
La GTC16 de Nvidia en direct de San José

GTC: Nvidia DGX-1: 8 Tesla P100 pour 129.000$
GTC: N'attendez pas de GeForce en GP100 !
GTC: Nvidia Tesla P100: 10 Tflops, HBM2...
GTC: Deep-learning : +70% pour Pascal
GTC: Multi-Res Shading, pas que pour la VR ?
GTC: La VR pour les pros et les Quadro
GTC: Nvidia annonce CUDA 8, prêt pour Pascal
GTC: 200 mm² pour le petit GPU Pascal ?
GTC: Supermicro premier sur le Tesla P100 ?
GTC: Tesla P100: débits PCIe et NVLink mesurés
GTC: La VR pour les pros et les Quadro



Si la GTC qui se tenait au début du mois s'est focalisée sur Pascal et le GPU computing, la réalité virtuelle était également mise à l'honneur. Il ne s'agissait cependant pas de jeu vidéo mais bien d'utilisation professionnelle de ce type d'affichage sur lequel misent de nombreux acteurs de l'industrie, dont Nvidia fait bien entendu partie.

Dans le monde professionnel, les possibilités sont nombreuses pour la réalité virtuelle. L'exemple le plus courant, et qui commence petit à petit à être réellement exploité dans le domaine commercial, concerne la prévisualisation par l'acheteur d'un élément qui peut être personnalisé. Que ce soit pour parcourir l'intérieur d'une nouvelle construction ou pour s'assurer de se sentir bien dans le cuir amarante clair de sa nouvelle voiture, la réalité virtuelle apporte un avantage indéniable par rapport à un écran classique.
Nvidia exploite d'ailleurs directement cette approche pour peaufiner ses nouveaux bureaux actuellement en construction et proposera dès le mois de juin Iray VR, une version adaptée à la VR de son moteur de rendu interactif photoréaliste.


Nous avons d'ailleurs pu tester une autre démonstration à base d'Iray VR qui permet cette fois de suivre les avancements du chantier jour par jour et de positionner le regard à n'importe quel niveau. Une maquette virtuelle et dynamique que l'on peut "prendre en main" et observer dans tous les sens.
Il existe cependant d'autres types d'usages, peut-être plus utiles, et le plus convaincant que nous ayons pu tester est probablement issu d'une démonstration dont nous n'avons malheureusement pas pu prendre de photo, à priori faute de droits sur le modèle. Pour cette démonstration, Nvidia exploite un modèle extrêmement détaillé d'une voiture Nissan : plusieurs dizaines de millions de triangles représentent la moindre vis de la voiture, aucun élément n'est texturé, même les surpiqures des sièges sont rendues à base de géométrie.
Outre l'aspect impressionnant de la prise en charge d'un modèle aussi complexe, c'est l'usage qui en est fait en réalité virtuelle qui est intéressant. Il est possible de prendre place à l'intérieur de la voiture bien entendu, mais surtout d'observer la moindre de ses pièces à n'importe quelle étape de sa construction. Et pouvoir le faire en se déplaçant simplement dans un environnement virtuel fait tout la différence par exemple pour comprendre rapidement comment remplacer une pièce cachée, à l'accès difficile. Un outil qui pourrait être précieux autant pour les professionnels que pour les amateurs.
Toujours dans le domaine de la réparation mais cette fois humaine, une des conférences à laquelle nous avons pu assister était présentée par le docteur Neil Martin, professeur et neurochirurgien à l'hôpital de l'UCLA. Il développe et exploite déjà la réalité virtuelle dans le cadre des phases préparatoires aux opérations, mais également au niveau de l'apprentissage des futurs neurochirurgiens. Voici à quoi cela ressemble :
A l'avenir le docteur Martin envisage d'aller plus loin en faisant entrer la réalité augmentée dans les salles opératoires pour avoir accès en direct à toutes sortes d'informations supplémentaires, mais nous n'en sommes pas encore là. Dans l'immédiat, la réalité virtuelle est uniquement utilisée pour améliorer et accélérer la perception de l'environnement dans lequel l'opération va avoir lieu et selon le praticien cela apporterait déjà des bénéfices tangibles par rapport à une visualisation en 3D sur un écran classique.
En fait, ces exemples d'utilisation de la VR dans le domaine professionnel ont la particularité de ne rien autoriser de nouveau. Ils permettent par contre de mieux profiter des rendus 3D que les systèmes d'affichage classiques mais comme pour tout ce qui touche à la VR, il faut enfiler un casque avec système de positionnement pour comprendre leur intérêt.
Plusieurs analystes estiment d'ailleurs que dans un premier temps, les plus gros débouchés pour les casques de VR vont prendre place dans le monde professionnel, que ce soit par effet de mode pour attirer le chaland ou par gain d'efficacité. Un déploiement qui aura besoin de solutions clés en main, certifiées. C'est là qu'interviennent Nvidia et ses partenaires qui vont proposer les systèmes complets, avec un marché qui pourrait être intéressant pour les Quadro ou à défaut pour les cartes graphiques haut de gamme.

Sur base des spécifications demandées par Oculus et HTC, qui conseillent au moins une GeForce GTX 970 ou une Radeon R9 290, Nvidia a fait passer son programme VR Ready dans la gamme Quadro. Sont ainsi certifiées pour la VR les Quadro M6000, M5000 et M5500 mobile accompagnées au minimum d'un Core i5-4590 ou d'un Xeon E3-1240 v3. Contrairement à AMD avec la Radeon Pro Duo, Nvidia n'a cependant pas l'intention pour l'instant de proposer une nouvelle carte bi-GPU pour aller un peu plus loin en termes de performances.

A noter que la VR n'existe pas qu'à travers les casques ou HMD (head mounted devices) et contrairement aux GeForce, les Quadro certifiées pour la VR profitent de quelques API supplémentaires prévues pour la VR de type CAVE (cave automatic virtual environment). Ces CAVE sont de petites pièces dont chaque face est un écran, en général de type projection arrière. De quoi placer le ou les spectateurs au centre de la représentation 3D, avec des usages quelque peu différent d'un casque de VR. Ce n'est pas toujours le cas, mais pour parfaire la simulation, le rendu peut être de type stéréoscopique.
Les API Warp & Blend, Synchronisation, GPU Affinity et GPUDirect for Video sont proposées par Nvidia pour déformer, mélanger et synchroniser les différentes images qui vont devoir former un environnement uniforme ainsi qui pour y incruster des vidéos. Ces API sont disponibles pour les développeurs enregistrés auprès de Nvidia à travers le SDK VRWorks for Quadro (anciennement appelé DesignWorks VR).
GTC: Nvidia annonce CUDA 8, prêt pour Pascal
Comme souvent, l'arrivée d'une nouvelle architecture est associée à une révision majeure de CUDA, l'environnement logiciel de Nvidia destiné au calcul massivement parallèle. Ce sera évidemment le cas pour les GPU Pascal qui pourront profiter dès cet été d'un CUDA 8 taillé sur mesure. Au menu : un support plus évolué de la mémoire unifiée, un profilage plus efficace et un compilateur plus rapide.

La principale nouveauté de CUDA 8 sera le support complet de l'architecture Pascal et particulièrement du GP100 qui équipe l'accélérateur Tesla P100. Déjà introduit avec CUDA 7.5 pour permettre aux développeurs de s'y préparer, le support de la demi-précision (FP16) sera finalisé et pourra permettre des gains conséquents pour les algorithmes qui peuvent s'en contenter. Dans le cas du GP100, CUDA 8 ajoutera évidemment le pilotage des accès mémoire à travers les liens NVLink.
La plus grosse évolution est cependant à chercher du côté de la mémoire unifiée qui va faire un bond en avant avec Pascal, ou tout du moins avec le GP100 puisque nous ne sommes pas certains que les autres GPU Pascal en proposeront un même niveau de support. Si vous avez l'impression qu'on vous a annoncé le support de cette mémoire unifiée avec chaque nouveau GPU, ne vous inquiétez pas, vous n'avez pas rêvé, nous avons la même impression.
Elle est en fait supportée depuis CUDA 6 pour les GPU Kepler et Maxwell mais de façon limitée, que nous pourrions qualifier d'émulée. Pour ces GPU, l'espace de mémoire unifié est en fait dédoublé dans la mémoire centrale et dans la mémoire physiquement associée au GPU. L'ensemble logiciel CUDA se charge de piloter et de synchroniser ces deux espaces mémoires pour qu'ils n'en représentent qu'un seul du point de vue du développeur. De quoi faciliter sa tâche mais au prix de sérieuses limitations : la zone de mémoire unifiée ne peut dépasser la quantité de mémoire rattachée au GPU, le CPU et le GPU ne peuvent y accéder simultanément et de nombreuses synchronisations systématiques sont nécessaires pour forcer la cohérence entre les copies CPU et GPU de cette mémoire.
Pour proposer un support plus avancé de la mémoire unifiée, des modifications matérielles étaient nécessaires au niveau du GPU, ce qui explique pourquoi nous estimons possible que cela soit spécifique au GP100. Tout d'abord l'extension de l'espace mémoire adressable à 49-bit pour permettre de couvrir l'espace de 48-bit des CPU ainsi que la mémoire propre à chaque GPU du système. Ensuite la prise en charge des erreurs de page qui permet d'éviter les coûteuses synchronisations systématiques. Si un kernel essaye d'accéder à une page qui ne réside pas dans la mémoire physique du GPU, il va produire une erreur qui va permettre suivant les cas soit de rapatrier localement la page en question, soit d'y accéder directement à travers le bus PCI Express ou un lien NVLink.
La cohérence peut ainsi être garantie automatiquement, ce qui permet aux CPU et aux GPU d'accéder simultanément à la zone de mémoire unifiée. Sur certaines plateformes, la mémoire allouée par l'allocateur de l'OS sera par défaut de la mémoire unifiée, et il ne sera plus nécessaire d'allouer une zone mémoire spécifique. Nvidia indique travailler à l'intégration de ce support avec Red Hat et la communauté Linux. Par ailleurs, CUDA 8 étend également le support de la mémoire unifiée à Mac OS X.

Ce support plus avancé de la mémoire unifiée va faciliter le travail des développeurs et surtout rendre plus abordable leurs premiers pas sur les GPU tout en maintenant un relativement bon niveau de performances. Tout du moins si le pilote et le runtime CUDA font leur travail correctement puisque c'est à ce niveau que tout va se jouer. A noter que les développeurs plus expérimentés conservent la possibilité de gérer explicitement la mémoire.
Parmi les autres nouveautés, Nvidia introduit une première version de la librairie nvGRAPH (limitée au mono GPU) qui fournit des routines destinées à accélérer certains algorithmes spécifiques au traitement des graphes. Traiter rapidement les opérations sur ces structures mathématique prend de plus en plus d'importance, que ce soit pour les moteurs de recherche, la publicité ciblée, l'analyse des réseaux ou encore la génomique. Faciliter l'exécution de ces opérations sur le GPU est donc important pour leur ouvrir la porte à de nouveaux marchés potentiels.
Une autre évolution importante est à chercher du côté des outils de profilages qui vont dorénavant fournir une analyse des dépendances. De quoi par exemple permettre de mieux détecter que les performances sont limitées par un kernel qui bloque le CPU trop longtemps. Ces outils revus prennent également en compte NVLink et la bande passante utilisée à ce niveau.
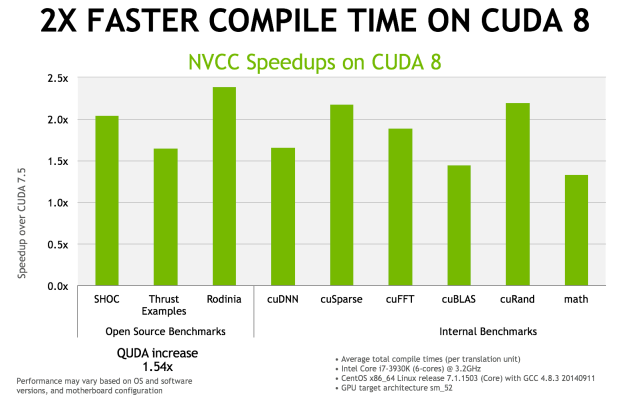
Enfin, le compilateur NVCC 8.0 a reçu de nombreuses optimisations pour réduire le temps de compilation. Nvidia annonce qu'il serait réduit de moitié, voire plus, dans de nombreux cas. Ce compilateur étend également le support expérimental des expressions lambda de C++11.
La sortie de CUDA 8.0 est prévue pour le mois d'août mais une release candidate devrait être proposée dès le mois de juin.
GTC: 200 mm² pour le petit GPU Pascal ?
Il y 3 mois, lors du CES, Jen-Hsun Huang avait présenté le Drive PX 2, le nouveau boîtier dédié à la conduite autonome de Nvidia qui embarque entre autre deux GPU Pascal. Seul petit problème c'est alors un prototype équipé de GM204 Maxwell et non de GPU Pascal qu'avait présenté Jen-Hsun Huang, en oubliant de préciser ce détail, ce qui n'avait pas manqué de susciter la polémique.

Le CEO de Nvidia a profité de la GTC pour rectifier cela en affichant cette fois le "vrai" Drive PX 2 équipé des nouvelles puces Pascal. Le module était ensuite visible dans la zone d'exposition de la GTC mais Nvidia avait malheureusement pris soin de le positionner de manière à ce que les GPU ne soient pas clairement visibles. Nous pouvions cependant les apercevoir suffisamment pour obtenir un second angle de vue pour confirmer la taille de la puce.


Sur la photo où Jen-Hsun Huang présente le Drive PX 2, nous mesurons à peu près 200 mm², alors que sur les autres photos nous sommes plutôt à 205 mm². Suffisamment proche pour pouvoir estimer la taille de ce GPU Pascal (GP106 ?) à +/- 200 mm² en 16nm.
Les spécifications de ce GPU ne sont pas encore connues, tout ce que nous savons est qu'il atteint 4 TFlops dans la configuration qui a été retenue pour le Drive PX 2 et qu'il semble équipé d'un bus mémoire de 128-bit vu la bande passante annoncée de 80 Go /s et malgré la présence de 8 puces 32 bits. De quoi imaginer par exemple un plus gros GPU Pascal grand public (GP102 ? GP104 ?) qui pourrait doubler tout cela. 350 à 400 mm² en 16nm, 8 TFlops et un bus mémoire GDDR5X 256-bit pourrait correspondre à ce que nous prépare Nvidia.
GTC: Supermicro premier sur le Tesla P100 ?
Supermicro exposait à la GTC un prototype non fonctionnel de serveur 1U à base de Tesla P100. Celui-ci est prévu pour embarquer 4 de ces accélérateurs ainsi qu'une configuration bi-Xeon et une carte graphique ou un autre accélérateur au format PCI Express 16x. Le fabricant taiwanais explique que le nouveau format de type mezzanine et les liens NVLink ont demandé pas mal de travail lors de la conception du serveur.

C'est notamment le cas au niveau du refroidissement qui est un challenge évident compte tenu de la consommation qui monte à 300W par Tesla P100 alors que la densité progresse compte tenu de la compacité de cette solution. Supermicro a ainsi décidé de placer ces 4 accélérateurs, surmontés d'imposants radiateurs, côte à côte juste après l'entrée d'air frais, ce qui permet de les refroidir tous de la même manière.

Supermicro précise que certains concurrents ont opté pour une autre organisation, avec par exemple un "carré" de Tesla P100, et que d'après ses essais, il y a beaucoup de risques que les GPU les plus éloignés de l'entrée d'air en souffrent, par exemple en atteignant plus rapidement leur limite de température.
Malgré l'état de la solution exposée, Supermicro nous a confirmé être très proche de la finalisation de ce serveur et s'attendre à être le premier sur le marché, tout du moins si Nvidia ne tarde pas à livrer les Tesla P100.
GTC: Tesla P100: débits PCIe et NVLink mesurés
Lors d'une session de la GTC consacrée à GPUDirect, qui regroupe les techniques de communications entre GPU et avec d'autres éléments d'un système, nous avons pu en apprendre un peu plus sur les performances du GP100 au niveau de ses voies de communication.
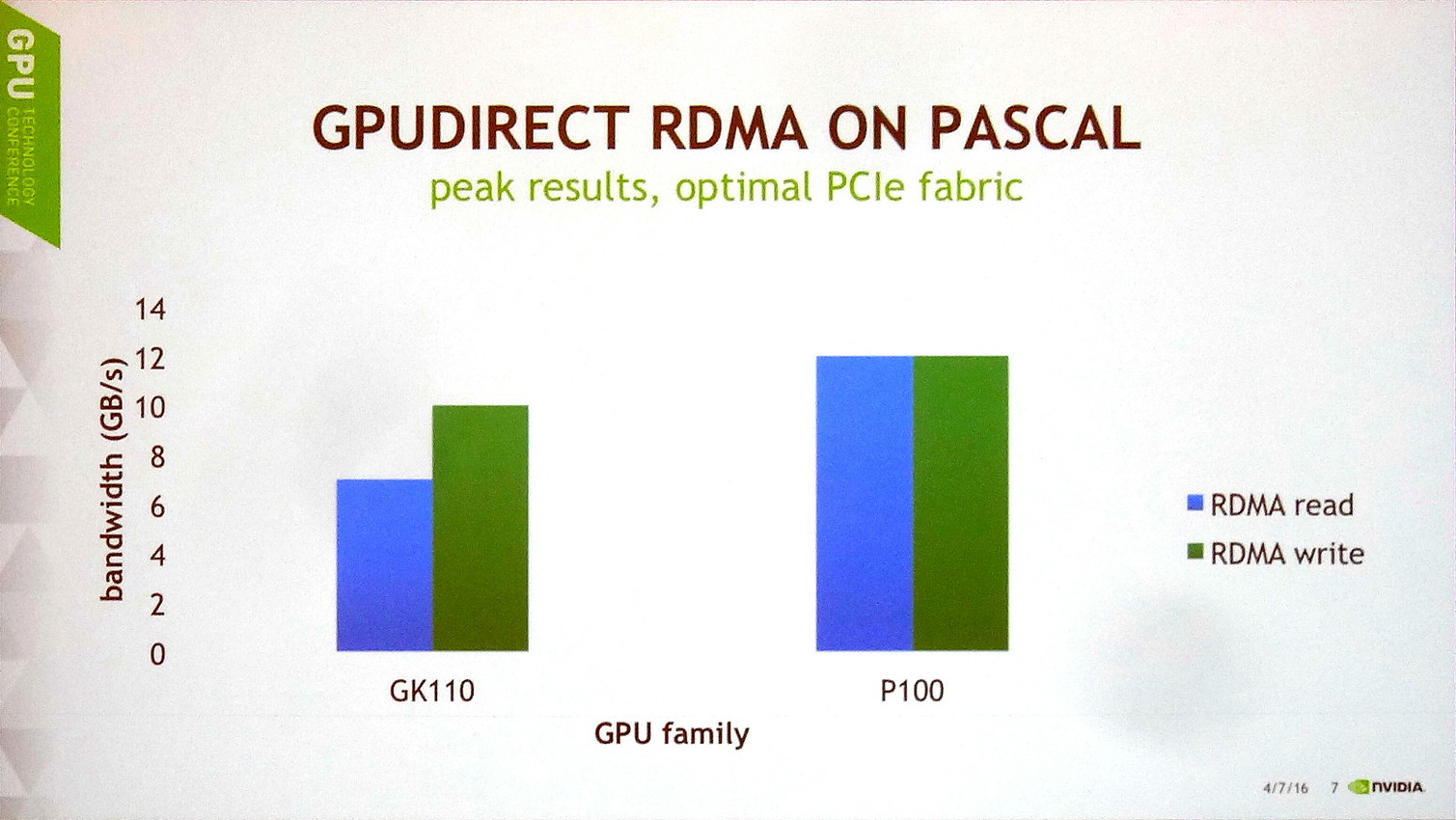
Il y a tout d'abord des progrès au niveau du PCI Express. Nvidia explique que les GPU Kepler et Maxwell souffraient de quelques limitations et devaient se contenter d'à peu près 10 Go/s en écriture et de 7 Go/s en lecture. Cela change avec Pascal dont le tissu PCI Express est dorénavant optimal pour une interface 16x 3.0, ce qui lui permet d'atteindre 12 Go/s dans les deux sens, soit à peu près le maximum théorique.
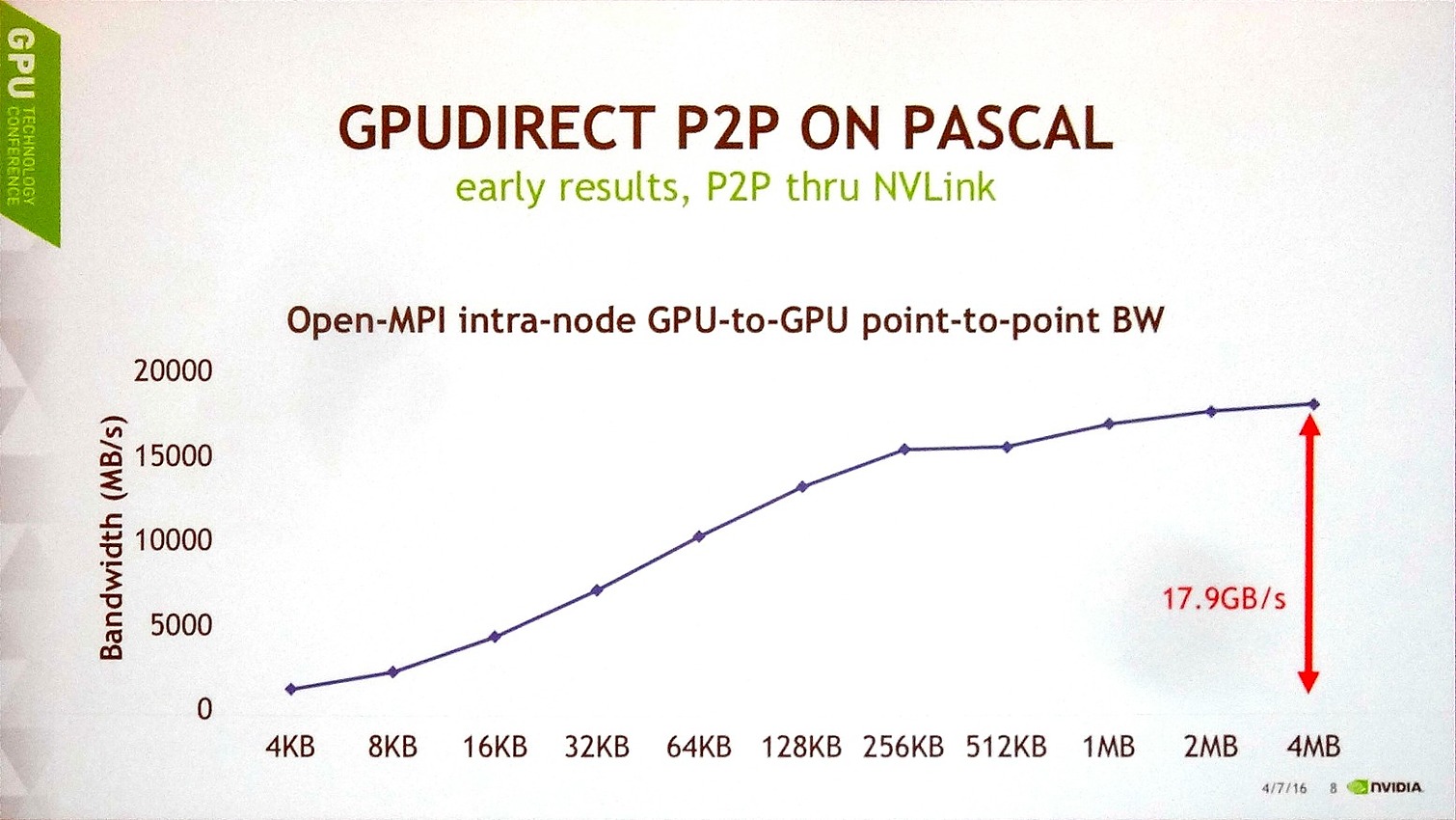
Ensuite, Nvidia a publié les premiers chiffres de débits obtenus pour les liens NVLink en communication point-à-point entre 2 GP100, tout en précisant que toutes les optimisations n'avaient pas encore été mises en place. Pour ce test, un seul lien NVLink est ici exploité et le transfert est unidirectionnel.
Avec des blocs de 4 Mo, le GP100 parvient à monter à 17.9 Go/s, ce qui est plutôt pas mal compte tenu du fait que l'interface est spécifiée à 20 Go/s dans chaque direction. Le débit reste supérieur à 15 Go/s avec des blocs de 256 Ko, mais plonge rapidement sous cette valeur, ce qui est un résultat attendu pour toute voie de communication compte tenu du surcoût par transfert. Ces premiers résultats sont donc plutôt encourageants et Nvidia explique qu'ils sont obtenus grâce à l'intégration de moteurs de copies pour chaque lien NVLink.