
Intel donne des détails sur le Penryn
Publié le 29/03/2007 à 00:28 par Franck Delattre



Intel sest décidé ce jour à donner quelques détails supplémentaires concernant les prochaines évolutions de sa gamme processeur, à commencer par le Penryn. On connaissait déjà de manière officielle quelques détails (cf. ici ou encore là)sur ce qui est avant tout présenté comme un « die-shrink » des processeurs actuels : une gravure en 45nm avec technologie high-k, et un nombre de transistor passant de 290 à 410 millions du fait du passage de 4 à 6 Mo de cache L2.

Le core Penryn et ses 6 Mo de cache L2
Première chose, Intel confirme être dans les temps pour commencer la production durant le second semestre, même si cela ne signifie pas pour autant que toute la gamme sera disponible cette année. Les fréquences sont annoncées comme supérieures à 3 GHz, ce qui en soit nest pas une surprise. Pour rappel, il faudra sur desktop au moins de nouvelles plates-formes, à base du chipset P35 qui sera lancé en juin ou du X38 qui arrivera à la rentrée.
Côté consommation, Intel a choisi de ne pas abaisser le TDP au profit dune augmentation de performances : du coup, on restera à 65 watts sur les dual core Wolfdale, et 95 à 130 watts sur les quad core Yorkfield (contre 105 à 130 actuellement). Le FSB ne devrait pour sa part pas augmenter sur desktop, soit 1333 pour le dual core et 1066 pour le quad core, mais il atteindra 1600 sur serveur.
Quid des améliorations architecturales ?
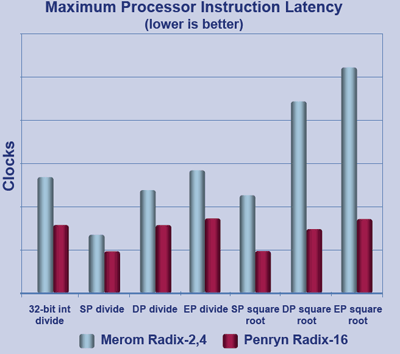
1/ Des divisions plus rapidesIntel n'a pas jugé utile de toucher aux unités de calcul déjà très performantes de l'architecture Core, exception faite de l'unité responsable de la division. La division reste une des opérations arithmétiques effectuée le plus lentement par un processeur, et il est intéressant de noter à ce sujet qu'Intel et AMD utilisent des techniques radicalement différentes. Les processeurs Intel utilisent, tout comme nous, la méthode euclidienne : à un diviseur et un dividende sont associés un quotient et un reste. Les processeurs opèrent la division par morceau, c'est-à-dire qu'à chaque cycle ne sont traités qu'un nombre fini de bits. L'opération est relativement lente (le nombre de cycles nécessaire dépend de la taille du dividende), mais est exacte.
Les processeurs AMD utilisent quant à eux une méthode d'approximation basée sur des tables et des multiplications. L'opération est beaucoup plus rapide, mais les tables micro-codées sont consommatrices de ressources. Les processeurs AMD n'emploient ainsi la technique que pour les divisions flottantes, et les divisions entières passent par une phase préalable de conversion de type (ce qui réduit notablement leur efficacité). L'opération est rapide (tout du moins en flottants), mais approximée. AMD semble cependant décider à abandonner cette méthode sur le K10 pour adopter la méthode euclidienne.
Intel a-t-il eu peur que le dernier né d'AMD soit plus performant sur les divisions ? Quoiqu'il en soit, là où Core traite deux bits par cycle (on parle de Radix-4), Penryn en traite quatre (Radix-16). La technique bénéficie également à d'autres opérations plus complexes faisant intervenir des divisions, telles que le calcul de la racine carrée qui a fait l'objet d'optimisations toutes particulières. Signalons que les moteurs 3D géométriques font une utilisation assez intensive de ce type d'opération.
2 / Super Shuffle et SSE4Le SSE se voit améliorer en deux points, le premier étant laccélération des instructions de shuffle, cest-à-dire les instructions qui mélangent les données de plusieurs registres SSE et qui sont grandement utilisées dans le codage et le décodage vidéos.
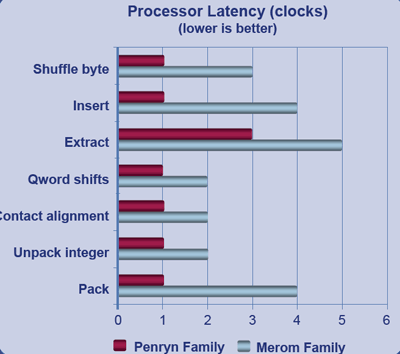
De plus, une nouvelle série dinstructions fait pour rappel son apparition, le SSE4 dont vous pouvez lire les détails dans ce document . Une cinquantaine dinstructions sont au menu du jour, dont une bonne partie pourrait apporter des gains très généraux, et dautres dans des domaines plus spécifiques tels que le calcul dune valeur CRC. Bien entendu il faudra que les programmes soient écrits ou compilés pour prendre en compte ces instructions, elles napporteront rien aux programmes actuels.
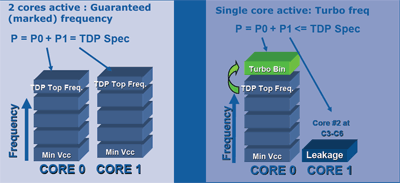
3/ Energie : IDA (Intel Dynamic Acceleration) et Deep Power DownLa technique d'accélération dynamique IDA n'est pas réellement propre au Penryn, car déjà implémentée sur les futurs modèles de Core 2 Duo Merom sur la plate-forme mobile Santa Rosa qui est prévue pour mai. Elle est à ce titre présentée comme relative à la gestion de l'énergie, bien que son utilisation nous semble intéressante au delà de cette seule perspective.
L'idée d'IDA consiste à booster la performance d'un des deux cores lorsque l'autre est inactif. Par exemple, sur un processeur double coeur cadencé à 2,2 GHz, l'inactivité d'un core se traduit par une accélération du second à 2,4 GHz. L'enveloppe thermique globale reste inférieure à ce qu'elle serait si les deux cores tournaient à 2,2 GHz, tout en assurant une performance supérieure du thread traité par le core actif. Par cette astuce, les applications mono-thread sont accélérées, tout en conservant une dissipation thermique globale dans des limites raisonnables. Il est fort dommage que cette technique ne soit implémentée que sur les plateformes mobiles, même si bien entendu dans le cadre dune machine overclockée il faudrait pouvoir la désactiver !
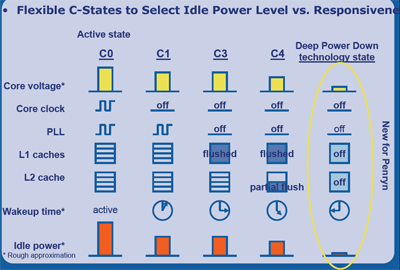
Notons pour finir que la version Mobile du Penryn bénéficie en outre d'un état supplémentaire appelé Deep Power Down, destiné à prolonger encore un peu l'autonomie des batteries des laptops. Dans ce mode, les caches L1 & L2 seront purement et simplement coupés, ce qui nétait pas le cas auparavant.
Et les performances ?Vous devrez vous contenter des chiffres avancés par Intel.
En environnement ludique, les améliorations micro-architecturales, l'inflation de la taille du L2, et les fréquences supérieures de Penryn se traduisent, selon Intel, par un gain de performance de l'ordre de 20% entre un Penryn 3.2 GHz et un Conroe 3.0 GHz. Les optimisations apportées aux instructions Shuffle et le SSE4 permettrait, par rapport au SSE3, datteindre un chiffre de lordre de 40% en encodage vidéo. Wait & See !
Vos réactions
Contenus relatifs
- [+] 09/05: AMD Ryzen 7 2700, Ryzen 5 2600 et I...
- [+] 04/05: Un Coffee Lake 8 coeurs en préparat...
- [+] 27/04: Le 10nm d'Intel (encore) retardé, l...
- [+] 26/04: Jim Keller rejoint... Intel !
- [+] 23/04: MAJ de notre test des Ryzen 7 2700X...
- [+] 20/04: MAJ de notre comparatif CPU géant
- [+] 19/04: AMD Ryzen 2700X et 2600X : Les même...
- [+] 19/04: 2008-2018 : tests de 62 processeurs...
- [+] 13/04: Les AMD Ryzen Pinnacle Ridge en pré...
- [+] 10/04: LGA4189 pour les Xeon Ice Lake !