
Radeon X1900 XTX, X1900 XT et X1900 CrossFire en test
Publié le 24/01/2006 par Damien Triolet



BranchementsLune des principales nouveautés qui a été introduite avec le GeForce 6800 est le branchement dynamique dans les pixel shaders. Cela permet de faciliter lécriture de certains shaders et daugmenter lefficacité dautres shaders en évitant de calculer une partie de ceux-ci sur les pixels qui nen ont pas besoin. Par exemple pourquoi appliquer le filtrage très coûteux de ladoucissement de bordure dune ombre si le pixel est au milieu de lombre ? Un branchement dynamique permet de détecter si le pixel en a besoin ou pas. Splinter Cell Chaos Theory utilise cette technique alors que Les Chroniques de Riddick calcule tout pour chaque pixel. Les performances baissent de 10 à 15% dans le premier cas et de plus de 50% dans le second. Bien entendu les algorithmes ne sont pas identiques mais cela donne une image de ce que peuvent permettre les branchements dynamiques.
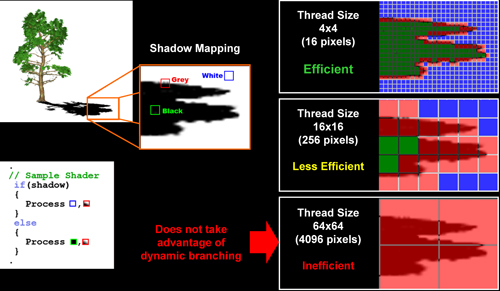
Mais tout nest pas si rose puisque ceux-ci ne sont efficaces que dans des cas bien précis. Les branchements ont une réputation d´être difficile à gérer, c´est particulièrement le cas dans les CPU qui doivent prédire le résultat du branchement à l´avance pour masquer la latence du calcul de celui-ci. Dans un GPU, les pixels sont traités par groupes de centaines voire de milliers de pixels, ce qui permet de masquer automatiquement cette latence. Le problème des CPUs n´existe donc pas réellement. Par contre un autre problème se pose. Lors dun branchement, tous les pixels doivent prendre la même branche sans quoi les 2 branches doivent être calculées pour tous les pixels, avec des masques pour nécrire que le résultat de la branche requise pour chaque pixel.
ATI dispose sur le papier d´un net avantage avec une unité de traitement dédiée aux branchements et des threads de très petite taille, voyons si cela se confirme en pratique via un petit test que nous avons développé qui nous permet de modifier la granularité du branchement, c´est-à-dire le nombre moyen de pixels consécutifs qui vont prendre une même branche. Nous spécifions la branche à prendre par colonne de pixels, une colonne sur 2 doit afficher un shader complexe et l´autre peut passer cette partie du rendu. Des triangles de taille moyenne en mouvement sont affichés à l´écran et traversent ces zones qui utilisent différentes branches, ce qui implique que tant les triangles et leur position que la taille de la colonne influent sur l´efficacité du branchement ce qui est proche d´une situation réelle.
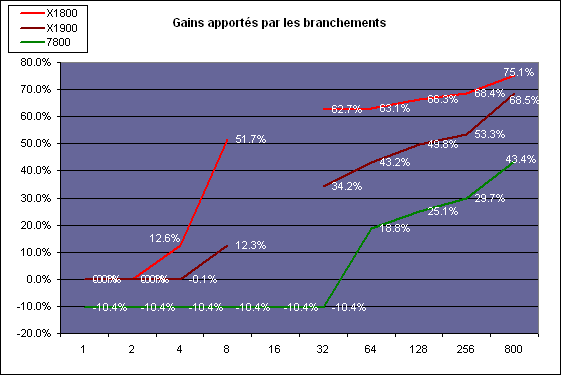
Avec des colonnes étroites, les GPU ne peuvent pas profiter du branchement pour éviter la partie complexe sur la moitié des pixels, mais par contre doivent traiter les instructions de branchement, ce qui fait baisser les performances au lieu de les augmenter. Tout du moins chez Nvidia. ATI dispose d´une unité dédiée aux branchements qui travaille en parallèle des pipelines de pixel shading et de texturing ce qui masque le coût des instructions de branchement.
Les petits threads d´ATI, de 16 pixels (4x4) permettent un gain de performances dès que la largeur des colonnes atteint 4 pixels alors qu´il faut attendre une largeur de 64 pixels chez Nvidia ! Vous remarquerez cependant que le Radeon X1900 ne commence à profiter des branchements qu´à partir d´une taille de colonne de 8 pixels (soit une granularité de 8x? pixels). Ceci est dû au fait que le Radeon X1900, du fait de son nombre plus élevé de pipelines de pixel shading, doit travailler sur des threads de 48 pixels au lieu de 16, ce qui le rend moins efficaces. Les threads ont une forme "en coin" qui représente 3 carrés de 16 pixels. Notez qu´un bug donne des résultats incohérents avec une taille de colonne de 16 pixels avec les drivers beta utilisés pour le test alors que ce problème n´existait pas avant. Nous avons donc retiré ceux-ci.
ATI atteint malgré tout des gains nettement supérieurs à ceux que permet l´architecture de Nvidia, que ce soit avec la Radeon X1800 qu´avec la Radeon X1900. Notez qu´il s´agit bien ici de gain et pas de performances pures. Ainsi bien que profitant moins des branchements, la Radeon X1900 est presque 3x plus performante sur ce pixel shader que la X1800. Quant à la 7800 GTX qui dispose elle aussi d´une forte puissance de calcul à la base, elle est toujours devant la X1800 en étant parfois 2x plus performante.
Globalement, l´efficacité des branchements chez ATI est donc de très loin supérieure à celle que l´on retrouve chez Nvidia, ce qui devrait permettre leur utilisation dans de plus en plus de cas, ce que les développeurs devraient apprécier. Si cela permettait à la X1800 de compenser son manque de puissance de calcul face à la 7800, cela permet à la X1900 de prendre une nette avance sur ce genre de shader.
Nous avons ensuite exécuté un second test lié aux branchements dynamiques. Cette fois nous avons rendu une fractale de Mandelbrot (test qui était utilisé à l´époque des GeForce FX) d´une manière classique et ensuite à base de branchements. Cet algorithme utilise un nombre élevé d´itérations identiques qui dans le shader classique se retrouvent une à la suite de l´autre. Dans le shader à base de branchements, nous avons utilisé une boucle autour de 2 itérations avec un test qui vérifie si le calcul d´itérations supplémentaires est utile ou pas. Si il n´est pas utile nous sortons de la boucle en laissant tomber les itérations qui ne sont pas nécessaires.

Shader complexe exige, en version de base, le X1800 n´est pas à la fête. Le Radeon X1900 corrige cela et passe devant le 7800. Mais tout cela n´est plus une surprise. Les résultats obtenus à partir du shader qui utilise les branchements sont intéressants : ils confirment qu´ATI peut en tirer un bénéfice très important. Par contre ils montrent que ce n´est pas toujours le cas chez Nvidia, puisque dans le cas présent, le fait que le GeForce 7800 ne dispose pas d´unité de calcul dédiée aux branchements implique qu´il va perdre un nombre énorme de cycles à traiter ces branchements. Cela couplé au fait qu´il n´en tire des bénéfices qu´avec une faible granularité entraîne qu´il voit ses performances chuter. Un shader optimisé pour ATI peut donc réduire les performances de l´autre côté. Les choix des développeurs pourraient donc jouer un rôle important dans les performances des Radeon par rapport aux GeForce. Vont-ils utiliser les branchements ? Les méthodes classiques ? Les 2 méthodes ? Difficile de répondre à cette question aujourd´hui.
Vertex ShaderNous avons testé les performances en T&L, VS 1.1, VS 2.0 et VS 2.X/3.0 dans RightMark :
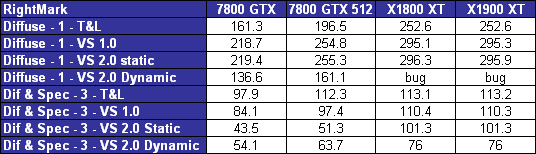
Depuis notre précédent test, les performances en vertex shading de la Radeon X1800 ont progressé. Etant donné qu´il n´y a pas eu de changement à ce niveau, celles de la X1900 sont identiques. Notez qu´un bug empêche de faire tourner l´un des tests sur les Radeon. Avec les branchements statiques, Nvidia souffre d´un problème de performances mais celui-ci n´est pas nouveau et résulte probablement d´un bug dans les drivers que Nvidia n´est pas pressé de corriger.
Contrairement à Nvidia, ATI fait l´impasse sur le support du Vertex Texturing qui pourtant nous semblait être requis pour pouvoir afficher le support des Vertex Shader 3.0. ATI prétend que son support n´est en réalité pas obligatoire, ce qui est étrange. En y regardant de plus près, nous avons remarqué qu´ATI reporte à DirectX le support du vertex texturing, mais ne l´autorise sur aucun format de texture, ce qui parait suspect et ressemble à une manière habile de contourner les spécifications de DirectX en affichant ainsi le support des Vertex Shader 3.0 sans que le Vertex Texturing ne puisse être utilisé. Bref tout ceci n´est pas très net. Mais quoi qu´il en soit, en pratique, le Vertex Texturing n´est pas très important, et mise à part 2-3 démos technologiques, il n´est pas utilisé parce que trop limité tout du moins dans son implémentation actuelle.
Accès aux texturesLes Radeon X1900 sont identiques à ce niveau aux Radeon X1800, nous n´avons donc pas réalisé de tests supplémentaires à ce niveau, mais vous pouvez consulter ceux présents dans le test de la X1800.
Les unités de texturing des X1900 ont cependant acquis une nouvelle capacité nommée fetch4 qui était déjà présente dans les Radeon X1300 et X1600. Lors du filtrage d´une texture, l´unité de texturing récupère 4 texels et les mélange entre eux via une interpolation linéaire. Certains rendus, comme celui de certaines ombres, ont besoin d´un autre filtrage (PCF par exemple). Dans ce cas, il faut accéder 4 fois à la texture en point sampling et utiliser un pixel shader pour filtrer les 4 texels de la bonne manière. Nvidia accélère le filtrage PCF en hardware et n´a donc pas besoin de faire cette opération. Par contre les Radeon n´en sont pas capables.
Fetch4 permet en partie de contourner ce problème. Dans le cas d´une texture à 1 canal (comme les textures utilisées dans le rendu des ombres, ça tombe bien), fetch4 va remplir les 4 canaux utilisés habituellement par les 3 couleurs et la transparence avec les 4 texels qui vont donc être retournés au pixel shader tels quels, soit non filtrés. Le shader devra toujours s´occuper du filtrage par contre il ne faut plus qu´un accès à la texture au lieu de 4. 3DMark06 utilise cette possibilité des Radeon X1300/X1600 et X1900 et les développeurs devraient eux aussi le faire à l´avenir.
Sommaire
Vos réactions
Contenus relatifs
- [+] 04/05: Nvidia abandonne son GeForce Partne...
- [+] 27/04: AMD Vega 7nm en labo, Zen 2 échanti...
- [+] 18/04: ASUS AREZ, l'effet GeForce Partner ...
- [+] 10/04: Nvidia : fin du support Fermi et 32...
- [+] 27/03: Pilotes Radeon et GeForce pour Far ...
- [+] 20/03: Pilotes GeForce 391.24 pour Sea of ...
- [+] 20/03: Microsoft annonce DirectX Raytracin...
- [+] 20/03: Radeon Software 18.3.3 beta avec Vu...
- [+] 08/03: 3 millions de GPU vendus pour le mi...
- [+] 08/03: Radeon Software 18.3.1 optimisé pou...