
Actualités informatiques du 22-01-2016
- La GDDR5X standardisée par le JEDEC
- AMD travaille sur un lien à 100 Go/s
- Gigabyte met à jour ses X99 pour Broadwell-E
- Intel fait pression sur ASRock pour SKY OC
- CES: Imagination: ray tracing en démonstration
- CES: Thermaltake lance les Core W100 et P100
| Janvier 2016 | ||||||
|---|---|---|---|---|---|---|
| L | M | M | J | V | S | D |
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
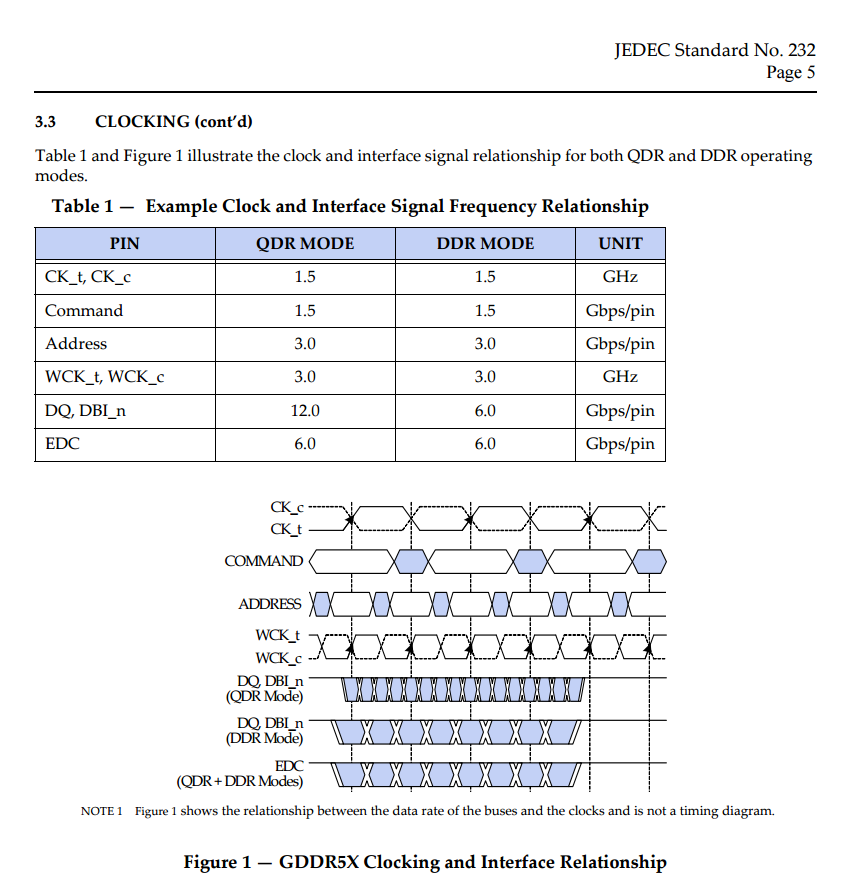
La GDDR5X standardisée par le JEDEC



Le JEDEC vient d'annoncer la publication des spécifications de la GDDR5. Le standard JESD232, daté de novembre 2015, définit la GDDR5X telle qu'elle a déjà été présentée par Micron. La GDDR5X supporte deux modes pour les données, un DDR similaire à celui de la GDDR5 fonctionnant avec un prefetch de 8n et des accès de 256 bits, et un QDR permettant de doubler à fréquence égale le débit avec en contrepartie un prefetch de 16n et des accès de 512 bits. Côté capacité le standard intègre des versions 12 et 16 Gbits là ou la GDDR5 se limitait à 8 Gb.
Le JEDEC indique que la GDDR5X cible des débits allant de 10 à 14 Gbps, soit 320 à 448 Go /s en bus 256 bits, mais Micron avait déjà évoqué la possibilité à terme d'atteindre 16 Gbps soit 512 Go /s. Ce dernier débit sera atteint avec seulement 2 puces de HBM2, une consommation moindre et probablement une meilleure bande passante effective du fait d'accès plus petits de 256 bits (voir 128 bits en mode Pseudo Channel), mais la GDDR5X devrait avoir l'avantage en terme de coût d'autant qu'elle évite de passer par un interposer.
Pour l'instant seul Micron, qui ne s'est pas positionné sur la HBM2 a contrario de SK Hynix et de Samsung, a annoncé qu'il allait produire de la GDDR5X mais rien n'empêche d'autres fabricants membre du JEDEC de se lancer.
AMD travaille sur un lien à 100 Go/s
AMD a indiqué à PC Watch qu'il travaillait sur un nouveau type d'interconnexion capable d'atteindre une bande passante de 100 Go /s. Il pourrait être utilisé entre les GPU, mais aussi entre CPU et GPU voire avec des FPGA spécialisés. AMD n'a pas souhaiter révéler si il était déjà prévu pour la mémoire unifiée et la cohérence des caches. Ce nouveau type de bus s'avère être nécessaire dans le cadre du GPGPU, certains calculs s'avérant limité en multi GPU par le bus PCIe.
Cette initiative n'est pas sans rappeler le NVLink de Nvidia. Annoncé en 2014, cette interconnexion verra le jour sur Pascal dans une première génération avec un débit de 20 Go /s par lien (16 Go /s effectifs) et a priori au moins 4 liens sur les GPU les plus haut de gamme. Il est question sur la seconde génération prévue pour les GPU Volta d'atteindre un total de 200 Go /s alors que cette version prendra en charge la mémoire unifiée.
Alors que NVLink sera intégré dans sa seconde version sur les Power9 d'IBM, on peut compter sur AMD pour intégrer son futur lien sur ses Opteron, voire pour ouvrir cette interconnexion à des tiers sans coût supplémentaire. Reste ensuite à offrir un écosystème assez intéressant afin de les motiver à l'intégrer !
Gigabyte met à jour ses X99 pour Broadwell-E
Gigabyte est le premier constructeur à mettre en ligne des bios pour ses cartes mères X99 Express intégrant le support de Broadwell-E. Afin de ne pas froisser Intel, le constructeur se garde de tout détail et se contente d'indiquer pour les bios F20 de ses cartes mères un support pour un nouveau processeur prévu pour le second trimestre 2016.

Pour rappel, Broadwell-E conserve le Socket LGA 2011-v3 et est compatible avec les cartes mères X99 via une simple mise à jour du bios. Par rapport à Haswell-E on aura un léger gain en IPC, un support officiel de la DDR4-2400 et de 100 à 200 MHz de plus dans la même enveloppe thermique. Mais le point le plus marquant sera l'arrivée d'un Core i7-6950X à 10 curs et 25 Mo de LLC, avec malheureusement un tarif qui pourrait s'envoler
Intel fait pression sur ASRock pour SKY OC
Lors du CES, ASRock avait indiqué à Tom's Hardware qu'il prévoyait de sortir des cartes mères à base de chipsets B150, H170 et C232 permettant l'overclocking des Skylake non-K, Xeon compris pour la dernière donc : les B150 Gaming K4/OC, H170 Pro4/OC, H170 Performance/OC et E3V5 Gaming/OC.
Pour rappel, quasi tous les constructeurs ont sorti de manière plus ou moins officielle des bios pour leurs Z170 activant cette fonction qui a toutefois des contreparties (cf. focus). Pour les autres chipsets selon ASRock une modification matérielle est nécessaire sur la carte mère.
Aujourd'hui ASRock a indiqué à Tom's Hardware qu'il avait décidé de retirer la technologie SKY OC de la liste de fonctionnalités de ces cartes car elle n'est pas conforme aux spécifications des processeurs Skylake.
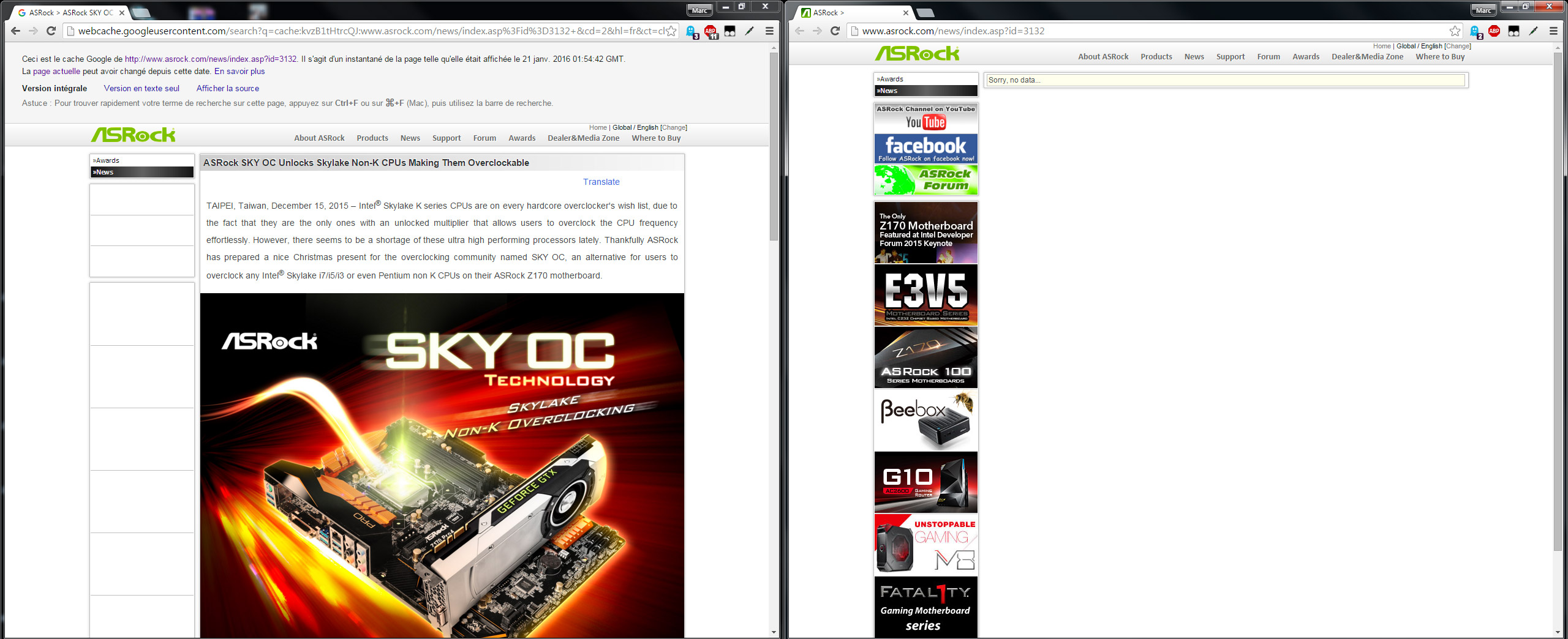
Comme d'habitude chaque mot est important et cela ne veut donc pas dire que la fonctionnalité ne sera pas disponible en pratique. Il semble en effet que Intel ait fait pression sur ASRock, qui était le seul à communiquer officiellement sur la chose, pour que ce soit ne soit plus le cas et ce même sur les Z170. Ainsi la page dédiée à "SKY OC" n'est plus disponible, alors que les pages de bios beta ne mentionnent plus un bios supportant cette fonctionnalité mais étant simplement capable d'améliorer les performances processeur !
CES: Imagination: ray tracing en démonstration
Lors de la GDC 2014, Imagination avait annoncé la possibilité d'intégrer à ses GPU un module d'accélération matérielle du ray tracing, ce que nous avions expliqué en détails ici. A peu près deux ans plus tard, lors de ce CES, nous avons pu observer cette technologie en action
face à un GPU haut de gamme classique.
Pour rappel, Imagination est un fournisseur de technologie et de propriétés intellectuelles, dont les GPU sont par exemple massivement intégrés dans les SoC Apple. Et, à notre connaissance, jusqu'ici aucun de ses clients n'a opté pour l'ajout du module optionnel de ray tracing, développé suite au rachat de Caustic Graphics en 2010. Mais étant donné qu'on n'est jamais aussi bien servi que par soi-même, Imagination a décidé de faire fabriquer en petit volume son propre GPU, le PowerVR GR6500, histoire de disposer d'un kit de développement et de pouvoir présenter quelques démonstrations de sa technologie.

Le PowerVR GR6500, nom de code Wizard, est une variante du PowerVR Series 6 XT(Rogue) équipée du module de ray tracing. Il est cadencé à 600 MHz et intègre 4 clusters pour une puissance de calcul de 150 Gflops (et 300 Gflops en basse précision). Une configuration identique, en dehors du ray tracing, à celle du GPU de l'Apple A8 (iPhone 6) mais cadencée à une fréquence doublée. Imagination nous a précisé que ce PowerVR 6500 a été fabriqué en 28nm, mesure un peu plus de 100 mm² et consomme 4.5 W, nous sommes donc plus proche du monde mobile que de celui des gros PC de bureau.
En ce qui concerne le ray tracing, ce GR6500 est capable de lancer 300 millions de rayons par seconde qui pourront représenter jusqu'à 24 milliards de tests et 100 millions de triangles par seconde. Et le tout avec un rendement énergétique très élevé, les techniques de ray tracing intégrées permettant de regrouper intelligemment les calculs et les accès mémoire.

Pour montrer ce dont est capable sa technologie, Imagination a tout d'abord mis en place un rendu de type path tracing, interactif avec amélioration progressive de l'image comme c'est souvent le cas. Une même scène est alors rendue sur le GR6500 ainsi que sur une GTX 980 Ti sous Blender avec accélération CUDA. Il y a quelques petites différences au niveau de l'interprétation des matériaux mais Imagination précise que la charge est identique, même si elle a probablement été choisie de manière à montrer Wizard sous son meilleur jour.

Le rendu du GR6500 en haut, de la GTX 980 Ti en bas.
Le résultat est sans appel : le PowerVR GR6500 est 5x plus performant que la GTX 980 Ti (qui est un modèle EVGA overclocké) tout en consommant nettement moins. Le système équipé du GPU Power consomme ainsi 10x moins que celui équipé de la GeForce, un écart qui exploserait si nous n'observions que la consommation des GPU.
Un rendu interactif c'est bien, mais un rendu en temps réel c'est encore mieux. Pour cela, Imagination a travaillé avec Unity pour intégrer le support de sa technologie, que ce soit pour un rendu 100% à base de ray tracing, ou hybride qui utiliserait cette approche pour certains éléments tels que les ombres, les réflexions ou encore les transparences.


Deux autres démonstrations étaient ainsi présentées par Imagination. Sur la première, qui tourne sur un GR6500, la géométrie et l'éclairage sont dynamiques et mettent en avant les multiples niveaux de réflexions ainsi que des ombres aux contours parfaits, ce que la rastérisation classique ne parvient pas à obtenir, même en ayant recours à plusieurs niveaux de détails avec les cascaded shadow maps.
La seconde démonstration se contente d'une géométrie fixe mais plus complexe et y ajoute la prise en compte de la réfraction. Pour celle-ci, un système plus musclé a été mis en place avec pas moins de 4 cartes équipées du GPU PowerVR GR6500 qui travaillent de concert. Une configuration globale qui n'est pas si éloignée que ça de ce que l'on pourrait imaginer pour de futurs SoC fabriqués sur des process plus évolués et qui permet à cette démonstration de tourner avec un haut niveau de performances, plus de 30 fps et probablement 60 fps.

Imagination a fourni un kit de développement sur base de cette carte PCI Express équipée du GR6500 à une poignée de développeurs et envisage d'étendre ce programme à d'autres qui en feraient la demande. Car ses ambitions sont sérieuses dans le monde mobile mais pas uniquement.
Comme pour chaque génération de consoles, Imagination compte répondre aux différents appels d'offre de Microsoft, de Sony ou encore de Nintendo pour leurs futurs modèles. Et a bon espoir de convaincre l'un d'eux en jouant sur l'aspect "différenciation". Un argument qui pourrait faire mouche après que deux fabricants se soient retrouvés dans une position délicate suite à une technologie très proche sur la génération de consoles actuelles : en ayant fait le choix d'un GPU AMD similaire mais moins musclé que celui pour lequel a opté Sony, Microsoft a perdu toute possibilité de se démarquer sur le plan graphique.
Le pari d'Imagination est qu'au moins un fabricant de console opte pour un GPU PowerVR de mainère à éviter cette situation, et l'argument du ray tracing pourrait faire la différence. Encore faut-il que les développeurs soient d'accord de faire l'effort nécessaire pour son support, mais Imagination se veut rassurant sur ce point en expliquant qu'utiliser sa technologie demande moins de travail que l'optimisation du rendu des ombres sur les GPU classiques.
CES: Thermaltake lance les Core W100 et P100
Après avoir présenté des prototypes en juin dernier, lors du Computex, Thermaltake vient de débuter la commercialisation de ses énormes boîtiers Core W/P. Les premiers prototypes avaient engendré une mini-tempête dans le milieu, l'américain CaseLabs ayant ouvertement accusé Thermaltake de plagiat avant de se raviser et de s'excuser, ne disposant pas de réel argument légal pour justifier ses premières déclarations enflammées.
Entre temps, Thermaltake a peaufiné le designs de ses boîtiers, mais sans y apporter de modification majeure, et débuté leur commercialisation. Il s'agit de boîtiers très spacieux, clairement orientés refroidissement et modding. Au départ, ce sont les W100 et P100 qui sont introduits.







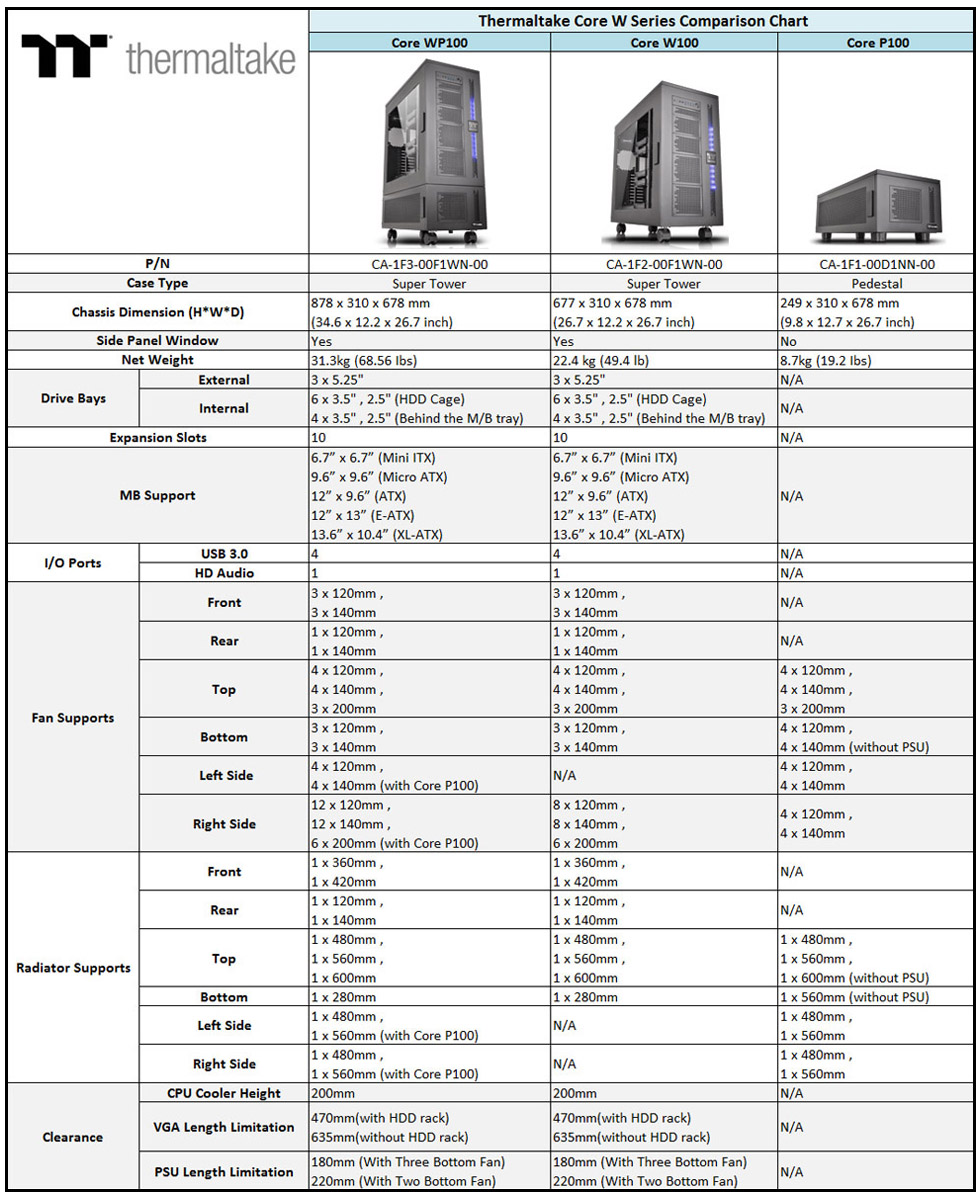
Le W100 est un boîtier très grande tour et élargi avec un peu plus de 7cm d'espace derrière la carte-mère. La photo de l'arrière du boîtier permet d'en apprécier les dimensions inhabituelles : 68x31x68 cm. Le P100 est son boîtier compagnon, ou piédestal, qui permet de l'agrandir si cela était nécessaire avec un volume qui passe alors à 88x31x68 cm.
Etant donné que ces boîtiers Thermaltake sont fabriqués exclusivement en acier (et non en aluminium comme c'est le cas chez CaseLabs), il faut compter 22.4 kg pour ce W100 et 8.7 kg avec le P100 pour un total de 31.1 kg, rien que ça. Thermaltake a eu la bonne idée de livrer des roulettes pour faciliter le déplacement de ces mastodontes.
A quoi est destiné tout cet espace ? Principalement au refroidissement et aux éventuels mods à base de watercooling. Le W100 peut ainsi accueillir jusqu'à 19 ventilateurs de 120 ou 140mm et jusqu'à 9 ventilateurs de 200mm. De quoi pouvoir également accueillir, dans le cadre du watercooling, un radiateur de 600mm sur le dessus, un de 420mm à l'avant et un de 280mm dans le bas du boîtier.
Et si cela s'avérait insuffisant, ou par soucis d'isolation des radiateurs, le P100 entre alors en jeu. Ce piédestal est en fait dédié principalement au refroidissement, même s'il peut également permettre d'accueillir une alimentation et des éléments de stockage. Il est d'ailleurs possible d'empiler plusieurs P100 sur le W100 ou d'en placer un en-dessous et un au-dessus.
Les cartes-mères sont bien entendu supportées jusqu'aux formats les plus imposants, E-ATX et XL-ATX, le ventirad CPU peut atteindre 20cm en hauteur et les cartes graphiques 63cm en longueur, Thermaltake précisant cependant qu'elles doivent se contenter de 47cm lorsque les racks à disques durs sont installés. A ce sujet le fabricant livre 3 blocs de 2 supports 3.5" pour la partie avant de la carte-mère et 4 blocs 3.5" individuels pour la partie arrière de la carte-mère. Tous ceux-ci sont compatibles 2.5".
Vous retrouverez l'ensemble des spécifications dans ce tableau :
Thermaltake annonce une disponibilité pour le mois de février aux Etats-Unis et sur son propre espace de vente TTPremium, lancé pour accompagner ses nouveaux produits haut de gamme, et pour mars en Europe. Les prix publics sont de 330$ pour le W100, 120$ pour le P100 et 440$ pour le WP100 qui regroupe ces deux éléments. Ce n'est pas donné, d'autant plus que ces boîtiers sont vendus nus, sans aucun ventilateur ou autres baies hot-swap.

Un peu plus tard, Thermaltake commercialisera des W200 (550$), P200 (150$) et WP200 (550$), similaires mais avec une largeur presque doublée pour pouvoir accueillir 2 systèmes complets (voire 3 avec un mini-itx), multiplier les disques durs ou encore déporter tout le système de watercooling derrière la carte-mère.