
Les derniers contenus liés aux tags Nvidia et GDC
Afficher sous forme de : Titre | FluxGDC en approche, AMD et Nvidia sur les rangs
GDC: D3D12, multi-GPU et frame pipelining
GDC: VR: Nvidia Multi-Res Shading en pratique
GDC: Vers de nouveaux types de shaders ?
GDC: Async Compute : ce qu'en dit Nvidia
Microsoft annonce DirectX Raytracing
GDC: Nvidia parle du Tile Caching de Maxwell et Pascal
GDC: Nvidia va proposer des GTX 1080 et 1060 OC
GDC: Nvidia annonce la GeForce GTX 1080 Ti 11 Go (maj)
GDC: Wave programming pour booster les perfs
Microsoft annonce DirectX Raytracing



Microsoft a profité de l'ouverture de la GDC pour annoncer une nouvelle API, DirectX Raytracing (DXR) . Comme son nom l'indique, il s'agit d'une nouvelle API qui vient s'ajouter aux autres API DirectX pour standardiser l'utilisation de certaines techniques dites de raytracing. Le raytracing tente pour rappel de représenter de manière plus exacte le parcours de la lumière pour proposer des rendus réalistes. L'inconvénient de la technique étant son coût généralement prohibitif, même si des approximations existent.
A l'inverse, le rendu 3D dans les jeux actuel est basé sur la rasterisation, la projection d'une scène 3D en 2D avant d'y appliquer les traitements pour obtenir la couleur des pixels, avec des techniques plus ou moins avancées de gestion de lumière (les premiers jeux 3D se contentant d'imiter les effets de lumière en les dessinant directement dans les textures, tandis qu'aujourd'hui les pixel shaders s'appliquent sur l'image 2D ce qui limite les possibilités même si les développeurs sont extrêmement créatifs). Comme le rappelle le sous titre de l'annonce de Microsoft, "3D Graphics is a lie" (le rendu 3D est un mensonge) !
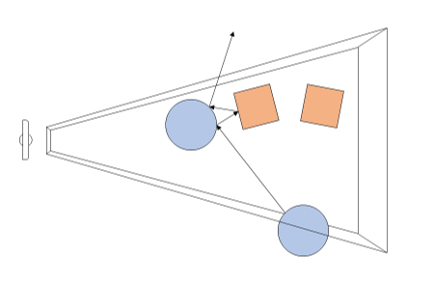
Avec DXR, Microsoft souhaite donc ajouter un peu de "réalisme" avec une petite dose de raytracing. Dans le détail, il s'agit d'une API complémentaire qui ajoute de nouvelles possibilités pour utiliser le raytracing par dessus les pipelines actuels de rasterisation. En pratique, DXR s'appuie sur une représentation de la géométrie pour lancer des rayons. Par dessus cette représentation, chaque objet ou groupe d'objet pourra définir des "raytracing shaders" et des textures spécifiques à utiliser. Une fois ceci crée, le lancé de rayons est appliqué, l'API définie les cas d'intersection, de non intersection, et de "presque" intersection (near miss), en gérant les cas ou les rayons rebondissent sur plusieurs surfaces (multi bounce).
Techniquement, le lancer de rayon est effectué a partir de la "caméra" dans la variante utilisée par DirectX, et peut se faire pour une sélection de pixels de l'écran ou la totalité (Microsoft prend l'exemple de ne le faire uniquement que pour les objets dont la surface est réfléchissante).

Un exemple de rendu DXR avec le moteur SEED d'EA, Project PICA
D'un point de vue compatibilité avec le matériel existant, Microsoft renvoi simplement vers les constructeurs pour les détails. Certains matériels sur le marché disposeraient déjà d'un support de DXR (on ne sait pas lesquels), et Microsoft semble proposer un mode de rendu alternatif s'appuyant sur Direct Compute pour fonctionner sur tout le matériel existant aujourd'hui (avec un niveau de performances on l'imagine réduit).
AMD nous a indiqué qu'ils collaboraient "étroitement" avec Microsoft "pour les aider à définir, améliorer et prendre en charge l'avenir de DirectX 12 et du ray tracing", un propos qui évite soigneusement de prononcer l'acronyme DXR. AMD dispose déjà d'une API de ce type utilisable sur de multiples plateformes avec Radeon Rays . Interrogé sur la question spécifique de l'accélération matérielle, AMD nous a indiqué qu'ils proposeraient, à un moment non défini, un pilote qui proposera une accélération DXR (au delà du mode "fallback" utilisant Direct Compute et qui lui marche sur tous les GPU, mais probablement en étant peu utilisable). Ce qui sera accéléré, et quelles cartes seront concernées n'est pas encore défini non plus selon le constructeur. On semble sentir une certaine précaution pour ne pas dire frilosité de la part de la société sur sa communication, il nous est difficile de savoir s'il s'agit d'un manque de préparation sur le sujet, d'un désaccord avec Microsoft sur certains choix effectués, ou d'autre chose.
Nvidia de son côté a évoqué son implémentation sous le nom de RTX, cette dernière ne s'appliquera qu'à compter des GPU Volta et ultérieurs (soit uniquement la Titan V dans les GPU "joueurs" actuels de la gamme du constructeur). Nvidia présente la technologie là aussi de manière assez vague, sous entendant que leur implémentation sera utilisable "via" DXR, mettant son API en avant sans que l'on sache si c'est simplement dans un but de démarcation compétitive ou autre chose. Là encore à l'image d'AMD, la communication des deux principaux constructeurs ne va pas exactement dans le même sens que celle de Microsoft (les relations entre Microsoft et les responsables GPU ont toujours été particulières, chacun tentant de tirer la couverture de son côté et de créer un avantage compétitif, que ce soit les constructeurs de GPU l'un face à l'autre, ou Microsoft à proposer une API et des fonctionnalités qui ne soient pas cross-platform).
Du côté des développeurs, Microsoft annonce que les moteurs Frostbite, SEED (plus haut), Unity et Unreal Engine proposeront une forme de support de DXR. Futuremark devrait également proposer un test de ce type pour une version de 3D Mark.
GDC: Nvidia parle du Tile Caching de Maxwell et Pascal
En parallèle de la GDC et lors de la présentation à la presse de la GeForce GTX 1080 Ti, Nvidia a communiqué officiellement pour la première fois au sujet d'une optimisation introduite depuis les GPU Maxwell : le Tile Caching.
Cet été, David Kanter de real world technologies avait mis en évidence un comportement étrange pour les GPU Maxwell et Pascal. Avec ceux-ci, la rastérisation de plusieurs triangles progressait par blocs plus ou moins petits de l'image (appelés tiles en anglais) et non pas strictement triangle par triangle. Contrairement à certaines analyses, nous étions alors sceptiques par rapport au rapprochement qui était fait avec le tile based rendering (TBR) ou tile based deffered rendering (TBDR) des GPU mobiles Adreno, Mali ou PowerVR. Ces modes de rendu sont peu efficaces avec une géométrie complexe et posent problème avec certaines techniques de rendu avancées. Des contraintes qui sont incompatibles avec un GPU haut de gamme destiné au PC. Nous estimions alors qu'il s'agissait d'une optimisation opportuniste spécifique à certaines situations.
Face à ces discussions et à l'introduction par AMD d'une approche similaire, voire identique, Nvidia vient de clarifier le fonctionnement de la rastérisation sur ses GPU Maxwell et Pascal. Ce qui commence par lui donner un nom : le Tile Caching.
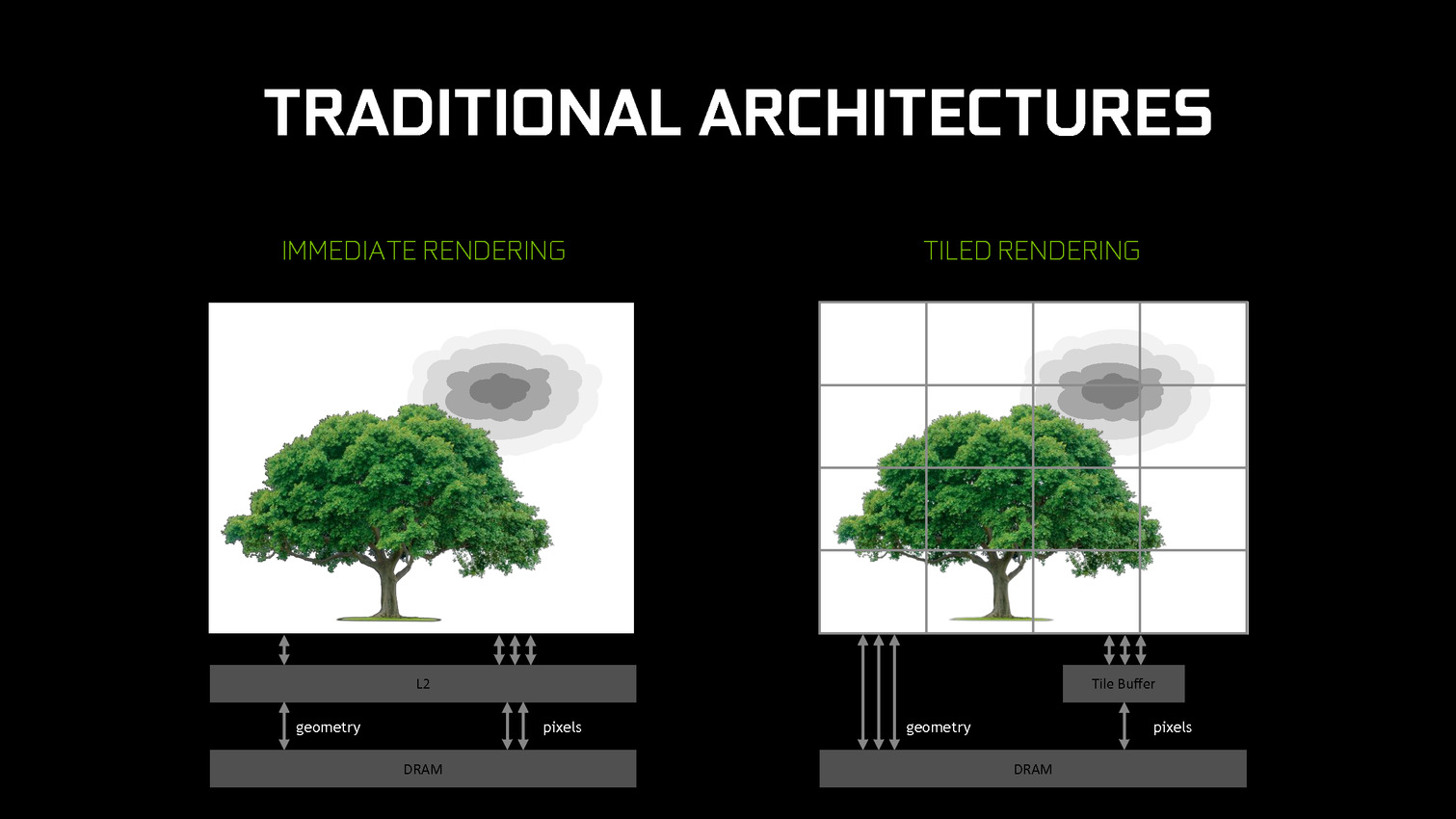
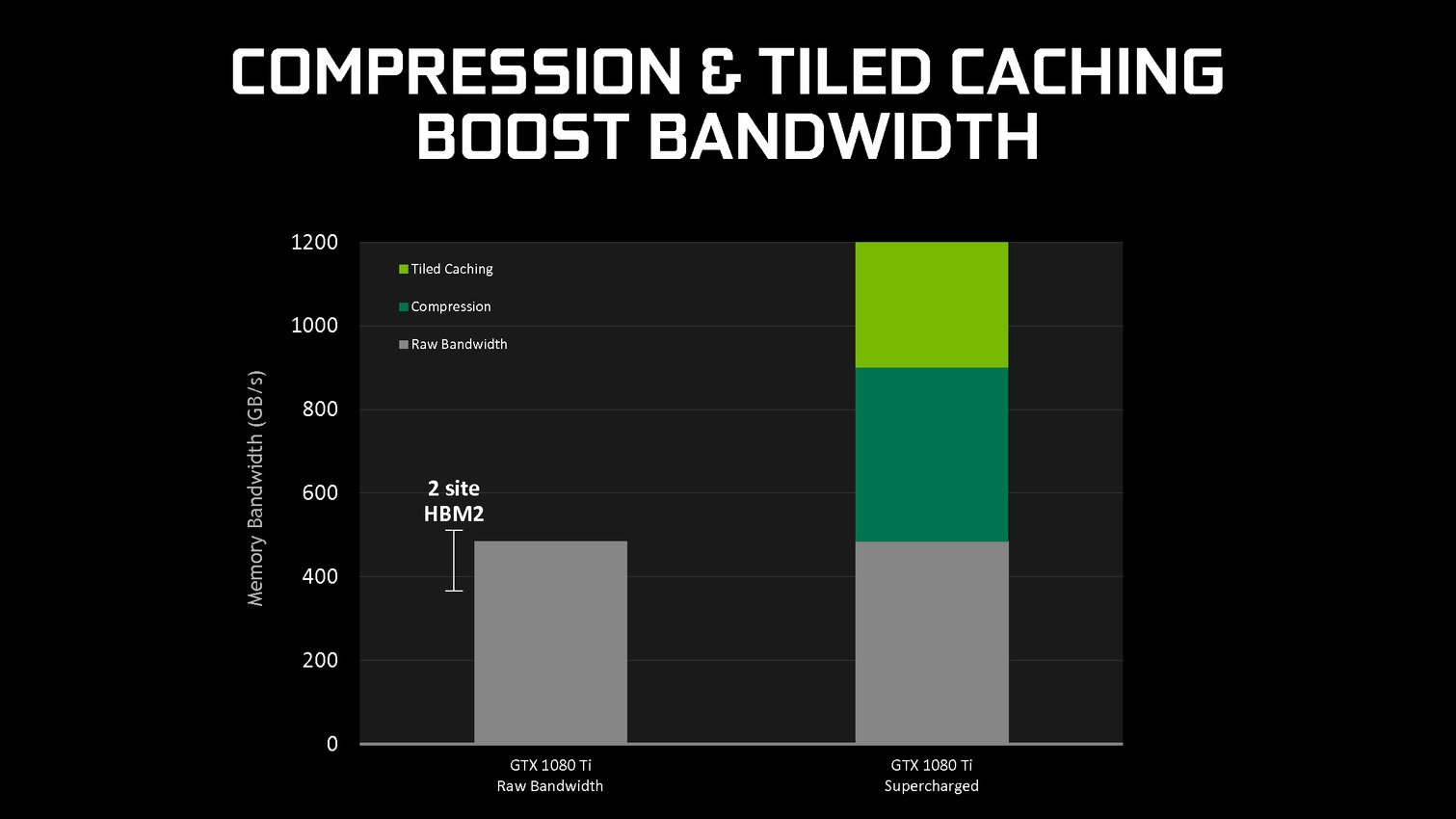
Traditionnellement, les GPU d'AMD et de Nvidia fonctionnent suivant le principe du rendu immédiat. Un triangle est pris en charge, il est découpé en pixels, les pixels sont écrits en mémoire. Si un second triangle traité par la suite se trouve entre le premier et la caméra, des pixels auront inutilement été calculés et écrits en mémoire. Différentes approches sont utilisées pour éviter ce gaspillage de ressources, mais il reste en partie présent.
De leur côté, les GPU mobiles font appel au TBR/TBDR qui fonctionne en deux passes. La première consiste à traiter toute la géométrie et à la récrire en mémoire en la réorganisant de manière à savoir quels triangles sont présents chaque bloc de l'image. Lors d'une seconde passe, ces triangles sont envoyés vers le moteur de rastérisation tile par tile (avec tri de visibilité dans le cas du TBDR). La construction de l'image dans de petites tiles en cache fait que les pixels ne seront écrits qu'une seule fois en mémoire. Cela revient à utiliser plus de bande passante pour la géométrie mais moins pour les pixels. Un compromis dont l'intérêt dépend évidemment du ratio entre la charge sur ces deux points.
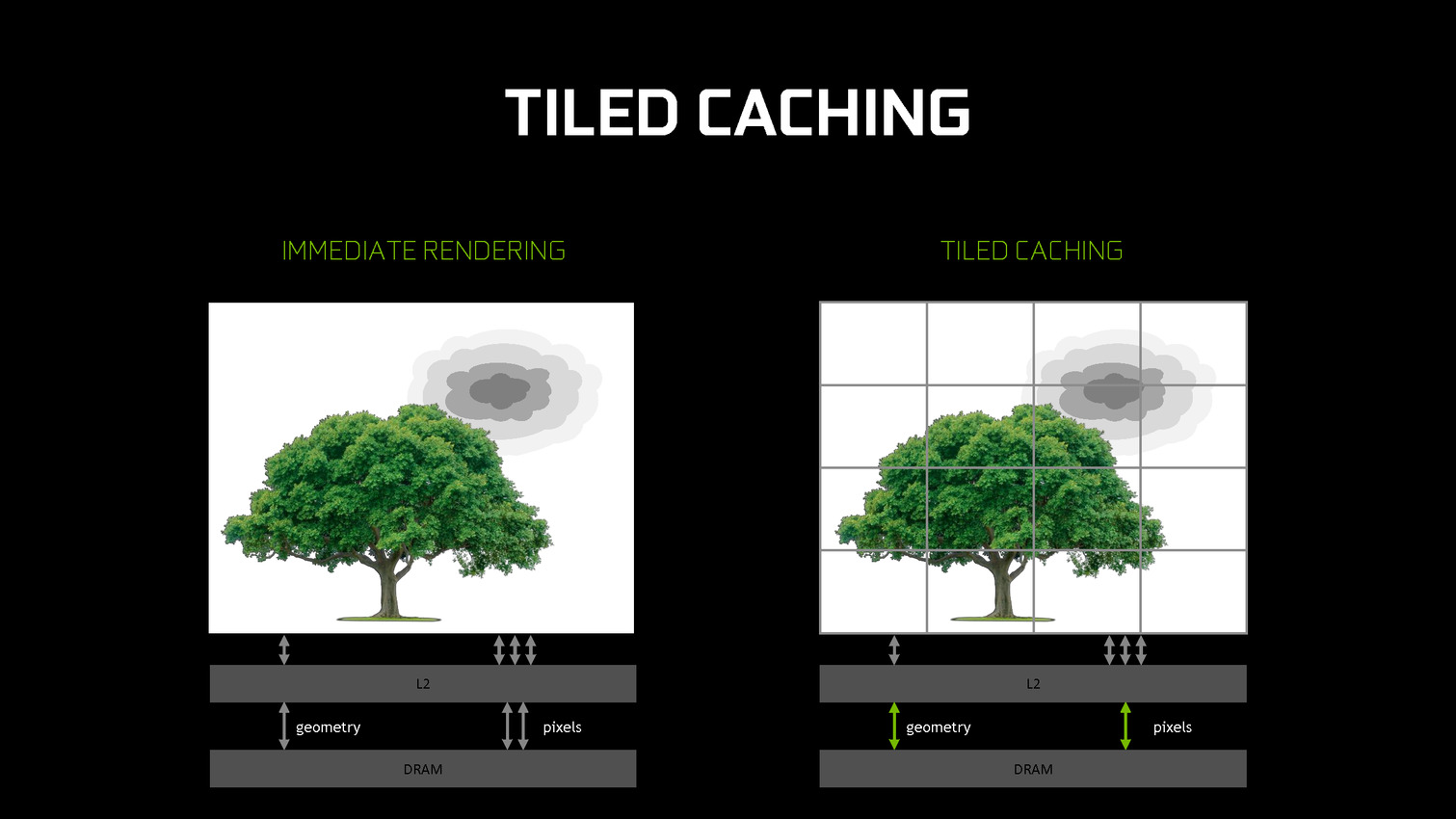
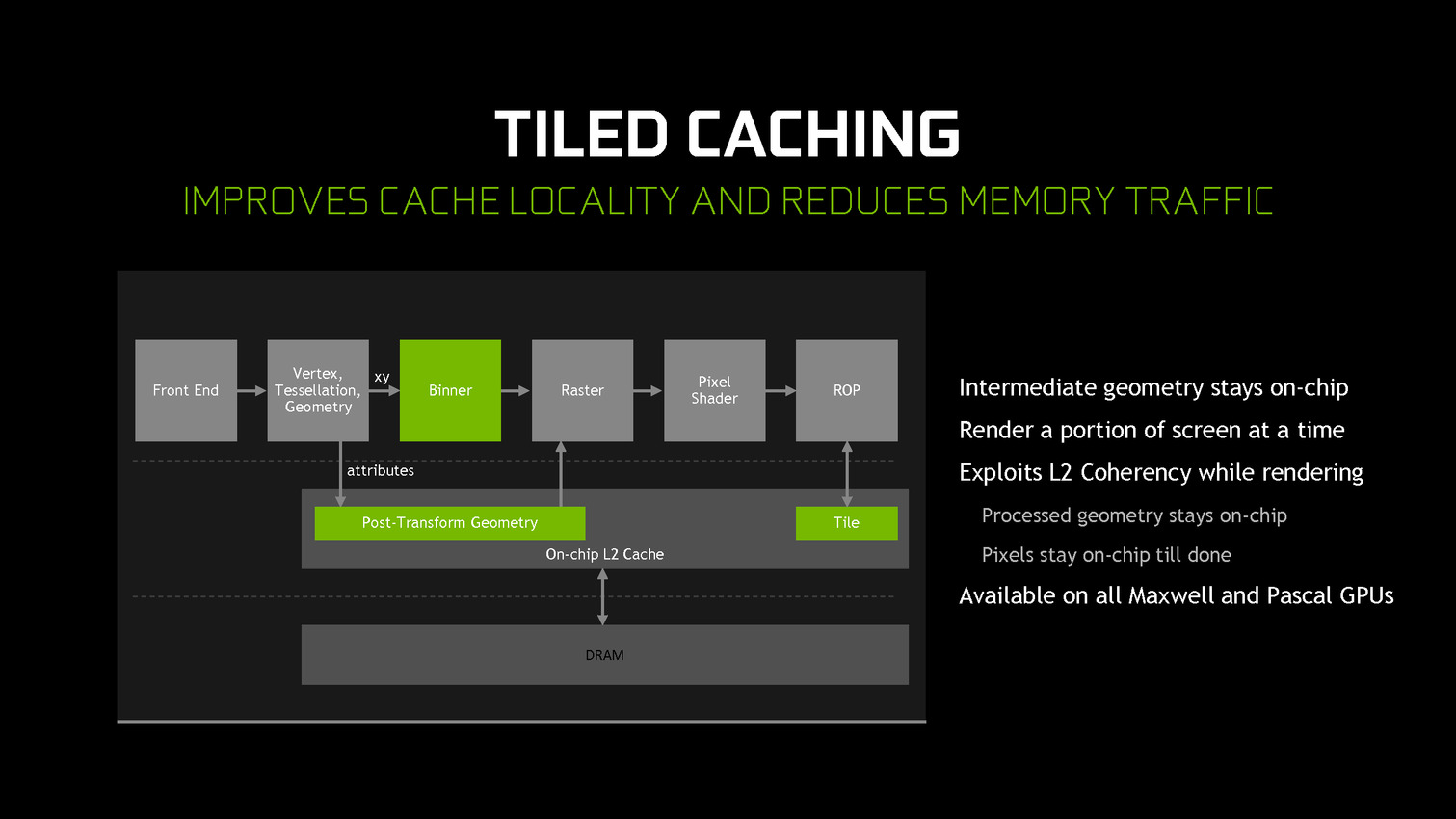
A partir des GPU Maxwell, Nvidia a cherché à pouvoir bénéficier d'une partie des avantages de cette seconde approche sans perdre la flexibilité du rendu immédiat. C'est le Tile Caching qui peut être vu comme un "rendu avec rastérisation retardée". Une fois un triangle traité, au lieu de l'envoyer vers le moteur de rastérisation, Nvidia le conserve en cache interne, ainsi que tous ses paramètres. Quand ce cache est rempli, la rastérisation peut débuter. Grossièrement, il s'agit d'interrompre le rendu et d'attendre d'avoir un plus d'informations (mais pas toutes) avant de le poursuivre plus efficacement.
Une petite unité fixe supplémentaire, appelée binner, se charge de suivre la position et la couverture de chaque triangle en cache. Quand le temps de leur rastérisation est arrivé, parmi ces quelques triangles, le GPU sait lesquels seront assurément et totalement masqués. L'inverse n'est par contre pas vrai puisque, contrairement au TBR/TBDR, tous les triangles n'ont pas été traités en amont, juste quelques-uns. Il s'agit d'une optimisation localisée et opportuniste plus que d'un changement de philosophie global pour ces GPU.
Cette approche permet de traiter la rastérisation par tile et non pas par triangle. Il y a un surcoût au niveau de la rastérisation (même si Nvidia profite probablement de son moteur de projection multiple pour le limiter) mais ces tiles peuvent rester en cache. Elles ne sont alors écrites en mémoire que quand que tous les triangles en cache et qui y sont visibles ont été traités. Contrairement au TBR/TBDR, ces tiles seront réécrites en mémoire plusieurs fois lorsque d'autres morceaux de géométrie qui les parcourent seront traités.
Nvidia nous précise qu'aucun cache spécifique n'a été implémenté et que c'est le cache L2 qui est exploité. C'est la raison pour laquelle il a fait un bond énorme en taille à partir des GPU Maxwell (1 voire 2 Mo par 128-bit de bus contre 256 Ko sur Kepler). Un système d'optimisation automatique à base d'heuristiques a été mis en place pour opter pour la taille la plus adaptée au niveau du buffer de triangle et des tiles, mais Nvidia peut configurer tout cela manuellement pour chaque jeu ou débrayer le Tile Caching s'il est contreproductif.
En se contentant de chercher des opportunités d'optimisation locales, par morceau de géométrie, Nvidia parvient à obtenir des gains sympathiques, certes inférieurs à ceux obtenus par une architecture purement TBR/TBDR, mais qui permettent de conserver plus de flexibilité et de performances dans un maximum de situations. C'est un des piliers de l'excellente efficacité des GPU Maxwell et Pascal. Cela fait également partie d'une stratégie réfléchie qui consiste à chercher à créer de la valeur au niveau de ses propres puces plutôt que via l'exploitation d'une mémoire plus onéreuse (bus 512-bit, HBM ).
GDC: Nvidia va proposer des GTX 1080 et 1060 OC
Nvidia va proposer à ses partenaires des versions OC de ses kits GPU et mémoire pour les GTX 1080 et GTX 1060 qu'ils conçoivent. Si les GPU seront identiques, ils seront associés à de la mémoire plus rapide.

La GeForce GTX 1080 8 Go OC profitera de la nouvelle GDDR5X 11 Gbps de Micron pour un gain de 10% au niveau de la bande passante mémoire. Du côté de la GeForce GTX 1060 6 Go OC, la mémoire GDDR5 passera de 8 Gbps à 9 Gbps. Aucune indication tarifaire ne nous a été donnée.
A voir bien entendu ce que feront les partenaires de ces nouvelles sous-déclinaisons et s'ils les réserveront à leurs versions OC les plus chères ou s'ils essayeront de les généraliser. Il sera également intéressant d'observer sur la marge d'overclocking, très élevée actuellement, progressera ou s'il s'agit uniquement de pouvoir proposer une certification à une fréquence légèrement supérieure.
GDC: Nvidia annonce la GeForce GTX 1080 Ti 11 Go (maj)
Mise à jour du 01/03 : ajout de quelques précisions sur les fréquences, prix et date de lancement.
Comme attendu, Nvidia a profité de la GDC pour dévoiler une nouvelle carte graphique haut de gamme : la GeForce GTX 1080 Ti. Au menu, les performances de la Titan X pour 500 de moins.

Attendue depuis quelques mois, la GeForce GTX 1080 Ti va enfin faire son apparition. Jen-Hsun Huang, le CEO de Nvidia, a profité d'un évènement organisé en marge de la GDC pour annoncer cette nouvelle carte graphique haut de gamme, très proche de la Titan X sur le plan des spécifications :
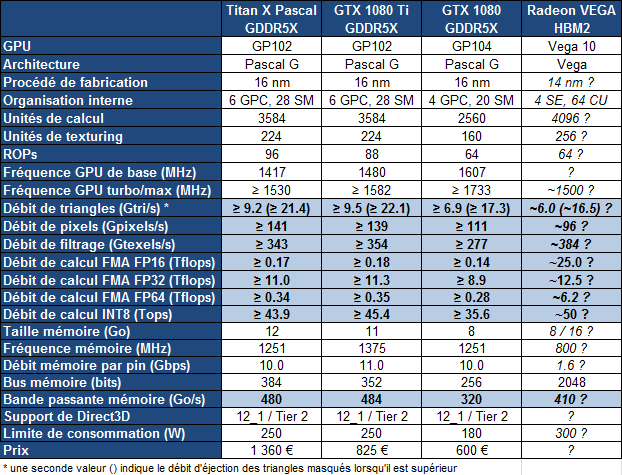
La GeForce GTX 1080 Ti reprend un GPU GP102 configuré de manière proche de celui de la Titan X, mais pas identique. Contrairement au nombre d'unités de calcul actives qui ne change pas (3584 sur 3840), l'interface mémoire a été bridée de 384-bit à 352-bit. C'est la raison pour laquelle la GTX 1080 Ti est équipée de 11 Go de mémoire GDDR5X et non de 12 Go.
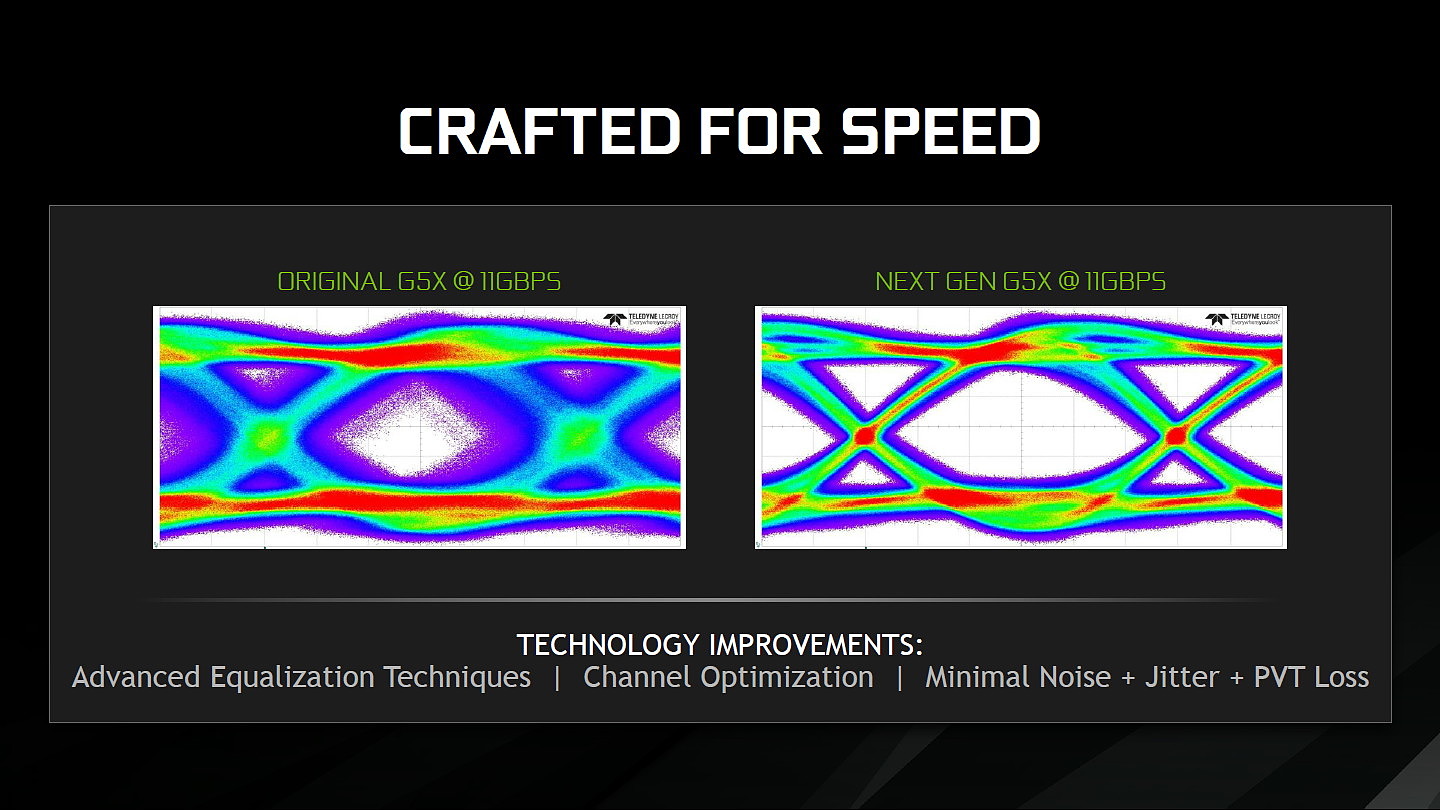
Nvidia semble d'ailleurs avoir misé particulièrement sur le chiffre 11 qui se retrouve au niveau de la puissance de calcul mais également au niveau du débit de la GDDR5X qui monte à 11 Gbps. Nvidia indique sur ce point profiter de la capacité de son interface mémoire à monter en fréquence avec une nouvelle révision de la GDDR5X de Micron qui permet un signal plus propre. La bande passante reste donc similaire à celle de la Titan X.

Comme pour les précédentes GeForce 10 haut de gamme, Nvidia va proposer un modèle Founders Edition qui reprend une esthétique similaire à celle de la GTX 1080 mais avec des connecteurs d'alimentation 8+6 pins pour s'adapter au TDP de 250W. Sous le capot, Nvidia indique avoir amélioré quelque peu l'efficacité du ventirad mais sans nous en dire plus. Nous pouvons supposer qu'une bonne partie des gains proviennent de la surface plus importante du GP102 par rapport au GP104.

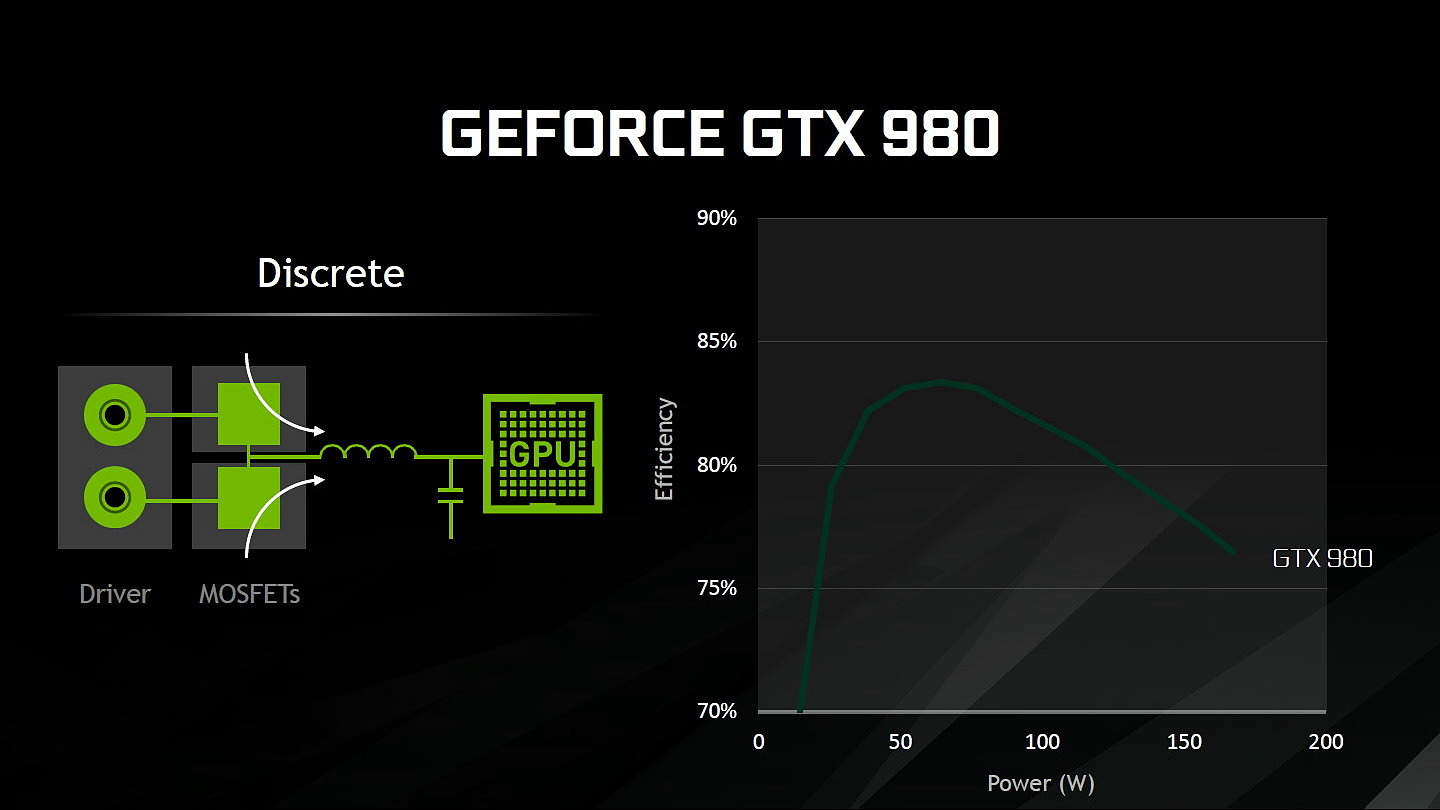
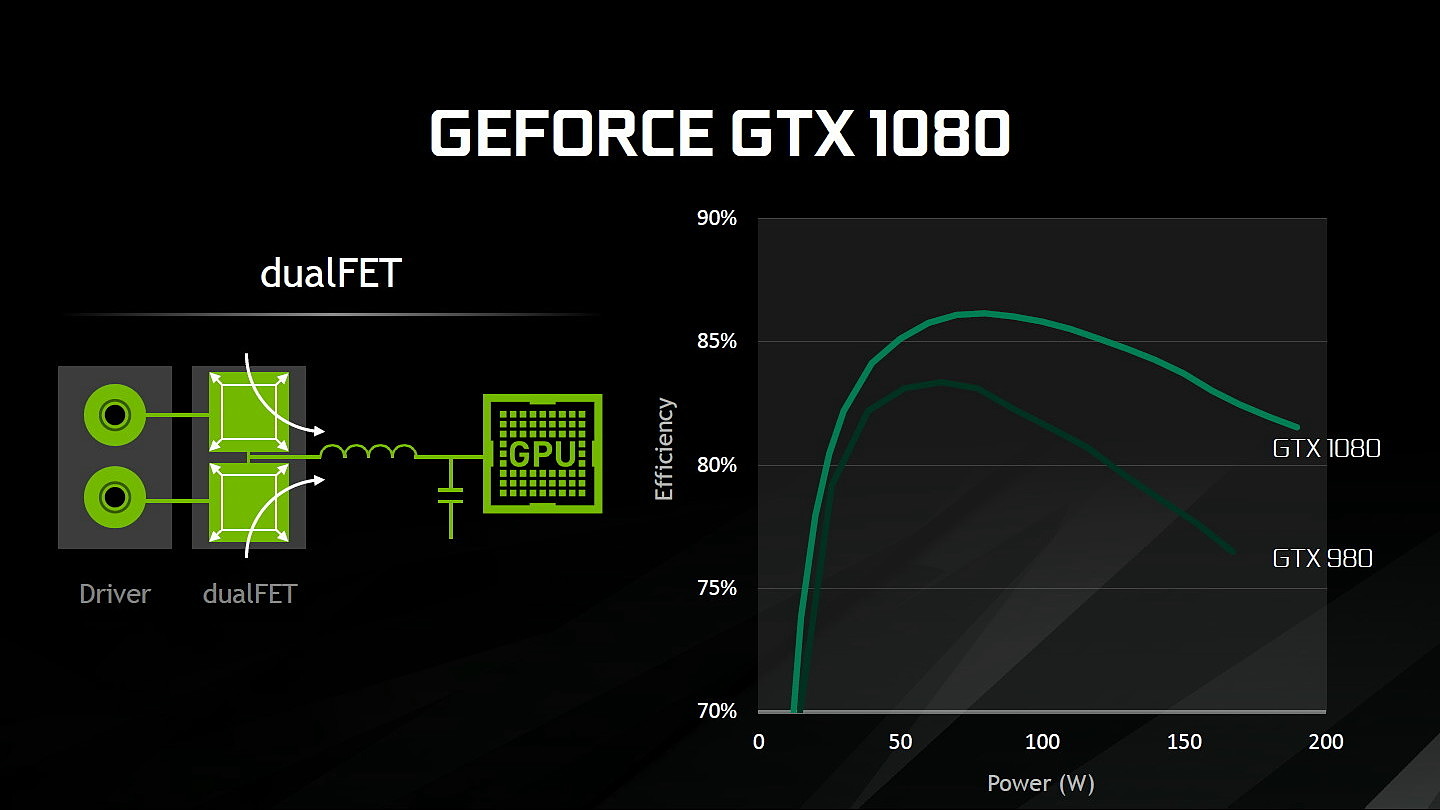
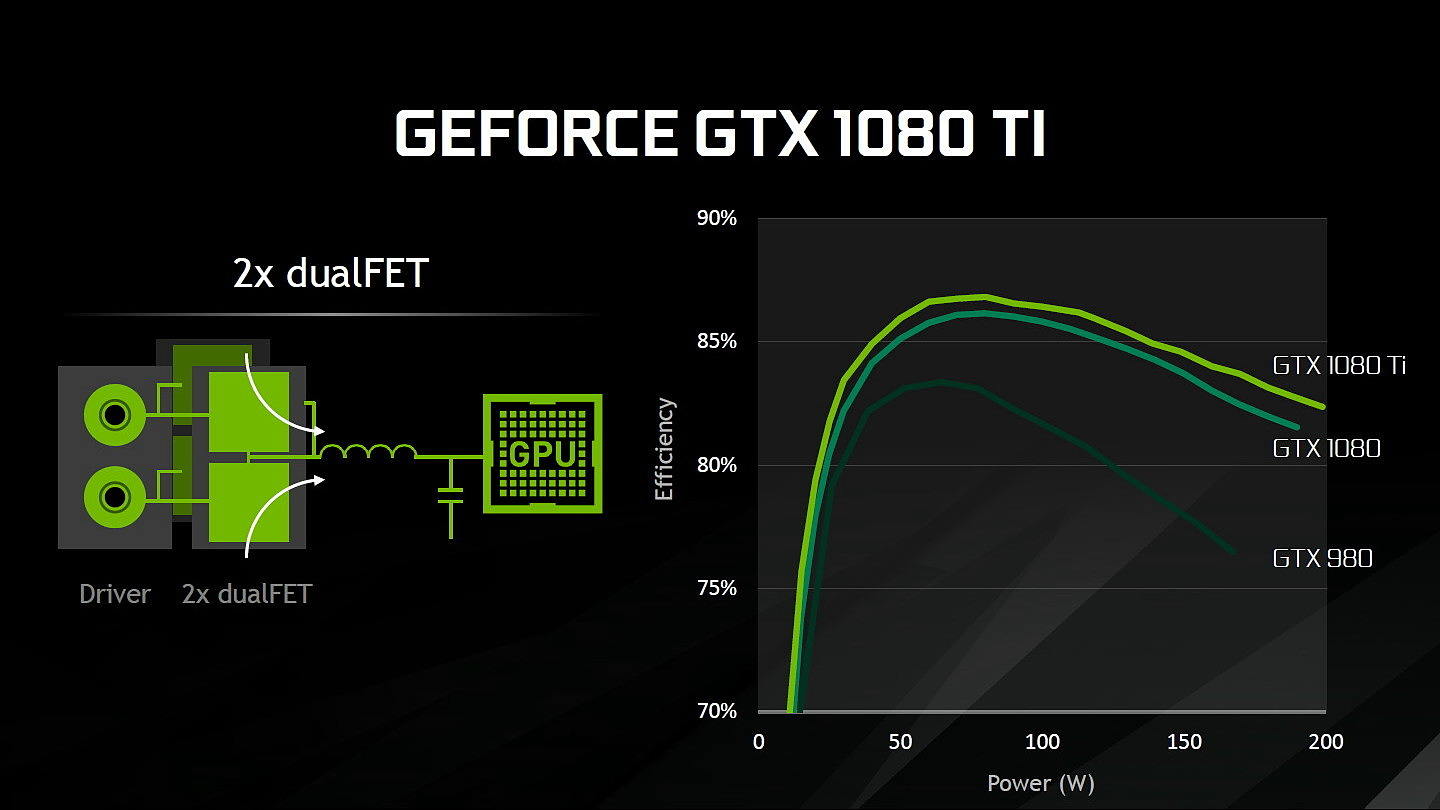
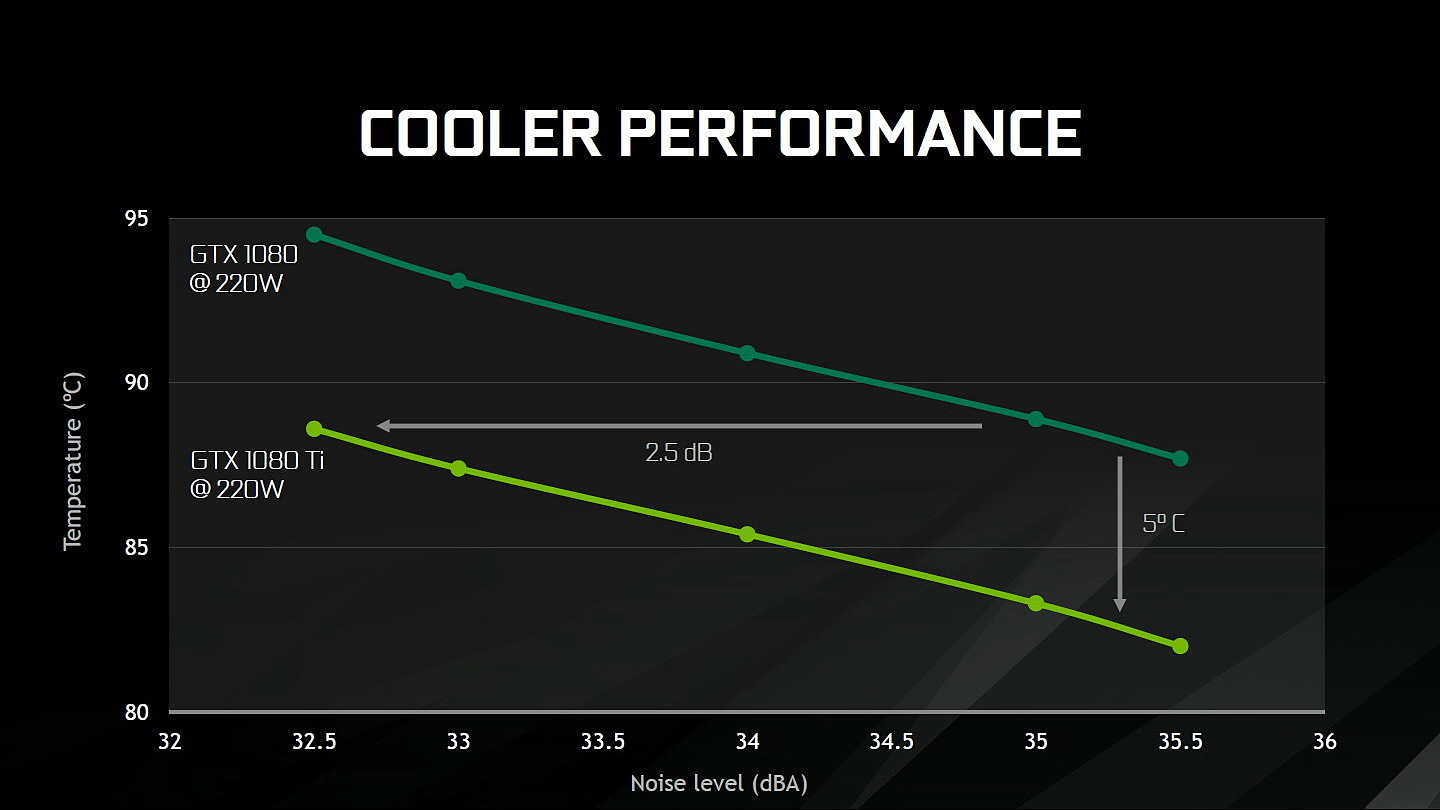

Au niveau du PCB, Nvidia explique avoir retravaillé l'étage d'alimentation. Equipé de 7 phases dédiées au GPU, il permet de délivrer jusqu'à 250A et pousserait le rendement encore un peu plus haut par rapport à la GTX 1080 grâce à un système à base de double DualFET.
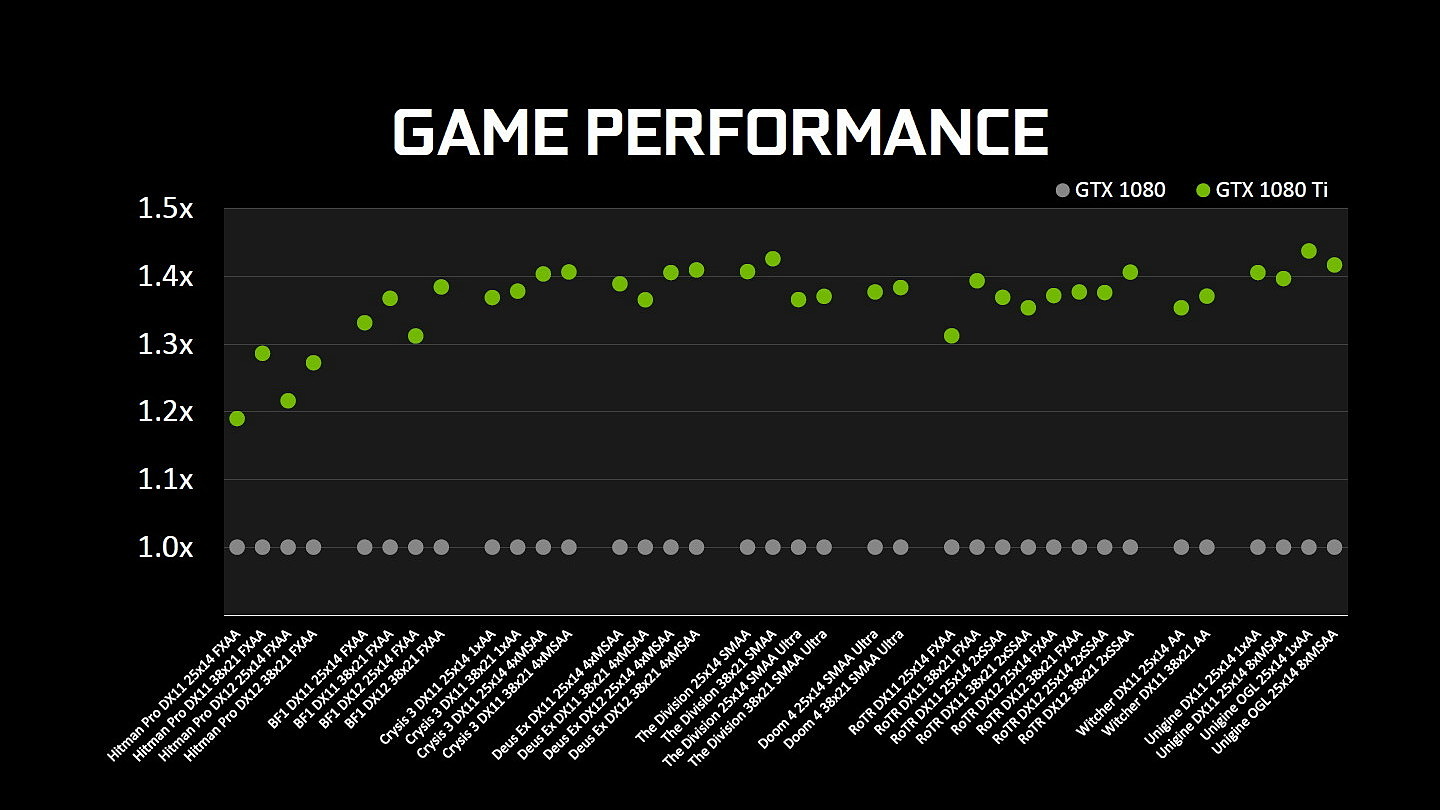
Sur le plan des performances, Nvidia parle d'un gain de 35% par rapport à la GTX 1080 mais nous supposons qu'il devrait en pratique se situer autour de 25% dans nos tests, comme pour la Titan X. Contrairement à cette dernière, les partenaires de Nvidia pourront proposer leurs propres designs qui devraient cette fois apporter assez facilement un gain de 35% sur la GTX 1080 FE.
La GeForce GTX 1080 Ti Founders Edition sera disponible au tarif de +/- 825 dès vendredi prochain alors que nous devrions vous en proposer un test la veille. Cette version FE sera la seule disponible au lancement et elle sera commercialisée en direct par Nvidia (les précommandes débutent demain) mais pas de manière exclusive comme c'est le cas pour la Titan X. Les versions personnalisées arriveront quelques semaines plus tard. Et bonne nouvelle, Nvidia en profite pour repositionner la GeForce GTX 1080 qui voit son tarif chuter d'une centaine d'euros.
La question qui ne trouve pas de réponse aujourd'hui concerne évidemment la comparaison avec la future Radeon Vega d'AMD. Sera-t-elle capable de lutter avec la GeForce GTX 1080 Ti ou devra-t-elle se contenter de la GTX 1080 ? Ce lancement début mars, nous laisse par contre penser que Nvidia estime que sa nouvelle solution conservera la première place.
Enfin notons que la Titan X actuelle perd tout intérêt et qu'il semble évident qu'elle sera remplacée sous peu par un modèle plus musclé. A base de GP102 complet ? Ou de GP100 ?
GDC: Wave programming pour booster les perfs
Comme chaque année, la journée d'ouverture de la GDC est l'occasion pour AMD et Nvidia de s'associer pour parler des nouvelles API et aider les développeurs à mieux les exploiter. Premier sujet du jour : le wave programming qui sera introduit prochainement sous DirectX 12 et Vulkan pour permettre de nouvelles optimisations des performances.

Les nouvelles API telles que Direct3D 12 ou DirectX 12 et Vulkan permettent d'optimiser les performances à différents niveaux. Elles ont été introduites avec des promesses au niveau d'une baisse drastique du surcoût CPU lié au rendu 3D mais également avec des opportunités de gains de performances côté GPU via l'exécution concomitante de certaines tâches ("async compute"). Une nouvelle possibilité d'optimisation au niveau du GPU va bientôt être standardisée : le wave programming.
Qu'est-ce que c'est ? Fondamentalement il s'agit d'exposer le comportement vectoriel des GPU de manière à permettre aux développeurs de mettre en place des optimisations spécifiques. Jusqu'ici, pour ce qui concerne le rendu 3D, les API font une abstraction totale du modèle d'exécution vectoriel des GPU. Un vertex représente un thread, un pixel représente un autre thread et les GPU exécutent cette masse de threads comme ils l'entendent.

Comme vous le savez probablement, les unités de calcul des GPU sont en réalité de larges unités vectorielles ou SIMD qui travaillent par ailleurs sur plusieurs cycles. Du côté des GeForce ce sont des vecteurs de 32 threads (warp) qui sont pris en charge par les unités d'exécution. Du côté des Radeon les GPU GCN travaillent avec des vecteurs de 64 threads (wavefront). Idéalement tous les threads d'un warp/wavefront vont suivre un même chemin prédéfini. Mais ce n'est pas toujours le cas, il peut y avoir des divergences dans les accès mémoires et les shaders.
Exposer ce fonctionnement aux développeurs apporte de nouvelles possibilités d'optimisations au niveau du contrôle des branches, des accès mémoire ou du partage de données entre threads. Cela fait partie des optimisations qui sont accessibles pour le GPU computing et qui sont exploitées par les développeurs sur console. C'est également ce qu'AMD a commencé à mettre en place via des extensions propriétaires et autres backdoors propriétaires pour DirectX 12. AMD y faisait référence jusqu'ici en tant que fonctions intrinsèques.

Pour donner un exemple du wave programming, c'est en grande partie ce qui permet aux Radeon d'obtenir leurs très bonnes performances dans Doom. Sur le GPU GCN de la PS4, le gain est de 43% au niveau de la passe de rendu principale et une technique similaire a pu être portée sur PC. C'est également ce à quoi Nvidia fait appel pour booster les performances de certaines de ses librairies dont Optix.
Un support standardisé au niveau des shaders est en préparation pour Vulkan mais également pour DirectX 12. Microsoft travaille depuis l'an passé sur une mise à jour de son API qui va apporter les Shader Model 6. Ces SM6 seront spécifiques à Direct3D 12 mais seront compatibles avec les GPU déjà existants. Nvidia parle d'un support pour tous ses GPU depuis Kepler et AMD depuis GCN 3.
Le wave programming ne sera cependant pas simple à exploiter de manière optimale, notamment parce que les développeurs devront prévoir directement dans les fonctions de leurs shaders au moins deux cas de figure vu les différences majeures d'architectures entre AMD et Nvidia.
Pas mal d'expérimentations et de tests seront ainsi nécessaires pour s'assurer que ces optimisations apportent réellement un bénéfice sur tous les GPU. Une optimisation de ce type pour GPU AMD sera contreproductive sur GPU Nvidia ou encore pourra poser problème sur un GPU qui serait équipé de moins de registres physiques. Par contre les meilleurs développeurs pourront pousser très loin l'optimisation des shaders et c'est évidemment une bonne nouvelle pour le jeu PC.
Vous pourrez retrouver l'intégralité de la présentation commune d'AMD et Nvidia ci-dessous :
























