
AMD FX-8150 et FX-6100, Bulldozer débarque sur AM3+
Publié le 12/10/2011 par Marc Prieur



Les unités de calculsChacune des deux unités d'exécution x86 du module Bulldozer est composée de deux ALUs (unités arithmétiques et logiques) ainsi que de deux AGUs (unités de génération d'adresse). Plus précisément, AMD parle en fait d'AGLUs plutôt que d'AGUs, ces unités étant capables d'effectuer des opérations simples.
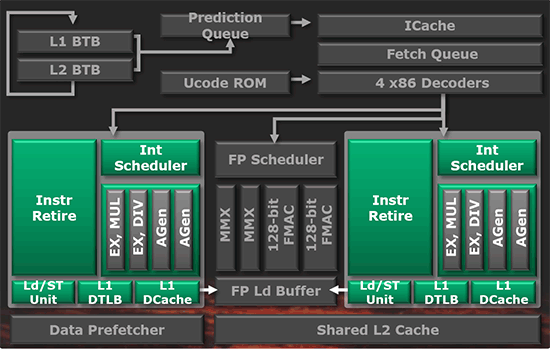
A contrario, l'architecture K10 proposait 3 ALUs et 3 AGUs, ce qui fait qu'avec 3 ALUs contre 2 ALUs Bulldozer peut dans le pire des cas ne pas dépasser 67% d'un K10 sur un seul thread.
Côté FPU chaque module est doté d'une seule FPU partagée entre les deux curs. Capable de gérer 2 thread, un pour chacun des curs parents, elle peut également combiner ses deux unités FMAC 128 bits pour traiter les opérations AVX 256 bits.
Qu'en est-il en pratique ? Nous avons effectué à l'aide d'AIDA une mesure de la latence et du débit pour les instructions sur K10, Bulldozer et Sandy Bridge dont voici un extrait. La latence représente le délai, exprimé en cycle, pour traiter une seule instruction, alors que le débit mesure la vitesse entre chaque instruction traitée lorsqu'on en traite plusieurs.
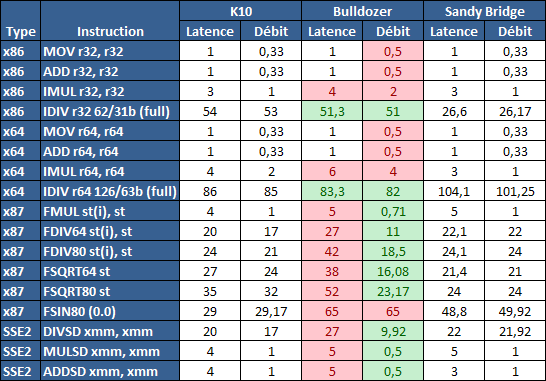
Par rapport à K10, on peut voir que Bulldozer améliore très légèrement la division entière 32 ou 64 bits (IDIV). Cette dernière reste par contre nettement plus rapide en 32 bits sur Sandy Bridge, mais plus lente en 64 bits. La multiplication entière (IMUL) souffre par contre sur Bulldozer tant en terme de latence que de débit, alors que les opérations plus simples telles que la copie (MOV) ou l'addition (ADD) conservent une bonne latence mais voir leur débit baisser, ce qui est lié au passage de 3 à 2 ALUs.
Du côté des nombres flottants (x87), et hormis le calcul du sinus qui souffre beaucoup par rapport à K10 qui était nettement plus rapide que SNB, on note une amélioration globale des débits, un bon point si on enchaine le même type d'instruction. Malheureusement c'est loin d'être systématique et la latence souffre beaucoup. Du côté des instructions SSE2, qui sont également exécutées par la FPU, on note le même phénomène.
Comme prévu les instructions AES apportent une amélioration des performances importantes, puisque l'on obtient les scores suivants en fonction des architectures (fréquence fixe de 3.2 GHz) sous le test AES de AIDA 64 :
- 35 315 pour Yorkfield (Core 2 Quad 65nm)
- 433 093 pour Sandy Bridge (Core i7 32nm)
- 35 743 pour Deneb (Phenom II X4)
- 52 833 pour Thuban (Phenom II X6)
- 344 131 pour Zambezi (FX-8)
L'apport de l'AVX et du SSE4 est pour sa part plus délicat à démontrer, d'autant plus qu'il est difficile de trouver des versions d'un même programme optimisées correctement pour chaque niveau de jeu d'instruction et pour chaque architecture. Le logiciel y-cruncher par exemple dispose d'une version AVX qui est environ 13% plus rapide que la version SSE3 (les versions SSE4 n'étant pas plus rapide que la version SSE3) sur Sandy Bridge. Ce même code AVX, qui a été optimisé sur la seule architecture AVX disponible (Sandy Bridge) est 10% moins rapide que la branche SSE3 sur Zambezi.
En ce qui concerne le FMA4 et le XOP, AMD nous a fournit il y a 48h une version de x264 censée tirer partie de ces instructions. Malheureusement sur nos tests nous n'avons noté aucune amélioration de performances par rapport à la version classique, que ce soit sur la 1ère ou la 2ème passe d'un encodage. Il faut bien dire que les optimisations XOP/FMA4 sont encore au stade de développement pour x264 et n'ont pas intégré la branche de développement principale. Voilà donc une partie qui reste à explorer quant aux performances de l'architecture Bulldozer.
Sommaire
1 - Une nouvelle architecture
2 - Zambezi devient AMD FX
3 - AM3+, un passage quasi obligatoire ?
4 - AMD FX-8150 et FX-6100 en test
5 - Nouveau protocole de test
6 - Les unités de calculs
7 - Performances des caches
8 - Performances mémoire
9 - Efficacité du CMT
10 - CMT, Turbo Core 2.0 et Windows 8
11 - Tests à 3.2 GHz
12 - Consommation et efficacité énergétique
2 - Zambezi devient AMD FX
3 - AM3+, un passage quasi obligatoire ?
4 - AMD FX-8150 et FX-6100 en test
5 - Nouveau protocole de test
6 - Les unités de calculs
7 - Performances des caches
8 - Performances mémoire
9 - Efficacité du CMT
10 - CMT, Turbo Core 2.0 et Windows 8
11 - Tests à 3.2 GHz
12 - Consommation et efficacité énergétique
13 - Overclocking
14 - Rendu 3D : Mental Ray et V-Ray
15 - Compilation : Visual Studio et MinGW/GCC
16 - Compression : 7-zip et WinRAR
17 - Encodage : x264 et MainConcept H.264
18 - Traitement photo : Lightroom et Bibble
19 - IA d'échecs : Houdini et Fritz
20 - Jeux 3D : Crysis 2 et Arma II : OA
21 - Jeux 3D : Rise of Flight et F1 2011
22 - Jeux 3D : Total War Shogun 2, Starcraft II et Anno 1404
23 - Moyennes
24 - Conclusion
14 - Rendu 3D : Mental Ray et V-Ray
15 - Compilation : Visual Studio et MinGW/GCC
16 - Compression : 7-zip et WinRAR
17 - Encodage : x264 et MainConcept H.264
18 - Traitement photo : Lightroom et Bibble
19 - IA d'échecs : Houdini et Fritz
20 - Jeux 3D : Crysis 2 et Arma II : OA
21 - Jeux 3D : Rise of Flight et F1 2011
22 - Jeux 3D : Total War Shogun 2, Starcraft II et Anno 1404
23 - Moyennes
24 - Conclusion
Vos réactions
Contenus relatifs
- [+] 17/03: AMD baisse ses prix AM3+/FM2+
- [+] 14/03: Bundle AMD pour les FX-6 et FX-8
- [+] 25/11: AMD dégaine ses offres de fin d'ann...
- [+] 04/10: AMD lance les Bristol Ridge Pro
- [+] 24/08: Deus Ex en bundle... avec les AMD F...
- [+] 19/05: Total War : Warhammer offert par AM...
- [+] 02/02: Excavator FM2+ et nouveaux ventirad...
- [+] 28/01: L'AM3+ a droit au M.2 et l'USB 3.1 ...
- [+] 15/12: AMD FX-6330 = FX-6300 + 100 MHz
- [+] 01/10: Perfs avec 2, 4, 6 et 8 curs : 4 j...