Actualités informatiques du 15-06-2011
- AMD Catalyst 11.6
- Intel présente le jeu d'instructions d'Haswell
- AFDS: AMD dévoile la FSA pour OpenCL
- SSD Intel Series 710 et 720
- AFDS: L'architecture des futurs GPUs AMD!
| Juin 2011 | ||||||
|---|---|---|---|---|---|---|
| L | M | M | J | V | S | D |
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | |||
AMD Catalyst 11.6



La version de juin des pilotes graphiques d'AMD vient d'être mise en ligne sur le site du constructeur. Il s'agit des premiers pilotes dédiées aux APU Llano, ils implémentent entre autre la fonctionnalité Steady Video dont nous parlions dans notre preview sur les APU A-Series du constructeur. Comme nous le redoutions, la fonctionnalité est grisée sur un PC équipé d'une Radeon et semble réservée uniquement aux APU.
Pour le reste les pilotes apportent un décodage XviD accéléré dans les applications Microsoft type Media Center et corrigent un certain nombre de bugs concernant Crossfire dans F1 2010, The Witcher 2, Riddick 2, Cars 2, Civilization V et Lego : PotC.
Quelques gains de performances sont également ajoutés pour les HD 6000 allant jusque :
- +7% dans Crysis
- +8% dans F1 2010 en mode DirectX 11
- +5% dans FarCry 2
- +8% dabs HAWX
- +10% dans Unigine OpenGL
Vous pourrez retrouver ces pilotes en téléchargement sur le site d'AMD .
Intel présente le jeu d'instructions d'Haswell
C'est par l'un de ses blogs qu'Intel a présenté le jeu d'instructions qui animera Haswell, l'architecture utilisée pour les processeurs qui remplaceront Sandy Bridge début 2013 (le tock en 22nm).
Comme a son habitude Intel étend le déjà large jeu d'instructions x86 avec AVX2 (format PDF) . Les nouveautés sont multiples et l'on notera en premier lieu l'arrivée de version 256 bits SIMD des instructions arithmétiques x86 classiques dédiées aux entiers (une partie des instructions dédiées aux flottants ayant été traitée par AVX). Le but du SIMD étant d'appliquer pour rappel une même opération à plusieurs données en simultané, l'extension aux nombres entier est bienvenue. On trouvera également dans le lot des nouveautés présentées des opérations de manipulations sur les bits, pour aider côté cryptographie, et sur le calcul de hash (avec l'apparition de RORX et MULX entre autre). Des opérations de permutations, et de shift sur des vecteurs sont également de la partie.
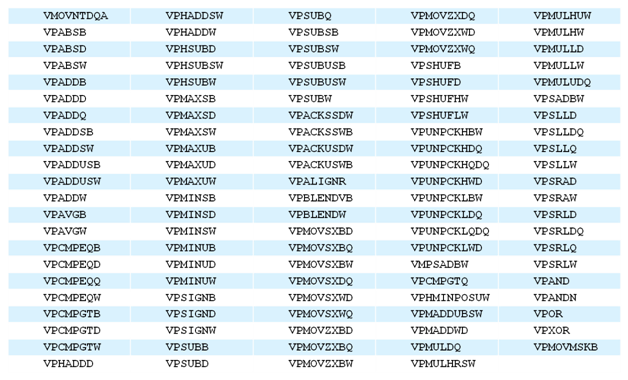
Les instructions entières SIMD 256 bits ajoutées par AVX2
D'autres instructions très "GPU" sont ajoutées avec en premier lieu des Gather qui permettent de charger dans des registres des données non adjacentes en mémoire. Le plus gros morceau reste l'implémentation du FMA, Fused Multiply Add. Pour rappel ces instructions permettent d'effectuer en une instruction une multiplication et une addition (a x b + c). Avec son architecture Bulldozer, AMD sera le premier à proposer le FMA dans un processeur (les AMD FX/Zambezi attendus pour la fin de l'été) avec une implémentation de type FMA4. Intel de son côté se contente d'une version FMA3. La différence entre les deux versions est que le FMA4 permet de stocker le résultat d'une opération dans un registre additionnel (d = a x b +c) là ou en FMA3, le résultat doit être stocké dans l'un des registres utilisés précédemment (par exemple : c = a x b + c). Une incompatibilité qui se paiera du côté des compilateurs et qui crée une différence de plus entre les architectures AMD et Intel.
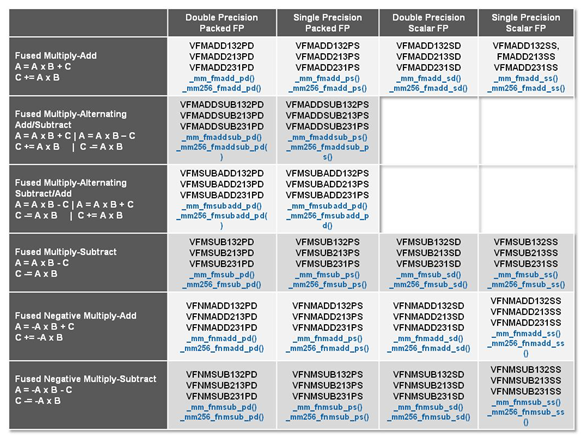
Les instructions FMA3 proposées par AVX2)
Si l'on regrette l'incompatibilité FMA3/FMA4 entre AMD et Intel (en notant que et Intel, et AMD ont changé leur fusil d'épaule sur le sujet, Intel ayant présenté d'abord un FMA4 avant d'arriver au FMA3, AMD ayant fait l'inverse !), AVX2 continue sur la lancée d'AVX en rendant le jeu d'instructions x86 de plus en plus capable d'effectuer des opérations en parallèle de manière efficace. Un modèle intéressant, censé contrer en partie la poussée du GPGPU, mais qui nécessitera un gros travail côté compilateurs pour pouvoir tirer parti des nouvelles instructions.
AFDS: AMD dévoile la FSA pour OpenCL
Ce qui est probablement l'annonce la plus importante de l'AFDS a été quelque peu éclipsée hier compte tenu des détails dévoilés sur la future architecture des GPUs AMD : la FSA.

Phil Rogers, AMD Corporate Fellow, dévoile les évolutions à venir dans le calcul hétérogène.
Un frein à l'utilisation du GPU computing réside dans l'overhead énorme lié à son exploitation, un point qu'AMD entend bien faire disparaître avec la Fusion System Architecture, une combinaison hardware et software destinée à simplifier le GPU computing et son utilisation combinée avec les cores CPUs.
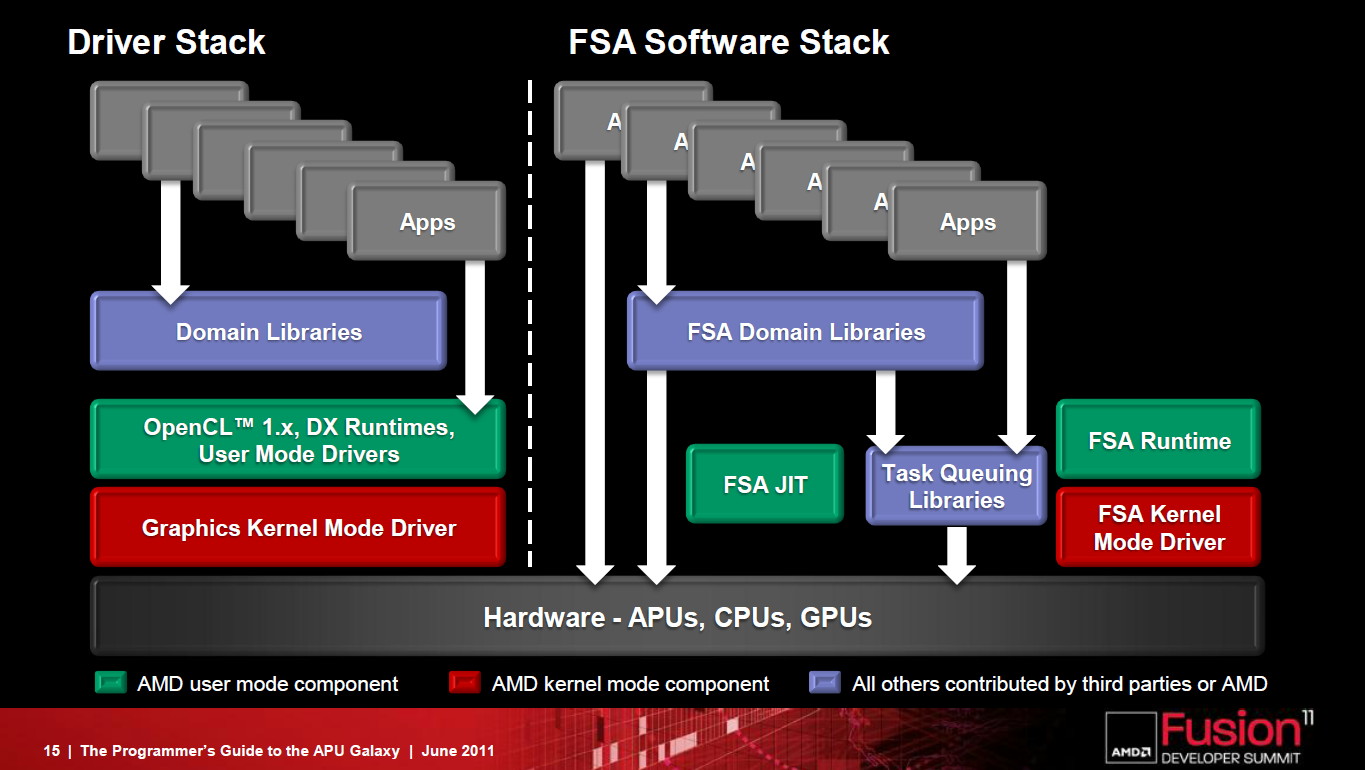

La FSA fait disparaître la lourdeur de la plateforme GPU compute actuelle.
Comme son nom l'indique, la FSA est avant tout pensée pour les APUs dans lesquels cores CPU et GPU sont proches l'un de l'autre, ce qui implique une communication simplifiée entre eux et une gestion d'un espace mémoire unifié plus simple à mettre en place. AMD compte cependant faire profiter les GPUs présents sur les cartes graphiques de tout ceci, grâce au PCI Express 3.0 qui offrira une bande passante supérieure ainsi qu'un espace unifié cohérent.

Cores CPU et GPU travaillent main dans la main plus efficacement grâce à la FSA.
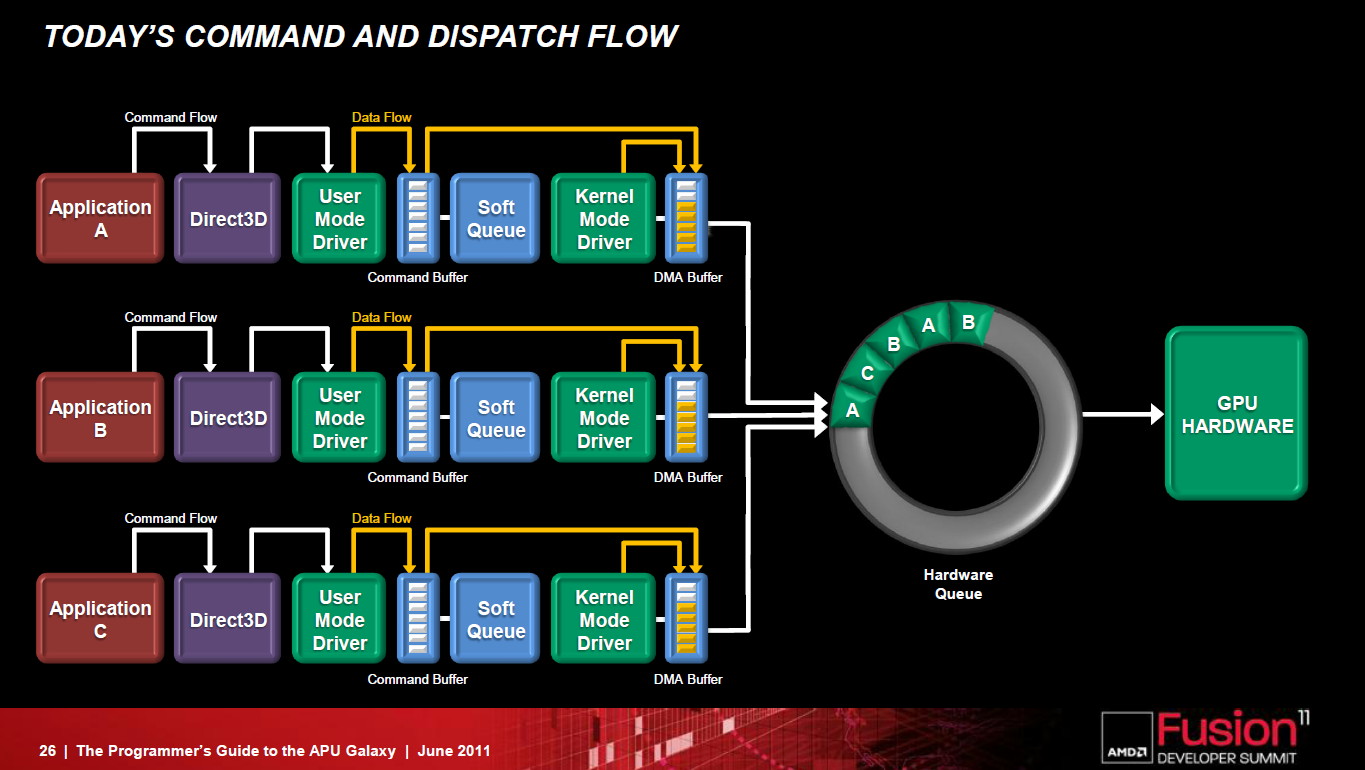
La FSA n'est pas une nouvelle API mais une plateforme optimisée pour OpenCL et destinée à remettre à plat l'utilisation du GPU computing. Latence réduite, fin des copies de données inutiles entre les espaces CPU et GPU, pointeurs partagés entre CPU et GPU, possibilité d'un accès bas niveau au hardware pour des librairies hyper optimisées, modèle de queues hardware repris du SMP
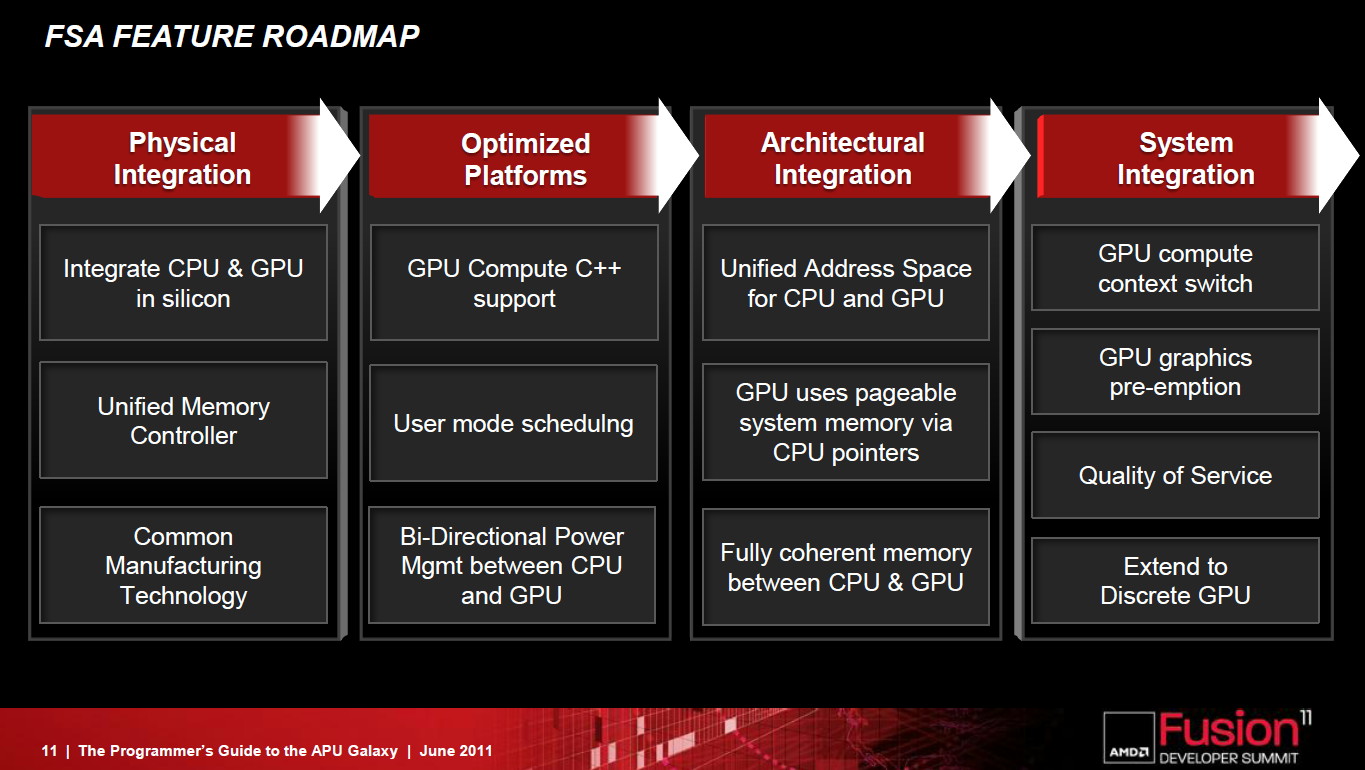
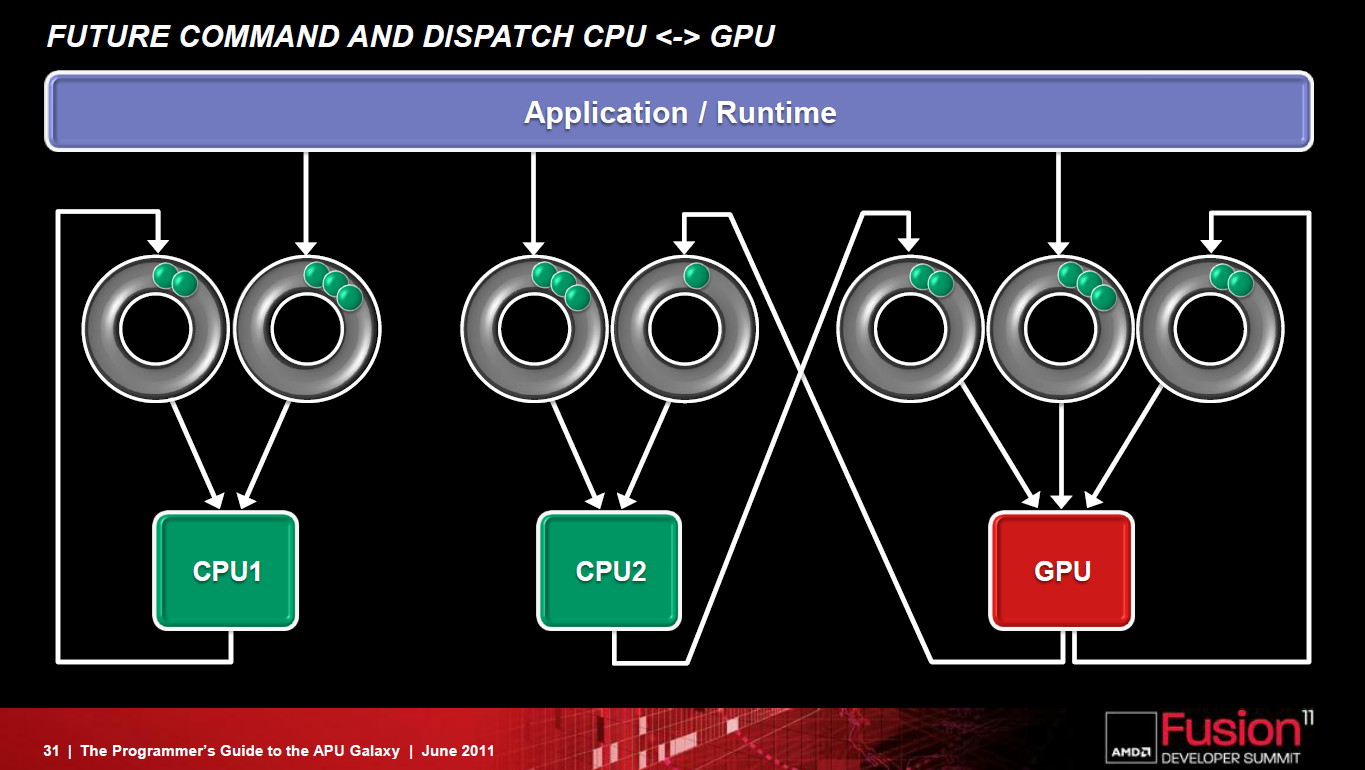
L'arrivée complète de la FSA se fera dans les 3 ans selon AMD, dont une partie (le dispatching optimisé) introduite en principe cette année avec la nouvelle architecture GPU dévoilée à l'AFDS également. AMD entend rendre la FSA ouverte à la concurrence, reste à voir si cet appel trouvera un écho chez Intel et Nvidia !
Dans tous les cas il est intéressant d'observer qu'AMD, vu comme plutôt passif dans le domaine du GPU computing ces dernières années, à décidé de prendre à bras le corps les challenges que représentent son exploitation. Il faut dire que le fabricant n'a pas d'autre choix, les APUs ayant un besoin criant de telles évolutions pour montrer tout leur intérêt. La documentation complète de la FSA devrait être publiée avant la fin de l'année de manière à permettre aux développeurs de s'y préparer.







SSD Intel Series 710 et 720
ComputerBase vient de publier quelques informations sur deux nouveaux SSD développés par Intel, les Series 710 et 720. Ces derniers viseront principalement le marché des entreprises.
Equipés de mémoire MLC 25nm et d'une interface Serial ATA 3Gb/s comme les Series 320, les Series 710 misent avant tout sur les performances en écriture et l'endurance. Les spécifications officielles côté performances restent à première vue en effet assez traditionnelles avec 270 Mo en lecture et 210 Mo en écriture séquentielle (contre 260/205 pour les Series 320 300 Go par exemple). On parlerait également de 36000 IOPS en lecture aléatoire sur des blocs de 4k (39500 pour le Series 320). Côté écriture seules les performances sur la totalité du disque sont évoquées, avec un avantage certain par contre pour le 710 series (on passe de 400 IOPS en lecture 4k pour le Series 320 300 Go à 2400 pour le 710). Une mesure IOPS en écriture 4k sur 8 Go (celles que l'on vous donne dans nos tests ) plus traditionnelle n'est malheureusement pas donnée.

Côté endurance par contre, si le MTBF passerait "seulement" de 1.2 millions d'heures à 2, l'endurance en écriture évolue beaucoup plus significativement avec 1 PB pour le modèle 200 Go, extensible à 1.3 PB si l'on active 20% d'overprovisionning. A titre de comparaison le Series 320 300 Go ne propose que 30 TB d'endurance. Difficile de dire doù vient la différence, on sait tout au plus que les puces mémoires MLC sont de type HET (dont l'acronyme signifierai High Endurance Technology) mais l'on ne sait pas ce qui justifie une telle différence sur la plan technique. On attendra avec impatience plus de détails sur le sujet, les 710 series sont attendues sous peu, dans des capacités de 100, 200 et 300 Go.
Le modèle Series 720 est plus original puisqu'il s'agira du premier SSD au format PCI Express d'Intel, qui plus est équipé de mémoire SLC (en 34nm). Les performances sont rapidement d'un autre ordre avec 2200 et 1800 Mo/s en lecture et écriture séquentielles. Les IOPS en lecture et écriture 4k (100% du disque) sont annoncées à 180k et 56k. C'est stratosphérique puisqu'à titre de comparaison, l'IOdrive duo de Fusion-IO en SLC se "contente" de 1.5 Go en lecture/écriture séquentielle et 186k d'IOPS 4k en lecture. Les Series 720 seront disponibles en version 200 et 400 Go.
AFDS: L'architecture des futurs GPUs AMD!
La première journée du Fusion Summit s'est terminée par une session surprenante durant laquelle Michael Mantor, Senior Fellow Architect, et Mike Houston, Fellow Architect, ont dévoilé la future architecture GPU d'AMD avec de très nombreux détails, ne laissant que quelques éléments spécifiques au rendu 3D de côté.

Michael Mantor, AMD Senior Fellow Architect.
AMD travaille sur cette nouvelle architecture depuis près de 5 ans déjà et a pour objectif principal d'en simplifier le modèle de programmation pour convaincre un maximum de développeurs de se pencher sur la puissance de calcul offerte par les GPUs. Il s'agit également de la première architecture a avoir été influencée en profondeur par l'intégration d'ATI dans AMD et par le projet Fusion.

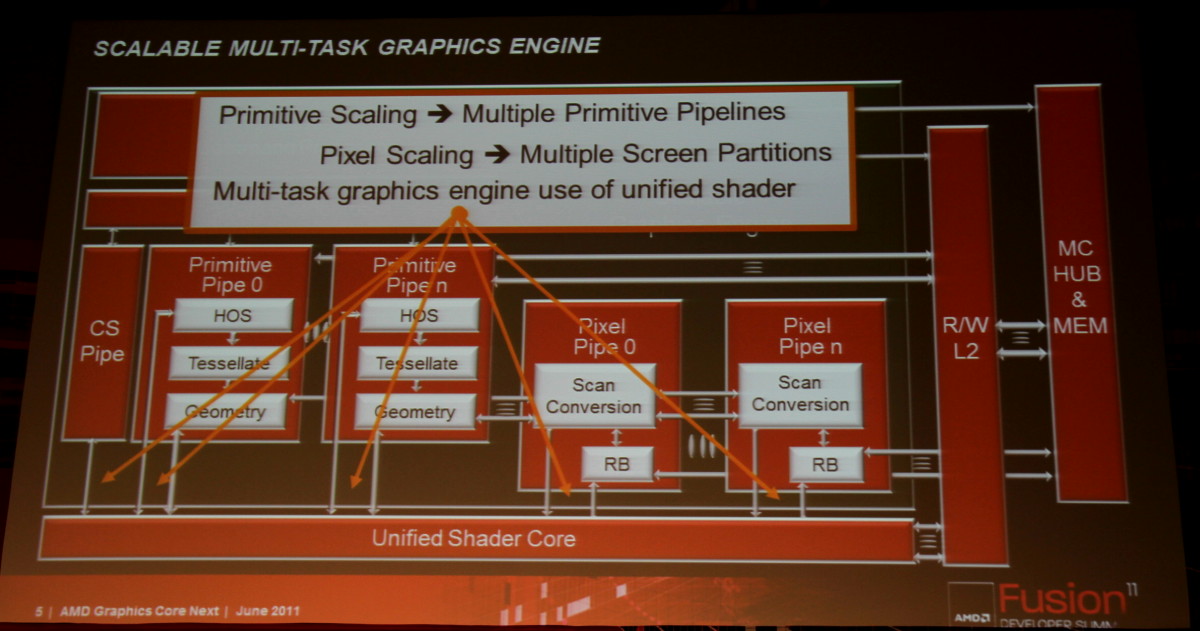
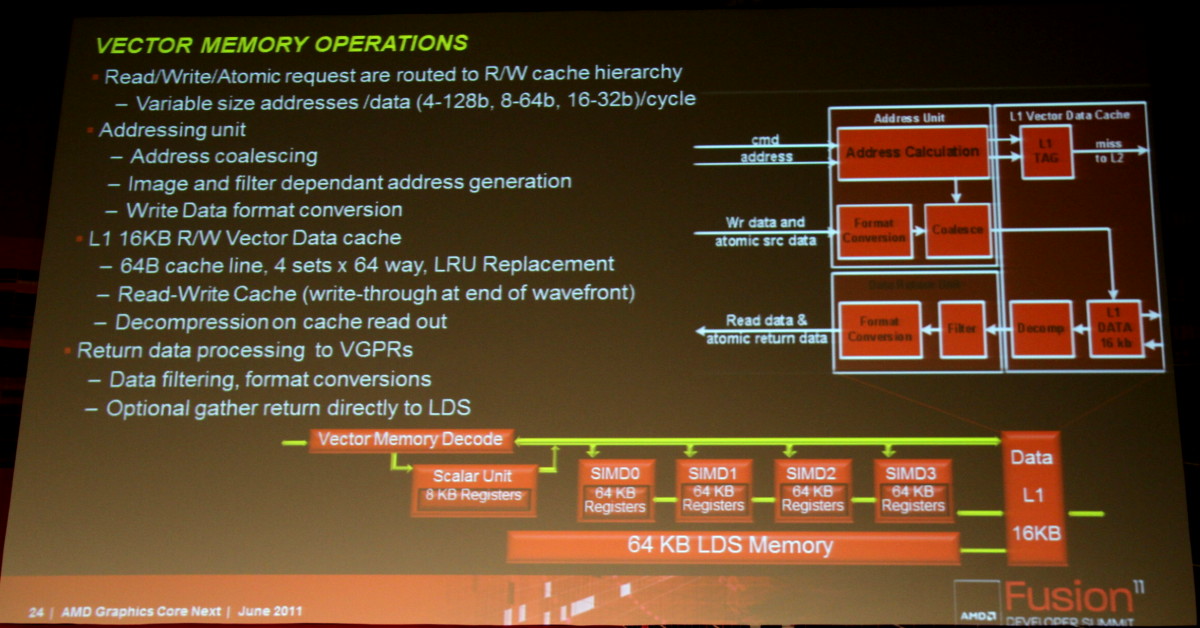
Cette architecture marque ainsi une rupture significative par rapport aux GPUs actuels en se débarrassant du modèle VLIW, qui repose sur l'exécution simultanée de plusieurs instructions indépendantes, au profit d'un fonctionnement scalaire du point de vue du programmeur. Le front-end, les processeurs de commandes et la structure des caches ont par ailleurs été entièrement revus pour proposer un mode compute plus performant et plus flexible ainsi que pour traiter efficacement le multitâche qui va devenir de plus en plus importants pour les GPUs.
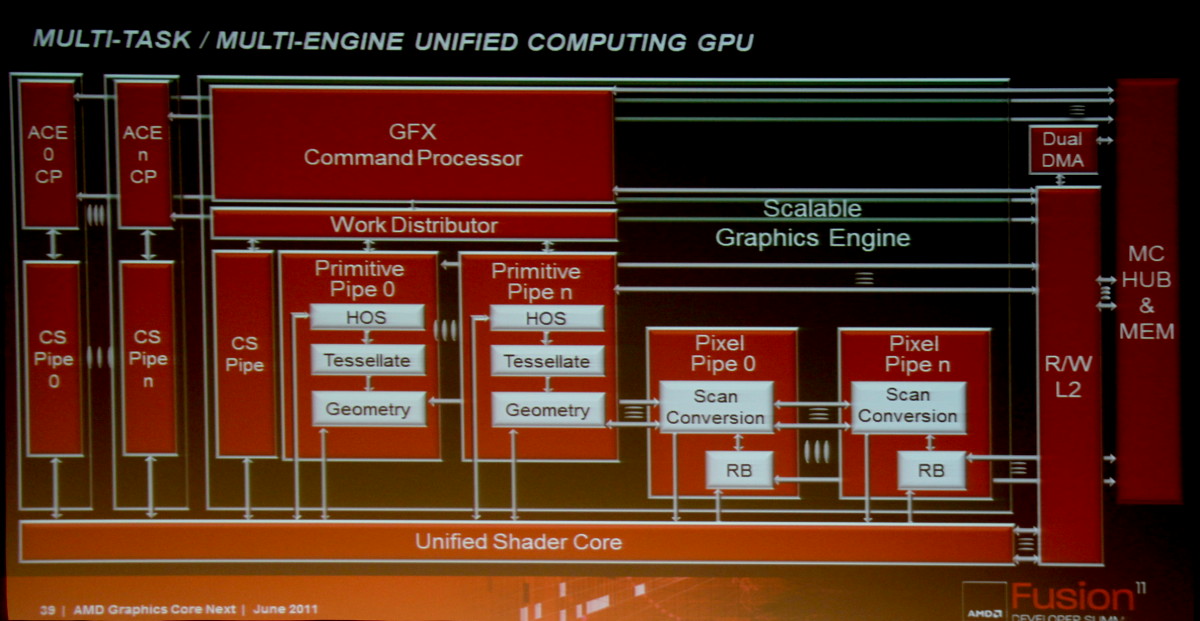
Des Asynchronous Compute Engines (ACE) font ainsi leur apparition pour prendre en charge les tâches compute sans passer par la partie graphique. Cette dernière n'est cependant pas en reste puisque les unités de gestion de la géométrie et des pixels sont parallélisées, ce qui profitera à la tessellation. Contrairement à l'approche de Nvidia, la prise en charge de la géométrie n'est pas distribuée au niveau des blocs d'unités de calcul, mais reste découplée de celles-ci.
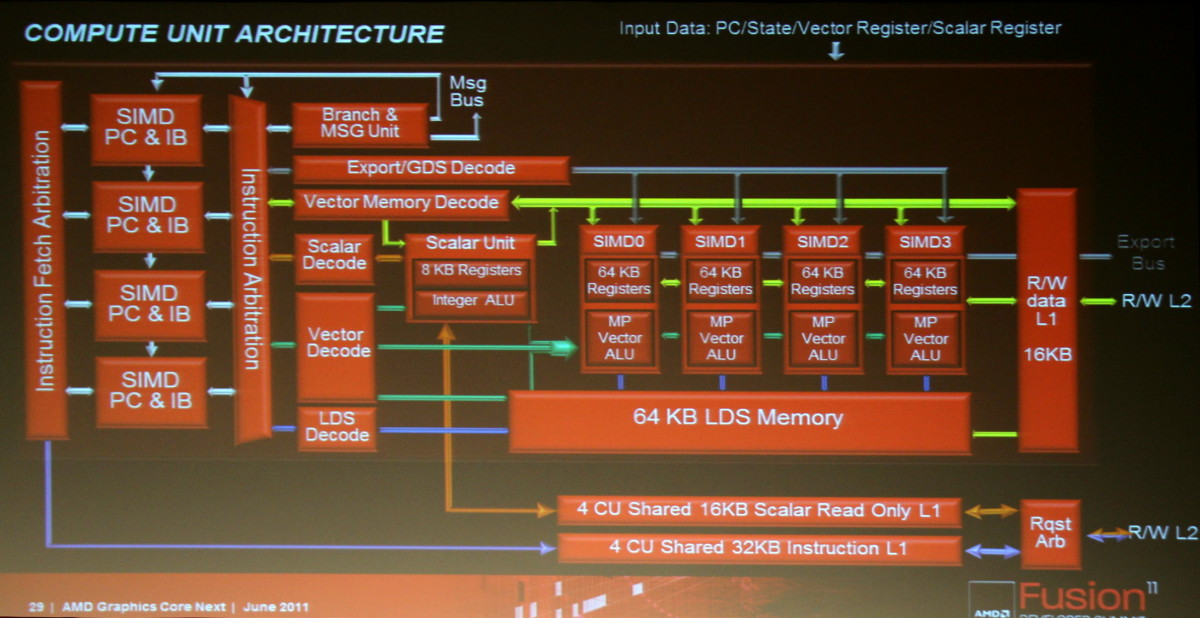
Les SIMDs actuels disparaissent au profit de Compute Units. Chaque CU dispose dorénavant d'une unité scalaire et de 4 petits SIMDs indépendants similaires à ceux des GPUs Nvidia. Grossièrement, un SIMD de Cayman peut exécuter une instruction vec4 sur 16 éléments à chaque cycle alors que chaque CU est capable d'exécuter 4 instructions sur 16 éléments issus de 4 groupes différents plus une instruction scalaire. La puissance de calcul d'une CU est donc similaire à celle d'un SIMD actuel mais devrait gagner nettement en efficacité.
AMD n'a pas voulu préciser quand cette architecture devrait être introduite et s'est contenté d'indiquer que le GPU de Trinity ne serait pas basé sur celle-ci mais bien sur l'architecture vec4 des Radeon HD 6900. Les bruits de couloir nous font cependant état d'une arrivée prévue dès cette année, voire même d'une démonstration du GPU qui l'inaugurera lors du keynote de clôture du Fusion Summit !
Il ne faudrait donc attendre que quelques mois pour voir ce qu'apportera en pratique cette nouvelle architecture prometteuse sur le papier. Si elle facilitera à terme l'optimisation du compilateur GPU, elle demandera cependant un effort important aux équipes chargées des pilotes compte tenu de la rupture avec les GPUs actuels. Concernant le coût de cette nouvelle architecture, AMD nous a indiqué qu'il n'était que légèrement plus élevé que celui des architectures actuelles, certaines parties étant plus complexe mais d'autres simplifiées. Elle ne devrait donc pas être un frein à l'augmentation du nombre d'unités de calcul.
Notez que cette architecture proposera plus de modularité qu'auparavant puisqu'en plus du nombre de CUs, AMD pourra faire varier le nombre d'ACEs, le nombre de pipelines dédiées à la géométrie ou aux pixels, la puissance de calcul en double précision (de 1/2 à 1/16) De toute évidence, la première implémentation devrait être un GPU haut de gamme avec au moins 30 CUs, plusieurs ACEs et un calcul en double précision à demi-vitesse.
Voici donc les grandes lignes de cette future architecture, sur laquelle nous essaierons de revenir plus en détails après le Fusion Summit.
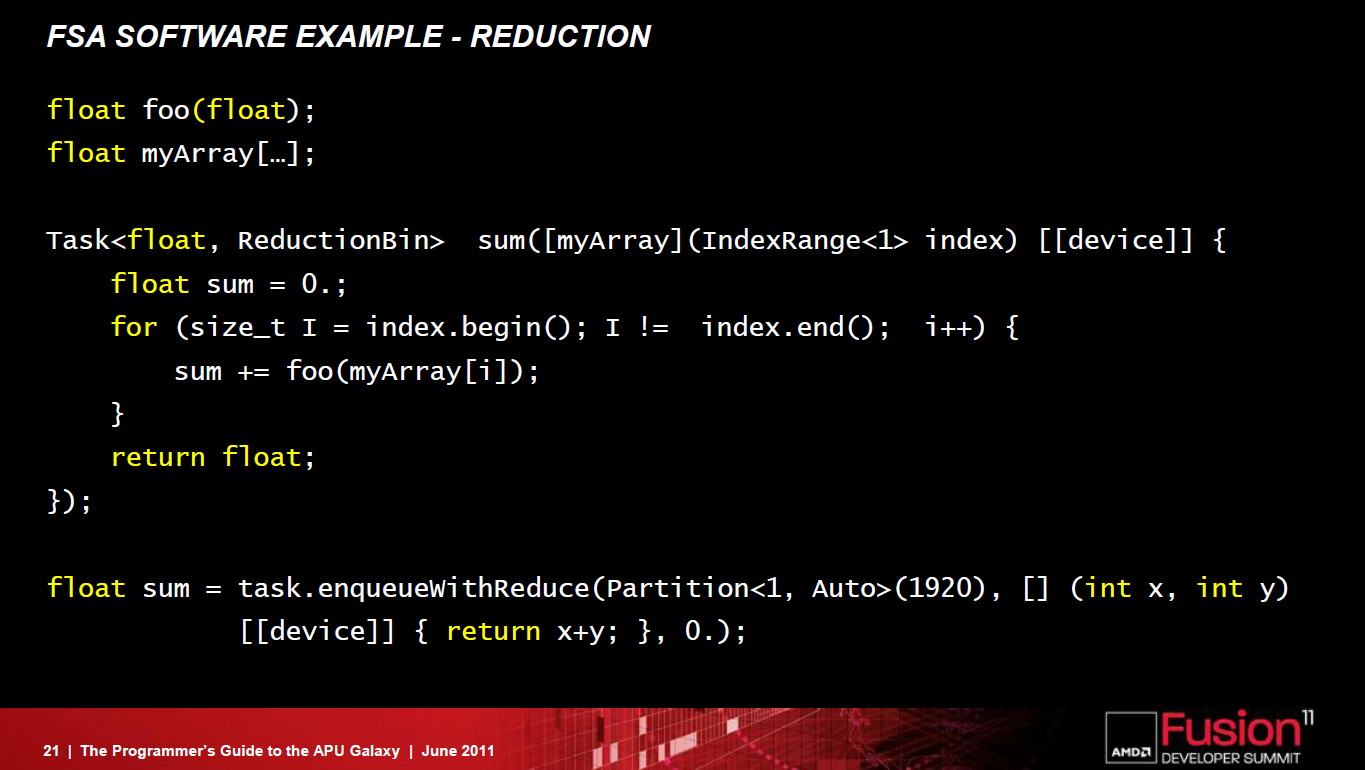
Nous avons publié quelques informations de plus dans une seconde actualité et voici tous les détails dévoilés par AMD sur cette architecture :




















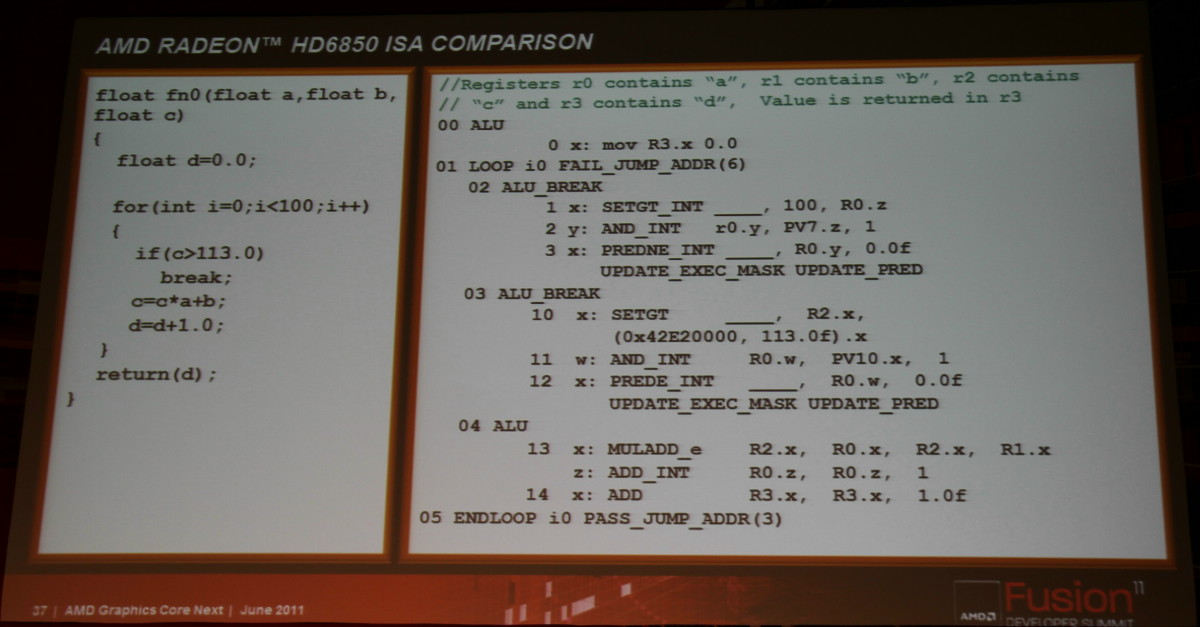
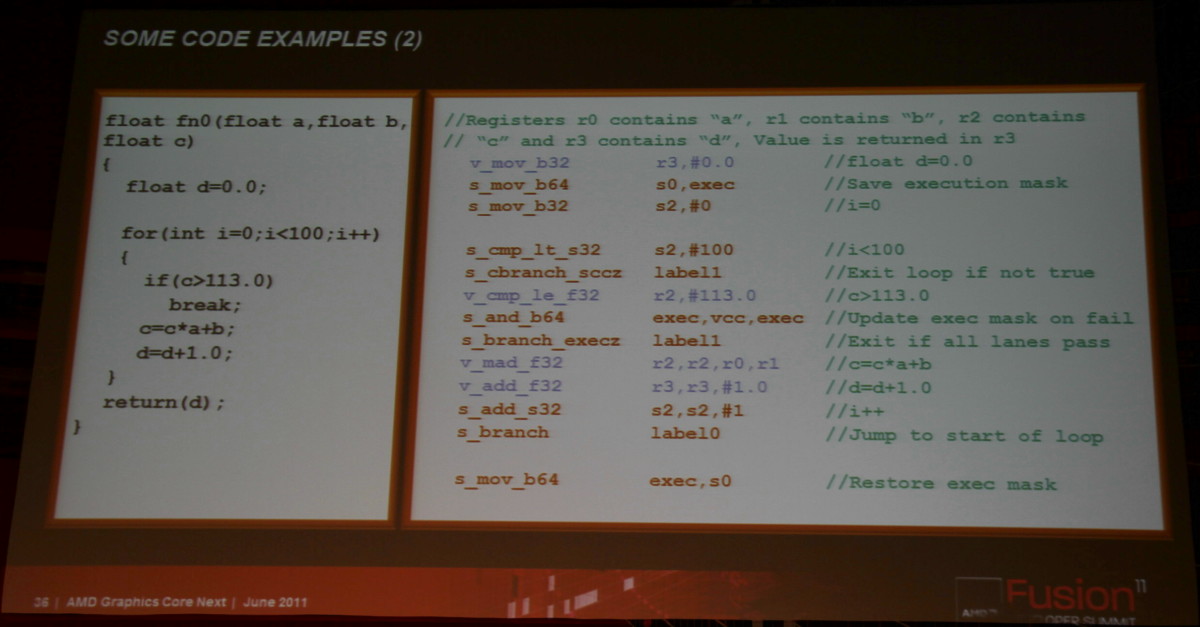
Ainsi que deux exemples de code généré pour l'architecture actuelle d'une part et pour cette nouvelle architecture d'autre part :