
Les contenus liés au tag Pascal
Afficher sous forme de : Titre | FluxGTC: Volta & Parker retardés, le 16nm TSMC responsable?
GTC: Nvidia annonce Pascal: NVLink, stacked DRAM, 2016
Pour quand les GPU Pascal et Polaris ?



A moins d'être en hibernation depuis quelques mois, vous savez probablement que l'année 2016 sera marquée par l'arrivée de deux nouvelles architectures GPU, avec d'un part Polaris chez AMD et de l'autre Pascal chez Nvidia. Ces architectures ont en commun l'utilisation de nouveaux procédés de fabrication, que ce soit le 14nm LPP chez Samsung / GlobalFoundries ou le 16nm FinFET+ chez TSMC, qui combinés avec les nouvelles mémoires (HBM2, GDDR5X) et les raffinements architecturaux promettent un gain important en terme de performances.

Côté AMD, Polaris a été évoqué officiellement à l'occasion du CES en ce début d'année. L'accent a notamment été mis sur un saut historique de la performance par watt, et deux puces seraient prévues, Polaris 10 et Polaris 11. L'une est prévue pour des livraisons à compter de mi-2016, il s'agit d'une puce de relativement petite destinée aux PC compacts et aux portables et qui sera associée à de la GDDR5. L'autre, plus grosse, serait destinée au haut de gamme et pourrait faire appel à la HBM2 mais aucun détail n'a été donné pour ce qui est de la date de commercialisation.

Chez Nvidia, Pascal fait les titres depuis longtemps puisqu'il en a été question dès la GPU Technology Conference qu'il a organisé en 2014. Le GTC 2015 en mars dernier a été l'occasion de quelques précisions, Nvidia mettant en avant une puissance de calcul par watt doublée (et même quadruplée grâce au FP16) ainsi qu'une capacité et une bande passante mémoire en forte hausse grâce à la mémoire 3D (la HBM2 en pratique). Lors du CES, Nvidia n'a évoqué Pascal que pour le Drive PX2 et n'en a pas fait de démonstration contrairement à son concurrent : il faudra probablement attendre le GTC 2016 en avril prochain, ou au mieux la GDC qui a lieu mi-mars, pour qu'il en dévoile plus.
A quelle date faut-il s'attendre à voir débarquer ces GPU ? De part et d'autre c'est le grand secret, sauf pour l'entrée de gamme chez AMD, autant pour ne pas donner d'indication à son (unique) concurrent que pour de ne pas impacter négativement les ventes de la génération actuelle. Ces derniers jours une "roadmap" établie sur la base de rumeurs et autres déductions, remplie de points d'interrogations et publiée à l'origine sur un site japonais a fait le tour de nombreux sites sans que les pincettes de rigueur soient de mise, voire parfois en laissant penser qu'il s'agissait d'une véritable roadmap. Il était notamment question sur ce document d'un premier gros GPU Pascal, GP100, lancé en avril lors de la GTC puis d'un second GPU, GP104, qui aurait fait son apparition en juin au Computex sous la forme d'une GeForce GTX 1080.
On ne peut malheureusement pas accorder de crédit à ces informations. Il faut bien admettre que Nvidia comme AMD gardent bien le secret pour la génération à venir, et les seules bribes d'informations qui nous parviennent laissent plutôt à penser que leur disponibilité interviendra au troisième trimestre, alors qu'initialement nous comptions plutôt sur le second trimestre. Mais il est tout à fait possible que l'un ou l'autre masque au maximum son jeu pour avoir un effet de surprise lors du lancement qui ne serait pas sans retombées commerciales positives wait & see !
CES: Drive PX 2: Tegra et Pascal au pilotage
Comme l'an passé, Nvidia a consacré sa traditionnelle conférence du CES au marché automobile pour lequel la société nourrit d'importantes ambitions, notamment en ce qui concerne la conduite autonome. Traditionnellement tournée autour du SoC Tegra, cette conférence du CES a progressivement évolué des smartphones et tablettes vers l'automobile au fur et à mesure que Nvidia repositionnait ses SoC.
Probablement arrivé sur ce marché un petit peu par hasard, Nvidia en a rapidement déduit le potentiel énorme, d'autant plus face à l'échec des SoC Tegra dans le monde des smartphones. Au départ, Nvidia s'est attaqué aux systèmes multimédia et d'affichage embarqués qui peuvent profiter de son expertise au niveau graphique et vidéo. Avec à la clé quelques succès pour les SoC Tegra, mais insuffisants pour justifier tous les efforts nécessaires à la conception de telles puces. Toujours à la recherche de marchés à plus forte valeur ajoutée, se battre sur les prix avec d'autres acteurs tels que TI et depuis peu Qualcomm ne fait pas partie de sa stratégie, Nvidia se concentre dorénavant en priorité à la conduite autonome.

Cet aspect de l'évolution entreprise dans le monde des transports a d'une part besoin de plus de puissance de calcul et d'autre part d'une expertise dans le domaine du deep learning, soit de l'apprentissage progressif par un réseau de neurones artificiels (ce qui fonctionne extrêmement bien dans le cas de la reconnaissance d'éléments à l'intérieur d'une série d'images). Deux points pour lesquels Nvidia peut compter sur ses technologies et ses ingénieurs pour essayer de se démarquer.
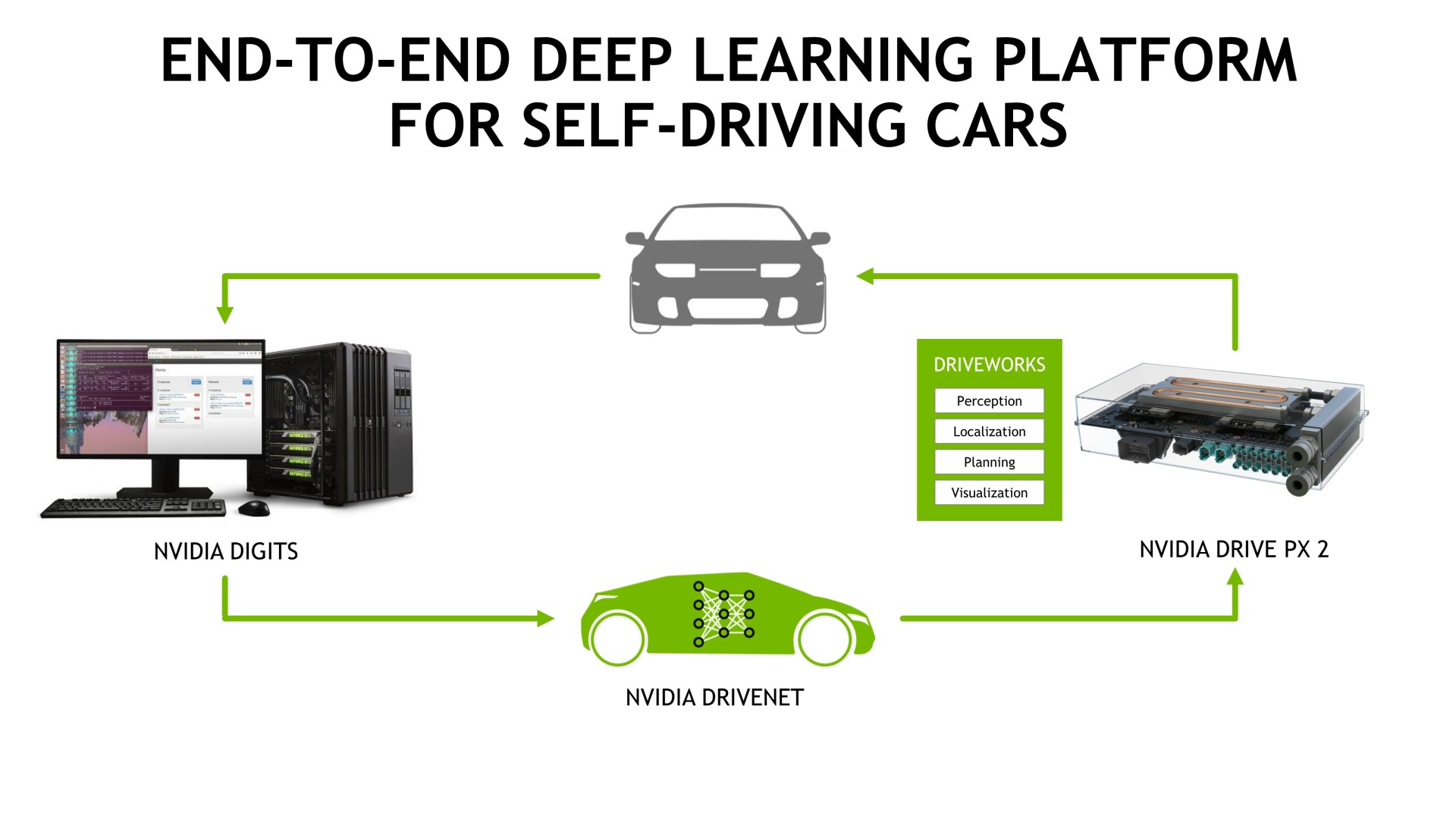
L'an passé, Nvidia a ainsi annoncé Drive PX, une plateforme de pilotage automatique bâtie autour de 2 SoC Tegra X1. Mais comme c'est devenu une tradition avec ces SoC, plusieurs annonces annuelles successives sont nécessaires avant que des résultats n'émergent éventuellement. Drive PX n'aura donc pas réellement d'existence commerciale et se contentera des rôles de kit de développement et d'illustration de la stratégie de Nvidia.
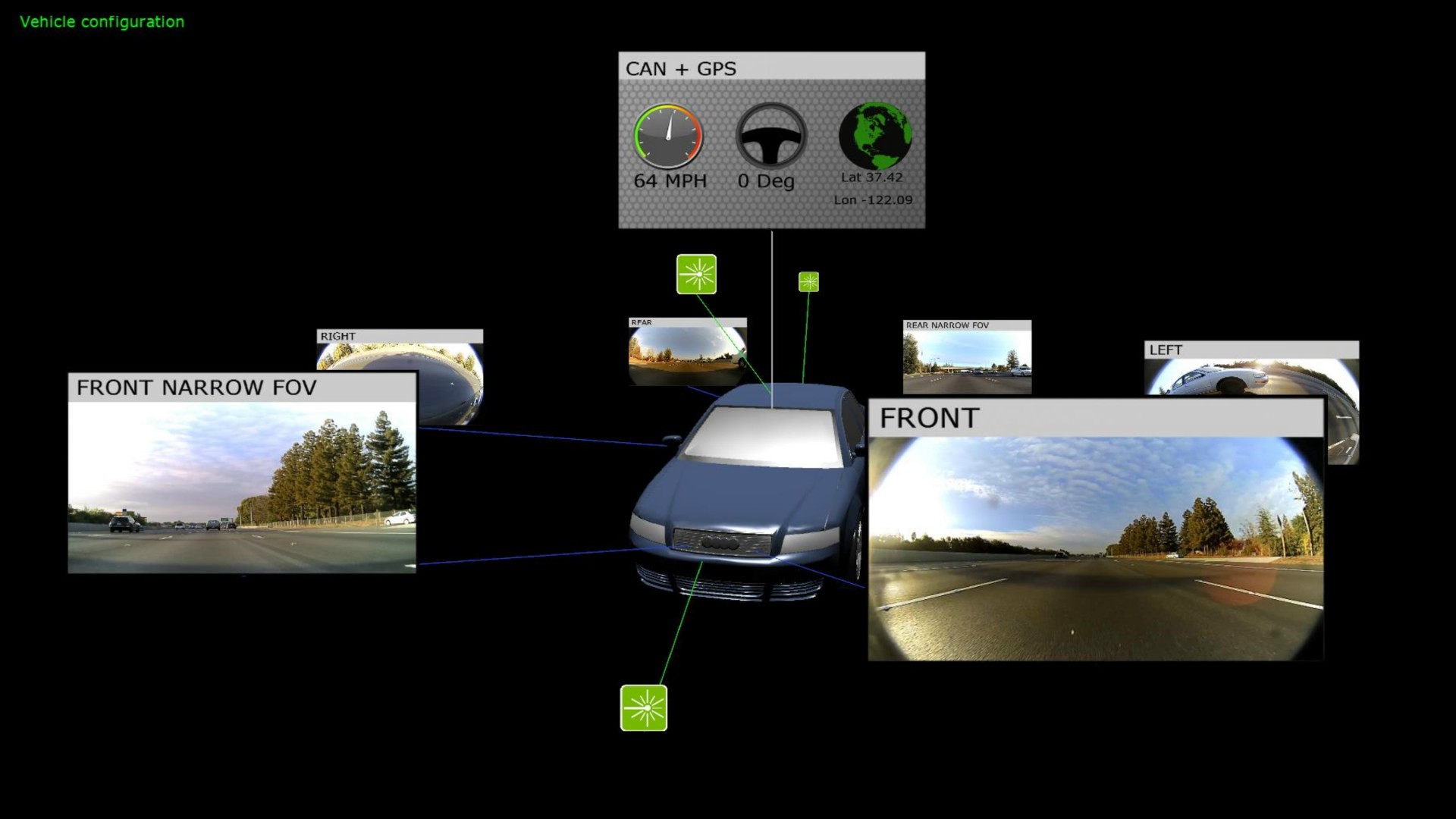
Fort logiquement, lors de ce CES, Nvidia a donc doublé la mise et annoncé son successeur, Drive PX 2, et peaufiné son angle d'attaque pour ce nouveau marché. Au cours des développements entrepris avec Drive PX, Nvidia a probablement fait le constat que sa solution n'était pas suffisamment performante, notamment au niveau des GPU Maxwell intégrés aux 2 Tegra X1 qui sont chargés de la détection des véhicules, personnes, panneaux et autres obstacles.


Pour Drive PX 2, Nvidia va toujours faire appel à 2 SoC Tegra mais d'une part il s'agira de SoC plus musclés et d'autre part ils seront accompagnés de 2 GPU dédiés ! Ces SoC seront fabriqués en 16nm FinFET et chacun équipés de 2 curs CPU Denver maison, de 4 curs Cortex-A57 et d'un GPU non précisé, qui ne sera peut-être pas exploité ici. Il est possible que ce SoC soit en fait celui qui était présenté depuis deux ans sous le nom de code Parker et qui serait donc équipé d'un GPU Maxwell.

Chacun de ces SoC sera connecté à un GPU de génération Pascal, également fabriqué en 16nm FinFET. Nvidia n'en communique pas les spécifications mais se contente de parler d'une puissance de calcul de 4 Tflops ce qui correspond à peu près à une GeForce GTX 970 et à un ensemble supérieur à la puissance de calcul d'une GTX Titan X. Et ce n'est pas tout, Nvidia annonce ces GPU Pascal comme étant 3x plus rapides dans le cadre du deep learning qu'un GPU Maxwell de puissance de calcul équivalente. Un coup de boost important qui découle probablement en grande partie du support natif des opérations en 16-bit et/ou 8-bit. A noter que les illustrations de Drive PX 2 sont basées sur un prototype équipé de GPU Maxwell GM204, ne cherchez donc pas à déduire de quelconques informations sur les futurs GPU Pascal sur base de ces photos.

Malgré le recours au 16nm FinFET, l'ensemble sera relativement gourmand et Nvidia parle de 250W. Au passage, nous pouvons ainsi imaginer grossièrement qu'un équivalent Pascal de la GTX 970 verrait sa consommation chuter de 150 à 100W. Pour refroidir l'ensemble, dont la fiabilité doit être garantie en toutes circonstances dans la cadre du pilotage d'une voiture, Nvidia a développé un système de watercooling spécifique mais les éventuels fabricants de voiture intéressés par Drive PX 2 seront bien entendu libres de mettre en place leur propre solution.
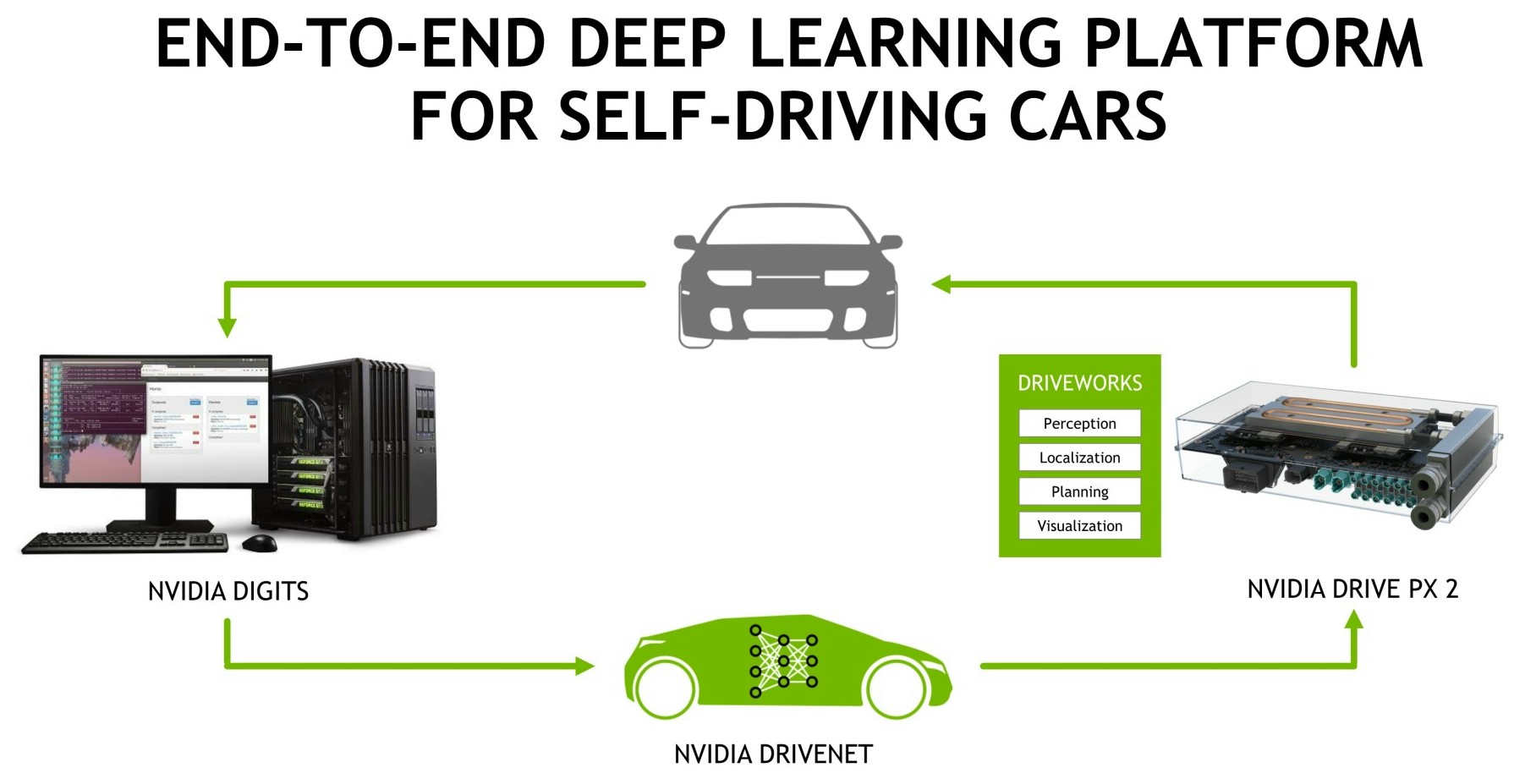
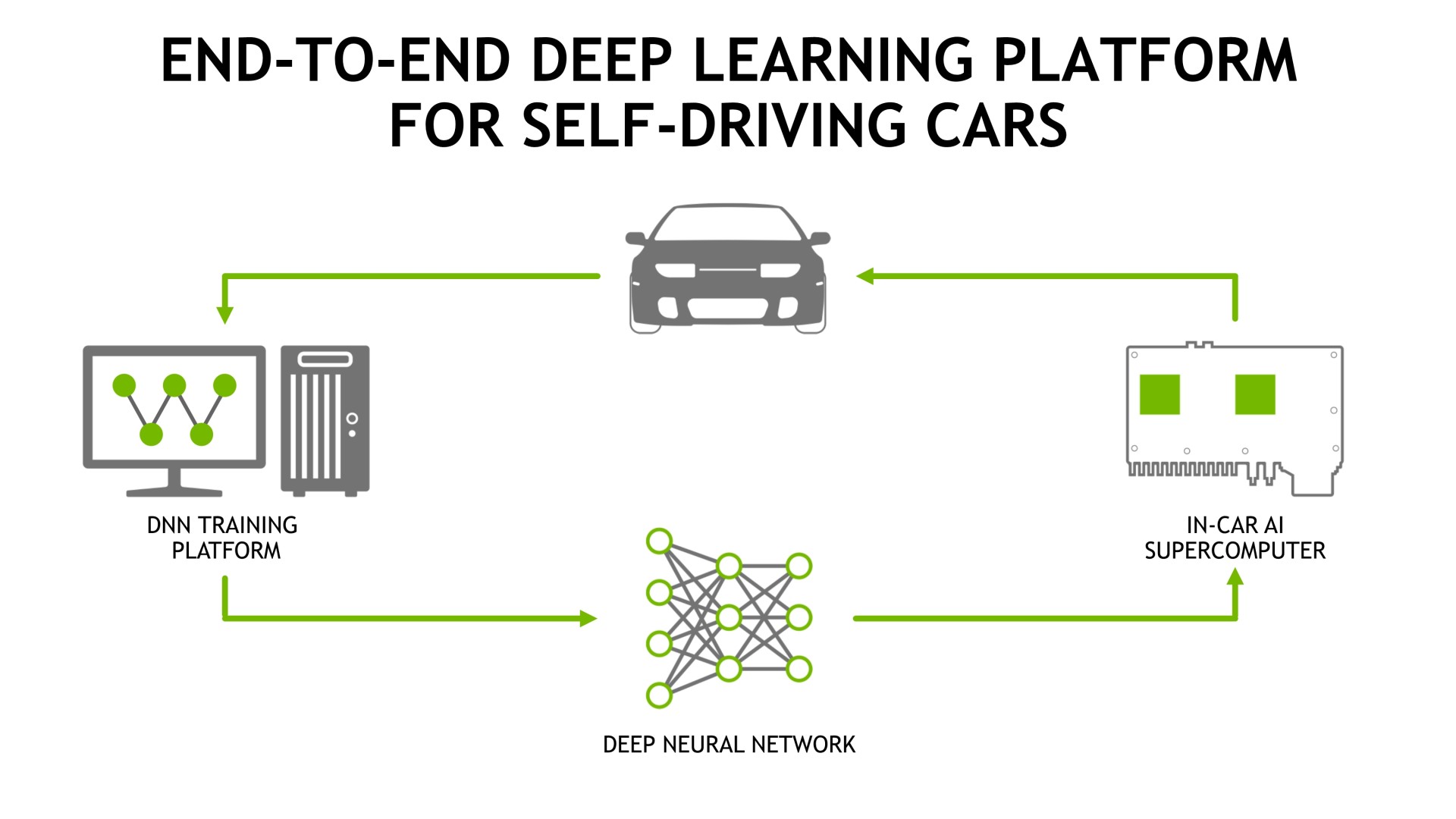
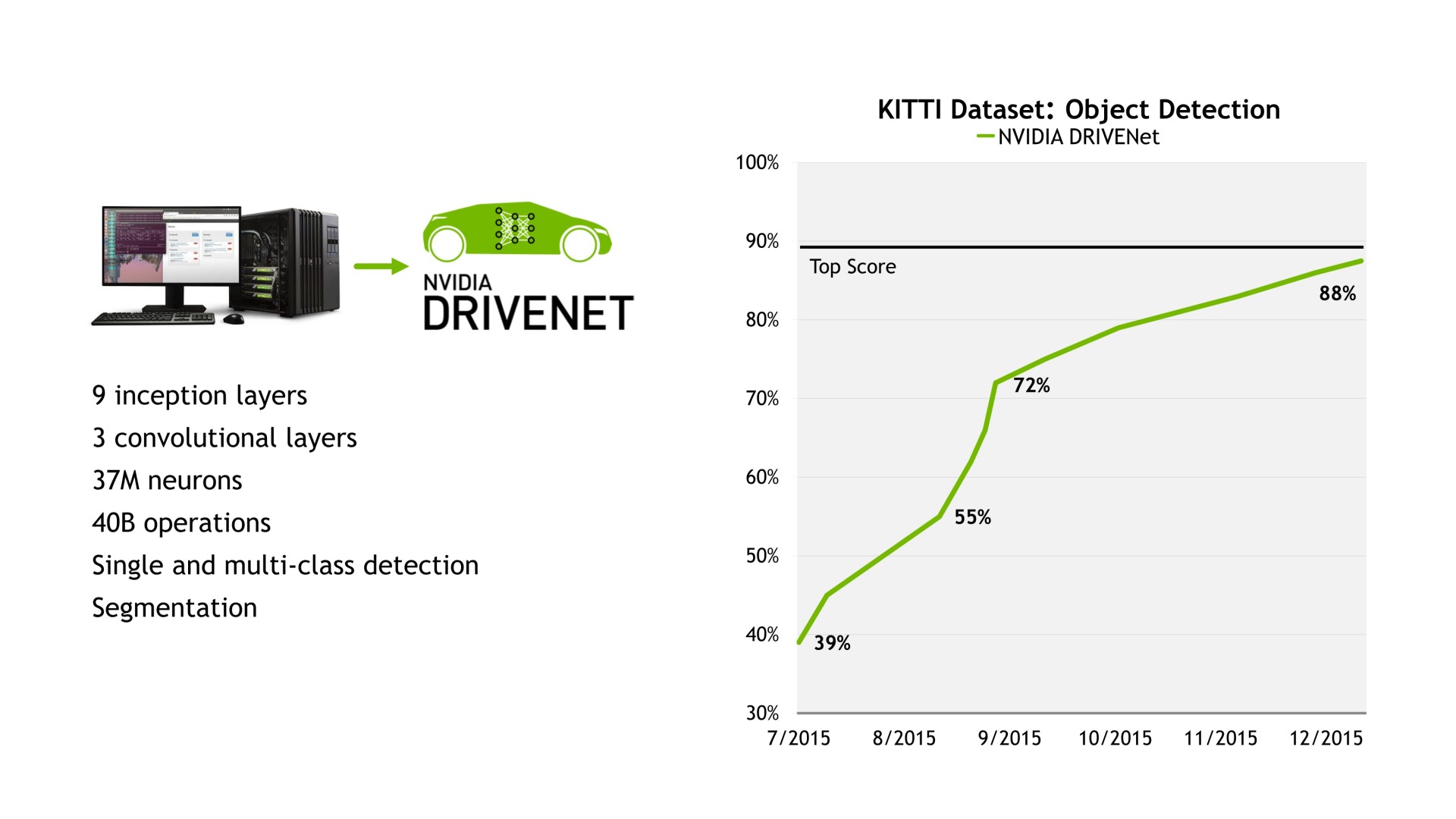
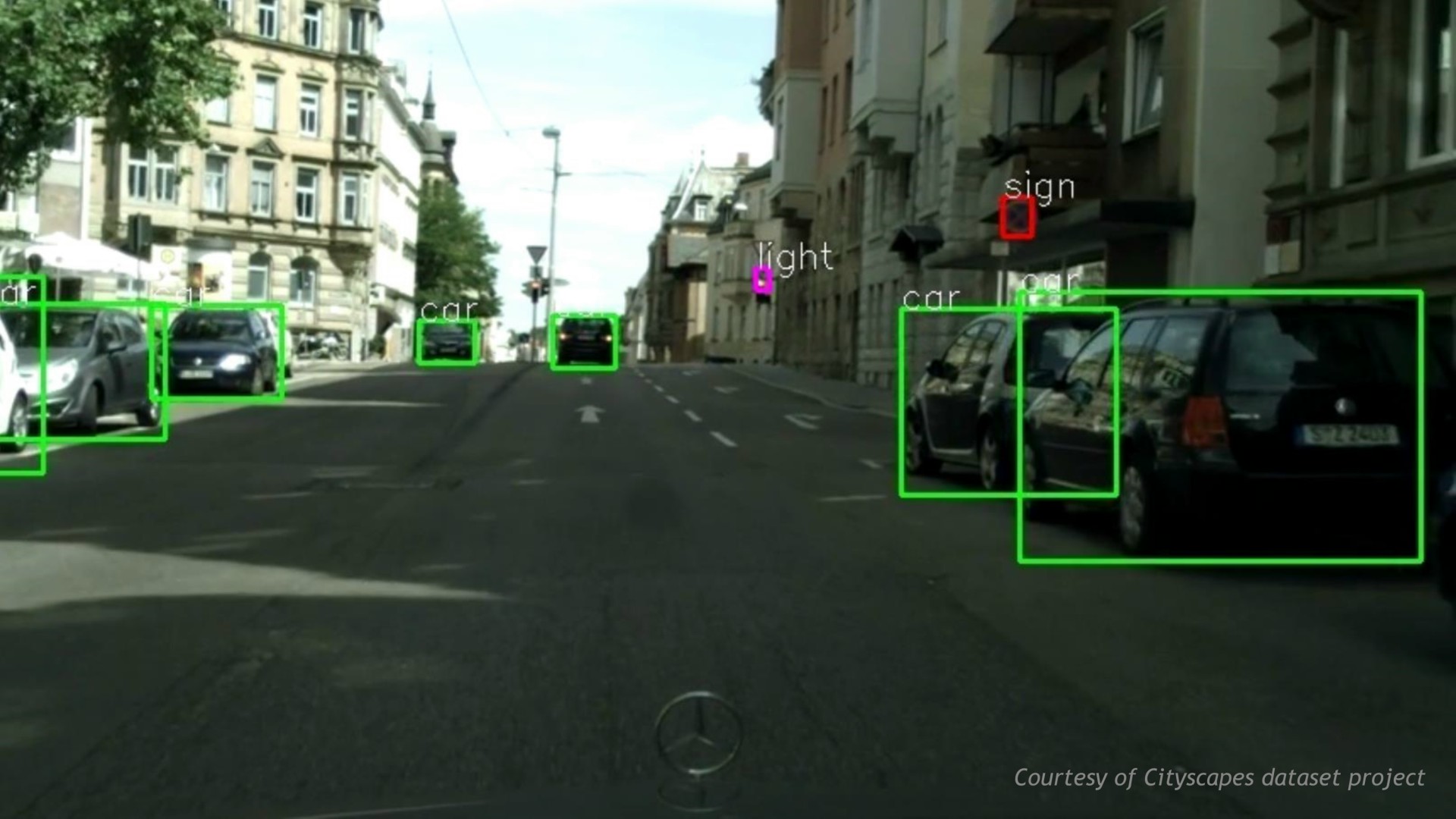
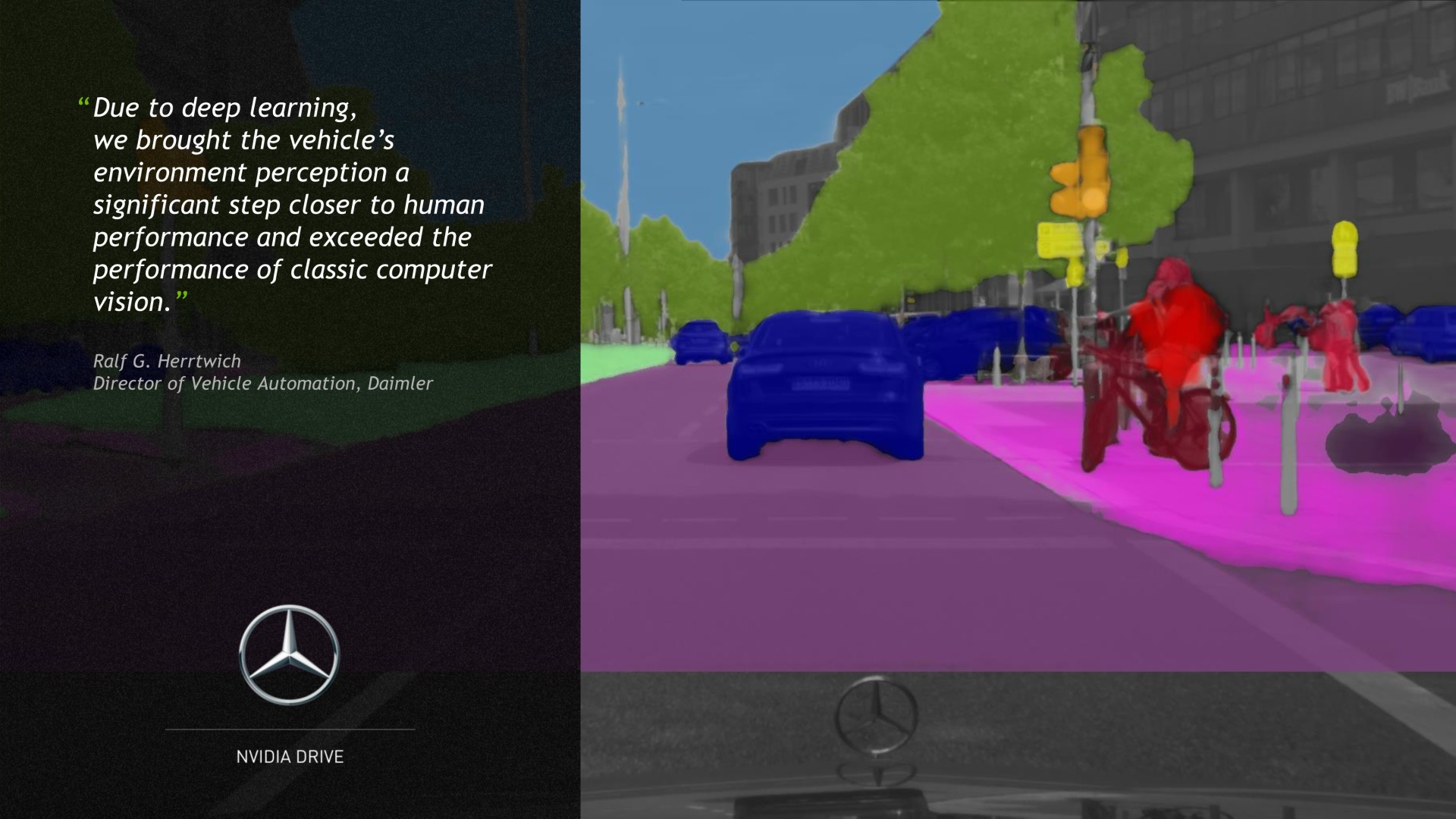
Enfin, pour mieux s'attaquer à ce marché, Nvidia a mis en place un écosystème complet qui passe par DIGITS, sa plateforme de deep learning, et d'autre part par DRIVENET, un réseau neuronal que ses ingénieurs ont commencé à entraîner il y a 6 mois et qui affiche déjà de très bons résultats. Nvidia peut ainsi fournir à des clients potentiels tous les outils nécessaires au développement de leur propre réseau neuronal ou une base déjà totalement fonctionnelle.
Un premier constructeur a déjà annoncé être intéressé par cette solution de Nvidia : Volvo qui intégrera Drive PX 2 en 2017 dans une centaine de voitures autonomes pour une première phase de test. De quoi peut-être permettre à "Drive PX 3" de trouver un succès commercial ?
Vous pourrez retrouver l'intégralité de la présentation de Nvidia ci-dessous :


























Pascal sera produit en 16nm chez TSMC
Selon Business Korea , c'est TSMC qui produira la prochaine génération de GPU de Nvidia dénommée Pascal. Nvidia conserverait donc son partenaire historique et son 16nm FinFET alors que des rumeurs indiquaient que Samsung était bien placé pour obtenir le contrat sur son 14nm FinFET. Il faut dire que Samsung semble en avance sur TSMC en termes de planning puisqu'il produit déjà en volume les SoC A9 équipant l'iPhone 6s.
On ne sait pas encore si AMD en fera de même ou s'il optera pour le 14nm Samsung qui est également déployé chez GlobalFoundries. Dans ce dernier cas on aurait droit à une bataille d'architecture combinée à une bataille de fondeurs sur le marché des GPU, ce qui n'est pas arrivé depuis belle lurette !
Nvidia Pascal: le FP16 pour doubler les Tflops
Le CEO de Nvidia, Jen-Hsun Huang, a profité de l'ouverture de la GPU Technology Conference pour donner un détail de plus concernant sa future architecture GPU prévue pour 2016 : Pascal supportera la précision de calcul FP16.
L'an passé, les premiers détails avaient déjà été communiqués au sujet de Pascal, vous pourrez retrouver nos actualités dédiées ici et là.
Ainsi, pour rappel, nous savions déjà au sujet de cette architecture intermédiaire entre Maxwell et Volta que Nvidia visait 32 Go de mémoire 3D et une bande passante totale de 1 To/s, soit à peu près le triple de ce dont est capable un GPU tel que le GM200 de la GeForce GTX Titan X. Nvidia avait également annoncé un format de type mezzanine pour les serveurs et une nouvelle interconnexion : NVLink.
Il était par contre alors question d'une augmentation de 66% des performances par watts en SGEMM (FP32). Visiblement, Nvidia est plus ambitieux cette année et parle dorénavant d'un doublement des performances par watts.
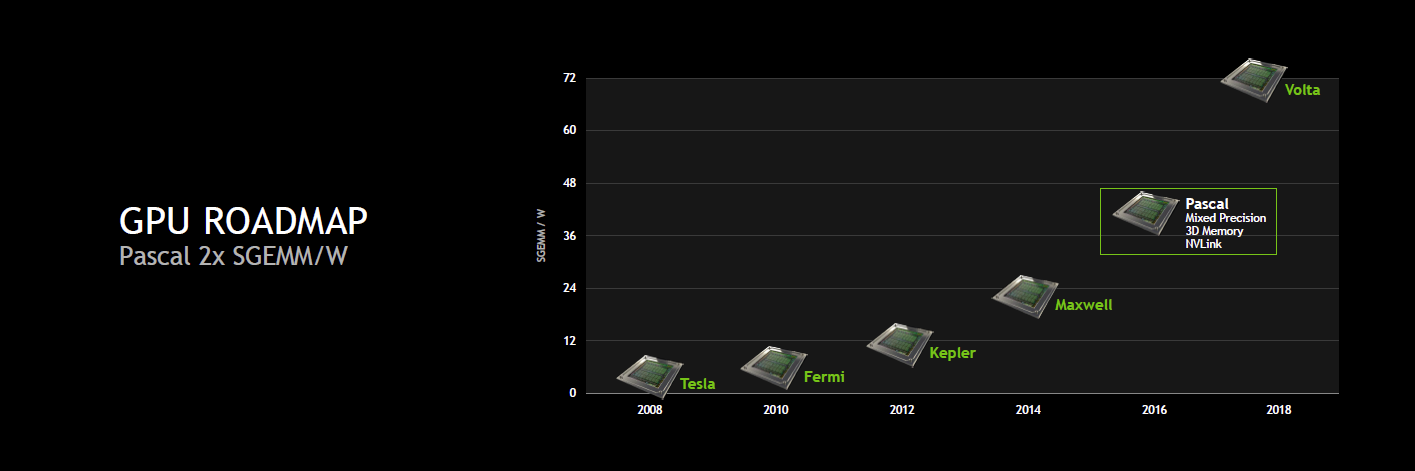
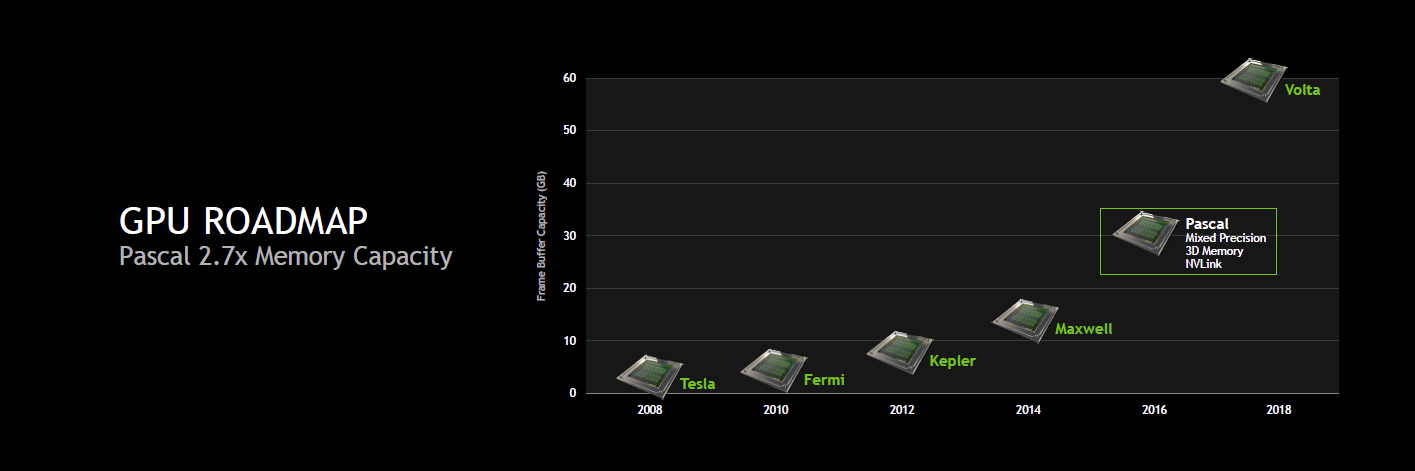
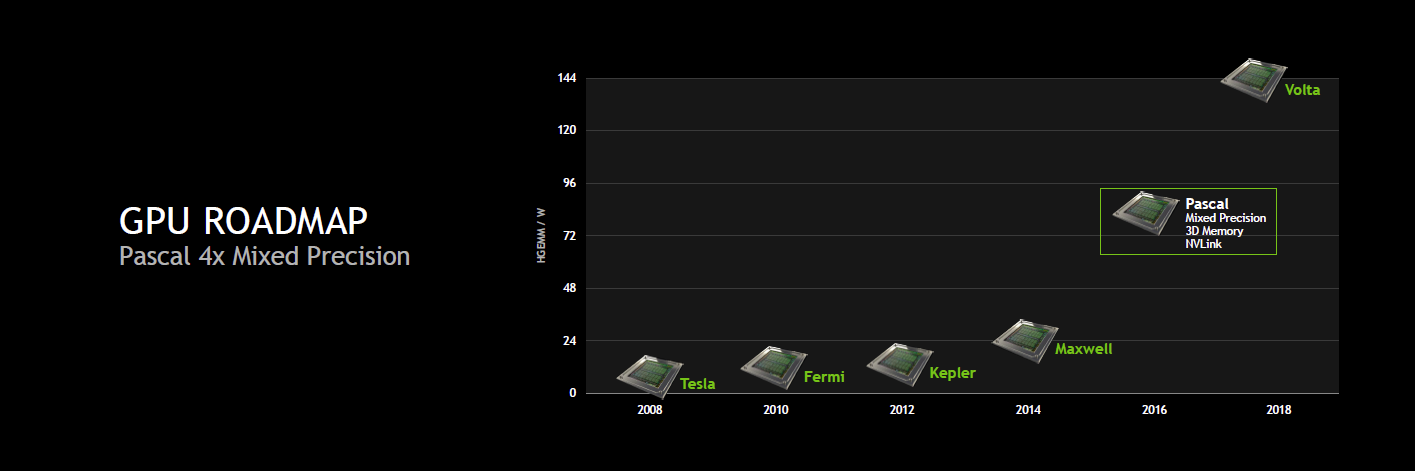
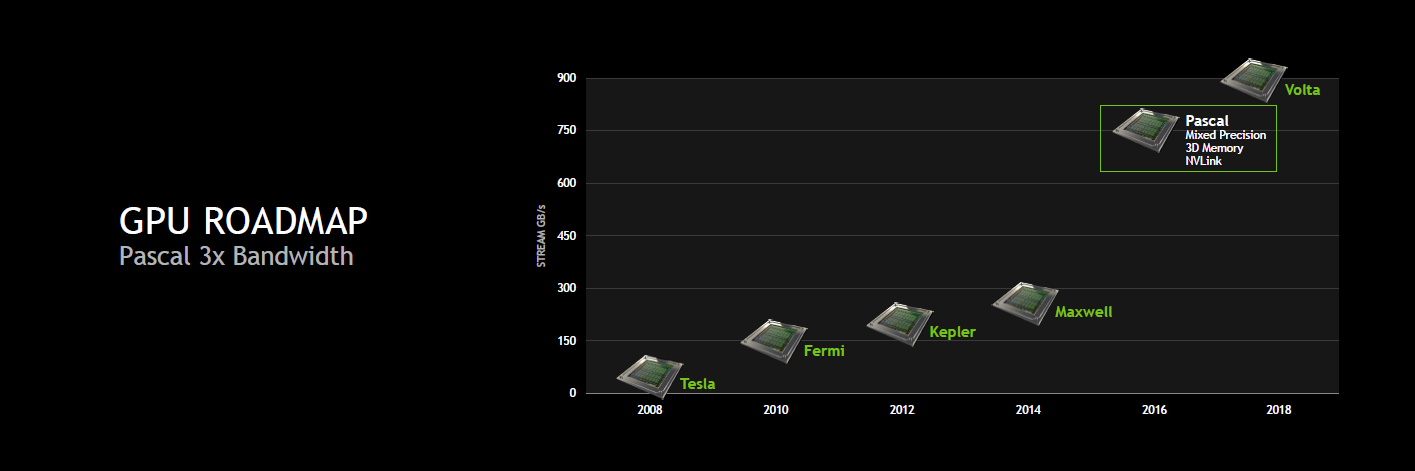

Mais surtout, Nvidia compte aller plus loin dans l'augmentation de la puissance de calcul et c'est là que se trouve le nouveau détail concernant Pascal : il supportera le calcul en FP16 et la précision mixte. Nvidia reprend probablement cette spécificité du Tegra X1 dont les unités de calcul FP32 sont également capables de traiter 2 opérations FP16, étendue pour plus de flexibilité. De quoi potentiellement doubler les performances pour les applications qui peuvent se satisfaire d'une précision de calcul réduite.
Le but de la précision mixte sera de pouvoir mélanger dans un algorithme des opérations des différents niveaux de précision supportés par le GPU, FP16, FP32, FP64, pour n'exploiter les instructions plus lentes et plus gourmandes que là où elles sont réellement nécessaires. Les optimisations potentielles sont légions mais les identifier et les exploiter efficacement en pratique est probablement une difficulté qui va se poser.
En combinant les évolutions au niveau du sous-système mémoire à cette précision mixte et en doublant le nombre de GPU d'un système à l'aide de NVLink, Nvidia table sur une multiplication par 10 des performances. Un chiffre qui est par contre probablement très optimiste.
GTC: Quelques détails de plus sur le GPU Pascal
Durant la GTC, nous avons pu poser quelques questions à Nvidia et en apprendre un peu plus sur le GPU Pascal qui a été introduit entre les générations Maxwell et Volta.
Si Nvidia se refuse à parler de process de fabrication, nous supposons que la raison du retard de Volta est à chercher de ce côté. Pascal devra donc se contenter du 20 nanomètres de TSMC, ce qui limitera quelque peu les possibilités de Nvidia par rapport à ses plans originaux pour la même période. Pour aller plus loin que les GPU Maxwell qui seront fabriqués en 20nm, Nvidia devra poursuivre la progression de l'efficacité énergétique, mais ce n'est pas tout.
Nvidia explique que certains développements entrepris pour Volta étaient prêts et pourront être proposés comme prévus à travers les GPU Pascal. C'est le cas des technologies NVLink et du DRAM stacking. NVLink, qui a été développé en partenariat avec IBM, devrait dans un premier temps rester spécifique au marché professionnel, mais le DRAM stacking fera son apparition du côté des dérivés grand public. Probablement uniquement dans le très haut de gamme au départ, mais Nvidia insiste sur le fait que la technique est utile pour tous les segments de marché. En dehors du coût et d'un travail important nécessaire pour assurer un assemblage fiable, ce recours au DRAM stacking ne présente que des avantages, aucun inconvénient selon Nvidia. Son implémentation généralisée n'est donc qu'une question de temps et de réduction progressive des coûts.
Concernant le prototype de Pascal qui a été présenté, il s'agit d'un "mechanical sample" qui n'est pas encore fonctionnel mais qui est utilisé par Nvidia pour développer un nouveau format de module "carte graphique". Sur ce module Pascal, nous pouvons observer le GPU avec ses 4 assemblages de puces mémoire qui prennent place sur le même packaging et sont connectés via un "interposer". Sur les côtés du module sont visibles les VRM nécessaires pour alimenter un GPU haut de gamme tel que devrait l'être Pascal. Nvidia précise que ce module n'aura pas de problème à délivrer au moins 300W.
Si aucun connecteur n'est visible au premier abord c'est parce qu'ils se situent en fait au dos, Nvidia ayant opté pour un format de type mezzanine qui consiste à superposer 2 PCB, avec un ou plusieurs connecteurs entre ceux-ci. Sur le module actuel, Nvidia précise que 2 connecteurs sont exploités.

Un exemple de connecteur mezzanine, SpeedStack de Molex, capable de supporter des débits de 40 Gbps par paire.
Pourquoi ce changement de format ? Pour faciliter l'implémentation de NVLink, qui pourrait être exclusive au format mezzanine, mais également parce que ce dernier est plus fiable, notamment lorsqu'il est question de laisser les assembleurs de serveurs monter leur propre radiateur. Nvidia n'abandonne cependant pas le format "carte PCI Express" pour Pascal, il restera également disponible, même sur le marché professionnel.
Nvidia a également publié des schémas un peu plus détaillés de systèmes NVLink :
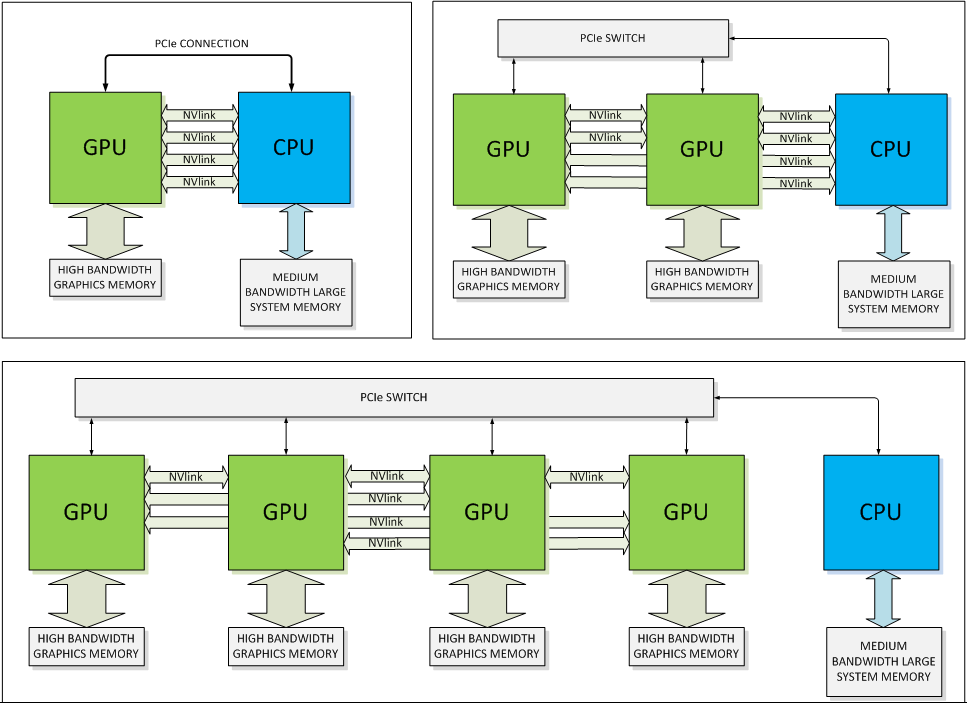
Sur ces schémas nous pouvons clairement observer 4 liens NVLink. Nvidia nous a précisé qu'il s'agissait d'un minimum et que certains modules Pascal, ou ses successeurs, pourraient en offrir plus, 8, 16 Il n'est d'ailleurs pas impossible que Nvidia en profite à l'avenir pour segmenter sa gamme professionnelle comme le fait aujourd'hui Intel avec les Xeon 2P/4P/8P. A noter que tous les liens peuvent être combinés pour former un très large bus de communication vers le CPU et/ou exploités pour connecter plusieurs GPU entre eux.
Chaque lien NVLink correspond à un bloc de 8 paires de lignes bidirectionnelles de type point-à-point. Une approche similaire à celle de l'HyperTransport et du QPI. Là où le bus PCI Express 3.0 16x apporte 16 Go/s dans chaque direction, l'ensemble NVLink pourra atteindre entre 80 et 200 Go/s. Nvidia indique par ailleurs que les déplacements de données à travers NVLink seront plus efficaces sur le plan énergétique que le PCI Express. Les premiers composants autres que Pascal qui supporteront NVLink seront de futurs CPU Power d'IBM. Nvidia précise par contre être en discussion avec d'autres fabricants de CPU, autres qu'Intel, mais sans en dire plus.
Enfin, nous avons interrogé Nvidia par rapport au recul du support complet de la mémoire unifiée qui était initialement prévu pour Maxwell mais est dorénavant annoncé pour Pascal. Ses responsables nous ont répondu que ce support avait bien été repoussé mais qu'il était présent partiellement depuis Kepler, reposant en partie sur une implémentation logicielle. Ils nous promettent que cette fois ce sera la bonne et que le dernier bloc nécessaire à la prise en charge matérielle complète de la mémoire unifiée fera enfin son apparition avec Pascal et NVLink.