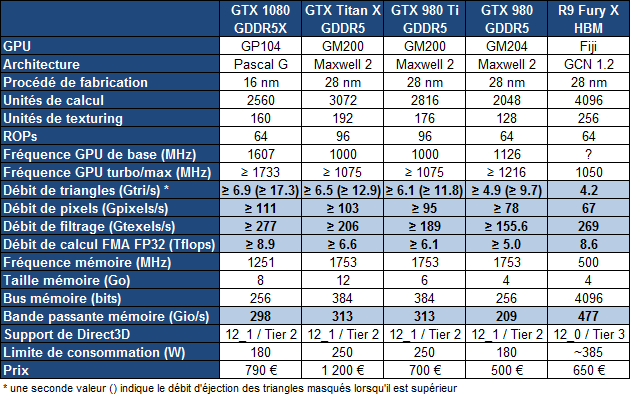 La GeForce GTX 1080 embarque un GPU GP104 complet, c'est-à-dire que toutes les unités qu'il contient sont actives. Comme vous pouvez le constater, les débits bruts augmentent fortement par rapport à la GeForce GTX 980 avec une puissance de calcul en hausse de 78% ou encore une bande passante mémoire qui progresse de 42%. Par rapport aux dérivés du GM200, la comparaison est un peu plus complexe. Ceux-ci conservent un petit avantage au niveau de la bande passante grâce à leur bus 384-bit. La GTX 1080 ne profite ensuite que d'un très petit gain au niveau du débit de triangles (rendus) et du débit de pixels mais voit sa puissance de calcul et de texturing prendre un avantage de 46% sur la GTX 980 Ti. Sur le papier, la Radeon R9 Fury X n'a pas à rougir avec une puissance de calcul et de texturing similaire et une bande passante largement supérieure grâce à la HBM. Elle affiche par contre un lourd déficit au niveau des débits de pixels et de triangles. Il faut cependant rappeler que ces chiffres bruts ne veulent pas tout dire. A puissance de calcul théorique similaire, les GeForce sont plus efficaces, notamment parce qu'elles disposent de 25% d'unités de calcul supplémentaires dédiées aux fonctions spéciales et qui ne sont par conséquent pas intégrées dans ces chiffres. La GeForce GTX 1080 affiche une limite de consommation de 180W, identique à celle de la GeForce GTX 980 et nettement inférieure aux 250W d'une GTX 980 Ti. Nous avons ensuite rassemblé les fonctionnalités reportées par Direct3D 12 : 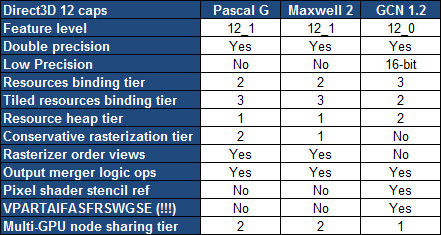 La seule évolution notable par rapport aux GPU Maxwell 2 concerne un support plus évolué de la rastérisation conservative. Les GPU AMD conservent globalement un avantage avec plus de flexibilité au niveau de la gestion des ressources mais les GeForce Maxwell et Pascal sont les seules à supporter les Volume tiled resources. L'accès aux données entre GPU (en dehors des copies) est également plus flexible en SLI qu'en CrossFire. Dans un premier temps, la GeForce GTX 1080 de référence devrait être la seule déclinaison disponible, mais les versions personnalisées partenaires devraient suivre très rapidement. Pour son ventirad de référence, Nvidia propose depuis quelques générations un design particulièrement efficace tant en termes d'esthétique et de finition que de performances dans le cadre d'une solution de type turbine. Après quelques hésitations, le fabricant compte afficher clairement l'aspect premium de son design, même s'il n'est pas accompagné d'un overclocking d'usine.  La première conséquence est qu'il reçoit un nom pour le mettre en avant : Founders Edition. Soit la carte construite par Nvidia, ce qui fait indéniablement pensé au feu Built-By-ATI (BBA) même s'il s'agissait à l'époque de cartes bien plus basiques. La seconde conséquence est que ce design va se payer au prix fort : 100 de plus que le tarif de base annoncé. C'est peut-être un peu beaucoup et un ajustement se fera si le marché en décide ainsi, mais il est loin d'être délirant de penser que ce design proposé par Nvidia vaut plus cher que certains modèles personnalisés qui visent avant tout à réduire les coûts. D'ailleurs c'est un problème que Nvidia a rencontré par le passé avec la disparition progressive de ses cartes de référence, ses partenaires préférant la remplacer par un modèle moins cher. Avec la GeForce GTX 1080 Founders Edition, Nvidia garanti une disponibilité de son design sur toute la durée de vie du produit, et la commercialisera d'ailleurs directement via son site internet sur certains marchés. Tous les partenaires restent cependant libres de la commercialiser comme n'importe quelle autre carte de référence. Ceci étant dit passons aux photos :  Nvidia reprend ici la même base que pour le ventirad des GeForce GTX haut de gamme précédentes mais a revu le style. Après quelques années un peu de changement ne fait pas de mal même si nous sommes partagés entre le design classique et le nouveau plus agressif (en fait non, le ventirad noir de la GTX Titan X de référence a notre préférence).  Question de goûts. La qualité de finition reste irréprochable et participe au bon comportement de ces cartes sur le plan des nuisances sonores. Sur la génération Maxwell, les cartes 180W (GTX 980) se contentaient de petits caloducs insérés dans la base du radiateur alors que la chambre à vapeur était réservée aux modèles 250W (GTX 980 Ti, Titan X). Pour cette GTX 1080, pourtant spécifiée à 180W, Nvidia a opté pour une chambre à vapeur.  Comme pour les précédentes GeForce 180W, la GTX 1080 reçoit une backplate. Celle-ci gagne en qualité et en minceur par rapport à celle de la GTX 980. Nvidia a eu la très bonne idée de la composer de deux pièces de manière à permettre de dégager l'arrière de la carte pour favoriser un meilleur apprivoisement en air dans le cadre du multi-GPU ou encore pour optimiser le refroidissement de l'étage d'alimentation si cela s'avérait nécessaire. A noter que le démontage de chaque partie de la backplate, qui ne désolidarise pas le ventirad du PCB et n'annule pas la garantie, se fait via de nombreuses vis aussi fragiles que petites. Lors du remontage ne tentez pas de les serrer plus que très légèrement sans quoi la tête de vis se brise très facilement.  Nvidia indique avoir travaillé en profondeur sur l'étage d'alimentation du GPU, composé de 5 phases pour le GPU et d'une de plus pour sa mémoire GDDR5X Micron. Ils sont alimentés via 2 sources de 12V : un connecteur 6 broches et le bus PCI Express. Nvidia précise avoir sélectionné les composants de manière à éviter le coil whine. Notre échantillon en produit cependant un tout petit peu, rien de bien méchant ceci dit.  Nvidia explique également avoir travaillé l'étage d'alimentation de manière à augmenter la capacitance des circuits de filtrage du courant et à réduire l'impédance des circuits de distribution. De qui permettre d'augmenter le rendement de cet étage d'alimentation de +/- 6% tout en réduisant le bruit électrique pour éventuellement aider à pousser l'overclocking un petit peu plus loin. Ce rendement supérieur implique que pour une consommation totale de la carte de 180W, la part dissipée par le GPU sera supérieure. Par ailleurs, ce GPU est 20% plus petit que celui de la GTX 980. Ces deux points font qu'à consommation égale le stress sera plus important sur le ventirad de la GTX 1080 que sur celui de la GTX 980. C'est pour cette raison que Nvidia a recours à une chambre à vapeur et ce n'est pas suffisant. La limite de température a été relevée de 79.5 °C pour une GTX 980 à 82 °C, une valeur proche des 83 °C des modèles 250W. Au final cela permet à la GTX 1080 d'afficher des nuisances similaires à celles de la GTX 980.  Enfin, la connectique vidéo est similaire à celle des GeForce GTX 900 : une DVI Dual Link, une HDMI et 3 DisplayPort, dont 4 peuvent être utilisées simultanément. Il y a cependant une petite différence visible pour les plus attentifs : il s'agit d'une sortie DVI-D et non plus DVI-I. En d'autres termes, la GTX 1080 ne supporte plus la connectique VGA. Pour ce dossier, nous avons revu en profondeur notre protocole de test en remplaçant et intégrant de nombreux jeux. Anno 2070, GRID 2, Far Cry 4, Hitman Absolution et Tomb Raider laissent place à Anno 2205, DiRT Rally, Far Cry Primal, Hitman et Rise of the Tomb Raider. Nous ajoutons par ailleurs Ashes of the Singularity, le premier jeu à réellement tirer parti de DirectX 12 qui est donc testé dans ce mode. Hitman et Rise of the Tomb Raider supportent également cette nouvelle API mais avec des performances légèrement inférieures. Nous nous sommes donc contentés de DirectX 11 pour ces deux titres. DOOM est également intégré et marque le retour d'un jeu OpenGL dans notre protocole. Reste ensuite The Division, un titre plutôt gourmand, ainsi que Grand Theft Auto V, enfin, suite à une demande soutenue depuis sa sortie. Nous avons utilisé les pilotes 368.13 beta fournis par Nvidia et les Crimson Edition 16.5.2 hotfix pour les Radeon (excepte pour la R9 290X dans DOOM pour laquelle nous sommes passés aux 16.5.2.1 qui corrigent un problème de performances spécifiques aux GPU Hawaii). Tous les derniers patchs au 12/05/2016 ont été installés, la plupart des jeux étant maintenus à jour via Steam/Origin/Uplay. Nous apporterons au passage des remerciements chaleureux à EA et Origin qui ont décidé depuis quelques mois de bloquer les clés de Battlefield 4 et de Star Wars Battlefront après plusieurs changements de cartes graphiques dans une période de 12h. Face à un support désarmé et qui n'a pas été mis au courant, nous n'avons eu d'autre choix que d'acheter de multiples clés. Un passage à la caisse qui permet de multiplier les Battlefield 4 dans un même compte Origin mais qui se contente d'avaler les nouvelles clés de Star Wars Battlefront sans rien débloquer et sans aucun avertissement ! @#~!&!!!@ Nous avons opté tout d'abord pour la résolution de 1440p avec un niveau de détail maximal ou très élevé. Nous avons évité d'activer l'antialiasing de type SSAA, que nous jugeons beaucoup trop gourmand par rapport à ce qu'il apporte. Nous avons ensuite ajouté à ce dossier des mesures en 4K sur les cartes les plus performantes en essayant de nous rapprocher des 60 fps sur GTX 1080 si cela ne compromettait pas trop la qualité graphique. Face aux journées qui se limitent à 24h et au niveau de performances de la GTX 1080, nous avons laissé de côté les tests en 1080p mais nous reviendrons éventuellement sur ce point lors du test de la GTX 1070. Toutes les cartes ont été testées avec une température ambiante contrôlée à 26 °C et, pour chaque jeux, nous avons pris le temps nécessaire pour que la fréquence GPU se stabilise. Voici le rélevé des fréquences pour information : 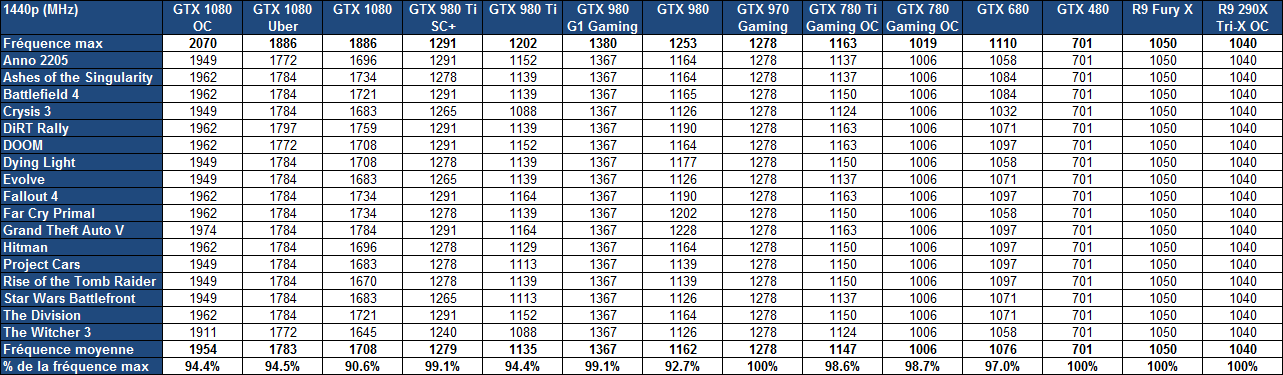 On remarquera qu'en moyenne la GTX 1080 est plus éloignée de sa fréquence maximale que les autres cartes, nous y reviendrons dans les pages GPU Boost et OC. Ce test a été l'occasion de mettre à jour notre plate-forme de test qui passe au X99 et au Core i7-5960X, poussé à 4 GHz. Au niveau de l'affichage, pour les tests en 1440p nous avons opté pour l'Asus ROG Swift PG278Q mais limité à 120 Hz, certains Radeon étant capricieuses en 144 Hz avec certains câbles sur ce moniteur. G-Sync était désactivé. Configuration de test
Nous avons mesuré les performances lors de l'accès aux textures avec filtrage bilinéaire activé et ce, pour différents formats : en 32 bits classique (8x INT8), en 64 bits "HDR" (4x FP16), en 128 bits (4x FP32), en profondeur de 32 bits (D32F) et en FP10, un format HDR introduit par DirectX 10 qui permet de stocker des textures HDR en 32 bits avec quelques compromis. Les GeForce GTX sont capables de filtrer les textures FP16 à pleine vitesse contrairement aux Radeon, ce qui leur donne un avantage considérable sur ce point. En dehors du HDR 64-bit, le GPU Fiji et le GP104 sont ici très proches. FillrateNous avons mesuré le fillrate sans et puis avec blending, et ce avec différents formats de données : [ Standard ] [ Avec Blending ] Le fillrate était l'un des points forts du GPU Hawaii qui intègre pas moins de 64 ROP chargés d'écrire les pixels en mémoire, qui plus est d'une efficacité élevée avec blending. Mais avec le GM204, Nvidia est revenu et le GP104 enfonce le clou grâce à sa fréquence très élevée qui lui permet même de surpasser le GM200 équipé de 50% de ROP en plus. Le GPU Fiji ne s'en tire bien qu'en HDR 64-bit, son déficit de fillrate est criant sur les formats inférieurs. A noter que les GeForce depuis Kepler sont capables de transférer les formats FP10/11 et RGB9E5 à pleine vitesse vers les ROP, comme les Radeon, mais le blending de ces formats se fait toujours à demi vitesse. Par ailleurs, si tous les GPU sont capables de traiter le FP32 simple canal à pleine vitesse sans blending, seules les Radeon conservent ce débit avec blending. Étant donné les différences architecturales des GPU récents au niveau du traitement de la géométrie, nous nous sommes évidemment penchés de plus près sur le sujet. Tout d'abord nous avons observé les débits de triangles dans deux cas de figure : quand tous les triangles sont affichés et quand ils sont tous rejetés (parce qu'ils tournent le dos à la caméra) : Si le débit de triangles rendus progresse peu entre le GM200 et le GP104, il explose par contre quand les triangles peuvent être éjectés du rendu. Cela en concerne en pratique toujours une part conséquente et la plupart des GeForce GTX peuvent profiter d'un débit supérieur pour se démarquer des Radeon. Ensuite nous avons effectué un test similaire mais en utilisant la tessellation. A noter que nous avons quelque peu revu notre test de manière à l'adapter à la puissance en hausse des GPU : Les GeForce réaffirment ici leur avantage face aux Radeon qui peuvent se retrouver plus rapidement submergées en cas de génération massive de données ou de hull shaders lourds. Les GeForce profitent d'une architecture qui distribue le traitement géométrique au niveau des SM ainsi que de groupes de threads plus petits (32 vs 64) qui facilitent le maintien d'un taux d'occupation élevé. Avant de rentrer dans le match habituel des performances, nous avons voulu observer comment se situait cette première GeForce Pascal par rapport aux premières GeForce Fermi, Kepler et Maxwell 2. Soit un petit match entre les GTX 1080, GTX 980, GTX 680 et GTX 480 sur l'ensemble de notre protocole de test. A noter que dans le cas des GTX 680 et GTX 480, qui ne disposent respectivement que de 2 Go et 1.5 Go, nous avons réduit la qualité des textures quand cela était nécessaire, ce qui n'a qu'un impact négligeable sur les performances. De quoi faire en sorte que leur mémoire vidéo ne soit pas un point qui bride leurs performances même si la qualité graphique sélectionnée ne leur est pas réellement adaptée. [ Performances (%) ] [ Performances (fps) ] Les gains sont relativement similaires d'une génération à l'autre : +74% de Fermi à Kepler, +82% de Kepler à Maxwell 2 et +67% de Maxwell 2 à Pascal G. Un petit avantage pour Maxwell 2 par rapport à Kepler mais il y avait eu entre temps une série GTX 700 avec une GTX 780 équipée d'un plus gros GPU. Nous avons utilisé le protocole de test qui nous permet de mesurer la consommation de la carte graphique seule. Nous avons effectué ces mesures au repos sur le bureau Windows 10 et en veille écran. Pour la charge, nous testons d'une part Battlefield 4 en mode Ultra qui représente un jeu moyennement lourd et d'autre part The Witcher 3 qui remplace Anno 2040 pour représenter un jeu très lourd. Si ce dernier est à peu près aussi lourd qu'Anno 2040 pour les GeForce, il l'est par contre un peu moins pour les Radeon. Nous réévaluerons éventuellement la possible utilisation d'un autre jeu dans le futur. Nous avons testé les GeForce GTX de référence en mode 'Uber', ce qui consiste à relever leurs limites de consommation et de température au maximum pour voir ce qu'elles ont dans le ventre sans ces dernières. Aucun overclocking n'est par contre appliqué mais le turbo par défaut se maintient à une fréquence plus élevée. La GeForce GTX 1080 affiche tout d'abord une consommation en nette baisse sur le bureau Windows, ce qui est de toute évidence en bénéfice du passage au 16 nm. En charge, la GTX 1080 se comporte comme une GTX 980, mais compte tenu de son étage d'alimentation plus efficace et de la GDDR5X annoncée moins énergivore, il est possible que le GPU consomme légèrement plus. Bien que ces données soient approximatives, compte tenu de la variation entre échantillons d'un même modèle, nous avons mis en relation ces mesures de consommation avec les performances, en retenant des fps par 100W pour que les données soient plus lisibles, de quoi donner une idée globale sur le rendement énergétique de toutes ces cartes : [ Battlefield 4 ] [ The Witcher 3 ] Avec une consommation stable et des performances qui progressent nettement, le rendement énergétique part bien entendu à la hausse : +75% par rapport à la GTX 980 ! Nous plaçons les cartes dans un boîtier Cooler Master RC-690 II Advanced et mesurons le bruit d'une part au repos et d'autre part en charge sous le test1 de 3DMark11. Un SSD est utilisé et tous les ventilateurs du boîtier ainsi que celui du CPU sont coupés pour la mesure. Le sonomètre est placé à 60cm du boîtier fermé et le niveau de bruit ambiant se situe à moins de 20 dBA, ce qui est la limite de sensibilité pour laquelle il est certifié et calibré. Sur le plan des nuisances sonores, la GeForce GTX 1080 se comporte à peu près comme la GTX 980. A peu près car au repos un petit flux d'air et un très léger coil whine n'échappent pas à notre sonomètre. En charge, la GTX 1080 se stabilise à sa fréquence de base et affiche une consommation de +/- 152W. Si nous la poussons en mode 'Uber', sans limites de consommation et de températures, elle monte à +/- 193W et maintient une fréquence moyenne de 1720 MHz. Ses nuisances sonores augmentent par contre significativement. Il faut cependant noter que comme pour les précentes GeForce GTX équipées du ventirad maison haut de gamme, ces cartes produisent un souffle étouffé qui est peu désagréable, moins gênant que le bruit plus faible produit par certaines cartes personnalisées. TempératuresToujours placées dans le même boîtier, nous avons relevé la température du GPU rapportée par la sonde interne : La température GPU de la GTX 1080 est similaire à celle de la GTX 980 Ti en charge, ce qui correspond à une limite revue à la hausse pour son système de contrôle des fréquences turbo. Thermographie infrarougeVoici les photos thermiques obtenues avec à chaque fois 45 minutes de mise en situation :  [ GeForce GTX 1080 sans backplate - Repos ] [ Charge ] [ Charge 'Uber' ] [ GeForce GTX 980 Ti - Repos ] [ Charge ] [ Charge 'Uber' ] Avec backplate, nous pouvons directement remarquer que celle-ci est en fait séparée en deux morceaux. La partie qui se trouve derrière le GPU est pourvue de 3 petites interfaces thermiques pour être en contact avec quelques composants. Nous pouvons cependant raisonnablement estimer que leur température n'augmente pas sans backplate et que Nvidia a plutôt installé ces pads thermiques pour éviter que leur température ne s'élève de trop une fois renfermés. Une fois la plaque arrière retirée, nous pouvons observer que la GTX 1080 chauffe moins qu'une GTX 980 Ti, ce qui est logique au vu de sa consommation inférieure. L'étage d'alimentation est donc très bien refroidit, même en mode 'Uber' quand les limites de consommation et de température sont poussées au maximum.  Nous lançons le test Fire Strike avec les presets standard, extrême et ultra proposés par Futuremark. [ Fire Strike ] [ Fire Strike Extreme ] [ Fire Strike Ultra ] La GeForce GTX 1080 est bien partie pour aller chercher de nouveaux records dans Fire Strike.  Après plusieurs années de bons et loyaux services, notamment en matière de mesure de l consommation, nous avons mis Anno 2070 à la retraite. Il est remplacé par Anno 2205, un peu plus lourd graphiquement mais moins gourmand énergétiquement. Nous utilisons le mode de qualité maximale du jeu mais en MSAA 4x et effectuons un déplacement sur une carte en mesurant les performances avec Fraps. Le jeu est maintenu à jour via Uplay. C'est dans ce premier jeu testé que la GeForce GTX 1080 se comporte le mieux dans notre panel. Elle affiche un gain énorme de 47% sur la GTX 980. Nous avons tout d'abord pensé à une erreur mais Nvidia nous a indiqué que quelques jeux profitaient pleinement de la puissance géométrique supplémentaire ainsi que de la compression du framebuffer améliorée et pouvaient entraîner des gains de plus de 50%. C'est visiblement le cas d'Anno 2205. En 4K, la GTX 1080 permet de jouer dans de très bonnes conditions et affiche toujours un gain très important sur la GTX 980 Ti.  Ashes of the Singularity est un des premiers jeux DirectX 12 disponible. Il a la particularité d'être conçu en terme de gameplay pour ces nouvelles API avec des scènes très lourdes qui ont besoin d'un surcoût réduit des commandes de rendu ainsi que d'une bonne exploitation des CPU multicoeurs. Par ailleurs, AotS intègre un support du multi engine destiné à booster les performances GPU, ce qu'AMD appelle Async Compute. Cette option apporte des gains sur les Radeon mais est contreproductive ou n'a pas d'effet sur les GeForce, y compris sur la GTX 1080. Nous avons utilisé la configuration par défaut du jeu qui active Async Compute sur Radeon et le désactive sur GeForce. Nous utilisons une partie du benchmark intégré avec un niveau de qualité Extreme et en mode DirectX 12. Le jeu est maintenu à jour via Steam. Comme prévu, les Radeon se comportent plutôt bien sur ce jeu, mais ce n'est pas suffisant pour empêcher la GTX 1080 de prendre le tête, même sans l'aide d'Async Compute. En 4K il faut bien entendu baisser le niveau de qualité d'un cran, les performances restent alors similaires.  Battlefield 4 repose sur le moteur Frostbite 3, une évolution de la version 2 présente dans Battlefield 3. La base du rendu reste très proche (rendu différé, calcul de l'éclairage via compute shaders) et les évolutions visibles sont mineures, DICE ayant principalement optimisé son moteur pour les consoles de nouvelle génération. Parmi les petites nouveautés, citons un support plus avancé de la tessellation et une amélioration du module "destruction" du moteur. Sur PC, un mode Mantle spécifique aux Radeon et qui permet de réduire le coût CPU du rendu est proposé mais nous ne l'avons pas utilisé pour ce test. Pour rappel, il s'agit d'une API propriétaire de plus bas niveau dédiée aux Radeon HD 7000 et supérieures, qui a été développée par AMD et DICE. Depuis l'arrivée d'autres API de bas niveau, AMD a cependant cessé les développements autour de Mantle et n'a pas optimisé son utilisation dans les pilotes pour ses derniers GPU. Nous testons le mode Ultra avec MSAA 4x et nous relevons les performances avec Fraps, sur un parcours bien défini. Le jeu est maintenu à jour via Origin. Les GeForce sont plus efficaces que les Radeon sous le Frosbite Engine avec MSAA et la GTX 1080 creuse l'écart. Compte tenu du niveau de performances élevé en 1440p, nous avons conservé exactement la même qualité graphique en 4K. La GTX 1080 augmente alors quelque peu son avance sur la GTX 980 Ti, alors que la R9 Fury X se comporte légèrement mieux. Pas de quoi inquiéter la GTX 1080 ceci dit.  Crysis 3 reprend le même moteur que Crysis 2 : le CryEngine 3. Ce dernier profite cependant de quelques petites évolutions telles qu'un support plus avancé de l'antialiasing : FXAA, MSAA et TXAA sont au programme, tout comme un nouveau mode appelé SMAA. Il s'agit d'une évolution du MLAA qui permet, optionnellement, de prendre en compte des données de type sous-pixels soit à travers la combinaison avec du MSAA 2x, soit avec une composante temporelle calculée à partir de l'image précédente. Le SMAA 1x est la simple évolution du MLAA, le SMAA 2tx utilise une composante temporelle relativement complexe et le SMAA 4x y ajoute le MSAA 2x. Notez qu'il ne faut pas confondre le SMAA 2tx proposé en mono-GPU avec le SMAA 2x proposé en multi-GPU, ce dernier utilisant du MSAA 2x sans composante temporelle. Nous mesurons les performances avec Fraps en très haute qualité avec SMAA 2tx. Le jeu est maintenu à jour via Origin. Crysis 3 est un jeu très gourmand au niveau de la puissance de calcul mais qui a aussi besoin de pas mal de bande passante, ce qui permet à la R9 Fury X de plutôt bien se comporter. Insuffisant pour inquiéter la GTX 1080. Nous baissons le niveau de qualité d'un cran, ce qui permet de se rapprocher des 60 fps sur GTX 1080.  Après une longue période en version beta, DiRT Rally est finalement sorti en version finale fin 2015. Il vient logiquement remplacer GRID 2 dans notre panel de test. Nous mesurons les performances avec Fraps sur une scène de test personnalisée qui inclut l'éclairage de nuit ainsi qu'une forte pluie, deux effets gourmands qui semblent poser problème aux Radeon alors même qu'il s'agit d'un jeu sponsorisé par AMD... Le jeu est maintenu à jour via Steam. Les Radeon souffrent et sont complétement larguées, nous attendons une réponse d'AMD concernant ce problème de performances. En 4K, nous désactivons l'Advanced Blending, ce qui fait revenir la R9 Fury X au niveau de la GTX 980 Ti de référence.  La nouvelle mouture de DOOM conserve la tradition d'un moteur graphique OpenGL, une API qui fait donc un retour dans notre suite de test. Le jeu n'est pas extrêmement gourmand, mais il est plutôt bien optimisé et atteint facilement 150 à 200 fps sur notre Core i7-5960X poussé à 4 GHz. Une version Vulkan est attendue sous peu et permettra de pousser encore plus haut les fps dans ce jeu au rythme plus que nerveux. Nous mesurons les performances avec Fraps sur un parcours bien défini. Le jeu est maintenu à jour via Steam. A noter que le jeu tourne en OpenGL 4.5 sur GeForce et en OpenGL 4.3 sur Radeon, AMD ayant un peu de retard au niveau de ses pilotes. La Radeon R9 Fury X s'en tire plutôt bien en égalant la GTX 980 Ti de référence mais la GTX 1080 pousse le niveau un cran plus haut. Le classement des cartes est similaire en 4K, si ce n'est pas que la R9 Fury X est 1 fps devant la GTX 980 Ti au lieu de 1 fps derrière. A noter que nous avons conservé une qualité maximale et que la GTX 1080 arrive presque à maintenir 60 fps dans ces conditions.  Dying Light est un jeu de type survival horror animé par le Chrome Engine 6 de Techland et dans lequel le monde est plutôt vaste et ouvert. Nvidia a travaillé avec Techland pour y inclure certains effets issus de ses librairies Gameworks tels que le HBAO+ et le Depth of Field. Nous avons mesuré les performances avec Fraps sur un parcours bien défini en qualité maximale. Le jeu est maintenu à jour à travers Steam. Dying Light souffrait de micro-saccades régulières qui impactaient fortement la fluidité sous Windows 7 et avec toutes les cartes, mais elles ont disparu lors du passage à Windows 10. Les GeForce sont plus à l'aise que les Radeon dans ce jeu. Pour jouer en 4K sur Dying Light, nous désactivons le filtrage des ombres PCSS de Nvidia, qui est relativement gourmand. De quoi s'approcher des 60 fps sur GTX 1080 et permettre à la R9 Fury X de se comporter un petit peu mieux.  Evolve, développé par Turtle Rock Studios, est basé sur le Cry Engine 3. Contrairement à ce dernier, les modes d'antialiasing à base de MSAA, extrêmement gourmands avec ce moteur, ne sont pas proposés. Un nouveau mode de SMAA a par contre été développé par Crytek et intégré dans les branches plus récentes de son moteur : le 1tx. Il s'agit d'une version quelque peu simplifiée du SMAA 2tx, antialiasing à base de composante temporelle, qui a la particularité d'être compatible avec le multi-GPU. Nous mesurons les performances à l'aide de Fraps sur un parcours bien défini et le jeu est maintenu à jour avec Steam. Les Radeon apprécient particulièrement ce titre mais la puissance de la GTX 1080 lui assure malgré tout la première place. Evolve est très gourmand en 4K, ses options graphiques ayant peu d'impact sur les performances. Nous avons opté pour le mode de qualité standard, le mode de qualité basse n'apportant pas réellement de gain. Malgré cela, impossible de s'approcher des 60 fps sur GTX 1080.  Fallout 4 repose sur une version améliorée du Creation Engine introduit avec Skyrim et développé en interne par Bethesda. Un moteur qui permet de pousser la qualité graphique vers le haut par rapport au Gamebryo exploité pour les jeux de la génération précédente dont faisait partie Fallout 3. Dans la version qui équipe Fallout 4, l'éclairage gagne en réalisme notamment avec le passage au physically-based deferred renderer et l'ajout d'une composante volumétrique pour représenter l'atmosphère. La version la plus évoluée de cet effet a été développée en collaboration avec Nvidia et fait appel à la tessellation. Au niveau de l'antialiasing les options proposées sont par contre assez pauvres avec au mieux un Temporal AA qui fonctionne plutôt bien mais uniquement en mouvement constant. A l'arrêt ce type d'antialiasing est évidemment limité dans son action. Nous testons Fallout 4 avec Fraps sur un parcours bien défini en poussant toutes les options au maximum (y compris l'éclairage volumétrique ultra). Le jeu est maintenu à jour via Steam. Les performances des Radeon sont étranges dans ce jeu avec une R9 290X qui se comporte très bien et une Fury X en retrait. Nous passons au niveau de qualité High qui permet de maintenir un rendu visuel satisfaisant et une moyenne de 60 fps sur la GTX 1080.  Dernier opus de la série, Far Cry Primal nous envoie chasser le mammouth dans la préhistoire. Il est graphiquement similaire à Far Cry 4 même si son moteur graphique a reçu quelques petites améliorations. Nous activons le niveau de qualité Ultra du jeu avec du SMAA 1x. Nous utilisons Fraps sur un parcours bien défini et le jeu est maintenu à jour via Uplay. Le positionnement des différentes cartes testées est plutôt logique dans ce jeu de plus dominé par la GTX 1080. Nous devons ici baisser assez fortement le niveau de qualité jusqu'en "Normal". La GTX 1080 doit se contente d'une moyenne de 50 fps alors que la R9 Fury X revient à un meilleur niveau en égalant la GTX 980 Ti personnalisée.  Enfin, après de nombreuses demandes, nous avons ajouté GTA V à notre protocole de test. Plutôt gourmand du côté des GPU, il propose de nombreuses options graphiques. Nous testons le jeu avec Fraps en qualité maximale à l'exception du MSAA qui reste en 2x. Le jeu est maintenu à jour via Steam. Les Radeon sont plutôt à la peine dans ce jeu. Par ailleurs elles souffrent d'un problème de fluidité avec une grosse saccade à peu près toutes les secondes, ce qui rend le jeu désagréable. La GTX 1080 domine facilement les échanges. Dans GTA V, nous nous contentons de désactiver le MSAA 2x, ce qui réduit suffisamment la charge GPU pour jouer en 4K sur GTX 1080. La R9 Fury X se positionne une fois de plus nettement mieux.  Cette dernière mouture d'Hitman, proposée sous la forme d'épisodes, a la particularité de supporter DirectX 12. Malheureusement, elle est un peu moins performante dans ce mode autant sur Radeon que sur GeForce et nous nous sommes donc contentés de la version DirectX 11. Pour mesurer les performances, nous poussons les options graphiques au niveau ultra et utilisons Fraps dans le jeu maintenu à jour via Steam. C'est le jeu dans lequel les Radeon sont le plus en forme avec une R9 290X qui égale la GTX 980 Ti. Il s'en fallait de peu pour que la R9 Fury X en fasse de même avec la GTX 1080. En 4K, nous devons passer à un niveau moyen pour la qualité graphique, ce qui permet à la R9 Fury X de surpasser la GTX 1080 !  Project Cars est un jeu de course automobile développé depuis 2011 sur base d'un système de beta participative qui permettait d'accéder aux nouvelles builds régulières et d'interagir avec les développeurs de Slightlymad Studios (à l'origine des Need For Speed Shift). Son moteur au rendu différé supporte DirectX 11 et c'est ce mode que nous avons testé en poussant toutes les options en mode High à l'exception de l'antialiasing pour lequel nous nous somme contenté du seul SMAA Ultra. Nous avons testé le jeu via Fraps sur un parcours bien défini et avec de la pluie au niveau des conditions météo. Un détail important à préciser puisqu'il réduit significativement les performances. Nous avons opté pour 7 concurrents qui restent devant nous pendant la mesure des performances. Les Radeon ont beaucoup de mal dans ce jeu très attendu et ce n'est pas nouveau. Critiqué pour avoir favorisé Nvidia, le développeur s'est justifié en expliquant que ce n'était pas du tout le cas, mais qu'AMD n'avait pas voulu collaborer en amont de la sortie du jeu pour s'assurer d'optimiser les performances. Difficile de savoir ce qu'il s'est réellement passé, mais depuis AMD a commencé à progressivement introduire quelques optimisations spécifiques dans ses pilotes, sans grand succès comme vous allez le voir. Les Radeon sont très nettement derrière les GeForce mais on peut remarquer que la R9 290X est très peu performante sans pour autant être limitée par le CPU. En 4K, nous désactivons le MSAA, type d'antialiasing qui fait souffrir la R9 Fury X en 1440p. Elle se positionne donc beaucoup mieux, au niveau de la GTX 980 Ti. La GTX 1080 permet de maintenir 60 fps. Particulièrement efficace dans ce jeu sans MSAA, le système de compression amélioré de Pascal permet à cette dernière d'afficher un gain de 43% sur la GTX 980 Ti.  Le précédent Tomb Raider était déjà plutôt réussi graphiquement, et le nouveau titre va encore plus loin. Une vraie réussite qui se traduit par une gourmandise qui peut être élevée. Les développeurs ont cette fois travaillé avec Nvidia et proposent la première implémentation du VXAO, une technique de calcul de l'occultation ambiante dérivée du VXGI spécifique aux GPU Maxwell et Pascal. Nous poussons la qualité au maximum, en dehors du VXAO dans un premier temps, et mesurons les performances sur un parcours bien défini avec Fraps. Le jeu est maintenu à jour via Steam. Les Radeon s'en tirent plutôt bien mais la GTX 1080 est hors d'atteinte. Malheureusement, nous n'avons pu faire tourner le jeu avec VXAO sur GeForce GTX 1080, un bug empêchant son lancement. Il aurait déjà été identifié et un patch serait en préparation par le développeur. En attendant, voici ce que cela donne sur les GeForce Maxwell 2 : Pour jouer confortablement avec VXAO, la puissance de la GTX 1080 ne sera pas de trop. Nous passons du niveau maximal au niveau de qualité élevé, aller plus bas réduisant un petit peu trop la qualité à notre goût. Difficile dans ces conditions de s'approche des 60 fps sur GTX 1080.  Développé par EA DICE, Star Wars Battlefront exploite comme vous vous en doutez le moteur maison Frostbite 3 qui a été introduit avec Battlefield 4. Il s'en distingue cependant par quelques petites améliorations graphiques au niveau de la tessellation pour ajouter des détails aux terrains et de l'éclairage qui gagne en réalisme et profite d'un effet d'occultation ambiante à base de compute shaders plus évolués. Star Wars Battlefront fait par contre totalement l'impasse sur le support du MSAA et se contente du FXAA ou du TAA, qui, une fois encore, se comporte plutôt bien mais uniquement lorsque les mouvements sont suffisants. Nous testons le jeu avec Fraps sur un parcours bien défini et il est maintenu à jour via Origin. Les Radeon se positionnement plutôt bien dans ce jeu mais la GTX 1080 continue de dominer facilement le match. Nous restons ici en niveau de qualité maximal et le classement des cartes reste similaire.  Nous testons le jeu en qualité maximale à l'exception des ombres qui restent en niveau élevé. Etant donné le cycle jour / nuit qui impacte les performances, nous devons utiliser le bench intégré. Nous n'utilisons cependant pas le score qu'il produit mais activons Fraps sur la partie du parcours qui correspond aux scènes de jeu, le benchmark ayant tendance à surévaluer les performances via des passages plus légers. Le jeu est maintenu à jour via Uplay. Les performances sont ici dans la moyenne avec une domination aisée de la GTX 1080. Nous activons ensuite les ombres de type HFTS (Hybrid Frustum Traced Shadows) qui font appel à des fonctionnalités actuellement spécifiques aux GeForce Maxwell 2 et Pascal pour dessiner des ombres plus nettes près des objets que les génères et faire disparaître certains artéfacts courants avec les shadow maps classiques. Avec sa puissance de calcul, la GeForce GTX 1080 permet de réellement profiter d'un tel raffinement graphique qui induit une baisse de performances de +/- 20%. Nous abaissons la qualité graphique au niveau élevé, mais ce n'est pas suffisant pour s'approcher des 60 fps sur GTX 1080.  Très attendu, le dernier opus de The Witcher ne déçoit pas. Développé par CD Projekt RED, il repose sur le REDengine 3, un moteur conçu pour gérer de vastes mondes ouverts, raison pour laquelle il tourne exclusivement en 64-bit. CD Projekt RED s'est associé à Nvidia pour intégrer deux effets gaphique de la suite Gameworks : le HBAO+ et surtout HairWorks. Réponse au TressFX d'AMD, HairWorks améliore la chevelure des personnages, la crinière des chevaux et la fourrure de plusieurs animaux ou créatures rencontrés dans le jeu en faisant appel à un niveau de tessellation très élevé pour chaque brindille. HairWorks est donc très gourmand et Nvidia aurait fait en sorte que son implémentation complique le travail d'optimisation d'AMD, ce qui n'a pas manqué de créer la polémique, même si en pratique désactiver cet effet ne dénature pas vraiment le jeu. Nous l'avons testé sans et avec HairWorks mais ce dernier mode ne fera pas partie de l'indice. A noter qu'avec HairWorks nous avons désactivé l'optimisation d'AMD spécifique à The Witcher 3 et qui force un niveau de tessellation inférieur à celui demandé par le jeu. Tous les autres paramètres sont poussés au niveau maximal. Nous effectuons un parcours bien défini avec Fraps. [ Sans HairWorks ] [ Avec HairWorks ] Sans HairWorks, le positionnement des Radeon et des GeForce est assez proche de la moyenne mais avec cet effet les performances des premières subissent un contrecoup plus important. Nous passons le niveau de qualité en Medium, ce qui permet d'afficher un compromis acceptable sur GTX 1080 en termes de performances et de qualité. Dans ces conditions, la R9 Fury X progresse dans le classement. Bien que les résultats de chaque jeu aient tous un intérêt, nous avons calculé un indice de performances en nous basant sur l'ensemble de résultats et en attachant une importance particulière à donner le même poids à chacun des jeux. Nous avons attribué un indice de 100 à la GeForce GTX 980 Ti de référence : Au terme de ce dossier, la GeForce GTX 1080 n'aura été devancée dans aucun jeu, c'est assez facilement qu'elle s'impose avec une avance de 29% sur la GTX 980 Ti de référence et, certes plus modestement, de 18% sur la version overclockée d'EVGA de celle-ci. Par rapport à la GeForce GTX 980 dont elle s'inscrit dans la lignée, le gain est bien entendu plus important et monte à 67%, ce qui est assez proche des 70% mis en avant par Nvidia et de l'augmentation théorique de la puissance de calcul et de la bande passante effective. La Radeon la plus performante du moment, la R9 Fury X, bien qu'elle se comporte assez bien sur certains jeux ajoutés à notre panel, ne peut rien faire. Elle est devancée de 38% et nous ne nous attendons pas à ce qu'AMD puisse faire mieux que celle-ci avant l'an prochain alors que les GTX 1080 customs vont enfoncer le clou. On voit par contre que le classement des 780 et 780 Ti s'est notablement dégradé, par exemple par rapport à notre protocole de septembre 2014 lors de la sortie de la GTX 980. A l'époque, la 290X Tri-X se situait entre les 780 et 780 Ti Gaming, désormais elle est au niveau de la Ti Gaming. Il en vas de même pour la 980 de référence qui était également entre les deux, un peu plus proche de la 780 Ti Gaming, et qui désormais a pris l'avantage sur la 780 Ti Gaming. Sans analyse plus poussée, il est impossible d'affirmer que cela vient d'un manque d'optimisation des pilotes ou d'une balance de la charge des derniers titres plus en défaveur d'une architecture qui pèche par son fillrate, mais en attendant les possesseurs de ces cartes en sont pour leurs frais... Avec 30% de gain sur la GTX 980 Ti et 70% sur la GTX 980, la GTX 1080 se positionne en 4K à peu près de la même manière qu'en 1440p. C'est avant tout la R9 Fury X qui se comporte beaucoup mieux lorsqu'il s'agit de calculer beaucoup de pixels avec une qualité moyenne à élevée que lorsque la qualité graphique est poussée au maximum. Alors que la GTX 1080 a une avance de 38% sur la Radeon en 1440p, elle chute à 24% en 4K. Notons cependant que dans certains jeux, les 4 Go de mémoire sur la Radeon pourront être insuffisants pour garantir une fluidité parfaite à moins de réduire la qualité des textures, mais cela annule alors l'intérêt de passer dans une telle résolution. Enfin, même sur GeForce GTX 1080, dans les jeux les plus gourmands affichés sur un écran 4K, nous estimons plus intéressant de rester en 1440p avec un niveau de qualité plus élevé plutôt que de faire des compromis sur les options graphiques pour jouer en résolution native. A moins bien entendu de passer au SLI ou de pouvoir faire quelques compromis en termes de performances grâce à un écran G-Sync. GPU Boost : pourquoi ? comment ?Nous vous en avons déjà parlé à plusieurs reprises, GPU Boost chez Nvidia et Powertune chez AMD représentent les ensembles matériels et logiciels chargés de la gestion de la consommation et de la température des GPU modernes. Ainsi, dans le cas des GeForce, c'est GPU Boost qui régule leur comportement de manière à s'assurer qu'elles restent dans les clous, c'est-à-dire qu'elles évoluent dans des conditions adaptées du point de vue de leur fiabilité et des nuisances. Les GPU AMD intègrent un moteur de gestion très avancé capable d'autoréguler le GPU à travers de nombreux capteurs internes et externes, c'est Powertune. Du côté de Nvidia, quelques petits circuits présents sur le PCB reportent au pilote, en temps réel, le niveau de consommation de la carte graphique. Cet ensemble matériel et logiciel a été baptisé GPU Boost. Le principe est le même : pouvoir proposer une carte graphique dont le GPU peut fonctionner à un niveau de spécification plus élevé que celui qu'elle est capable de maintenir dans le pire des cas. Grossièrement, au lieu de valider un GPU à une fréquence faible, par exemple 1.4 GHz, mais adaptée à tout type de charge, l'approche d'AMD et Nvidia consiste à le valider à une fréquence plus élevée, par exemple 1.8 GHz, mais qui sera réduite lorsque la charge dépasse un certain niveau. De quoi apporter un gain de performances significatif dans de nombreuses applications, dont la majorité des jeux vidéo. Pour aller plus loin, les spécialistes du GPU ont intégré dans leur analyse la prise en compte de la température GPU. Le but est double : éviter l'envolée des nuisances sonores et leur permettre de valider leurs solutions à des fréquences encore plus élevées, cette fois sans devoir prendre en compte le pire des cas au niveau de la température ambiante. De quoi offrir quelques points de performances de plus lorsque le boîtier est très bien ventilé (ou en hiver ou lorsque le testeur n'a pas le temps de laisser le GPU chauffer ). Toutes ces évolutions sont bénéfiques pour l'utilisateur : elles permettent d'obtenir plus de performances. Elles peuvent cependant être source d'abus. Par exemple, si les testeurs se laissent abuser par l'inertie thermique, ils risquent de surévaluer les performances. C'est notamment le cas lorsque des benchmarks intégrés aux jeux sont utilisés par facilité puisque les performances sont alors mesurées après une plus ou moins longue période de chargement durant laquelle le GPU est au repos. La fréquence GPU, et donc ses performances, peut être significativement différente si les performances sont mesurées au milieu d'une session de jeu. Prendre en compte cette évolution des cartes graphiques allonge significativement les périodes de tests et demande à ce que l'environnement soit contrôlé lors des comparaisons. Une carte graphique testée en hiver à 20 °C puis en été à 28 °C n'affichera pas les mêmes performances. Un autre abus possible est à chercher dans la sélection des échantillons de test. La consommation peut varier quelque peu d'un exemplaire à l'autre, la production n'étant pas uniforme, notamment au niveau des courants de fuite. Quand un exemplaire particulier de GPU consomme moins qu'un autre dans des conditions identiques, lorsque la consommation devient le facteur limitant, le moteur de gestion va l'autoriser à rester à une fréquence plus élevée. AMD, Nvidia et leurs partenaires ont ainsi l'opportunité de fournir à la presse les meilleurs échantillons, issus d'un tri plus ou moins sélectif de la production. Un détail qui, comme vous pouvez vous en douter, ne leur a pas échappé. Petite variante de cet abus, la fréquence maximale variable spécifique aux GeForce. Sur le plan technique, Nvidia a décidé depuis les GTX 600 de ne plus spécifier une fréquence maximale mais uniquement une tension maximale. La fréquence GPU évoluant différemment par rapport à la tension pour chaque échantillon, la fréquence maximale devient variable, tout comme les performances maximales. Un tri sélectif permet de gagner quelques points par rapport à la moyenne, d'autant plus si les tests sont brefs et favorisent l'application en pratique de la fréquence maximale. Enfin, la gestion du GPU et de ses limites est devenue une des variables d'ajustement compétitif les plus importantes, qui peut être actionnée en cas de déficit de performances. Par exemple, si le fabricant de la carte graphique X estime que les limites devraient être de 85 °C et de 250W mais constate que dans ces conditions il n'est pas possible lutter face à la carte graphique Y, après réflexion il pourra en conclure que finalement 95 °C et 300W c'est en fait très bien. Si AMD et Nvidia en jouent, il en va de même pour leurs partenaires. Ainsi lorsqu'un fabricant nous demande comment sa carte se comporte face au même modèle de la concurrence et que nous l'informons que c'est un petit peu moins bien sur tel ou tel point, il n'est pas rare d'obtenir une réponse du type "Attendez, ne publiez pas le test comme ça, je vous envoie un BIOS dont vous me direz des nouvelles ! Top performances ! Bon par contre je vous demande de ne pas l'utiliser pour les mesures de bruit, cet aspect n'a pas été optimisé, mais ce sera nickel quand il sera rendu public, c'est promis." Les paramètres de gestion d'une carte graphique représentent un compromis global qui lie entre eux différents aspects de son comportement tels que les performances, les nuisances sonores, la température du GPU et des autres composants, la consommation Si un point est modifié, cela ne peut se faire sans conséquence sur au moins un autre point. Si les performances augmentent, les nuisances sonores et/ou la température GPU aussi. Si les nuisances sonores baissent, soit la température augmente, soit les performances baissent. Etc. Quelle solution pour la presse technique ?La parade pourrait être pour la presse de se fournir exclusivement dans le commerce et de tester à chaque fois plusieurs échantillons (3 ? 5 ? 10 ? de lots différents ?). Que ce soit en termes de coûts, s'il faut systématiquement acheter plusieurs cartes, ou de temps, s'il faut en tester de nombreux exemplaires, ce n'est malheureusement pas réaliste. Nous essayons ainsi pour notre part de prendre en compte autant que possible le comportement du système de gestion dans nos protocoles de tests, nos analyses et nos conclusions. Cela implique de prendre le temps de le comprendre, ce qui n'est pas toujours évident, AMD et Nvidia refusant en général de communiquer à son sujet au-delà de quelques détails grossiers, dans certains cas incorrects puisque dictés par des impératifs de communication qui n'ont que faire de la réalité technique. Nous effectuons dès lors de très nombreux tests pour en savoir plus et, à chaque lancement de GPU, nous harcelons autant AMD que Nvidia pour plus de clarté à ce sujet, grignotant par-ci par-là un petit détail à force d'insistance ou lorsqu'ils se retrouvent face à des données qui pourraient leur causer du tort. En cas de doute ou si nous avons des indices qui pointent vers des performances potentiellement surévaluées à la suite d'un tri très sélectif, nous faisons en sorte de nous pencher sur des exemplaires issus du commerce. Des freins bienvenusMalgré toutes ces possibilités d'abus qui compliquent le travail des testeurs (à moins de faire en sorte de fermer les yeux sur cette problématique), la gestion de la consommation avancée des GPU, mise en avant en tant que "turbo", est globalement une très bonne chose pour l'utilisateur. Un utilisateur qui peut cependant avoir l'impression, à tort, qu'il est anormal d'observer des baisses de fréquence significatives lors de sessions de jeu. Cette incompréhension est à chercher du côté de la communication autour de ces technologies : il ne s'agit pas vraiment de turbos mais plutôt de freins. Une réalité moins facile à vendre sur le plan commercial, qui explique en grande partie pourquoi AMD et Nvidia se contorsionnent pour éviter de décrire trop clairement leurs systèmes de gestion des GPU. Grossièrement, que ce soit GPU Boost chez Nvidia ou Powertune chez AMD, l'approche est la même : le GPU part de sa fréquence maximale et freine si nécessaire pour rester dans les clous en terme de sécurité, de fiabilité et de nuisances. La baisse de la fréquence GPU, ou le "throttling" en anglais, n'est pas une anomalie. C'est un phénomène voulu qui, en fin de compte, autorise plus de performances avec une limitation des nuisances. Ceci étant dit, un problème ou un défaut de conception peut causer une baisse de fréquence plus importante et, au contraire, un effort supplémentaire des fabricants de cartes graphiques au niveau de la capacité du ventirad et de l'étage d'alimentation peut limiter cette baisse. AMD et Nvidia ont la possibilité de mettre en place une fréquence limite, en général appelée fréquence de base pour renforcer "l'effet turbo", sous laquelle ils estiment qu'il faut éviter de descendre. Pour ne pas trop pénaliser les performances ils peuvent alors prévoir leurs cartes graphiques pour accepter automatiquement des compromis différents, que ce soit au niveau de la fiabilité ou des nuisances. Par exemple, si les GeForce sont descendues jusqu'à un certain niveau de fréquence, Nvidia laisse la température du GPU s'apprécier au-delà de la limite fixée. Une approche qui permet de garantir un certain niveau de performances dans un maximum de situations (pas dans toutes, la fréquence GPU reprend sa chute au-delà d'un nouveau seuil). GPU Boost en pratiqueComme les précédentes GeForce GTX, la GTX 1080 exploite une technologie de turbo et de contrôle de ses paramètres vitaux : GPU Boost. Il fonctionne de la sorte dès qu'une application est lancée :
Lorsque les GPU GeForce sont produits par Nvidia, ils sont testés à un moment donné pour vérifier s'ils sont totalement ou partiellement fonctionnels ainsi que pour leur attribuer différents paramètres tels que les fréquences et tensions. Nvidia ne donne aucun détail à ce niveau, mais nous pouvons supposer que les tests effectuées permettent de déterminer quelques couples de tensions et fréquences, avec une marge de sécurité suffisante pour assurer la fiabilité. Ces paramètres sont inscrits dans le GPU. Ensuite, d'autres paramètres sont spécifiés dans le BIOS, c'est le cas de la fréquence de base et de la tension GPU maximale. Le pilote exploite ces quelques paramètres pour en extrapoler une courbe de couples tension et fréquence qui sera utilisée par GPU Boost pour moduler la consommation et les performances. Voici à quoi ressemble cette courbe, avec en exemple une GTX 980, mais c'est le même principe avec la GTX 1080, simplement avec une courbe plus longue compte tenu de sa fréquence élevée : 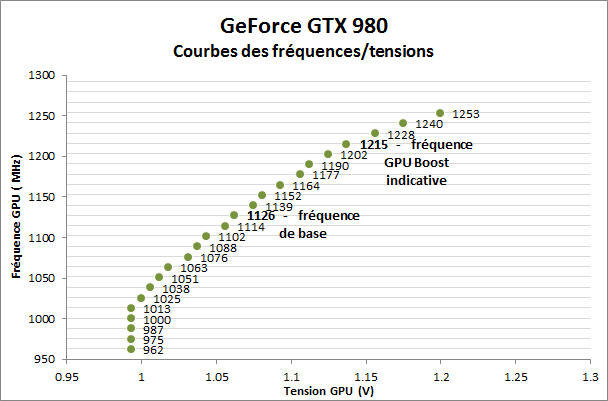 Nous pouvons y observer une vingtaine de valeurs entre lesquelles les performances vont évoluer. Nous avons fait ressortir la fréquence de base et la fréquence GPU Boost officielle. Vous remarquerez que celle-ci n'est pas la fréquence maximale. Il s'agit en fait d'une valeur factice spécifiée dans le BIOS de manière à pouvoir être affichée par exemple dans GPU-Z. Elle n'est exploitée ni pour définir la courbe, ni pour définir le comportement de GPU Boost. Au bas de la courbe, il y a une tension minimale sous laquelle le GPU ne descend jamais. La fréquence peut continuer à chuter, mais la tension reste alors figée. La fréquence maximale est déterminée par le point correspondant à la tension maximale autorisée dans le bios, elle est de 1.2125V pour l'ensemble des GTX 980/970 et de +/- 1.1V pour les GTX 1080. Il faut cependant noter qu'il n'y a pas de fréquence spécifiée à chaque niveau de tension, notamment dans le haut de la courbe, c'est alors la valeur inférieure la plus proche qui fait officie de limite pratique. La tension maximale du GPU peut ainsi varier entre 1.9V et 1.2125V suivant l'échantillon. La couple le plus élevé pour notre exemplaire est de 1.2V et 1253 MHz, sa courbe ne dispose pas de fréquence spécifiée pour 1.20625V et 1.2125V. La courbe étant générée sur base de paramètres spécifiques à chaque GPU, elle est différente pour chacun d'entre eux. Voici par exemple les courbes de 3 GeForce GTX 970 cadencées aux mêmes fréquences de référence : 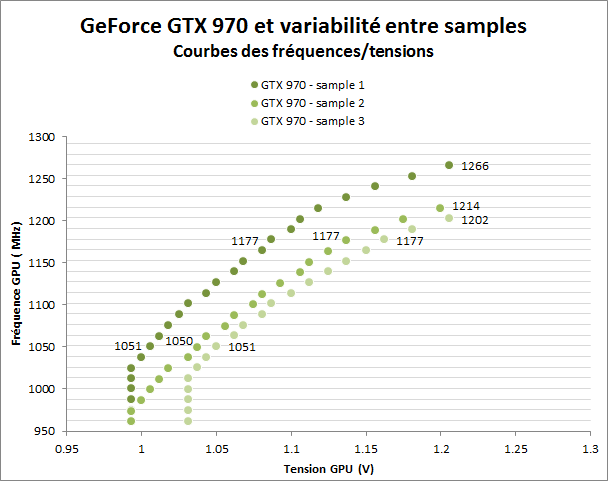 Tensions minimales, tensions maximales et fréquences maximales varient. Le premier échantillon est clairement le meilleur, il a besoin d'une tension inférieure pour chaque niveau de fréquence. Alors que les 3 cartes sont annoncées avec une même fréquence GPU Boost de 1177 MHz, un échantillon culmine en réalité à 1202 MHz, un autre à 1214 MHz et le meilleur à 1266 MHz. Un écart de 5% qui pourra se retrouver dans les performances en jeu. A noter qu'il est très bien visible sur ce second graphe que les derniers paliers de fréquence sont atteints avec un bond grandissant au niveau de la tension. Ils entraînent ainsi une augmentation de la consommation toujours plus importante, ce qui explique pourquoi ils peuvent être difficiles à maintenir lorsque les limites de consommation et de température sont strictes. Comment cette courbe est-elle affectée par l'overclocking ?Un graphique pour résumer le tout : 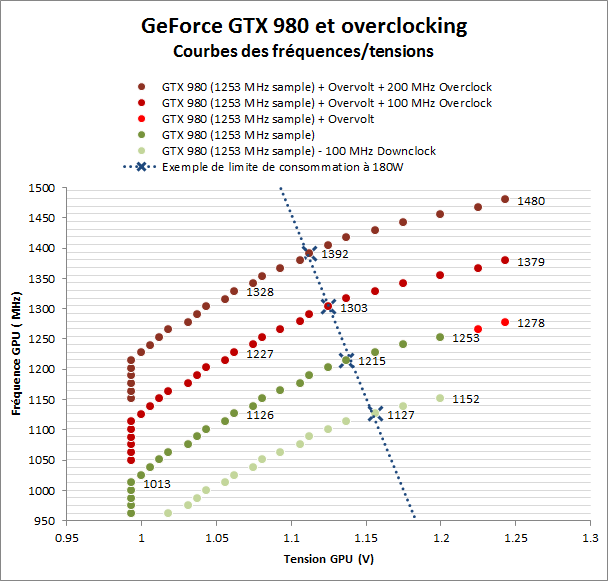 Tout d'abord, intéressons-nous brièvement à la fonction d'overvolting proposée par Nvidia. Elle consister à autoriser une tension maximale plus élevée et revient donc à prolonger légèrement la courbe des fréquences, si des fréquences sont disponibles pour les nouvelles tensions. Notre GTX 980 gagne ainsi deux paliers et peut passer de 1253 à 1278 MHz avec une tension de 1.2425V. Certaines cartes par contre ne profiteront d'aucun gain si elles ne disposent pas sur leur courbe de fréquences associées à ces tensions plus élevées. L'overclocking du GPU consiste en un offset ou biais appliqué à la totalité de la courbe des fréquences d'origine. Chaque palier progresse par exemple de 100 ou 200 MHz et pas seulement la fréquence maximale. Cela signifie que l'overclocking a de l'intérêt même quand les limites empêchent le GPU de tourner à sa fréquence maximale. Un offset positif revient à réduire la tension GPU pour chaque niveau de fréquence et augmente le rendement énergétique. A l'inverse un offset négatif impacte le rendement énergétique et n'a donc aucun intérêt à être utilisé. Pour illustrer cela, nous avons relevé la fréquence à laquelle cette GTX 980 se stabilise lorsqu'une charge stable de 180W est exécutée avec ces différents offsets. Si nous appliquons un offset de 100 MHz, la fréquence observée passe de 1215 à 1303 MHz, soit un net gain à consommation égale qui profitera au rendement énergétique en plus de booster les performances. Quelques détails de plusNous n'avons pas pu en déterminer le mécanisme exact, mais il existe quelques restrictions de plus au niveau de la gestion des fréquences et tensions. D'après nos observations, GPU Boost empêche l'accès aux derniers niveaux de tension et de fréquences lorsque la température et/ou la charge atteignent certaines valeurs inférieures aux limites de température et de consommation classiques. Il s'agit pour Nvidia d'une part d'éviter autant que possible le fonctionnement du GPU à une tension et à une température élevé, deux éléments qui ne font pas bon ménage puisqu'ils impactent la fiabilité des puces. Nvidia semble cependant être extrêmement conservateur sur ce point. D'autre part cette approche permet de freiner la montée en température du GPU et donc de lisser plus facilement la courbe de ventilation. Par exemple, si une carte donnée dispose d'une fréquence à un niveau de tension élevé, mais que la charge exécutée est lourde alors que la température GPU monte au-delà de 75 °C, cette fréquence ne sera pas exploitable. Le GPU redescendra au niveau inférieur, avec un impact mineur sur les performances. Ce phénomène était limité à un ou deux paliers sur GTX 900, mais il prend de l'ampleur sur la GeForce GTX 1080. Voici ce que nous avons pu observer en poussant ses limites de consommation et de températures à leur valeur maximale pour qu'elles n'aient pas d'influence : 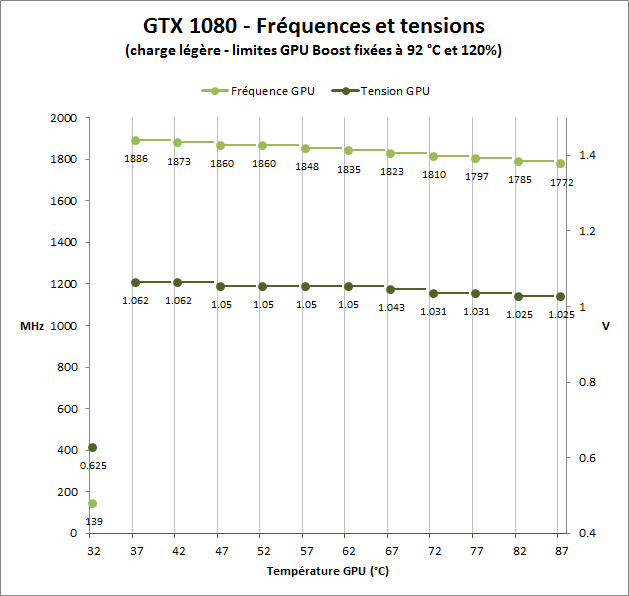 A notre grand étonnement, Nvidia applique cette stratégie dès 37 °C ! Nous avons du mal à comprendre pourquoi Nvidia enclenche cet algorithme à un niveau de température si bas sur cette nouvelle GeForce, mais c'est bel et bien le cas. Pour que le GPU puisse atteindre sa fréquence maximale, en plus de ne dépasser aucune limite, il doit donc rester sous les 37 °C. Ensuite, tous les 5 °C, il redescend d'un cran supplémentaire. Avec un système de refroidissement calibré pour stabiliser la fréquence GPU à 82 °C, notre échantillon de GTX 180 Founders Edition ne pourra donc jamais profiter de sa fréquence maximale de 1886 MHz et sera toujours limité au mieux à 1797 ou 1785 MHz. Comment est mesurée la consommation ?Avec GPU Boost, Nvidia ne protège pas le GPU de manière directe comme le fait AMD en mesurant sa consommation. Nvidia le fait de manière indirecte en mesurant la consommation totale de la carte graphique. C'est moins précis au niveau du GPU (la mesure englobe la consommation des autres composants, les pertes liées à l'étage d'alimentation etc.), mais cela a l'avantage de pouvoir protéger la carte dans son ensemble et de s'assurer que les normes d'alimentation soient bien respectées. Les GeForce GTX sont équipées d'un petit circuit de mesure de l'intensité du courant pour chacune des entrées 12V présentes sur le PCB. Typiquement :
La consommation en 3.3V est ignorée, mais elle n'est pas très importante au vu de la consommation totale de ces cartes (1 à 5W). Le BIOS des GeForce GTX contient une limite de consommation globale (la somme des 3 lignes 12V) ainsi qu'une limite pour chacune des lignes 12V. Typiquement, ces dernières sont fixées à hauteur des normes PCI Express : 66W via le bus, 75W pour un connecteur 6 broches et 150W pour un connecteur 8 broches. Un taux d'utilisation est calculé pour chaque ligne 12V ainsi que par rapport à la limite de consommation globale. Les outils de monitoring dérivés de RivaTuner reportent une valeur de consommation en % qui correspond au plus élevé des 4 taux de consommation, sans qu'il soit possible de savoir duquel il s'agit. Par exemple une carte limitée parce qu'elle affiche 100% de consommation peut en réalité consommer relativement peu, mais tirer trop de courant au niveau du bus. En général, si les étages d'alimentation sont bien conçus, avec une forte charge, c'est toujours le taux de consommation global qui est le plus élevé. C'est presque toujours le cas sur les cartes de référence Nvidia. Le taux affiché par GPU-Z est par contre toujours le taux de consommation global de la carte graphique. Nvidia Inspector de son côté reporte les deux valeurs : le taux de consommation global (nommé GPU Power !?!) et le taux le plus élevé des quatre (nommé Board Power ?!?). Que peuvent personnaliser les fabricants ?Les partenaires de Nvidia ont la possibilité de personnaliser différents paramètres à commencer bien entendu par les fréquences. Ils ont la possibilité de définir ou pas une marge de manoeuvre pour la fonction d'overvolting GPU Boost en spécifiant une tension maximale à cet effet. Il est possible de proposer une augmentation classique de la tension GPU, mais les fabricants doivent le faire en dehors du cadre défini par Nvidia, généralement via des composants additionnels. Ils peuvent également revoir à la hausse la limite de consommation pour donner plus de marge de manoeuvre au GPU et s'assurer qu'il reste à une fréquence élevée même en charge très lourde. Ils modifient alors la limite totale, mais peuvent également augmenter les limites de chaque ligne 12V s'ils le souhaitent. Ils peuvent modifier au passage la marge de manoeuvre donnée à l'utilisateur pour augmenter la consommation maximale. Nvidia autorise par exemple de relever la limite globale de 25% sur la GTX 980 de référence, alors que certains partenaires se contentent de 6%. Ils n'ont par contre pas le droit de modifier la limite de température fixée par Nvidia, ni la marge de manoeuvre donnée à l'utilisateur pour relever la température maximale. Pas question donc pour un fabricant de passer la limite à 90 °C pour éviter que le GPU ne voie sa fréquence réduite en chauffant. Nvidia nous a indiqué que cette mesure était destinée à garantir la durée de vie des GPU et à pousser ses partenaires à prendre le problème dans l'autre sens : installer des systèmes de refroidissement performants. Maintenir le GPU à moins de 80 °C, voire moins, permet de maintenir une fréquence turbo plus élevée. Enfin, les fabricants doivent bien entendu calibrer la courbe de ventilation en faisant en sorte d'opter pour un bon compromis en termes de température GPU et de nuisances sonores. A ce petit jeu, tous ne sont pas aussi habiles, certains peuvent faire des choix radicaux qui ne sont pas des plus adaptés. Par exemple en faisant exploser les nuisances sonores pour éviter de dépasser 60 °C. A noter que les partenaires ne sont pas les seuls responsables des paramètres de leurs cartes. Ils doivent proposer ces paramètres à Nvidia, qui doit signer les BIOS. C'est Nvidia qui a le dernier mot et peut les adapter si ses ingénieurs l'estiment nécessaire. Pour Nvidia il s'agit d'assurer une qualité cohérente pour l'ensemble des GeForce même si certains fabricants ne sont pas toujours d'accord avec d'éventuelles restrictions forcées sur leurs produits et estiment que certaines marques sont privilégiées lorsque ces décisions sont prises. Après cet énorme rappel concernant GPU Boost, il est temps de passer aux spécificités de l'overclocking de la GeForce GTX 1080. Comme pour les précédentes GeForce GTX, plusieurs paramètres sont actionnables :
Pour mettre en place un overclocking et vous assurer de sa stabilité, nous vous conseillons de toujours pousser ces deux derniers paramètres à leur valeur maximale. Vous pourrez la ramener à leur valeur d'origine par la suite. L'overclocking basique consiste ensuite à appliquer un offset, tout d'abord sur la mémoire. Pour la GTX 1080 il est exprimé étrangement puisqu'il ne prend pas en compte le passage au QDR pour la GDDR5X. Ainsi, appliquer un offset de 500 MHz sur la GDDR5X la fera passer d'une valeur de 5000 à 5500 MHz, ce qui correspond à un débit de 11 Gbps au lieu de 10 Gbps ou à une fréquence appliquée aux modules de 1375 MHz au lieu de 1250 MHz. Du côté du GPU, l'offset appliqué revient à déplacer la courbe des fréquences / tension, comme expliqué en page précédente. Nous y avons cependant pris l'exemple de la GTX 980, plus simple. Sur une GTX 1080, l'amplitude est beaucoup plus élevée entre la fréquence maximale et les fréquence au niveau desquelles la carte évolue en pratique. Déterminer un offset maximum stable peut donc être très difficile. Nous avons nous-mêmes passé pas mal de temps à la déterminer (à ce sujet c'est Ashes of the Singularity en DX12 qui s'est avéré être le jeu le plus dur à stabiliser). N'importe quel niveau de tension peut être source d'instabilité et suivant leur lourdeur, tous les jeux vont se maintenir à un niveau de tension différent, voire alterner sans cesse entre différents niveaux. Face à cette problématique Nvidia apporte de nouvelles possibilités d'overclocking sous la bannière GPU Boost 3.0 : 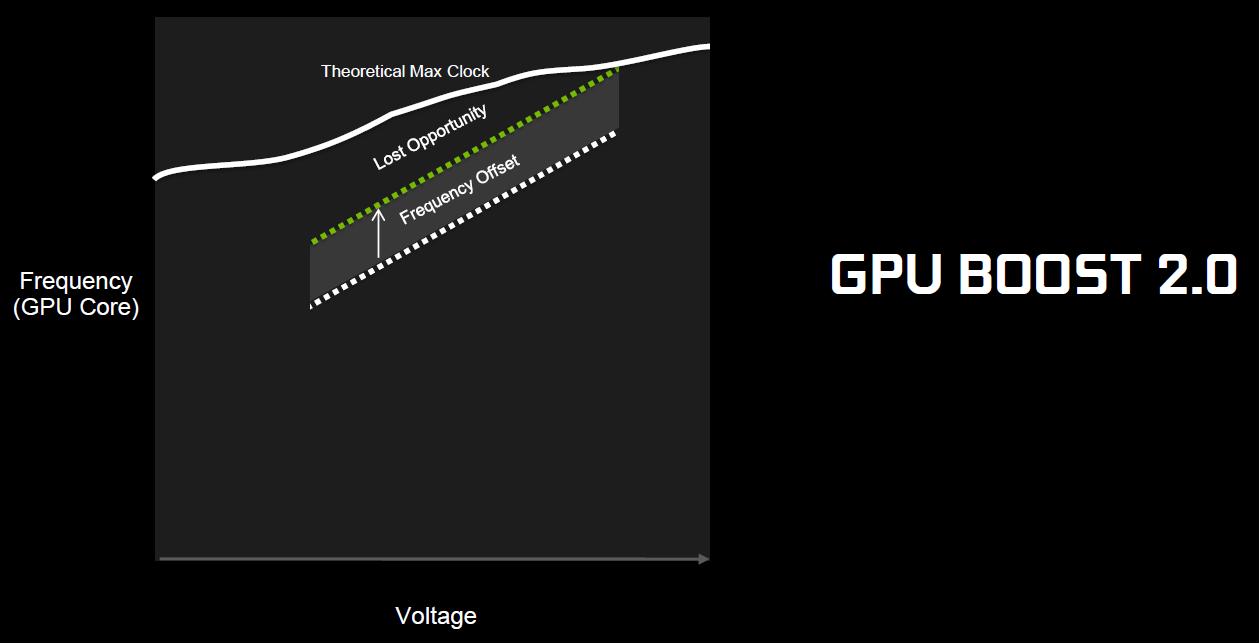 [ GPU Boost 2.0 ] [ Nouvelle option de GPU Boost 3.0 ] Au lieu d'appliquer un offset à toute la courbe de fréquences, il devient possible de spécifier un offset différent pour chaque niveau de tension ! Un travail de précision qui demande cependant du temps et beaucoup de patience. Heureusement, à moins que votre but premier ne soit de jouer à GPU Boost, Nvidia a travaillé avec EVGA pour intégrer à Precision X un outil dédié à déterminer ces fréquences à votre place. Nous avons pu en essayer une version beta, mais elle s'avère actuellement plutôt instable. A terme le but est de pouvoir laisser le logiciel tester, avec une petite marge de sécurité, tous les niveaux de fréquence pour chaque tension. Un processus qui pourra prendre un certain temps, probablement au moins 30 minutes. EVGA en a profité pour ajouter un autre mode : un offset linéaire. Pour ce dernier, il suffit de spécifier un offset pour le niveau de tension maximal et le logiciel en génère une fonction linéaire en partant d'un offset de 0 par le niveau de tension minimal. Une approche conservative au niveau de la stabilité mais qui ne permet pas de profiter de tout le potentiel de la carte en termes de performances. Voici à quoi cela ressemble : 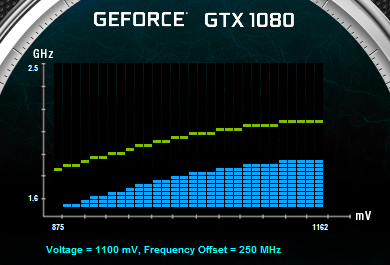 [ Offset fixe classique ] [ Fonction linéaire ] [ Offset personnalisé par tension ] L'overclocking de notre GTX 1080Dans le cadre de ce test, nous nous sommes contentés d'un overclocking classique. Etant donné que la GTX 1080 reste toujours sous sa fréquence maximale principalement pour des raisons liées à la température GPU, nous n'avons pas jugé utile d'actionner le levier de l'overvolting. Nous avons pu stabiliser le GPU avec un offset fixe de 184 MHz, un overclocking de +/- 10% qui pousse la fréquence maximale à 2070 MHz. La plupart des jeux étaient stables au-delà (jusqu'à 233 MHz pour 3DMark), mais pas tous. Quant à la mémoire nous avons pu appliquer un offset de 500 MHz, soit une augmentation de 125 MHz qui correspond là aussi à un overclocking de 10%. La mémoire était presque stable à +600 MHz mais les performances étaient alors en baisse probablement suite à des corrections d'erreurs trop nombreuses. Nous avons également mesuré les performances de la carte en mode 'Uber', c'est-à-dire sans overclocking mais avec ses limites de consommation et de température poussées au maximum. Voici ce que cela donne tout d'abord dans Fire Strike : [ OC - Fire Strike ] [ OC - Fire Strike Extreme ] [ OC - Fire Strike Ultra ] Ensuite sur l'ensemble de notre protocole : [ Performances (%) ] [ Performances (fps) ] En mode Uber, la GTX 1080 gagne de 1 à 6% suivant les jeux, avec une moyenne de 2.7%. Un gain est quasiment exclusivement lié au rehaussement de la limite de la température. L'overclocking permet de gagner de 4 à 11% de plus pour un gain combiné de 6 à 16% avec une moyenne de 11.7%. C'est similaire à ce que permettent de gagner de nombreuses GeForce GTX 980 Ti personnalisées mais cela reste quelque peu en deçà de ce dont en sont capables les modèles les plus lourdement armés. Pour aller plus loin au niveau de l'overclocking, la GeForce GTX 1080 aura besoin d'une limite de consommation revue à la hausse mais surtout d'un système de refroidissement costaud capable de maintenir le GPU au frais à pleine charge, idéalement sous les 70 °C, afin d'avoir accès à des couples de tension/fréquence plus élevés. Fréquences relevéesEnfin, pour terminer, voici un tableau qui récapitule les fréquences moyennes approximatives soutenues que nous avons pu observer durant nos mesures de performances : La fréquence maximale de notre échantillon de GTX 1080 est de 1886 MHz, mais en pratique dans les jeux elle se stabilise après quelques minutes entre 1645 à 1784 MHz selon les cas. En mode Uber, GPU Boost limite moins le GPU (mais il limite quand même, voir la page précédente) qui tourne alors entre 1772 et 1797 MHz. Après overclocking, la fréquence GPU monte d'un cran et varie entre 1911 à 1974 MHz selon les cas, contre une fréquence maximale de 2070 MHz. Sur base de tous ces chiffres, nous avons calculé une fréquence moyenne, qui vaut ce qu'elle vaut puisqu'il s'agit d'une approximation basée sur des approximations, mais qui permet de nous faire une idée du comportement des différents GPU par rapport à leur fréquence maximale. Notre exemplaire de GTX 1080 affiche alors une moyenne de 1708 MHz qui est plutôt proche de la fréquence GPU Boost officiellement communiquée par Nvidia. Cela représente 90,6% de la fréquence maximale. C'est à ce niveau moins bien que les GTX 980 et GTX 980 Ti. Une fois les limites de consommation et de température relevées, que ce soit avec ou sans overclocking, la GTX 1080 monte à 94.5% de sa fréquence maximale. Un chiffre cette fois comparable à celui de la GeForce GTX 980 Ti de référence. Avec le GP104, Nvidia propose un premier GPU 16nm offrant des performances impressionnantes étant donné la taille de la puce. Les fréquences atteintes n'y sont pas étrangères et permettent à la GeForce GTX 1080 d'afficher un gain de performance important par rapport à la GeForce GTX 980 et notable face à la GTX 980 Ti, même si elle a plus fort à faire face aux modèles customs de cette dernière. Le tout se fait avec une consommation qui reste stable en charge face à la GTX 980, une quantité de mémoire doublée avec 8 Go de GDDR5X et de nouvelles fonctionnalités intéressantes, notamment du côté de la VR.  Sur le plan technique, c'est donc un quasi sans faute pour Nvidia et un must pour les joueurs fortunés. Tout juste pourrons nous regretter de ne pas observer de gains probants dans le premier jeu capable d'exploiter DirectX 12 pour booster les performances GPU. Nvidia promet de meilleurs résultats dans d'autres titres à venir, ce que nous ne manquerons pas de vérifier. Mais, il fallait s'y attendre, avec une position déjà dominante sur le marché haut de gamme, Nvidia n'a malheureusement aucune raison d'être agressif côté tarifaire et positionne la GTX 1080 dans la version "Founders Edition", soit la carte de référence, à 790 TTC, rien que ça ! Si côté dénomination la GTX 1080 succède à la GTX 980, côté tarifaire elle se positionne donc plutôt en remplaçante de la GTX 980 Ti ! Les premières cartes personnalisées, qui suivront de peu, devraient débuter pour leur part à 670 mais il reste à voir ce qui sera proposé par les partenaires de Nvidia à ce tarif.  A moins d'être adepte des modèles à turbine et de ne pas regarder à la dépense, il parait donc opportun de ne pas se jeter sur le modèle de référence lors de sa disponibilité le 27 mai mais plutôt d'attendre de voir ce que donneront les modèles personnalisés et surtout ceux de la GeForce GTX 1070 qui débarqueront à partir du 10 juin. Certaines cartes ne devraient pas manquer de profiter de la marge d'overclocking, qui reste conséquente malgré les fréquences de base élevées, pour offrir un surplus de performance notable, quitte à pousser la consommation vers le haut. Côté AMD, on devrait également en savoir plus en juin même si il parait clair que Polaris visera un cran plus ou moins important en-dessous d'un point de vue performance et jouera donc probablement la carte du rapport performance/prix. Ceux qui attendent un vrai bond en performance pour remplacer une GTX 980 Ti par exemple devront plutôt attendre l'arrivée d'un "gros" GPU 16nm combinant HBM2. Il faudra pour cela a priori attendre l'an prochain, que ce soit côté Nvidia qui a là encore dégainé en premier mais avec un GP100 réservé aux Tesla ou côté AMD qui prévoit de lancer Vega en 2017. D'ici là, la première place du podium semble garantie à Nvidia ! Copyright © 1997-2026 HardWare.fr. Tous droits réservés. |