
Nvidia GeForce GTX 980 et GTX 970 : le GM204 Maxwell et les Gigabyte G1 Gaming en test
Publié le 19/09/2014 (Mise à jour le 30/01/2015) par Damien Triolet



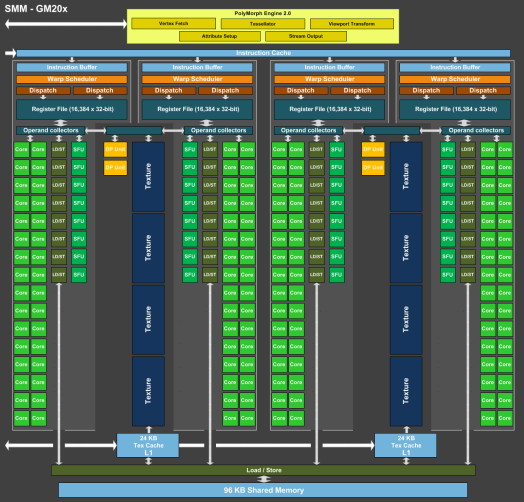
Le SMM en détailPour rappel, Nvidia a revu l'organisation interne des SMM de manière à augmenter leur rendement aussi bien énergétique que par unité de surface. Pour cela, le ratio d'unités de calcul par unité de texturing augmente, une évolution logique depuis quelques années qui permet de s'adapter aux algorithmes de rendu graphique de plus en plus complexes sur le plan arithmétique.
Ensuite, Nvidia se sépare de certains blocs d'unités de calcul qui en pratique étaient peu utilisés, ce qui fait mécaniquement augmenter le rendement des unités restantes. Au final nous passons de 24 flops par unité de texturing sur Kepler (excepté GK208) à 32 flops par unité de texturing sur Maxwell, avec, qui plus est, une meilleure utilisation de cette puissance de calcul.
Pour représenter cela plus en détail, nous avons modifié des diagrammes d'architecture de Nvidia de façon à nous rapprocher de la réalité, au mieux de nos connaissances actuelles des différentes architectures :
| [ SMX GK110 ] [ SMX GK10x ] [ SMX GK20x ] [ SMM GM10x ] [ SMM GM20x ] |
En plus grand :
Comme le montrent ces illustrations, les SMX et les SMM sont subdivisés en 4 partitions. Nvidia a en réalité simplifié le SMM sur 2 points principaux. Premièrement, les blocs de 4 unités de texturing ont été mis en commun par paire de partitions, comme c'était déjà le cas sur le GK208 et le GK20A (Tegra K1) et contrairement aux autres GPU Kepler pour lesquels chaque partition d'un SMX dispose de son propre bloc. C'est ce point qui fait augmenter automatiquement le ratio d'unités de calcul par unité de texturing. Ces dernières sont gourmandes notamment parce qu'elles ont besoin de voies d'accès royales au sous-système mémoire du GPU.
Exploiter les 50% d'unités de calcul principales supplémentaires s'est avéré difficile sur Kepler, probablement parce que le fichier registre n'offre pas suffisamment de bande passante et/ou de flexibilité au niveau des accès à ses différentes banques. Il est dès lors difficile de pouvoir obtenir toutes les opérandes nécessaires pour alimenter l'ensemble de ces unités, et en pratique elles le sont rarement. D'après les chiffres communiqués par Nvidia, ces 50% d'unités de calcul supplémentaires, qui permettent d'afficher une puissance de calcul brute en nette hausse, n'apportent qu'un gain pratique d'un peu plus de 10%.
C'est donc logiquement que Nvidia a supprimé ces unités supplémentaires des SMM. Le travail de l'ordonnanceur et du compilateur s'en trouve simplifié, ce qui permet des gains énergétiques du côté du premier et la possibilité de pousser plus loin certaines optimisations du côté du second.
Au final, en passant du SMX au SMM nettement plus petit, Nvidia a donc supprimé la moitié des unités de texturing, la moitié des unités de calcul 64-bit et un tiers des unités de calcul 32-bit. Malgré cela, en ne conservant que le plus utile aux charges modernes, le SMM conserve des performances proches de celles du SMX, de l'ordre de 90% selon Nvidia. Bien entendu, en jeu et quand le texturing prend beaucoup d'importance, ce nouveau SMM pourra être amené à se contenter de 50% des performances du SMX.
Avec la seconde génération Maxwell, Nvidia a apporté de petites modifications pour rapprocher encore plus les performances d'un SMM de celles d'un SMX. Par rapport au GM107, le cache des unités de texturing, qui fait aussi office de cache L1 pour certains accès mémoire (il ne s'agit pas d'un cache en lecture/écriture polyvalent), passe de 12 Ko à 24 Ko par groupe de 4.
Par ailleurs, la mémoire partagée progresse de 64 à 96 Ko. En pratique, cela ne veut pas dire que les tâches de type calcul (CUDA ou compute shaders) pourront utiliser plus de mémoire. Celle-ci étant attribuée par groupe de threads, cela signifie que plus de ces groupes pourront résider par SMM, ce qui donne plus de possibilités pour maximiser son rendement.
Quelques nouveautésAvec la seconde génération Maxwell, Nvidia a eu un petit peu plus de temps pour implémenter de nouvelles fonctionnalités.
Elles s'articulent principalement autour de la mise à jour des moteurs de rastérisation, ces unités chargées de la découpe des triangles en pixels. Une limitation à leur niveau (absence de support de la fonction Target Independant Rasterization) empêchait jusqu'ici Nvidia de supporter le niveau de fonctionnalité matériel 11_1 de Direct3D bien que la plupart de ses autres spécificités soient bien supportées sur les GPU Kepler et Maxwell de première génération.
Nvidia n'a pas simplement ajouté ce qui manquait au support du niveau 11_1 mais a fait en sorte de faire le maximum pour s'assurer du support du prochain niveau, dont le numéro n'est pas encore connu. Celui-ci sera supporté par Direct3D 12 ainsi que par Direct3D 11.3 qui apportera l'équivalent sur l'API classique de Microsoft, tous les développeurs n'étant pas prêts à migrer vers la nouvelle API de bas niveau.
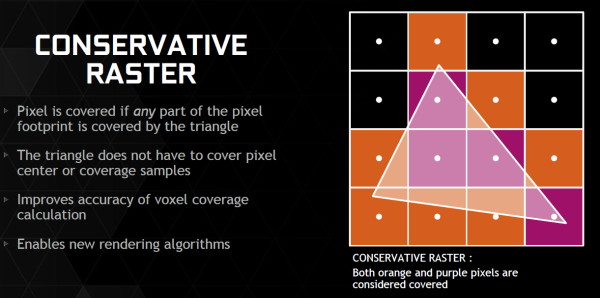
Parmi les nouvelles fonctionnalités de ces futures API, citons la Conservative Rasterization qui permet de vérifier si une primitive est présente dans n'importe quelle petite partie de la zone couverte par un pixel et pas simplement présente en son centre. De quoi pouvoir mieux évaluer sa couverture, ce qui est nécessaire pour certains algorithmes.

Nvidia supporte également les Rasterized Ordered Views et les Volume Tiled Resources. La première fonctionnalité permet de contrôler le respect de l'ordre de rendu des différents éléments de la scène, ce qui est par exemple nécessaire lorsqu'il y a plusieurs niveaux de transparence à respecter (Order Independant Transparency). La seconde transpose dans le monde du voxel le principe des tiled resources ("megatextures").
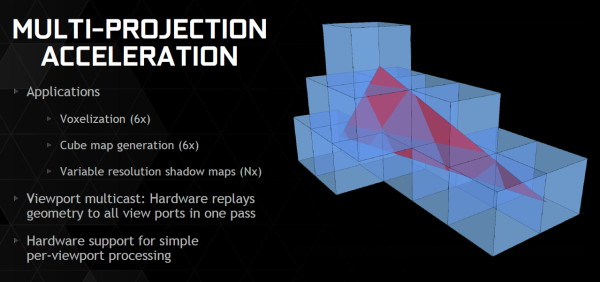
Nvidia combine d'ailleurs le support des Tiled Resources et de la Conservative Rasterization avec quelques petites améliorations matérielles de son cru (notamment l'accélération des projections multiples) pour accélérer efficacement un nouveau type de rendu : le VXGI pour VoXel Global Illumination. Ce nouvel algorithme développé en interne permet d'appliquer un effet de GI en temps réel, sans avoir besoin de le précalculer en amont. Nous tacherons de revenir plus en détails à ce sujet plus tard.

Nvidia s'attend à ce que les petites modifications apportées à son architecture pour l'accélérer se généralisent d'ici quelques temps, autant chez la concurrence qu'au niveau des API graphiques. En attendant, un module VXGI est en développement pour l'Unreal Engine 4 et il sera proposé aux développeurs dès la fin de l'année.
Tant qu'à modifier les moteurs de rastérisation sur plusieurs points, Nvidia en a profité pour améliorer leur flexibilité par rapport aux grilles d'échantillonnage utilisées avec l'antialiasing. Ils sont dorénavant capables de faire varier la position des samples d'une image à l'autre et ou d'utiliser une grille multi-pixels. Cette seconde possibilité permet de répartir différent les samples d'un pixel à l'autre pour éviter un schéma uniforme moins efficace. Nvidia n'exploite pas encore cette possibilité.

Faire varier la position des samples, c'est déjà ce que faisais ATI et AMD avec le Temporal AA. Et c'est ce que va faire Nvidia avec le MFAA qui sera disponible d'ici quelques temps via de nouveaux pilotes. Nvidia ne s'est cependant pas contenté de recopier ce principe mais y a ajouté un filtre plus avancé qui combine downsampling et composante temporale basée sur l'image précédente. De quoi se rapprocher de la qualité du MSAA 4x avec seulement du MSAA 2x avec alternance de la position des samples (MFAA 2x), selon Nvidia. Il faudra vérifier en pratique ce qu'il en est, notamment en mouvement.
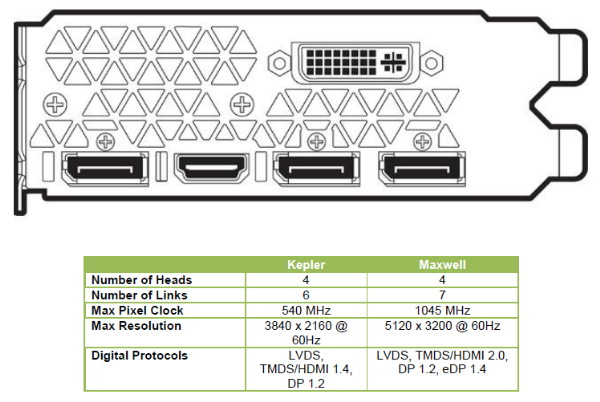
Nouveautés vidéoA noter également le passage au HDMI 2.0, qui apporte une hausse notable de bande passante afin de pouvoir gérer à l'instar du DisplayPort 1.2 les écrans 4K à 60 Hz sans avoir recours à un sous échantillonnage des informations de couleurs comme c'est le cas en HDMI 1.4a. A noter que chacun des 4 contrôleurs d'affichage est désormais capable de gérer plusieurs flux MST de même résolution, ce qui permet par exemple d'utiliser un seul contrôleur pour adresser en DisplayPort un écran 4K "tiled" composé de deux dalles. Cela permet de gérer jusqu'à 4 écrans de ce type, à condition de disposer de 4 sorties DisplayPort (en pratique les fabricants en intègrent jusqu'à 3 à ce jour), contre 2 sur les cartes Nvidia précédentes.
Côté vidéo et H.265, le GM204 profite du décodage hybride introduit avec les GTX 750/750 Ti et depuis étendu aux Kepler par les pilotes. Il s'agit en fait de réutiliser quand c'est possible certaines parties du décodeur matériel H.264 pour le décodage H.265, et quand ça ne l'est pas d'utiliser un décodage logiciel faisant appel aux unités de calcul du GPU.
Le GM204 ne dispose donc pas encore d'un décodeur H.265 complet, qui sera plus efficace côté énergétique, mais chose étonnante il intègre par contre un encodeur H.265 ! Celui-ci n'est pas encore utilisable via des pilotes, mais devrait profiter à terme aux applications de Streaming tel que ShadowPlay. Ce dernier profite par contre déjà d'autres nouveautés introduites dans NVENC, tel que l'encodage en 1440p et même en 2160p à 60 fps jusqu'à 130 Mbps alors qu'on était auparavant limité au 1080p à 60 fps et 50 Mbps.
Sommaire
1 - Introduction
2 - GM204 : 5.2 milliards de transistors
3 - GM204 : le SMM et les nouveautés
4 - GM204 : 3.5 Go + 0.5 Go pour la GTX 970
5 - Performances théoriques : pixels
6 - Performances théoriques : géométrie
7 - Spécifications, la GeForce GTX 980 de référence
8 - Gigabyte GTX 980 & 970 G1 Gaming
9 - Consommation, efficacité énergétique
10 - Bruit et températures
11 - Protocole de test
12 - Benchmark : 3DMark et Unigine
13 - Benchmark : Anno 2070
2 - GM204 : 5.2 milliards de transistors
3 - GM204 : le SMM et les nouveautés
4 - GM204 : 3.5 Go + 0.5 Go pour la GTX 970
5 - Performances théoriques : pixels
6 - Performances théoriques : géométrie
7 - Spécifications, la GeForce GTX 980 de référence
8 - Gigabyte GTX 980 & 970 G1 Gaming
9 - Consommation, efficacité énergétique
10 - Bruit et températures
11 - Protocole de test
12 - Benchmark : 3DMark et Unigine
13 - Benchmark : Anno 2070
14 - Benchmark : Batman Arkham Origins
15 - Benchmark : Battlefield 4
16 - Benchmark : Crysis 3
17 - Benchmark : Far Cry 3
18 - Benchmark : GRID 2
19 - Benchmark : Hitman Absolution
20 - Benchmark : Metro Last Light
21 - Benchmark : Splinter Cell Blacklist
22 - Benchmark : Tomb Raider
23 - Récapitulatif des performances
24 - Overclocking : 1.5 GHz à portée de clic
25 - Conclusion
15 - Benchmark : Battlefield 4
16 - Benchmark : Crysis 3
17 - Benchmark : Far Cry 3
18 - Benchmark : GRID 2
19 - Benchmark : Hitman Absolution
20 - Benchmark : Metro Last Light
21 - Benchmark : Splinter Cell Blacklist
22 - Benchmark : Tomb Raider
23 - Récapitulatif des performances
24 - Overclocking : 1.5 GHz à portée de clic
25 - Conclusion
Vos réactions
Contenus relatifs
- [+] 08/03: GDC: Nvidia parle du Tile Caching d...
- [+] 12/09: La class-action GTX 970 ouverte aux...
- [+] 01/08: Tile rendering pour Maxwell et Pasc...
- [+] 30/07: 30$ pour les acheteurs de GTX 970 ?
- [+] 17/06: Baisses AMD et Nvidia pour vider le...
- [+] 10/06: Computex: Mini-PC Zotac MAGNUS EN98...
- [+] 24/03: GDC: VR: Nvidia Multi-Res Shading e...
- [+] 24/03: GDC: Zotac MAGNUS EN980 avec GTX 98...
- [+] 23/03: GDC: Async Compute : ce qu'en dit N...
- [+] 13/01: CES: Gigabyte passe ses GTX 900 en ...