| |
| |
| Nvidia annonce CUDA 4.0 Cartes Graphiques Publié le Lundi 28 Février 2011 par Damien Triolet URL: /focus/29/.html Pour fêter les 4 ans d’anniversaire de CUDA, Nvidia vient de lever le voile sur la version 4.0 du kit de développement qui permet de profiter de la puissance de calcul des GPUs dans de nombreux domaines. C’est en effet début février 2007 que Nvidia nous fournissait la première version bêta de son kit de développement, avant d’en sortir une version 1.0 au mois de juin de la même année. 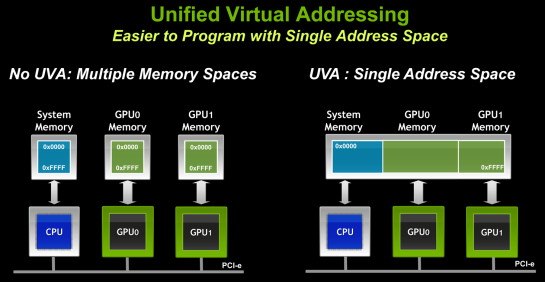 Cette version 4.0 RC de CUDA introduit deux innovations majeures, qui sont en réalité liées, et réservées aux GPUs des familles Fermi et suivantes. La première se nomme UVA pour Unified Virtual Adressing. Il s’agit d’une évolution très demandée par les développeurs, y compris à l’intérieur de Nvidia où plusieurs équipes mettent au point des librairies ou des moteurs d’accélération basés sur CUDA. Comme son nom l’indique, elle consiste à unifier l’espace mémoire pour l’ensemble du programme CUDA, pour le code qui tourne sur le CPU et pour le code qui tourne sur le ou les GPUs. Cette évolution peut être vue comme une manière pour Nvidia de prendre en charge une partie du travail des développeurs qui n’auront plus à se soucier de la gestion de plusieurs espaces mémoire. De son côté Nvidia devra s’assurer de la robustesse d’une telle gestion globale, une tâche relativement complexe. La seconde grosse évolution se nomme GPUDirect v2.0 et est facilitée par la première. Elle permet un transfert de données direct entre GPUs, alors qu’actuellement, à quelques exceptions près, toute communication devait passer par la mémoire centrale. Par ailleurs, un seul thread pourra dorénavant accéder aux ressources de tous les GPUs présents. De quoi faciliter l’exploitation de plusieurs GPUs mais également d’élargir les possibilités d’un tel système qui pourra, qui plus est, très bientôt profiter de la bande passante supplémentaire offerte par le PCI Express 3.0. 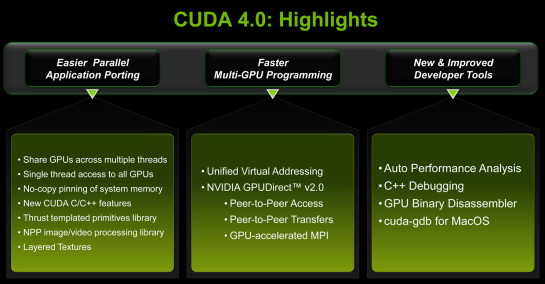 De nombreuses autres petites nouveautés sont également au menu, telles que l’intégration de Thrust (équivalent CUDA de STL), de nouvelles fonctions C++, d’un désassembleur et d’un débuggeur pour MacOS. La version RC est disponible pour les développeurs enregistrés auprès de Nvidia , en attendant une version finale qui arrivera probablement d’ici quelques mois. Copyright © 1997-2026 HardWare.fr. Tous droits réservés. |