
AMD dévoile Steamroller et Jaguar



AMD a profité de la 24eme édition de la conférence Hot Chips - conférence dédiée aux semi conducteurs qui se tient actuellement à Cupertino en Californie - pour dévoiler quelques détails sur ses futures architectures. En ce second jour de la conférence, Mark Papermaster présentait un keynote dans lequel plusieurs nouveautés ont été évoquées, une présentation qui nous a été fournie en amont par AMD.


D'abord côté stratégie globale, le CTO d'AMD a mis en avant sa vision de certains mouvements qui ont lieu actuellement dans l'industrie, avec en tête la multiplication des solutions type Cloud. Outre des besoins de stockage de plus en plus importants, ces Clouds d'un nouveau type deviendront de plus en plus intelligents et au delà des classiques tâches d'identification des utilisateurs et du cryptage de leurs données, vont devoir faire face à de nouvelles problématiques plus gourmandes en temps de traitement (recherche, indexation, traitements type intelligence artificielle, data mining, etc). Au point de proclamer le début de l'ère du Surround Computing, définie comme la juxtaposition de ces Clouds intelligents à des clients, divers, multiples, et eux aussi toujours plus intelligents. Des clients qui migrent vers des interfaces de contrôle plus naturelles (gestes, voix, reconnaissances faciale et biométrique, mouvement des yeux, etc) elles aussi gourmandes d'un point de vue ressources (Mark Papermaster cite par exemple la reconnaissance vocale d'Apple, Siri, dont le traitement est aujourd'hui déporté côté serveur).


Des problèmes à résoudre selon AMD par des architectures système hétérogènes (HSA) qui mixent différentes capacités de calcul. Pour rappel pour 2013, AMD souhaite ajouter un espace d'adressage mémoire unifié entre CPU et GPU, y compris de la mémoire paginée afin de simplifier l'écriture de tâches qui partagent le calcul entre x86 et architecture graphique. La stratégie HSA aboutissant déjà sur les APU (qui intègrent pour rappel CPU et GPU sur un même die) même si quelques petites clarifications autour du rôle des SoC (voir notre interview de Mark Papermaster) ont été apportés (voir plus loin).
Steamroller
Miser sur l'aspect hétérogène est une chose qui ne doit pas se faire au détriment des performances des cœurs x86. Alors que l'on attend sous peu la prochaine version des AMD FX (les processeurs Vishera, basés sur l'architecture Piledriver, version 2 de Bulldozer), Mark Papermaster a évoqué la prochaine architecture x86 de la marque, Steamroller. Toujours dérivée de l'architecture CMT de Bulldozer (voir notre présentation pour référence), elle opère quelques changements importants. Avant d'aller plus loin, noter que les chiffres de performances qui sont indiqués sont purement basés sur des simulations internes d'AMD.

Tout d'abord du côté du frontend, un bloc d'unité crucial qui à pour but d'alimenter en instruction le reste du pipeline. Un rôle d'autant plus crucial dans le cas de l'architecture Bulldozer puisqu'un "module" est défini par AMD comme l'utilisation d'une unité frontend unique et de deux pipelines indépendant capables de traiter des instructions entières (le pipeline flottant étant lui-même partagé). Plusieurs modifications sont effectuées, à commencer par une augmentation (non quantifiée) de la taille du cache d'instruction (64 Ko sur Bulldozer) qui devrait réduire les cas où l'instruction demandée n'est pas dans le cache (cache miss) de 30%. Les mécanismes de prédiction de branchement, qui empruntaient déjà certaines idées à l'architecture Nehalem deviennent eux aussi plus efficaces avec une réduction des 20% des mauvaises prédictions.
Le changement le plus important concerne cependant la partie décodeur : AMD passe d'un décodeur unique (4 ops par clock maximum) à deux décodeurs distincts (possiblement 2 x 3 ops) qui alimenteront chacun leur bloc integer. Les deux blocs pourront également dispatcher conjointement des instructions vers le scheduler de l'unité virgule flottante. En soit, il s'agit d'un changement assez majeur d'orientation qui devrait permettre une meilleure utilisation lorsque les deux threads d'un module sont utilisés. Dans notre test de l'AMD FX, nous avions noté que dans les applications fortement multithreadées, l'activation d'un second thread par module n'apportait "que" 53.1% de gain en moyenne. AMD espère significativement augmenter les performances lorsque deux threads sont utilisés et évoque 30% d'opérations par cycle en plus envoyées aux unités de calcul.
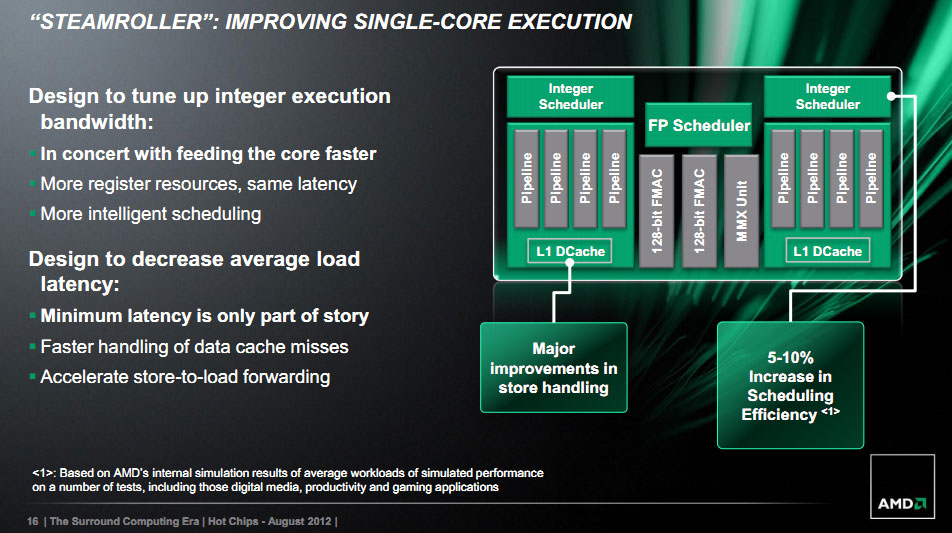
AMD effectue également quelques changements dans les unités de calcul pour maximiser leurs performances. Les détails sont ici extrêmement minces puisque AMD ne s'avance pas au delà de "plus de registres" et d'un meilleur scheduling, plus efficace de 5 à 10%. Les derniers changements évoqués concernent le rendement énergétique, avec une optimisation du côté de l'unité de fetch. AMD n'évoque pas cependant le cout lié à l'ajout d'un second décodeur. Le cache L2 pourra également réduire dynamiquement sa taille en fonction de son utilisation, pour limiter la consommation.

Un des slides les plus intéressants de la présentation de Mark Papermaster - et qui n'est pas directement lié a Steamroller - concernait la phase de design des puces. Sont mis côte à côte une partie des blocs de l'unité virgule flottante telle qu'implémentée dans Bulldozer en 32nm, et les mêmes blocs en 32nm toujours, ré implémentés avec une bibliothèque haute densité (possiblement pour Piledriver/Vishera même si cela n'est pas précisé). AMD indique une réduction de 30% de la surface et entre 15 et 30% d'économie d'énergie.
Bien entendu il est trop tôt pour se prononcer sur les changements apportés par Steamroller, architecture qui débarquera en 2013 et en 28nm sur les APU dans un premier temps (a l'image de Trinity qui intègre déjà Piledriver et que nous avions testé en version mobile, alors que son pendant desktop, Vishera, est attendu sous peu en 32nm), mais certains des changements semblent aller dans une bonne direction, particulièrement du côté des décodeurs qui devraient permettre d'augmenter l'efficacité lors de l'utilisation simultanée des deux threads d'un module. Des changements bénéfiques, certes, mais lointains puisque côté concurrence, on parlera déjà d'Haswell.
SoC et interconnexions
Dans l'interview que nous lui avions consacré, Mark Papermaster avait fortement insisté sur l'approche SoC d'AMD et la flexibilité qu'apportait la possibilité de réaliser des designs customs pour des clients, utilisant diverses ISA (par exemple de type ARM). Si AMD ne s'avance toujours pas plus dans les détails sur le sujet d'éventuels SoC clients en cours de réalisation, le constructeur a indiqué travailler sur un mécanisme d'interconnexion dédié aux SoC. Baptisé Freedom Fabric, cette technologie repose sur un ASIC intégré au SoC qui permet son interconnexion avec d'autres SoC. Extrêmement peu de détails ont été donnés, si ce n'est que la bande passante de l'interconnexion est de 160 Gbps et que l'ASIC gère la virtualisation des I/O.

Une technologie intéressante sur le papier même s'il faudra voir en pratique où elle s'appliquera. AMD annonçant sa scalabilité au delà de centaines ou milliers de SoC un point intéréssant côté serveur pour des plateformes comme celles de SeaMicro.
Jaguar
En marge du Keynote de Mark Papermaster, AMD a également effectué hier une présentation plus complète sur Jaguar, l'autre architecture x86 d'AMD qui vise, elle, les utilisations basse consommation. Jaguar est une évolution de Bobcat, l'architecture utilisée dans les APU Brazos d'AMD lancés début 2011. Bobcat est pour rappel une architecture basse consommation de type OOO (Out Of Order, possiblité pour le scheduler de changer l'ordre d'exécution des instructions pour améliorer les performances), contrairement à l'Atom qui utilise une architecture In Order (exécution dans l'ordre exact dans lequel les instructions sont fournies.
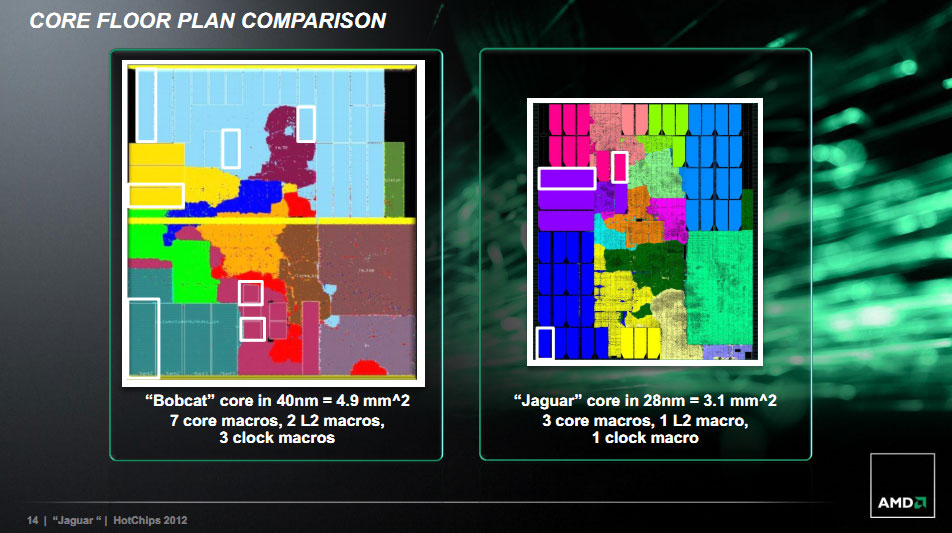
D'un point de vue produit, et comme évoqué plus tôt par AMD, Jaguar apparaitra en 2013 côté mobile avec les APU Tamesh (2 cœurs, tablettes et autres utilisation sans ventilateur) et Kabini (2-4 cœurs pour des netbook/portables/desktop).
Côté ISA, Jaguar remet au gout du jour Bobcat en apportant le support de SSE4.1, 4.2, AVX ainsi que les instructions dédiées à AES (avec pour être complet en prime CLMUL, MOVBE, XSAVE/OPT, F16C et BMI1). Le support de la virtualisation est annoncé comme amélioré, mais sans plus de détails.

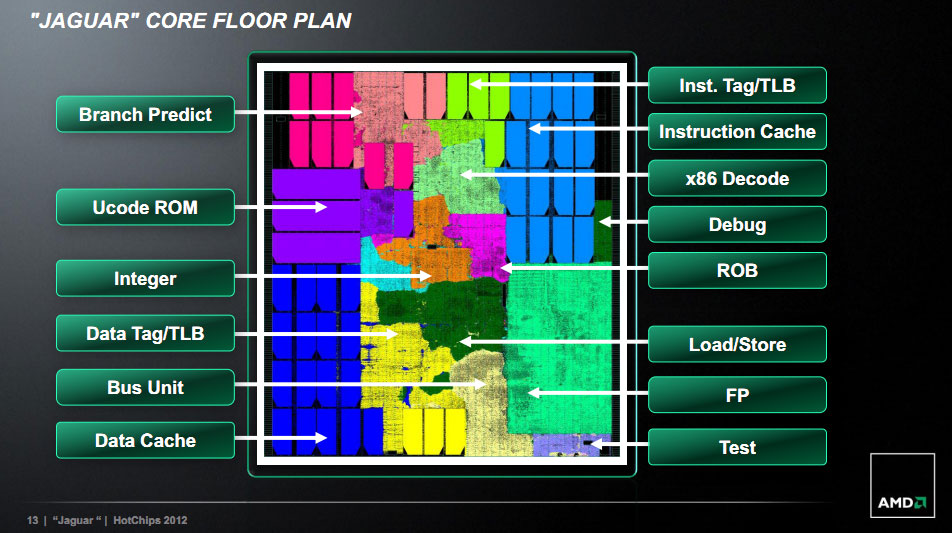
Le frontend de Jaguar reprend les grandes lignes de Bobcat à savoir un cache d'instruction de 32 Ko et un décodeur 2 way (deux instructions). Jaguar apporte cependant quelques plus en ajoutant des buffers additionnels pour le cache d'instruction. Le prefetcher d'instruction est également amélioré pour augmenter l'IPC (avec un gain non quantifié).
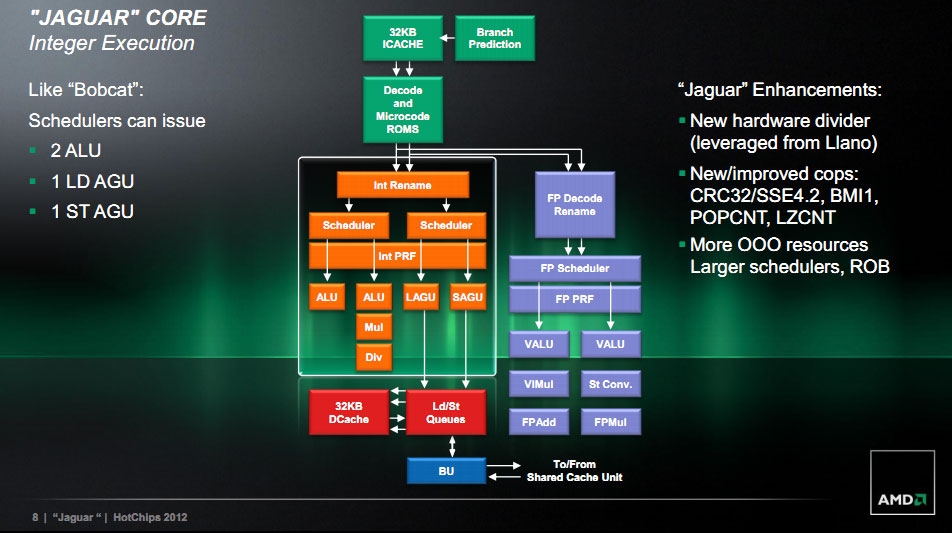
Du côté du pipeline entier, le plus gros changement se situe au niveau de la division, un bloc d'exécution récupéré de Llano et porté pour cette architecture. La gestion Out Of Order est également améliorée avec un scheduler plus large et un buffer de réordonnancement (ROB) plus large.
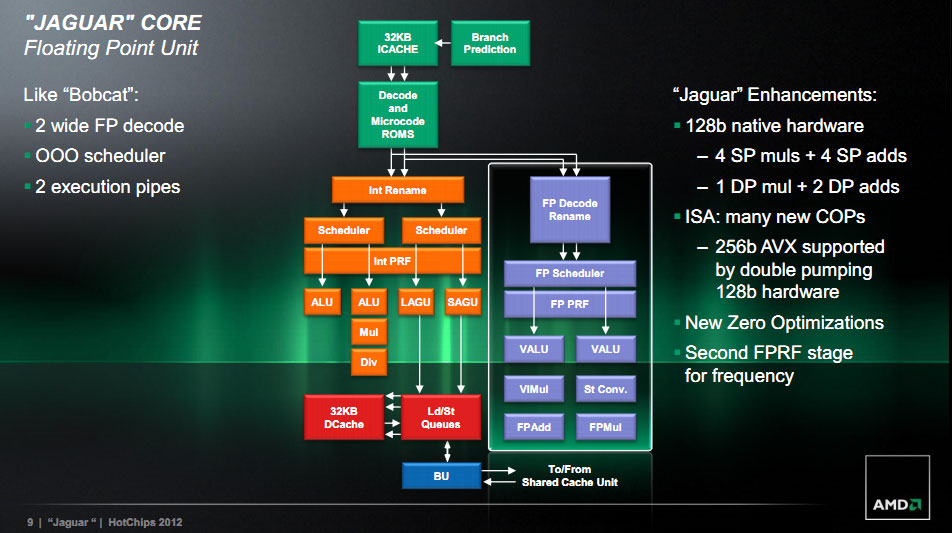
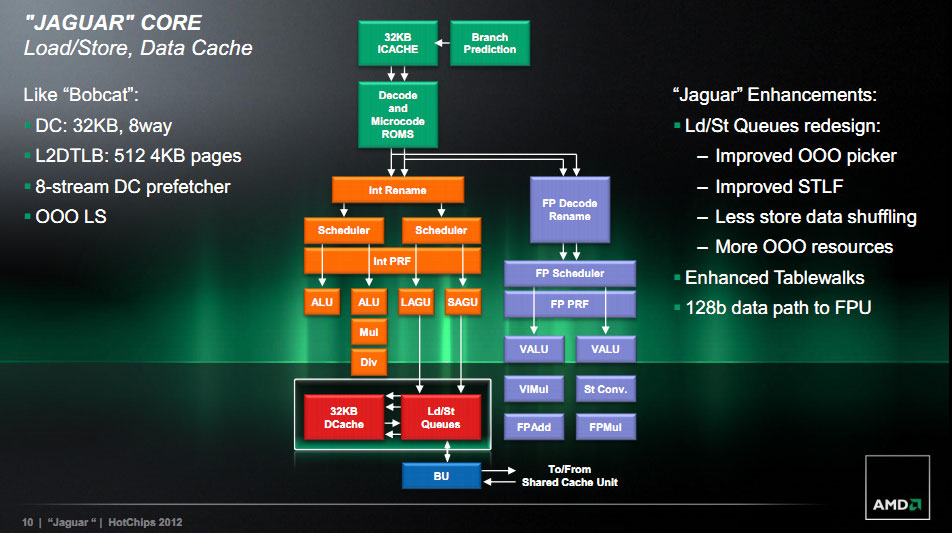
Le pipeline flottant dispose toujours de deux pipelines d'exécution, mais profondément revus avec des unités natives 128 bits capables de travailler main dans la main pour executer des instructions 256 bits (certaines instructions AVX sont disponibles en variantes 256 bits, ce même type d'optimisation est présent pour rappel sur Bulldozer). Le cache de données de niveau 1 reste de 32 Ko mais AMD a optimisé fortement le fonctionnement des unités Load/Store (qui chargent/écrivent les données di cache en mémoire). Le cache L1 est également relié à l'unité flottante par un lien 128 bits.


En ce qui concerne le L2, AMD a effectué plusieurs changements. Ce cache L2 est de type inclusif (le contenu du L1 se retrouve dans le L2) et l'on retrouve jusque 4 banks L2 de 512 Ko distincts, connectés à une interface pour obtenir jusque 2 Mo de mémoire L2 avec une associativité 16 way. Cette interface fonctionne à la même fréquence que les cœurs, tandis que la mémoire se veut cadencée plus lentement, à demi vitesse. Cette interface gère jusqu'à 24 opérations lectures/écritures en simultanée, à partager entre les cœurs.
Notez enfin en ce qui concerne la gestion de l'énergie que Jaguar ajoute un mode C6 au niveau de chaque core (CC6) afin de pouvoir les éteindre individuellement de manière efficace. AMD indique également avoir amélioré la latence du mode C6 (tous les cœurs éteints).
Côté performances, AMD estime une amélioration de 15% de l'IPC, combinée à une augmentation de la fréquence d'environ 10%. Des gains sur le papier qui paraissent plutôt intéressants par rapport à la plateforme Atom actuelle qui a relativement peu évoluée depuis son lancement. Mais Intel lancera en 2013 également (enfin !) une nouvelle architecture Atom, Silvermont, qui sera également de type OOO et sur laquelle on ne connait pour l'instant que relativement peu de détails.




Contenus relatifs
- [+] 04/10: AMD lance les Bristol Ridge Pro
- [+] 02/02: Excavator FM2+ et nouveaux ventirad...
- [+] 07/01: CES: AMD en dit plus sur les APU A1...
- [+] 09/10: Les FX-9370 et FX-9590 avec waterco...
- [+] 12/09: AMD FX 9590 : 5 GHz, ou pas, en tes...
- [+] 08/08: Kaveri en 2014, AMD confirme
- [+] 17/07: Kaveri finalement en 2014 ?
- [+] 19/06: AMD FX 4350 et FX 6350 en test
- [+] 18/06: AMD détaille sa roadmap serveur 201...
- [+] 30/04: AMD lance les FX-4350 et FX-6350