
Les derniers contenus liés aux tags CUDA et GPGPU
Dossier: Nvidia CUDA : l'heure de la concrétisation ?
Premier Centre d'Excellence CUDA
Dossier: Nvidia CUDA : plus en pratique
Nvidia lance Tesla
Dossier: Nvidia CUDA : aperçu
AMD et HPC: nouveaux outils, support de CUDA
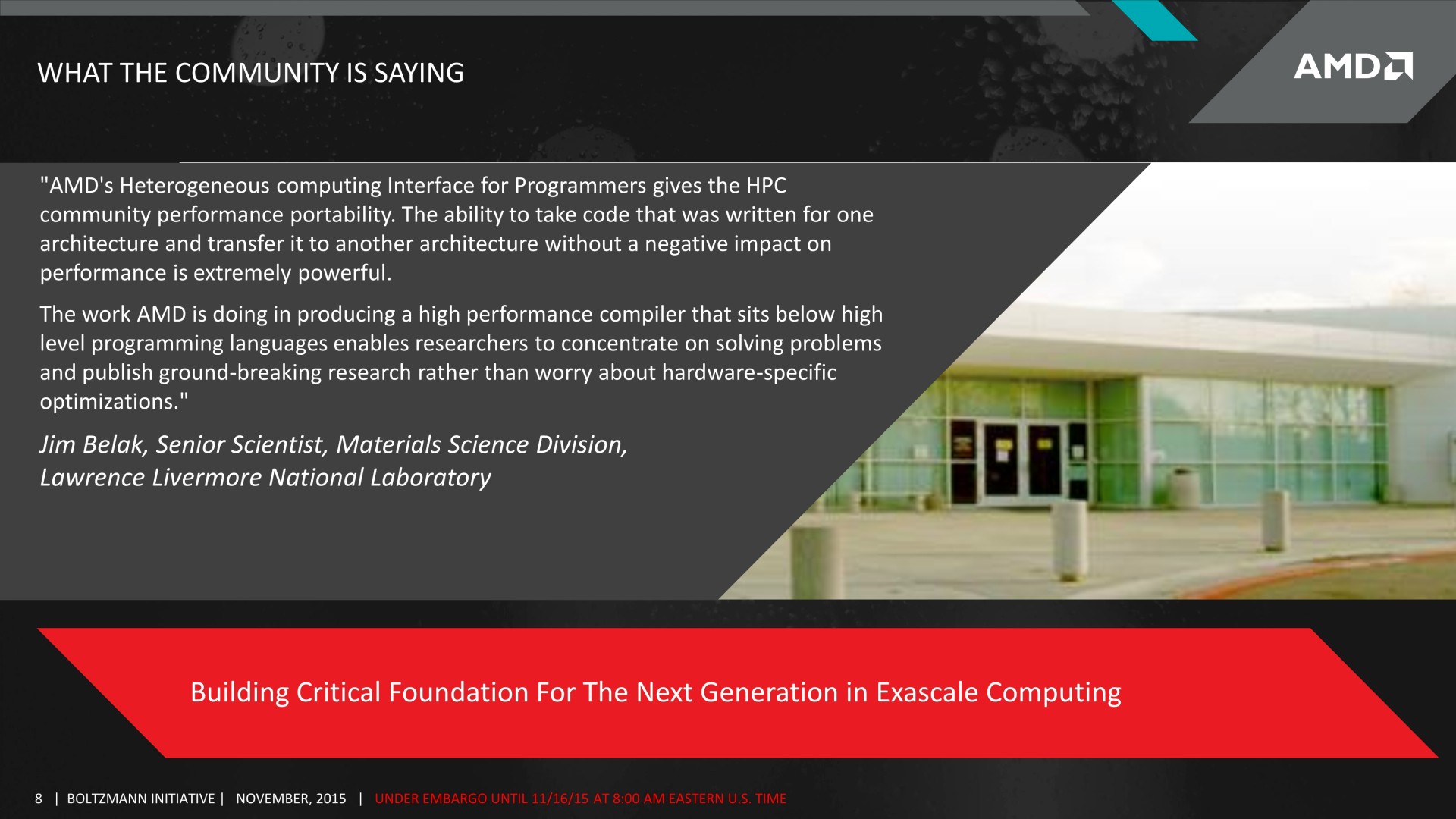
AMD profite du forum SC15 pour annoncer l'initiative Boltzmann, un ensemble de nouveaux outils dédiés à renforcer sa présence dans le HPC, notamment via un portage du code CUDA.
Il y a quelques semaines, le départ de Phil Rogers d'AMD pour rejoindre Nvidia a pu soulever quelques inquiétudes. Cet ingénieur émérite était la figure de proue de la HSA, la plateforme ouverte dédiée au calcul hétérogène ("CPU + GPU"), poussée par AMD avec le support du monde ARM. Une perte incontestable pour AMD qui mise beaucoup sur la HSA, que ce soit au niveau du HPC (calcul haute performances) ou du grand public.

A l'occasion du SC15 (SuperComputing), AMD tient cependant à rassurer quant à l'avenir de la HSA et de son écosystème dédié au calcul hétérogène. De nombreux développements, dédiés initialement au monde professionnel, sont en cours de finalisation et, avec une bonne dose de pragmatisme, ont pour objectif commun d'apporter aux développeurs et aux clients potentiels les outils dont ils ont besoin. AMD regroupe cet ensemble de développements sous le nom de code "Initiative Boltzmann", en référence au physicien Ludwig Eduard Boltzmann dont les équations profitent aujourd'hui de la puissance de calcul des GPU.

Sans donner de précisions liées au hardware, les annonces sont concentrées sur le software, AMD annonce tout d'abord l'extension du support de la HSA des APU (Kaveri) vers les GPU dédiés. Pour cela, AMD proposera un nouveau pilote Linux headless, c'est-à-dire totalement dédié au calcul, allégé du support des parties graphiques et vidéo. De quoi proposer plus facilement un adressage mémoire unifié entre les CPU et les GPU (et rattraper Nvidia sur ce point crucial), réduire la latence des transferts PCIe et de l'envoi des commandes, mieux exploiter tout le sous-système mémoire des GPU etc. Des systèmes de gestion spécifique des GPU (fréquences turbo etc.) seront également proposés ainsi qu'un support étendu de la communication P2P, y compris pour des GPU présents dans des nuds différents dans le cadre des supercalculateurs.

Ensuite, AMD annonce un nouveau compilateur : HCC pour Heterogeneous Compute Compiler. Il s'agit d'un compilateur de type source unique, c'est-à-dire qu'il traite autant le code CPU que le code GPU mis en avant à l'aide de directives (à la manière de C++ AMP de Microsoft). HCC est compatible C++ 11/14, C11 et OpenMP 4.0. Il propose par ailleurs un support alpha de la Parallel Standard Template Library de C++17 (C++1z), la prochaine révision de C++ attendue pour 2017. AMD annonce différentes optimisations qui devraient profiter aux performances tels qu'une meilleure gestion de la mémoire et le support de l'exécution asynchrone des kernels (et concomitante).

Enfin, AMD fait face à la réalité : CUDA de Nvidia est bien implanté dans le monde du HPC. Suffisamment pour que sa seule stratégie à ce niveau ne puisse plus se résumer à essayer de nier cet état de fait avec des statistiques d'utilisation d'OpenCL chez les développeurs. Avec pragmatisme, AMD annonce ainsi l'interface HIP (Heterogeneous-compute Interface for Portability) dont le but est de permettre au code CUDA de tourner sur ses propres GPU.
Cela se fera de manière indirecte bien entendu, avec des outils qui porteront le code source CUDA vers un language C++ commun (cudaMemcpy -> hipMemCpy). Après conversion, le code pourra ensuite tourner aussi bien sur les GPU Nvidia via le compilateur NVCC que sur les GPU AMD via le compilateur HCC. AMD indique que d'après ses tests, 90% du code CUDA peut être automatiquement porté alors que les 10% restants doivent être traités manuellement mais en C++ standard. AMD estime que cela devrait répondre aux demandes du marché qui appréciera l'ouverture de l'offre matérielle pour une bonne partie des systèmes amenés à faire tourner du code CUDA. A voir par contre si Nvidia appréciera cette initiative de la même manière...
A noter que ce support du code CUDA reste partiel et ne concerne que l'ensemble de plus haut niveau, soit le code C/C++ CUDA pour l'API runtime. Le code qui vise l'API driver ainsi que le code PTX ne seront pas supportés, tout du moins initialement.
AMD fera la démonstration de ces outils durant le SC15 et une première version beta sera mise dans les mains des développeurs au premier trimestre 2016.









Nvidia annonce la Tesla K40 et CUDA 6
La semaine passée, à l'occasion du SC13 (Supercomputing 2013), Nvidia a annoncé deux nouveautés liées au calcul haute performance : l'accélérateur Tesla K40 et la version 6 de CUDA.
Pour rappel, c'est la gamme Tesla qui a été la première à profiter du plus gros GPU de la famille Kepler, le GK110. Contrairement aux Quadro K6000 et GeForce GTX 780 Ti plus récentes, cette gamme Tesla n'accueillait cependant toujours pas de version complète du GK110, c'est-à-dire avec l'ensemble de ses unités d'exécution actives. Une configuration facilitée par l'arrivée de la révision B1 du GPU.
La Tesla K40 profite ainsi de 15 SMX, de 2880 unités de calcul FMA 32-bit et de 960 unités FMA 64-bit pour afficher une puissance de calcul en hausse de près de 10% par rapport à la Tesla K20X. Par ailleurs, comme pour le Quadro K6000, Nvidia profite de la disponibilité effective de la GDDR5 4 Gbits pour faire passer la mémoire dédiée de son accélérateur de 6 à 12 Go. Sa fréquence est par ailleurs revue à la hausse ce qui profite à la bande passante mémoire en hausse de 15%.

Si la fréquence GPU ne progresse que très peu pour la Tesla K40, c'est uniquement pour garantir que l'enveloppe thermique ne soit pas atteinte dans les tâches de type calcul, sachant que, contrairement aux GeForce, Nvidia ne propose pas de turbo pour ces cartes afin d'éviter que leurs performances soient variables. Par contre, pour la Tesla K40, Nvidia propose 2 modes avec des fréquences GPU différentes : optionnellement, il sera ainsi possible de passer le GPU de 745 à 810 ou 875 MHz. Il ne s'agit pas d'un overclocking dans le sens où ces fréquences sont validées par Nvidia, ni d'un turbo automatique, même si Nvidia place cette possibilité sous l'appellation GPU Boost, marque du turbo des GeForce... Si la personne qui exploite ces Tesla K40 constate qu'elles restent loin de leur TDP dans une certaine situation, elle aura la possibilité de passer à un de ces modes de fréquence supérieure. De quoi profiter 9% voire 17% de puissance supplémentaire.
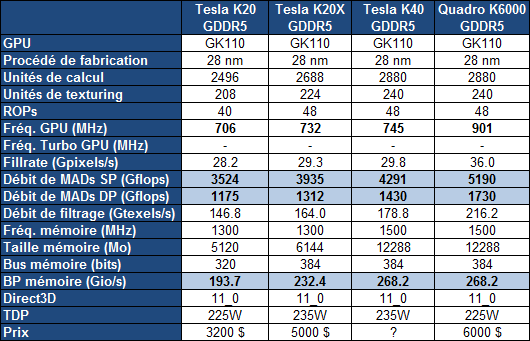
A noter que la Tesla K40 sera proposée autant avec un refroidissement actif, comme la K20, qu'avec un refroidissement passif en vue d'intégration dans un serveur, comme la K20X. Enfin, le PCI Express 3.0 est activé sur la K40 contrairement aux K20/X.
Nvidia ne communique pas au niveau de la tarification, mais elle devrait rester inférieure à celle de la Quadro K6000, probablement passer à 5000$ alors que les K20/X devraient voir leur tarif baisser. Il faut cependant garder en tête que sur ce marché de niche, les prix sont fortement variables, les grossistes n'hésitant pas à se réserver des marges conséquentes. Ainsi pour des tarifs annoncés par Nvidia de 3200$ et de 5000$ pour les K20 et K20X, en pratique, il fallait en général compter plutôt 4000$ et 7500$, la même chose en euros.
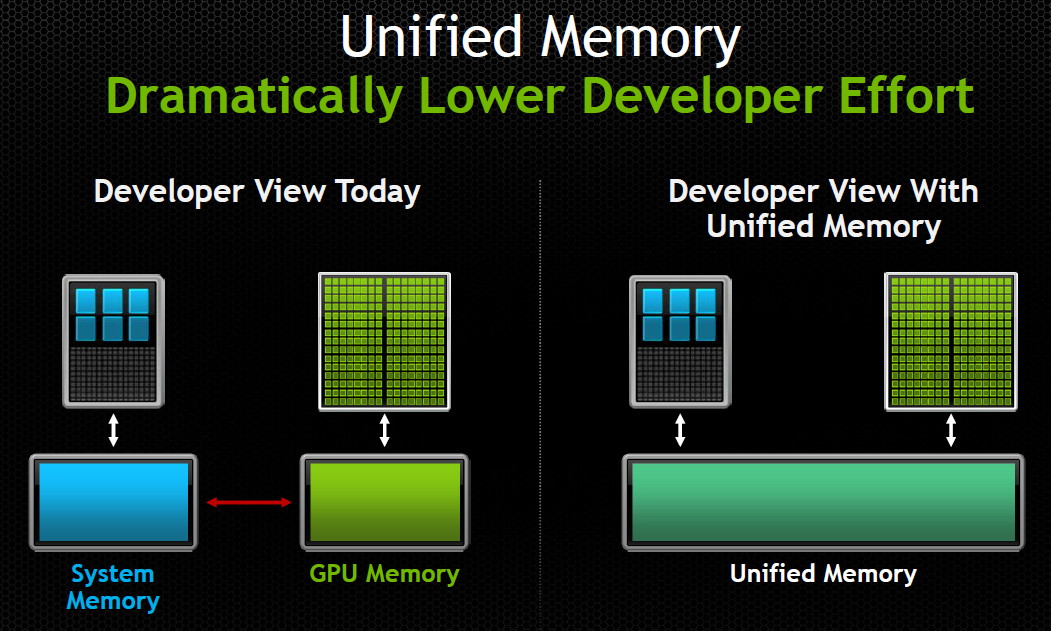
Parallèlement à l'arrivée de cette nouvelle Tesla, Nvidia a annoncé CUDA 6 qui apporte une nouveauté majeure et très attendue : la prise en charge d'une mémoire unifiée. Une fonctionnalité qui donne l'impression d'être annoncée et réannoncée régulièrement, AMD et Nvidia ayant régulièrement joué sur les mots à ce niveau. Pour rappel, depuis quelques temps, CUDA supporte un adressage de mémoire virtuelle unifié, qui facilite quelque peu le développement mais n'était qu'un premier pas. La mémoire unifiée, représente cette fois une abstraction totale de la gestion de la mémoire : il n'est plus nécessaire que le développeur gère les transferts de données de la mémoire centrale vers la mémoire de l'accélérateur.
Une gestion manuelle de la mémoire restera possible, étant donné qu'aussi bénéfique soit cette simplification, elle peut avoir un coût sur le plan des performances et de l'efficacité puisqu'il reviendra aux pilotes et/ou aux compilateurs d'essayer de placer automatiquement les données au bon endroit.

Confiant dans l'avenir, Nvidia termine par annoncer que l'ouverture par IBM, cet été, de sa plateforme serveur POWERn, va permettre d'y intégrer des accélérateurs Tesla dès 2014. Des accélérateurs qui seront ainsi exploités non plus uniquement sur x86 mais également sur architectures POWER et ARMv8.
Nvidia, PGI et Cray dévoilent OpenACC
Le SC11 aura vu débarquer officiellement un énième langage destiné aux accélérateurs massivement parallèle, et en particulier aux GPU : OpenACC. Standard ouvert proposé par Nvidia, The Portland Group (PGI) et Cray, avec l'aide de CAPS, il représente une alternative à une initiative similaire proposée par Microsoft avec C++ AMP.

OpenACC permet ainsi de définir très simplement dans le code les zones à accélérer, à l'aide de directives pour le compilateur, qui se charge ensuite de toute la complexité liée à l'utilisation d'un accélérateur. Cette approche simplifie nettement le travail des développeurs et permet de conserver la compatibilité avec les systèmes dépourvus d'accélérateur, puisqu'il suffit alors d'ignorer ces directives.
Reste bien entendu qu'une telle approche est moins efficace qu'un code optimisé manuellement pour une architecture spécifique, mais elle permet d'obtenir rapidement des résultats intéressants pour les morceaux de code naturellement parallèles, de pouvoir juger de l'intérêt des accélérateurs sans gros investissement et d'éviter d'être enfermé dans le support d'une seule architecture. Compte tenu de temps de développement qui peuvent être très longs, utiliser un langage tel qu'OpenACC et, éventuellement, intégrer quelques fonctions natives lors de la mise en production (cela reste bien entendu possible), permet de limiter les risques.
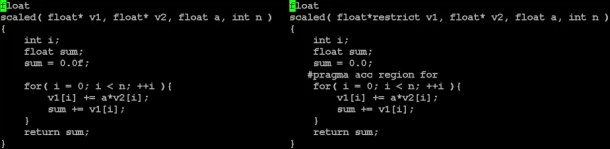
Un exemple simple de conversion d'un code classique vers le modèle de PGI à base de directives dont OpenACC est très proche.
OpenACC, défini pour C, C++ et Fortran, est une version étendue et ouverte du modèle de programmation à base de directives pour les accélérateurs de PGI, un petit peu comme OpenCL est une version étendue et ouverte de C pour CUDA. OpenACC complexifie légèrement le langage de PGI, ce qui était nécessaire pour étendre ses possibilités. Dans un premier temps 3 compilateurs seront compatibles :
- PGI Accelerator C/C++/Fortran pour CUDA (GPU Nvidia)
- Cray CCE pour systèmes Cray (qui supportent les GPU Nvidia)
- CAPS Enterprise HMPP Workbench (qui supporte OpenCL)
Grossièrement, les compilateurs OpenACC qui sont actuellement prévus concernent avant tout l'utilisation d'accélérateurs CUDA, Nvidia étant l'un des membres à l'origine du langage. Rien n'empêche cependant la mise en place de compilateurs OpenCL, comme le fait CAPS, ou dédiés aux GPU AMD, si ce n'est le fait qu'actuellement chacun semble développer son propre "standard" en prenant soin de nier les initiatives issues de la concurrence.
Reste qu'OpenACC semble avoir été tiré de la réflexion initiale du groupe de travail sur les accélérateurs d'OpenMP, dont l'exploitation représente un des objectifs de la version 4.0 de ses spécifications. Les membres fondateurs d'OpenACC ne cachent d'ailleurs pas leur intention de l'intégrer à OpenMP, précisant que ce lancement anticipé permettra à ce sujet d'obtenir de la part des développeurs des retours importants pour la finalisation du standard complet et robuste d'OpenMP pour le calcul hétérogène.
Vous pourrez obtenir les spécifications complètes de la version 1.0 d'OpenACC par ici .
Focus : Nvidia annonce CUDA 4.0
Pour fêter les 4 ans d’anniversaire de CUDA, Nvidia vient de lever le voile sur la version 4.0 du kit de développement qui permet de profiter de la puissance de calcul des GPUs dans de nombreux domaines. C’est en effet début février 2007 que Nvidia nous fournissait la première version bêta de son kit de développement, avant d’en sortir une version 1.0 au mois de juin de la même année.
Si, à l’origine, CUDA représentait le nom de l’architecture introduite par Nvidia pour faciliter...
[+] Lire la suite

Computex : Nvidia mise sur GPU Computing



Le fabricant de GPUs a tenu une première conférence, avant l'ouverture officielle du Computex, qui était principalement tournée sur le GPU Computing.
Nvidia a pu annoncer l'arrivée chez SuperMicro d'un serveur équipé d'une plateforme Intel et d'accélérateurs Tesla offrant 2 teraflops en occupant seulement 1U. Les solutions proposées par Nvidia tiennent également dans 1U mais n'embarquent que les GPUs et doivent donc être liée à un serveur maître. La solution de SuperMicro présente donc un intérêt important même si nous n'en connaissons pas encore les spécifications exactes. Tout au juste pouvons nous déduire des 2 teraflops qu'elle sera équipée du côté GPU de 2 GT200b.

Jen-Hsun Huang, President & CEO, Nvidia.
Du côté grand public, Nvidia s'est félicité du nombre croissant d'applications capables de tirer partie du GPU en tant que coprocesseur parallèle tout en précisant que ce n'était qu'un début puisque l'arrivée de DirectX 11 et de Windows 7 devrait accélérer la tendance. Le premier permettra d'exploiter les GPUs (y compris les versions actuelles !) d'une manière standardisée à travers les Compute Shaders. Le second, en plus d'inclure DirectX 11 à sa base, intégrera un transcodeur capable d'exploiter les GPUs, à travers les Compute Shaders, pour accélérer la conversion des vidéos.

Microsoft et Nvidia mettent en avant la prise en charge native du GPU dans Windows 7 pour accélérer le transcodage vidéo.
Grâce à CUDA, Nvidia a pris une nette avance sur la concurrence du côté du GPU Computing puisque le fabricant est prêt depuis longtemps du côté logiciel. Si à l'avenir tous les composants devraient être supportés, dans l'immédiat, l'avance prise du côté logiciel permet aux GeForce de profiter de la primeur de ces accélérations dans quelques applications principalement dédiées au traitement des vidéos. Il en va de même avec PhysX qui offre aux GeForce le premier support matériel pour la physique d'effets.
Pour appuyer sa vision Nvidia a cependant recours à des artifices grossiers dont la société use et abuse et qui finissent par transformer un sujet intéressant en caricature de communication. Par exemple pour convaincre la presse que le GPU en tant que coprocesseur est l'avenir du PC, l'argument de Jen-Hsun Huang, CEO de Nvidia, est de dire que tout le monde affirme que c'est le cas. Sous-entendu « vous la presse devez écrire la même chose pour ne pas avoir l'air ridicule ». Autre exemple, quand Nvidia nous fait la démonstration d'un jeu avec effets physiques accélérés par le GPU, le volume sonore est réduit de moitié lorsque ces effets sont désactivés, pour accentuer la sensation de perte d'immersion.
Mais ce qui nous ennuie le plus, c'est la simplification qui consiste à présenter un élément d'une unité de calcul vectorielle des GeForce comme étant un core. Une simplification qui devient de plus en plus tordue à mesure que les GPUs et les CPUs s'affrontent. Si la rhétorique de Nvidia est acceptée, alors un CPU quadcore devrait être vu comme composé d'au moins 16 cores compte tenu de ses unités vectorielles. Tout le monde crierait alors au ridicule et à raison. Nvidia est cependant coincé puisqu'après avoir utilisé à la base de son marketing les cores de cette manière il est difficile de revenir en arrière. Comment dire maintenant que le GT200 est en fait composé de 10 voire 30 cores et non pas de 240 ?