
Les derniers contenus liés au tag LPDDR4
TSMC et InFo PoP pour l'A10 de l'iPhone 7
Samsung évoque la GDDR6
Le JEDEC ratifie la LPDDR4
Quelques détails sur les LPDDR4, DDR4 et Wide I/O
TSMC et InFo PoP pour l'A10 de l'iPhone 7



Ce week end, la société Chipworks a procédé à son traditionnel "teardown" des puces incluses dans l'iPhone 7 , en se concentrant particulièrement sur le SoC A10 d'Apple.
Rappel sur l'A9
Avant de regarder l'A10, revenons un instant sur l'A9 inclus l'année dernière dans l'iPhone 6S. Il avait la particularité d'être sourcé en parallèle chez Samsung et TSMC, quelque chose de quasi unique pour des puces haut de gamme sur des process de dernière génération, ce qui nous avait permis d'effectuer quelques comparaisons.
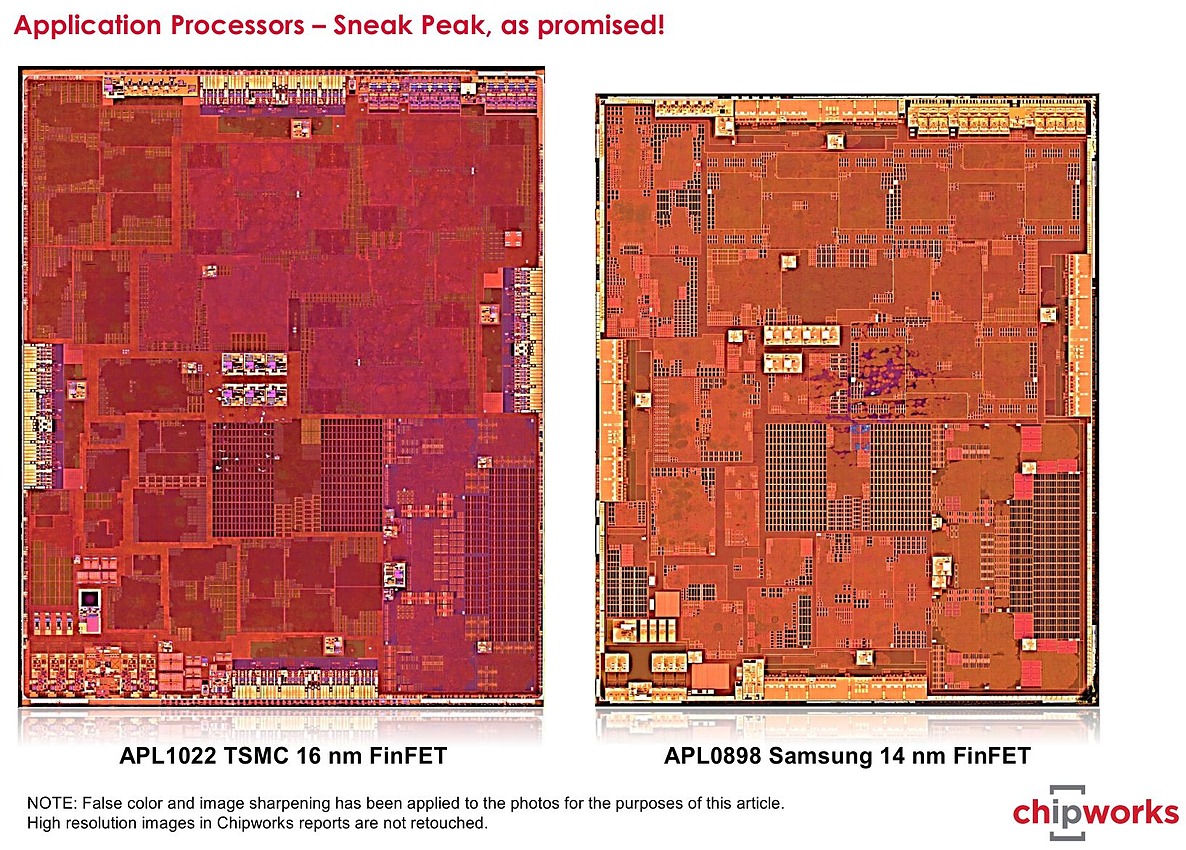
Les deux A9 de l'iPhone 6S (2015)
La différence la plus visible était la densité des deux process : l'A9 "Samsung" mesurant 96mm2, contre 104.5mm2 pour la version TSMC. A l'époque nous n'avions pas de certitudes sur les variantes exactes des process utilisées. Depuis, Chipworks a confirmé qu'il s'agissait bien du 14LPE chez Samsung. Le cas de TSMC est plus compliqué, Chipworks ne répondant pas (gratuitement) à la question. Les rumeurs laissent penser qu'il ne s'agissait pas d'un simple 16FF, mais d'une version "custom" empruntant en partie au process 16FF+.
Outre la densité, les tests pratiques avaient suggéré une différence de consommation à pleine charge avec un avantage pour la puce de TSMC. De quoi laisser penser que son process avait besoin de tensions inférieures à celui de Samsung pour obtenir les mêmes performances.
Depuis, Chipworks a la aussi répondu partiellement à la question suggérant que le problème se situerait pour le process de Samsung sur le rapport puissance/performances de ses NMOS . On ne sait pas si le problème persiste sur la version 14LPP qui a remplacé le 14LPE.
L'A10 : 16FFC TSMC
Première différence par rapport à l'année dernière, l'A10 semble produit cette année exclusivement par TSMC. Il est plus large que l'A9, mesurant 125mm2 pour 3.3 milliards de transistors annoncés. Côté process il s'agit du 16FFC (ou d'une variante) de TSMC, la troisième version "optimisée" du 16nm de TSMC. Annoncée en janvier dernier, le C signifie "Compact" et ce process vise avant tout les usages basses consommation tout en réduisant de manière significative les coûts de fabrication.

D'après Chipworks, l'utilisation des bibliothèques optimisées permet une bien meilleure utilisation du die, avec une compacité équivalente à celle des process TSMC précédents. Chipworks estime que la même puce aurait demandé 150mm2 en 16FF. Etant donné que 70 tapeouts de clients de TSMC sont attendus sur ce process cette année, les progrès de densité du 16FFC devraient profiter assez largement, on attendra de voir les constructeurs qui annonceront des puces l'utilisant.


Chipworks note également que l'A10 est beaucoup moins haut que les générations précédentes. Comme beaucoup de SoC, il est de type PoP et embarque la mémoire au dessus du die logique. Cependant plutôt que d'empiler les quatre dies de mémoire (2 Go de LPDDR4 Samsung sur l'A10 de l'iPhone 7), ils sont placés côte à côte.
Qui plus est, comme nous le supposions la puce utilise le nouveau packaging InFo de TSMC (dans sa version InFo-PoP) pour relier les dies entre eux.
big.LITTLE et performances
Côté performances les premiers benchmarks synthétiques évoquent 40% de gains pour le CPU ARM par rapport à l'année dernière, tout en restant en 16nm.
Pour arriver à ce gain, Apple augmente d'abord significativement la fréquence, passant de 1.85 GHz sur l'A9 à 2.35 GHz sur l'A10. Sur ce point, la marque exploite à la fois la marge notée de son process l'année dernière (on peut supposer facilement que l'A9 aurait eu une fréquence plus élevée s'il avait été sourcé uniquement chez TSMC) et les gains apportés par le 16FFC.

Ce gain de 27% de fréquence est accompagné de changements au niveau de l'architecture. Ceux ci ne sont pas encore connus, au delà du nom Hurricane, mais Chipworks note que le cluster CPU prend une place plus importante sur le die, 16mm2 face à 13mm2 sur l'A9, malgré l'utilisation d'un process plus compact.
Il est cependant difficile de se baser sur cette différence de taille étant donné que l'A10 est en réalité un quad core big.LITTLE dans la nomenclature ARM. En plus des deux coeurs hautes performances à 2.35 GHz (big), deux coeurs basse consommation à 1.05 GHz (LITTLE) sont également présents sur le die (leur emplacement exact est pour l'instant inconnu, ce qui vaut les points d'interrogation sur le diagramme au dessus).
Contrairement à d'autres implémentations dans l'écosystème ARM, les applications ne peuvent pas utiliser en simultanée les deux blocs de coeurs, le passage de l'un à l'autre étant transparent pour elles (géré par la puce et l'OS). L'intérêt de cet arrangement est bien entendu d'augmenter l'autonomie en ne sollicitant les coeurs haute performances que lorsque nécessaire.
Déjà largement en avance côté performances sur le reste de l'écosystème ARM, l'A10 commence à devenir embarrassant même pour Intel, dépassant un Core M Skylake en monothread sous Geekbench 4 (voir ici et là ), avec un "TDP" au moins deux fois inférieur (et sans mécanisme Turbo).
Intel se consolera tout de même de sa présence dans une partie des iPhone 7 car c'est l'autre information de Chipworks, la société confirme qu'une partie des modèles utilise un modem Intel XMM 7360 (certains modèles intègrent un modem Qualcomm X12). Très en retard, le XMM 7360 est un modem LTE 450 Mb/s Cat 10 certes dessiné par Intel, mais fabriqué selon toutes vraisemblances comme ses prédécesseurs... par TSMC.
Samsung évoque la GDDR6
En parallèle à la mémoire HBM, Samsung à évoqué le futur de la GDDR5, ignorant quelque peu l'existence de la GDDR5X de Micron qui, bien que standardisée par le JEDEC, n'a pas été adoptée par ses concurrents.
Pour la GDDR6, Samsung évoque certaines des pistes de travail envisagées. Côté objectifs la mémoire visera dans un premier temps 14 à 16 Gbps, ce qui était la cible haute pour rappel de la GDDR5X lors de sa présentation par Micron. Lors de la certification de la GDDR5X par le JEDEC, 14 Gbps est devenu le maximum visé. On notera que la GTX 1080 utilise pour rappel de la GDDR5X 10 Gbps. Techniquement, la GDDR5X abaissait la tension de la GDDR5 à 1.35V et doublait la bande passante en doublant le prefetch.
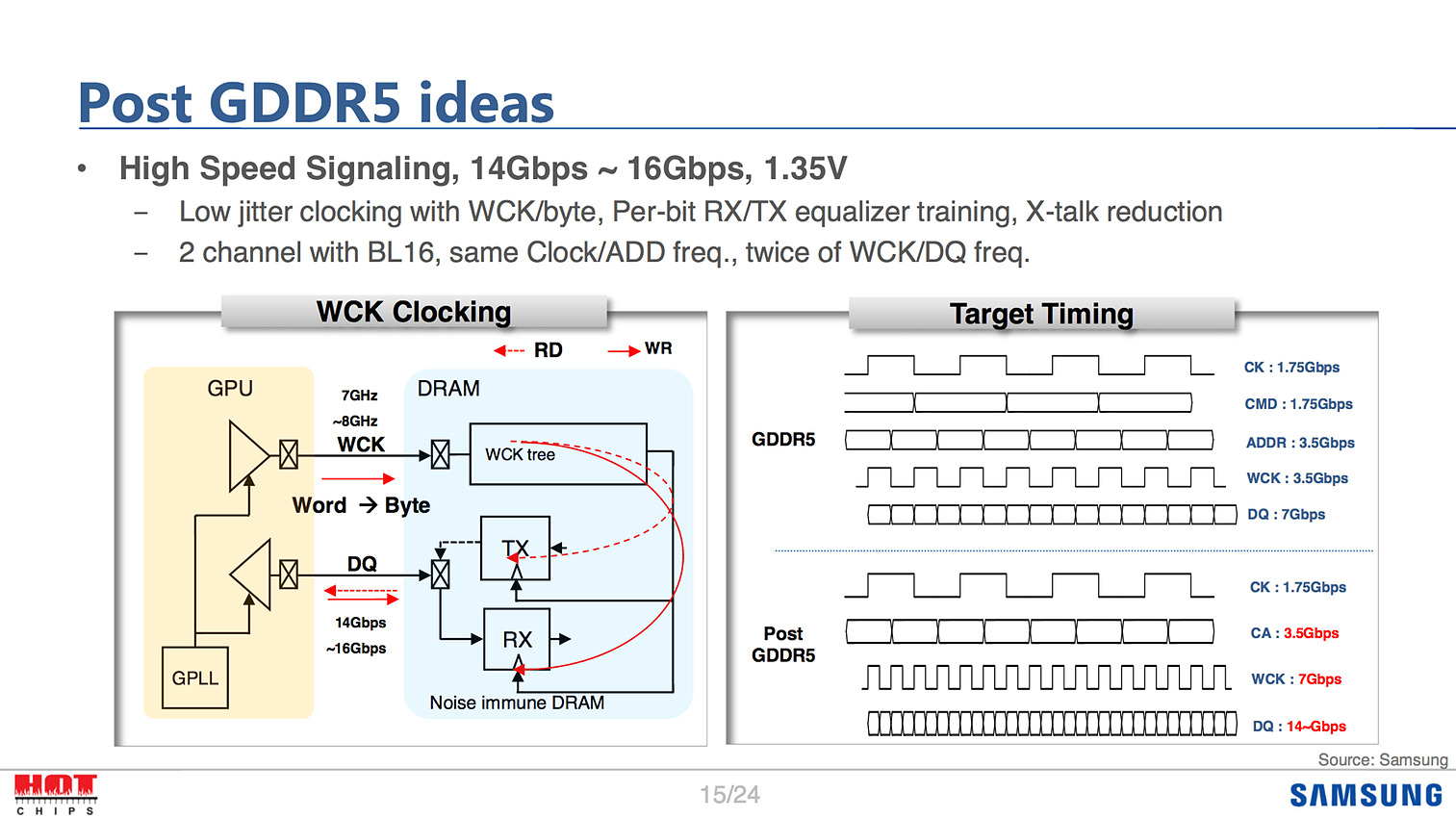
Samsung donne ici quelques idées sur la GDDR6, reprenant par exemple l'idée de la tension à 1.35V. L'élaboration de la spécification finale se fera au sein du consortium JEDEC dans les mois à venir.
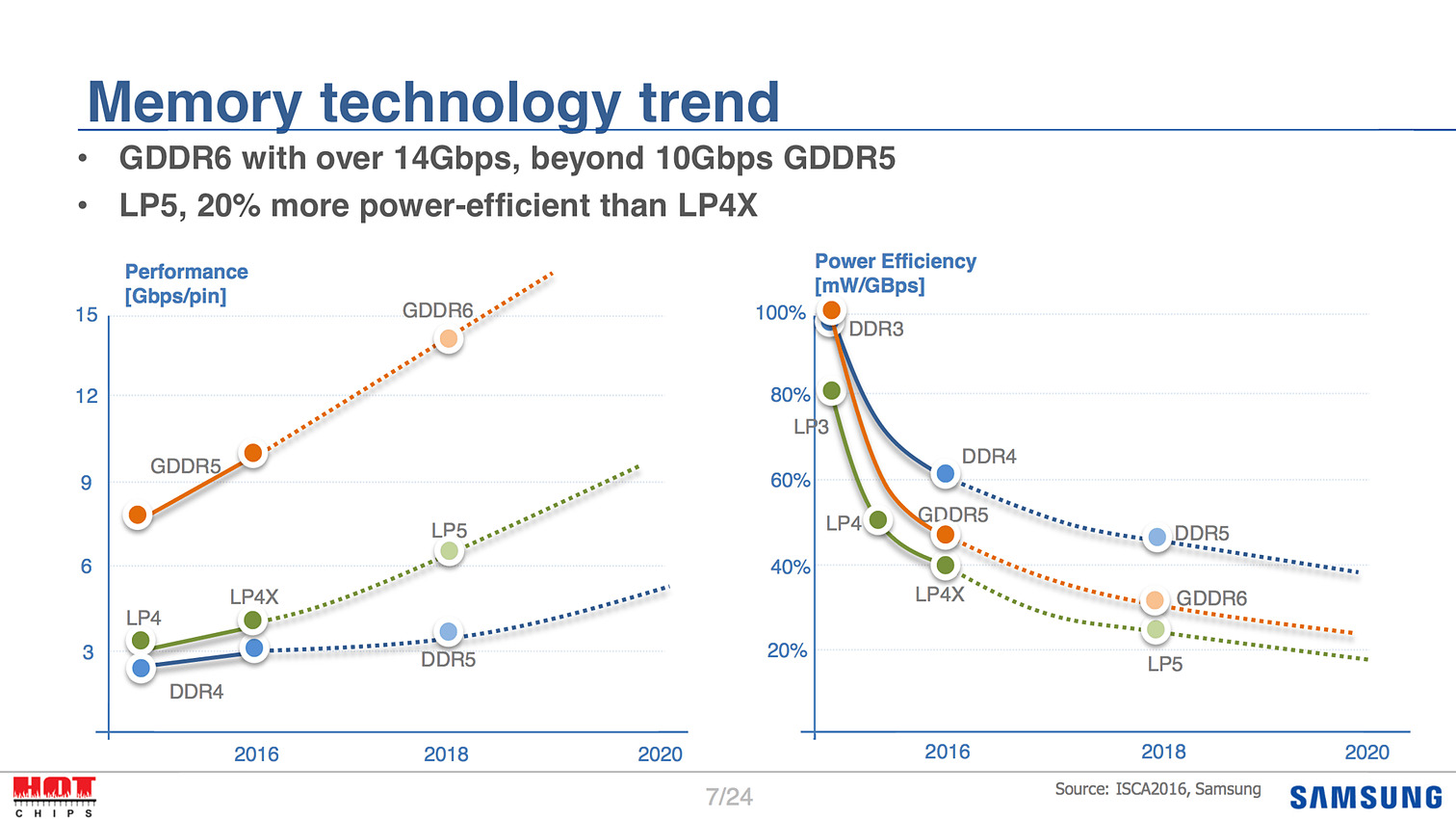
Côté timing, Samsung évoque 2018, aligné avec la DDR5 et la LPDDR5, et un gain d'efficacité énergétique autour des 30%. On notera au passage que Samsung continue lui aussi de pousser son propre standard "X" avec la LPDDR4X, une variante de la mémoire mobile LPDDR4 qui fait "seulement" baisser la tension VDDQ à 0.6V pour obtenir un gain d'efficacité de 20%. Si le JEDEC n'a pas encore ratifié la LPDDR4X, on notera que SK Hynix avait annoncé en juin qu'il produirait lui aussi ce type de mémoire.
Le JEDEC ratifie la LPDDR4
Le comité s'occupant de la standardisation des formats de mémoire (JEDEC) vient d'annoncer la publication de la spécification LPDDR4 (Low Power DDR4). Destinée aux plateformes mobiles, ce nouveau standard arrive seulement deux ans après la ratification de la LPDDR3. Outre l'utilisation dans les smartphones et les tablettes, Intel avait notamment commencé à proposer le support de la LPDDR3 dans ses plateformes Haswell-ULT (un support utilisé notamment par les Macbook Air).
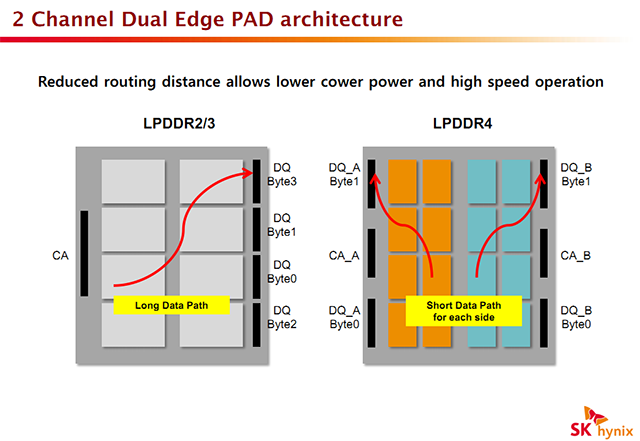
La LPDDR4 a pour objectif principal d'augmenter la bande passante disponible, annonçant entre 3200 et 4266 MT/s tout en réduisant encore plus la consommation. La tension principale passe ainsi de 1.2 à 1.1V, et diverses tensions additionnelles (terminaisons, signal, etc) ont également été revues à la baisse. Techniquement on retrouvera quelques changements communs avec la DDR4, même si les deux standards sont indépendant, comme le Data Bus Inversion qui permet d'inverser les bits à transmettre (1 en 0 et inversement) pour réduire la consommation (transmettre un 1, présence de signal, est plus couteux qu'un 0, absence de signal). On notera la présence de deux interfaces séparées pour créer deux canaux de données indépendants sur chaque puce pour réduire le routage nécessaire à l'intérieur de la puce.
La spécification est consultable directement sur le site du Jedec à cette adresse .
Quelques détails sur les LPDDR4, DDR4 et Wide I/O
L'IDF de Pékin était aussi l'occasion pour Intel et ses partenaires d'évoquer les futurs standards mémoires DDR4 et LPDDR4. D'abord côté Intel ou l'on pouvait trouver ce slide qui compare les différentes versions de DDR :
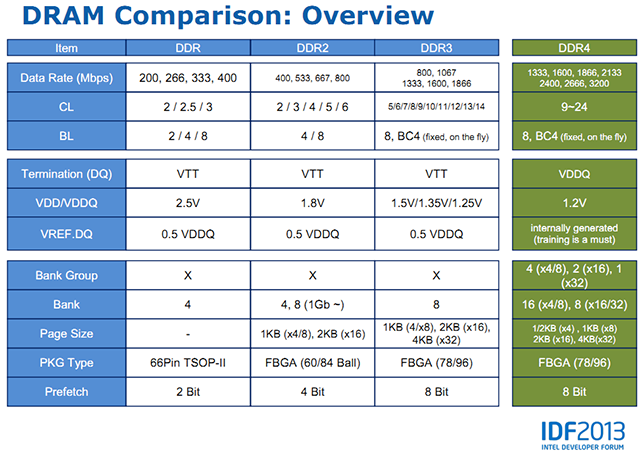
Par rapport à la présentation que nous avions faite précédemment, on peut noter quelques petits changements. Notamment la mention des modes 3200 MT/s qui n'étaient que très peu évoquées dans la spécification originelle de la DDR4. Intel évoque ainsi des latences qui pourront atteindre 24 cycles. Pour le reste il s'agit des informations dont nous disposions déjà, pour rappel un des intérêts techniques principaux de la DDR4 tient dans l'organisation de l'adressage mémoire sous forme de groupes capables d'exécuter des instructions de manière indépendante.
La LPDDR4 est également évoquée dans une présentation donnée par la société Hynix. Encore au rang de pré-standard pour le JEDEC, Hynix indique que la version finale devrait être ratifiée d'ici à la fin de l'année. Notez que si les noms se ressemblent, les standards LP ne sont pas identiques aux standards DDR classiques, à l'image de ce que l'on connait bien avec la GDDR par exemple. Les choix techniques effectués peuvent différer, l'objectif des standards LP étant de minimiser au maximum la consommation.
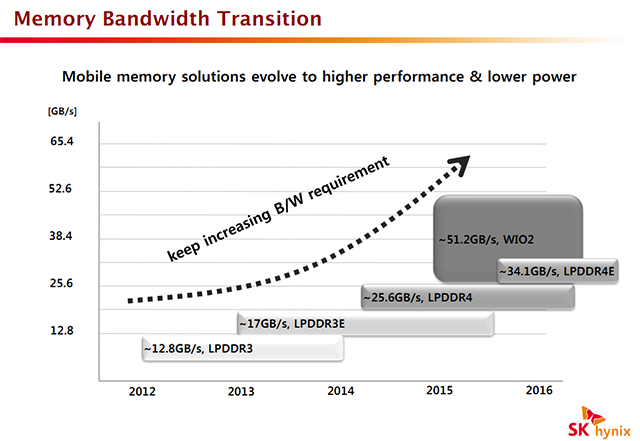
Comme toujours augmenter la bande passante est l'objectif, elle est doublée par rapport à la LPDDR3. On notera d'ailleurs sur ce graphique l'arrivée attendue d'un autre standard, Wide I/O 2. Un premier standard Wide I/O avait en effet été publié par le JEDEC fin 2011, il vise a standardiser la pratique dite du die stacking de mémoire, à savoir superposer des dies de mémoires par-dessus un SoC, le tout étant relié par le biais de TSV. La première version de Wide I/O avait avant tout pour but de régler les problèmes techniques autour de la solution et est relativement conservatrice en termes de débits, pouvant atteindre 17 Go/s (via une généreuse interface 512 bits !). La seconde version, attendue pour 2015 (le standard est encore loin d'être finalisé), visera des débits significativement plus élevés, pouvant atteindre 51 Go/s.
En ce qui concerne la LPDDR4, on notera au niveau des détails que la tension de base baisse de 1.2 à 1.1V par rapport à la LPDDR3, et une tension de terminaison qui est divisée par 3 (de 1.2V à 0.4V). Une réduction du routage fait également partie des objectifs attendus, ce qui devrait avoir pour conséquence un changement assez drastique dans le packaging.
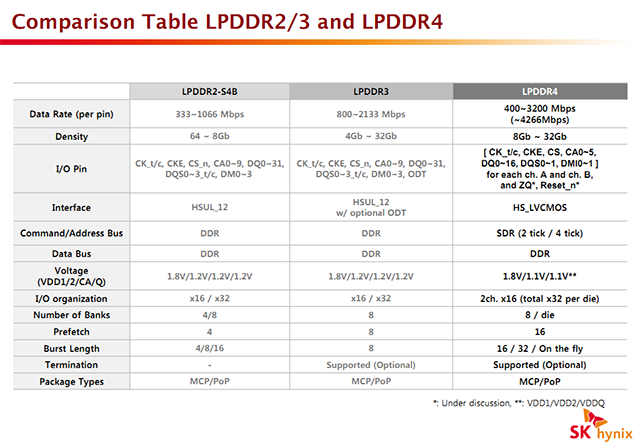
Pour le reste, Hynix nous parait particulièrement optimiste en indiquant que la LPDDR4 sera disponible pour la mi-2014. Il faudra voir si cet enthousiasme sera partagé par le reste de l'industrie !