
AMD Radeon HD 6970 & 6950, seules et en CrossFire X
Publié le 15/12/2010 par Damien Triolet



CaymanAvec Cayman, AMD a pris un risque en décidant de revoir un aspect de larchitecture de ses unités de calcul qui navait pas évolué depuis la Radeon HD 2900 XT. Dune manière simplifiée, nous caractérisons les unités de calcul dAMD de vec5, ce qui signifie quelles sont capables dexécuter jusquà 5 instructions en parallèle. Cependant, avec une telle architecture, si le code à exécuter ne permet pas de paralléliser autant dinstructions, elles ne seront pas pleinement exploitées, à linverse de larchitecture scalaire de Nvidia qui peut maintenir un rendement élevé dans un maximum de situations. Deux approches tout aussi valides lune que lautre.
Attention à ne pas confondre unité de calcul avec « core », une notion marketing utilisée par Nvidia pour se comparer aux CPUs et suivie par AMD qui en profite pour compter 5 cores par unités de calcul vec5. Globalement vous pouvez voir les choses sous 2 angles : une unité vec5 dAMD est plus efficace quune unité scalaire de Nvidia ou un core dAMD est moins efficace quun core Nvidia.
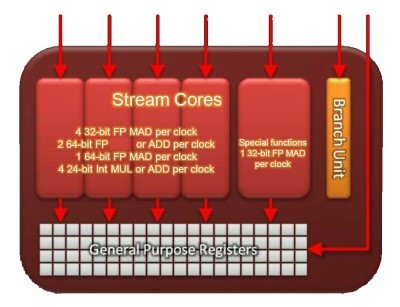
Gros plan sur une unité de calcul vec5 de Cypress.
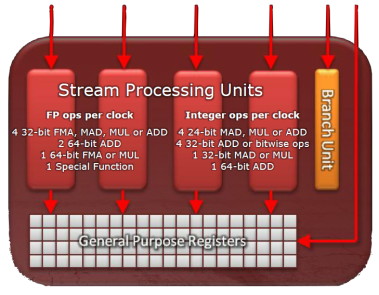
Gros plan sur une unité de calcul vec4 de Cayman.
Avec le GF104 des GeForce GTX 460, ainsi que ses dérivés, Nvidia sest rapproché dun fonctionnement vectoriel pour augmenter le rendement et AMD entend faire de même avec Cayman, mais dans lautre sens, en passant de vec5 à vec4. Les unités de calcul de Cayman sont ainsi moins puissantes que celle des précédents GPU dAMD, mais elles sont statistiquement plus efficaces, mais pas plus performantes, la nuance est importante. Par contre en étant plus simples, ces unités occupent moins de place et consomment moins, ce qui permet den augmenter le nombre, tout autre chose restant égale.
Plus en détail, les précédents GPUs Radeon reposaient sur des unités de calcul de type 4+1, avec une ligne dexécution capable de prendre en charge les instructions complexes. Cest ce « +1 » dont AMD a décidé de se débarrasser. En contrepartie ces instructions complexes doivent être traitées sur les autres lignes via une succession dopérations plus simples. Ces instructions monopoliseront ainsi 3 des 4 lignes dexécution, ce qui les rendra bien plus gourmandes puisque seule une instruction simple pourra être exécutée en parallèle contre 4 auparavant.
Sans ce « +1 » un peu spécial et dans certains cas difficile à alimenter correctement, le compilateur va voir sa tâche grandement simplifiée, ce qui pourra même dans quelques cas rendre ces unités vec4 plus performantes que les précédentes vec5 mais globalement AMD a maintenant besoin de plus dunités de calcul vec4 pour maintenir un même niveau de performances.
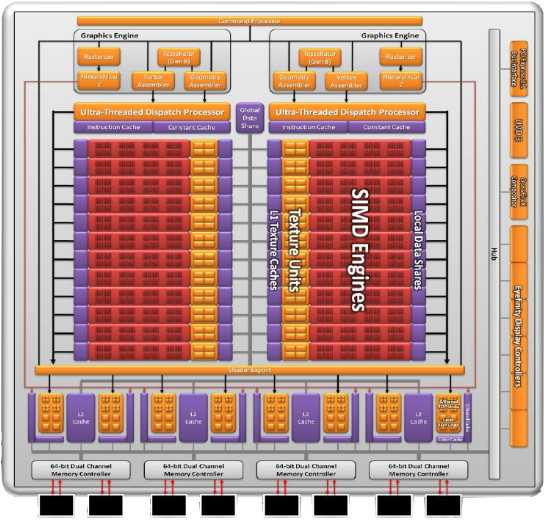
Alors que Cypress, le GPU des Radeon HD 5800, disposait de 20 blocs de 16 unités de calcul vec5, Cayman dispose de 24 blocs de 16 unités de calcul vec4. Nous avons donc affaire à 320 unités vec5 contre 384 unités vec4, ce qui est moins flatteur une fois transposé en « cores » puisque cela nous donne 1536 cores « seulement » pour Cayman contre 1600 pour Cypress. Un détail important se retrouve cependant au niveau des unités de texturing dont le nombre est fixé à 4 par bloc. Cayman voit donc sa puissance à ce niveau augmenter de 20% à fréquence égale. Notez quAMD indique avoir augmenté le débit de calcul en double précision, mais il sagit dune manière tordue dinterpréter le fait que le « +1 » ne prenait pas en charge la double précision. Une unité de Cayman est identique à une unité de Cypress à ce niveau.
AMD ne sest pas arrêté là et à introduit dautres petites améliorations à son architecture. La première concerne le traitement de la géométrie qui se voit parallélisé de manière à casser la limite dun triangle par cycle. Attention cependant, il est parallélisé mais pas distribué au niveau des blocs dunités de calcul contrairement à ce qui se passe du côté des GeForce. Voici une manière simplifiée de voir les choses :
Cypress : 1 unité complexe de traitement géométrique -> 1 triangle de 32 pixels par cycle,
Cayman : 2 unités complexes de traitement géométrique -> 2 triangles de 16 pixels par cycle
GF100/GF110 : 16 unités simples de traitement géométrique -> 4 triangles de 8 pixels par cycle
Nvidia conserve donc un avantage avec les petits triangles et surtout, avec plus dunités simples de traitement géométrique, évite un engorgement au niveau du GPU lorsque de très nombreuses données sont générées par la tessellation. Pour combattre ce problème, AMD a élargi le buffer dédié dans Barts, le GPU des Radeon HD 6800, et Cayman et va plus loin avec ce dernier qui est capable de transférer toutes ces données temporairement dans la mémoire vidéo pour éviter de bloquer tout le GPU. Cette fonction nest cependant pas directement exposée et nous ne savons pas si elle senclenche automatiquement lors de certaines charges ou si AMD doit y avoir recours manuellement au cas par cas.
AMD a également amélioré ses ROPs pour augmenter le débit des formats 16 bits entiers et 32 bits flottants. Ils gagnent également en efficacité avec lantialiasing, ainsi que lors de lécriture en mémoire en mode « compute ». A ce sujet, AMD sest inspiré de ce que propose Nvidia et permet lexécution simultanée de plusieurs kernels différents alors quauparavant le GPU devait leur attribuer des périodes dexécution successives. Il en va de même pour la communication avec le CPU qui pourra se faire dans les deux sens en même temps grâce à 2 moteurs DMA, comme le GF100/110. Les contrôleurs mémoire ont par ailleurs été revus pour pouvoir supporter plus facilement de la GDDR5 rapide.

Cayman : 2.64 milliards de transistors
Enfin, AMD a franchi un pas important en intégrant, pour la première fois dans un GPU, une unité chargée de contrôler sa consommation. Via des centaines de capteurs répartis dans tous les blocs du GPU, Cayman est capable de connaître sa consommation et de sautolimiter au niveau de la fréquence pour rester dans la consommation maximale définie. AMD parle dune granularité dune frame. Une précision et une réactivité qui na donc rien de comparable à ce que Nvidia propose avec les GeForce GTX 500. Cayman se comporte ici dune manière similaire à celle des CPUs récents si ce nest quil ne dispose pas de fonction Turbo qui lui permettrait daugmenter sa fréquence lorsque la consommation est inférieure à la limite. Cette technologie, nommée PowerTune, devrait se généraliser dans tous les futurs GPUs dAMD et prendra tout son intérêt dans le monde mobile !
Tous ces changements ont gonflé le nombre de transistors de Cayman qui passe de 2.15 à 2.64 milliards, soit une augmentation de 23% qui se retrouve également au niveau de la taille du die qui passe, elle, de 334 à 389mm². Une augmentation de 16% seulement qui indique que la densité des transistors est maintenant supérieure.
Sommaire
Vos réactions
Contenus relatifs
- [+] 30/11: Pilotes Radeon Software 17.11.4
- [+] 04/11: MAJ: Radeon Software 16.11.2 pour C...
- [+] 20/10: Pilotes AMD Radeon Software 16.10.2
- [+] 08/09: Pilotes AMD Radeon Software 16.9.1
- [+] 01/09: Pilotes AMD Radeon Software 16.8.3
- [+] 10/08: Pilotes AMD Radeon Software 16.8.1 ...
- [+] 26/04: AMD lance la Radeon Pro Duo à 1650
- [+] 25/03: GDC: D3D12, multi-GPU et frame pipe...
- [+] 29/06: CrossFire et Radeon R9 Fury X, Fiji...
- [+] 02/05: DirectX 12 supportera un mix de GPU