
AFDS: L'architecture des futurs GPUs AMD!
Publié le 15/06/2011 à 08:00 par Damien Triolet



La première journée du Fusion Summit s'est terminée par une session surprenante durant laquelle Michael Mantor, Senior Fellow Architect, et Mike Houston, Fellow Architect, ont dévoilé la future architecture GPU d'AMD avec de très nombreux détails, ne laissant que quelques éléments spécifiques au rendu 3D de côté.

Michael Mantor, AMD Senior Fellow Architect.
AMD travaille sur cette nouvelle architecture depuis près de 5 ans déjà et a pour objectif principal d'en simplifier le modèle de programmation pour convaincre un maximum de développeurs de se pencher sur la puissance de calcul offerte par les GPUs. Il s'agit également de la première architecture a avoir été influencée en profondeur par l'intégration d'ATI dans AMD et par le projet Fusion.

Cette architecture marque ainsi une rupture significative par rapport aux GPUs actuels en se débarrassant du modèle VLIW, qui repose sur l'exécution simultanée de plusieurs instructions indépendantes, au profit d'un fonctionnement scalaire du point de vue du programmeur. Le front-end, les processeurs de commandes et la structure des caches ont par ailleurs été entièrement revus pour proposer un mode compute plus performant et plus flexible ainsi que pour traiter efficacement le multitâche qui va devenir de plus en plus importants pour les GPUs.
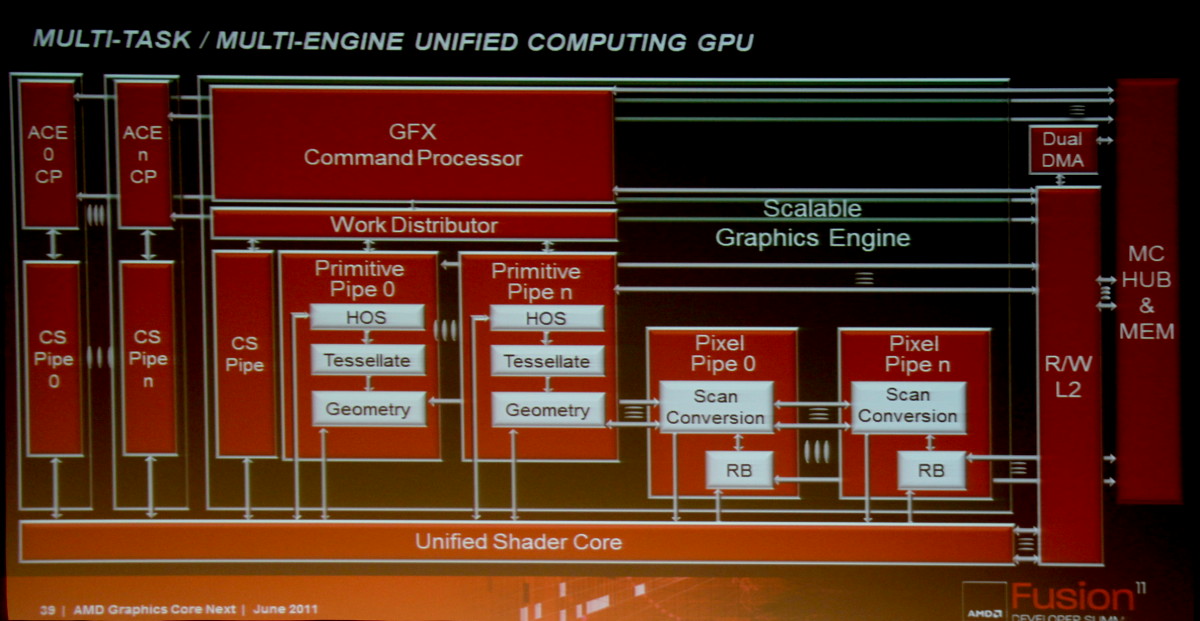
Des Asynchronous Compute Engines (ACE) font ainsi leur apparition pour prendre en charge les tâches compute sans passer par la partie graphique. Cette dernière n'est cependant pas en reste puisque les unités de gestion de la géométrie et des pixels sont parallélisées, ce qui profitera à la tessellation. Contrairement à l'approche de Nvidia, la prise en charge de la géométrie n'est pas distribuée au niveau des blocs d'unités de calcul, mais reste découplée de celles-ci.
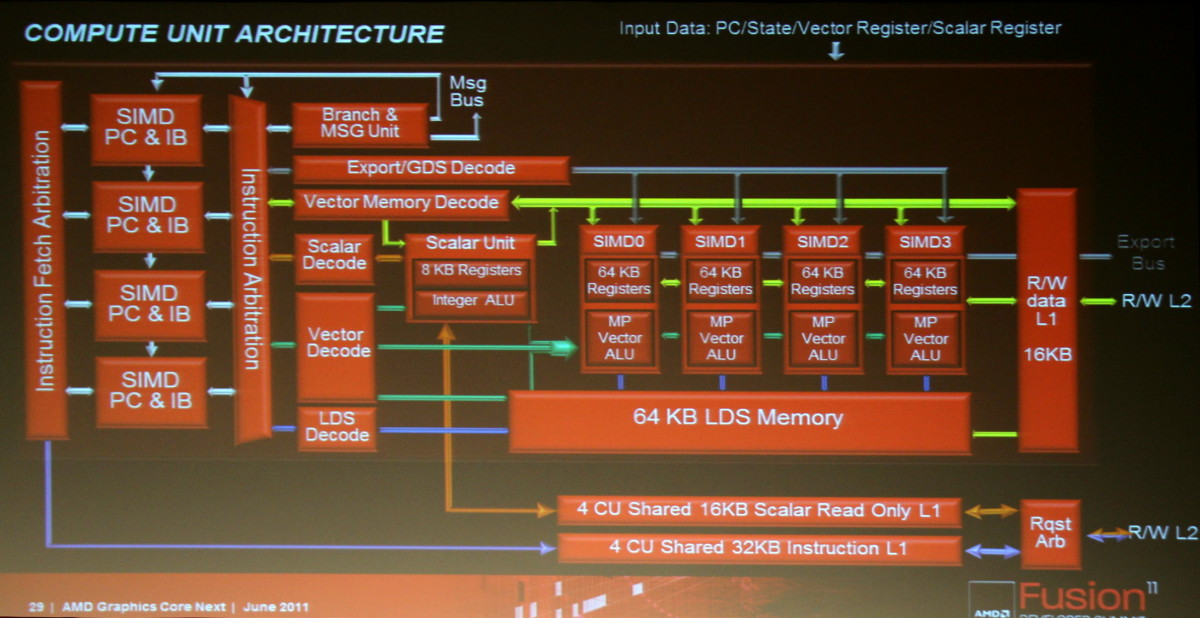
Les SIMDs actuels disparaissent au profit de Compute Units. Chaque CU dispose dorénavant d'une unité scalaire et de 4 petits SIMDs indépendants similaires à ceux des GPUs Nvidia. Grossièrement, un SIMD de Cayman peut exécuter une instruction vec4 sur 16 éléments à chaque cycle alors que chaque CU est capable d'exécuter 4 instructions sur 16 éléments issus de 4 groupes différents plus une instruction scalaire. La puissance de calcul d'une CU est donc similaire à celle d'un SIMD actuel mais devrait gagner nettement en efficacité.
AMD n'a pas voulu préciser quand cette architecture devrait être introduite et s'est contenté d'indiquer que le GPU de Trinity ne serait pas basé sur celle-ci mais bien sur l'architecture vec4 des Radeon HD 6900. Les bruits de couloir nous font cependant état d'une arrivée prévue dès cette année, voire même d'une démonstration du GPU qui l'inaugurera lors du keynote de clôture du Fusion Summit !
Il ne faudrait donc attendre que quelques mois pour voir ce qu'apportera en pratique cette nouvelle architecture prometteuse sur le papier. Si elle facilitera à terme l'optimisation du compilateur GPU, elle demandera cependant un effort important aux équipes chargées des pilotes compte tenu de la rupture avec les GPUs actuels. Concernant le coût de cette nouvelle architecture, AMD nous a indiqué qu'il n'était que légèrement plus élevé que celui des architectures actuelles, certaines parties étant plus complexe mais d'autres simplifiées. Elle ne devrait donc pas être un frein à l'augmentation du nombre d'unités de calcul.
Notez que cette architecture proposera plus de modularité qu'auparavant puisqu'en plus du nombre de CUs, AMD pourra faire varier le nombre d'ACEs, le nombre de pipelines dédiées à la géométrie ou aux pixels, la puissance de calcul en double précision (de 1/2 à 1/16) De toute évidence, la première implémentation devrait être un GPU haut de gamme avec au moins 30 CUs, plusieurs ACEs et un calcul en double précision à demi-vitesse.
Voici donc les grandes lignes de cette future architecture, sur laquelle nous essaierons de revenir plus en détails après le Fusion Summit.
Nous avons publié quelques informations de plus dans une seconde actualité et voici tous les détails dévoilés par AMD sur cette architecture :
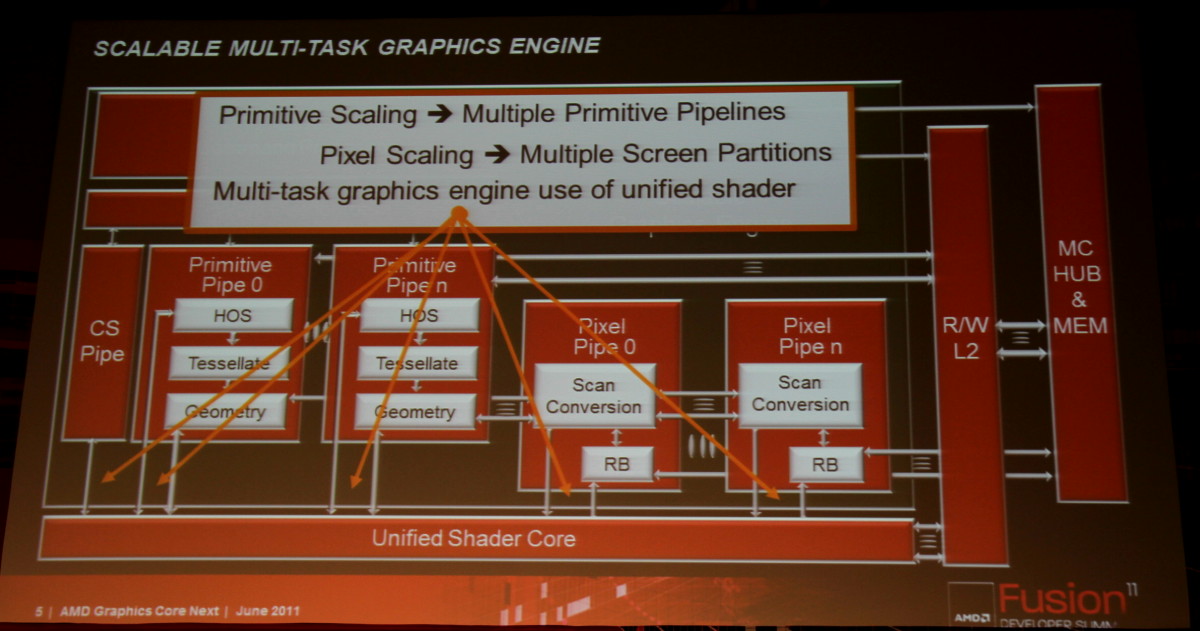














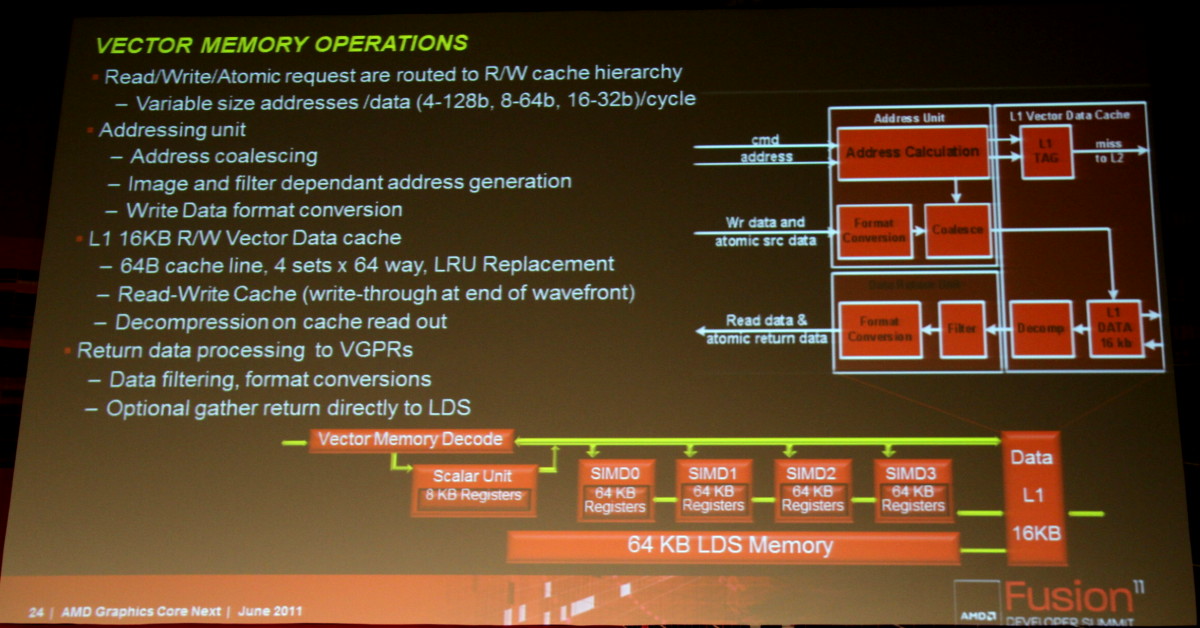






Ainsi que deux exemples de code généré pour l'architecture actuelle d'une part et pour cette nouvelle architecture d'autre part :


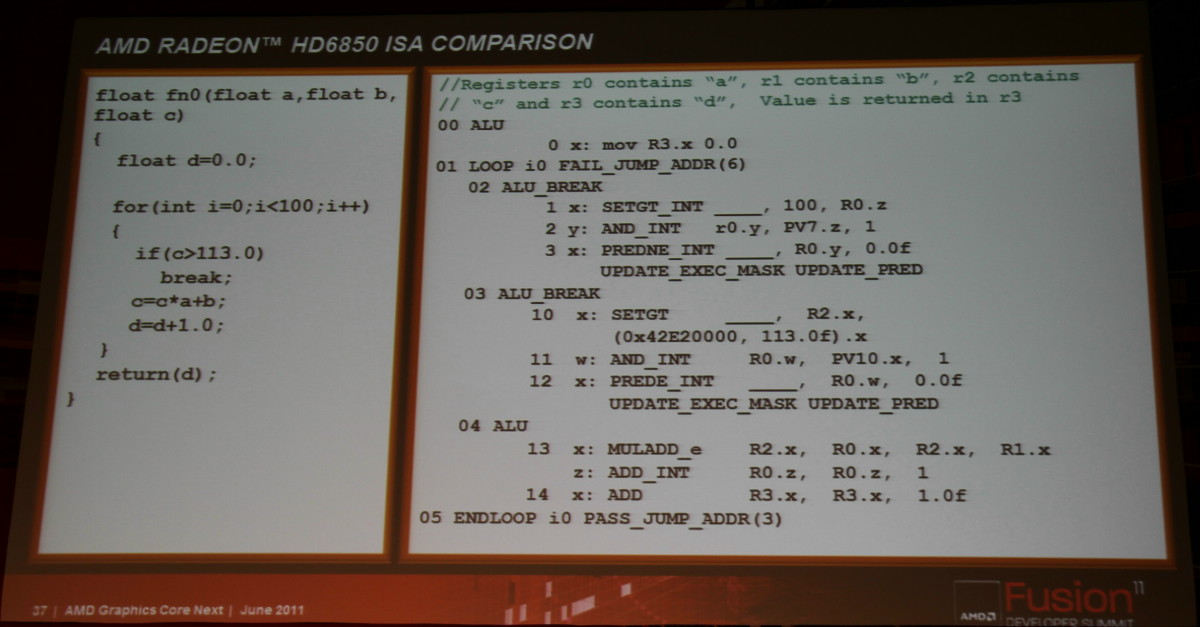
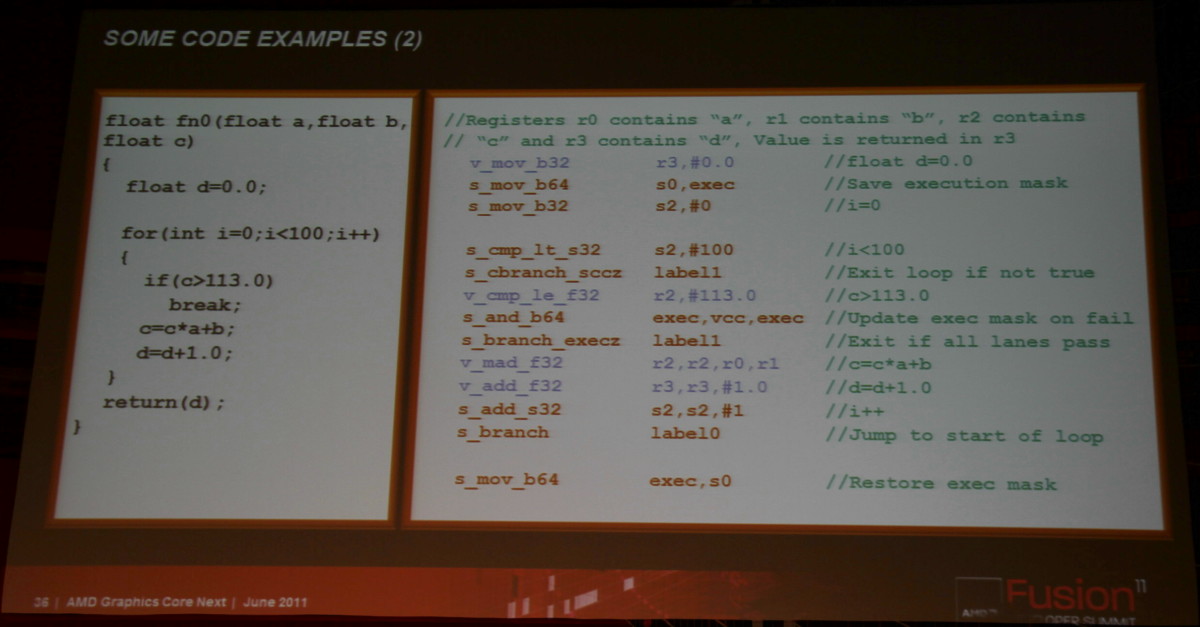
Vos réactions
Contenus relatifs
- [+] 09/05: AMD Ryzen 7 2700, Ryzen 5 2600 et I...
- [+] 27/04: AMD Vega 7nm en labo, Zen 2 échanti...
- [+] 26/04: Jim Keller rejoint... Intel !
- [+] 23/04: MAJ de notre test des Ryzen 7 2700X...
- [+] 19/04: AMD Ryzen 2700X et 2600X : Les même...
- [+] 19/04: 2008-2018 : tests de 62 processeurs...
- [+] 18/04: ASUS AREZ, l'effet GeForce Partner ...
- [+] 13/04: Les AMD Ryzen Pinnacle Ridge en pré...
- [+] 27/03: Pilotes Radeon et GeForce pour Far ...
- [+] 20/03: Microsoft annonce DirectX Raytracin...