
Les contenus liés au tag PowerVR
Afficher sous forme de : Titre | FluxLes Cedar Trail mobiles repoussés ?
L'Atom Cedar Trail reste DirectX 9
Les Atom Cedar Trail passeront au PowerVR !
PowerVR Series 6
Imagination lance le PowerVR SGX545
GDC: GPU PowerVR Wizard avec ray tracing accéléré



Imagination Technologies profite de la Game Developer Conference de San Francisco pour faire une annonce qui pourra difficilement passer inaperçue dans le petit monde du rendu 3D temps-réel : la possibilité d'intégrer un module d'accélération matérielle du ray tracing dans ses GPU PowerVR mobiles !
Il y a 4 ans, certains ont pu se demander pourquoi Imagination Technologies avait mis la main sur Caustic Graphics, une petite startup californienne qui misait sur l'accélération matérielle du ray tracing. Nous avons dorénavant la réponse : intégrer sa technologie dans les GPU PowerVR.

Un exemple de rendu faisant appel au ray tracing PowerVR
Cette technologie issue de Caustic Graphics et dont le développement a été poursuivi par Imagination Technologies repose sur une API de bas niveau, OpenRL, développée sur la base du modèle d'OpenGL. Cette API peut être exploitée autant sans accélération matérielle qu'avec, notamment parce qu'elle gère d'une manière transparente pour le développeur les structures de données nécessaire au ray tracing. Des accélérateurs Caustic R2100 (500$) et R2500 (1000$) sont d'ailleurs commercialisés et peuvent être exploités pour réduire significativement le temps de rendu sous Maya ou mental ray.
Le cur de métier d'Imagination Technologies se situe dans la mobilité, notamment à travers ses GPU PowerVR commercialisés sous licence, et il peut paraître autant surprenant que logique d'y voir débarquer le ray tracing. Cette technique de rendu n'est-elle pas trop gourmande pour de petits SoC ? Oui et non. Imagination Technologies est très claire quant au but visé : le rendu hybride. Il ne s'agit pas de remplacer le rendu 3D classique (ou TBDR cher à la société) mais de l'améliorer ou de l'optimiser à travers quelques touches plus ou moins importantes de ray tracing.
Plusieurs cas pratiques sont présentés par Imagination Technologies, à commencer par l'éclairage précalculé dans des lightmaps, des "textures" qui sont ensuite appliquées sur les surfaces pour en représenter l'éclairage (avec illumination globale et occultation ambiante). Mettre en place un éclairage dynamique à base de lightmaps n'est pas simple, il est d'ailleurs en général statique, puisque cela revient à devoir les mettre à jour pour chaque image. Le ray tracing permet d'accélérer cette tâche et de la rendre réaliste pour du rendu en temps réel.
Un autre cas est un rendu hybride dans lequel le ray tracing n'est utilisé que pour certaines surfaces qui présentent de la transparence ou des réflexions. De quoi profiter des performances du rendu classique et de la finesse du ray tracing uniquement là où c'est jugé utile par les développeurs. De quoi également profiter d'optimisations énergétique en utilisant le ray tracing là où le rendu classique est peu efficace et demande des algorithmes lourds pour contourner ses limitations. Un rendu purement à base de ray tracing est possible mais en termes de performances, l'implémentation n'est pas prévue pour cela.

[ Rastérisation classique ] [ Rendu hybride avec ray tracing ]
Avec les futurs GPU PowerVR Wizard, Imagination Technologies vient en fait "simplement" greffer un module de ray tracing sur ses GPU actuels, de la série PowerVR Series6XT (nom de code Rogue, que nous avions abordé l'an passé sur base des premières déclinaisons). Le futur PowerVR GR6500 est ainsi identique à l'actuel PowerVR Series6XT GX6450 mais intègre l'unité de ray tracing (RTU). Cette unité spécialisée communique avec les unités de calcul principales du GPU (les "cores") mais Imagination Technologies ne précise comment le travail est réparti ni quel est le coût de la RTU. Nous pouvons cependant supposer au vu de l'usage mobile qui est visé, et donc de l'intégration dans un GPU lui-même intégré dans un SoC, que ce coût reste modéré.
Voici la description des blocs qui ont été ajoutés au GPU pour supporter l'accélération du ray tracing :
- a dedicated ray tracing data master that feeds ray intersection data to the main scheduler, in preparation for shaders to run, which evaluate the ultimate data contribution from the ray.
- a specialized Ray Tracing Unit (RTU) which uses fixed-function math to perform ray tracing intersection queries, in addition to gathering ray coherency in order to reduce power and bandwidth consumption.
- a scene hierarchy generator to speed up dynamic object updates.
- a frame accumulator cache that provides write-combining scattered access to the frame buffer.

A une fréquence de 600 MHz, la RTU et le GR6500 sont capables de lancer 300 millions de rayons par seconde qui pourront représenter jusqu'à 24 milliards de tests et 100 millions de triangles par seconde. A côté de cela nous retrouverons des unités de calcul capables de 150 Gflops (32-bit) ou de 300 Gflops (16-bit), mais il est probable qu'une partie de cette puissance de calcul soit monopolisée par le côté ray tracing du rendu. Notons qu'il est possible d'effectuer du ray tracing via le GPU computing sur la plupart des GPU, mais Imagination Technologies précise que son unité spécialisée est 100x plus rapide dans le cas du PowerVR GR6500.
Voici les détails publiés par la société :
- Full-blown graphics and compute performance: four Unified Shading Clusters (USCs), with 128 ALU cores delivering more than 150 GFLOPS (FP32) or 300 GFLOPS (FP16) at 600 MHzA noter que pour la première fois, Imagination Technologies n'est pas mentionné par Microsoft parmi les partenaires privilégiés pour le développement du futur DirectX. Par ailleurs, alors que pour la Series6 Rogue il était question d'un module DirectX 11 / Tessellation optionnel, il n'est plus mentionné dans le cas des GPU Wizard. Dans un sens, Imagination Technologies pourrait avoir sacrifié le support de toutes les fonctionnalités de DirectX 11/12 au profit du ray tracing.
- Unmatched real-world ray tracing performance: Up to 300 MRPS (million rays per second), 24 billion node tests per second and 100 million dynamic triangles per second at 600 MHz
- PowerGearing G6XT for advanced power management and dynamic resource allocation
- PVR3C triple compression technologies (PVRTC and ASTC for texture compression, PVRIC for frame buffer compression, PVRGC for geometry compression)
- Deep Color support for very high image quality at Ultra HD resolutions and beyond
- Support for a range of APIs such as OpenGL ES 3.1/2.0/1.1, OpenGL 3.x, Direct3D 11 Level 10_0, OpenCL 1.2, and OpenRL 1.x
Imagination Technologies ne commercialise pas directement ses GPU ou des SoC et il reste donc à voir si cette initiative trouvera preneur. Apple, l'un de ses plus gros clients, pourrait par exemple y voir l'opportunité de se démarquer de la concurrence. Dans l'immédiat, Unity vient d'annoncer supporter OpenRL et l'accélération du ray tracing PowerVR dans son moteur Unity 5.
Nous sommes actuellement en route pour la GDC et nous tâcherons d'essayer de voir le tout en action chez Imagination Technologies et/ou Unity que nous avons également prévu de rencontrer.
GDC: L'architecture PowerVR Series 6 Rogue
Dans une session dédiée à l'architecture PowerVR, Imagination a donné quelques détails sur l'architecture Series 6, nom de code Rogue, qui a été dévoilée il y a plus de deux ans et qui devrait très bientôt arriver dans différents SoC.
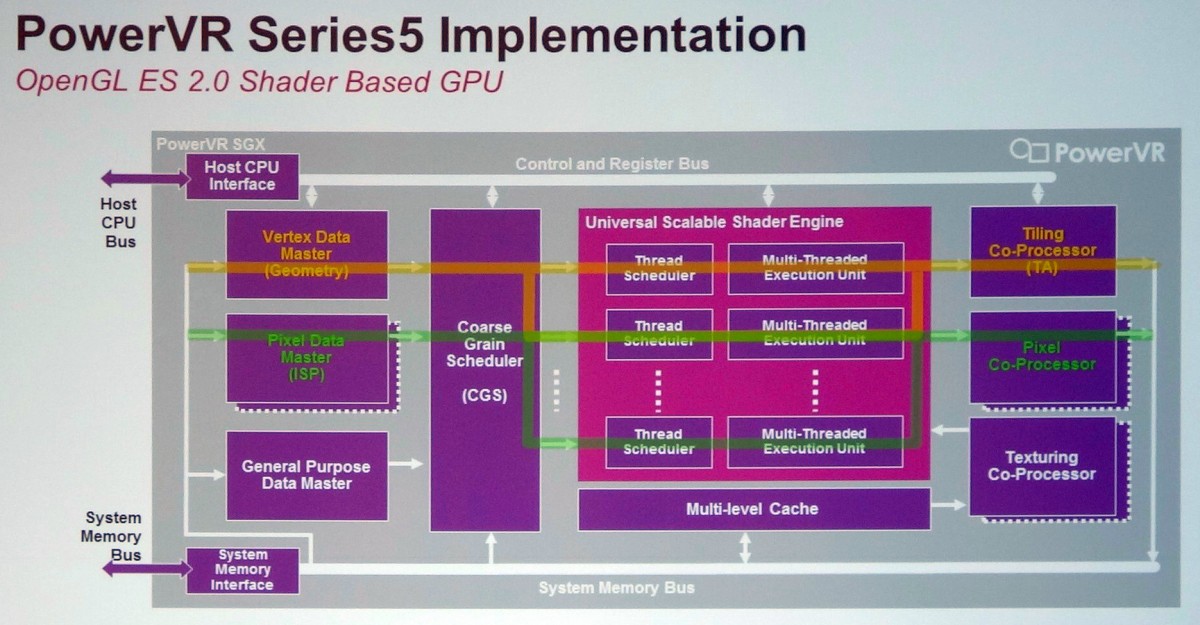
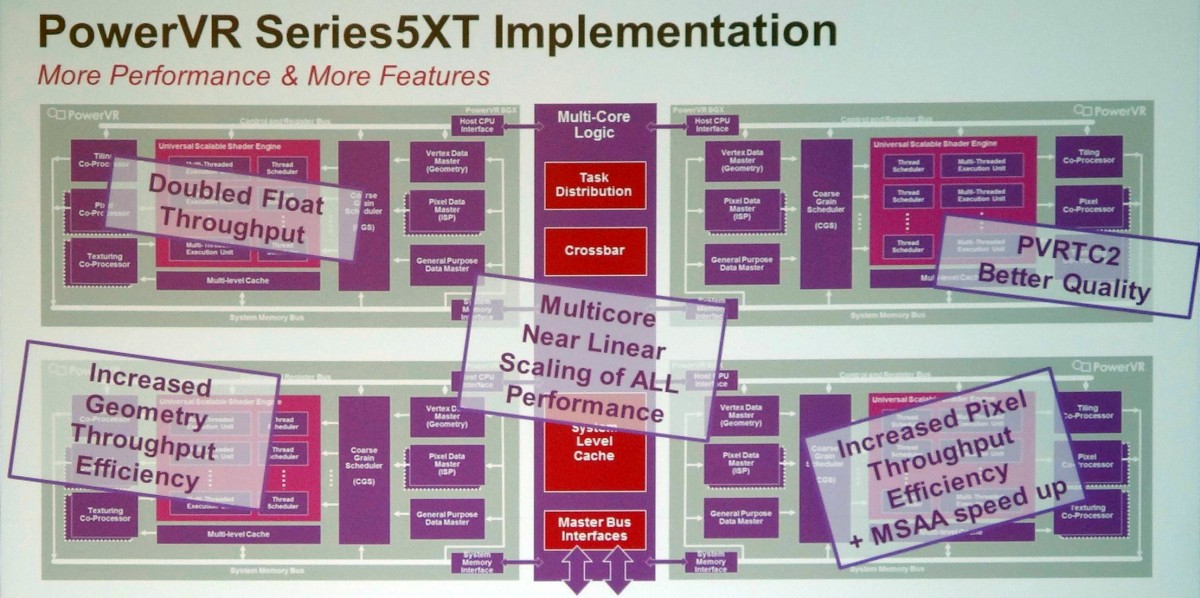
L'architecture PowerVR Series 5 est exploitée depuis de nombreuses années, par exemple dans les SoC Atom Intel ou dans l'A4 d'Apple. Elle a évolué il y a un peu plus de 3 ans pour passer en version Series 5XT avec le PowerVR SGX543 qui a doublé la puissance de calcul (elle passe de 8 à 16 MAD par cycle) et amélioré l'efficacité au niveau des débits de triangles et de pixels, notamment avec MSAA. Le support d'OpenCL a par ailleurs été introduit.
Par ailleurs, Imagination a introduit la possibilité d'avoir recours au multicore pour démulitplier la puissance des GPU PowerVR. L'ensemble du GPU SGX543 représente alors un core qui peut être dédoublé jusqu'à 8x, le tout étant piloté par un distributeur de tâche qui intègre un cache commun. Cette notion de core est donc ici assez proche d'un core CPU et n'a rien avoir avec la notion de core utilisée par Nvidia dans ses GPU, y compris Tegra. Comparer le GeForce ULP 72 cores du Tegra 4 au PowerVR SGX543MP4 "seulement 4 cores" est donc un non-sens, même si comme vous vous en doutez le côté commercial ne s'en prive pas.
Notez que le PowerVR SGX544 a ajouté le support de DirectX en niveau 9_3 alors que le PowerVR SGX554 a doublé une nouvelle fois la puissance de calcul qui passe à 32 MAD par cycle par core.
Avec l'architecture PowerVR Series 6, Imagination a dû faire face à la problématique de la consommation énergétique. Dédoubler les cores Series 5XT c'était "simple", mais les GPU finissaient alors par devenir trop gourmands. L'architecture a donc été revue pour devenir similaire à celle des GPU desktops modernes et pouvoir multiplier, à l'intérieur d'une structure fixe, des blocs (USC - Unified Shading Clusters) comprenant des unités de calcul et d'autres des unités de texturing. De quoi supprimer la redondance pour rendre le GPU plus compact et plus économe.
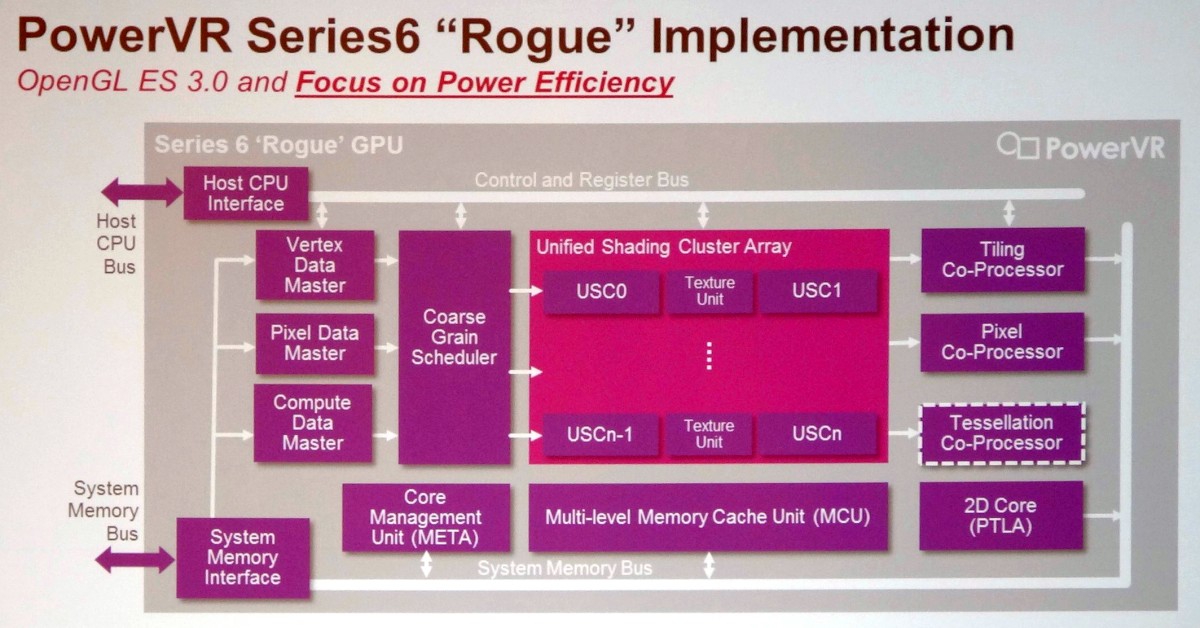
De nombreux petits raffinements ont été apportés à l'architecture, toujours dans le but de la rendre plus efficace. C'est le cas par exemple du passage à un fonctionnement perçu de type scalaire des unités de calcul (comme pour les GeForce 8+ et les Radeon HD 7000+) ou encore du support d'une compression lossless pour la géométrie et les pixels. Le support d'OpenGL 3.0 est complet et du côté DirectX on passe au niveau 10_0. Le support de DirectX 11_1 est par ailleurs possible, optionnellement, avec notamment l'ajout d'un tessellateur.
Parmi les détails, Imagination précise ceci :
- les unités de texturing ont gagné en performances lors d'accès dépendants
- le support de la basse précision lowp (FX10) a été abandonné, ne restent que le mediump (FP16) et le highp (FP32)
- les branchements dynamiques sont dorénavant traités par groupes de threads et peuvent être moins performants en cas de divergence, comme sur GPU desktop et contrairement aux Series 5
- lors de l'utilisation de MRT - Multiple Render Targets (écriture vers plusieurs buffers en une seule passe), il faut prendre garde à ne pas dépasser 128 bits par pixel, le maximum supporté pour profiter du buffer lié au tile rendering, ce qui se traduit grossièrement par "HDR + MSAA + MRT = pas bien"
Imagination prévoit actuellement 6 variantes, les PowerVR G6100, G6200 et G6400 ainsi que les PowerVR G6230, G6430 et G6630. D'après ce que communique Imagination, les G6x30 affichent des débits bruts similaires aux G6x00 mais avec quelques améliorations de l'architecture pour gagner en performances. S'il est possible que ces G6x30 soient compatibles avec le niveau 11_1 de DirectX, nous estimons plus probable que ce support ne soit prévu que pour une variante future.
Le second chiffre représente le nombre d'USC : 1 pour le G6100 jusqu'à 6 pour le G6630. Chaque paire d'USC, excepté pour le G6100 bien entendu, est associée à un bloc d'unités de texturing, mais Imagination ne précise pas le nombre d'unités de calcul (MAD) par USC. Il s'agira probablement de 32 unités de calcul par USC, avec, en terme de puissance brute et à fréquence égale, un G6100 qui serait équivalent à un SGX544MP2 et un G64x0 qui serait équivalent à un SGX554MP4.
Si ces GPU semblent prometteurs sur le papier, il faudra cependant patienter jusqu'à l'arrivée des premiers SoC qui les intégreront, et d'informations plus complètes, pour se faire une idée plus précise de leur niveau de performances.
Annoncé il y a plus de 2 ans, le Nova A9600 de ST-Ericsson devait être le premier SoC à intégrer un GPU PowerVR Series 6. Malheureusement le Nova A9600 a fait les frais du divorce entre STMicro et Ericsson.
GDC: Architecture GPU : IMR, TBR ou TBDR ?
Durant la GDC, il n'était pas question uniquement des GPU PC ou console : le monde du GPU mobile était également à l'honneur tant il se développe à une vitesse fulgurante. Compte tenu du nombre important d'acteurs à ce niveau, des contraintes fortes en terme d'efficacité énergétique et une bande passante mémoire très limitée, différents types d'architectures s'y côtoient, avec des compromis différents. L'occasion de faire le point entre les variantes IMR, TBR ou TBDR, en nous basant sur quelques slides récapitulatives proposées par Imagination.
Rappelons tout d'abord deux concepts :

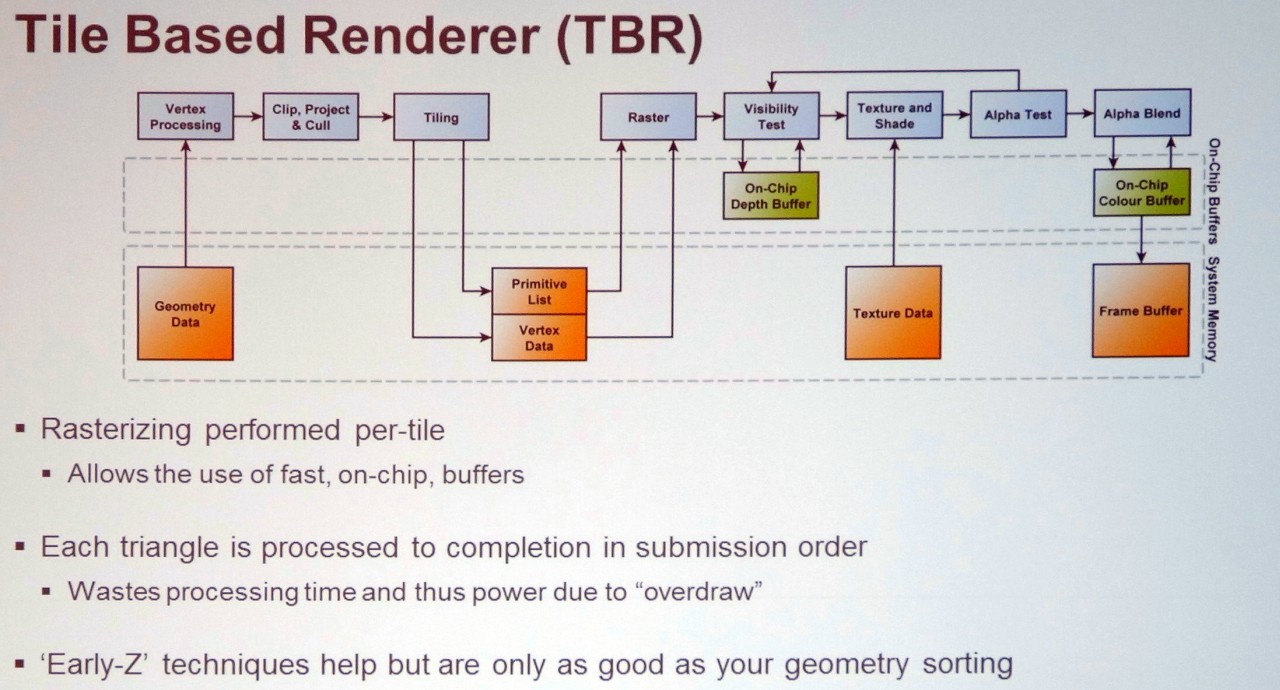
Le rendu basé sur des tiles (tuiles), également appelé binning, consiste à subdiviser le framebuffer en un ensemble de petites zones de l'image qui seront rendues les unes après les autres et qui peuvent tenir dans un petit cache interne au GPU. Cela a pour avantage d'éviter de passer par la mémoire externe et de gaspiller de la bande passante mémoire lors de l'écriture de pixels "temporaires". Imagination parle par exemple de tiles de 32x32 pixels, en précisant que la taille exacte est variable selon le GPU Power VR.
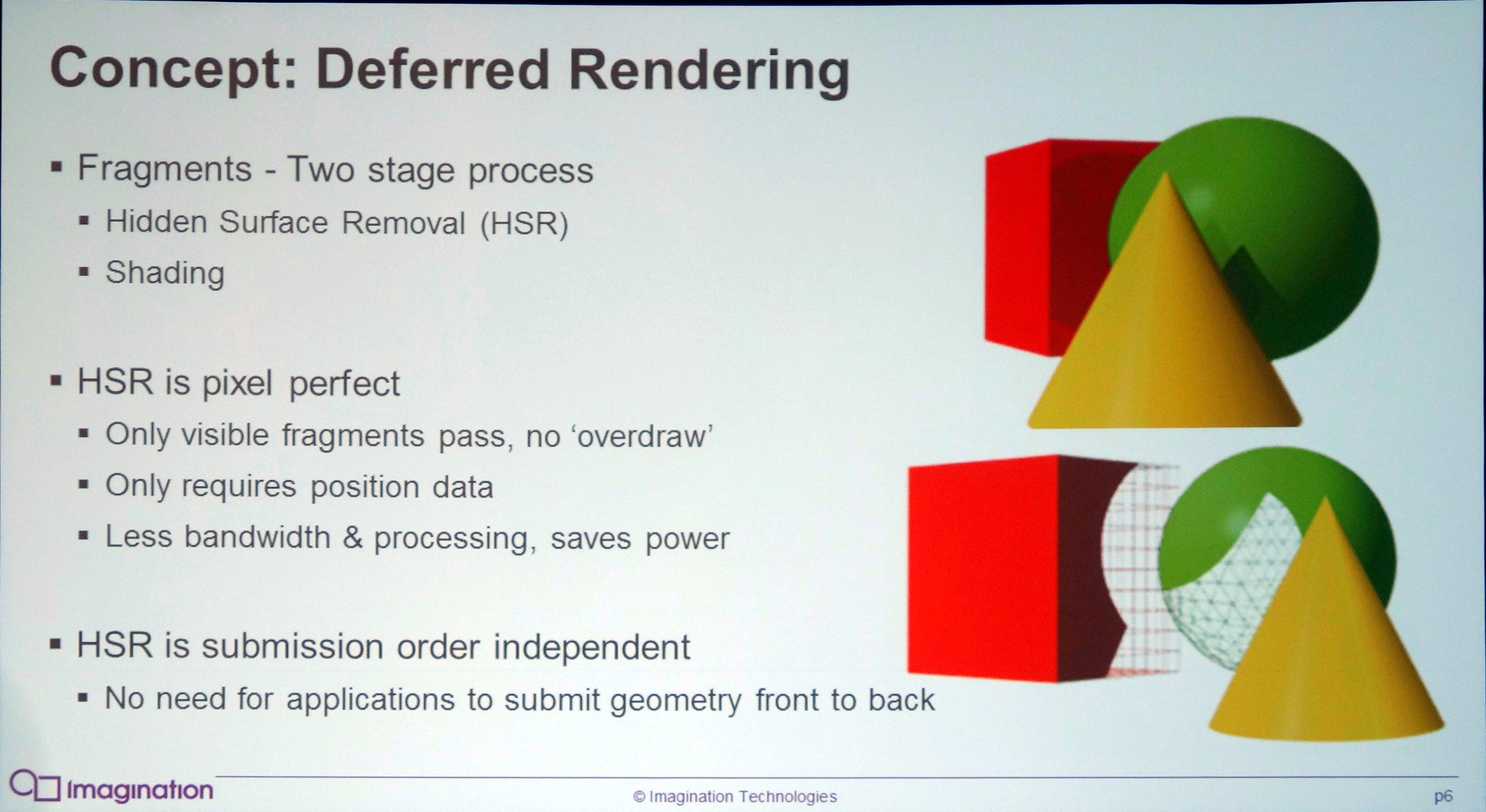
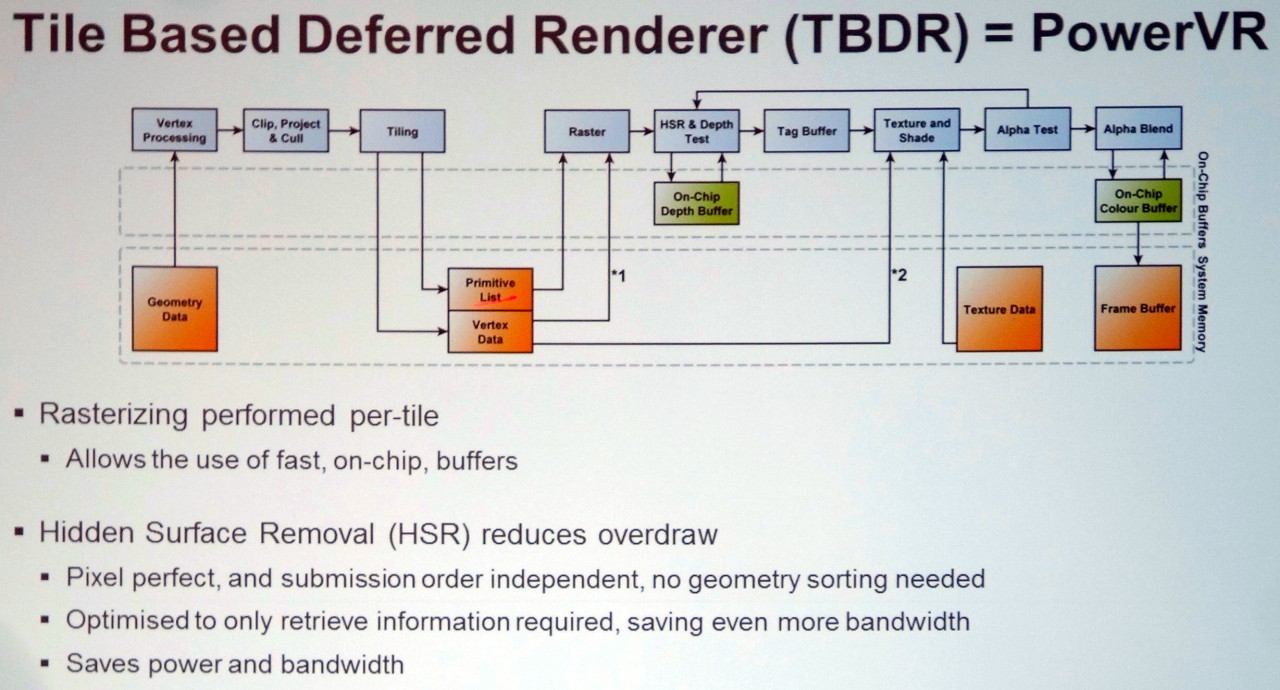
Le rendu différé permet de se baser sur une première passe dans laquelle la géométrie est passée en revue pour ne retenir qu'un seul pixel à finaliser par point de l'écran et ainsi réduire, voire supprimer, l'overdraw (le rendu de pixels masqués). Le rendu différé peut être implémenté de manière logicielle comme le font de nombreux moteurs graphiques pour ne calculer la partie complexe de l'éclairage qu'une fois par pixel. Il peut également être implémenté de façon matérielle en tant que technique de HSR (Hidden Surface Removal) pour permettre au GPU de déterminer l'unique pixel visible par point de l'écran.
Il existe trois grands groupes d'architectures GPU (notez qu'étant donné qu'il s'agit de slides d'Imagination, les points cités sur celles-ci se contentent de mettre en avant les avantages du TBDR maison) :
| [ IMR Immediate Mode Renderer ] [ TBR Tile Based Renderer ] [ TBDR Tile Based Deferred Renderer ] | Agrandir Agrandir Agrandir |
{kind=link}
{kind=link}
{kind=link}
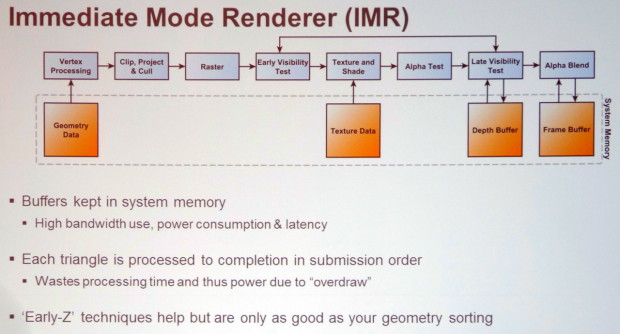
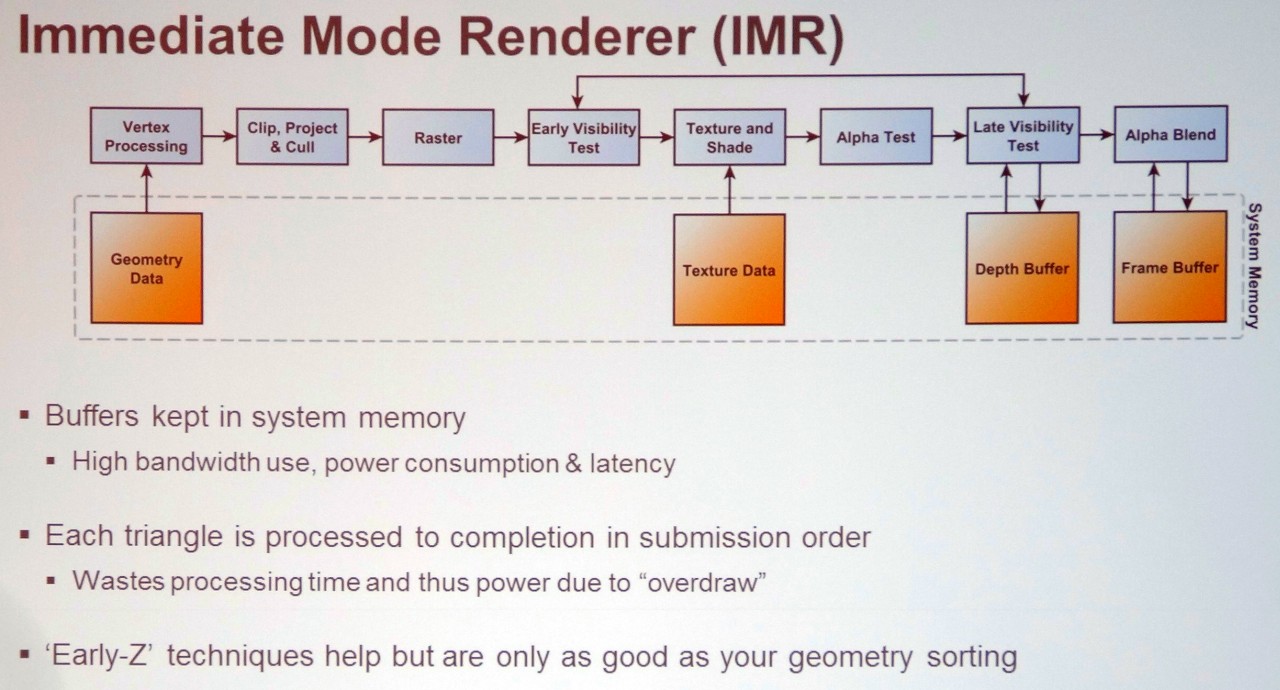
L'IMR ou le rendu immédiat représente l'approche "naturelle" du rendu sur base de primitives : la géométrie est transformée pour prendre place dans la scène, les triangles sont directement découpés en pixels les uns à la suite des autres, les pixels sont rendus et écris en mémoire. Cette approche est très flexible mais peut consommer beaucoup de bande passante mémoire et entraîner le calcul de pixels masqués quand un triangle caché par un autre est rendu avant celui-ci. Les GPU d'AMD, d'Intel et de Nvidia (y compris Tegra), ainsi qu'optionnellement les GPU Adreno de Qualcomm, exploitent l'IMR et disposent de nombreuses optimisations pour éviter de gaspiller trop de ressources.
Le TBR ou binning, soit le rendu tile par tile "simple", est exploité à des degrés divers par les GPU Mali d'ARM, Adreno de Qualcomm voire dans certains cas Xenos de la Xbox 360 et HD Graphics d'Intel. Pour être efficace et éviter de devoir traiter plusieurs fois la géométrie (pour chaque tile), cette approche doit être combinée à un rendu en deux étapes. La première consiste à passer en revue toute la géométrie et à écrire en mémoire la position de chaque primitive (triangles) après transformation ainsi qu'un lien vers toutes les tiles que chacune affecte. Le rendu classique peut ensuite se faire tile par tile, en ne traitant que les triangles qui s'y retrouvent et en ne gaspillant pas de bande passante mémoire externe, que ce soit pour écrire des pixels cachés ou pour des opérations de mélange lorsque des objets transparents sont rendus.
Dans certains cas, cette approche est cependant peu efficace, par exemple lorsque la géométrie est très complexe et représente autant, voire plus, de données à écrire en mémoire que ce qui est économisé au niveau des pixels. Par ailleurs, lorsque de petits triangles (qui peuvent être traités en un seul cycle) croisent plusieurs tiles, le rasterizer peut se retrouver débordé puisqu'il va devoir les traiter une fois pour chaque tile. Cette perte d'efficacité potentielle est la raison pour laquelle les GPU d'Intel et de Qualcomm supportent l'IMR en plus du TBR.
Le TBDR exploité par les GPU PowerVR ajoute au TBR le principe du rendu différé : se débarrasser de l'overdraw. Ainsi une technique de HSR (Hidden Surface Removal) hardware basée sur un lancer de rayon permet pour chaque pixel de retrouver le triangle visible au milieu de l'ensemble de la géométrie liée à la zone de rendu, ce qui est bien entendu facilité par le rendu par tile. Notez que le TBDR peut perdre d'avantage en efficacité que le TBR quand la géométrie devient très complexe puisque le moteur de HSR va avoir plus de mal à déterminer les triangles visibles et potentiellement devenir le facteur limitant.
Par contre, en plus de n'écrire en mémoire externe qu'un seul pixel par point de l'écran, seulement un pixel est calculé par les GPU de type TBDR, ce qui permet des économies supplémentaires au niveau de la puissance de calcul et de texturing. Notez qu'en contrepartie, certaines techniques de rendu demandent des adaptations particulières, qui peuvent avoir un coût, pour fonctionner sur ce type d'architecture : c'est le cas de certains effets de transparences ou qui modifient la profondeur effective du pixel après le traitement géométrique (bump mapping avancé par exemple).
Chaque approche a donc des avantages et des désavantages. Comme pour tout ce qui concerne le rendu 3D temps réel en général, il s'agit toujours d'un compromis. En dehors de Nvidia, il semble cependant y avoir un consensus dans le monde mobile en faveur de l'utilisation de tiles, tout du moins optionnellement, pour économiser autant que possible la bande passante mémoire et l'énergie qui y est liée, quitte à complexifier l'architecture du GPU.
GDC: AMD, Intel, Nvidia, Qualcomm... à la GDC
Lors de la GDC, dont l'édition 2013 s'est terminée vendredi dernier à San Francisco, les plus importants fournisseurs de technologies graphiques (les GPU Radeon, Mali, PowerVR, HD Graphics, GeForce, Adreno) étaient présents avec notamment pour but de convaincre les développeurs de jeux vidéo d'exploiter toutes les possibilités de leurs produits récents à travers des techniques de rendu toujours plus évoluées que ce soit sur PC ou dans le monde mobile, qui progresse à vive allure.






En plus de diverses présentations, AMD, ARM, Imagination, Intel, Nvidia et Qualcomm étaient présents à travers des stands principalement exploités pour mettre en avant leurs outils maisons : AMD GPU PerfStudio, ARM Mali Graphics Debugger, Imagination PVRTune, Intel Graphics Performance Analyzers, Nvidia Nsight, Qualcomm Adreno Profiler
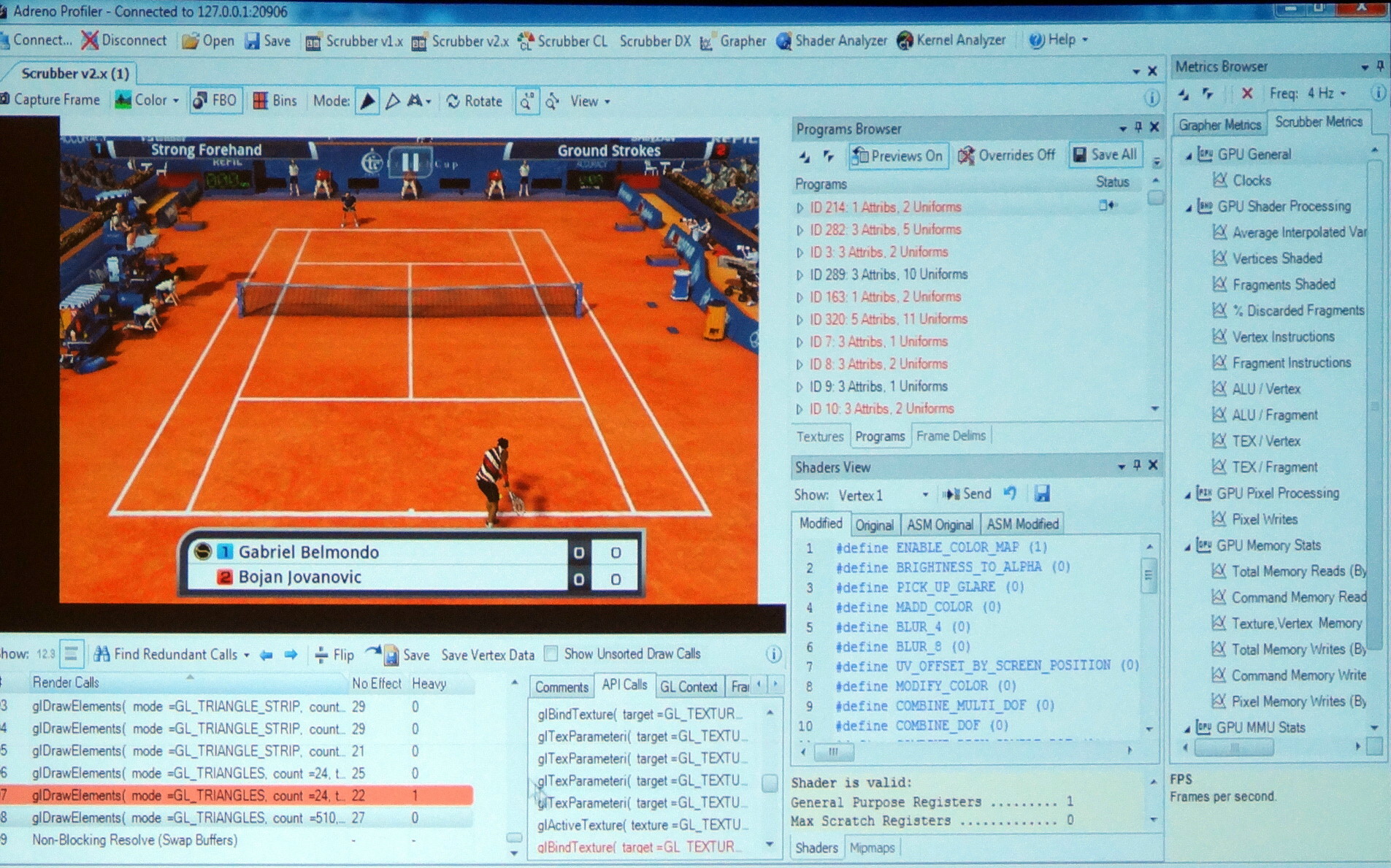
Ici en exemple, l'Adreno Profiler de Qualcomm qui permet d'observer assez facilement le comportement des GPU Adreno et d'appliquer des modifications à la volée pour identifier des bugs ou des goulots d'étranglement (bottlenecks). Il est ainsi possible de modifier un shader, de désactiver la synchronisation verticale, de réduire la taille de toutes les textures, etc., et d'observer l'impact en temps réel sur le smartphone ou sur la tablette.
Les outils de tous les acteurs cités proposent des possibilités similaires, chacun ayant des petits avantages ou inconvénients par rapport à la concurrence. Ils sont en général autant adapté au débogage et à l'optimisation de la partie graphique que de la partie "compute" éventuellement exposée pour les GPU.
Lors de plusieurs rencontres avec des développeurs, nous avons voulu savoir quels outils ils préféraient et pourquoi. La réponse de nos interlocuteurs a été unanime : aucun ! Pourquoi ? Tout simplement parce que la multiplication de ces outils devient problématique et que peu importe leurs qualités ou leurs défauts, devoir utiliser un outil spécifique à chaque marque de GPU est tout sauf pratique, d'autant plus quand il faut en supporter bon nombre comme c'est le cas sous Android.

Même avec seulement 3 acteurs, c'est un problème dans le monde PC comme le rappelle Crytek en parlant des opportunités et défis à venir. Il serait ainsi intéressant que Microsoft et Google proposent des outils de développement plus évolués qu'actuellement et dans lesquels les concepteurs de GPU pourraient venir s'interfacer pour proposer autant de détails que dans leurs propres outils mais d'une manière plus ou moins unifiée.
Notez au passage que Crytek en profite pour rappeler à Microsoft qu'il serait peut-être bon de travailler sur la documentation de DirectX !
Intel lance les Atom Clover Trail+ Z2500
Intel profite de MWC qui se tient actuellement à Barcelone pour lancer des nouveaux Atom destinés à renforcer sa présence dans le monde des smartphones. Jusqu'ici, Intel devait se contenter de la plateforme Medfield et du SoC simple core Penwell (Atom Z2460, Z2420), la plateforme Clover Trail et le SoC dual core Cloverview (Atom Z2760) étant un peu plus gourmands et réservés aux tablettes.
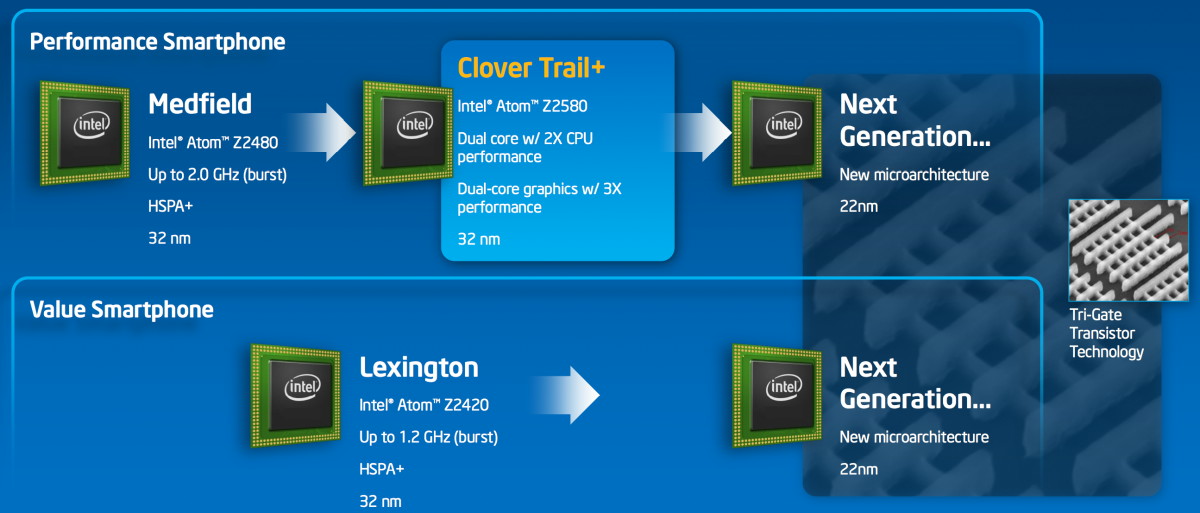
La plateforme Clover Trail+ et le SoC Cloverview+ apportent enfin à Intel une solution dual core pour smartphones. Bien que très proches sur certains points de Cloverview, sa version "+" est bel et bien un SoC différent, notamment équipé d'un GPU plus costaud, tout en étant mieux optimisé pour une faible consommation : le PowerVR SGX544MP2.
Il s'agit d'une nette évolution par rapport au GPU PowerVR SGX540 de l'Atom Z2460, d'une part sur le plan des performances brutes qui sont plus que quadruplées et d'autre part sur le plan des fonctionnalités. Ainsi, le PowerVR SGX540 ne supporte pas du tout les API graphiques "desktop" présentes sous Windows et est donc réservé à Android alors qu'en plus d'OpenGL ES 2.0, le PowerSGX544MP2 supporte le niveau 9_3 de DirectX et OpenGL 2.1. La résolution maximale supporté évolue par ailleurs du 1024x768 au 1080p. Par rapport au PowerVR SGX545 de l'Atom Z2760, il fait l'impasse sur le support du niveau 10_1 de DirectX, qui n'avait cependant jamais abouti dans les pilotes Intel.
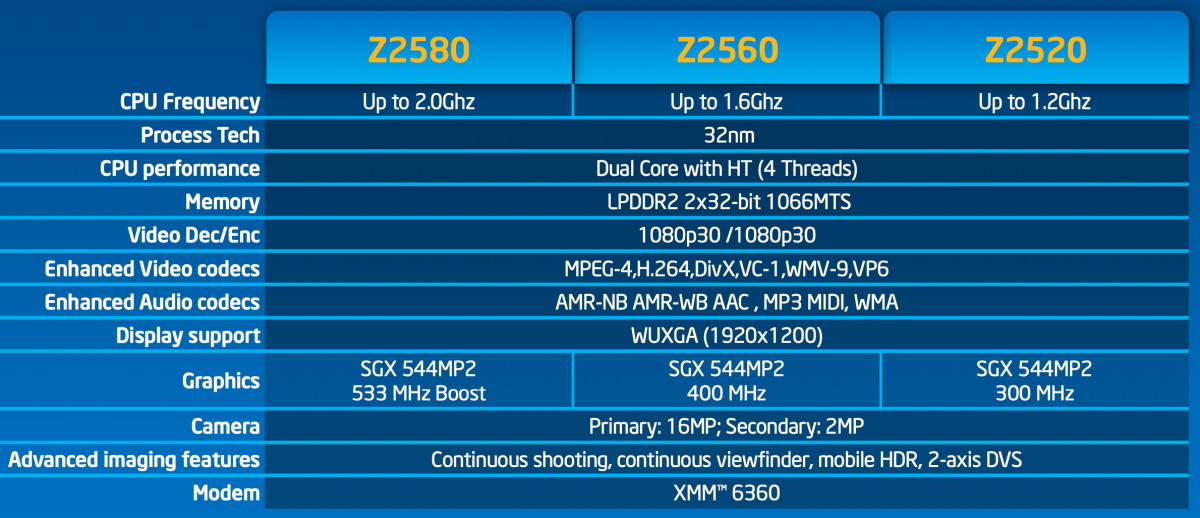
Intel a prévu 3 Atom Clover Trail+ qui se différencieront au niveau de leurs performances et de leur consommation :
Atom Z2580 : 2 coeurs avec HT à 933 MHz et turbo à 2 GHz, GPU à 533 MHz
Atom Z2560 : 2 coeurs avec HT à 933 MHz et turbo à 1.6 GHz, GPU à 400 MHz
Atom Z2520 : 2 coeurs avec HT à 933 MHz et turbo à 1.2 GHz, GPU à 300 MHz
Lenovo sera le premier fabricant à exploiter commercialement Clover Trail+ avec l'IdeaPhone K900 mais Intel indique avoir également convaincu Asus et ZTE pour certains de leurs futurs produits, en précisant que, compte tenu du support du 1080p, ces nouveaux SoC se retrouveraient également dans des tablettes.
Précisons que ces nouveaux Atom restent fabriqués en 32 nm et qu'il faudra attendre la fin de l'année pour voir enfin débarquer un nouveau core Atom, Silvermont, fabriqué en 22 nm. Plus performant, il sera associé à un GPU PowerVR série 6 dans les SoC dualcore Tangier (plateforme Merrifield) et quadcore Valleyview (plateforme Bay Trail), avant de débarquer dans un premier SoC Intel qui intégrera directement un modem.