
Les contenus liés au tag Imagination Technologies
Afficher sous forme de : Titre | FluxGDC: L'architecture PowerVR Series 6 Rogue
Dans une session dédiée à l'architecture PowerVR, Imagination a donné quelques détails sur l'architecture Series 6, nom de code Rogue, qui a été dévoilée il y a plus de deux ans et qui devrait très bientôt arriver dans différents SoC.
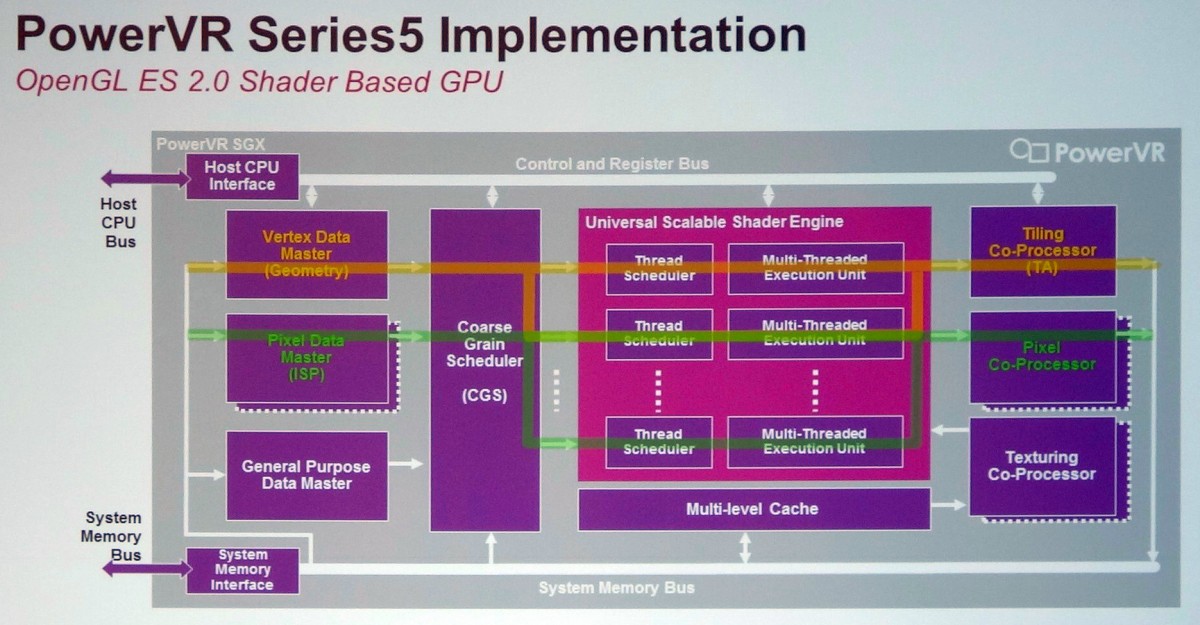
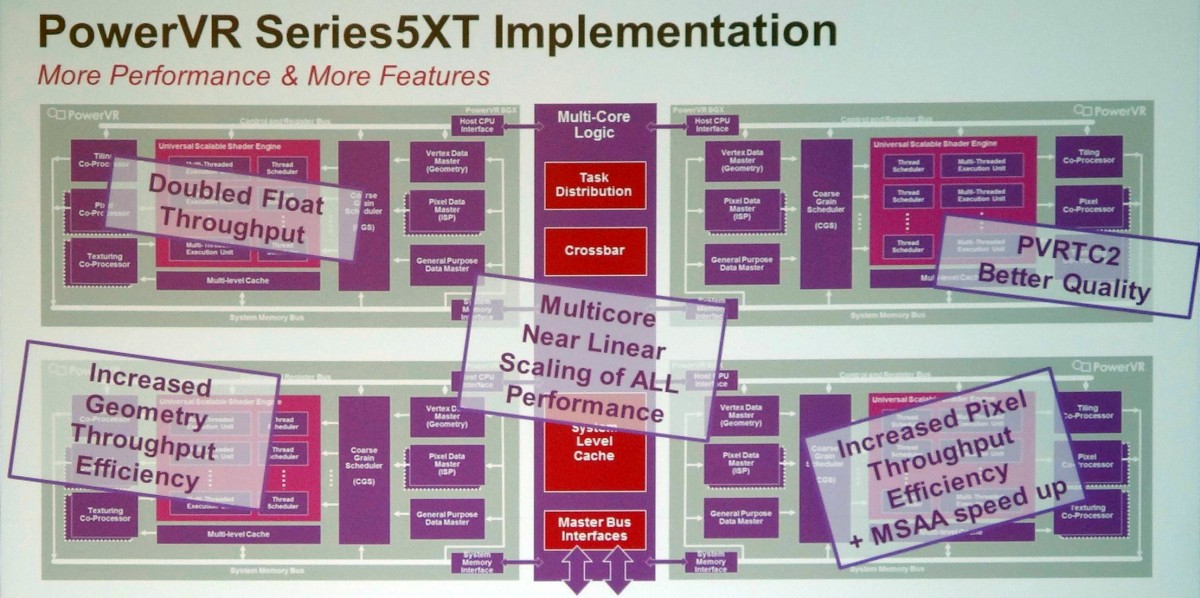
L'architecture PowerVR Series 5 est exploitée depuis de nombreuses années, par exemple dans les SoC Atom Intel ou dans l'A4 d'Apple. Elle a évolué il y a un peu plus de 3 ans pour passer en version Series 5XT avec le PowerVR SGX543 qui a doublé la puissance de calcul (elle passe de 8 à 16 MAD par cycle) et amélioré l'efficacité au niveau des débits de triangles et de pixels, notamment avec MSAA. Le support d'OpenCL a par ailleurs été introduit.
Par ailleurs, Imagination a introduit la possibilité d'avoir recours au multicore pour démulitplier la puissance des GPU PowerVR. L'ensemble du GPU SGX543 représente alors un core qui peut être dédoublé jusqu'à 8x, le tout étant piloté par un distributeur de tâche qui intègre un cache commun. Cette notion de core est donc ici assez proche d'un core CPU et n'a rien avoir avec la notion de core utilisée par Nvidia dans ses GPU, y compris Tegra. Comparer le GeForce ULP 72 cores du Tegra 4 au PowerVR SGX543MP4 "seulement 4 cores" est donc un non-sens, même si comme vous vous en doutez le côté commercial ne s'en prive pas.
Notez que le PowerVR SGX544 a ajouté le support de DirectX en niveau 9_3 alors que le PowerVR SGX554 a doublé une nouvelle fois la puissance de calcul qui passe à 32 MAD par cycle par core.
Avec l'architecture PowerVR Series 6, Imagination a dû faire face à la problématique de la consommation énergétique. Dédoubler les cores Series 5XT c'était "simple", mais les GPU finissaient alors par devenir trop gourmands. L'architecture a donc été revue pour devenir similaire à celle des GPU desktops modernes et pouvoir multiplier, à l'intérieur d'une structure fixe, des blocs (USC - Unified Shading Clusters) comprenant des unités de calcul et d'autres des unités de texturing. De quoi supprimer la redondance pour rendre le GPU plus compact et plus économe.
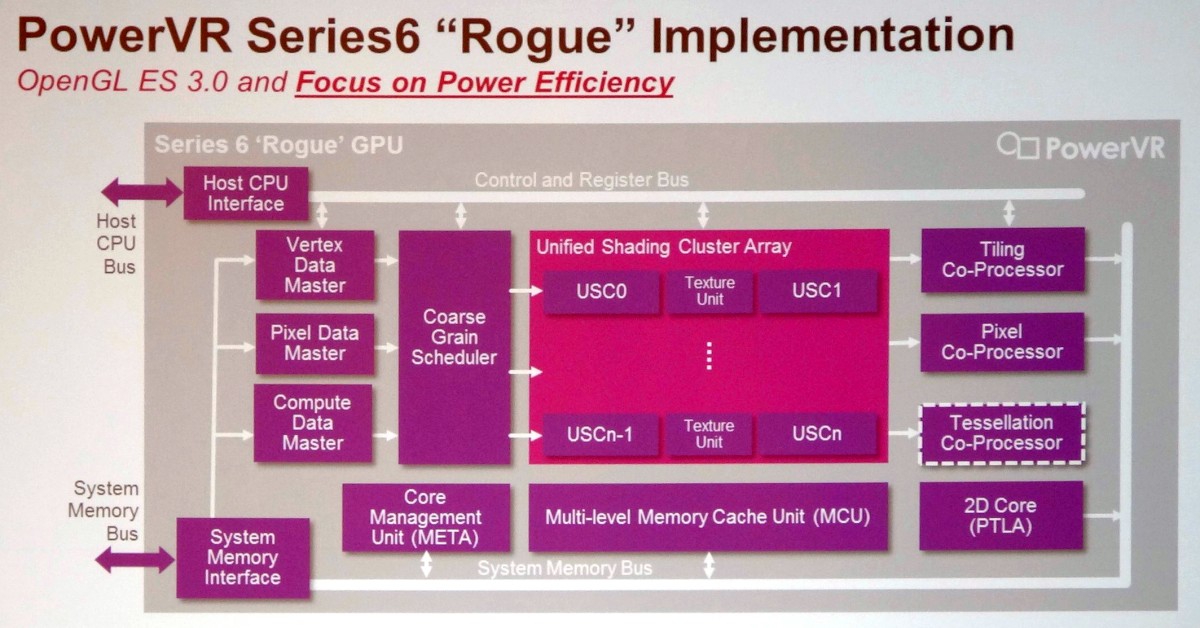
De nombreux petits raffinements ont été apportés à l'architecture, toujours dans le but de la rendre plus efficace. C'est le cas par exemple du passage à un fonctionnement perçu de type scalaire des unités de calcul (comme pour les GeForce 8+ et les Radeon HD 7000+) ou encore du support d'une compression lossless pour la géométrie et les pixels. Le support d'OpenGL 3.0 est complet et du côté DirectX on passe au niveau 10_0. Le support de DirectX 11_1 est par ailleurs possible, optionnellement, avec notamment l'ajout d'un tessellateur.
Parmi les détails, Imagination précise ceci :
- les unités de texturing ont gagné en performances lors d'accès dépendants
- le support de la basse précision lowp (FX10) a été abandonné, ne restent que le mediump (FP16) et le highp (FP32)
- les branchements dynamiques sont dorénavant traités par groupes de threads et peuvent être moins performants en cas de divergence, comme sur GPU desktop et contrairement aux Series 5
- lors de l'utilisation de MRT - Multiple Render Targets (écriture vers plusieurs buffers en une seule passe), il faut prendre garde à ne pas dépasser 128 bits par pixel, le maximum supporté pour profiter du buffer lié au tile rendering, ce qui se traduit grossièrement par "HDR + MSAA + MRT = pas bien"
Imagination prévoit actuellement 6 variantes, les PowerVR G6100, G6200 et G6400 ainsi que les PowerVR G6230, G6430 et G6630. D'après ce que communique Imagination, les G6x30 affichent des débits bruts similaires aux G6x00 mais avec quelques améliorations de l'architecture pour gagner en performances. S'il est possible que ces G6x30 soient compatibles avec le niveau 11_1 de DirectX, nous estimons plus probable que ce support ne soit prévu que pour une variante future.
Le second chiffre représente le nombre d'USC : 1 pour le G6100 jusqu'à 6 pour le G6630. Chaque paire d'USC, excepté pour le G6100 bien entendu, est associée à un bloc d'unités de texturing, mais Imagination ne précise pas le nombre d'unités de calcul (MAD) par USC. Il s'agira probablement de 32 unités de calcul par USC, avec, en terme de puissance brute et à fréquence égale, un G6100 qui serait équivalent à un SGX544MP2 et un G64x0 qui serait équivalent à un SGX554MP4.
Si ces GPU semblent prometteurs sur le papier, il faudra cependant patienter jusqu'à l'arrivée des premiers SoC qui les intégreront, et d'informations plus complètes, pour se faire une idée plus précise de leur niveau de performances.
Annoncé il y a plus de 2 ans, le Nova A9600 de ST-Ericsson devait être le premier SoC à intégrer un GPU PowerVR Series 6. Malheureusement le Nova A9600 a fait les frais du divorce entre STMicro et Ericsson.
GDC: AMD, Intel, Nvidia, Qualcomm... à la GDC
Lors de la GDC, dont l'édition 2013 s'est terminée vendredi dernier à San Francisco, les plus importants fournisseurs de technologies graphiques (les GPU Radeon, Mali, PowerVR, HD Graphics, GeForce, Adreno) étaient présents avec notamment pour but de convaincre les développeurs de jeux vidéo d'exploiter toutes les possibilités de leurs produits récents à travers des techniques de rendu toujours plus évoluées que ce soit sur PC ou dans le monde mobile, qui progresse à vive allure.






En plus de diverses présentations, AMD, ARM, Imagination, Intel, Nvidia et Qualcomm étaient présents à travers des stands principalement exploités pour mettre en avant leurs outils maisons : AMD GPU PerfStudio, ARM Mali Graphics Debugger, Imagination PVRTune, Intel Graphics Performance Analyzers, Nvidia Nsight, Qualcomm Adreno Profiler
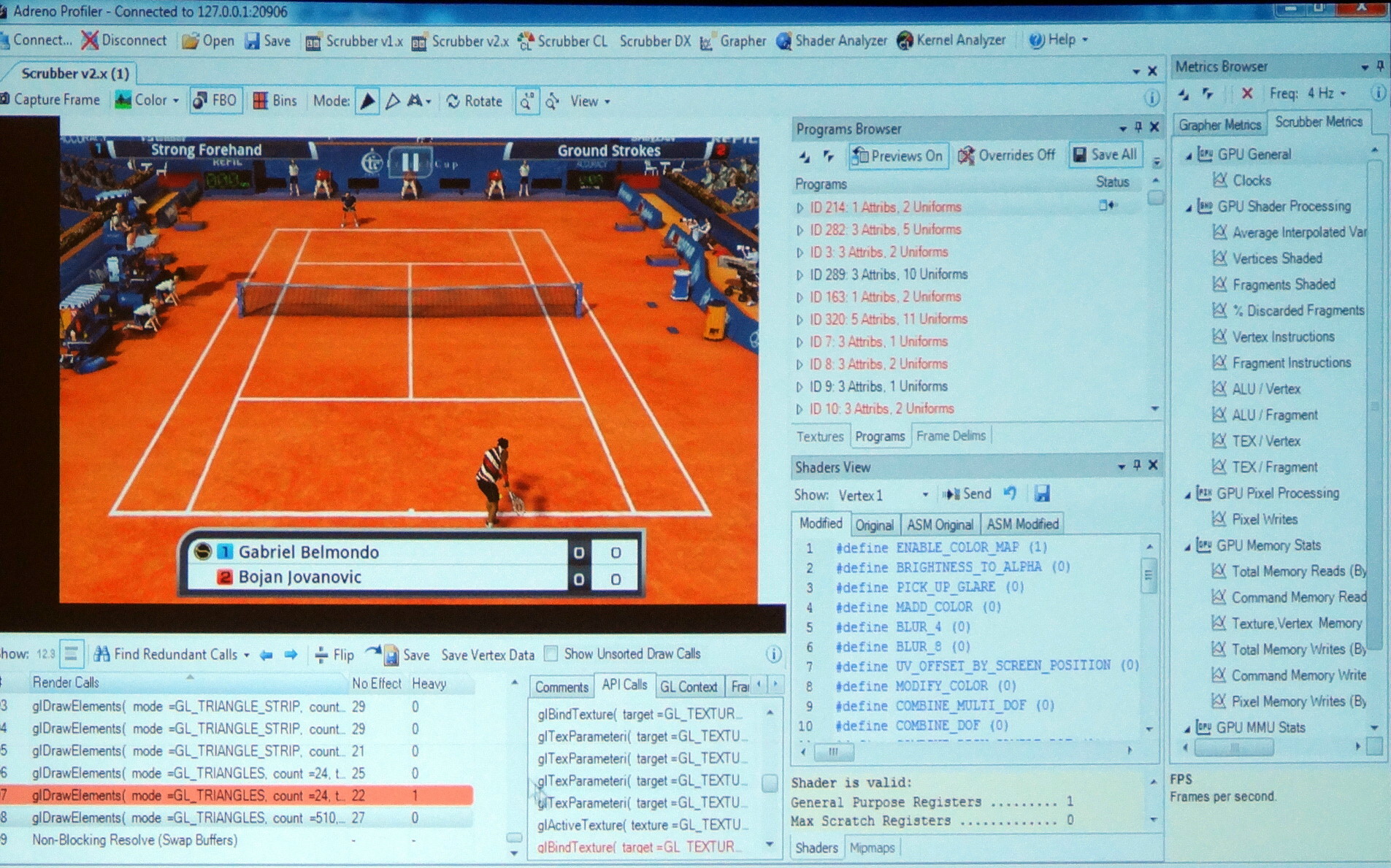
Ici en exemple, l'Adreno Profiler de Qualcomm qui permet d'observer assez facilement le comportement des GPU Adreno et d'appliquer des modifications à la volée pour identifier des bugs ou des goulots d'étranglement (bottlenecks). Il est ainsi possible de modifier un shader, de désactiver la synchronisation verticale, de réduire la taille de toutes les textures, etc., et d'observer l'impact en temps réel sur le smartphone ou sur la tablette.
Les outils de tous les acteurs cités proposent des possibilités similaires, chacun ayant des petits avantages ou inconvénients par rapport à la concurrence. Ils sont en général autant adapté au débogage et à l'optimisation de la partie graphique que de la partie "compute" éventuellement exposée pour les GPU.
Lors de plusieurs rencontres avec des développeurs, nous avons voulu savoir quels outils ils préféraient et pourquoi. La réponse de nos interlocuteurs a été unanime : aucun ! Pourquoi ? Tout simplement parce que la multiplication de ces outils devient problématique et que peu importe leurs qualités ou leurs défauts, devoir utiliser un outil spécifique à chaque marque de GPU est tout sauf pratique, d'autant plus quand il faut en supporter bon nombre comme c'est le cas sous Android.

Même avec seulement 3 acteurs, c'est un problème dans le monde PC comme le rappelle Crytek en parlant des opportunités et défis à venir. Il serait ainsi intéressant que Microsoft et Google proposent des outils de développement plus évolués qu'actuellement et dans lesquels les concepteurs de GPU pourraient venir s'interfacer pour proposer autant de détails que dans leurs propres outils mais d'une manière plus ou moins unifiée.
Notez au passage que Crytek en profite pour rappeler à Microsoft qu'il serait peut-être bon de travailler sur la documentation de DirectX !
HSA, calcul hétérogène: Intel et Nvidia isolés?
Début juin, AMD inaugurait la HSA Foundation en partenariat avec ARM, Imagination Technologies, MediaTek et Texas Instruments. Cette fondation a pour rappel comme objectif de concevoir des standards dédiés au calcul hétérogène qu'ils concernent l'aspect programmation ou l'implémentation matérielle. Coup sur coup, elle vient d'accueillir de nouveaux membres importants.
ATI, avant d'être englobé par AMD, avait été le premier à nous faire part de l'ambition d'utiliser la puissance de calcul des GPU à d'autres fins que le rendu 3D en temps réel pour lequel ils ont à l'origine été conçus. Probablement par manque de moyens, ces développements ont avancé très lentement et il aura fallu attendre plus d'un an avec la concrétisation de l'initiative similaire de Nvidia pour que le GPU mette enfin un pied dans la porte du monde du calcul haute performance. Disponible dès début 2007, CUDA a ainsi relégué au second plan toute initiative similaire de la part d'ATI/AMD.
Quelques tergiversations au niveau des choix technologiques et des langages de programmation, ainsi que l'intégration d'ATI dans AMD, ont par la suite empêché toute avancée rapide. Il faut dire qu'avec le projet Fusion d'AMD, l'objectif n'était plus simplement d'exploiter le GPU, mais de profiter de la symbiose GPU + CPU. Par ailleurs AMD a fait le choix, probablement par défaut, de se reposer sur des standards ouverts. A l'inverse, Nvidia a opté pour une approche propriétaire qui lui a permis d'être plus agile et surtout beaucoup plus rapide dans ses développements.
Entre le monde x86 largement dominé par Intel, et le calcul sur GPU dominé par Nvidia, AMD s'est retrouvé dans une situation délicate dans laquelle il était devenu difficile de peser sur les choix technologiques des développeurs et donc de les inciter à programmer pour ses solutions hétérogènes.
Pour sortir de cette impasse, AMD avait besoin de rallier d'autres acteurs à sa cause. Proposer un standard d'architecture pour le calcul hétérogène était une solution naturelle à ce problème, d'autant plus qu'il allait devenir essentiel pour de nombreux autres acteurs : les concepteurs de SoC ultra basse consommation. Lorsque l'enveloppe thermique est limitée, comme c'est le cas pour tous les périphériques mobiles, pouvoir exploiter différents types de curs destinés au calcul (séquentiel ou massivement parallèle) permet de maximiser les performances dans plus de cas de figure. En d'autres termes, tout l'écosystème ARM était voué à exploiter le calcul hétérogène et allait faire face aux mêmes problèmes qu'AMD lorsqu'il s'agirait de trouver la meilleure approche pour le mettre en place.
Mi-2011, AMD a ainsi proposé la FSA, Fusion System Architecture, comme base de travail, avec en coulisse le support d'ARM. Un an plus tard, après un changement de nom pour HSA, Heterogeneous System Architecture, AMD a remis tous ses travaux initiaux à une fondation dont les membres fondateurs initiaux incluaient également ARM, Imagination Technologies, MediaTek et Texas Instruments. Les statuts de la fondation laissaient cependant la possibilité à d'autres acteurs de devenir des membres fondateurs s'ils se manifestaient dans les 3 mois, à partir du 1er juin 2012.
A quelques jours de l'échéance, Samsung a ainsi rejoint la fondation en tant que sixième membre fondateur, accompagné par Apical, Arteris, MulticoreWare, Sonics, Symbio et Vivante en tant que membres secondaires. Si l'arrivée d'un poids lourd tel que Samsung était une bonne nouvelle pour la HSA, l'absence de Qualcomm était étonnante. Avec des objectifs très importants au niveau des capacités de ses SoC, et l'arrivée à la tête de son département d'ingénierie d'Eric Demers, l'ancien responsable des architectures GPU d'AMD, il ne faisait aucun doute que Qualcomm voudrait rejoindre la HSA
et pas en tant que membre secondaire.
Les négociations ont probablement été plus compliquées et longues que prévues, mais ont fini par aboutir et la HSA Foundation a modifié ses statuts de manière à faire disparaître la date limite pour l'entrée de nouveaux membres fondateurs. Hier, Qualcomm est ainsi devenu le septième membre fondateur.

En s'adjoignant le poids de presque tout l'écosystème ARM, AMD ne pouvait probablement pas trouver de meilleure approche pour le développement d'un standard dédié au calcul hétérogène et la présentation graphique du site de la fondation ne laisse guère de doute concernant le fait que la porte reste ouverte pour un huitième membre principal. S'il faudra encore convaincre certains acteurs importants tels qu'Apple ou Microsoft, les grands absents restent Intel et Nvidia.
Ceux-ci, d'une part par égo vis-à-vis d'AMD et d'autre part pour ne pas faciliter l'arrivée de concurrence sur des marchés très juteux, restent hostiles à l'arrivée d'un tel standard. Intel veut conserver un contrôle total de sa plateforme, proposer ses propres solutions destinées au calcul massivement parallèle et favoriser l'utilisation des cores x86 qui sont en train de gagner beaucoup en efficacité énergétique. De son côté, Nvidia n'entend pas saboter les premiers succès commerciaux de sa division Tesla liée à l'architecture propriétaire CUDA, et prépare sa propre solution hétérogène.
Pour éviter de se retrouver isolés du reste de l'industrie, nul doute cependant qu'Intel et Nvidia vont suivre de très près l'évolution de la HSA ainsi que ses premières spécifications. Annoncées pour fin 2011, elles ont pris du retard mais seraient maintenant entre les mains de l'ensemble des membres de la fondation pour une publication avant la fin de cette année.
AFDS: AMD, ARM, ImgTech, TI : HSA Foundation

L'AMD Fusion Developer Summit, un forum technologique dédié au calcul hétérogène, a actuellement lieu à Seattle. Ce forum peut être vu comme la réplique d'AMD à la GPU Technology Conference de Nvidia qui s'est tenue le mois passé, mais un point important distingue cependant les deux évènements : AMD conçoit autant des cores CPU que des cores GPU. Plus que le calcul massivement parallèle, qui exploite les GPU, c'est ainsi le calcul hétérogène qui est ici à l'honneur.
Exploiter en symbiose des cores CPU et des cores GPU est complexe, notamment parce qu'ils ne partagent pas encore un espace mémoire totalement unifié, même si l'APU Trinity apporte quelques avancées à ce niveau. L'an passé, AMD avait annoncé la Fusion System Architecture, une tentative d'apporter des réponses à cette problématique de manière à pouvoir fournir une plateforme plus simple à exploiter pour un maximum de développeurs. AMD avait alors précisé vouloir en faire un standard ouvert : publier une documentation complète avant la fin 2011 et mettre en place un consortium pour gérer la FSA.
AMD a pris du retard sur la documentation qui n'est toujours pas disponible, mais a entretemps renommé la FSA en Heterogeneous System Architecture de façon à la détacher de sa marque Fusion. Il y a quelques mois, AMD précisé ses plans au sujet du consortium qui se dénommerait HSA Foundation et se verrait transférer tous ses travaux initiaux.
Cette édition de l'AFDS est l'occasion pour AMD de concrétiser la mise en place de la HSA Foundation, qui est effective depuis quelques jours. Il s'agit d'une organisation à but non-lucratif qui sera dorénavant chargée du développement et de la promotion de ce standard ouvert destiné à simplifier le calcul hétérogène qu'il concerne les PC, les smartphones ou les serveurs. Sa tâche sera également de produire des outils de développements efficaces et d'aider à la formation des développeurs.


AMD transfère à cette fondation la totalité de ses travaux initiaux sur la FSA/HSA, à savoir : un compilateur open source, des librairies et les documentations préliminaires qui concernent la programmation, les spécifications hardware ainsi que les spécifications software. AMD fournis par ailleurs une partie des fonds pour la mise en place de la fondation.
La fondation est bien entendu destinée à accueillir un maximum de membres, qui pourront être de plusieurs types : fondateurs (ce qui est encore possible s'ils y sont invités dans les 90 jours), promoteurs, supporters, contributeurs, universitaires et autres associés. Comme c'est généralement de mise pour ce type d'organisation, chaque membre participe à son budget de fonctionnement suivant son rôle, ce qui représente jusqu'à 125.000$ par an pour les membres fondateurs.

Les représentants des cinq membres fondateurs de la HSA Foundation, qui forment son conseil d'administration actuel.
La mise en place de la HSA Foundation n'aurait pas pu se faire sans son élargissement à d'autres grands noms de l'industrie. La présence d'ARM à l'AFDS l'an passé ne laissait aucun doute sur l'intérêt de la société spécialisée dans les modules destinés au SoC, pour laquelle le calcul hétérogène est la seule solution viable sur le plan énergétique, et c'est donc sans surprise qu'ARM fait partie des membres fondateurs de la fondation. D'autres ont rejoint l'initiative et sont tous liés aux SoC d'une manière ou d'une autre : Imagination Technologies, MediaTek et Texas Instruments.
Chacune de ces sociétés disposera d'un membre au conseil d'administration de la fondation (Manju Hedge, Vice-Président des solutions développeurs destinées au calcul hétérogène chez AMD et ex-CEO d'Ageia; Jem Davies Vice-Président responsable de la division Media Processing chez ARM ) qui sera gérée au quotidien par Phil Rogers, Président de la HSA Foundation et AMD Corporate Fellow.
Reste bien entendu que d'autres grands noms sont malheureusement absents du tableau, tels que Nvidia et surtout Intel. Les membres fondateurs ne désespèrent pas à l'idée de les voir rejoindre l'initiative, sans cependant se faire d'illusion à ce sujet. Mais ce sont, avant tout autre chose, les développeurs qu'ils devront s'attacher à convaincre et pour cela, comme le rappelait Adobe présent également à l'AFDS, il faudra leur proposer des outils complets, performants, simples d'utilisation et fiables. Un gros chantier en perspective.
Vous pourrez retrouver toutes les informations disponibles actuellement sur le site de la HSA Foundation qui vient d'être mis en ligne mais la documentation complète se fait cependant toujours attendre.
PowerVR Series 6



 Annoncée en septembre dernier larchitecture GPU mobile série 6 de PowerVR vient de se dévoiler un petit peu plus. Imagination Technologies a en effet annoncé publiquement le premier client qui utilisera larchitecture, à savoir ST-Ericsson (joint venture entre ST-Microelectronics et Ericsson). La puce baptisée Nova A9600 est prévue pour les nodes 28 nm et utilisera larchitecture Cortex A15 dARM à une fréquence pouvant atteindre jusque 2.5 GHz. Des spécifications qui reprennent sans surprises celles de lOMAP 5 de Texas Instruments, ce dernier se contentant cependant de larchitecture 5XT (version « multi core » du Series 5 adopté également par Sony pour la prochaine PSP).
Annoncée en septembre dernier larchitecture GPU mobile série 6 de PowerVR vient de se dévoiler un petit peu plus. Imagination Technologies a en effet annoncé publiquement le premier client qui utilisera larchitecture, à savoir ST-Ericsson (joint venture entre ST-Microelectronics et Ericsson). La puce baptisée Nova A9600 est prévue pour les nodes 28 nm et utilisera larchitecture Cortex A15 dARM à une fréquence pouvant atteindre jusque 2.5 GHz. Des spécifications qui reprennent sans surprises celles de lOMAP 5 de Texas Instruments, ce dernier se contentant cependant de larchitecture 5XT (version « multi core » du Series 5 adopté également par Sony pour la prochaine PSP).
Côté disponibilité, rien nest officiellement annoncé si ce nest que ST-Ericsson pense pouvoir échantillonner lA9600 avant la fin de lannée, tout comme TI pour son OMAP 5. La disponibilité en volume de lOMAP 5 est pour rappel fixée à la seconde moitié 2012.
Pour la première fois, un chiffre est communiqué autour des performances de la série 6 de PowerVR avec 210 GFlops, soit environ 4x plus que les performances estimées pour le SGX543MP4+ de la prochaine PSP. Une estimation ambitieuse mais qui dépend surtout de la place sur le die accordé au GPU sur le futur Nova A9600.