
NVIDIA GeForce 7800 GTX
Publié le 22/06/2005 par Damien Triolet et Marc Prieur



Pixel Shader améliorés, en théorieNVIDIA ne sest pas contenté dajouter 8 pipelines de pixel shading supplémentaires mais les a également améliorés. Il ne sagit pas dun changement radical, mais dun petit lifting destiné à augmenter leur efficacité. Tout comme les GeForce 6, le GeForce 7800 dispose donc globalement de 2 unités de calcul par pipeline. Chaque unité prend en charge plusieurs opérations mais ne peut sortir quun résultat à la fois. Elles peuvent donc exécuter une opération simple ou une combinaison de celles-ci, mais pas 2 opérations différentes.
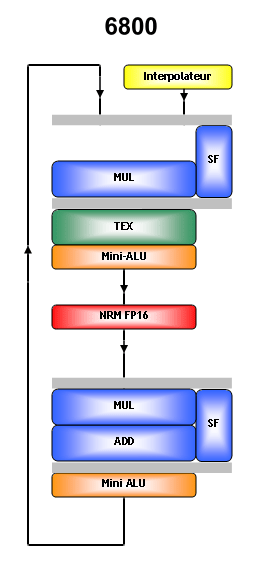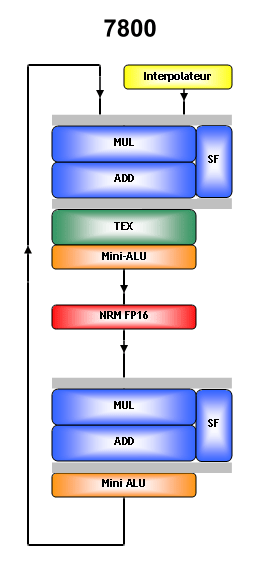
Lamélioration principale qui a été apportée, et fortement mise en avant par NVIDIA, est lajout dun additionneur dans la première unité, qui dans les GeForce Serie 6 nétait pas capable de traiter les additions et les autres instructions qui y sont liées, notamment les MADs. Un MAD est une multiplication suivie dune addition, par exemple : X * Y + Z. Ces 2 opérations, les multiplications et les additions, sont des opérations courantes dans les différents algorithmes de rendu (dans tout algorithme en fait), il arrive donc souvent quune multiplication et une addition soient dépendantes lune de lautre, ce qui permet de les traiter en une seule opération MAD au lieu de 2 instructions.
Les MAD sont donc courantes et pouvoir les traiter rapidement nest pas inintéressant. Dans le GeForce 6800, seule la seconde unité dispose du couple multiplicateur / additionneur et est donc la seule à pouvoir traiter un MAD. Dans le GeForce 7800, les 2 unités de calcul ont cette capacité, ce qui, selon NVIDIA double la puissance de calcul du nouveau GPU par rapport à lancien. Il sagit bien entendu dun raccourci trop facile puisque un pixel shader, dans la pratique, nutilise pas que des MADs.
En réalité, le nombre dinstructions maximum pouvant être traitées par cycle dhorloge sur un pipeline de GeForce 7800 nest pas plus élevée que sur un autre de GeForce 6800, par contre, le GeForce 7800 serait maintenant capable de sen rapprocher plus en pratique.
Linterpolateur est lunité qui, comme son nom lindique, se charge dinterpoller les couleurs ou les adresses des textures à partir des valeurs des 3 sommets de chaque triangle et peut ainsi alimenter le pipeline de pixel shading a raison dune valeur par cycle. Les blocs "SF" sont des unités qui prennent en charge des opérations spéciales scalaires comme (1/x, 2^x...). Les mini-ALU peuvent appliquer des modifiers (opération simple comme x2, x4, x8...) sur ce qui sort de chaque unités. Lunité NRM (normalisation dun vecteur, fort utile avec le normal mapping) a été ajoutée par NVIDIA pour accélérer cette instruction, mais uniquement en FP16. Sans cela, une instruction NRM est divisée en plusieurs instructions et monopolise plusieurs unités et plusieurs cycles.
Pixel Shader améliorés en pratiqueLors de nos premiers tests, ce que nous venons de vous expliquer, sest avéré être à la fois faux et vrai. Faux parce que nous ne somme pas parvenus à observer cet additionneur supplémentaire en action, que ce soit sur de simples additions ou sur des MADs. Nous avons essayé une multitude de variations dans nos tests, sans succès. Nous avons questionné NVIDIA à ce sujet qui nous a alors fourni un exemple à partir du quel nous avons pu écrire un bout de code qui montrait que les 2 MADs étaient bel et bien fonctionnels, mais uniquement dans des cas spécifiques (d´après le nombre de registres utilsés, le type de ces registres, les dépendances entre instructions etc.). Cas qui à priori ne devraient pas se retrouver dans des jeux.
Par contre, lors de nos nombreux tests, nous avons bel et bien remarqué une augmentation de lefficacité des pipelines de pixel shading, augmentation parfois très importante ! Alors que se passe-t-il ? Selon nos premiers tests lefficacité augmente, mais ne vient que partiellement et indirectement de lamélioration décrite ci-dessus. Indirectement puisque la présence d´un MAD dans chaque unité permet au compilateur / scheduler de mieux agencer le code. Par exemple, si un MAD est suivi d´une instruction spéciale prise en charge par l´unité 2, il faudra 2 cycles au 6800 pour les traiter, alors que le 7800 pourra le faire en un seul cycle, si toutes les conditions sont réunies. Partiellement puisque le changement apporté est en fait l´augmentation de l´efficacité du pipeline, l´additionneur supplémentaire n´étant qu´un des points qui y participent.
Avec le GeForce 6800, NVIDIA a introduit dans le pipeline de pixel shading (mais également de vertex shading) une gestion très flexible du co-issuing. Pour rappel, le co-issuing consiste à faire exécuter 2 instructions par la même unité. Comment est-ce possible puisquelles ne sont censées pouvoir en traiter quune seule ? En fait une instruction complète est réalisée sur 4 composantes, qui peuvent représenter les 4 canaux du format RGBA (rouge, vert, bleu, transparence) ou nimporte quoi dautre. Avec le co-issuing il est possible dexécuter 2 instructions, mais la totalité de leurs composantes ne peut pas excéder 4. Il est donc possible de traiter 2 opérations sur 2 composantes ou une sur 3 et une autre sur 1. ATI gère le co-issuing également depuis le Radeon 8500, mais uniquement en mode 3 + 1. Bien entendu, 2 instructions traitées en co-issuing ne peuvent pas être dépendantes lune de lautre, et certaines restrictions existent au niveau des opérations qui peuvent en profiter.
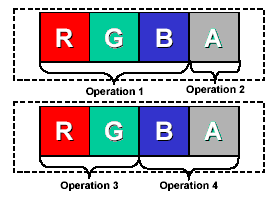
Lors de nos tests du GeForce 6800, nous avions remarqué, au départ, une très faible efficacité du co-issuing qui nétait pas souvent utilisé ou utilisable, ce que nous avions attribué à un défaut de jeunesse des drivers et principalement du compilateur quils contiennent. 1 an après, lefficacité du co-issuing sur GeForce Serie 6 sest améliorée mais natteint que difficilement son maximum defficacité.
Par contre sur GeForce 7800 GTX, la situation a changé et le co-issuing a gagné en efficacité, surpassant même dans certains cas ce que lon pouvait en attendre. Cest en tout cas lexplication logique qui découle des tests que nous avons effectués. Lefficacité sest également améliorée sur dautres petits détails ce qui globalement augmente lIPC, cest-à-dire le nombre dinstructions exécutées par cycle dans la pratique. Ce type de gain est difficilement quantifiable puisquil peut varier entre 0% et 100% daprès la suite dinstructions que contient le shader. Il convient de préciser que le trio compilateur (driver), scheduler (driver / GPU), organisation du pipeline (GPU) doit être parfaitement en phase pour permettre une forte efficacité et cela semble être bien plus le cas sur GeForce 7800 que sur GeForce 6800.
PerformancesNous avons extrait des shaders de 3 applications qui en utilisent des complexes : 3DMark05, Far Cry et Tomb Raider AOD. Nous les avons exécutés sur tout lécran dans une application externe.

La Radeon X850 XT PE apprécie particulièrement le shader de Tomb Raider puisquelle se permet de devancer la 7800 GTX qui progresse, par rapport à la 6800 Ultra, grâce à ses pipelines supplémentaires. Par contre dans les 2 autres shaders, les gains sont plus importants que cette augmentation du nombre de pipelines, ce qui prouve que lefficacité de ceux-ci a augmenté : +6% avec le shader 3DMark et +20% avec celui de Far Cry
Nous avons ensuite testé 2 shaders déclairage :

Les gains obtenus sur 7800 GTX sont ici aussi plus importants que laugmentation du nombre de pipelines. En FP32, lefficacité augmente de 22% avec léclairage de type Blinn et de 37% en éclairage de type Phong. Pas mal !
Sommaire
1 - Introduction
2 - Pixel Shader : théorie et pratique
3 - Branchements, Vertex Shader
4 - HDR, Textures, Up/Down
5 - Filtrage et anti-crénelage
6 - La carte, consommation, bruit
7 - Le test, CPU Limited ?
2 - Pixel Shader : théorie et pratique
3 - Branchements, Vertex Shader
4 - HDR, Textures, Up/Down
5 - Filtrage et anti-crénelage
6 - La carte, consommation, bruit
7 - Le test, CPU Limited ?
Vos réactions
Contenus relatifs
- [+] 04/05: Nvidia abandonne son GeForce Partne...
- [+] 27/04: AMD Vega 7nm en labo, Zen 2 échanti...
- [+] 18/04: ASUS AREZ, l'effet GeForce Partner ...
- [+] 10/04: Nvidia : fin du support Fermi et 32...
- [+] 27/03: Pilotes Radeon et GeForce pour Far ...
- [+] 20/03: Pilotes GeForce 391.24 pour Sea of ...
- [+] 20/03: Microsoft annonce DirectX Raytracin...
- [+] 20/03: Radeon Software 18.3.3 beta avec Vu...
- [+] 08/03: 3 millions de GPU vendus pour le mi...
- [+] 08/03: Radeon Software 18.3.1 optimisé pou...