Les contenus liés au tag GPGPU
Afficher sous forme de : Titre | FluxGTC: GTC 2012: la semaine du GPU computing
Nvidia GK110: 7 milliards de transistors à la GTC?
Nvidia, PGI et Cray dévoilent OpenACC
Focus: Nvidia annonce CUDA 4.0
NVIDIA 1er au Top 500
HSA, calcul hétérogène: Intel et Nvidia isolés?



Début juin, AMD inaugurait la HSA Foundation en partenariat avec ARM, Imagination Technologies, MediaTek et Texas Instruments. Cette fondation a pour rappel comme objectif de concevoir des standards dédiés au calcul hétérogène qu'ils concernent l'aspect programmation ou l'implémentation matérielle. Coup sur coup, elle vient d'accueillir de nouveaux membres importants.
ATI, avant d'être englobé par AMD, avait été le premier à nous faire part de l'ambition d'utiliser la puissance de calcul des GPU à d'autres fins que le rendu 3D en temps réel pour lequel ils ont à l'origine été conçus. Probablement par manque de moyens, ces développements ont avancé très lentement et il aura fallu attendre plus d'un an avec la concrétisation de l'initiative similaire de Nvidia pour que le GPU mette enfin un pied dans la porte du monde du calcul haute performance. Disponible dès début 2007, CUDA a ainsi relégué au second plan toute initiative similaire de la part d'ATI/AMD.
Quelques tergiversations au niveau des choix technologiques et des langages de programmation, ainsi que l'intégration d'ATI dans AMD, ont par la suite empêché toute avancée rapide. Il faut dire qu'avec le projet Fusion d'AMD, l'objectif n'était plus simplement d'exploiter le GPU, mais de profiter de la symbiose GPU + CPU. Par ailleurs AMD a fait le choix, probablement par défaut, de se reposer sur des standards ouverts. A l'inverse, Nvidia a opté pour une approche propriétaire qui lui a permis d'être plus agile et surtout beaucoup plus rapide dans ses développements.
Entre le monde x86 largement dominé par Intel, et le calcul sur GPU dominé par Nvidia, AMD s'est retrouvé dans une situation délicate dans laquelle il était devenu difficile de peser sur les choix technologiques des développeurs et donc de les inciter à programmer pour ses solutions hétérogènes.
Pour sortir de cette impasse, AMD avait besoin de rallier d'autres acteurs à sa cause. Proposer un standard d'architecture pour le calcul hétérogène était une solution naturelle à ce problème, d'autant plus qu'il allait devenir essentiel pour de nombreux autres acteurs : les concepteurs de SoC ultra basse consommation. Lorsque l'enveloppe thermique est limitée, comme c'est le cas pour tous les périphériques mobiles, pouvoir exploiter différents types de curs destinés au calcul (séquentiel ou massivement parallèle) permet de maximiser les performances dans plus de cas de figure. En d'autres termes, tout l'écosystème ARM était voué à exploiter le calcul hétérogène et allait faire face aux mêmes problèmes qu'AMD lorsqu'il s'agirait de trouver la meilleure approche pour le mettre en place.
Mi-2011, AMD a ainsi proposé la FSA, Fusion System Architecture, comme base de travail, avec en coulisse le support d'ARM. Un an plus tard, après un changement de nom pour HSA, Heterogeneous System Architecture, AMD a remis tous ses travaux initiaux à une fondation dont les membres fondateurs initiaux incluaient également ARM, Imagination Technologies, MediaTek et Texas Instruments. Les statuts de la fondation laissaient cependant la possibilité à d'autres acteurs de devenir des membres fondateurs s'ils se manifestaient dans les 3 mois, à partir du 1er juin 2012.
A quelques jours de l'échéance, Samsung a ainsi rejoint la fondation en tant que sixième membre fondateur, accompagné par Apical, Arteris, MulticoreWare, Sonics, Symbio et Vivante en tant que membres secondaires. Si l'arrivée d'un poids lourd tel que Samsung était une bonne nouvelle pour la HSA, l'absence de Qualcomm était étonnante. Avec des objectifs très importants au niveau des capacités de ses SoC, et l'arrivée à la tête de son département d'ingénierie d'Eric Demers, l'ancien responsable des architectures GPU d'AMD, il ne faisait aucun doute que Qualcomm voudrait rejoindre la HSA
et pas en tant que membre secondaire.
Les négociations ont probablement été plus compliquées et longues que prévues, mais ont fini par aboutir et la HSA Foundation a modifié ses statuts de manière à faire disparaître la date limite pour l'entrée de nouveaux membres fondateurs. Hier, Qualcomm est ainsi devenu le septième membre fondateur.

En s'adjoignant le poids de presque tout l'écosystème ARM, AMD ne pouvait probablement pas trouver de meilleure approche pour le développement d'un standard dédié au calcul hétérogène et la présentation graphique du site de la fondation ne laisse guère de doute concernant le fait que la porte reste ouverte pour un huitième membre principal. S'il faudra encore convaincre certains acteurs importants tels qu'Apple ou Microsoft, les grands absents restent Intel et Nvidia.
Ceux-ci, d'une part par égo vis-à-vis d'AMD et d'autre part pour ne pas faciliter l'arrivée de concurrence sur des marchés très juteux, restent hostiles à l'arrivée d'un tel standard. Intel veut conserver un contrôle total de sa plateforme, proposer ses propres solutions destinées au calcul massivement parallèle et favoriser l'utilisation des cores x86 qui sont en train de gagner beaucoup en efficacité énergétique. De son côté, Nvidia n'entend pas saboter les premiers succès commerciaux de sa division Tesla liée à l'architecture propriétaire CUDA, et prépare sa propre solution hétérogène.
Pour éviter de se retrouver isolés du reste de l'industrie, nul doute cependant qu'Intel et Nvidia vont suivre de très près l'évolution de la HSA ainsi que ses premières spécifications. Annoncées pour fin 2011, elles ont pris du retard mais seraient maintenant entre les mains de l'ensemble des membres de la fondation pour une publication avant la fin de cette année.
AFDS: AMD, ARM, ImgTech, TI : HSA Foundation

L'AMD Fusion Developer Summit, un forum technologique dédié au calcul hétérogène, a actuellement lieu à Seattle. Ce forum peut être vu comme la réplique d'AMD à la GPU Technology Conference de Nvidia qui s'est tenue le mois passé, mais un point important distingue cependant les deux évènements : AMD conçoit autant des cores CPU que des cores GPU. Plus que le calcul massivement parallèle, qui exploite les GPU, c'est ainsi le calcul hétérogène qui est ici à l'honneur.
Exploiter en symbiose des cores CPU et des cores GPU est complexe, notamment parce qu'ils ne partagent pas encore un espace mémoire totalement unifié, même si l'APU Trinity apporte quelques avancées à ce niveau. L'an passé, AMD avait annoncé la Fusion System Architecture, une tentative d'apporter des réponses à cette problématique de manière à pouvoir fournir une plateforme plus simple à exploiter pour un maximum de développeurs. AMD avait alors précisé vouloir en faire un standard ouvert : publier une documentation complète avant la fin 2011 et mettre en place un consortium pour gérer la FSA.
AMD a pris du retard sur la documentation qui n'est toujours pas disponible, mais a entretemps renommé la FSA en Heterogeneous System Architecture de façon à la détacher de sa marque Fusion. Il y a quelques mois, AMD précisé ses plans au sujet du consortium qui se dénommerait HSA Foundation et se verrait transférer tous ses travaux initiaux.
Cette édition de l'AFDS est l'occasion pour AMD de concrétiser la mise en place de la HSA Foundation, qui est effective depuis quelques jours. Il s'agit d'une organisation à but non-lucratif qui sera dorénavant chargée du développement et de la promotion de ce standard ouvert destiné à simplifier le calcul hétérogène qu'il concerne les PC, les smartphones ou les serveurs. Sa tâche sera également de produire des outils de développements efficaces et d'aider à la formation des développeurs.


AMD transfère à cette fondation la totalité de ses travaux initiaux sur la FSA/HSA, à savoir : un compilateur open source, des librairies et les documentations préliminaires qui concernent la programmation, les spécifications hardware ainsi que les spécifications software. AMD fournis par ailleurs une partie des fonds pour la mise en place de la fondation.
La fondation est bien entendu destinée à accueillir un maximum de membres, qui pourront être de plusieurs types : fondateurs (ce qui est encore possible s'ils y sont invités dans les 90 jours), promoteurs, supporters, contributeurs, universitaires et autres associés. Comme c'est généralement de mise pour ce type d'organisation, chaque membre participe à son budget de fonctionnement suivant son rôle, ce qui représente jusqu'à 125.000$ par an pour les membres fondateurs.

Les représentants des cinq membres fondateurs de la HSA Foundation, qui forment son conseil d'administration actuel.
La mise en place de la HSA Foundation n'aurait pas pu se faire sans son élargissement à d'autres grands noms de l'industrie. La présence d'ARM à l'AFDS l'an passé ne laissait aucun doute sur l'intérêt de la société spécialisée dans les modules destinés au SoC, pour laquelle le calcul hétérogène est la seule solution viable sur le plan énergétique, et c'est donc sans surprise qu'ARM fait partie des membres fondateurs de la fondation. D'autres ont rejoint l'initiative et sont tous liés aux SoC d'une manière ou d'une autre : Imagination Technologies, MediaTek et Texas Instruments.
Chacune de ces sociétés disposera d'un membre au conseil d'administration de la fondation (Manju Hedge, Vice-Président des solutions développeurs destinées au calcul hétérogène chez AMD et ex-CEO d'Ageia; Jem Davies Vice-Président responsable de la division Media Processing chez ARM ) qui sera gérée au quotidien par Phil Rogers, Président de la HSA Foundation et AMD Corporate Fellow.
Reste bien entendu que d'autres grands noms sont malheureusement absents du tableau, tels que Nvidia et surtout Intel. Les membres fondateurs ne désespèrent pas à l'idée de les voir rejoindre l'initiative, sans cependant se faire d'illusion à ce sujet. Mais ce sont, avant tout autre chose, les développeurs qu'ils devront s'attacher à convaincre et pour cela, comme le rappelait Adobe présent également à l'AFDS, il faudra leur proposer des outils complets, performants, simples d'utilisation et fiables. Un gros chantier en perspective.
Vous pourrez retrouver toutes les informations disponibles actuellement sur le site de la HSA Foundation qui vient d'être mis en ligne mais la documentation complète se fait cependant toujours attendre.
GTC: Plus de détails sur le GK110
Lors d'une session technique sur l'architecture du GK110, nous avons pu apprendre quelques détails de plus à son sujet par rapport aux premières informations d'hier. Des détails bien entendu concentrés sur la partie compute de ce GPU. Tout d'abord, Nvidia propose cette fois un schéma de l'architecture qui montre sans ambiguïté que le GK110 est composé de 15 SMX de 192 unités de calcul, soit un total de 2880, et d'un bus mémoire de 384 bits.

On apprend par ailleurs que le cache L2 passe à 256 Ko par contrôleur mémoire 64 bits, soit un total de 1.5 Mo contre 768 Ko pour le GF1x0 et 512 Ko pour le GK104. Tout comme pour le GK104, chaque portion de cache L2 affiche une bande passante doublée par rapport à la génération Fermi.
Les blocs fondamentaux d'unités de calcul, appelés SMX dans la génération Kepler, sont similiaires pour le GK110 ceux du GK104 :

Le nombre d'unités de calcul simple précision est identique, tout comme le nombre d'unités dédiées aux fonctions spéciales, aux lectures/écritures, au texturing Les caches sont également identiques que ce soit les registres, le L1/mémoire partagée, les caches dédiés aux texturing.
La seule différence fondamentale réside dans la multiplication des unités de calcul en double précision qui passent de 8 pour le GK104 à 64 pour le GK110. Alors que le premier est 24x plus lent dans ce mode qu'en simple précision, le GK110 n'y sera que 3x plus lent. Couplé à l'augmentation du nombre de SMX, cela nous donne un GK110 capable de traiter 15x plus de ces instructions par cycle ! Par rapport au GF1x0 il s'agit d'un gain direct de 87.5% à fréquence égale.
Dans le GK110, tout comme dans le GK104, chaque SMX est alimenté par 4 schedulers, chacun capable d'émettre 2 instructions. Toutes les unités d'exécution ne sont cependant pas accessibles à tous les schedulers et un SMX est en pratique séparé en 2 parties symétriques à l'intérieur desquelles une paire de schedulers se partage les différentes unités. Chaque scheduler dispose de son propre lot de registres : 16384 registres de 32 bits (512 registres généraux de 32x32 bits en réalité). Par ailleurs chaque scheduler dispose d'un bloc dédié de 4 unités de texturing accompagnées d'un cache de 12 Ko.
Contrairement à ce à quoi nous nous attendions, l'ensemble cache L1 / mémoire partagée n'évolue pas dans le GK110 par rapport au GK104 et reste proportionnellement inférieur à ce qui était proposé sur la génération Fermi. Nvidia introduit par contre trois petites évolutions qui peuvent entraîner des gains importants :
Tout d'abord, chaque thread peut se voir attribuer jusqu'à 256 registres contre 64 auparavant. Quel intérêt quand le nombre de registres physiques n'augmente pas ? Il s'agit de donner plus de flexibilité au développeur et surtout au compilateur pour jongler entre le nombre de thread en vol et la quantité de registres allouée à chacun pour maximiser les performances. C'est particulièrement important dans le cas des calculs en double précision qui consomment le double de registres et qui étaient auparavant limités à 32 registres par thread. Passer à 128 permet des gains impressionnants dans certains cas selon Nvidia.

Ensuite, la seconde petite évolution consiste à autoriser l'accès direct aux caches dédiés au texturing. Auparavant il était possible d'en profiter manuellement en bricolant un accès à travers les unités de texturing, mais ce n'était pas pratique. Avec le GK110, ces caches de 12 Ko peuvent être exploités directement depuis les SMX mais uniquement dans le cas d'accès à des données en lecture seule. Ils ont l'avantage de disposer d'un accès royal au sous-système mémoire du GPU, de souffrir moins en cas de cache miss et de mieux supporter les accès non alignés. C'est le compilateur (via une directive) qui se charge d'y avoir recours lorsque c'est utile.
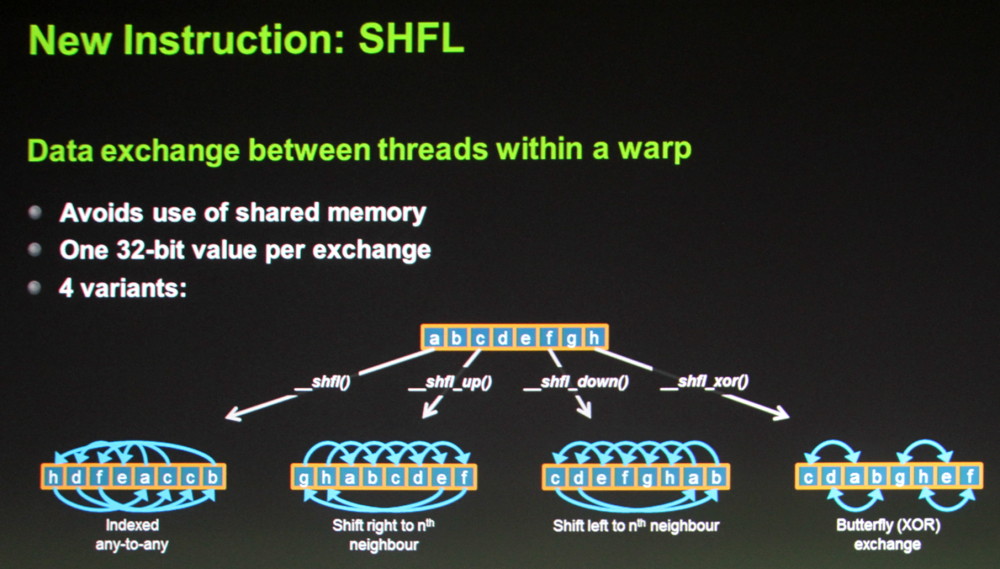
Enfin, une nouvelle instruction fait son apparition : SHFL. Elle permet un échange de donnée de 32 bits par thread à l'intérieur d'un warp (bloc de 32 threads). Son utilité est similaire à celle de la mémoire partagée et cette instruction vient donc en quelque sorte compenser sa quantité relativement faible, proportionnellement au nombre d'unités de calcul. Dans le cas d'un échange de données simple il sera donc possible d'une part de gagner du temps (un transfert direct à la place d'une écriture puis d'une lecture) et d'autre part d'économiser la mémoire partagée.
D'autres petits détails évoluent également tels que l'ajout des quelques instructions atomiques manquantes en 64 bits (min/max et opérations logiques) et une réduction de 66% du surcoût lié à la mémoire ECC.
Au final, avec la génération Kepler, Nvidia a bien pris une direction différente de celle de la génération Fermi. Le gros GPU Fermi, le GF100/110, disposait d'une organisation interne différente de celle des autres GPU de la famille, de manière à augmenter la logique de contrôle au détriment de la densité des unités de calcul et du rendement énergétique.
Avec le GK110, Nvidia n'a pas voulu faire de compromis sur ce dernier point ou plutôt devrions nous dire "n'a pas pu". Il s'agit dorénavant de faire un maximum dans une enveloppe thermique qui n'est plus extensible. C'est la raison pour laquelle le GK110 reprend la même organisation interne que celle du GK104, en dehors de la capacité de calcul en double précision qui a été revue nettement à la hausse.
Ainsi, Nvidia n'a pas cherché à complexifier son architecture pour soutenir les performances en GPU computing et s'est attaché à essayer de faire un maximum avec les ressources disponibles en se contentant d'évolutions mineures mais qui peuvent avoir un impact énorme. C'est également la raison pour laquelle le processeur de commandes a été revu pour permettre de maximiser l'utilisation du GPU avec les technologies Hyper-Q et Dynamic Parallelism que nous avons décrites brièvement hier et sur lesquelles nous reviendront dès que possible avec quelques détails de plus.
GTC: Tesla passe à Kepler avec les K10 et K20

Nvidia vient de dévoiler deux nouvelles cartes Tesla basées sur l'architecture Kepler. La première, dénommée K10 est en quelque sorte une version Tesla serveur de la GeForce GTX 690. Il s'agit donc d'une carte équipée de 2 GPU GK104 et d'un switch PCI Express 3.0 PLX. Par rapport à la GeForce GTX 690, les fréquences ont bien entendu été revues à la baisse et passent d'une fourchette de 915 à plus de 1100 Mhz (suivant le niveau de turbo) à 745 MHz pour le GPU et de 1500 à 1250 MHz pour la mémoire.
Nvidia semble ainsi avoir laissé de côté GPU Boost, probablement parce que la variabilité qui y est liée n'est pas compatible avec le monde professionnel. La base de la technologie, qui permet de contrôler dynamiquement la fréquence pour maintenir un certain TDP est par contre de toute évidence de la partie, ce qui permet à Nvidia de proposer un TDP relativement faible qui tourne autour de 225-235W, contre 300W pour la GeForce GTX 690.
La K10 est équipée de 4 Go de mémoire GDDR5 par GPU, soit 8 Go au total, et supporte l'ECC, d'une manière similaire à ce qui se fait sur les précédentes cartes Tesla : une partie de la mémoire est utilisée pour stocker les données de parité, ce qui réduit l'espace mémoire disponible ainsi que la bande passante pratique. La puissance de calcul en double précision reste par contre extrêmement faible, tout comme certaines opérations logique ou sur les entiers, le GPU GK104 étant très limité à ce niveau. En d'autres termes, la carte K10 affiche une puissance de calcul en simple précision flottante énorme, de 4577 Gflops et sera donc destinée à ce type de calculs uniquement. En double précision le débit tombe à 190 Gflops.
La seconde carte Kepler annoncée aujourd'hui, la K20 est la plus intéressante des deux puisqu'elle embarquera un GPU GK110 au sujet duquel Nvidia vient de donner les premières informations. Peu de détails sur la K20 sont communiqués à ce jour, ses spécifications ne seront fixées que plus tard dans l'année puisqu'elle est prévue pour le dernier trimestre 2012. Il est cependant probable qu'elle soit équipée d'un GK110 partiellement castré avec 13 blocs d'unités de calcul actifs sur les 15 disponibles pour un total de 2496 de ces unités de calcul. Nvidia indique par ailleurs que ses performances en double précision seront triplées par rapport à la génération actuelle et supérieures à 1 Tflops, ce qui en fera une carte bien plus polyvalente pour le calcul, d'autant plus que son GPU apporte plusieurs innovations importantes pour faciliter son exploitation avec un maximum d'efficacité.

La carte K20 devrait être accompagnée de 6 Go de mémoire GDDR5 et sera disponible avec un TDP de 225W, ce qui est plutôt impressionnant compte tenu de la complexité de ce GPU. Il est probable que Nvidia profite du fait qu'en général les blocs du GPU dédiés au graphique ne seront pas utilisés pour pouvoir compresser le TDP. Nvidia nous précise cependant que si un intégrateur dispose d'une plateforme certifiée pour un TDP plus élevé, la carte K20 pourra s'y adapter pour profiter de la marge supplémentaire. Elle sera par ailleurs disponible en version workstation en plus de la version serveur.
GTC: Nsight évolue, s'ouvre à Linux et Mac OS
Nvidia profite de la GTC pour dévoiler deux nouvelles versions de Nsight, son environnement de développement intégré (IDE) dédié autant au graphique qu'au GPU computing.
Tout d'abord Parallel Nsight est renommé en Nsight Visual Studio Edition et passe en version 2.2. Parmi les nouveautés, citons enfin le support de DirectX 9 (précédemment Nsight était limité à DirectX 10 et 11), le support de l'architecture Kepler, le débogage des kernels optimisés SASS/PTX (Source and ASSembly / Parallel Thread eXecution) et le débogage CUDA en local sur une machine équipée d'un seul GPU (qui est donc également en charge de l'affichage).
Ensuite Nvidia lance Nsight Eclipse Edition qui est destinée à la plateforme de développement ouverte du même nom, initiée par IBM il y a une dizaine d'années. De quoi permettre à Nsight d'être exploité sur Linux ou Mac OS et de faciliter l'utilisation du GPU computing sur ces systèmes d'exploitation.
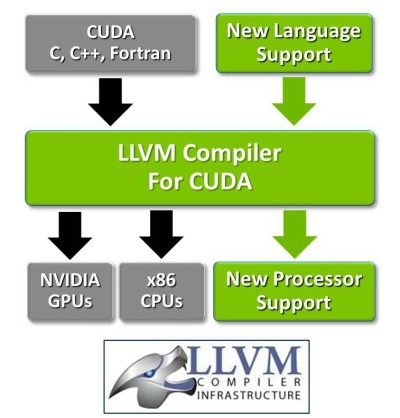
Si ses solutions propriétaires restent bien à l'ordre du jour, il est intéressant d'observer que Nvidia se tourne ainsi de plus en plus vers l'open source. Ainsi, dans le même courant, Nvidia a annoncé la semaine passée le support de l'architecture CUDA par LLVM, un compilateur open source modulaire très répandu qui permettra aux développeurs d'exploiter les GPU à travers de nombreux langages de programmation. Un support dont la mise en place a été facilitée par le remplacement, il y a quelques mois, de la base du compilateur CUDA de Nvidia (limité au C, C++ et Fortran) par des modules LLVM.