
Intel Pentium 4 E « Prescott »
Publié le 02/02/2004 par Marc Prieur



L´architecture en pratique cache & instructionsAvant de nous attaquer aux performances applicatives du Prescott, nous avons voulu voir quel était son comportement dans trois domaines bien précis, à savoir son cache, linfluence de ce dernier sur les performances et lHyperThreading.
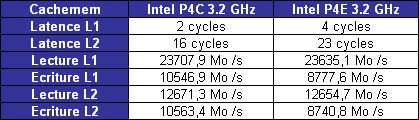
Comme vous pouvez le voir, les temps de latences, exprimés en cycle dhorloges, des caches L1 et L2 (mesurés avec cachemem) sont bien plus importants sur le Prescott que sur le Northwood. Il faut noter que mesurer la latence du cache L1 est complexe, et quil est tout à fait possible que cette latence plus élevée découle dautres paramètres de larchitecture du Prescott.
En terme de bande passante, le Prescott savère aussi rapide en lecture, mais plus lent pour ce qui est de lécriture des données. Les caches du Prescott sont certes doublés, mais ils sont donc également plus lents. Ceci est notamment lié à la volonté quà Intel de monter en fréquence, puisque avec le même temps de latence de 4.7ns, avec 16 cycles de latence comme sur le Northwood on peut atteindre 3.4 GHz, contre 4.9 GHz pour 23 cycles comme sur le Prescott.
Afin de voir quel pouvait être linfluence de la vitesse du cache, nous avons utilisé un petit logiciel de test fournis par nos confrères dOnversity . Ce logiciel a lavantage deffectuer quelques tests parmi lesquels lexécution dune addition, dune multiplication dentier et dune instruction de décalage, le tout avec 3 tables de 40 Ko dune part et 3 tables de 4 Mo dune part. Dans le premier cas, on reste donc au sein du cache L2.
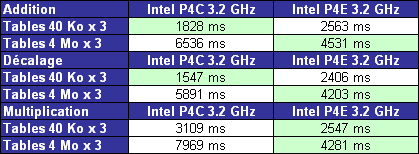
Lorsquon reste au sein du cache L2, le Northwood est pas moins de 40% plus rapide que le Prescott sur une addition, ceci étant dû aux latences trop élevées du cache L2. Par contre, lorsque lon passe sur des tables de taille plus importante, le Prescott est 44% plus rapide, ceci étant dû en partie à la taille du cache et aux améliorations apportées au prefetching matériel du Prescott.
Bizarrement, on remarque la même chose avec linstruction de décalage (shift), cette dernière étant 56% plus rapide sur le Northwood dans le premier cas et 40% plus rapide dans le second cas. Etant donné que ce type dinstruction peut désormais être calculé via une ALU fonctionnant à vitesse double, le Prescott devrait mieux tirer son épingle du jeu.
Pour ce qui est de linstruction imul (multiplication dentiers), le fait de ne plus devoir passer par la FPU est très avantageux puisque même quand on reste au sein du cache L2 le Prescott est 22% plus rapide, cet avantage passant à 86% avec des tables de taille plus importante.
Bref, les fortes latences inhérentes à la mémoire cache du Prescott peuvent dans certains cas être très négatives pour les performances. Selon les applications, ce dernier pourrait être notablement en retrait par rapport au Northwood ...
Sommaire
1 - Introduction
2 - La face visible et cachée du Prescott
3 - Les P4E, Compatiblité
4 - Température et Overclocking
5 - L'archi en pratique cache & instructions
6 - L'archi en pratique HyperThreading
7 - 3d Studio Max et Maya
2 - La face visible et cachée du Prescott
3 - Les P4E, Compatiblité
4 - Température et Overclocking
5 - L'archi en pratique cache & instructions
6 - L'archi en pratique HyperThreading
7 - 3d Studio Max et Maya
Vos réactions
Contenus relatifs
- [+] 09/05: AMD Ryzen 7 2700, Ryzen 5 2600 et I...
- [+] 04/05: Un Coffee Lake 8 coeurs en préparat...
- [+] 27/04: Le 10nm d'Intel (encore) retardé, l...
- [+] 26/04: Jim Keller rejoint... Intel !
- [+] 23/04: MAJ de notre test des Ryzen 7 2700X...
- [+] 20/04: MAJ de notre comparatif CPU géant
- [+] 19/04: AMD Ryzen 2700X et 2600X : Les même...
- [+] 19/04: 2008-2018 : tests de 62 processeurs...
- [+] 13/04: Les AMD Ryzen Pinnacle Ridge en pré...
- [+] 10/04: LGA4189 pour les Xeon Ice Lake !