
Les derniers contenus liés au tag TSX
AMD détaille l'architecture de Zen
Intel désactive TSX suite à un bug
Les instructions TSX absentes des Core K/R !
AMD détaille l'architecture de Zen



Comme annoncé, AMD a profité de la conférence Hot Chips pour dévoiler les détails de l'architecture des cores CPU Zen, utilisée par ses prochains processeurs. AMD avait déjà dévoilé la semaine dernière quelques grandes lignes, cette fois on dispose de beaucoup plus de détails techniques.
Notez qu'en ce qui concerne les versions disponibles des puces, le nombre de cores, la fréquence, ou le fonctionnement du contrôleur mémoire, il faudra attendre, AMD ne dévoilera ce type de détails qu'ultérieurement. On a tout de même droit à nombre de détails techniques.
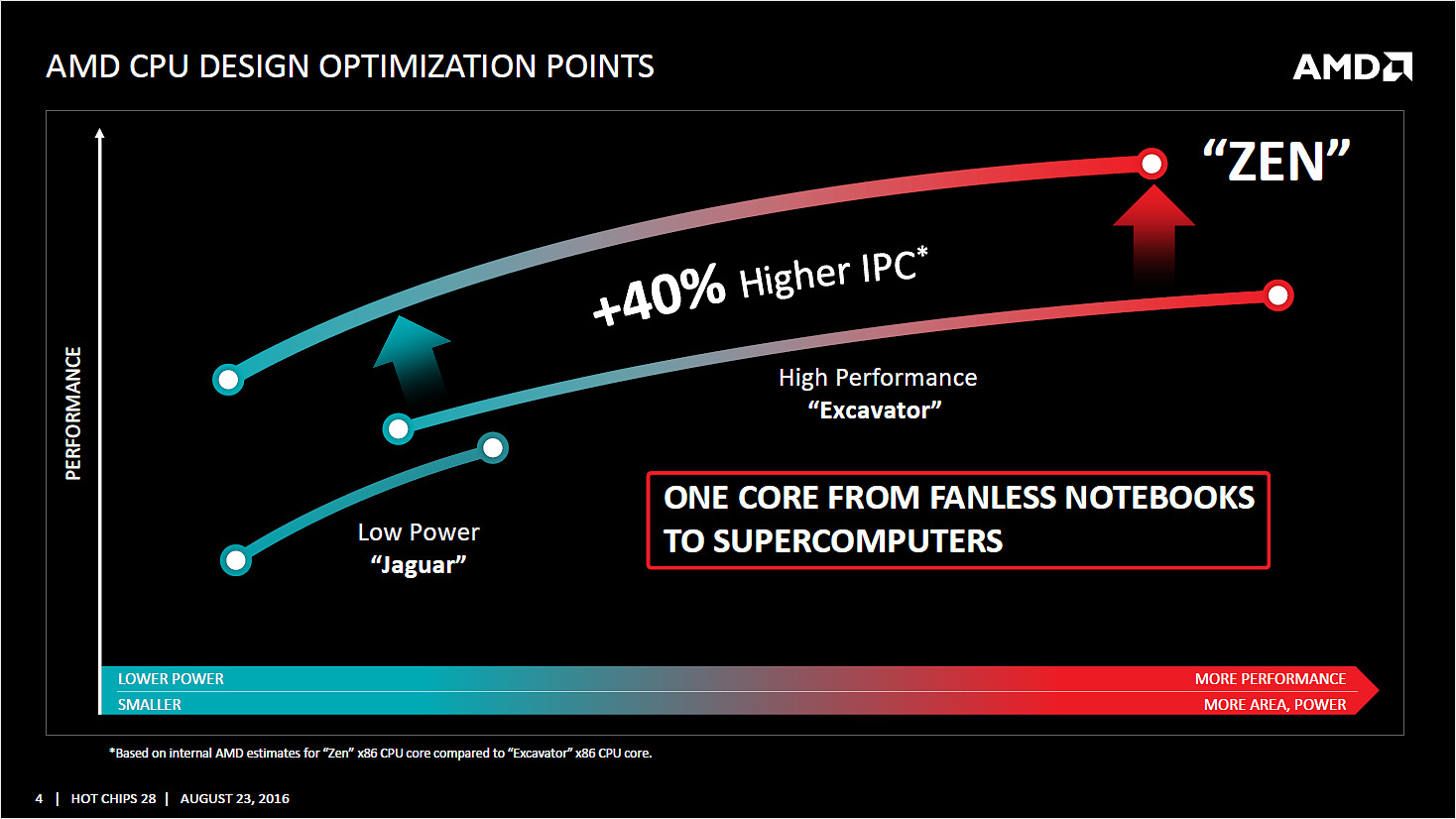
Le message de base d'AMD est de dire que l'architecture est repartie d'une feuille blanche, même si AMD concède avoir réutilisé certains blocs fonctionnels de ses architectures précédentes. En pratique, Zen aura été développé pour remplacer intégralement Jaguar et Excavator, ce qui laisse penser qu'on verra Zen décliné dans de larges gammes de TDP dans les mois à venir.
Le jeu d'instruction

Avant d'entrer dans les détails, un point sur les jeux d'instructions. AMD se met à jour en supportant à peu près toutes les extensions existantes, on retrouve ainsi AVX et AVX2, l'accélération des instructions SHA, mais aussi des choses plus originales comme les instructions de mémoire transactionnelle (TSX), introduites avec assez peu de succès par Intel pour Haswell. AMD rajoute en prime deux instructions, dont une pour libérer une ligne de cache, et l'autre pour combiner des pages mémoires. AMD est donc aligné sur ce que proposait Intel jusque Broadwell, Skylake n'ajoutant que SGX et MPX dont l'utilisation est plus particulière.
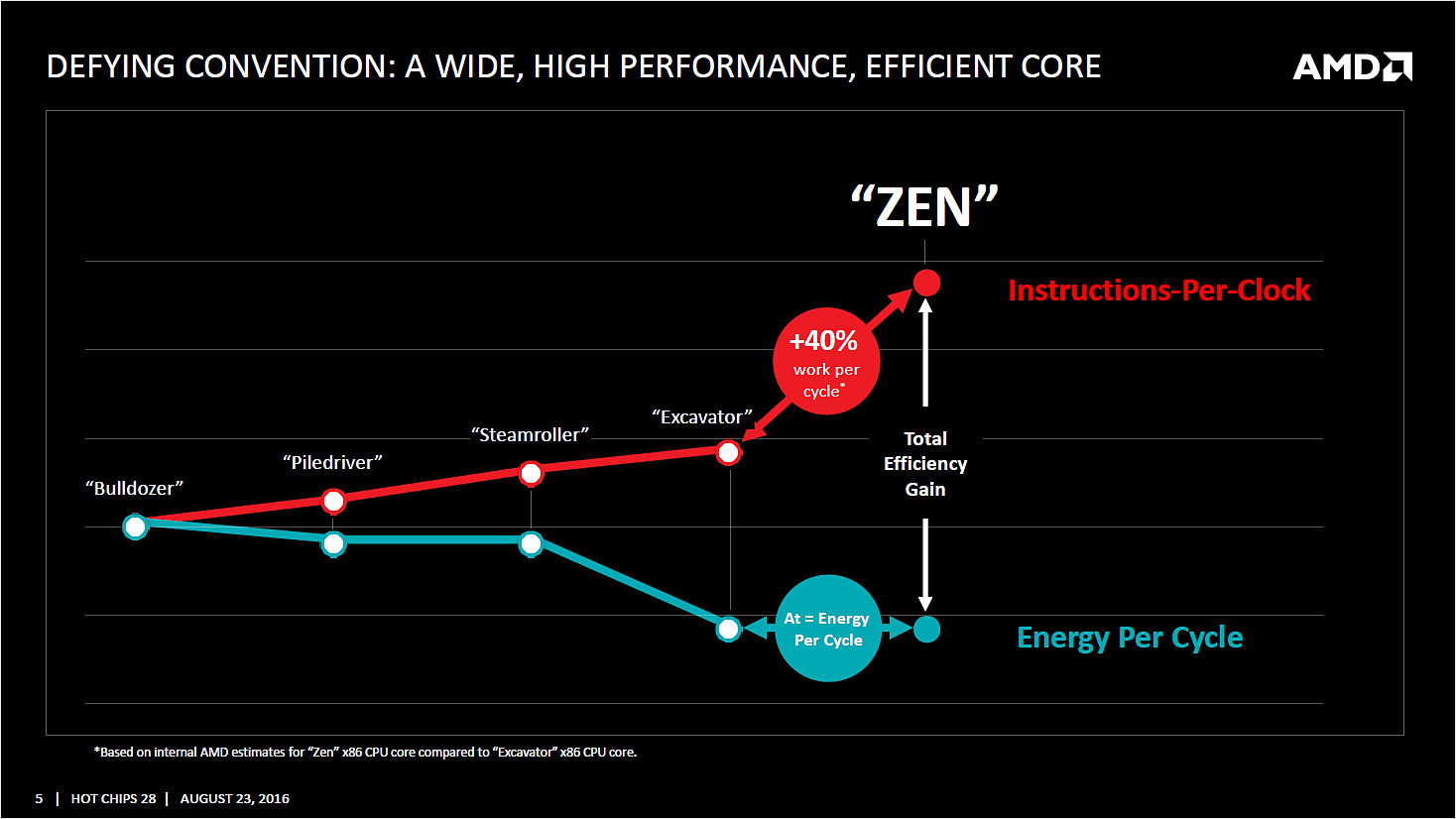
Zen dans les grandes lignes

Ce schéma des grandes lignes avait déjà été présenté mais désormais AMD y accole beaucoup plus de détails. Pour rappel ce schéma commence en haut à droite, avec la partie Branch Prediction ou les instructions arrivent avant d'être décodées. Le point important à retenir est qu'AMD distingue clairement le chemin "Integer" (bloc rouge, opérations sur les nombres entiers, et toutes les opérations classiques comme les boucles, etc...) et le chemin "Floating Point" (bloc orange, opération sur les nombres à virgules). Ils disposent de chaque côté de leurs propres schedulers et Mike Clark, l'architecte en chef de Zen qui a effectué la présentation pour AMD les décrit comme des coprocesseurs indépendants.
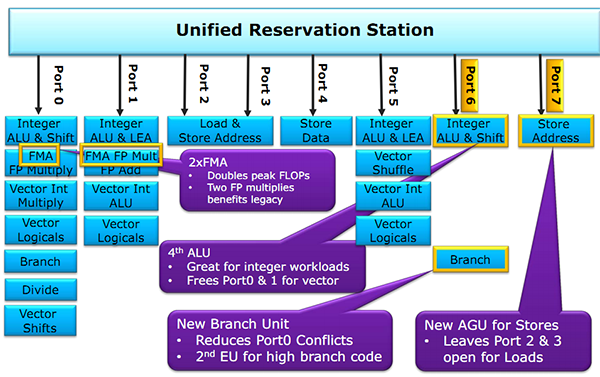
Schéma de fonctionnement des Haswell avec leurs ports d'exécution qui mélangent entiers et flottants sur les ports 0 et 1
Comme vous pouvez le voir ci dessus, il s'agit d'une implémentation qui diffère de ce que propose Intel sur ses architectures Core ou les instructions flottantes sont traitées sur les mêmes ports que les autres instructions (un port peut regrouper plusieurs unités d'execution), avec un scheduler unique. Par le passé, cette scission était nécessaire pour AMD, l'architecture Bulldozer regroupait dans un module deux blocs "Integer" et partageait un seul bloc "Floating Point". Ce qui ressemblait a une bonne idée s'est heurtée à de nombreux problèmes sur Bulldozer et ses dérivés. AMD a voulu conserver l'idée de la séparation tout en résolvant les problèmes restant, nous y reviendrons.
Le front-end

Tout en haut du graphique d'architecture précédent, on retrouve la partie du front end qui récupère (fetch) les instructions. Son rôle est d'extraire les instructions à exécuter, la prédiction de branchements (on parle de conditions, si elle est vraie, effectue ceci, sinon, effectue cela) tentant de déterminer lesquels seront nécessaires. Le TLB (un cache pour traduire les adresses mémoires virtuelles) est intégré et tout le mécanisme a été amélioré pour être plus efficace en ajoutant une table pour les adresses de retour des branches (l'endroit ou l'exécution doit se poursuivre à la fin de la branche, le bloc d'instruction exécuté après la condition).
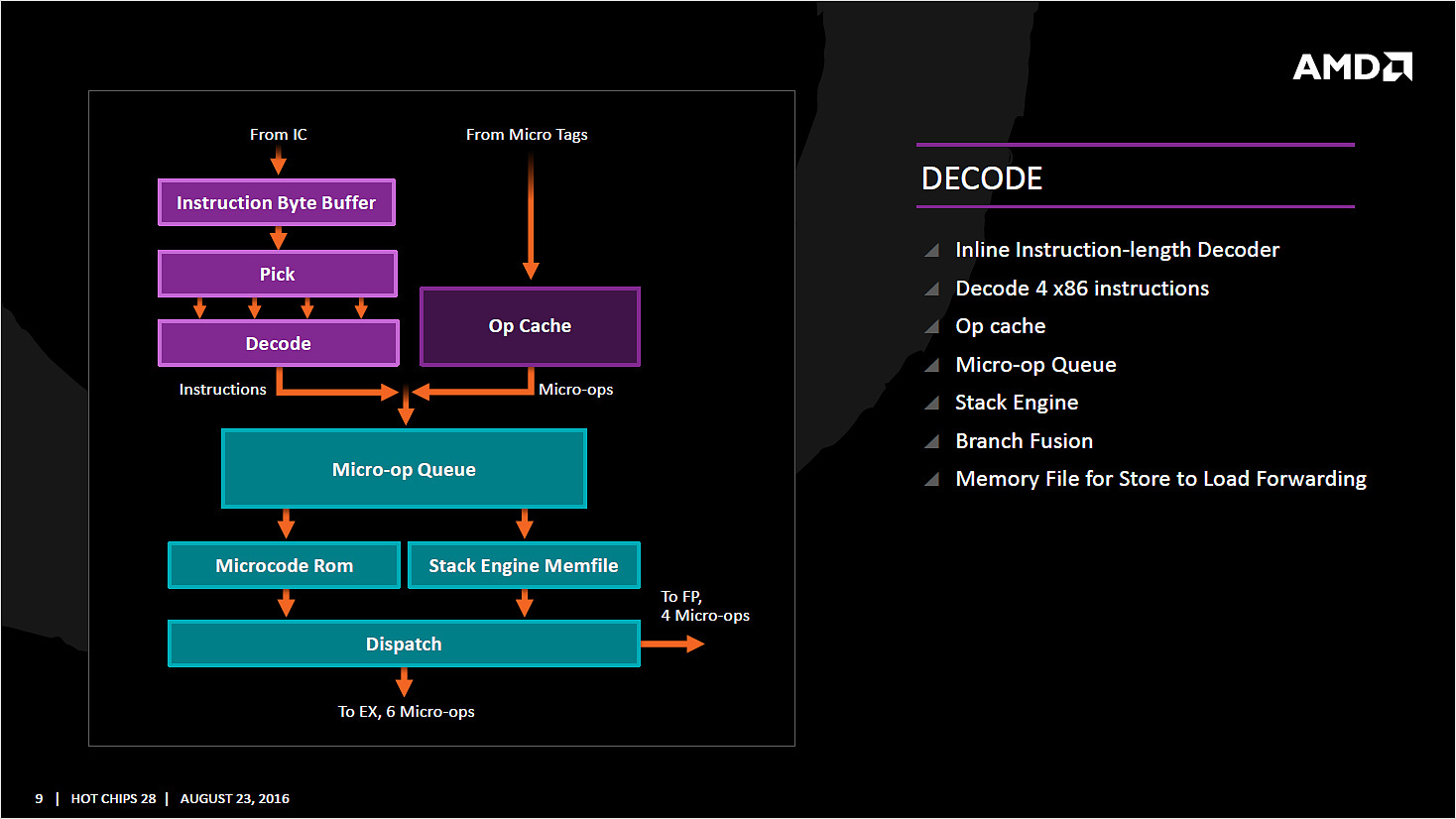
Les instructions récupérées vont ensuite être placées dans le cache d'instruction avant d'être décodées. C'est ici que les instructions x86 sont lues par le processeur, qui les transforme en des micro-opérations (micro-op) qui seront exécutées par la suite dans le pipeline. Les décodeurs sont capables de traiter jusque quatre instructions par cycle (c'est équivalent à ce que propose Intel sur Haswell et Skylake) qui sont transformés en jusque 6 micro-op. Certaines instructions peuvent être fusionnées en une seule micro-op (notamment celles de branchements), la encore les similarités avec ce que propose Intel sont fortes.
Comme chez Intel, AMD utilise un cache qui stocke la correspondance entre une instruction décodée et la micro opération qui en est issue. Le jeu d'instruction x86 comportant un bon millier d'instructions de tailles variables, l'idée est de garder en cache les instructions les plus récemment décodées en mémoire pour pouvoir les traduire automatiquement en micro-op sans repasser par la case décodage. Cela permet d'ajouter plusieurs micro-op supplémentaires par cycles a traiter.
Par rapport à ses architectures précédentes, AMD dit avoir "significativement" augmenté la taille de son Op Cache et que ce seul changement est responsable d'une grande partie des gains d'IPC et de consommation. On y retrouve une logique semblable aux évolutions architecturales que l'on a vu à la concurrence : le front end joue un rôle excessivement important dans les architectures x86 sur les performances du reste de la puce. Le voir soigné de la sorte est plutôt une bonne nouvelle pour Zen même si comme toujours nous réserverons notre jugement en pratique !
On notera que les micro-ops sont placées dans une file, ou plus exactement deux files. AMD implémente pour rappel le SMT (Simultaneous Multi Threading) qui permet de gérer deux threads par coeur (l'HyperThreading est le nom marketing de l'implémentation SMT d'Intel). La file de micro-op est ainsi scindée en deux (ce qui est identique à ce que fait Intel pour Sandy Bridge et Skylake, Haswell ayant utilisé une file commune). Les instructions vont enfin être dispatchées vers les ports. En pratique 10 micro ops peuvent être envoyées (6 vers la partie "Integer" de la puce, 4 vers la partie "Floating Point"), soit deux de plus que sur Haswell (Intel ne nous a pas donné l'information pour Skylake).
Les unités d'executions

Les micro-op vont être dispatchées vers 6 files d'exécution (l'équivalent des ports d'Intel) dont la taille a été significativement augmentée (14 entrées par file, soit 84 pour cette partie de la puce, Skylake en compte 97 en tout mais il faut ajouter celles dédiées aux opérations FP, nous y reviendrons). AMD dispose de deux files dédiées aux opérations mémoires (AGU, adress génération unit) qui asservissent un système de lecture/écriture mémoire (Load/Store) sur lequel on reviendra. Quatre files sont dédiées aux instructions de "calcul" et de branchements. AMD les appelle ALU sur son schéma, il s'agit en pratique d'une série d'unités d'executions. Chaque ALU regroupe au minimum la possibilité de traiter les instructions logiques de base. AMD ne le détaille pas sur son schéma, mais d'autres unités sont présentes.
Le constructeur nous a confirmé que deux des ALU contiennent une unité dédiée au branchement, une ALU contient une unité gérant les divisions, une ALU contient une unité gérant les multiplications entières, et enfin une ALU contient une unité dédié au CRC32. AMD ne détaille pas la répartition exacte des unités sur les ALU, mais on apprécie les détails supplémentaires qui ont été donnés. L'efficacité de ces unités dépendra en grande partie de la capacité du front-end a les alimenter, mais sur le papier là encore, le design semble largement adéquat.
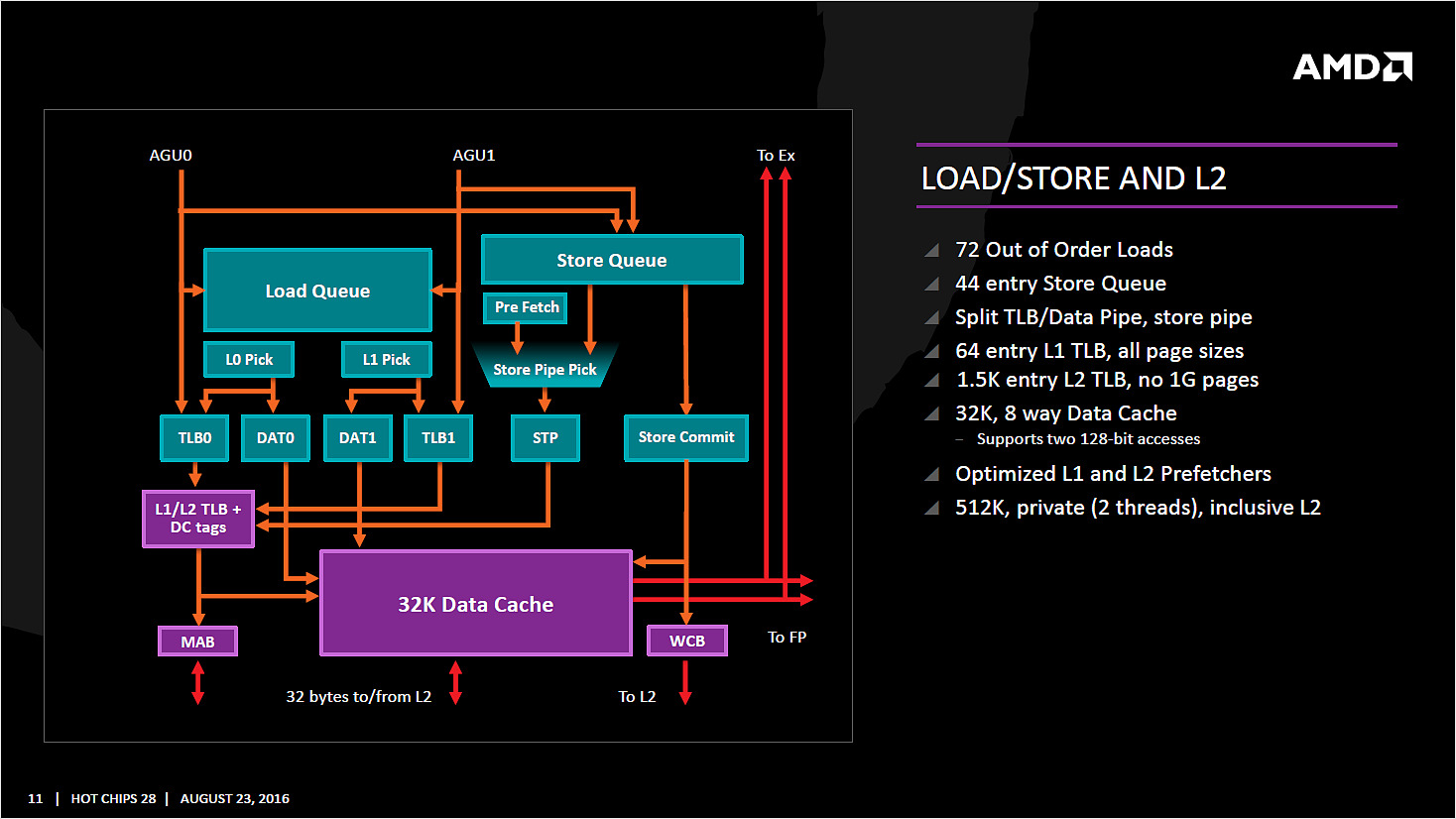
Comme nous le disions, les AGU asservissent les unités qui lisent et écrivent les données dans le sous système de cache. On retrouve des longueurs de files comparables à ce que l'on a chez le concurrent (72/44 pour Zen, 72/42 pour Haswell et 72/56 pour Skylake). Pour les chargements, AMD rentre dans le détail en indiquant qu'un des autres points faibles de ses architectures précédentes était lié aux opérations de chargement mémoire. Deux accès séparés 128 bits en lecture sont désormais possibles, et les unités peuvent accéder en simultanée au cache L1 et au cache TLB pour maximiser le débit, et ainsi streamer les données rapidement du cache L2 vers le L1.
L'efficacité des prefetchers (qui tentent de récupérer les informations en avance du moment ou le processeur en aura besoin) est indiquée comme meilleure et là encore il faudra attendre pour en savoir plus. Si AMD ne donne pas la rapidité de ses caches, il nous a été confirmé que la bande passante pratique est significativement plus rapide désormais, ce qu'on ne manquera pas de vérifier.

Si l'on revient en arrière, le dispatcher de micro-op pouvait envoyer jusque 6 instructions vers la partie Integer, et quatre vers la partie Floating point. Le scheduler dédié aux unités flottantes dispose ici de 96 entrées ce qui nous donne un total de 180 entrées par coeur (contre 97 pour Skylake). Il s'agit même en pratique d'un double scheduler.
C'était l'un des points faibles du design séparé que l'on évoquait plus haut : sur Bulldozer un scheduler trop petit sur la partie FP pouvait arriver à bloquer la partie Integer du CPU, un cas qui visiblement était assez fréquent. Avec un double scheduler, AMD dit avoir résolu le problème en pratique. On disposerais désormais bel et bien de deux blocs réellement indépendants pouvant travailler en parallèle (et ne se bloquant plus l'un l'autre).
Quatre unités d'exécution FP 128 bits sont donc présentes, deux dédiées plus spécifiquement aux multiplications et deux aux additions. Elles peuvent être combinées pour réaliser jusque 2 FMA 128 bits en parallèle par cycle. Sur ce point AMD est en retrait puisque Haswell pouvait effectuer deux FMA 256 bits par cycle. Il faudra voir l'impact pratique sur les performances, mais sur de micro benchmarks ou des cas spécifiques, ce sera un point limitant pour Zen.
Les caches mémoires
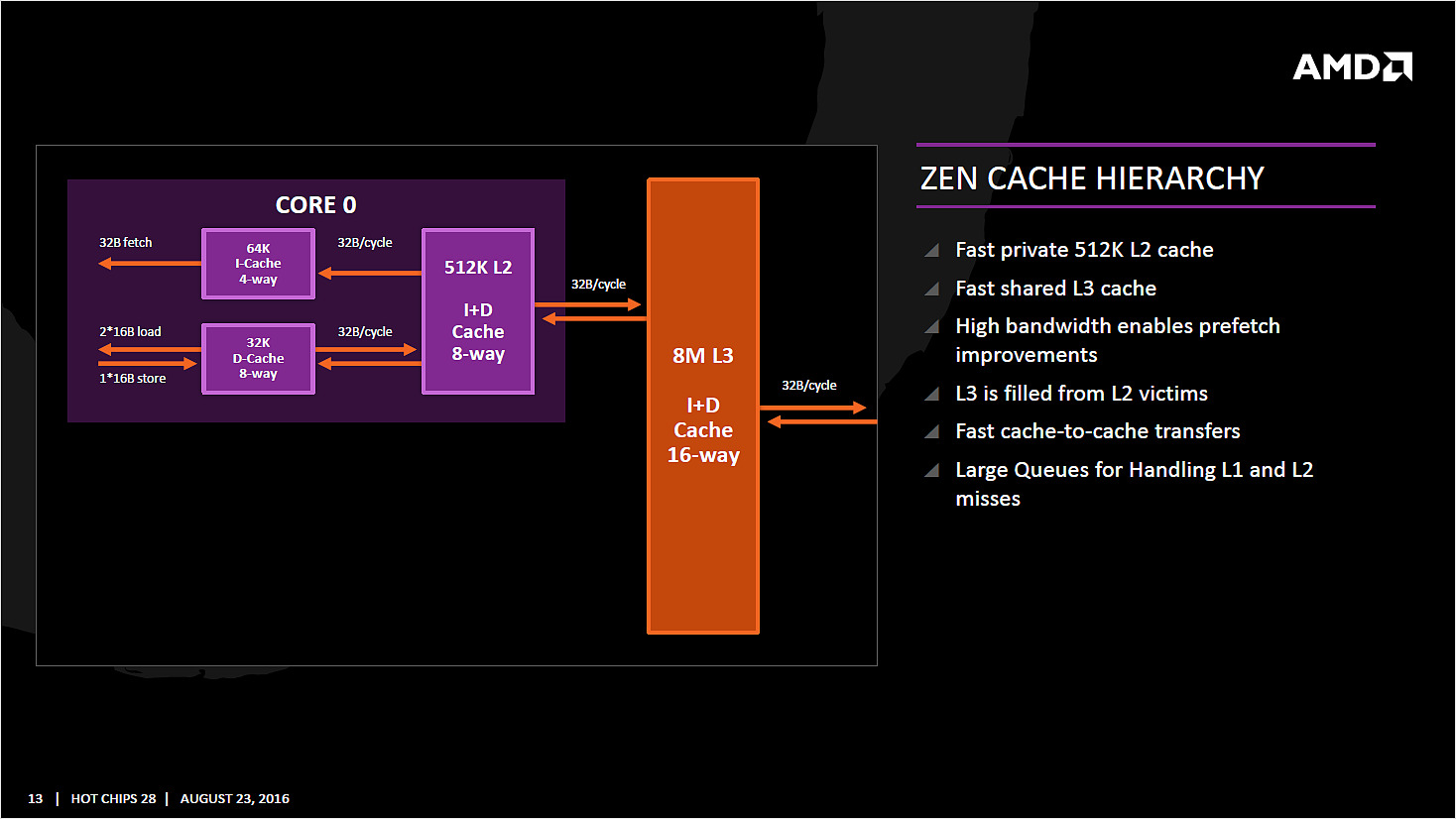
Sortons de la partie exécution pour regarder plus précisément les caches mémoires. AMD a choisi d'utiliser un cache L1 write back au lieu du write through utilisé précédemment, s'alignant là aussi sur ce que fait Intel. Cela devrait assurer une bien meilleure bande passante mémoire pour le L1 dont la taille est de 32 Ko. Chaque coeur dispose en prime d'un cache L2 de 512 Ko (le double de Skylake), et l'on retrouve un cache L3 partagé de 8 Mo assez spécial. Il est en prime (principalement) exclusif par rapport au cache L2.
Les blocs de coeurs
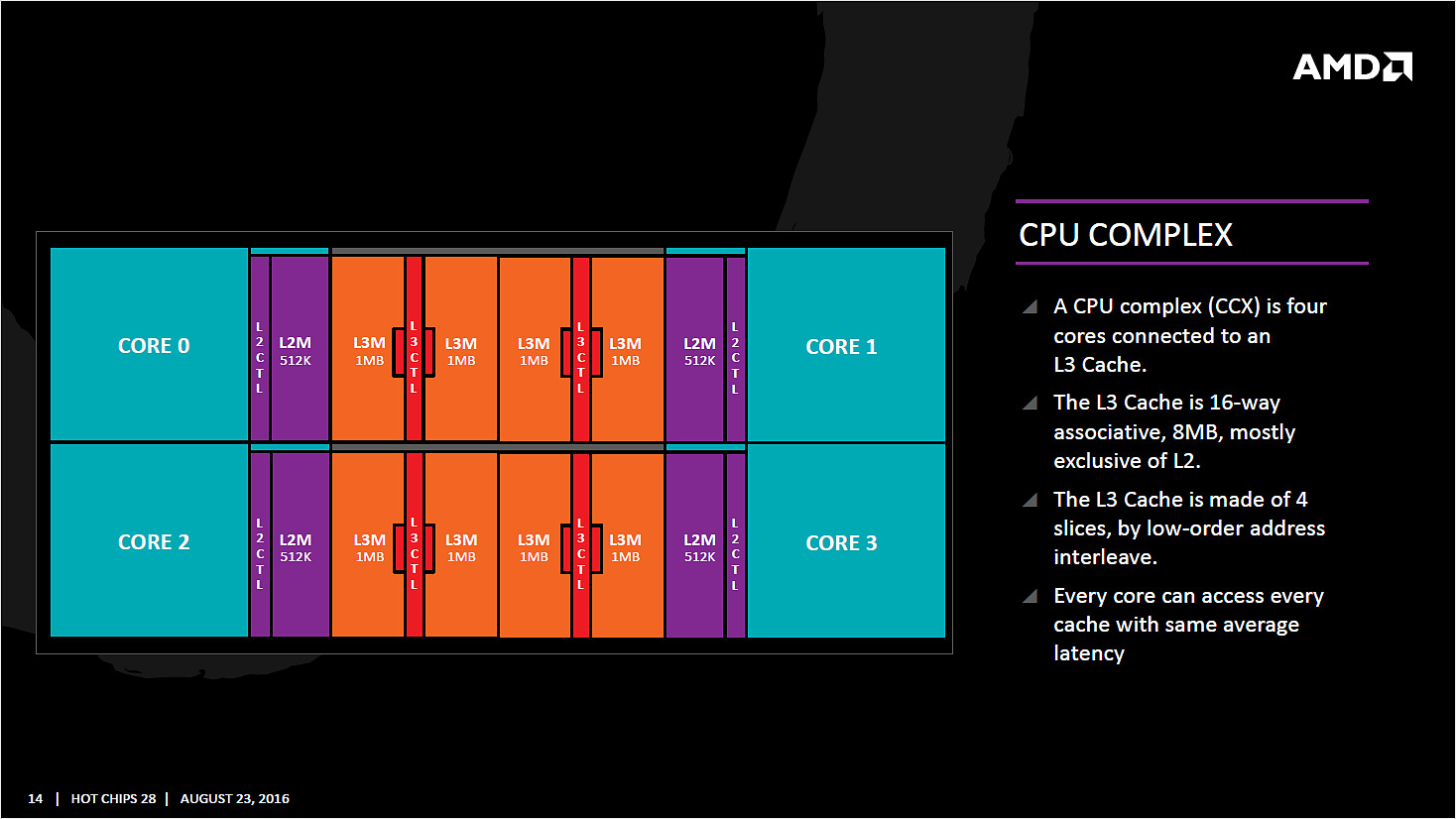
C'est l'un des rares détails d'un peu plus haut niveau qu'aura partagé AMD : les coeurs Zen sont regroupés par blocs de quatre. Chaque coeur comme indiqué plus haut est relié a son propre cache L2 de 512 Ko, et également à 2 Mo de cache L3. Ces quatre partitions de cache L3 sont reliées ensemble et chaque coeur peut accéder a chacune des partitions. Selon l'emplacement des données, la latence ne sera pas la même, même si AMD n'a pas voulu quantifier l'éventuelle différence (on admirera la manière dont AMD a tenté de détourner le sujet en parlant de latence moyenne !). Chaque CCX (le nom donné au groupe) dispose donc au total de 8 Mo de cache, et AMD peut ainsi construire des puces utilisant plusieurs modules CCX.
Ces derniers sont reliés point à point au reste du système (notamment au contrôleur mémoire, etc) par un data fabric, un système de bus interne. Dans le cas d'une puce disposant de deux CCX, un coeur souhaitant accéder à la mémoire L3 de l'autre bloc CCX passera par les blocs en amont du contrôleur mémoire, avec un système de cohérence type MOESI. Il n'y a pas de lien direct point à point entre les CCX à ce qui nous a été indiqué, en tout cas pour ce qui concerne les premières versions de Zen (les déclinaisons serveurs pourraient être reliées différemment). On notera enfin que les coeurs/L2 et le L3 disposent d'un plan de fréquence séparé.
Un dernier mot sur le Simultaneous Multi Threading
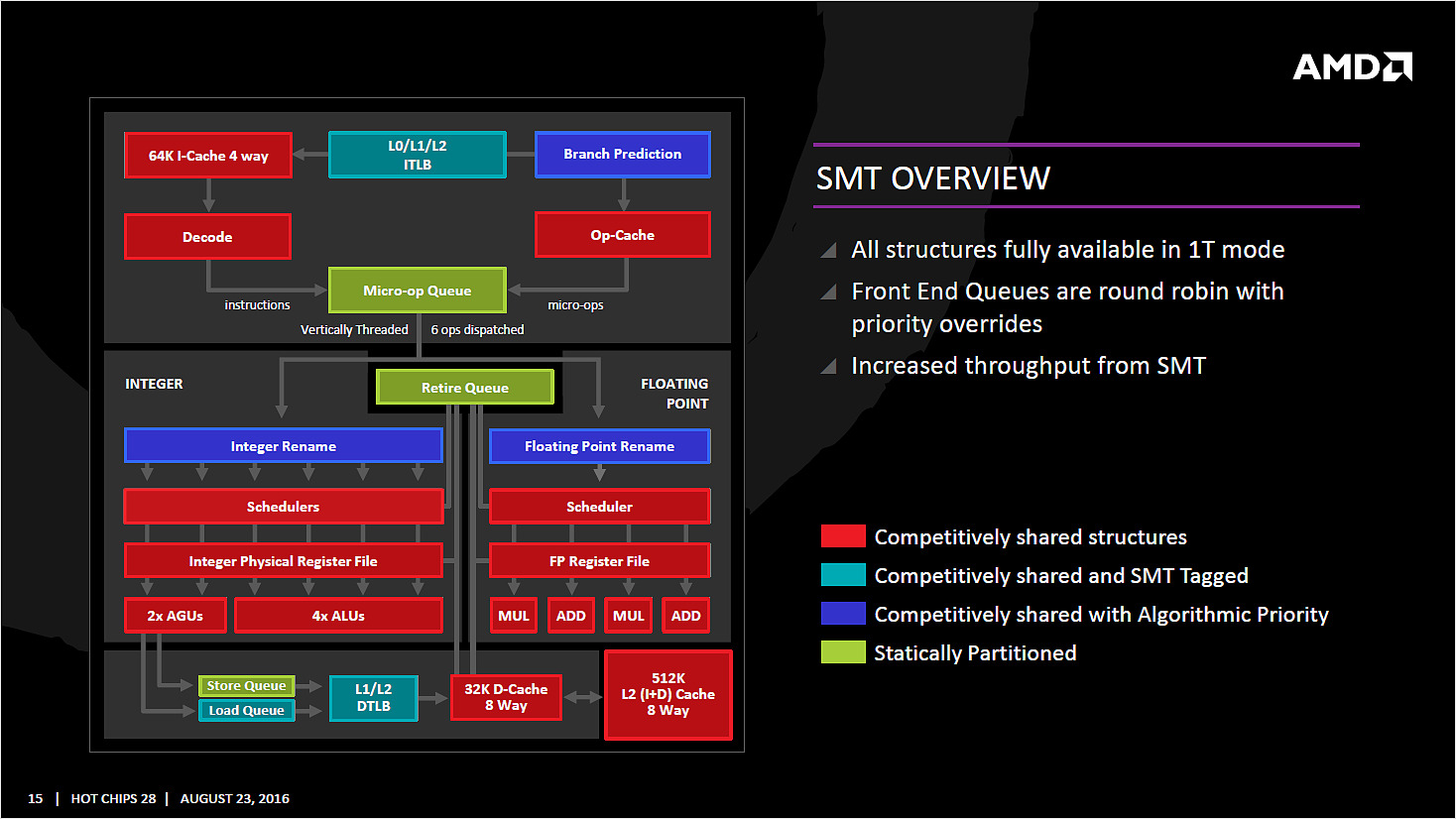
AMD a terminé sa présentation en indiquant avec beaucoup de précisions la manière dont les blocs sont partagés lorsque l'on utilise le SMT. En pratique il n'y a que très peu de cas ou AMD partitionne en deux des buffers pour chacun des threads. C'est le cas, nous l'avons vu plus haut, de la file de micro-op principale, et l'on notera que c'est le cas aussi pour la file d'écriture vers les caches. Les autres structures sont partagées entre les threads en fonction des besoins, ce qui est plutôt une bonne nouvelle là aussi.
En résumé
Cette présentation de Hot Chips était l'une des plus attendues, et l'on est obligé de dire que sur le papier au moins, AMD semble proposer une architecture vastement supérieure à ce qu'il proposait auparavant avec ses coeurs Jaguar ou Excavator. Certains diront que c'était un moindre mal, mais les changements sont conséquents.
Sur le papier, le travail important réalisé sur le front-end nous rappelle de nombreux choix également effectués par Intel pour son architecture Core, ce qui semble être une très bonne chose pour les performances et la consommation.
AMD garde un design différent pour la partie exécution en scindant en deux les ports "Integer" et "FPU". Un design qui n'avait pas particulièrement réussi aux modules de Bulldozer, mais AMD semble avoir appris des problèmes que cette partition avait causé. Il faudra voir si en pratique cette séparation portera enfin les fruits attendus.
De la même manière l'architecture des caches semble avoir été revue dans le bon sens, le passage au write back pour le L1 devrait augmenter largement sa bande passante, et le reste des caches est confortablement dimensionné.
Sur le papier, le retard architectural d'AMD semble en très grande partie comblé, et il n'y a que sur le choix des unités 128 bits en virgule flottante que l'on émettra un bémol.
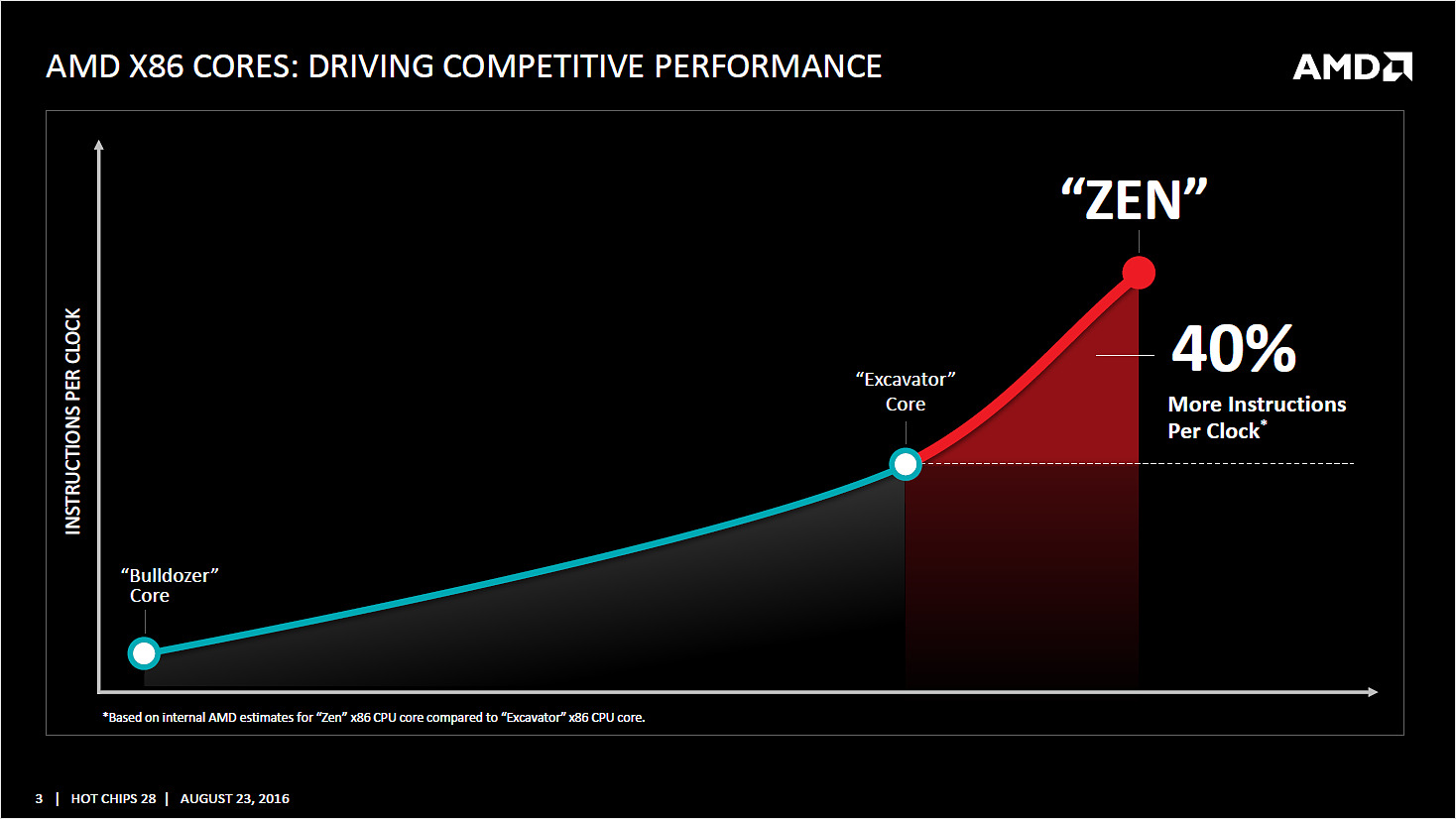
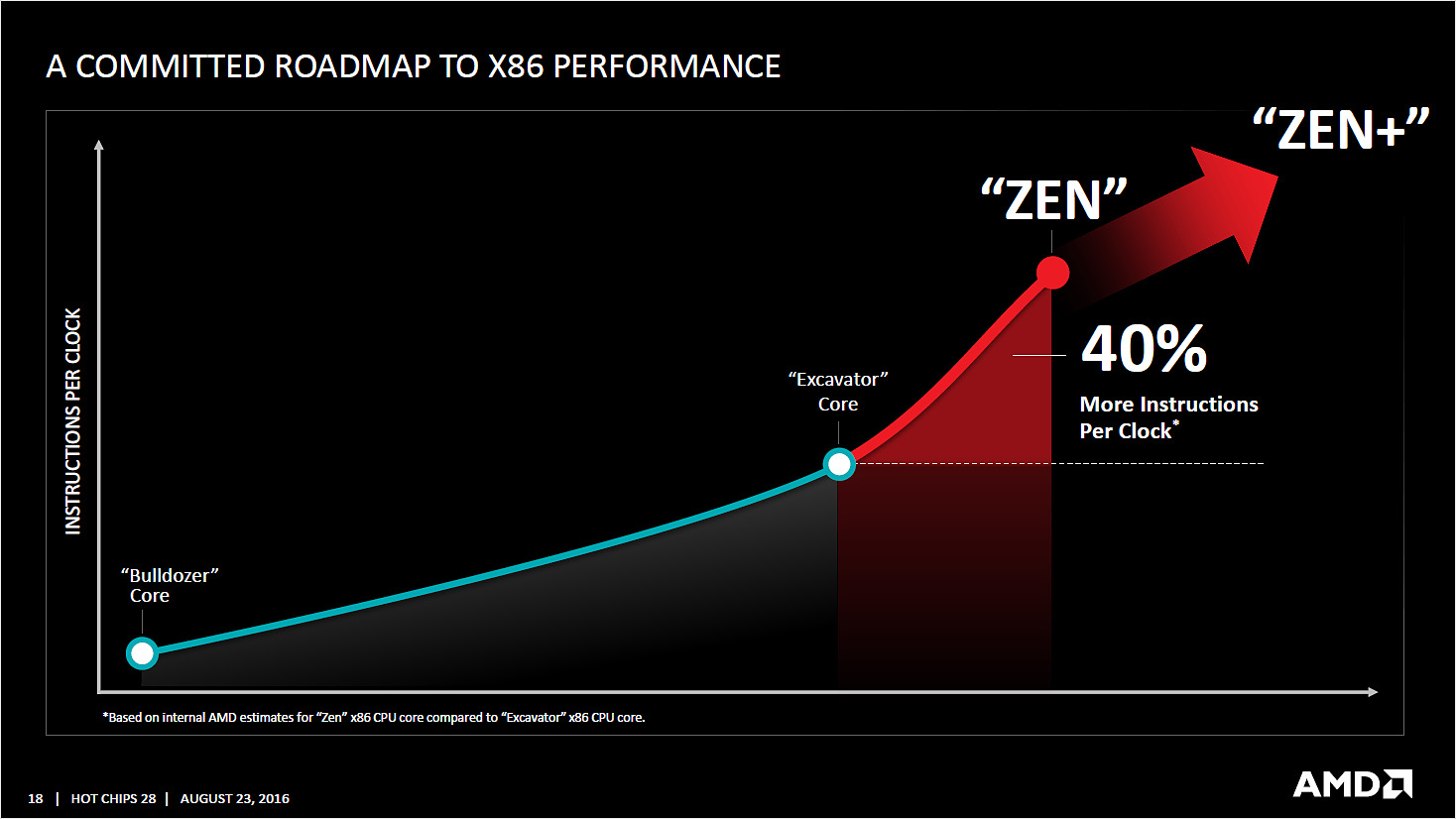
Reste qu'entre la théorie et la pratique, de nombreuses choses peuvent jouer et si AMD martèle avoir fait progresser de 40% l'IPC par rapport à son architecture précédente, on rappellera que le chiffre est obtenu en comptant l'effet de l'intégration du Simultaneous Multi Threading. Sur ce qui est des performances monothread, point primordial, rien n'a été indiqué. Le fait que la notion de coeur ait été malmenée par Bulldozer et Excavator complique de toute manière l'interprétation de ces chiffres.
Comme toujours, seuls des tests pratiques pourront nous donner la réalité de la situation. Dans l'attente d'autres détails, que ce soit sur la partie uncore, et bien évidemment sur les fréquences et quantités de coeurs embarqués (sans parler des prix), nous n'irons pas plus loin dans les prédictions.
Dans tous les cas, le retour d'un semblant de concurrence dans le marché du x86 ne serait pas pour nous déplaire !
Vous pouvez retrouver ci dessous l'intégralité de la présentation d'AMD :



Intel désactive TSX suite à un bug
TechReport rapporte qu'Intel va déployer via de nouveaux firmware pour les cartes mères un nouveau microcode pour les processeurs Haswell visant à désactiver les instructions TSX que nous avions décrites ici.

Un développeur a en effet remonté à Intel un bug dans l'implémentation TSX au sein de Haswell pouvant entraîner des "défaillances logicielles critique". Ce bug a été confirmé par Intel qui n'a donc que d'autre choix de désactiver TSX.
Les premiers processeurs Broadwell seront également concernés par ce bug et auront donc le TSX désactivé en attendant un prochain stepping en cours de développement. Ce sera également le cas sur les Haswell-E/EP qui seront prochainement lancés sur la gamme Xeon, ce qui est assez dommageable vu que l'utilité de TSX se situe dans le monde professionnel. Selon AnandTech , Intel recommande dans ce cas d'attendre Haswell-EX, ce qui sous entend qu'aucun stepping correctif n'est prévu pour Haswell-E et qu'il faudra donc attendre Broadwell-E/EP dans un an pour disposer d'un correctif sur cette gamme de puce.
Les instructions TSX absentes des Core K/R !
Intel a mis à jour sa base de données publique de processeur, le très utile site ARK avec ses nouveaux processeurs Core de quatrième génération. Un non événement en soit, sauf que nous avons remarqué une information pour le moins surprenante sur la fiche du Core i7 4770K : il ne supporte pas les instructions TSX !
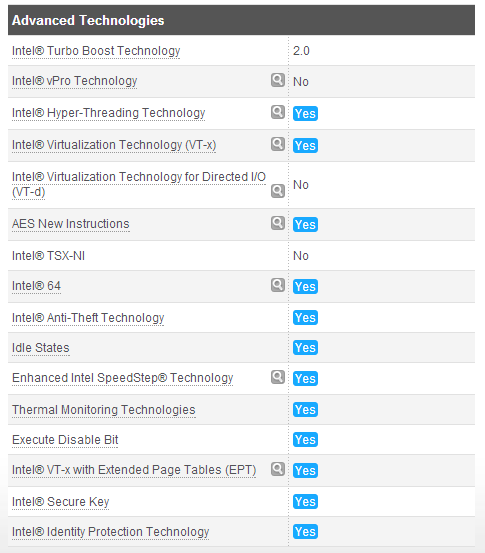
Pour rappel, TSX est une extension du jeu d'instruction qui permet de gérer les opérations mémoires de manière transactionnelle. Nous avions publié un premier article sur le sujet ici et également dans notre test de ces nouveaux Core.
Là ou l'on pensait que ce support serait universel, il s'agit après tout d'une extension du jeu d'instruction, Intel joue une fois de plus le jeu de la segmentation sans que l'on comprenne trop pourquoi. Car le Core i7 4770K n'est pas le seul modèle à ne pas proposer TSX, voici la liste des modèles que nous avons notés comme ne supportant pas TSX côté desktop :
- Core i7 4770K
- Core i7 4770R
- Core i5 4670K
- Core i5 4430S
- Core i5 4430
Notez que toutes les déclinaisons Xeon en LGA 1150 sont annoncées comme compatibles.
Côté mobile, c'est encore un peu moins logique, les HQ, MX et MQ semblent supporter TSX, même si pour certains modèles le champ n'est pas renseigné dans la base de données. L'intégralité des modèles Y ne supportent pas TSX. En ce qui concerne les U, le cas est variable, nous avons noté ces modèles comme incompatibles :
- Core i7 4550U
- Core i7 4500U
- Core i7 4558U
- Core i5 4520U
- Core i5 4200U
- Core i5 4258U
- Core i5 4288U
Si la segmentation des gammes autour de fonctionnalités n'est pas une première - on l'a déjà vu avec le non support de VT-d par exemple sur les Core K - le choix de ne pas supporter ces instructions TSX nous semble non seulement très difficile à justifier, mais en prime complètement contre productif pour l'adoption éventuelle de ces instructions dans les logiciels.
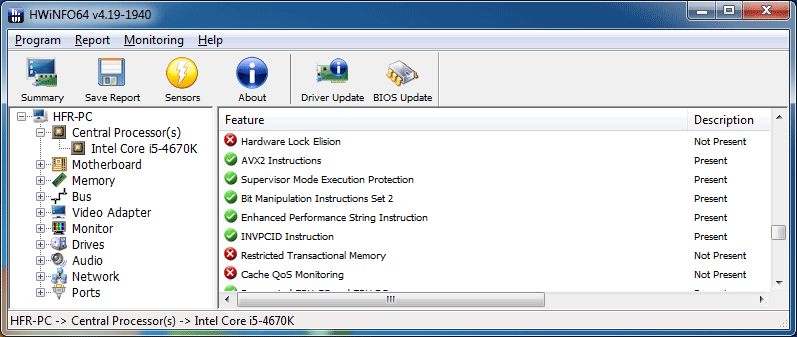
Sur un i5-4670K, les instructions TSX qui sont rapportées comme Hardware Lock Elision et Restricted Transactional Memory sous HWiNFO ne sont pas supportées
Pour rappel les instructions TSX sont en effet classées en deux catégories, d'un côté les optionnelles, qui peuvent s'exécuter sur toutes les machines, et de l'autre les instructions qui doivent être réellement supportées. Avec une segmentation si particulière, on doute que l'adoption de TSX dans sa version non optionnelle soit considérée par quiconque tant il va être complexe d'expliquer aux utilisateurs quels processeurs sont supportés. La segmentation à outrance devrait avoir des limites