
Les contenus liés au tag GPGPU
Afficher sous forme de : Titre | FluxFocus: Le futur de Nvidia : Kepler et Maxwell
AMD FireStream 9350 et 9370
Computex: serveurs avec GPUs chez Supermicro
Tesla 20 et Fermi : plus de détails
Nvidia dévoile des Tesla 20 avec Fermi
GTC: GTC 2012: la semaine du GPU computing
Nvidia organise en ce moment à San José l'édition 2012 de la GPU Technology Conference (GTC), un évènement centré sur le GPU computing : supercalculateurs, langages destinés à la programmation massivement parallèle, cloud computing pour les jeux vidéo...
Nous serons sur place toute la semaine pour couvrir ce forum technologique durant lequel nous nous attendons à recevoir de nombreuses informations sur CUDA 5, d'éventuels dérivés Tesla basés sur le GPU GK104 des GeForce GTX 670/680/690, mais surtout sur le GK110, le futur gros GPU de la famille Kepler.

Les grandes lignes de ces nouveautés devraient être dévoilées ce mardi durant la keynote d'ouverture de Jen-Hsun Huang, le CEO de Nvidia, et abordées plus en détail par la suite. Si le sujet vous intéresse, notez que cette keynote sera retransmise en direct depuis le site officiel de la GTC à partir de 19h30 heure française.
Nvidia GK110: 7 milliards de transistors à la GTC?
Comme nous l'indiquions dans notre test de la GeForce GTX 680, cette dernière ne repose pas sur le plus gros GPU de la famille Kepler, qui a été retardé ou remplacé pour des raisons inconnues, probablement liées à la problématique de la fabrication sur le process 28 nanomètres.
Si Nvidia a décidé d'introduire initialement la GeForce GTX 600 haut de gamme en se basant sur le "petit" GK104, au départ destiné au segment inférieur, cela ne veut pas dire que le plus gros GPU de la famille a été annulé. S'il n'est pas strictement nécessaire sur le plan des performances en jeu, Nvidia ne peut pas s'en passer pour le marché professionnel, particulièrement du calcul haut performance. En effet, le GK104 fait de nombreux compromis à ce niveau, et s'il permet de proposer un excellent rendement dans les jeux vidéo, ce n'est plus le cas lorsqu'il s'agit de l'exploiter en tant qu'accélérateur massivement parallèle.
Tout comme le GK104 (GTX 680) est en réalité le successeur du GF104/114 (GTX 460/560 Ti), le GK110 sera le vrai successeur du GF100/110 (GTX 480/580). Il aura pour tâche d'enfoncer le clou en termes de performances brutes, ce qui profitera également à la partie graphique, mais surtout de poursuivre l'évolution vers plus de flexibilité pour le calcul massivement parallèle.

En dehors de sa raison d'être évidente, peu d'informations circulent à ce jour sur ce GPU. En guise de teasing, Nvidia a cependant glissé une petite information dans le descriptif d'une des sessions de la GPU Technology Conference (GTC) qui se tiendra à San José, du 14 au 17 mai :
In this talk, individuals from the GPU architecture and CUDA software groups will dive into the features of the compute architecture for Kepler NVIDIA's new 7-billion transistor GPU. From the reorganized processing cores with new instructions and processing capabilities, to an improved memory system with faster atomic processing and low-overhead ECC, we will explore how the Kepler GPU achieves world leading performance and efficiency, and how it enables wholly new types of parallel problems to be solved.Sans que le GK110 ne soit directement nommé, Nvidia mentionne un nouveau GPU Kepler de pas moins de 7 milliards de transistors ! Pour rappel, le GK104 s'en contente de 3.5 milliards alors que le plus gros GPU d'AMD, Tahiti n'affiche "que" 4.3 milliards au compteur.
Par rapport au GK104, de nombreuses fonctionnalités strictement liées au calcul professionnel seront introduites. Nvidia mentionne ici un sous-système mémoire amélioré pour des opérations atomiques plus performantes et un overhead réduit pour l'ECC, déjà présent sur le GF100/110 mais avec un coût relativement important. Ce nouveau GPU disposera également d'une capacité de calcul en double précision très élevée, alors que sur le GK104 son support est anecdotique avec des performances équivalentes à 1/24ème celles de la simple précision. Précédemment, Nvidia mettait d'ailleurs en avant l'explosion du rendement énergétique en calcul double précision (x3) pour positionner Kepler par rapport à Fermi.
La GTX 680 déjà remplacée après 2 mois ? Pas vraiment : sauf énorme surprise, la GeForce GTX 690 qui sera présentée sous peu sera une carte bi-GPU basée sur des GK104. Une GeForce basée sur le GK110 sortira sans aucun doute (GTX 685 ? GTX 780 ?), mais probablement pas avant la rentrée. Dans l'immédiat Nvidia veut probablement avant tout préparer les professionnels à son arrivée, les cycles de développement étant très longs, mais également les convaincre des bienfaits du GPU Computing, à l'heure où la réponse d'Intel avec Knights Corner et l'architecture MIC n'est plus très loin.
Dans tous les cas, nous serons présents à la GTC et nous ne manquerons pas de vous rapporter toutes les informations liées à ce nouveau GPU ainsi qu'à la plateforme CUDA 5 !
Nvidia, PGI et Cray dévoilent OpenACC
Le SC11 aura vu débarquer officiellement un énième langage destiné aux accélérateurs massivement parallèle, et en particulier aux GPU : OpenACC. Standard ouvert proposé par Nvidia, The Portland Group (PGI) et Cray, avec l'aide de CAPS, il représente une alternative à une initiative similaire proposée par Microsoft avec C++ AMP.

OpenACC permet ainsi de définir très simplement dans le code les zones à accélérer, à l'aide de directives pour le compilateur, qui se charge ensuite de toute la complexité liée à l'utilisation d'un accélérateur. Cette approche simplifie nettement le travail des développeurs et permet de conserver la compatibilité avec les systèmes dépourvus d'accélérateur, puisqu'il suffit alors d'ignorer ces directives.
Reste bien entendu qu'une telle approche est moins efficace qu'un code optimisé manuellement pour une architecture spécifique, mais elle permet d'obtenir rapidement des résultats intéressants pour les morceaux de code naturellement parallèles, de pouvoir juger de l'intérêt des accélérateurs sans gros investissement et d'éviter d'être enfermé dans le support d'une seule architecture. Compte tenu de temps de développement qui peuvent être très longs, utiliser un langage tel qu'OpenACC et, éventuellement, intégrer quelques fonctions natives lors de la mise en production (cela reste bien entendu possible), permet de limiter les risques.
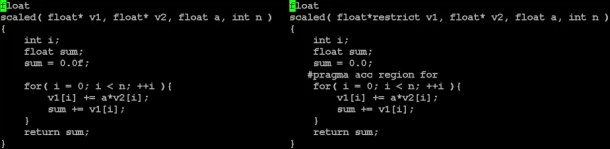
Un exemple simple de conversion d'un code classique vers le modèle de PGI à base de directives dont OpenACC est très proche.
OpenACC, défini pour C, C++ et Fortran, est une version étendue et ouverte du modèle de programmation à base de directives pour les accélérateurs de PGI, un petit peu comme OpenCL est une version étendue et ouverte de C pour CUDA. OpenACC complexifie légèrement le langage de PGI, ce qui était nécessaire pour étendre ses possibilités. Dans un premier temps 3 compilateurs seront compatibles :
- PGI Accelerator C/C++/Fortran pour CUDA (GPU Nvidia)
- Cray CCE pour systèmes Cray (qui supportent les GPU Nvidia)
- CAPS Enterprise HMPP Workbench (qui supporte OpenCL)
Grossièrement, les compilateurs OpenACC qui sont actuellement prévus concernent avant tout l'utilisation d'accélérateurs CUDA, Nvidia étant l'un des membres à l'origine du langage. Rien n'empêche cependant la mise en place de compilateurs OpenCL, comme le fait CAPS, ou dédiés aux GPU AMD, si ce n'est le fait qu'actuellement chacun semble développer son propre "standard" en prenant soin de nier les initiatives issues de la concurrence.
Reste qu'OpenACC semble avoir été tiré de la réflexion initiale du groupe de travail sur les accélérateurs d'OpenMP, dont l'exploitation représente un des objectifs de la version 4.0 de ses spécifications. Les membres fondateurs d'OpenACC ne cachent d'ailleurs pas leur intention de l'intégrer à OpenMP, précisant que ce lancement anticipé permettra à ce sujet d'obtenir de la part des développeurs des retours importants pour la finalisation du standard complet et robuste d'OpenMP pour le calcul hétérogène.
Vous pourrez obtenir les spécifications complètes de la version 1.0 d'OpenACC par ici .
Focus : Nvidia annonce CUDA 4.0
Pour fêter les 4 ans d’anniversaire de CUDA, Nvidia vient de lever le voile sur la version 4.0 du kit de développement qui permet de profiter de la puissance de calcul des GPUs dans de nombreux domaines. C’est en effet début février 2007 que Nvidia nous fournissait la première version bêta de son kit de développement, avant d’en sortir une version 1.0 au mois de juin de la même année.
Si, à l’origine, CUDA représentait le nom de l’architecture introduite par Nvidia pour faciliter...
[+] Lire la suite

NVIDIA 1er au Top 500



Après avoir atteint la 2nd place lors du dernier classement des supercalculateurs TOP 500 lors de la dernière mise à jour de Juin, NVIDIA et la Chine devraient prendre la première place du prochain classement grâce à un score de 2,507 Petaflops obtenu par Tianhe-1A.

Basé sur 7 168 GPU Tesla M2050 et 14 336 CPU, ce supercalculateur bat largement le précédent record de 1,759 Petaflops détenu par le Cray XT5-HE. Il sagit en fait dune mise à jour du Tianhe-1 qui était basé sur 5120 GPU de Radeon 4870 X2 et qui était 7è au précédent classement avec 563,1 Teraflops.
NVIDIA met en avant la consommation lefficacité énergétique du Tianhe-1A, qui ne consomme "que" 4,04 Megawatts, là ou un système 100% CPU consommerait 3 fois plus pour arriver à un niveau de performance similaire.