
L'architecture AMD Bulldozer
Publié le 13/05/2011 par Franck Delattre



L'unité front-end
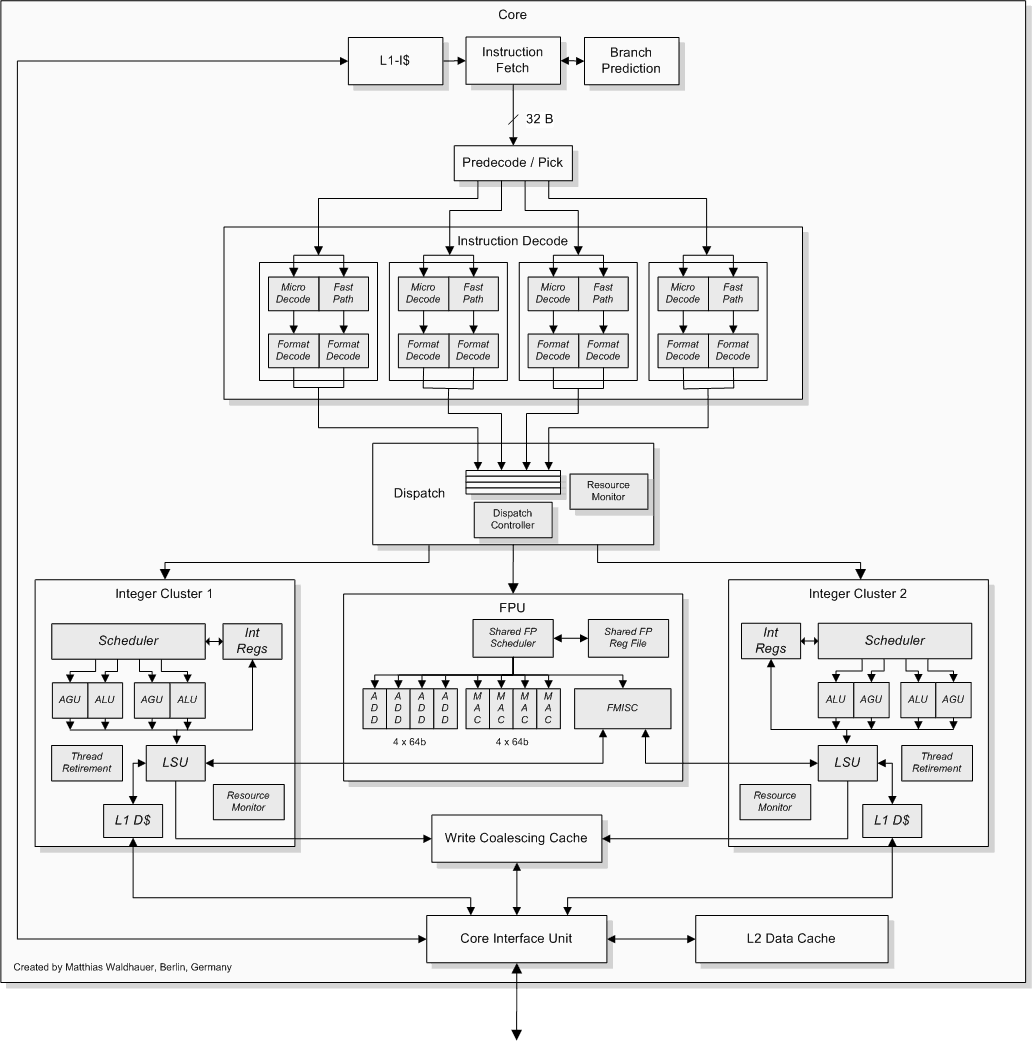
Crédit : Dresdenboy
L'unité front-end est responsable de l'alimentation en instruction du reste du pipeline de traitement. Son rôle est donc essentiel dans les performances, car les capacités de traitement ne peuvent être pleinement exploitées que lorsque le flux d'instructions est élevé et constant. Le front-end du module de base du Bulldozer doit être capable d'alimenter non plus un mais deux cores en instructions, on comprend dès lors le rôle clé que cette unité occupe dans la nouvelle architecture d'AMD.
Les branchements, ou sauts dans le code, sont le principal casseur de flux d'instructions, c'est pourquoi les architectures modernes ont recours à la prédiction de branchements. Plusieurs mécanismes complémentaires sont couramment utilisés afin d'obtenir une efficacité maximale. Bulldozer n'échappe pas à la règle et reprend la plupart des mécanismes que l'on trouve sur Nehalem ! : un détecteur de boucles, une gestion des branches directes et indirectes, ainsi qu'un mécanisme de prédiction hybride qui gère les branches selon leur localité (portée locale ou globale) ; pour finir, un mécanisme dédié au stockage des adresses de retour (à la différence des BTB Branch Target Buffer - qui stockent les adresses de destination).
AMD évoque également la présence d'un trace-cache (un cache contenant des micro-instructions déjà décodées), permettant de diminuer les pénalités en cas d'erreur de prédiction de branchement. A noter qu'on retrouve la présence d'un tel cache dans le détecteur de boucles du Nehalem.
Le module Bulldozer intègre un unique cache L1 d'instructions de 64Ko. Celui-ci est associatif à deux voies, soit une voie pour chaque core.
L'unité de décodage de Bulldozer a été élargie par rapport à celle du K10, et ce dans l'optique de répondre aux besoins de deux cores. Un module Bulldozer peut ainsi décoder jusqu'à 4 instructions par cycle, soit une de plus que le K10. Présent depuis le Core 2 chez Intel, le mécanisme de fusion fait son apparition pour la première fois sur un processeur AMD. A titre de rappel, la fusion consiste en le décodage de certains couples d'instructions comme une seule instruction, en l'occurrence pour le Bulldozer les couples composés d'une instruction de comparaison ou de test suivie d'une instruction de saut (on parle de fusion de branche). Ainsi, quand une telle occurrence se produit, le module peut décoder jusqu'à 5 instructions par cycle.
Moteur OOO et unités de calculLors de notre étude de l'architecture Sandy Bridge, nous avions évoqué le changement que constituait l'utilisation d'un fichier de registres physiques (PRF). A titre de rappel, le fichier de registres physiques consiste en une table de registres de travail utilisés par le moteur d'exécution out-of-order (OOO), vers laquelle pointent les entrées du buffer de réordonnancement (ROB). Ce mécanisme de pointage permet un ROB de taille plus importante en comparaison à un système où le ROB contient lui-même les données des micro-opérations. Bulldozer utilise également un fichier de registres physiques, et tout comme pour Sandy Bridge, la motivation de ce choix tient dans la taille des opérandes du jeu d'instructions AVX.
Chacune des deux unités d'exécution x86 du module Bulldozer est composé de deux ALUs (unités arithmétiques et logiques) ainsi que de deux AGUs (unités de génération d'adresse). Là où l'architecture K10 offre trois ALUs, pour un débit maximum de 3 instructions exécutées par cycle, le module Bulldozer offre un débit maximal de 2 x 2 instructions entières par cycle. La performance brute entière théorique d'un module Bulldozer est donc égale à 2 x 2 / 3 x 3 = 67% de celle d'un K10 double core.
Cela étant, il s'agit du cas théorique le plus défavorable au Bulldozer par rapport au K10 et AMD indique que l'IPC devrait être amélioré en pratique. De plus, il faut garder à l'esprit que l'intérêt du module ne tient pas tant dans la performance pure, mais dans le rapport entre la performance et la puissance consommée, et à ce titre un module de Bulldozer devrait se montrer beaucoup plus efficace que deux cores K10.
L'unité de calcul flottant est une des ressources partagées par les deux cores du module Bulldozer. Elle consiste en deux pipelines de traitement de type FMAC 128-bits (fused multiply accumulate), ce qui signifie que les unités sont capables d'effectuer directement une opération de produit scalaire (que l'on trouve couramment dans les traitements graphiques et les moteurs géométriques). Outre le gain de performance, l'intérêt réside dans la précision de calcul : aucun arrondi n'est effectué entre les deux opérations (multiplication et addition), ce qui garantit une précision de calcul maximale. Ces deux unités peuvent être unifiées en une unité 256-bits pour le traitement des instructions AVX. A noter que la FPU du Bulldozer semble être capable de tourner en mode « économie d'énergie », en n'opérant pas sur tous les bits des opérandes.
Sommaire
Vos réactions
Contenus relatifs
- [+] 17/03: AMD baisse ses prix AM3+/FM2+
- [+] 14/03: Bundle AMD pour les FX-6 et FX-8
- [+] 25/11: AMD dégaine ses offres de fin d'ann...
- [+] 04/10: AMD lance les Bristol Ridge Pro
- [+] 24/08: Deus Ex en bundle... avec les AMD F...
- [+] 19/05: Total War : Warhammer offert par AM...
- [+] 02/02: Excavator FM2+ et nouveaux ventirad...
- [+] 15/12: AMD FX-6330 = FX-6300 + 100 MHz
- [+] 01/10: Perfs avec 2, 4, 6 et 8 curs : 4 j...
- [+] 10/09: AMD FX-8370E, un FX 8 curs 95 watt...