
Actualités informatiques du 29-05-2017
- ARM annonce les Cortex-A75, A55 et Mali G72
- Samsung détaille sa roadmap jusqu'au 4nm
- AMD évoque la prochaine version de l'AGESA
- Dossier: Desktop, mobile et en box : la GTX 1080 dans tous ses états
| Mai 2017 | ||||||
|---|---|---|---|---|---|---|
| L | M | M | J | V | S | D |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 | ||||
ARM annonce les Cortex-A75, A55 et Mali G72



ARM vient d'annoncer de nouveaux blocs processeurs pour ses partenaires, sous le nom de Cortex-A75 et A55 (pour un rappel sur la stratégie d'ARM, nous vous renvoyons au début de cet article). Ces nouveaux Cortex sont des coeurs CPU clefs en main qui peuvent être utilisés par les partenaires d'ARM pour concevoir leurs SoC.
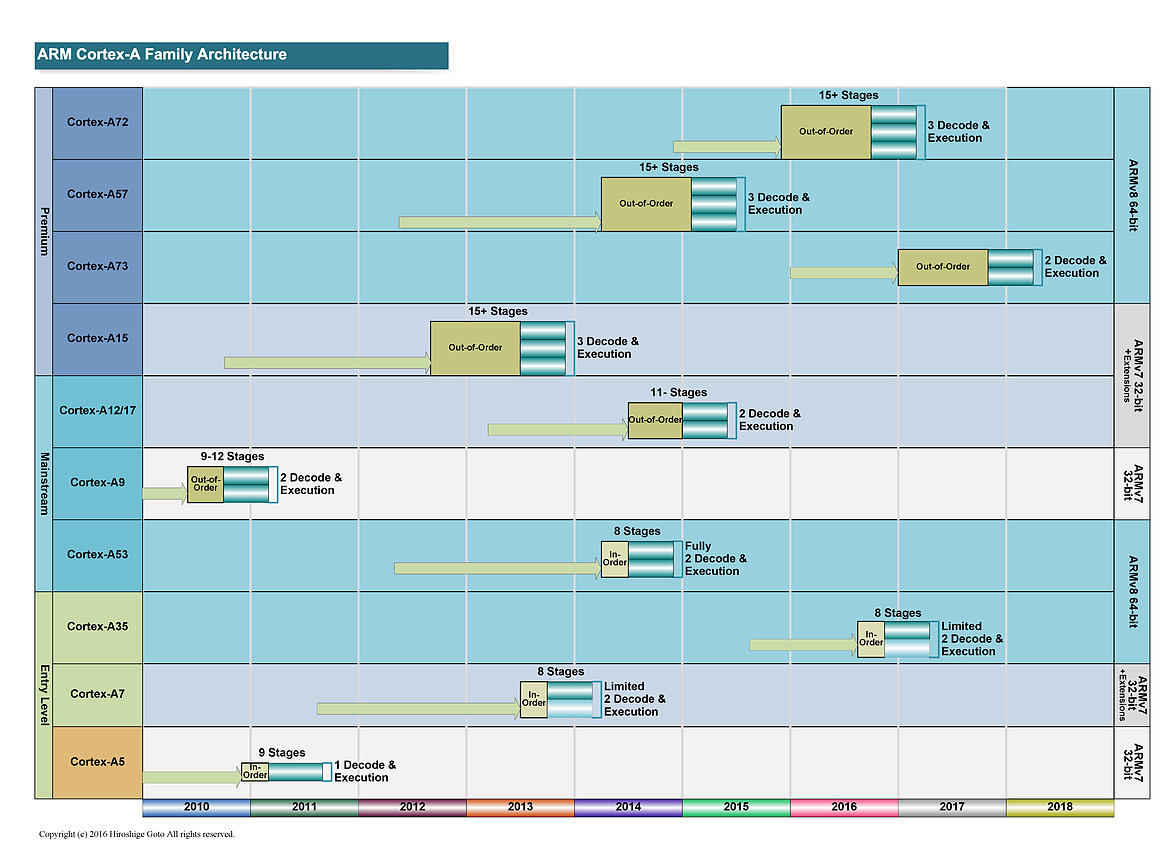
Les nomenclatures marketing d'ARM sont assez complexes à déchiffrer, la société dispose de plusieurs équipes qui font évoluer en parallèle des versions différentes de leurs architectures. Pour les "gros" coeurs, on retrouve deux familles distinctes avec d'un côté des "très gros" coeurs qui tendent à consommer significativement plus d'énergie. Ce sont les Cortex A15, A57 et A72 développés par l'équipe d'Austin. En parallèle, une autre équipe à Sophia-Antipolis développe des "gros" coeurs un peu plus efficaces comme les A12, A17 et plus récemment A73.
A l'origine, cette gamme était vue comme un intermédiaire par ARM même si la consommation élevée des "très gros" coeurs tend la société à pousser aujourd'hui les coeurs "Sophia" sur le haut de gamme mobile. Cette tendance se confirme aujourd'hui puisque l'A75 est en pratique le successeur de l'A73.
Techniquement ces puces se distinguent par un pipeline plus court, et sur ce point l'A75 ne change rien en gardant un pipeline court de 11 étapes pour les instructions entières. Le plus gros changement concerne le nombre d'instructions décodées par cycle puisque l'on passe de deux instructions décodées à trois, alignant sur cette caractéristique l'A75 avec ce qui se faisait sur les "très gros" ARM. On passe donc en pratique de 6 micro-ops par cycle à 8. Le nombre d'unités reste identique mais l'A75 ajoute des files supplémentaires pour stocker les micro-ops à traiter.
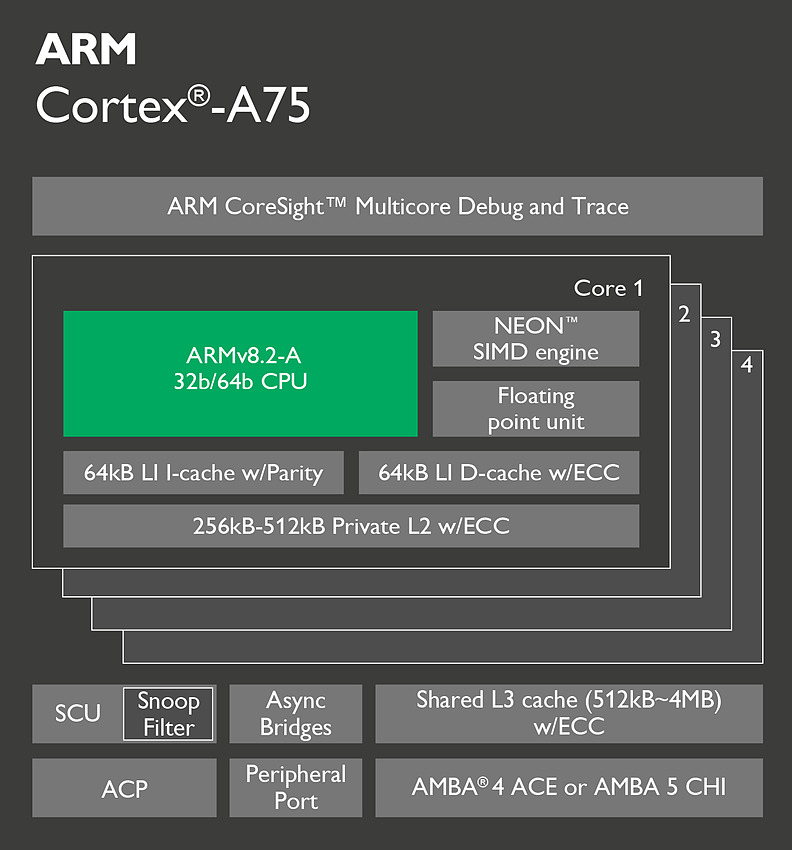
ARM applique un changement similaire pour les instructions flottantes et vectorielles (on parle de NEON dans le marketing ARM, le pendant de SSE/AVX sur x86) avec là aussi la possibilité de décoder trois instructions par cycle. Cela s'accompagne par une file supplémentaire et une troisième unité NEON spécifiquement utilisée pour les accès mémoire.
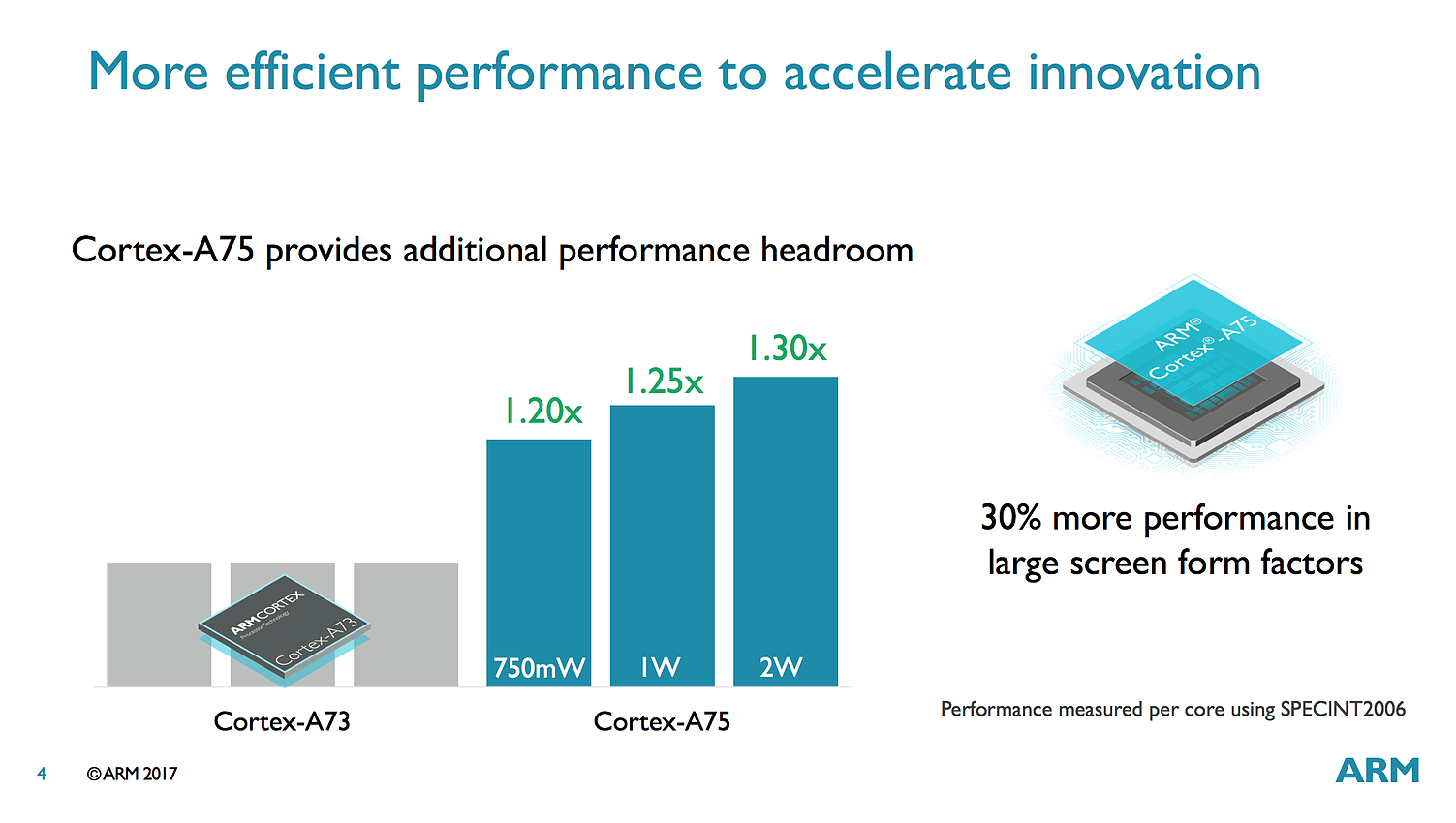
ARM annonce des gains de performance allant de 20 à 30% pour l'A75 rapport à l'A73 en fonction de la consommation autorisée, ce qui est plutôt intéressant. L'A75 est un bloc qui comme l'A73 est prévu pour le 10nm et il devrait faire son apparition en toute fin d'année ou plus probablement l'année prochaine dans des produits commerciaux.
Un nouveau coeur LITTLE
En plus des gros coeurs dont nous vous parlions au-dessus, ARM propose également des coeurs plus petits, à la consommation beaucoup plus faible et qui ont pour but d'être appairés à des gros coeurs dans ce qu'ARM appelait jusqu'ici des configurations big.LITTLE. Après avoir utilisé dans ce rôle l'A53 depuis plusieurs années (il avait été introduit en 2012 !), ARM propose enfin une nouvelle mouture de son petit coeur baptisée Cortex-A55.
Il s'agit toujours d'un coeur dit "In Order", les instructions ont exécutées dans l'ordre dans lequel elles arrivent (à l'opposé des processeurs plus gros/modernes qui utilisent des architectures "Out Of Order", les instructions sont réordonnancées pour optimiser l'exécution et améliorer le parallélisme).
Il y a assez peu de changements sur l'A55, le plus gros concerne la séparation des unités de lecture/écriture mémoire ainsi qu'un nouveau prédicteur de branchements. Le reste des changements se situant au niveau des caches mémoires qui ont été reconfigurés.
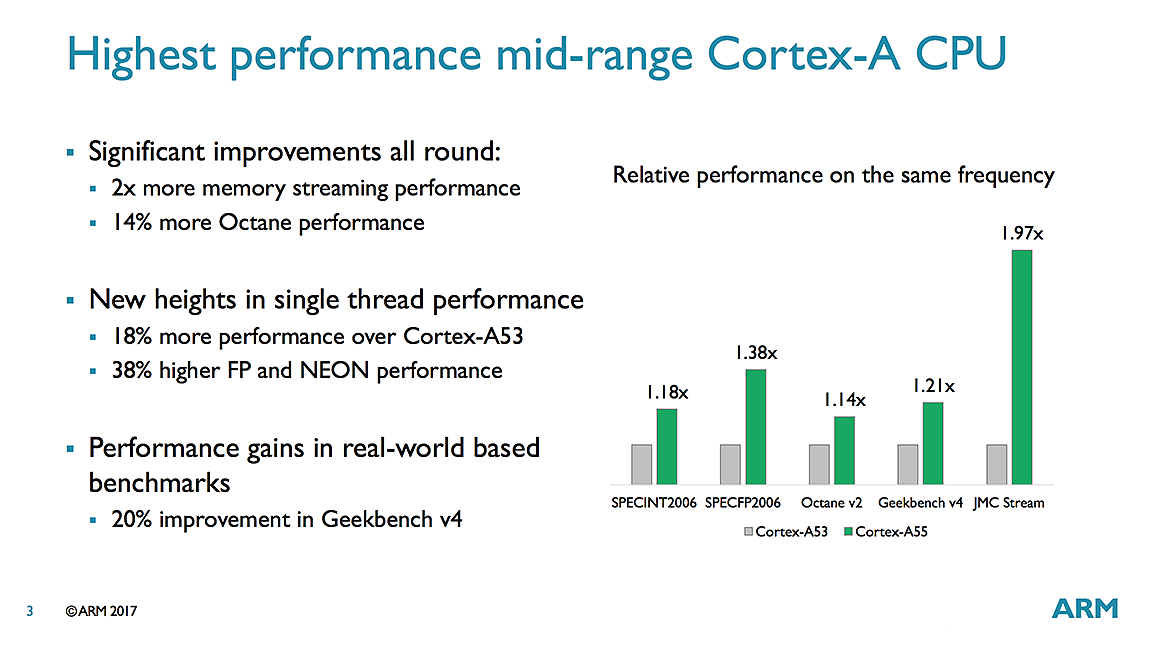
ARM annonce des gains de performances autour de 20% sur l'A55 à fréquence égale par rapport à un A53, des gains qui peuvent cependant monter beaucoup plus haut quand on prend en compte les caches. Sous SPECFP2006, la société annonce ainsi 38% de gains.
DynamIQ, big.LITTLE V2.0
Le concept du big.LITTLE évolue et prend désormais le nom de DynamIQ. ARM a repensé la manière dont il permettait de relier ses coeurs entre eux et propose un nouveau concept qui résout beaucoup de problèmes sur le papier.

L'idée principale est de remplacer big.LITTLE par des "clusters" qui peuvent regrouper jusque huit coeurs. On pourra mélanger au sein d'un cluster différents types de coeurs (par exemple quatre A75 et quatre A55) ce qui engendre un changement important au niveau de la structure des caches. Désormais, chaque coeur ARM (A55 ou A75) disposera de son propre cache L1 et de son propre cache L2. Ce changement est bienvenu et devrait éviter ces bugs embarrassants comme celui de Samsung et de son M1 qui mélangeait ses coeurs à des A53 avec des lignes de caches différentes.
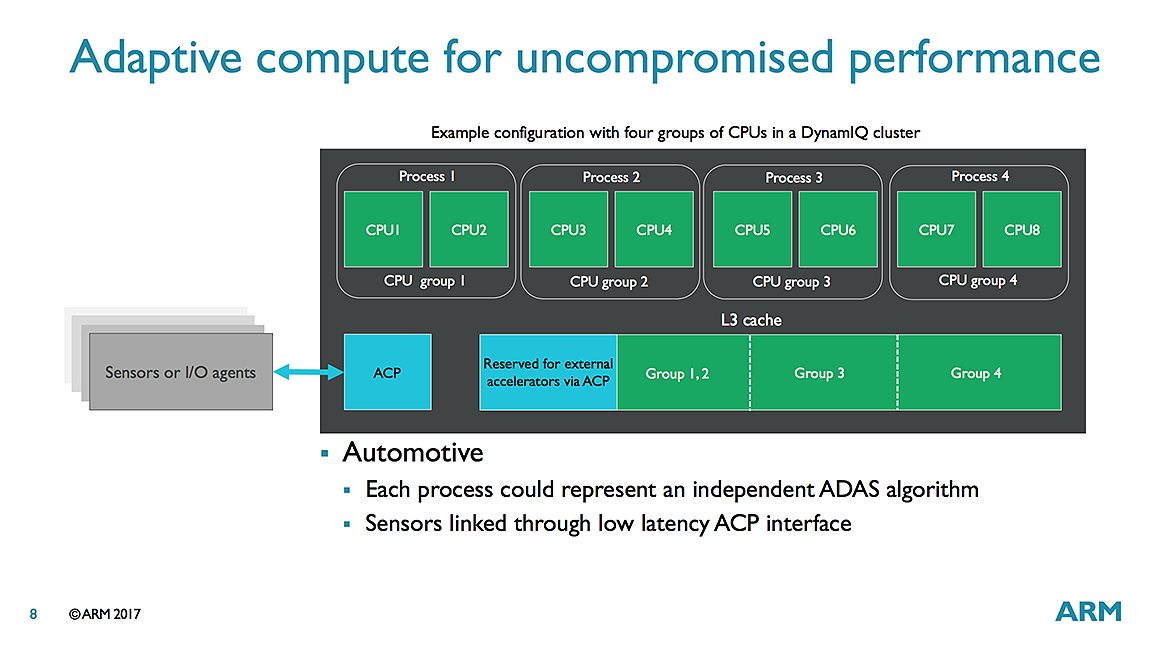
Tous les coeurs d'un cluster partageront un cache L3 commun (jusque 4 Mo) et l'on pourra disposer de plusieurs clusters - jusque 32 - au sein d'une puce (quelque chose qui devrait surtout servir pour d'éventuelles versions serveurs de ces processeurs). Une organisation qui n'est pas sans rappeler celle utilisée par AMD avec ses CCX dans Ryzen, on notera qu'ARM indique que son cache L3 peut être partitionné dynamiquement pour certains coeurs ou pour d'autres applications.
En bref
On notera également côté GPU l'arrivée une version optimisée du Mali G71, baptisé G72 pour lequel il n'y a pas de changement majeur au niveau de l'architecture Bifrost d'ARM. L'augmentation de la taille des caches permet d'augmenter l'efficacité énergétique ce qui est appréciable.
Si les modifications effectuées sur les Cortex A75 et A55 sont intéressantes, on retiendra surtout de l'annonce d'ARM l'arrivée de DynamIQ qui devrait permettre de mieux exploiter les coeurs. Car si big.LITTLE était sur le papier une bonne idée, son implémentation pratique avait montré de multiples limites. Cette nouvelle approche sous la forme de clusters contribue aussi sur les gains de performances, tout comme la réorganisation des caches.
Le sous-système mémoire des Cortex a toujours été la faiblesse de l'architecture avec des contrôleurs extrêmement optimisées pour la basse consommation, mais pas forcément pour les performances ce qui donne aux architectures ARMv8 tierces (comme celles d'Apple et même de Samsung) un avantage en général très net sur ce point.
Samsung détaille sa roadmap jusqu'au 4nm
Samsung a donné quelques détails sur les prochaines versions de ses process de fabrication, annonçant pas moins de cinq nouveaux process baptisés 8LPP, 7LPP, 6LPP, 5LPP et... 4LPP. Quelques informations sont données sur les différences. Ainsi, le 8LPP sera une variante du process 10nm de Samsung qui profitera de gains de performances ainsi que de gains de densité, possiblement par l'utilisation de nouvelles bibliothèques (les blocs de base qui servent à créer les puces).
Le 7LPP sera le prochain "vrai" node de Samsung. Prévu pour la fin 2018, il s'agira du premier node à introduire la lithgraphie EUV. Le constructeur indique dans son communiqué de presse avoir co-développé avec ASML une source lumineuse 250W pour cette mise en production (pour rappel, tous les fabricants ont collaboré avec ASML sur l'EUV, TSMC évoquait également 250W fin 2018 pour la mise en production de l'EUV).
Le 6LPP sera une variante optimisée du 7LPP qui utilisera ce que le marketing appelle du "Smart Scaling", diverses techniques permettant d'améliorer la densité. Il s'agira surtout pour Samsung de profiter de l'apprentissage de son premier process EUV pour optimiser légèrement les choses.
Le 5LPP sera vraisemblablement le "node" suivant au sens traditionnel du terme, il servira à préparer le terrain pour le suivant. Car c'est au niveau du 4LPP qu'un gros changement arrivera avec un passage à un nouveau type de structure de transistor. Samsung utilisera des transistors dit Gate All Around (GAAFET) qui sont une variante des FinFET où la Gate entoure le canal. La version de Samsung sera baptisée MBCFET (Multi Bridge Channel FET) et utilisera une nanosheet sur laquelle aucun détail n'est donné pour l'instant.
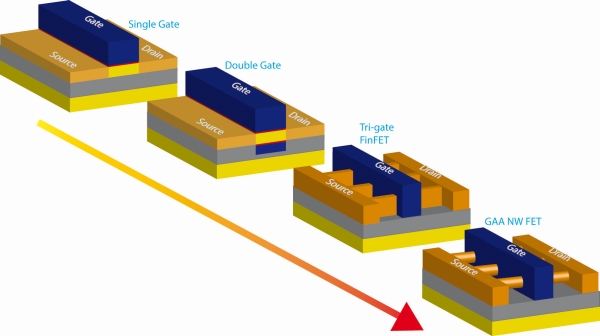
Les différences entre les types de transistors (source )
Ces nodes et ces variantes devraient apparaître progressivement dans les années à venir, Samsung évoquant simplement son 4LPP pour 2020 pour ne pas s'engager plus fortement sur le timing. On ne leur en tiendra pas rigueur, il est assez rare que les fondeurs partagent publiquement, et avec tant de visibilité leur roadmap.
On pourra bien entendu s'interroger sur les nomenclatures choisies par Samsung, mais au-delà de cela, la tendance reste commune chez tous les fondeurs qui multiplient les variantes d'un même process. TSMC en est à sa quatrième version de "16nm", baptisée pour le coup 12FFC, tandis qu'Intel annonçait fin mars pour la première fois trois versions de 14nm et de 10nm.
Derrière ces annonces, on retrouve des constatations communes, il est de plus en plus difficile de réduire la taille des puces, et les gains de performances et de densités apportés ne sont plus forcément aussi importants qu'auparavant (même si les fondeurs, Intel en tête, continuent d'innover sur les formules mathématiques pour ne pas dire que la loi de Moore ralentit).
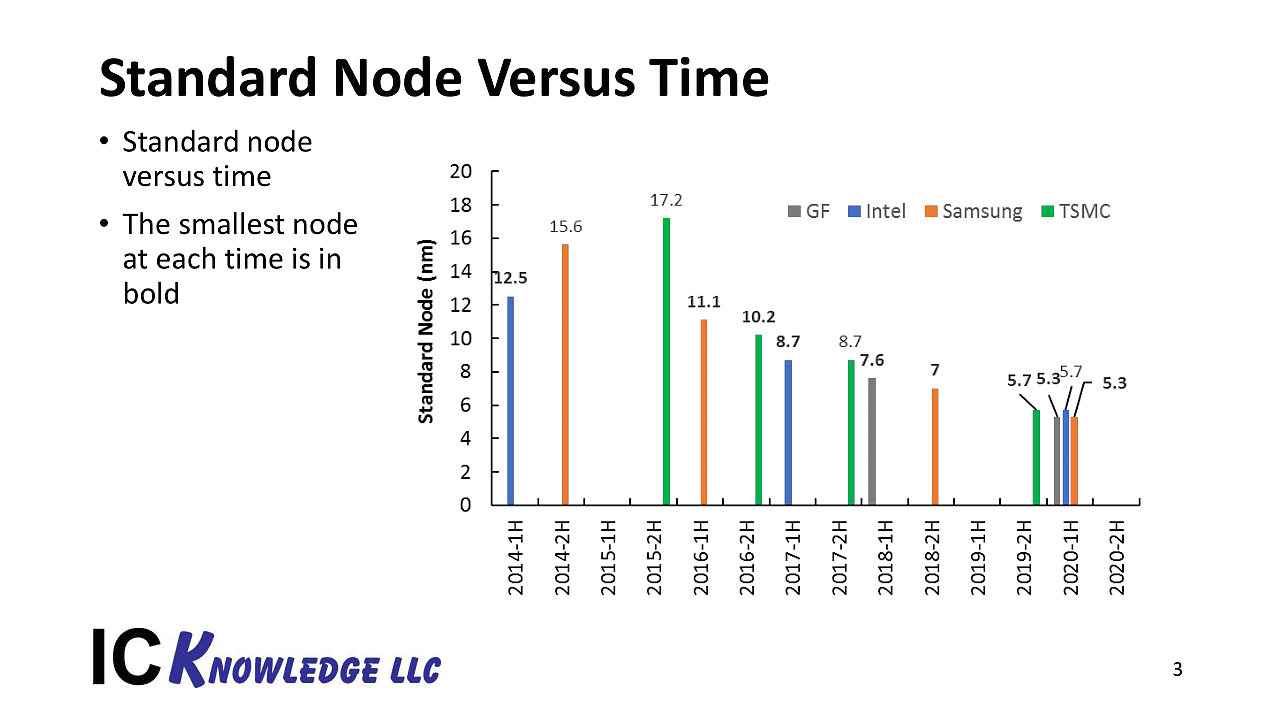
Le passage au 5nm chez tous les fondeurs est attendu autour de 2020 en production risque, même si chez Intel on parlerait logiquement de "7nm", cf cette roadmap basée sur des estimations publiées sur le blog SemiWiki
Mais au-delà du marketing derrière les variantes, le rythme annoncé par Samsung reste assez soutenu laissant penser à un écart de deux ans entre le 7nm et le 5nm, ce qui est très agressif et aligné sur ce que devrait proposer TSMC (qui lancera son 7nm d'abord sans EUV, le 8LPP lui étant opposé par Samsung). TSMC a confirmé qu'il lancera le début de sa production en 7nm ce trimestre (la production en volume est attendue l'année prochaine). Le 5nm démarrera ses essais de production en 2019 pour une production volume en 2020 chez le fondeur taiwanais.
La confiance de Samsung sur l'EUV est également un point que l'on ne négligera pas, la lithographie à immersion touche aujourd'hui ses limites et si les problèmes de l'EUV ne sont pas tous résolus, la technologie devrait donner un peu de marge aux fondeurs.
AMD évoque la prochaine version de l'AGESA
Nous avons eu l'occasion de le noter à plusieurs reprises, la question de la compatibilité mémoire reste un problème pour la nouvelle plateforme Ryzen d'AMD. Le constructeur avait indiqué qu'il proposerait une nouvelle mise à jour importante sur cette question et, via un billet de blog , a annoncé quelques détails de ce que proposera son futur AGESA 1.0.0.6.

Le premier changement - le plus simple - est l'ajout de coefficients multiplicateurs mémoires supplémentaires. Jusqu'ici, on ne pouvait pas dépasser les timings DDR4-3200 sans changer la refCLK, faute de coefficients suffisants. Ce problème sera corrigé dans la prochaine version de l'AGESA qui permettra donc d'atteindre théoriquement DDR4-4000 sans changer le refCLK. Si nous qualifions ce changement de simple, c'est avant tout parce qu'il ne s'agit que de changer les multiplicateurs disponibles, cela ne règle pas les questions de compatibilité bien entendu.
Pour s'attaquer à ces dernières, l'AGESA 1.0.0.6 apportera un plus grand nombre de réglages mémoires. Jusqu'ici, certains timings mémoires n'étaient pas réglables par l'utilisateur dans le BIOS, et devaient être réglés manuellement par les constructeurs proposant donc plusieurs versions beta avec des réglages différents. Le plus visible pour beaucoup était le réglage 1T/2T, même si nombre d'autres timings mémoires manquaient à l'appel.
Une vingtaine de réglage seront donc ajoutés à ce futur AGESA, incluant le Command Rate mais aussi le ProcODT, un grand nombre de timings (tWCL, tRC, tFAW, tWR, tRDWD, tRFC, tRDD...) et des options comme le Gear Down Mode et le Power Down Mode.
Outre la possibilité pour les utilisateurs de régler finement ces timings, l'arrivée de ces options permet aussi aux BIOS d'essayer différents réglages lors des phases de détection mémoire et donc, potentiellement, de monter un peu plus haut en fréquence. Les constructeurs commencent très doucement à proposer des premiers BIOS beta avec ces nouvelles options et si certains utilisateurs rapportent un peu de mieux, cela ne semble pas résoudre encore tous les problèmes qui varient pour rappel en fonction des marques des dies mémoires et de leurs types.
Les plus téméraires pourront essayer ces BIOS s'ils disposent des bons modèles de carte mère (les constructeurs ne proposent en général ces BIOS beta que pour quelques modèles, voir ici par exemple pour Gigabyte ), pour les autres, il faudra patienter encore un peu, AMD annonce qu'en fonction des constructeurs ces versions finales pourraient arriver dans la seconde moitié de juin si tout se passe comme prévu !
Dossier : Desktop, mobile et en box : la GTX 1080 dans tous ses états
Toutes les GTX 1080 sont-elles égales ? Intégrée au PC, desktop ou portable, ou encore exploitée en boîtier externe Thunderbolt ? C'est ce que nous allons vérifier dans ce dossier.
[+] Lire la suite
