
NVIDIA GeForce3
Publié le 27/04/2001 par Marc Prieur



Lightspeed Memory ArchitecturePlutôt que d´aborder le problème du fillrate et surtout de la bande passante de manière brute comme il l´avait fait avec le GeForce2 Ultra par exemple, NVIDIA a cette fois ci décidé d´y aller plus finement, grâce à trois fonctions :
- Crossbar Memory Controller
- Lossless Z Compression
- Z-Occlusion Culling
> Crossbar Memory Controller
Sous ce nom très poétique se cache le nom du contrôleur mémoire du GeForce3, ou plutôt les contrôleurs mémoires. En effet, ils sont 4, afin de pouvoir lire et écrire dans le frame buffer par blocs de 64 bits. Jusqu´alors, les lectures / écritures se faisaient en fait par blocs de 256 bits, ce qui n´était pas toujours des plus efficaces puisque certaines données demandées faisait une taille moindre.
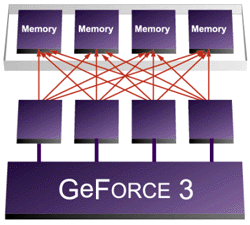
Bien entendu, ces 4 contrôleurs sont capables de communiquer entre eux afin d´accéder a la mémoire par bloc de 256 bits si besoin est. D´après NVIDIA, le Crossbar Memory Controller peut être jusqu´a 4x plus efficace que les contrôleurs mémoire d´ancienne génération : c´est effectivement le cas si toutes les données que l´on veut lire / écrire ne font que 64 bits, mais heureusement ce cas ne représente par une majorité des accès mémoire.
> Lossless Z Compression
Comme son nom l´indique, il s´agit d´une méthode de compression des données de profondeur Z. A titre de rappel, cette donnée est stockée dans une zone mémoire appelée Z-Buffer. Le Z-Buffer permet au chip graphique de savoir si le pixel rendu sera ou non affiché (cad non caché par un autre pixel qui a une profondeur moindre). La lecture de cette donnée Z, qui est codée en 16, 24 ou 32 bits, se fait donc à chaque fois que l´on effectue le rendu d´un pixel, et son écriture se fait lorsque le pixel est déterminé comme ´affichable´. Afin de diminuer le trafic engendré par le Z-Buffer, NVIDIA a donc mis au point cet algorithme de compression non destructeur des données Z-Buffer. Si l´algorithme n´est pas détaillé par NVIDIA, le taux de compression est annoncé à 4 pour 1.
Cette technique n´est pas sans rappeler de Z-Compression de l´HyperZ d´ATI.
> Z-Occlusion Culling
Si cette dénomination ne vous rappelle rien, le Tile Rendering (PowerVR), le Hierarchical Z (Radeon) ou le Hidden Surface Removal (3dfx) vous disent peut être quelque chose : toutes ces techniques ont le même but. Comme vous le savez déjà, dans une architecture graphique traditionnelle, le rendu de tous les pixels est effectué, qu´il soient visibles ou non. C´est la valeur Z qui déterminera ensuite si ce pixel sera visible, et s´il faut donc l´écrire ou pas dans le frame buffer.
Le but du Z-Occlusion Culling est simple : déterminer si un pixel sera visible ou pas au final, afin de savoir s´il est utile d´en effectuer le rendu. S´il s´avère que ce pixel ne sera pas visible, puisque caché par un pixel de mêmes coordonnées x, y qui se trouve plus près, il ne sera pas rendu. Avec les jeux actuels, qui ont une depth complexity 2 (en moyenne deux pixels de mêmes coordonnées X,Y mais de coordonnées Z différentes pour chaque point à l´écran), on peut donc économiser jusqu´a 50% de la bande passante mémoire nécessaire pour le rendu.
L´architecture Lightspeed Memory intègre une quatrième nouveauté, qui s´attaque pour sa part au problème de la bande passante du bus AGP 4x : Les Higher Order Surfaces (également appelés Higher Order Primitives ou Patches), que nous étudieront un peu plus loin.
Sommaire
Vos réactions
Contenus relatifs
- [+] 04/05: Nvidia abandonne son GeForce Partne...
- [+] 27/04: AMD Vega 7nm en labo, Zen 2 échanti...
- [+] 18/04: ASUS AREZ, l'effet GeForce Partner ...
- [+] 10/04: Nvidia : fin du support Fermi et 32...
- [+] 27/03: Pilotes Radeon et GeForce pour Far ...
- [+] 20/03: Pilotes GeForce 391.24 pour Sea of ...
- [+] 20/03: Microsoft annonce DirectX Raytracin...
- [+] 20/03: Radeon Software 18.3.3 beta avec Vu...
- [+] 08/03: 3 millions de GPU vendus pour le mi...
- [+] 08/03: Radeon Software 18.3.1 optimisé pou...