
Intel Pentium 4 E « Prescott »
Publié le 02/02/2004 par Marc Prieur



 Depuis son lancement en Novembre 2000, larchitecture NetBurst incluse au sein du Pentium 4 a connu une évolution majeure. En effet, du core Willamette de lépoque, on est passé ensuite en Janvier 2002 au core Northwood. On passait alors dune gravure en 0.18µ à une gravure en 0.13µ, de 42 à 55 Millions de transistors, et de 256 à 512 Ko de cache de second niveau. En ce mois de Février 2004, Intel lance, après trois mois de retard, une nouveau core intégrant larchitecture NetBurst, cest le Prescott.
Depuis son lancement en Novembre 2000, larchitecture NetBurst incluse au sein du Pentium 4 a connu une évolution majeure. En effet, du core Willamette de lépoque, on est passé ensuite en Janvier 2002 au core Northwood. On passait alors dune gravure en 0.18µ à une gravure en 0.13µ, de 42 à 55 Millions de transistors, et de 256 à 512 Ko de cache de second niveau. En ce mois de Février 2004, Intel lance, après trois mois de retard, une nouveau core intégrant larchitecture NetBurst, cest le Prescott.La gravure du PrescottLes nouveautés apportées par le Prescott sont diverses. Cette fois, on passe à pas moins de 125 Millions de transistors, gravés en 0.09µ sur un die dune surface de 112mm², contre 131mm² pour le Northwood et 217mm² pour le Willamette. Grâce à cette finesse de gravure, Intel est donc parvenu à avoir un die plus petit, ce qui lui permet de graver plus de processeurs sur une même galette de silicium alors que ces derniers disposent de plus du double de transistors. Le coût de production est donc réduit.


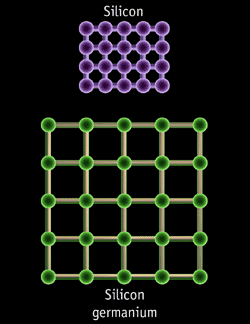
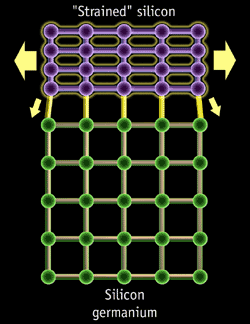
On notera toutefois que contrairement à AMD, Intel nutilise toujours pas de technologie de type SOI (Silicon On Insulator) qui permet déliminer certaines fuites de courant liées à labaissement de la gravure. De son côté, la technologie strained silicon (silicium tendu), permet daccélérer le passage des électrons au sein du transistor en espaçant tout simplement les atomes de silicium. Il est à noter que le 0.09µ devrait nous accompagner pendant plus d´un an et demi, l´arrivée du 0.065µ chez Intel étant prévue pour fin 2005 / début 2006.
La face visible du Prescott
 La micro-architecture NetBurst a également évoluée au sein du Prescott. Ainsi, de 20 étages, le pipeline pour le calcul dentiers passe à 31 étages, contre 10 pour rappel sur ce bon vieux Pentium. La subdivision de certaines parties de lexécution dune instruction a un gros avantage : elle permet daugmenter la fréquence maximale que peut atteindre une architecture donnée, mais au dépend dune efficacité par cycle dhorloge réduite.
La micro-architecture NetBurst a également évoluée au sein du Prescott. Ainsi, de 20 étages, le pipeline pour le calcul dentiers passe à 31 étages, contre 10 pour rappel sur ce bon vieux Pentium. La subdivision de certaines parties de lexécution dune instruction a un gros avantage : elle permet daugmenter la fréquence maximale que peut atteindre une architecture donnée, mais au dépend dune efficacité par cycle dhorloge réduite.Cela est en fait dû aux dépendances inhérentes à un programme informatique, puisque afin dexécuter une instruction il est dans de nombreux cas nécessaire dattendre le résultat de la précédente. Afin dalimenter continuellement le pipeline, il est nécessaire de prédire quel sera ce résultat, cest ce quon appelle la prédiction de branchement. Le problème, cest que lorsque vous faites une erreur dans cette prédiction de branchement, il faut remettre à 0 le pipeline, et plus le pipeline est long, plus cette opération est pénalisante.
Afin de compenser en partie la perte de performance inhérente à lallongement du pipeline, Intel sest attelé à améliorer cette prédiction de branchement. Selon les chiffres fournis par le géant de Santa Clara, sous SPECint_base2000 les erreurs de prédiction de branchement, très pénalisantes en terme de performances, sont réduites de 12.2% sur le Prescott par rapport au Northwood.
Au niveau des unités dexécution, Intel a amélioré la latence des instructions shift et rotate. Ces instructions étant auparavant exécutées telles que des opérations complexes au sein de lALU (unité de calcul dentiers) dédiée à ce type dinstruction. Intel a modifié une des ALU fonctionnant à 2 fois la vitesse du core afin quelle puisse exécuter ce type dinstruction. Intel a également modifié le fonctionnement des unités en ce qui concerne les multiplications dentiers, qui ne passent plus par lunité de calcul en virgule flottante, ce qui évite de perdre du temps dans le transfert à la FPU. Dautres améliorations mineures ont également été apportées, notamment au niveau des schedulers ou du prefetch.
La face visible et cachée du Prescott

Sommaire
Vos réactions
Contenus relatifs
- [+] 09/05: AMD Ryzen 7 2700, Ryzen 5 2600 et I...
- [+] 04/05: Un Coffee Lake 8 coeurs en préparat...
- [+] 27/04: Le 10nm d'Intel (encore) retardé, l...
- [+] 26/04: Jim Keller rejoint... Intel !
- [+] 23/04: MAJ de notre test des Ryzen 7 2700X...
- [+] 20/04: MAJ de notre comparatif CPU géant
- [+] 19/04: AMD Ryzen 2700X et 2600X : Les même...
- [+] 19/04: 2008-2018 : tests de 62 processeurs...
- [+] 13/04: Les AMD Ryzen Pinnacle Ridge en pré...
- [+] 10/04: LGA4189 pour les Xeon Ice Lake !