
Les contenus liés aux tags Intel et AMD
Afficher sous forme de : Titre | FluxDossier: Les solutions de streaming : Streaming local Steam et Nvidia GameStream en test
Ventes iGPU / GPU : marché en berne, AMD recule
Dossier: Celeron N3150 et Pentium N3700 : Braswell en test
GPU, 71% pour Intel et 76% pour Nvidia
Focus: Perfs avec 2, 4, 6 et 8 curs : 4 jeux à la loupe
Polaris 11 en version mobile chez AMD



Sans trop de surprises, le lancement des MacBook Pro hier par Apple s'est accompagné, côté GPU, de puces AMD. Le constructeur a mis pour l'occasion en ligne un site mettant en avant ses nouvelles références .
Si l'on trouve des Polaris 10 mobiles sur le site d'AMD avec des références comme les R9 M485X, les MacBook Pro ont droit à leur propre nomenclature, on parlera de Radeon... Pro . Cela permet aussi d'enlever le M, quelque chose qui fait écho à ce que l'on a vu chez Nvidia il y a quelques semaines.
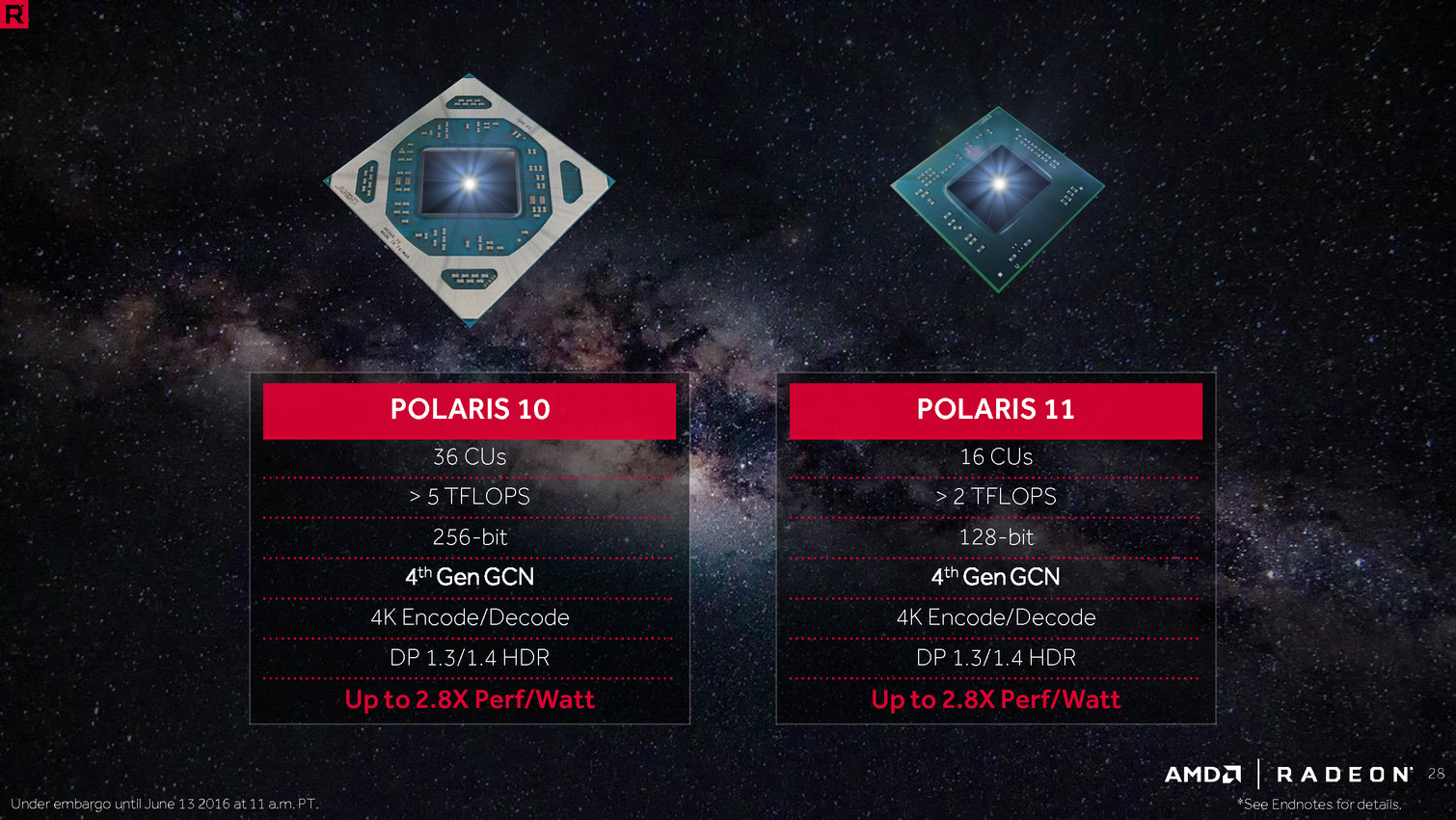
Techniquement, il s'agit de puces Polaris 11, qui sont aussi utilisées côté desktop dans les Radeon RX 460. Il s'agit du "petit" Polaris qui propose 16 CU et un bus mémoire 128 bits. Vous pouvez retrouver plus de détails sur l'architecture des Polaris dans cet article.
Trois références sont annoncées, les Radeon Pro 460, 455 et 450. Nous avons récapitulé leurs caractéristiques sur le tableau ci dessous :
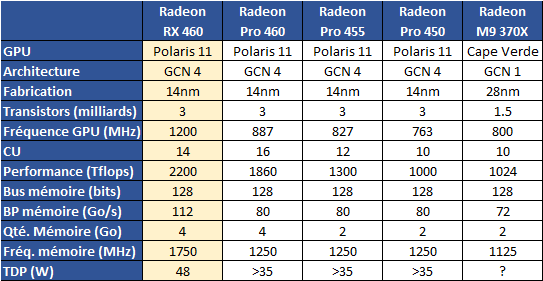
Nous avons ajouté dans la première colonne les caractéristiques de la RX 460, la configuration desktop de Polaris 11 afin d'avoir un point de comparaison, ainsi que le M9 370X qui équipait la génération précédente de MacBook Pro. L'arrivée du 14nm fait que l'on a droit a un choc générationnel. Par rapport à la configuration desktop, AMD réduit la fréquence, et exploite tout les CU du die Polaris 11 pour offrir environ 84% du niveau de performance théorique. La bande passante mémoire est inférieure de 10.4%.

Il est intéressant également de faire un petit aparté sur les CPU utilisés par Apple dans ces MacBook Pro, on retrouvera ces références (dans les configurations de base) :
- Core i5 6360U (2C/4T, 2.0/3.1 GHz, 15W, Iris Graphics 540 avec 64 Mo d'eDRAM)
- Core i5-6267U (2C/4T, 2.9/3.3 GHz, 28W, Iris Graphics 550 avec 64 Mo d'eDRAM)
- Core i7-6700HQ (4C/8T, 2.6/3.5 GHz, 45W, Iris Graphics 530 sans eDRAM)
- Core i7-6820HQ (4C/8T, 2.7/3.6 GHz, 45W, Iris Graphics 530 sans eDRAM)
La gamme d'Intel est compliquée, et celle d'Apple a peine moins puisque le constructeur propose un CPU 15 watts dans son modèle d'entrée de gamme 13 pouces (le modèle sans "touch bar" avec ironiquement une batterie encore plus grosse !). L'autre 13 pouces (avec "touch bar") utilise l'autre Core i5 28 Watts. Dans les deux cas il n'y a pas de GPU AMD sur ces configurations, et Apple utilise les GPU Intel avec 64 Mo d'eDRAM (GT3e). La marque annonce la même autonomie pour les deux modèles, ce qui est assez risible !
Le point qui nous intéresse le plus concerne la situation GPU sur les modèles 15 pouces. Contrairement à la gamme précédente de MacBook ou Intel était présent sur toutes les configs côté GPU (le M370X n'était disponible qu'en option sur une référence), ce n'est plus le cas ici. Les Core i7 utilisés sont dépourvus d'eDRAM et on retrouve systématiquement un GPU AMD.
Intel semble en effet avoir eu des problèmes de fabrication avec ses modèles GT4e, équipés de 128 Mo d'eDRAM. Le constructeur ne communique pas vraiment dessus mais les Skylake GT4e sont pratiquement absents des gammes mobiles des constructeurs (en cherchant, on en retrouve un dans un... NUC Intel !).
Difficile d'en connaître la raison exacte, mais le constructeur a qui plus est jeté l'éponge sur le GT4e pour la prochaine génération, Kaby Lake, comme nous vous l'indiquions un peu plus tôt. Cela reste un coup dur pour le constructeur dont la stratégie GPU reposait en grande partie sur l'apport proposé par cet eDRAM pour les hautes performances. Si l'eDRAM spécifiquement est en cause, il sera intéressant de voir quelle alternative le constructeur choisira pour la remplacer.
Ou si, plus simplement, il se contentera d'être de nouveau absent du marché du GPU mobile milieu/haut de gamme.
10/7nm en avance pour TSMC, EUV pour le 5nm
TSMC vient de publier ses résultats financiers pour le troisième trimestre. Le fondeur taiwannais enregistre une hausse séquentielle de 17% (+22% par rapport à la même période sur 2015), au dessus de ses prévisions. Des bons chiffres qui s'expliquent selon TSMC par une forte demande sur le marché des smartphones.

Ramenés par process, le 16/20nm représente 31% des revenus de la société (contre 23% le trimestre précédent). Le 28nm voit sa part baisser à 24% des revenus, mais TSMC confirme que ses usines restent "pleinement utilisées".
En ce qui concerne les prochains nodes, TSMC a confirmé les informations publiées un peu plus tôt, à savoir l'avance prise par les process 10 et 7nm.
Le 10nm entre en production ce trimestre et les premiers produits finaux seront livrés au premier trimestre 2017. Ce node ne sera pour rappel utilisé que par les très gros clients de TSMC, à savoir Apple et possiblement Qualcomm. Les autres clients attendront le 7nm. La montée des yields est décrite comme "similaire" à celle du 16nm même si "techniquement plus difficile".
Le 7nm entrera en production "risque" au premier trimestre 2017 et TSMC s'empresse d'indiquer qu'il sera utilisé non seulement pour les smartphones, mais aussi pour des GPU, des puces serveurs, et des "PC et tablettes". TSMC décrit des tapeout aggressifs qui commenceront au début du second trimestre. 15 produits devraient être qualifiés en 2017.

La fondeur a également évoqué le 5nm, qui a quitté le stade de la recherche pure pour entrer dans une phase de développement. Et TSMC confirme qu'ils utiliseront de manière "extensive" la lithographie EUV. Cette dernière aurait fait des progrès sur tous les plans, que ce soit en fiabilité, ou sur les problèmes techniques complexes (masques, photo resist, etc). La production "risque" reste prévue pour la première moitié de 2019 (la production volume suit en général de 3 à 4 trimestres).
Lors de la présentation des résultats aux analystes financiers, le CEO de TSMC, Mark Liu, a réitéré une fois de plus voir "l'informatique haute performance" comme un marché sur lequel TSMC espère voir une progression de ses ventes. Les serveurs et les PC clients sont mis en avant, et on a du mal a ne pas y voir un lien avec les annonces d'AMD sur sa renégociation du contrat WSA qui les lie à GlobalFoundries.
Dans la séance de questions/réponses posées, on notera qu'a la question de savoir si la prise de licence ARM par Intel est un risque, Mark Liu estime surtout que cela renforce le rôle d'ARM, tout en ne négligeant pas le rôle qu'Intel pourrait jouer. Reste que sur ce trimestre, la part de marché de TSMC chez les fondeurs (hors activité propre comme Intel pour ses propres puces donc) était de 55%.
Hot Chips : M1, SVE, Parker, InFo et Skylake !
La conférence Hot Chips qui se tenait la semaine dernière a donné lieu a d'autres annonces intéressantes que nous avons essayé de regrouper dans cette actualité !
Rajouter des tiers de mémoire côté serveur
On avait déjà noté un peu plus tôt la volonté de rajouter de la mémoire HBM à divers endroits, et même la volonté de Samsung de travailler sur une version moins onéreuse, mais l'on rajoutera ce slide issu d'une présentation d'AMD qui rappelle les objectifs de la société côté serveurs, prenant pour le coup l'exemple du big data
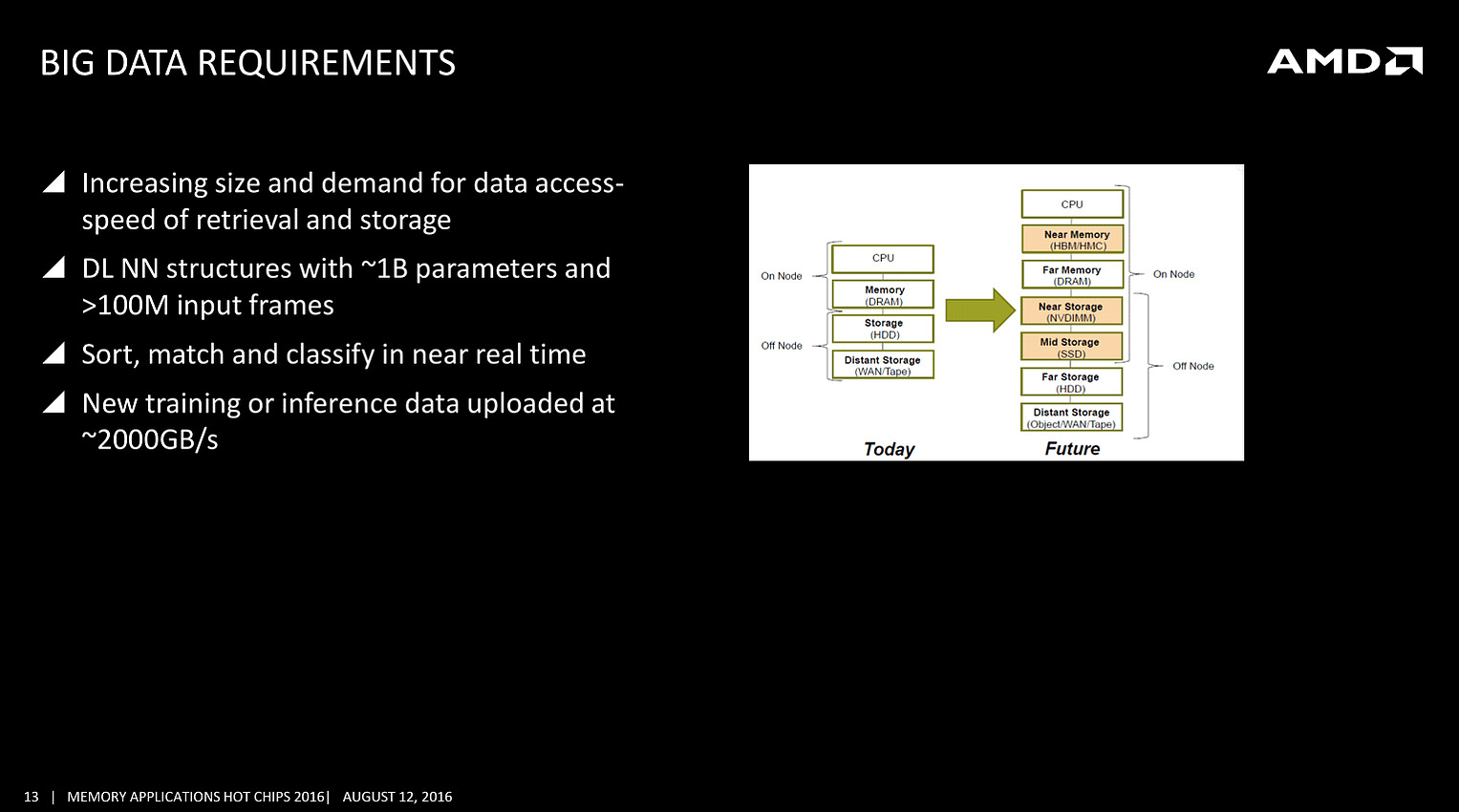
On s'attardera sur le graphique à droite qui pointe l'ajout d'une mémoire intermédiaire côté CPU, type HBM ou HMC (AMD misera plutôt sur la HBM pour les déclinaisons serveurs de Zen), et aussi l'utilisation de NVDIMM pour s'intercaler avant un SSD. Il faudra attendre encore un peu pour voir comment seront déclinées ces technologies, mais il est intéressant de noter la manière dont les avancées côté mémoire sont mises en avant, parfois un peu trop tôt comme l'a fait Intel avec 3D XPoint, dans toute l'industrie.
Quelques détails de plus sur SVE
Chez ARM, outre une présentation de Bifrost côté GPU dont on vous avait déjà parlé, l'annonce principale concernait SVE, la nouvelle extension vectorielle introduite par la société.
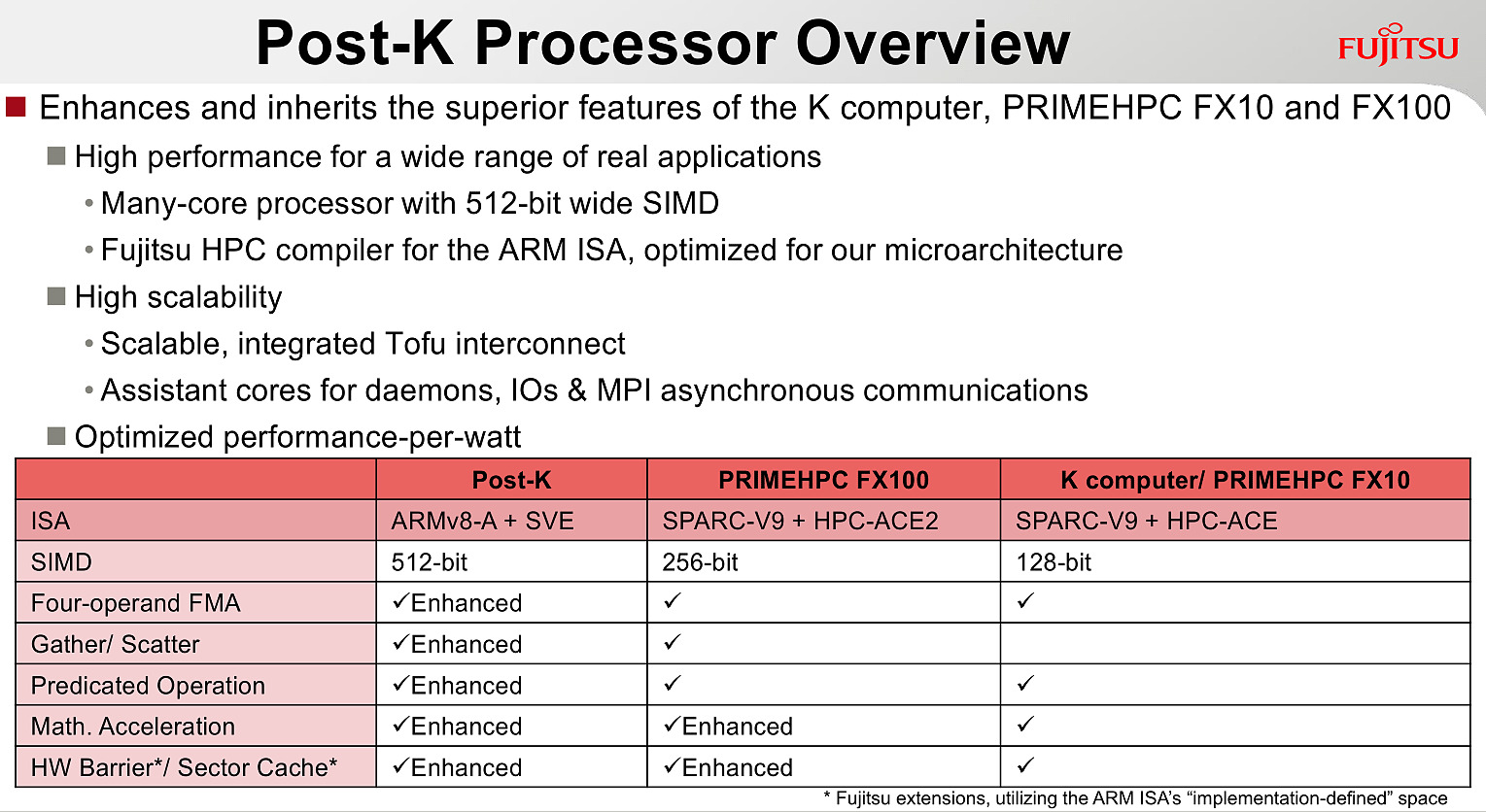
Le premier partenaire annoncé par ARM est Fujitsu, qui mettra au point des processeurs ARMv8 avec extension SVE pour le futur supercalculateur japonais Post-K. Fujitsu a donné quelques détails, indiquant par exemple que les unités vectorielles auraient une largeur de 512 bits sur ses puces.


Chez ARM, le constructeur présente plusieurs benchmarks assez théoriques, on notera surtout sur les barres grises les améliorations qui ont été effectuées côté auto-vectorisation, c'est a dire la capacité du compilateur à utiliser des instructions vectorielles pour extraire du parallélisme. ARM devrait proposer dans les semaines qui viennent des patchs pour les différents compilateurs open source, incluant LLVM et GCC.
Le Samsung M1, un timide premier pas
La particularité de l'écosystème d'ARM est que les partenaires peuvent soit utiliser des coeurs "clefs en main", développés par ARM (les gammes Cortex, comme par exemple le Cortex A57), ou créer leurs propres implémentations de l'architecture ARM (qui restent compatibles, tout en étant différentes, à l'image des processeurs d'AMD et d'Intel qui diffèrent bien que restant compatibles). Plusieurs sociétés disposent de licences "architecture" qui permettent de créer ces puces, Apple étant jusqu'ici la société la plus à la pointe sur armv8 même si de nombreuses sociétés proposent tour à tour leurs architectures.

Parmi les nouveaux venus, il y a Samsung qui s'est lancé lui aussi dans le design d'une architecture armv8 custom pour ses Exynos M1. A la tête du projet, on retrouve Brad Burgess qui était architecte chez AMD pour les Bobcat. Il aura même été rejoint un court instant par Jim Keller (K8 chez AMD, A7 chez Apple, puis Zen chez AMD), qui n'est cependant pas resté très longtemps chez Samsung et qui n'aura probablement pas eu un grand impact. Le projet aura nécessité trois années, et en soit arriver a produire quoique ce soit du premier coup en un temps si court est un exploit.
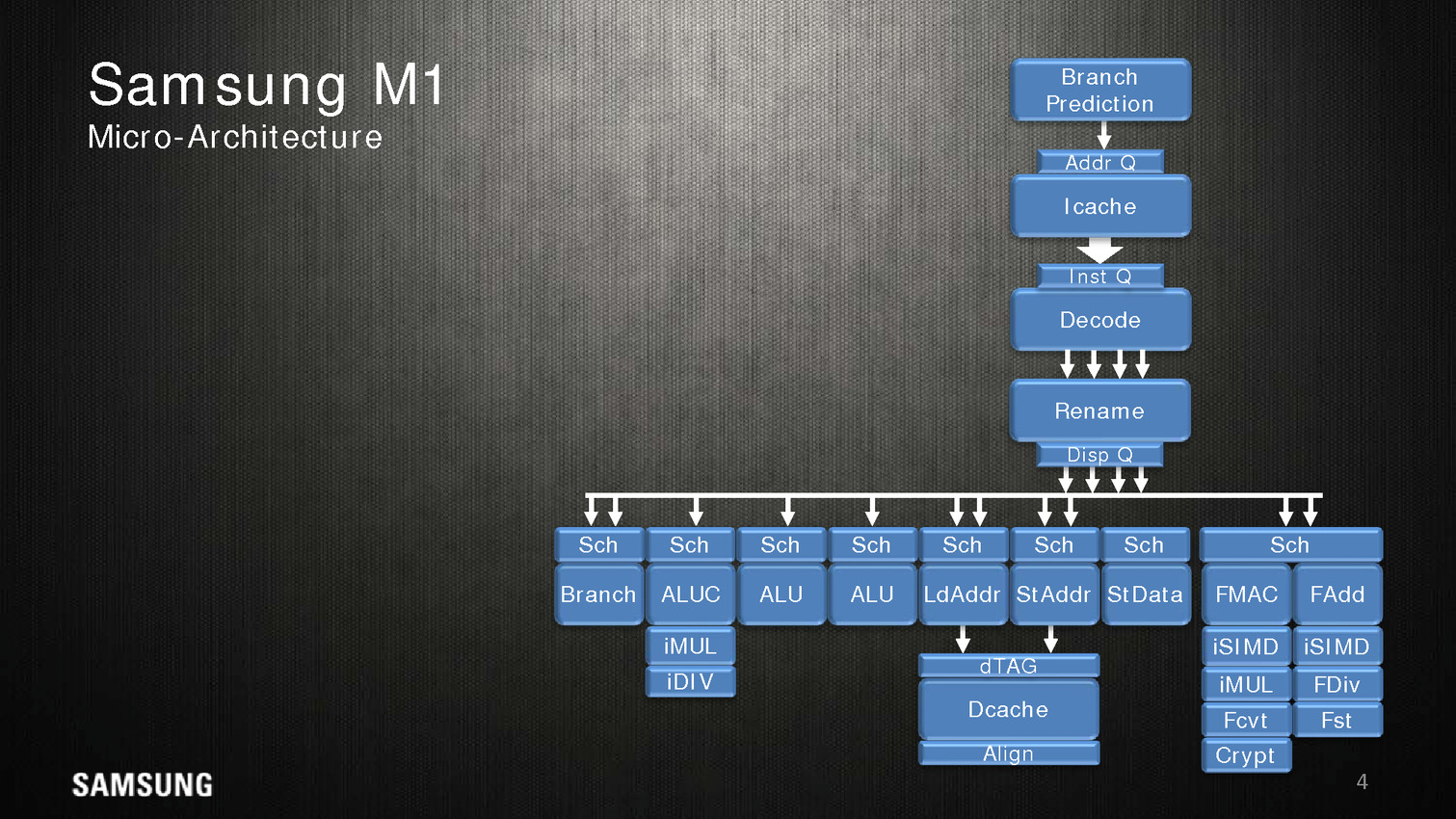
Côté architecture, Samsung indique utiliser un perceptron (un réseau de neurones simple) au niveau de ses mécanismes de prédiction de branches. Deux branches sont considérées par cycle, mais il est difficile d'estimer quoique ce soit sur l'éventuelle efficacité.
Quatre instructions peuvent être décodées/dispatchées par cycle aux unités d'exécutions qui sont regroupées sur sept files. On note deux files dédiées aux écritures mémoires, trois aux opérations mathématiques simple (avec un port sur lequel sont ajoutés les multiplications/divisions) et une aux branchements. Les opérations en virgules flottantes sont regroupées séparément avec un scheduler unique pour deux files. Samsung annonce 5 cycles pour effectuer une opération FMA.
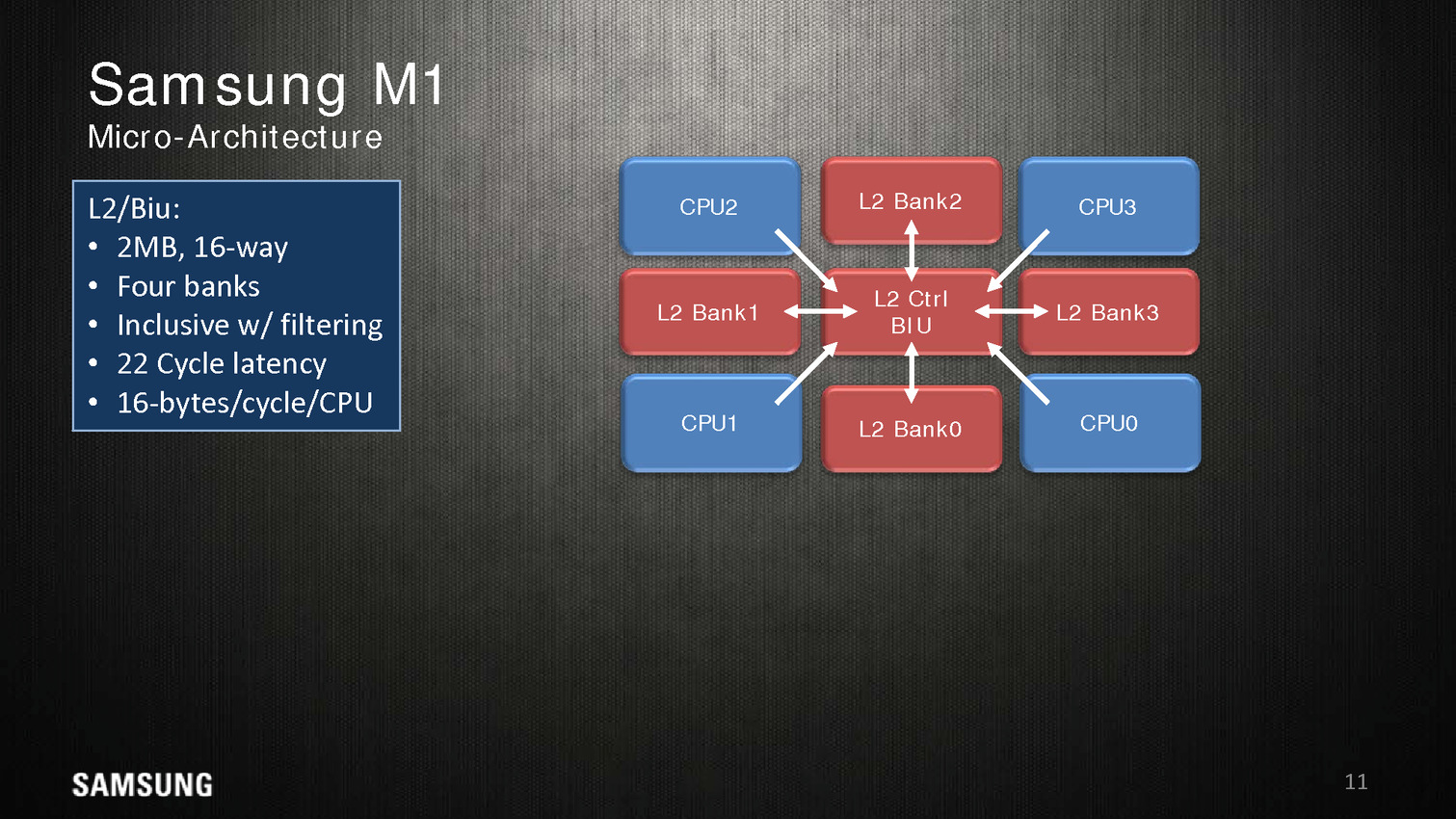
Dans une configuration quatre coeurs, le M1 dispose de 2 Mo de cache L2 coupé en quatre blocs, les coeurs accèdent au L2 via une interface commune. On appréciera aussi les schémas très spécifiques que propose Samsung, pas vraiment avare de détails techniques.

Reste qu'en pratique, les benchmarks mis en avant par Samsung ne sont pas forcément très convaincants. Avec 200 MHz de plus, sur un coeur, un M1 propose 10% de performances en plus qu'un Cortex A57 à consommation égale, ce qui est tout de même très peu. Samsung fait beaucoup mieux sur les opérations mémoires (c'est relativement facile, on l'a évoqué de nombreuses fois, les contrôleurs mémoires ARM ne sont pas particulièrement véloces/adaptés aux hautes performances), mais n'en tire pas particulièrement profit hors des benchmarks théoriques.
La présentation se termine en indiquant que ce n'est qu'un premier pas pour Samsung et que d'autres designs sont en cours d'élaboration. En soit si les performances ne vont pas révolutionner le monde des SoC ARM, Samsung a au moins une base de travail qu'ils pourront faire évoluer par la suite. A condition évidemment que Samsung continue d'investir sur le sujet dans les années à venir !
Les curieux pourront retrouver la présentation en intégralité ci dessous :














Parker/Denver 2 : design asymétrique
Nvidia était également présent à Hot Chips, donnant quelques détails sur son futur SoC baptisé Parker. Ce dernier est annoncé comme crée spécifiquement pour le marché automobile avec des fonctionnalités dédiées à ce marché. On ne sait pas si le constructeur le déclinera en d'autres versions plus génériques.

Les détails techniques ne sont pas particulièrement nombreux, on notera côté SoC que l'encodage 4K est désormais accéléré à 60 FPS, que l'on peut contrôler jusque trois écrans en simultanée, et que le contrôleur mémoire passe sur 128 bits (contre 64 précédemment). Côté GPU, Parker utilisera une version dérivée de son architecture Pascal.



C'est du côté CPU que les choses sont les plus originales, après avoir utilisé son architecture Denver sur les TK1, puis être revenu aux Cortex A57 sur les TX1, Nvidia propose une architecture asymétrique avec deux coeurs "Denver 2" (sur lesquels aucun détail n'aura été donné, à part un gain performance/watts de 30% donné sans précision sur les process comparés) et quatre coeurs Cortex A57. Ce n'est pas la première fois que l'on voit des configurations originales, durant Hot Chips, le taiwannais MediaTek présentait un SoC 10 coeurs avec quatre coeurs Cortex A53 à 1.4 GHz, quatre coeurs Cortex A53 à 2 GHz, et deux coeurs Cortex A72 à 2.5 GHz !
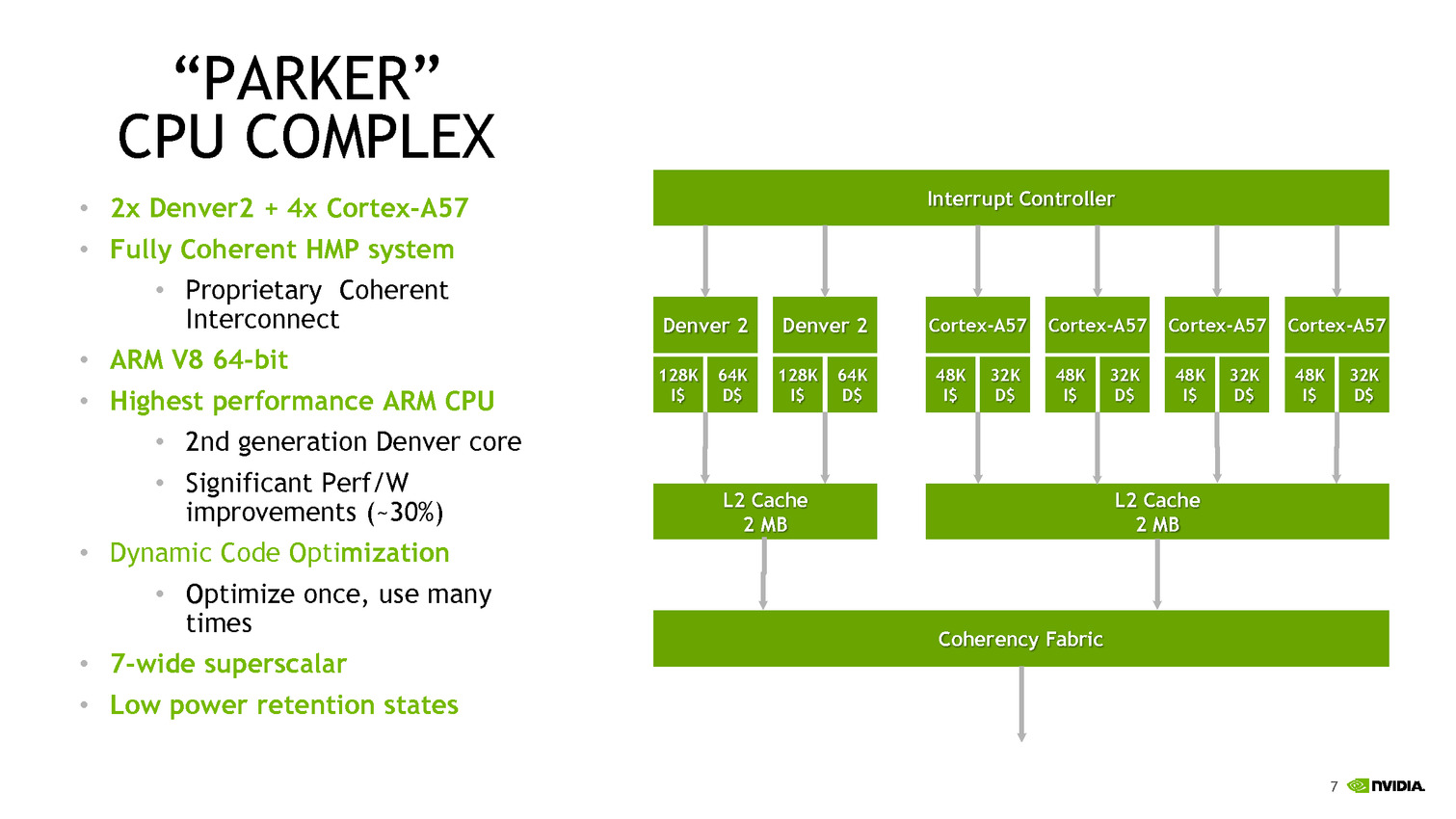
Dans le cas de MediaTek, l'idée est de proposer différentes options à différents niveaux de consommation. Pour ce qui est de Nvidia, le choix est différent, le Cortex A57 étant "haute performance" contrairement aux A53 de MediaTek. Il faut dire surtout que le marché visé, l'automobile, n'a pas les mêmes contraintes de consommation que le marché mobile. Reste que Nvidia se doit de gérer cette asymétrie avec un scheduler qui doit décider sur quel coeur placer les threads, ce qui n'est pas particulièrement simple. On notera que chaque groupe de coeurs dispose de son propre cache L2 de 2 Mo.
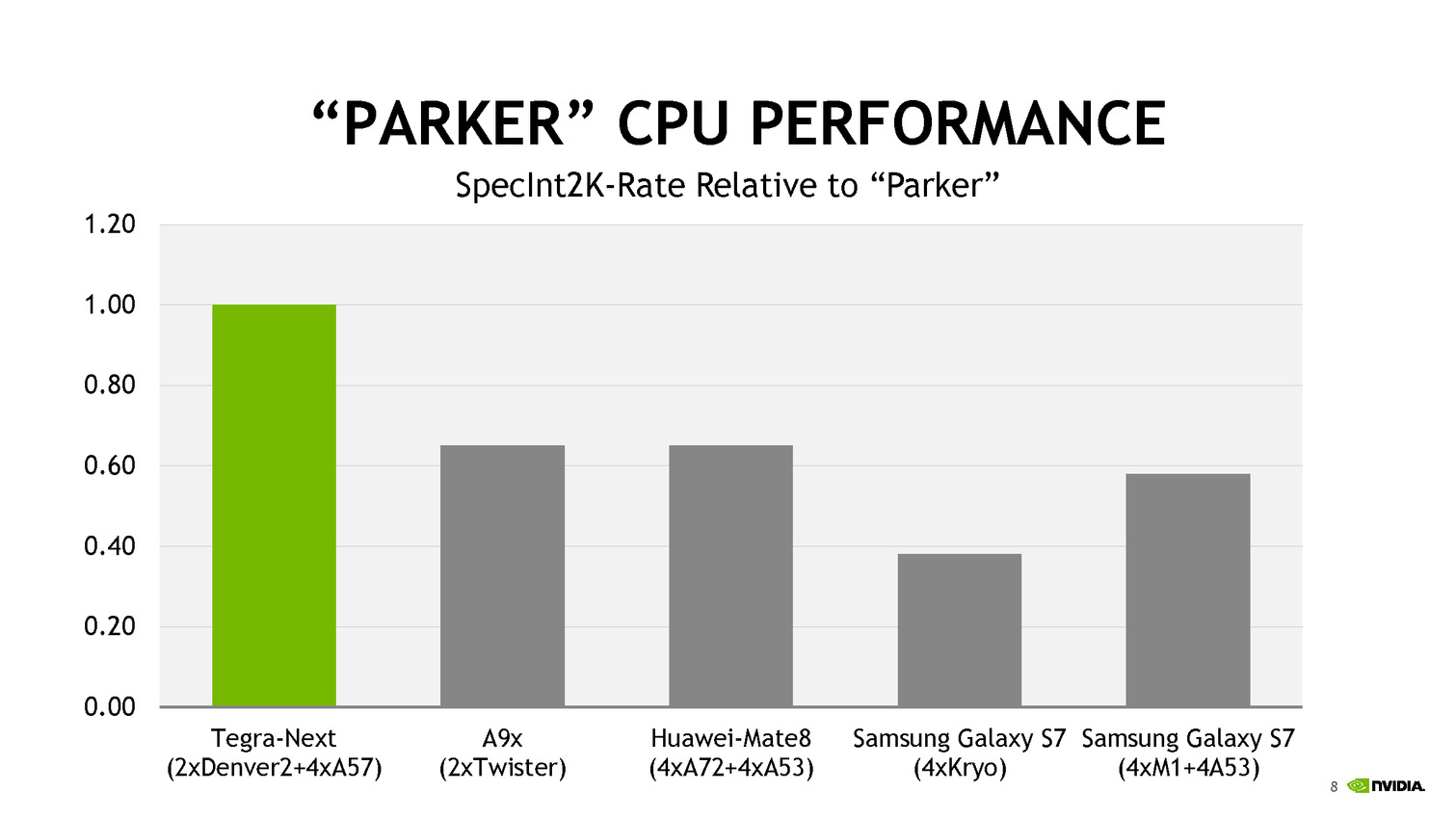
Côté performances, Nvidia avec ses 6 coeurs se présente comme moitié plus rapide qu'un A9X d'Apple en deux coeurs. Le graphique mélangeant des puces à TDP différents (on y retrouve des puces pour smartphones et pour tablettes), on admettra que la comparaison n'est pas faite à TDP identique.
TSMC parle de ses packages InFo
Une des nouveautés présentées cette année par TSMC est la disponibilité d'un nouveau type de packaging, l'InFo-WLP. L'idée est de permettre de relier plusieurs dies en les "moulant" dans un substrat commun très fin qui contient également les interconnexions entre les puces. Il s'agit d'une version à cout beaucoup plus faible que les interposer (utilisés par exemple par AMD pour Fiji).
La présentation de TSMC est dédiée aux interconnexions entre les puces, et présente une puce 16nm reliant un SOC à une puce mémoire avec une bande passante de 89.6 Go/s sur 256 bits, le tout avec une consommation très réduite.
En plus de la solution présentée qui évoque le cas simple d'une puce mémoire et d'un Soc, TSMC évoque la solution comme permettant un jour de relier également plusieurs dies de logique, par exemple des groupes de coeurs séparés, pour réduire le coût de fabrication des puces (qui augmentent exponentiellement avec la taille des dies).
































La présentation est technique mais reste intéressante, l'InFo-WLP ouvre des opportunités supplémentaires pour réaliser des produits qui mélangent processeur et mémoire. Le coût réduit et la finesse de l'interconnexion fait qu'on pourrait retrouver assez rapidement cette technique utilisée, y compris sur le marché mobile. Les prochains SoC d'Apple pourraient par exemple utiliser un tel package.
Et Skylake !
Juste avant la présentation de Zen, Intel proposait aussi une présentation de son architecture Skylake, lancée l'année dernière. Si la majorité du contenu est déjà connu, on aura noté un détail intéressant : un diagramme sur les unités d'exécution de Skylake. On rappellera que l'année dernière durant l'IDF, Intel nous avait promis plus de détails sur le sujet, sans jamais nous les donner !
Pour rappel, voici la répartition sur Haswell :
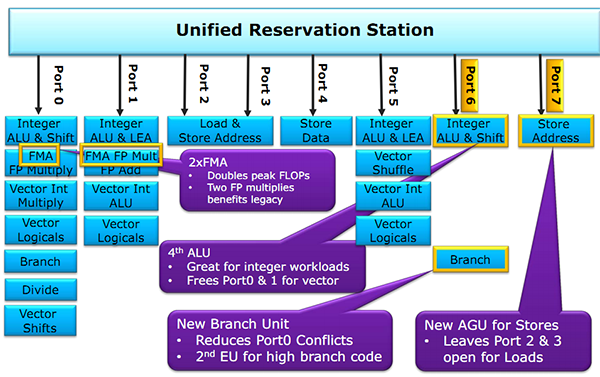
Récapitulatif des ports/unités d'exécution sur Haswell
Un an après, voici enfin un diagramme similaire pour Skylake :
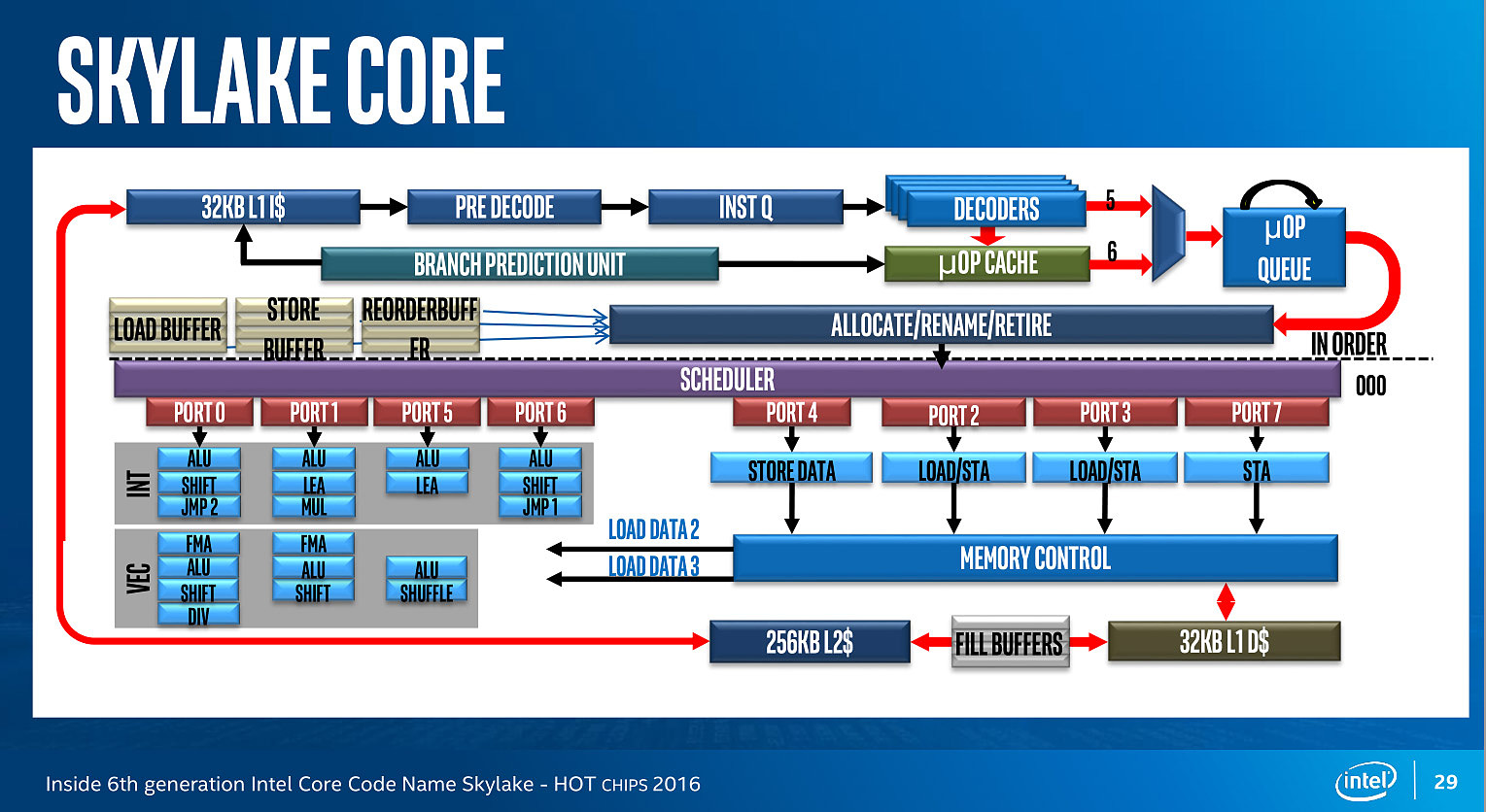
Conformément à ce que nous avaient indiqué les ingénieurs d'Intel l'année dernière, le nombre d'unité a bel et bien augmenté. Le nombre de ports reste constant, à 8, mais l'on compte... une nouvelle unité. Sur le port 1, Intel a en effet ajouté une unité de shift vectorielle. Pour le reste, la répartition reste similaire à celle d'Haswell. Un mystère enfin élucidé !
AMD continue de gagner des parts de marché GPU
Mercury Research vient de publier ses derniers chiffres (format PDF) concernant les ventes de GPU sur le second trimestre.
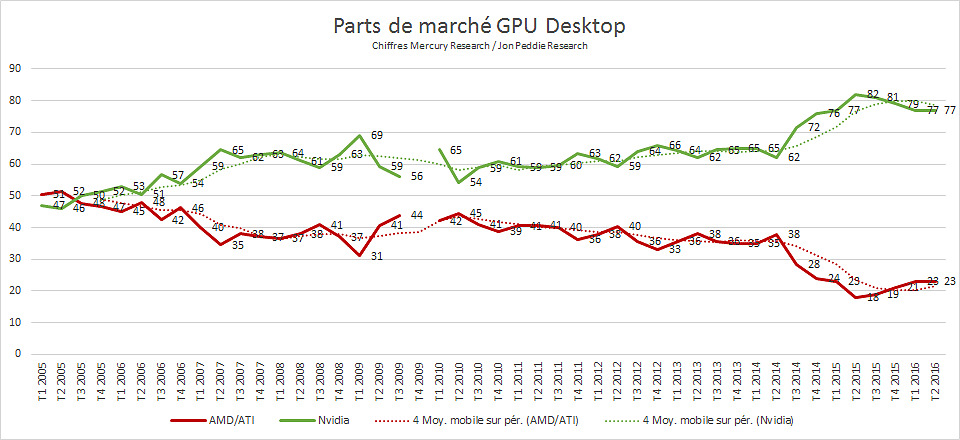
Du côté des GPU desktop, les changements sont restreints puisque AMD passe seulement de 22.7 à 22.8% de parts de marché, pas de quoi compenser le déclin qui avait commencé au troisième trimestre 2014.
En ce qui concerne le marché des GPU additionnels mobiles, là aussi AMD note un gain, passant de 35.9% sur le trimestre précédent à 36.4%. Si l'on considère la totalité du marché GPU, Intel baisse très légèrement (pour la première fois depuis 10 ans selon la firme) passant de 71.7% au trimestre précédent à 71.5%. Nvidia passe de 16.3% à 16.1% tandis qu'AMD progresse de 11.8% à 12.3%. A l'inverse d'Intel, c'est la première fois qu'AMD inverse sa courbe de baisse depuis le premier trimestre 2012. On peut tout de même tempérer cela en rappelant qu'au second trimestre 2015, AMD disposait de 14% de parts de marché GPU global.
Côté tendances, le marché global du GPU reste à la baisse avec -3.1% de ventes par rapport à la même période l'année dernière, et -6.5% séquentiellement en nombres d'unités. Sur les GPU desktop, la baisse par rapport au trimestre précédent a atteint un impressionnant -20%, majoritairement lié à un inventaire important chez les distributeurs, concernant principalement Nvidia.
Le constructeur a compensé cela par l'arrivée de ses références haut de gamme, Mercury Research remarquant que le prix de vente moyen des GPU desktop a atteint sur ce trimestre un nouveau record.
Microsoft capitule sur le support de Skylake
En début d'année, Microsoft avait publié un billet de blog surprenant , indiquant que non seulement les futurs processeurs d'Intel et d'AMD ne seraient supportés pleinement que par Windows 10, mais qu'en prime les plate-formes Intel Skylake (la dernière génération en date de processeurs d'Intel) ne disposeraient d'un support sous Windows 7 (et 8.1) que jusqu'en juillet 2017 !
Quelque chose que nous avions interprété à l'époque comme une bien lourde tentative d'inciter les OEM, les revendeurs, et les utilisateurs, à passer à Windows 10. La firme de Redmond ayant été pour le moins obscure sur ce que cette limite supposait, sous entendant dans son billet que seules les failles de sécurité les plus critiques feraient l'objet de patch.
Rapidement, Microsoft est revenu en arrière une première fois, rajoutant une année de "support" et repoussant cette limite à juillet 2018.

Aujourd'hui, Microsoft revient en arrière une deuxième fois, abandonnant définitivement l'idée d'un support sélectif de Skylake. Un nouveau billet de blog indique que Microsoft fournira "tous les patchs" pour les plate-formes Skylake jusqu'à la fin du support officiel de Windows 7 (14 janvier 2020) et 8.1 (10 janvier 2023). Microsoft crédite ce changement à son "partenariat fort" avec Intel qui s'occupera de la validation des patchs, et aussi à la demande de ses clients entreprise.
Microsoft continue cependant d'indiquer que les futures plate-formes d'Intel et d'AMD comme Kaby Lake et Bristol Ridge ne seront "supportés pleinement" que sous Windows 10. On ne sait pas encore ce que cela veut dire, il serait étonnant qu'Intel et AMD ne proposent pas, par exemple, de pilotes chipsets pour Windows 7 et 8.1 pour leur prochaine génération.
Cette capitulation de Microsoft n'est pas forcément surprenante étant donné la frilosité historique des entreprises à passer à une nouvelle version de Windows. Combiné à la non percée sur le marché des smartphones avec Windows 10 Mobile et malgré l'utilisation de techniques peu admissibles d'un point de vue moral (et légal ) pour forcer les mises à jour vers Windows 10, la société de Redmond à du revenir en arrière sur ses objectifs d'atteindre un milliard de machines sous Windows 10 d'ici 2018.
Les changements de politique de Microsoft en matière de vie privée posent également question, la société utilisant désormais abondamment la "télémétrie", et Microsoft se réservant le droit "d'accéder, transférer, communiquer et stocker" vos données personnelles dans une liste de cas relativement large (voir la section complète Reasons We Share Personal Data pour plus de détails), incluant par exemple la protection de la propriété intellectuelle de Microsoft !
On notera cependant qu'une grande partie de la télémétrie a été déployée sous Windows 7 et 8.1 via des mises à jour Windows Update. Si l'on pouvait désactiver manuellement celles ci, nos confrères d'Ars Technica indiquaient hier que Microsoft ne proposera plus la possibilité pour Windows 7 et 8.1 de télécharger et choisir individuellement les patchs à partir d'octobre, proposant uniquement des bundles. Dans un premier temps, cela ne concernera que les nouveaux patchs de sécurité mais toutes les mises à jour seront concernées à terme.