
Intel présente le jeu d'instructions d'Haswell



C'est par l'un de ses blogs qu'Intel a présenté le jeu d'instructions qui animera Haswell, l'architecture utilisée pour les processeurs qui remplaceront Sandy Bridge début 2013 (le tock en 22nm).
Comme a son habitude Intel étend le déjà large jeu d'instructions x86 avec AVX2 (format PDF) . Les nouveautés sont multiples et l'on notera en premier lieu l'arrivée de version 256 bits SIMD des instructions arithmétiques x86 classiques dédiées aux entiers (une partie des instructions dédiées aux flottants ayant été traitée par AVX). Le but du SIMD étant d'appliquer pour rappel une même opération à plusieurs données en simultané, l'extension aux nombres entier est bienvenue. On trouvera également dans le lot des nouveautés présentées des opérations de manipulations sur les bits, pour aider côté cryptographie, et sur le calcul de hash (avec l'apparition de RORX et MULX entre autre). Des opérations de permutations, et de shift sur des vecteurs sont également de la partie.
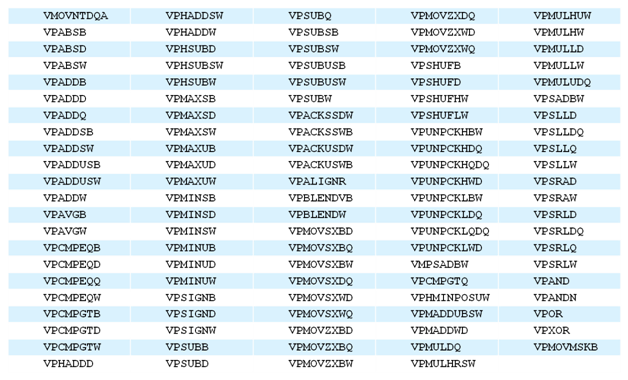
Les instructions entières SIMD 256 bits ajoutées par AVX2
D'autres instructions très "GPU" sont ajoutées avec en premier lieu des Gather qui permettent de charger dans des registres des données non adjacentes en mémoire. Le plus gros morceau reste l'implémentation du FMA, Fused Multiply Add. Pour rappel ces instructions permettent d'effectuer en une instruction une multiplication et une addition (a x b + c). Avec son architecture Bulldozer, AMD sera le premier à proposer le FMA dans un processeur (les AMD FX/Zambezi attendus pour la fin de l'été) avec une implémentation de type FMA4. Intel de son côté se contente d'une version FMA3. La différence entre les deux versions est que le FMA4 permet de stocker le résultat d'une opération dans un registre additionnel (d = a x b +c) là ou en FMA3, le résultat doit être stocké dans l'un des registres utilisés précédemment (par exemple : c = a x b + c). Une incompatibilité qui se paiera du côté des compilateurs et qui crée une différence de plus entre les architectures AMD et Intel.
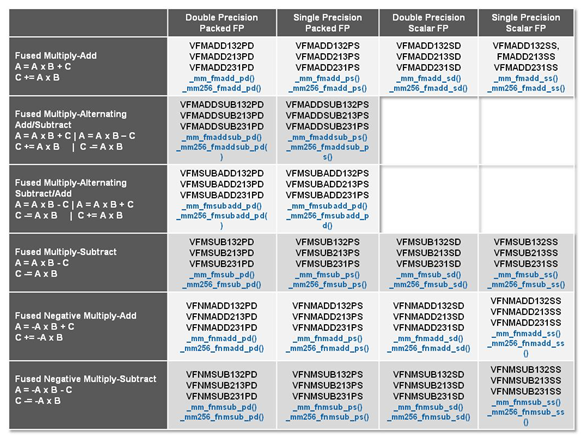
Les instructions FMA3 proposées par AVX2)
Si l'on regrette l'incompatibilité FMA3/FMA4 entre AMD et Intel (en notant que et Intel, et AMD ont changé leur fusil d'épaule sur le sujet, Intel ayant présenté d'abord un FMA4 avant d'arriver au FMA3, AMD ayant fait l'inverse !), AVX2 continue sur la lancée d'AVX en rendant le jeu d'instructions x86 de plus en plus capable d'effectuer des opérations en parallèle de manière efficace. Un modèle intéressant, censé contrer en partie la poussée du GPGPU, mais qui nécessitera un gros travail côté compilateurs pour pouvoir tirer parti des nouvelles instructions.
Contenus relatifs
- [+] 07/02: Windows 10, Meltdown et Spectre : q...
- [+] 26/03: Nouveaux Pentium et Core i3 Haswell...
- [+] 01/10: Perfs avec 2, 4, 6 et 8 curs : 4 j...
- [+] 29/08: Intel Haswell-E, LGA 2011-v3 et DDR...
- [+] 12/08: Intel désactive TSX suite à un bug
- [+] 21/07: +100 MHz pour +0$ sur les Core i3 e...
- [+] 23/06: i3-4370, i3-4160 et Pentium G3460 e...
- [+] 17/06: ASUS permet l'oc du G3258 sur toute...
- [+] 13/06: Core i7-4790K en test, Devil's Cany...
- [+] 11/06: EUs des iGPU Broadwell et Skylake