
Nvidia GeForce GTX 980 et GTX 970 : le GM204 Maxwell et les Gigabyte G1 Gaming en test
Publié le 19/09/2014 (Mise à jour le 30/01/2015) par Damien Triolet



GM204 : 3.5 Go + 0.5 Go pour la GTX 970Un peu plus de 4 mois après son lancement, les spécifications de la GTX 970 ont été rectifiées et de nouveaux détails ont été dévoilés par Nvidia sur la gestion de sa mémoire. Des détails que nous allons explorer sur cette page.
Une partition mémoire plus flexibleLes GPU Kepler et précédents embarquaient un certain nombre de partitions mémoires, souvent résumées à "contrôleurs mémoire de 64-bit". Ces partitions intégraient les interfaces mémoire vers deux puces GDDR5, soit un accès de 64-bit, une certaine quantité de cache L2 et un certain nombre de ROP. Les ROP sont pour rappel ces unités chargées de piloter les écritures de pixels en mémoire, d'effectuer le mélange de couleurs lorsqu'une surface transparente est dessinée par-dessus une autre surface, et de chercher à compresser (sans perte) tout ce qui peut l'être.
Avec Maxwell de seconde génération, Nvidia a revu quelque peu l'architecture de ses partitions mémoire, qui ont globalement été subdivisées en deux. Chacune inclus ainsi 2 interfaces GDDR5 32-bit, pilotées chacune par un sous-contrôleur indépendant, deux blocs de 256 Ko de L2 et deux blocs de 8 ROP. Soit 64-bit, 512 Ko et 16 ROP au total.
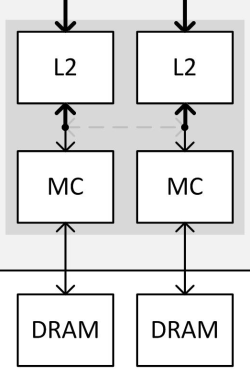
Sur ce schéma, le bloc L2 représente 256 Ko de cache L2 et 8 ROP. Le bloc MC représente un sous-contrôleur 32-bit et l'interface GDDR5.
Si Nvidia a subdivisé en deux les partitions mémoire, c'est pour avoir plus de flexibilité lors de la configuration des puces. Des blocs entiers de celles-ci peuvent être désactivés, soit pour en réutiliser lorsqu'elles souffrent de petits défauts de fabrication, soit pour des raisons de segmentations. Avec le GM204, au lieu de devoir désactiver un contrôleur mémoire de 64-bit avec 512 Ko de L2 et 16 ROP, Nvidia est dorénavant capable de ne désactiver qu'un contrôleur de 32-bit avec 256 Ko et 8 ROP. Une configuration qui gagne ainsi en finesse. Mais ce n'est pas tout.
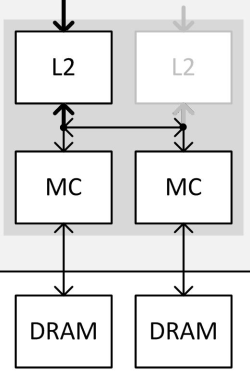
Un petit bus a été implémenté pour rediriger le trafic d'un sous-contrôleur de 32-bit vers le bloc cache L2 de son voisin. Quand il est activé, un unique bloc L2 est ainsi capable de piloter les deux sous-contrôleurs mémoire 32-bit de la partition. L'intérêt de l'opération est évident pour Nvidia : ne pas avoir à réduire la largeur de l'interface mémoire, soit sa bande passante théorique maximale et la quantité de mémoire à laquelle elle peut être associée.
Nvidia nous a précisé que ce bus croisé entre les L2 et les MC n'a été implémenté qu'à cet effet, ce qui démontre à quel point proposer une carte graphique 256-bit / 4 Go a de la valeur sur le plan commercial par rapport à une solution de type 224-bit / 3.5 Go. La GeForce GTX 970 est la première carte graphique équipée d'un GPU qui exploite cette nouvelle flexibilité.
Malheureusement, le doublement de la charge sur un seul ensemble L2 + ROP n'est pas sans conséquences sur le plan des performances comme vous pouvez vous en douter. Nvidia a bien prévu un accès plus large au L2 qui lui permet d'encaisser le trafic de 2 sous-contrôleurs de 32-bit mais ce n'est vrai que dans certains cas. Pour ce cas de figure, Nvidia a ainsi implémenté dans ses pilotes un mode spécial de gestion de la mémoire.
Les accès mémoire plus en détailPour bien comprendre ce qu'il se passe, quelques détails de plus sont nécessaires. Les interfaces mémoire et leurs contrôleurs sont très complexes, et ce qui suit reste évidemment une simplification.
A chaque cycle, chaque bloc L2 est capable de soumettre à son contrôleur mémoire jusqu'à 2 requêtes de lectures de 32 octets ainsi que 2 autres requêtes d'écriture de 32 octets, soit 4 requêtes au total. Parmi ces requêtes (et probablement d'autres qui n'ont pas encore été exécutées), le contrôleur en choisit une, celle qui permet une utilisation optimale des accès mémoire, et l'exécute. Une seule requête de 32 octets par cycle peut être exécutée par chaque contrôleur mémoire.
Précisons que le bloc L2 fonctionne suivant un domaine de fréquence propre, différent de la fréquence GPU classique et de la fréquence de l'interface mémoire. Nvidia ne nous a pas communiqué sa fréquence mais nous a indiqué qu'elle était bien supérieure à 875 MHz, soit à la moitié de celle de l'interface mémoire qui est de 1750 MHz sur les GeForce GTX 980 et 970. Une puce GDDR5 32-bit débite des morceaux de 32 octets tous les deux cycles (à 1750 MHz), la fréquence du bloc L2 est donc au moins suffisante pour encaisser le flux de données.
Le nombre de requêtes soumises par cycle par un bloc L2 étant bien plus important que le nombre de requêtes exécutables par un contrôleur mémoire, chaque L2 est en théorie capable de piloter simultanément deux contrôleurs mémoires. Par contre, d'après les explications de Nvidia, qui manquent de détails sur ce point, des requêtes d'un même type ne pourraient pas être envoyées vers deux contrôleurs différents. Par exemple il ne serait pas possible de demander une requête en lecture à chacun. Le seul moyen d'exploiter ces deux contrôleurs en parallèle serait donc d'envoyer des demandes de lectures à l'un et d'écritures à l'autre.
L'organisation de la mémoireLes données sont en règle générale placées en mémoire de manière à profiter de toute l'étendue de l'interface et donc d'une bande passante maximale. L'espace mémoire est réparti équitablement à travers tous les contrôleurs mémoire. Par exemple, chaque contrôleur mémoire ne s'occupe pas de textures particulières, mais chaque texture est répartie sur l'ensemble des contrôleurs mémoire.
Si vous combinez ceci avec la limitation décrite dans le paragraphe précédent, vous comprendrez qu'un problème va se poser. Si une donnée est répartie sur l'ensemble de la mémoire alors qu'une partie de celle-ci ne peut être lue en même temps qu'une autre, cela implique qu'un large accès devra se faire en deux temps. De quoi diviser la bande passante par deux dans le pire des cas. Un pire des cas qui aurait probablement été courant et aurait fortement impacté les performances de la GeForce GTX 970.
Pour éviter ce problème, Nvidia divise l'espace mémoire en deux. Le principal est interfacé à 224-bit et comprend 3.5 Go de mémoire. Les données sont principalement réparties à travers cet espace mémoire. Un second espace mémoire interfacé en 32-bit et doté de 0.5 Go de mémoire, prend place à côté et n'est exploité que quand l'espace principal est rempli.
Si l'occupation mémoire est inférieure à 3.5 Go, seul l'espace principal est utilisé par le GPU, ce qui évite de rencontrer un conflit dans les accès qui pourrait pénaliser lourdement la bande passante pratique. Par contre cela revient à limiter l'interface mémoire de manière ferme à 224-bit et à réduire ainsi de 12.5% la bande passante disponible.
Lorsque l'occupation mémoire dépasse 3.5 Go, les 512 Mo supplémentaires font en quelque sorte office de réserve de mémoire de secours, avant de devoir passer par le bus PCI Express pour aller puiser dans la mémoire centrale. Ces accès mémoire sont beaucoup plus lents vu que l'interface chute de 224-bit à 32-bit.
Dans certains cas des accès peuvent se faire en parallèle entre les deux espaces mémoires (lecture dans l'un, écriture dans l'autre), mais de toute évidence c'est suffisamment rare pour que ce second espace mémoire ne soit exploité qu'en dernier recours par Nvidia soit quand ses faibles performances restent préférables à celles de la mémoire centrale. En d'autres termes, Nvidia n'estime pas qu'utiliser ce second espace mémoire permet d'obtenir en pratique une bande passante supérieure à celle d'un bus 224-bit. Nous devons donc considérer la GeForce GTX 970 comme une carte graphique équipée d'un bus 224-bit avec 3.5 Go de mémoire rapide et 0.5 Go de mémoire lente.
C'est similaire à ce qui se passait avec les GPU Fermi et Kepler associés à une mémoire asymétrique (puces de mémoire de plus grosse capacité sur certains contrôleurs), si ce n'est que l'asymétrie n'est pas présente physiquement sur le PCB de la carte graphique. L'avantage principal est de permettre à Nvidia de pouvoir mettre en avant un bus de 256-bit. Le comportement de la GTX 970 aurait probablement été similaire, voire identique, si son interface mémoire était physiquement de 224-bit mais avec un module mémoire de 1 Go contre 512 Mo pour les 6 autres (au lieu de 8 modules de 512 Mo interfacés en 256-bit).
Un exercice d'équilibristes pour les pilotes et l'OSIl revient aux pilotes à l'OS de gérer tout cela au mieux, encore une fois, à peu près de la même manière que pour les cartes précédentes équipées d'une mémoire asymétrique (GTX 660 par exemple). Cela n'a pas été un gros problème pour ces cartes et il n'y a pas de raison que la GTX 970 en souffre plus. Mais il est évident que l'efficacité et les performances pourront être moindres quand la quantité de mémoire allouée et réellement utilisée s'approche de la limite.
Il est important de rappeler une fois de plus qu'il faut faire la distinction entre mémoire allouée et mémoire réellement utile. Tant qu'il reste de la place en mémoire, certaines données qui ne sont plus utilisées mais l'ont été auparavant, vont rester en mémoire. Un principe qui permet de disposer de celles-ci directement par la suite au cas où cela serait nécessaire. Mais effacer des textures non-utilisées et les retransférer par la suite n'est pas un gros problème, à moins bien entendu que cela ne se fasse de façon incessante.
Avant d'utiliser le second espace mémoire de 0.5 Go, les pilotes et l'OS font d'abord en sorte d'essayer, plus ou moins agressivement, de faire de la place dans l'espace principal de 3.5 Go. C'est pour cette raison que dans certains cas il est possible d'avoir l'impression que la quantité de mémoire plafonne à 3.5 Go. C'est tout simplement parce que Nvidia fait en sorte, si possible, de n'utiliser que la mémoire la plus performante.
Si une quantité supérieure à 3.5 Go est estimée utile, alors les 512 Mo supplémentaires sont exploités puisqu'ils restent plus rapides que la mémoire centrale, tant en termes de bande passante que de latence. Il revient dans ces cas-là aux pilotes à essayer de faire en sorte que les données les plus importantes sur le plan des performances ne se retrouvent pas dans la partie lente de la mémoire. Un système d'heuristiques générales est utilisé pour aider le pilote à opter pour une bonne stratégie et des optimisations spécifiques peuvent être implémentées pour certains jeux et certaines conditions.
Nvidia n'a pas communiqué de détails sur la façon dont le pilote gère tout cela en pratique. Nous avons par contre pu observer qu'en SLI, le pilote essaye plus agressivement de ne pas dépasser 3.5 Go. Globalement, il nous a été difficile de prendre en défaut la GTX 970 et nous ne prenons pas trop de risques en concluant que les pilotes s'en sortent très bien dans les situations classiques, voire difficiles. Il est par contre impossible de garantir que ce sera toujours le cas et il est certain qu'une GTX 970 ne peut être aussi efficace qu'une GTX 980 lorsque 4 Go de mémoire sont utiles.
Sommaire
1 - Introduction
2 - GM204 : 5.2 milliards de transistors
3 - GM204 : le SMM et les nouveautés
4 - GM204 : 3.5 Go + 0.5 Go pour la GTX 970
5 - Performances théoriques : pixels
6 - Performances théoriques : géométrie
7 - Spécifications, la GeForce GTX 980 de référence
8 - Gigabyte GTX 980 & 970 G1 Gaming
9 - Consommation, efficacité énergétique
10 - Bruit et températures
11 - Protocole de test
12 - Benchmark : 3DMark et Unigine
13 - Benchmark : Anno 2070
2 - GM204 : 5.2 milliards de transistors
3 - GM204 : le SMM et les nouveautés
4 - GM204 : 3.5 Go + 0.5 Go pour la GTX 970
5 - Performances théoriques : pixels
6 - Performances théoriques : géométrie
7 - Spécifications, la GeForce GTX 980 de référence
8 - Gigabyte GTX 980 & 970 G1 Gaming
9 - Consommation, efficacité énergétique
10 - Bruit et températures
11 - Protocole de test
12 - Benchmark : 3DMark et Unigine
13 - Benchmark : Anno 2070
14 - Benchmark : Batman Arkham Origins
15 - Benchmark : Battlefield 4
16 - Benchmark : Crysis 3
17 - Benchmark : Far Cry 3
18 - Benchmark : GRID 2
19 - Benchmark : Hitman Absolution
20 - Benchmark : Metro Last Light
21 - Benchmark : Splinter Cell Blacklist
22 - Benchmark : Tomb Raider
23 - Récapitulatif des performances
24 - Overclocking : 1.5 GHz à portée de clic
25 - Conclusion
15 - Benchmark : Battlefield 4
16 - Benchmark : Crysis 3
17 - Benchmark : Far Cry 3
18 - Benchmark : GRID 2
19 - Benchmark : Hitman Absolution
20 - Benchmark : Metro Last Light
21 - Benchmark : Splinter Cell Blacklist
22 - Benchmark : Tomb Raider
23 - Récapitulatif des performances
24 - Overclocking : 1.5 GHz à portée de clic
25 - Conclusion
A lire également




Vos réactions
Contenus relatifs
- [+] 08/03: GDC: Nvidia parle du Tile Caching d...
- [+] 12/09: La class-action GTX 970 ouverte aux...
- [+] 01/08: Tile rendering pour Maxwell et Pasc...
- [+] 30/07: 30$ pour les acheteurs de GTX 970 ?
- [+] 17/06: Baisses AMD et Nvidia pour vider le...
- [+] 10/06: Computex: Mini-PC Zotac MAGNUS EN98...
- [+] 24/03: GDC: VR: Nvidia Multi-Res Shading e...
- [+] 24/03: GDC: Zotac MAGNUS EN980 avec GTX 98...
- [+] 23/03: GDC: Async Compute : ce qu'en dit N...
- [+] 13/01: CES: Gigabyte passe ses GTX 900 en ...