
Les contenus liés aux tags TSMC et 10nm
Afficher sous forme de : Titre | FluxTSMC vise 2020 pour le 5nm via l'EUV
Résultats TSMC, 16 FinFET+ dans l'iPhone 6s
16nm à l'heure, EUV en retard pour TSMC
ASML vend 15 machines EUV à Intel
Quelques (bonnes !) nouvelles de l'EUV
1er tape-out 10nm ARM chez TSMC



ARM vient d'annoncer qu'il avait effectué le tape-out d'un puce de test en 10nm chez TSMC. Cette puce intègre 4 coeurs Artemis, le successeur du Cortex-A72, utilisant l'architecture ARMv8-A mais un iGPU simplifié avec un seul coeur graphique. Le communiqué précise que le tape-out, c'est-à-dire l'envoi des informations chez TSMC pour graver la puce, a eu lieu au quatrième trimestre 2015.
ARM a précisé à AnandTech que le tape-out avait en fait eu lieu en décembre, mais que si la validation de la puce de test est un succès il est question d'un retour de la puce chez ARM dans les semaines à venir, soit un délai tout de même assez long.

[ 1 ] [ 2 ]
Du coup les chiffres annoncées, qui font état selon les cas de 11-12% de performances en plus pour une même consommation que le 16nm ou d'une consommation réduite de 30% pour les mêmes performances, sont en fait des simulations. Dans le même temps la densité du 10nm TSMC devrait être jusqu'à 2.1x plus importante que celle du 16nm.
Cette annonce fait suite à un partenariat datant d'octobre 2014 sur le 10nm. Pour rappel le début de la production en volume pour le 10nm chez TSMC est prévu pour 2017, mais à l'instar du 20nm une partie des clients attendront le node suivant (7nm) en 2018.
Quelques nouvelles du 10 et 7nm chez TSMC
TSMC tenait la semaine dernière à San José son symposium, une conférence au cours de laquelle le fondeur taiwanais a partagé des détails inédits sur ses prochains process de fabrication de puces. Des détails rapportés par nos confrères d'EETimes et de Semiwiki (partie 1 et partie 2 ).
16FF+ et 16FFC
Pour le 16nm, si Apple l'utilise depuis de longs mois, les autres clients semblent peiner à lancer leur production, probablement à cause des coûts importants engendrés par la nouvelle technologie et aussi de quelques limites de capacité. TSMC s'est contenté de confirmer que son 16FF+ est en production "volume" (c'est à dire dédiée à des produits finis) depuis le troisième trimestre 2015 et qu'il s'attend à ce que son volume de wafers 16nm augmente significativement entre juin et octobre avec pour but d'atteindre 300 000 wafers par trimestre d'ici à la fin de l'année. Plusieurs produits 16FF+ sont déjà en production, comme les FPGA de Xilinx.
En parallèle TSMC propose également une version "compacte" (16FFC) de son process qui tente de réduire les coûts en diminuant par exemple le nombre de masques nécessaires. Cette version FFC sera celle qui sera privilégiée pour les usages non haut de gamme, même si elle propose plusieurs avantages intéressants, par exemple pour les usages très basse consommation (tension d'alimentation de 0.5V), mais aussi pour une version spécifique aux usages automobiles (une variante qui attendra mi 2017). TSMC avait annoncé cette variante publiquement en janvier, mais la production en volume sera entamée dès le mois d'avril. 70 tapeout 16FFC sont attendus cette année (à titre de comparaison, il y a déjà eu 70 tapeout 16FF+ en 2016), il sera intéressant de voir quels produits l'utiliseront !
10nm
TSMC est confiant sur l'arrivée du 10nm, même s'il s'agira vraisemblablement d'un node qui ne sera pas utilisé par tout le monde. La production en volume prendra place dans la Fab 15, dans deux nouvelles tranches construites pour l'occasion (les autres tranches produisent en 28nm). Le constructeur s'attend à produire 200 000 wafers par trimestres d'ici la fin de l'année 2017. Un premier tapeout 10nm pour un produit d'un de ses clients aurait été réalisé et la qualification est attendue au troisième trimestre cette année.
Malgré tout le 10nm reste un node qui sera limité côté clients, Xilinx ayant par exemple indiqué publiquement qu'ils attendraient le 7nm. Étant donné les délais suspicieusement courts entre le 10 et le 7nm, on peut les comprendre (productions en volume respectives annoncées pour 2017 et 2018) !
7nm
L'attente autour du 7nm est importante, et TSMC a commencé a donner quelques réponses à nos interrogations. D'abord, le fondeur proposera dès le début deux versions distinctes de son process 7nm, une version dédiée au mobile, et une autre aux produits hautes performances (+10 à 15% de performances en plus, avec pour but d'atteindre 4 GHz).
Les deux variantes devraient entrer en qualification en simultané au premier trimestre 2017. Pour expliquer le délai court entre le 10 et le 7nm, nous avions spéculé que le constructeur utiliserait une stratégie identique à celle utilisée entre le 20 et le 16nm, à savoir utiliser un BEOL (la partie basse de la puce qui contient les couches métalliques d'interconnexion) commun ce qui limiterait les gains de densité.
Après avoir évité a plusieurs reprises de répondre à la question dans ses conférences aux investisseurs, TSMC a confirmé que ce ne sera pas le cas : la variante mobile du 7nm apportera une densité 1.63x supérieure à celle de son 10nm ! C'est certes moins que le passage 28 à 20nm (1.9x) mais largement au dessus de la transition 20 à 16nm (1.15x, obtenu principalement par des optimisations des règles de design). Par rapport au 10nm, le 7nm devrait apporter 15 à 20% de performances en plus, ou 35 à 40% de consommation en moins selon les usages.
TSMC utilisera un matériel commun à 95% entre le 10 et le 7, facilitant la transition. La différence tiendra sur l'utilisation plus massive à 7nm du quadruple patterning (on ne sait pas encore exactement ou il sera utilisé, il semblait entendu sur les dernières roadmaps ITRS que le quadruple patterning - SAQP - serait utilisé pour les couches métal à 10 et 7 par exemple).
Le développement du 7nm avance puisque TSMC a indiqué avoir déjà produit des modules de SRAM de 128 Mbit, atteignant déjà des yields de 30% pour des dies pleinement fonctionnels. Il est toujours difficile de comparer ces chiffres tant les constructeurs les gardent secrets. En février 2010, soit une vingtaine de mois avant le lancement des premiers GPU 28HP (les Radeon 7970), TSMC annonçait cependant des yields sur sa SRAM de 26% . Atteindre 30% sur des puces pleinement fonctionnelles semble donc particulièrement encourageant à ce stade.
Si l'on considère les difficultés attendues par tous à 10 et à 7nm, la roadmap de TSMC semble particulièrement agressive et il faudra voir si le fondeur arrive a l'exécuter. On comprendra en tout cas qu'il ne faudra pas s'attendre à voir de 10nm ailleurs que chez Apple, ou possiblement Qualcomm étant donné les délais.
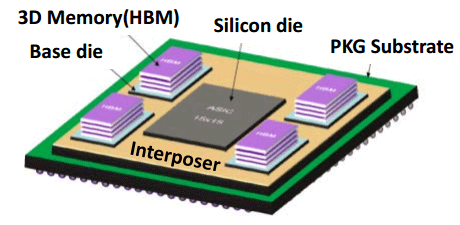
On conclura sur quelques informations données côté packaging, TSMC pense que c'est de ce côté que l'on réalisera des gains "faciles" et importants. D'abord pour la version haute performance CoWoS (Chip on Wafer on Substrate) qui consiste à utiliser un interposer en silicium pour relier des puces, le fondeur indique que l'on pourra atteindre des tailles plus importantes à 7nm dépassant les 1200mm2 (l'interposer utilisé par AMD sur les Fury X mesure un peu plus de 1000mm2) ce qui devrait donner un peu plus de marge. TSMC a également indiqué avoir réalisé le tapeout le mois dernier d'un "CPU" accompagné de deux piles de mémoire HBM2.
Côté mobile, c'est l'InFO WLP (Integrated FanOut Wafer Level Packaging) qui devrait apporter des gains intéressants. Par rapport au CoWoS, il s'agit d'une version beaucoup plus fine qui réduit voir élimine le substrat en "moulant" un ou plusieurs dies pour reconstituer un package très fin. TSMC annonce 20% de performances en plus pour une consommation 10% inférieure.
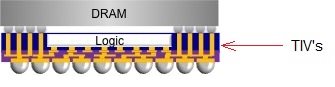
Exemple d'InFO POP
TSMC a rajouté une variante POP qui ajoute la possibilité de superposer un autre package (par exemple mémoire) par dessus un package InFO. TSMC utilise des fils dans les parties neutres du die pour relier la puce du dessus (des TIV, un concept identique aux TSV - through silicon Vias - si ce n'est que les fils traversent cette fois ci le package InFO et non un interposer). La production des InFO POP devrait débuter au second trimestre, ce qui coïncide côté timing avec le début de production attendu du prochain SoC d'Apple qui devrait utiliser ces technologies de packaging.
L'EUV possiblement pour le 7nm ?
Le site SemiWiki nous rapporte quelques informations sur l'état de la fabrication EUV, en provenance de la conférence SPIE Advanced Lithography qui se tient actuellement à San José.
Lors de la même conférence l'année dernière, les nouvelles étaient pour rappel plutôt bonnes (voir le lien pour un rappel complet sur la fabrication des processeurs et l'importance capitale de l'EUV !) et l'on espérait une introduction en cours de process pour le 10nm, et une introduction complète à 7nm. Malheureusement, on le rappelait en janvier, TSMC avait calmé les ardeurs en indiquant qu'il faudrait attendre le 5nm pour une éventuelle introduction de cette technologie.

SemiWiki confirme certains chiffres donnés lors de la dernière conférence aux investisseurs de TSMC, à savoir que la machine avait atteint sur une période de quatre semaines une production de 518 wafers/jour, un niveau encore largement insuffisant. Intel a partagé également quelques chiffres, un peu inférieurs à ceux de TSMC, à savoir entre 2000 et 3000 wafers par semaine (285-428 par jour).
On notera quand même que le taux de disponibilité des scanners de la société ASML a augmenté, passant de 55 à 70% chez TSMC (Intel rapportant une disponibilité identique) ! On notera que s'il est question d'une introduction en début de node à 5nm, TSMC laisse la porte ouverte pour le 7nm si jamais des progrès étaient effectués. Intel de son côté n'a pas donné d'information. Samsung envisagerait l'introduction à 7nm selon les présentations, sans plus de précisions.
Si la question de la disponibilité est importante, celle de la puissance de la source lumineuse l'est encore plus. Après avoir été limité à 40 watts l'année dernière, les machines actuellement en évaluation chez TSMC disposent désormais de sources 80 watts. C'est mieux, mais cela reste loin des 250 watts promis par ASML pour fin 2015. Les dernières prédictions sont désormais de 250 watts en 2016-2017, et au delà en 2018-2019, des plages particulièrement larges.
Atteindre les 250 watts de puissance permettrait d'augmenter significativement la cadence de production, atteignant 170 wafers/heure en théorie. ASML a effectué des démonstrations que TSMC et Intel semblent juger prometteuses de 185 et 200 watts. Reste à les voir en production, bien évidemment. Les challenges de cette technologie restent complexes et ne se limitent pas à ces deux points cruciaux, la question des défauts dans les masques est elle aussi importante même si là aussi TSMC et Intel ont visiblement noté quelques progrès. Vous pouvez retrouver plus de détails sur ces points dans l'article de SemiWiki .
L'ITRS prépare l'après loi de Moore
C'est la section actualité de la très sérieuse revue scientifique Nature qui l'affirme : la loi de Moore est arrivée à son terme. Énoncée en 1965 par Gordon Moore, l'un des cofondateurs d'Intel, il s'agit d'une observation par laquelle la quantité de transistors dans les circuits intégrés doublait à peu près tous les ans. Une observation transformée en loi pour prédire que cette cadence pouvait être extrapolée pour les années à venir.
En 1975, la loi avait été révisée pour prendre la forme que l'on connaît actuellement, à savoir un doublement des transistors tous les deux ans. L'importance de la loi de Moore allait cependant au-delà de la simple prédiction puisqu'elle prenait en compte les coûts de fabrication : l'observation se fait sur les puces ayant le coût par transistor le plus faible (tentant donc de prendre en compte les questions de yields et de défauts en fonction de la taille des puces).
Plus qu'une prédiction, la loi de Moore a servie, particulièrement chez Intel, de guide au fil des années, prédisant à l'avance les budgets en nombre de transistors alloués aux ingénieurs, et poussant vers l'avant la nécessité d'investir dans de nouveaux process de fabrications, la fameuse stratégie du Tick-Tock poussée d'abord en interne par Pat Gelsinger au début des années 2000 avant d'être utilisée publiquement pour décrire les générations à venir.
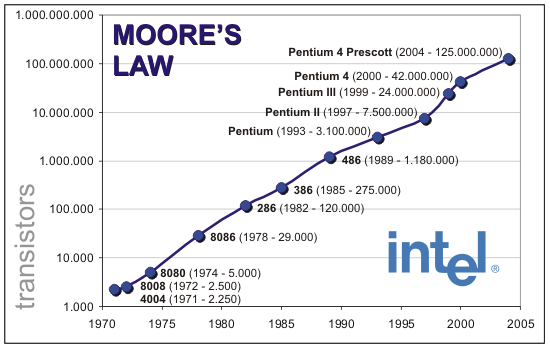
De manière intéressante, au-delà d'Intel, c'est toute l'industrie du semi-conducteur qui s'est mise d'accord autour de la loi de Moore, à savoir non seulement les fondeurs, mais aussi et surtout les fournisseurs d'outils. Le besoin de coordination entre tous les acteurs aura conduit à l'élaboration d'une roadmap, d'abord appelée National Technology Roadmap for Semiconductors dès 1993, avant d'être renommée sous sa forme actuelle, l'International Technology Roadmap for Semiconductors (ITRS).
Le rôle joué par cette roadmap, dont la dernière version a été publiée en 2013 aura été particulièrement important ces dernières années où, passé le 90nm, les challenges techniques ont contraint à des changements d'approches importants. L'augmentation des performances par la fréquence, méthode classique aura atteint un plateau à cause de l'augmentation de la consommation, poussant dans le commerce les stratégies de multiplication des coeurs que l'on connaît. Le rôle de la roadmap, au-delà de la concertation, est de s'assurer de trouver des pistes pour continuer la cadence de réduction des coûts/augmentation des transistors de la loi de Moore.
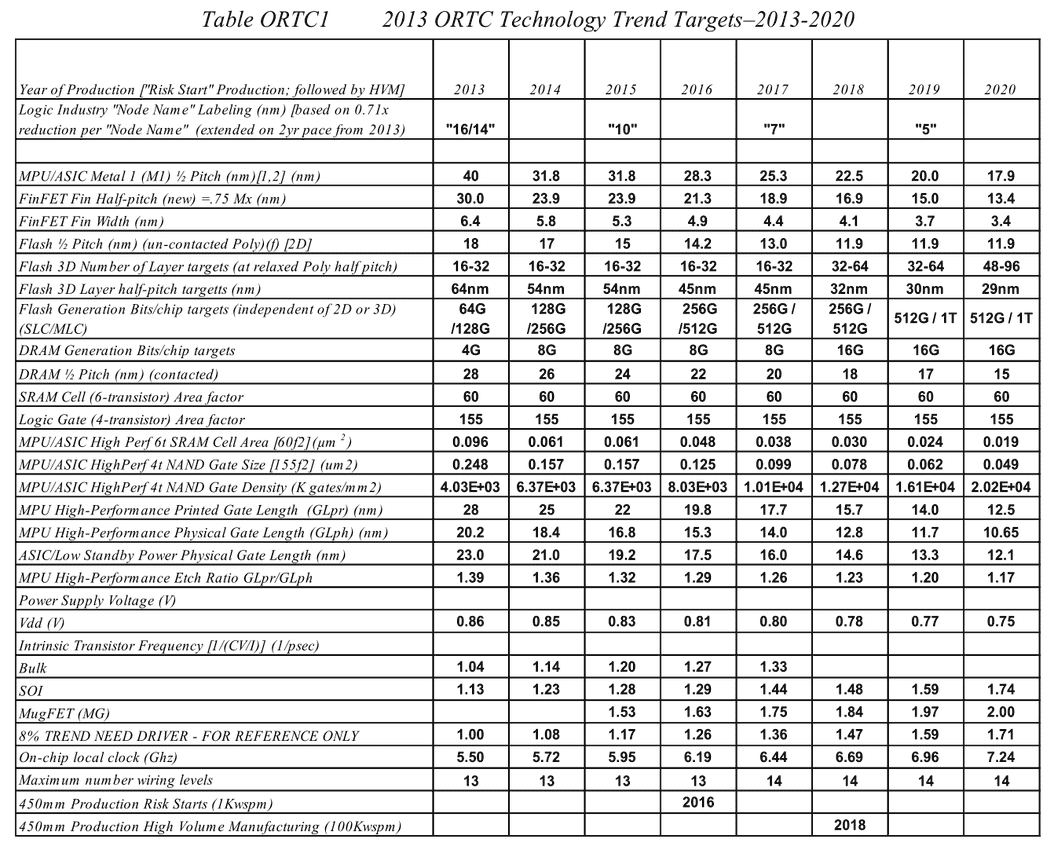
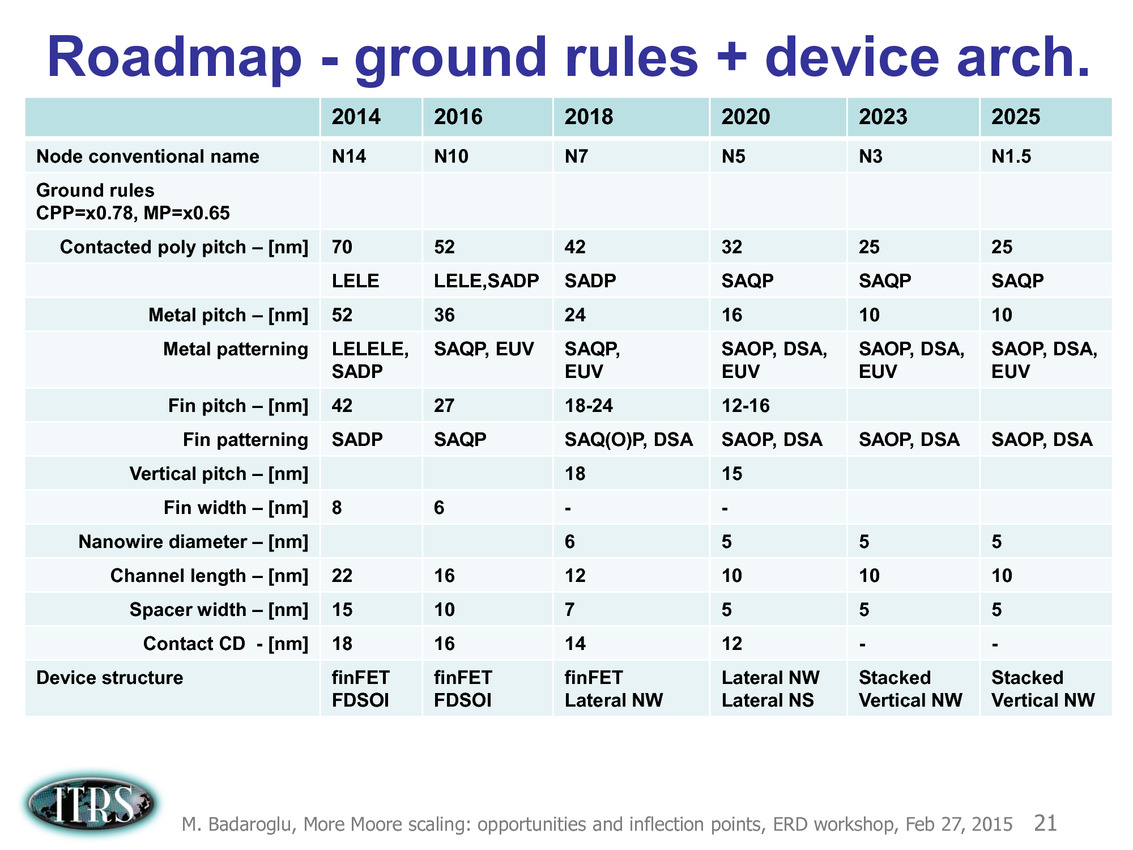
La dernière roadmap ci-dessus donnait des grandes lignes sur la manière de mettre à l'échelle les différents composants des transistors. Après les difficultés autour du 90nm, l'industrie est passé progressivement de la règle dite de la mise à l'échelle géométrique (on réduit tout dans des proportions identiques, le nom du node indiquant en général la taille de la porte) à celle de la mise à échelle par équivalence (equivalent scaling).
Etant donné que différentes parties composant les puces posent des problèmes différents, des règles d'équivalences ont été mises au point pour permettre de continuer a atteindre les buts de réduction des coûts/augmentation de densité imposé par la loi de Moore (on peut voir sur le tableau la couche d'interconnexion M1 et l'écart minimal entre deux transistors FinFET, en passant par des estimations des tailles de blocs fondamentaux comme la SRAM).
Pour 2016, la roadmap annonçait par exemple de la SRAM 6 transistors (6T) haute performance en 10nm autour de 0.048 µm2, ce qui n'est pas très éloigné de ce que présentait Samsung il y a une dizaine de jours de cela. En pratique cependant, on notera qu'on est globalement assez en retard sur la roadmap qui prévoyait des débuts de production à petite échelle en 10nm en 2015 (Risk Start dans la roadmap, suivi de HVM, fabrication en volume). Chez TSMC par exemple, la production risque est prévue pour la fin 2016 avec une production en volume pour 2017. Intel prévoit ses puces en volume pour 2017 également.
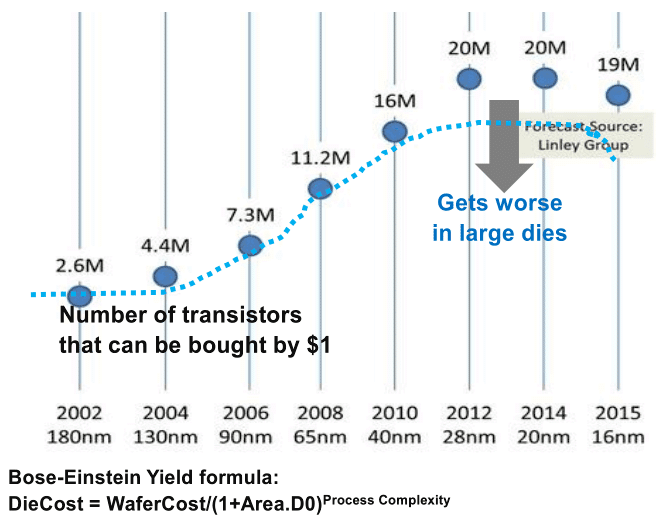
Évidemment depuis 2013 les choses se sont un peu plus compliquées et l'absence de roadmap en provenance de l'ITRS n'a pas forcément aidé. En pratique, la réduction des coûts s'est arrêtée, avec même un retour en arrière à 16nm signant de facto la fin de la loi de Moore, comme on peut le voir sur cette estimation ci-dessus tirée d'une présentation de l'ITRS en février 2015.
L'absence de nouvelle roadmap en provenance de l'ITRS aura même donné lieu à des divergences d'interprétations fortes, Intel titillant ses concurrents sur la question de la densité théorique. TSMC et Samsung ont fait pour rappel le choix de conserver un BEOL (Back End of Line, la partie basse d'une puce qui sert à l'interconnexion des transistors) commun entre le 20 et le 16nm pour accélérer la cadence de mise en production. En pratique chez TSMC, malgré le BEOL commun, le half pitch M1 reste tout de même dans les clous à 32nm (entre 40 et 31.8 sur la roadmap).
La densité pratique reste de toute manière très différente de ce que peuvent proposer des formules grossières comme celle utilisée par Intel (qui multipliait le pitch M1 par le pitch entre deux portes), qui pour exploiter les FinFET aura fait le choix d'utiliser pour certains de ses transistors critiques des structures plus larges composées de plusieurs fins (dans des proportions non négligeables même si la proportion exacte est rarement évoquée de manière précise par Intel).
Cumulé a de multiples autres détails (différents types de blocs sont présents avec des densités différentes, de la SRAM aux blocs plus ou moins critiques) il est impossible de tirer grand-chose de la théorie. L'écart entre un Core M Broadwell 14nm fabriqué par Intel (82mm2 pour 1.3 milliards de transistors) et un A8 fabriqué par TSMC en 20nm (89 mm2 pour 2 milliards de transistors) montre qu'il est difficile de comparer quoique ce soit à moins de prendre deux puces strictement identiques. Cela aura été possible pour l'A9 d'Apple, dont la superficie atteint 96mm2 chez Samsung contre 104.5mm2 chez TSMC.

Le mois prochain, l'ITRS devrait donc enfin communiquer une nouvelle roadmap qui d'après Nature tirera définitivement un trait sur la question de la loi de Moore comme moteur d'évolution unique. D'après Nature, la prochaine roadmap se concentrera sur les applications pratiques, allant du smartphones aux puces serveurs et regardera les applications pratiques, que ce soit au niveau circuits d'alimentations, des capteurs nécessaires, ou d'autres blocs de siliciums répondant à des besoins particuliers.
La véritable question est de savoir ce que comportera réellement cette roadmap qui serait rebaptisée d'après Nature International Roadmap for Devices and Systems, abandonnant même le mot transistor !
Ce que l'on sait, c'est que la réorganisation de l'ITRS en 2014 s'est faite autour de groupes de travaux, avec notamment un groupe baptisé « More Moore » pour évoquer les pistes techniques pour les prochains nodes, dont vous pouvez retrouver ci-dessous la dernière présentation datant de février 2015.




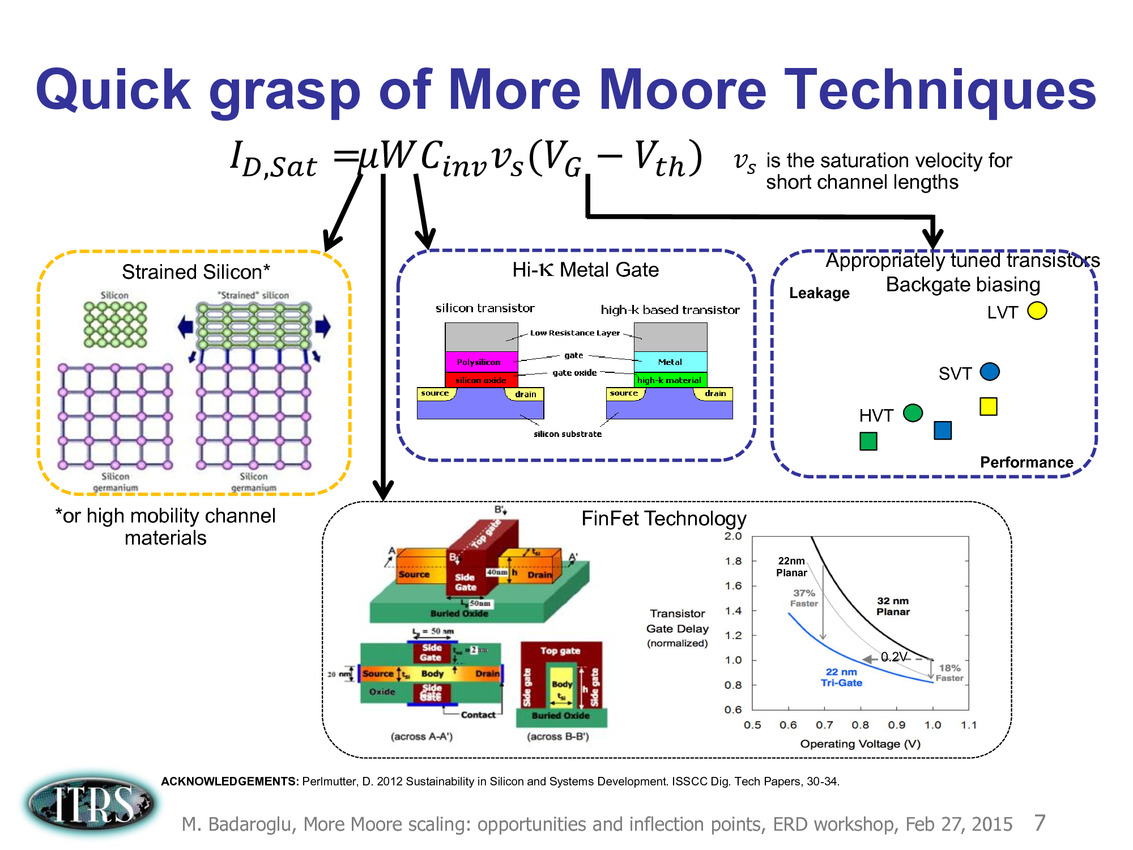
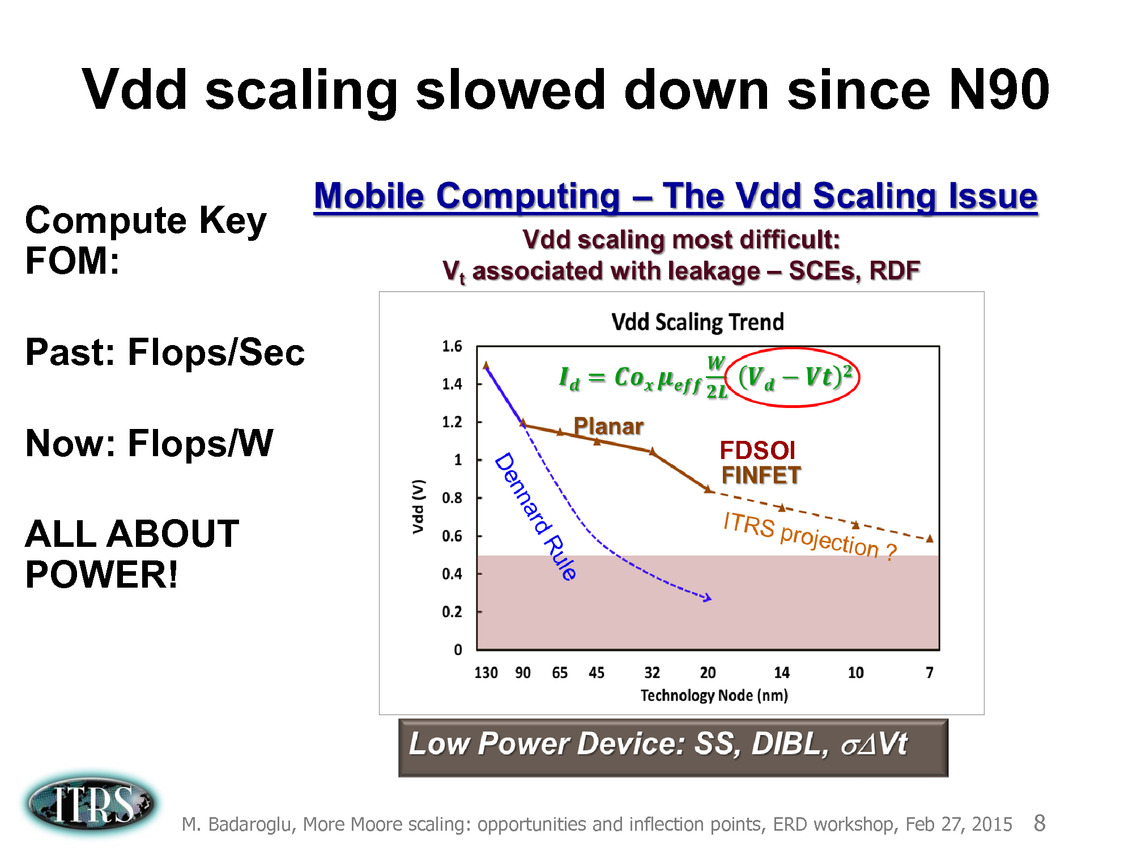
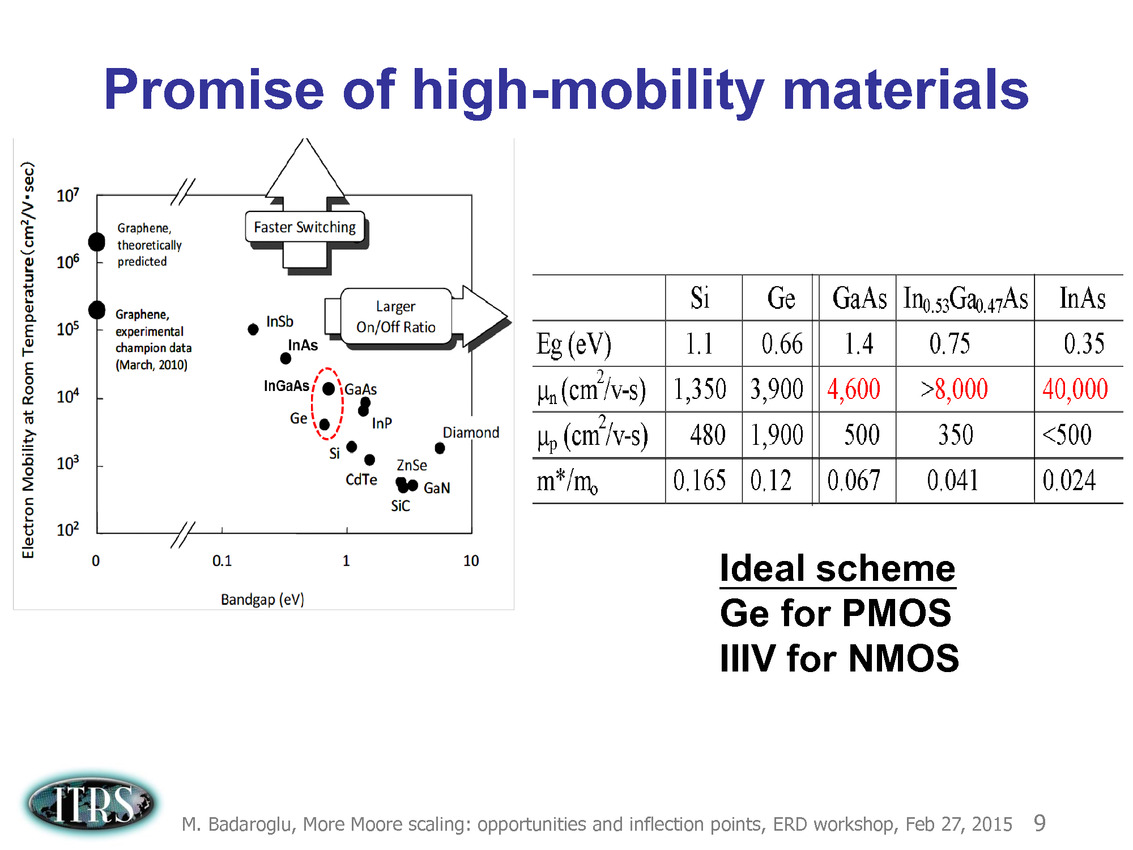
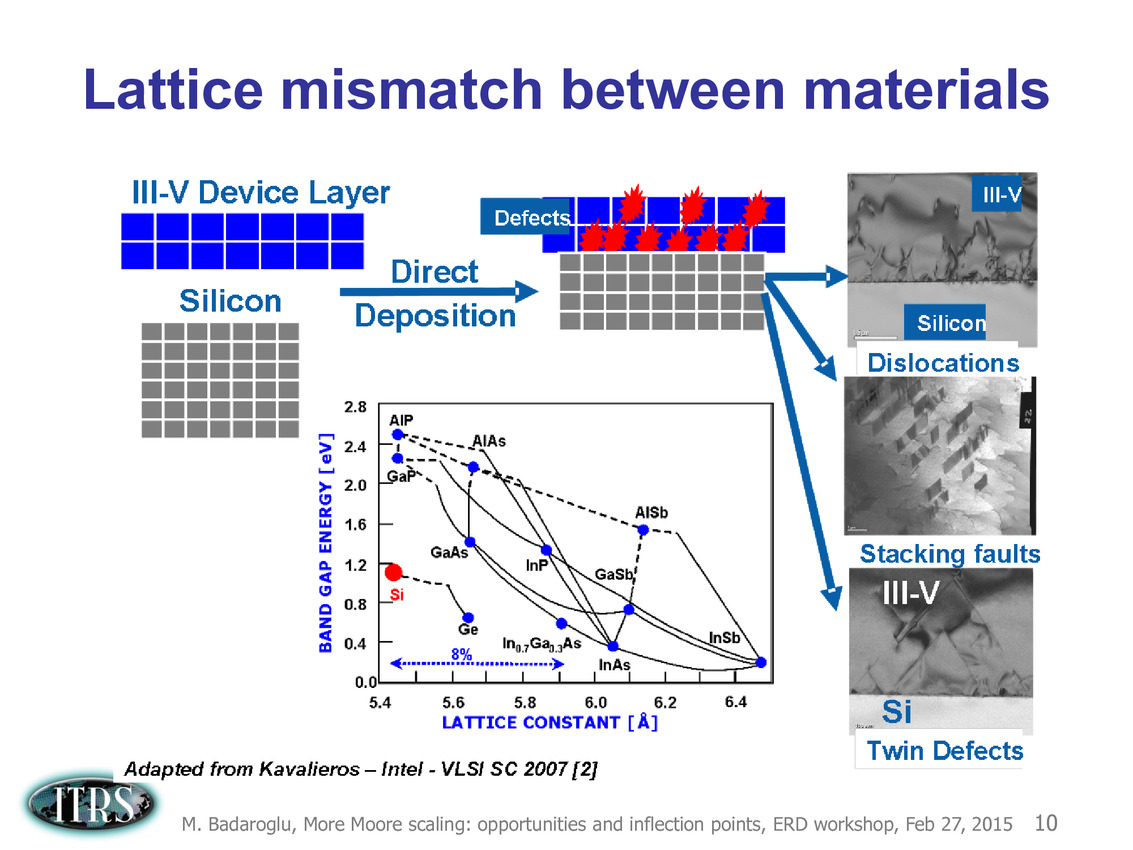
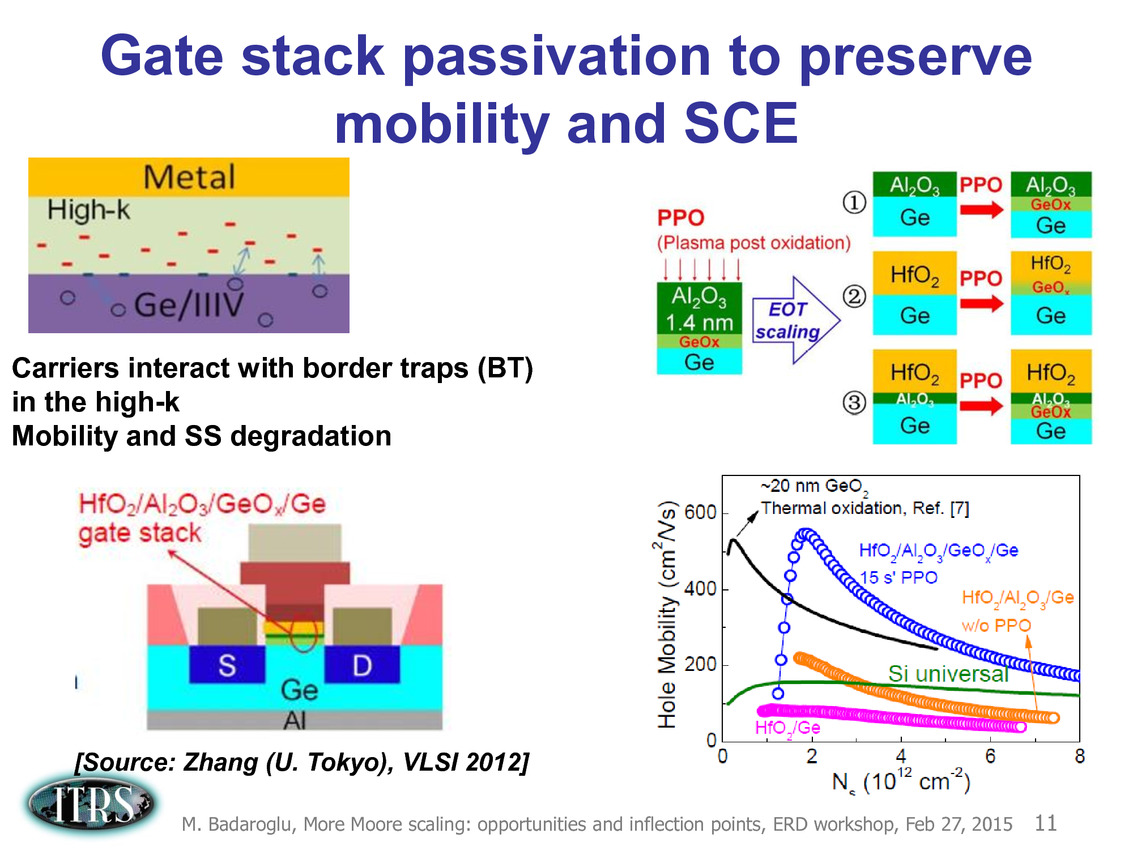
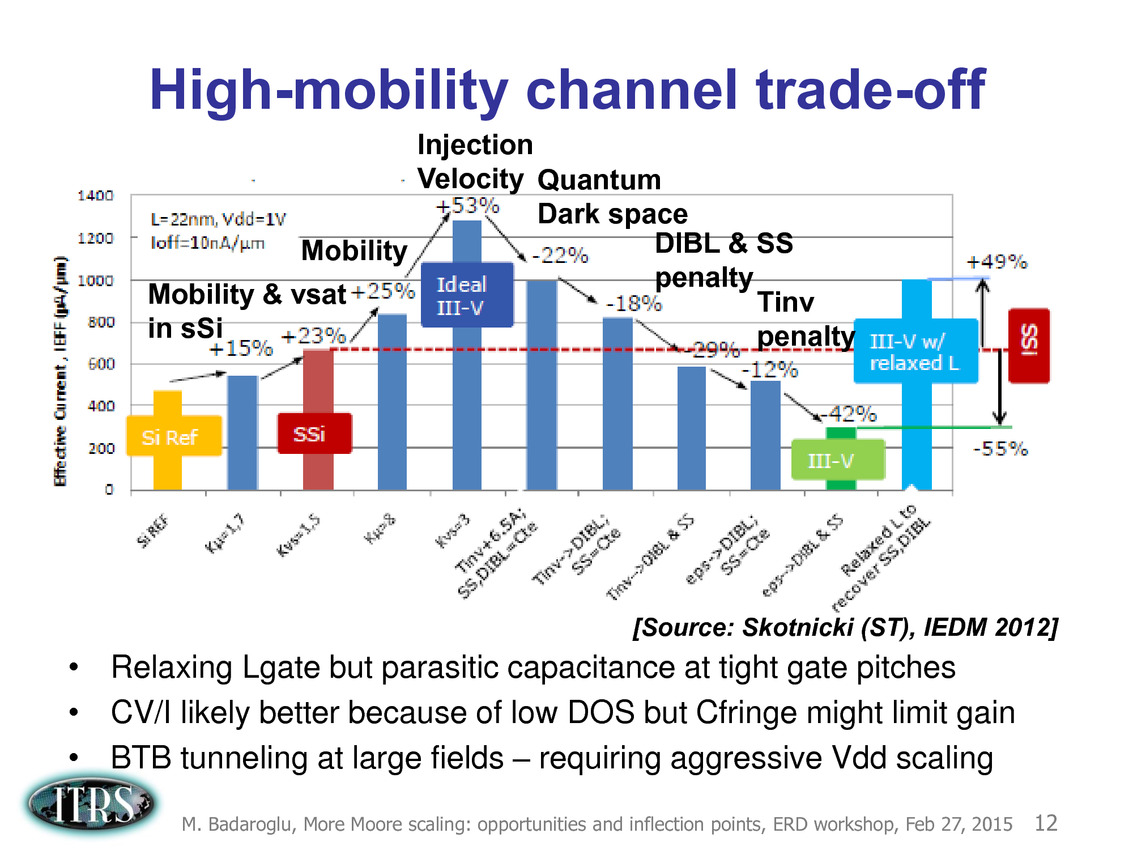
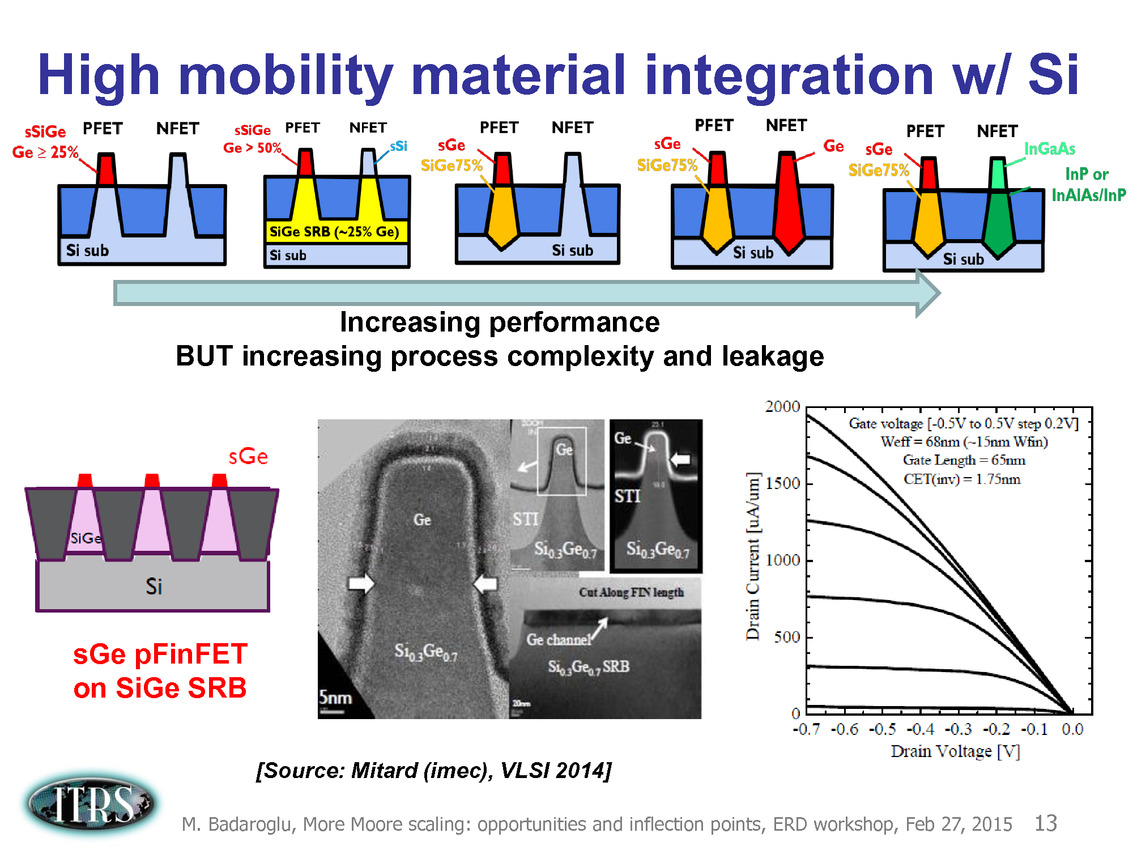

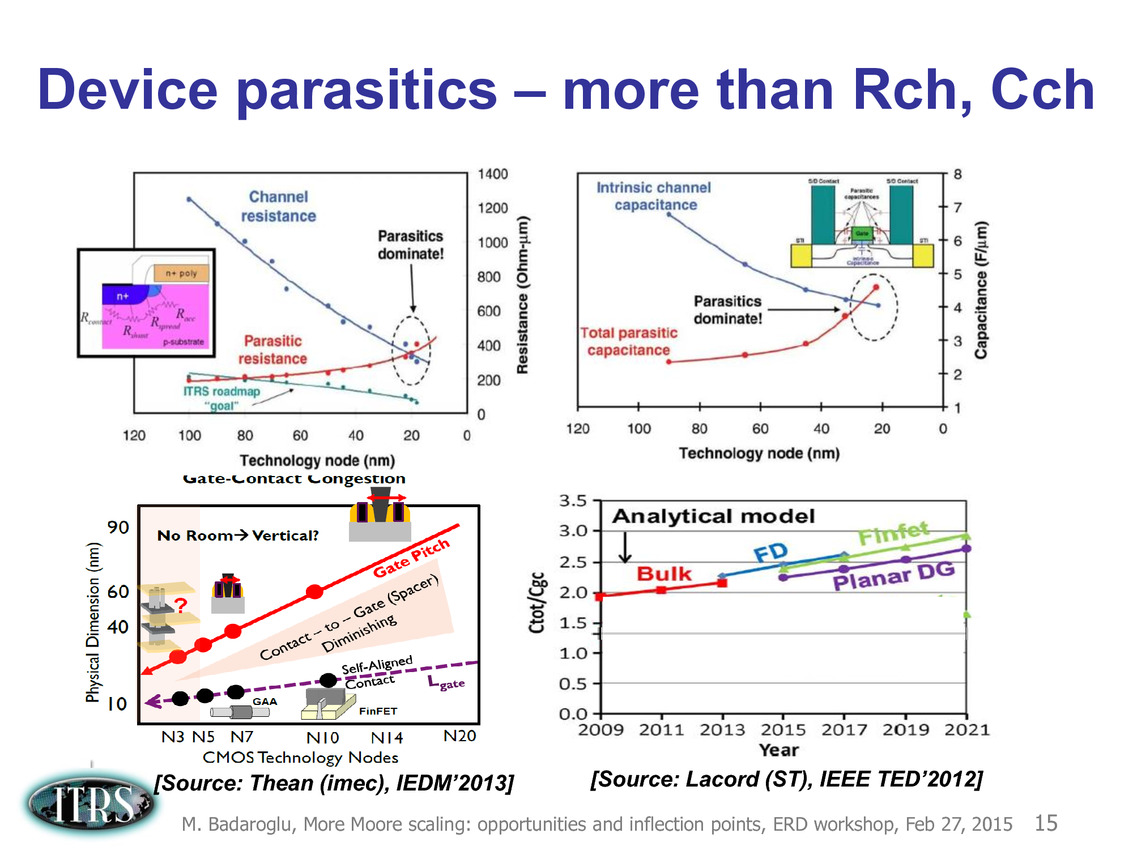
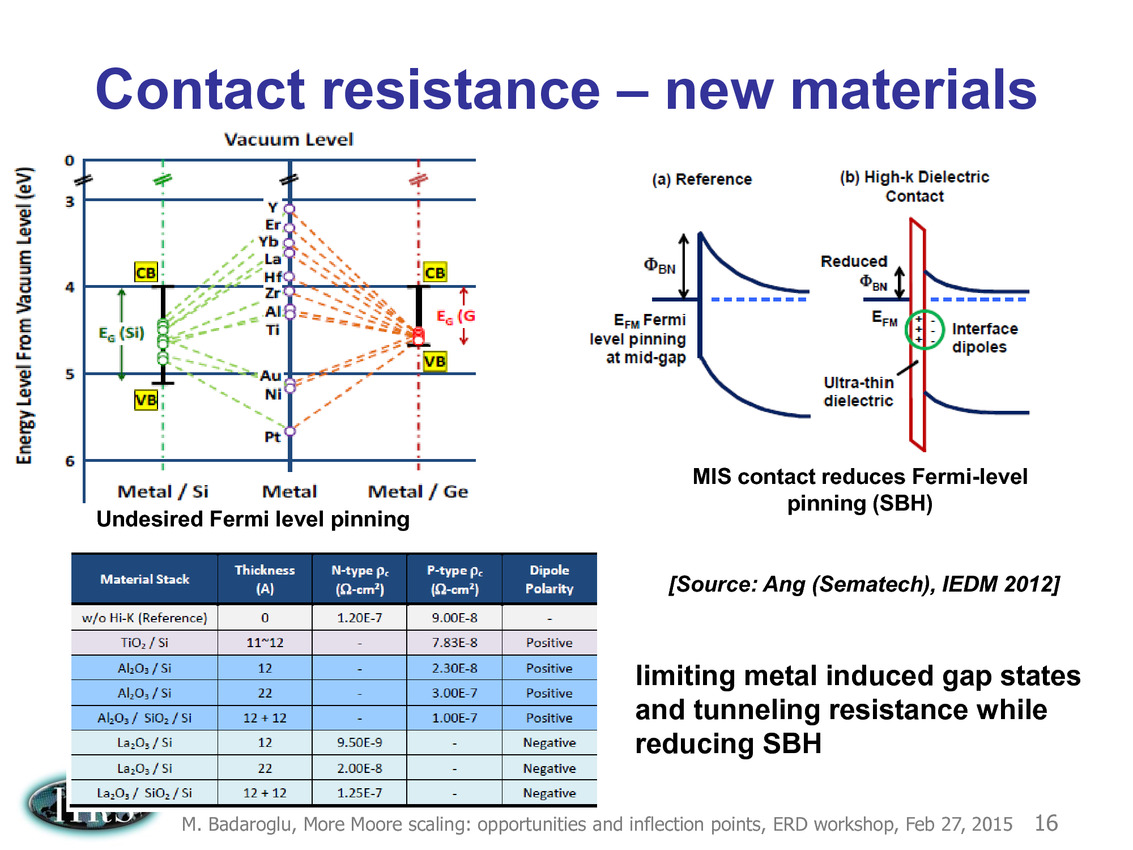
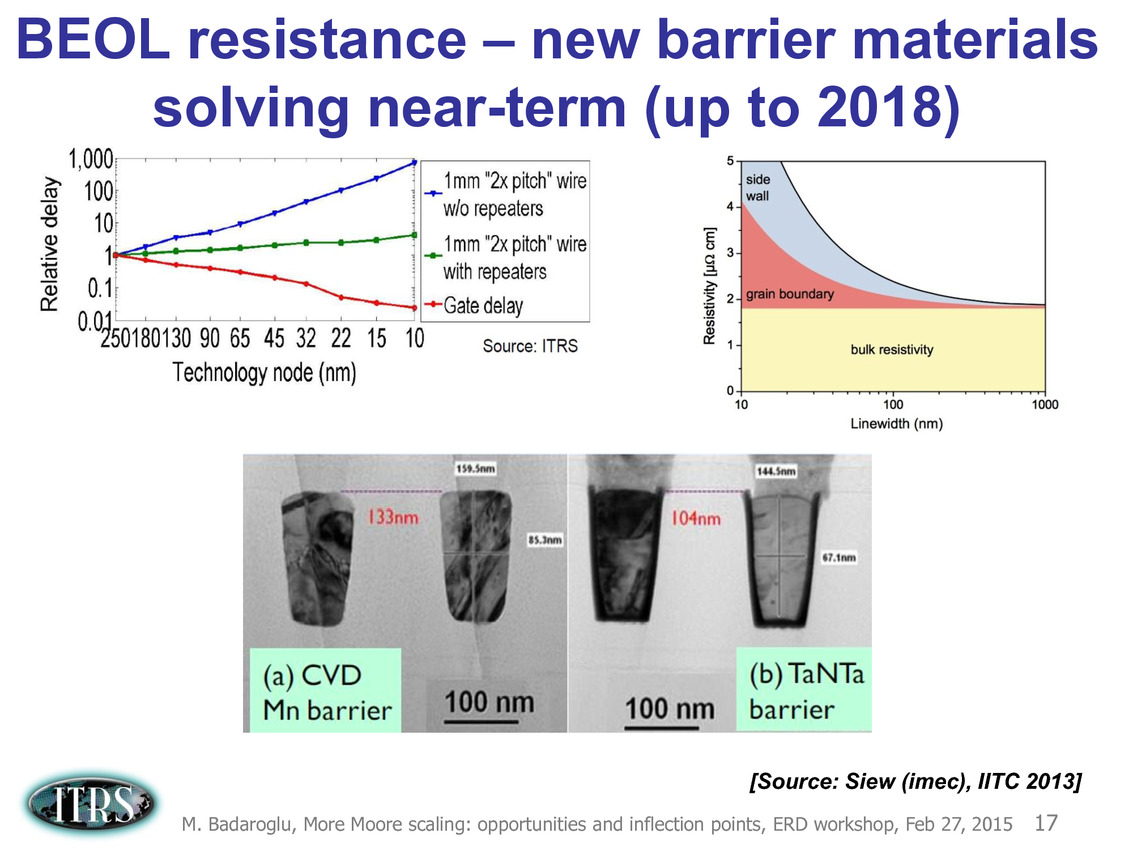
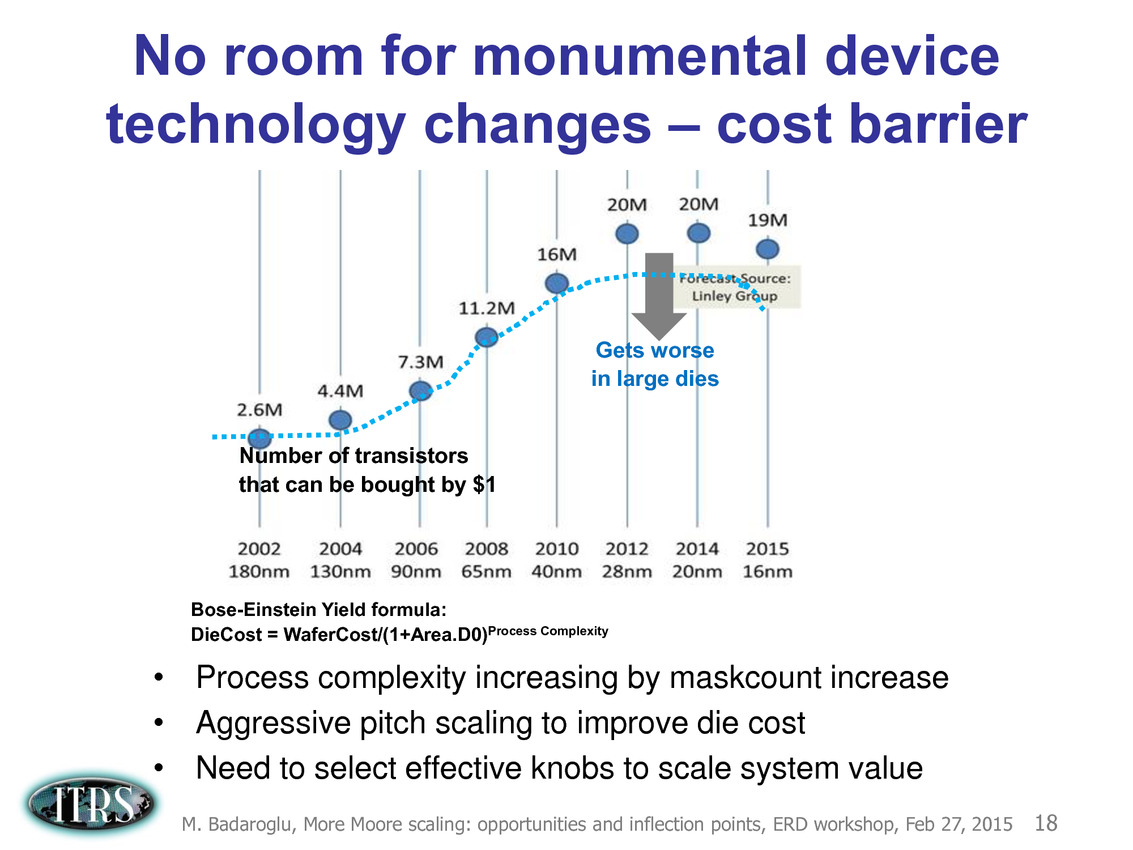
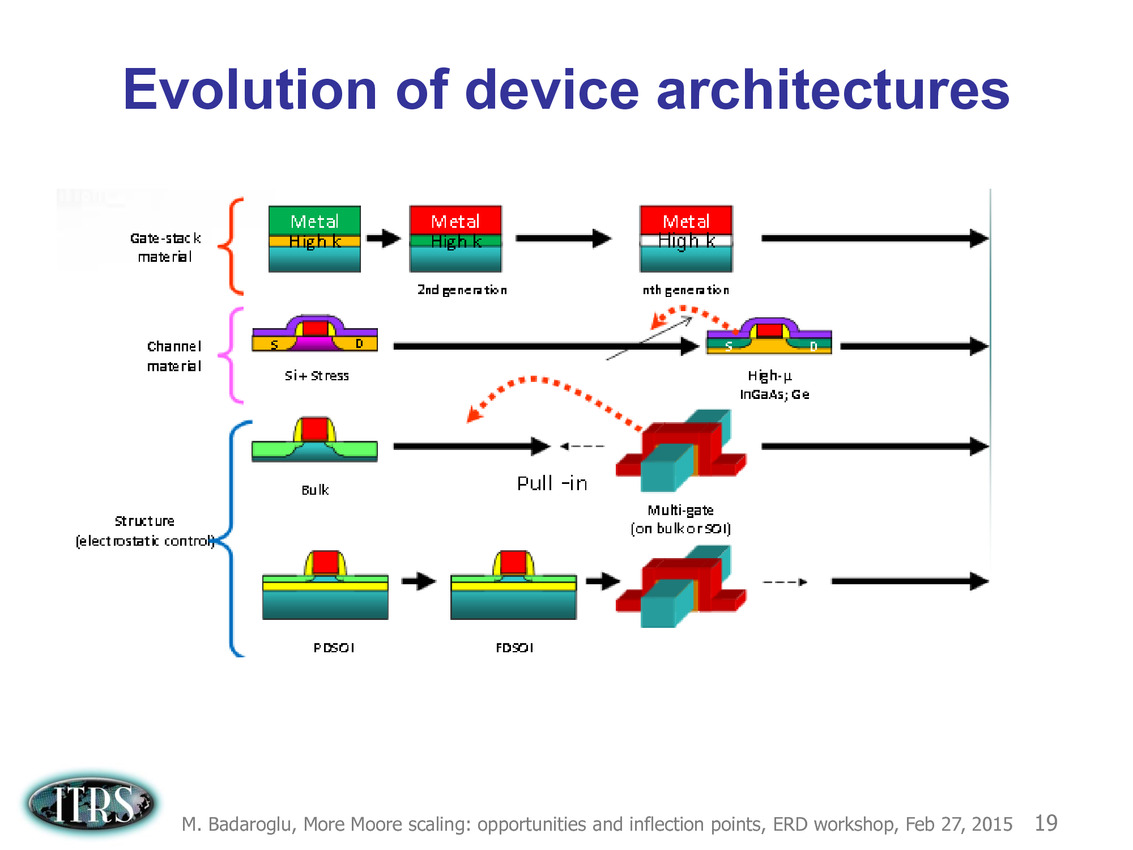
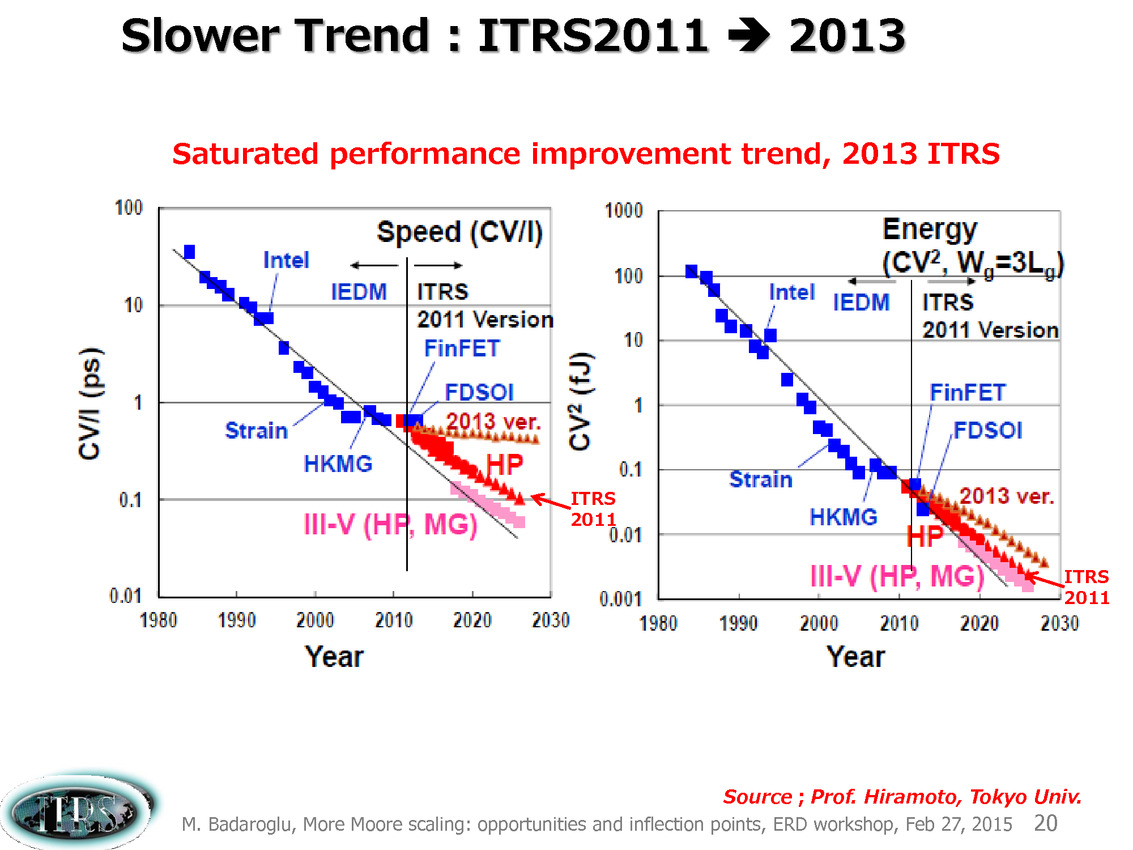
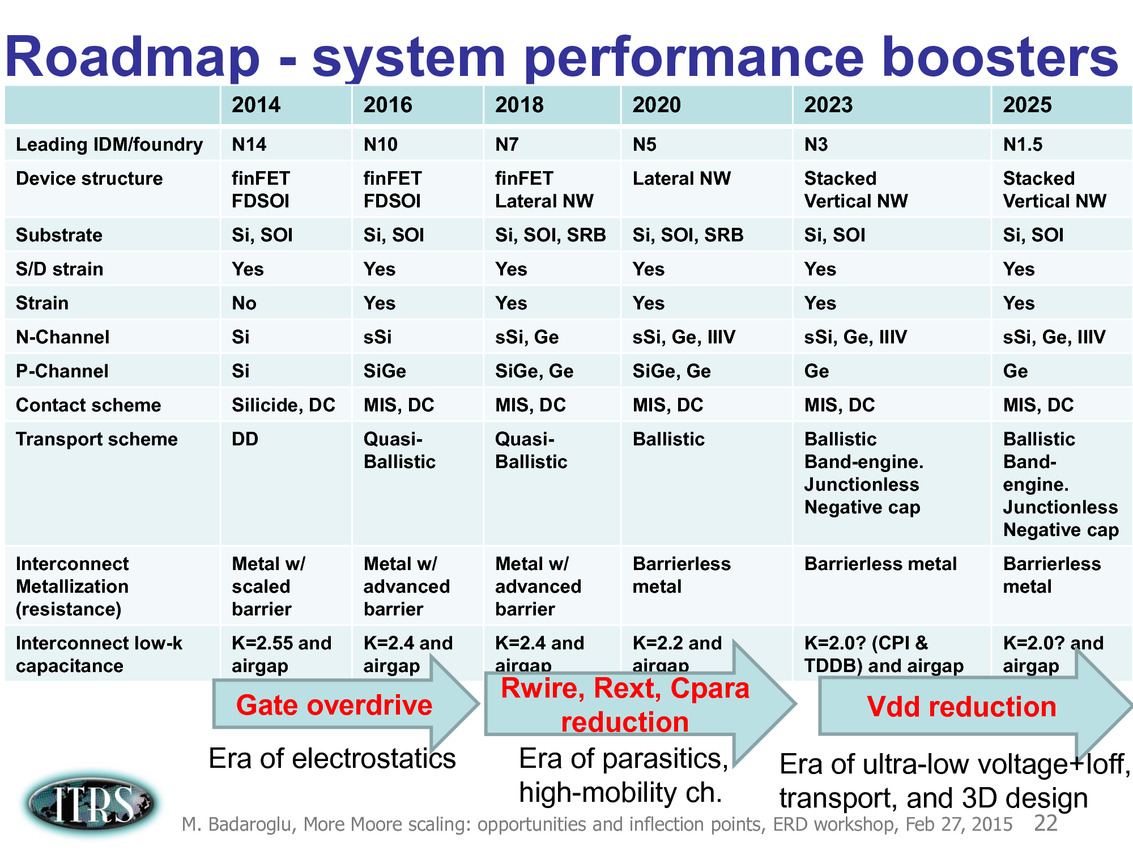
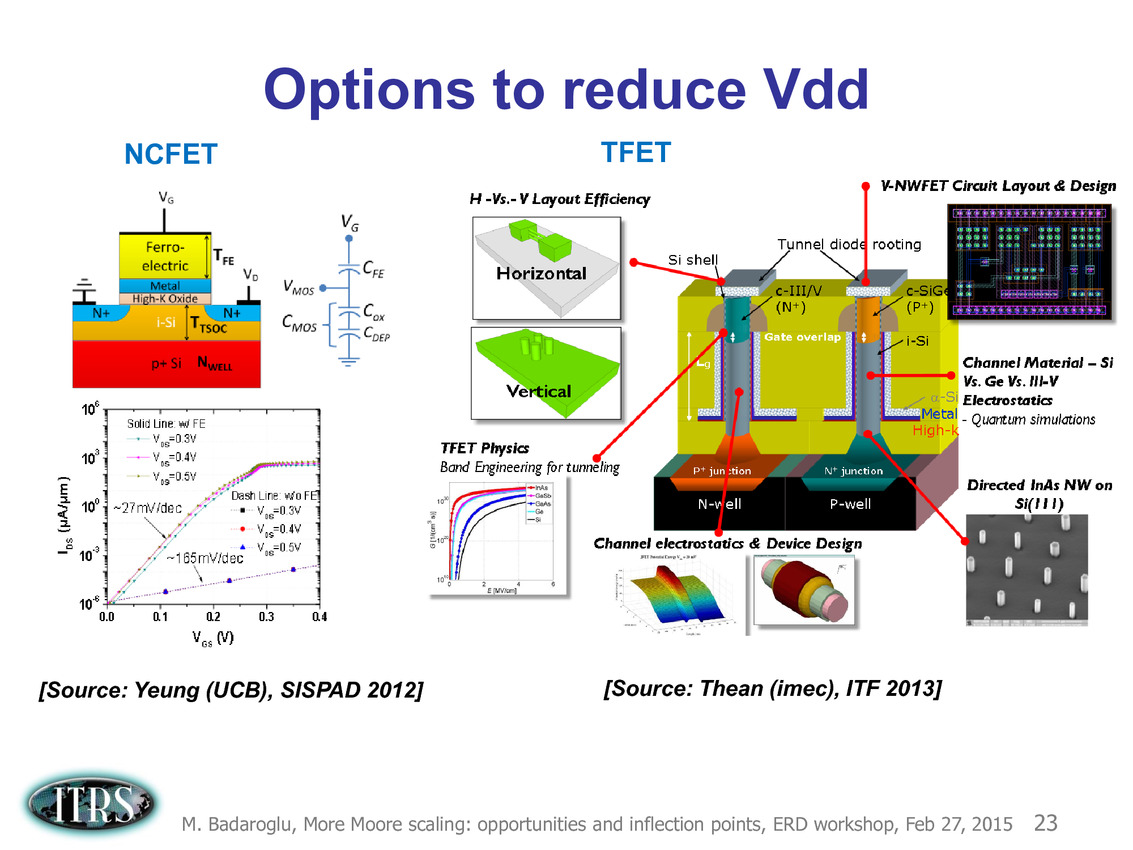
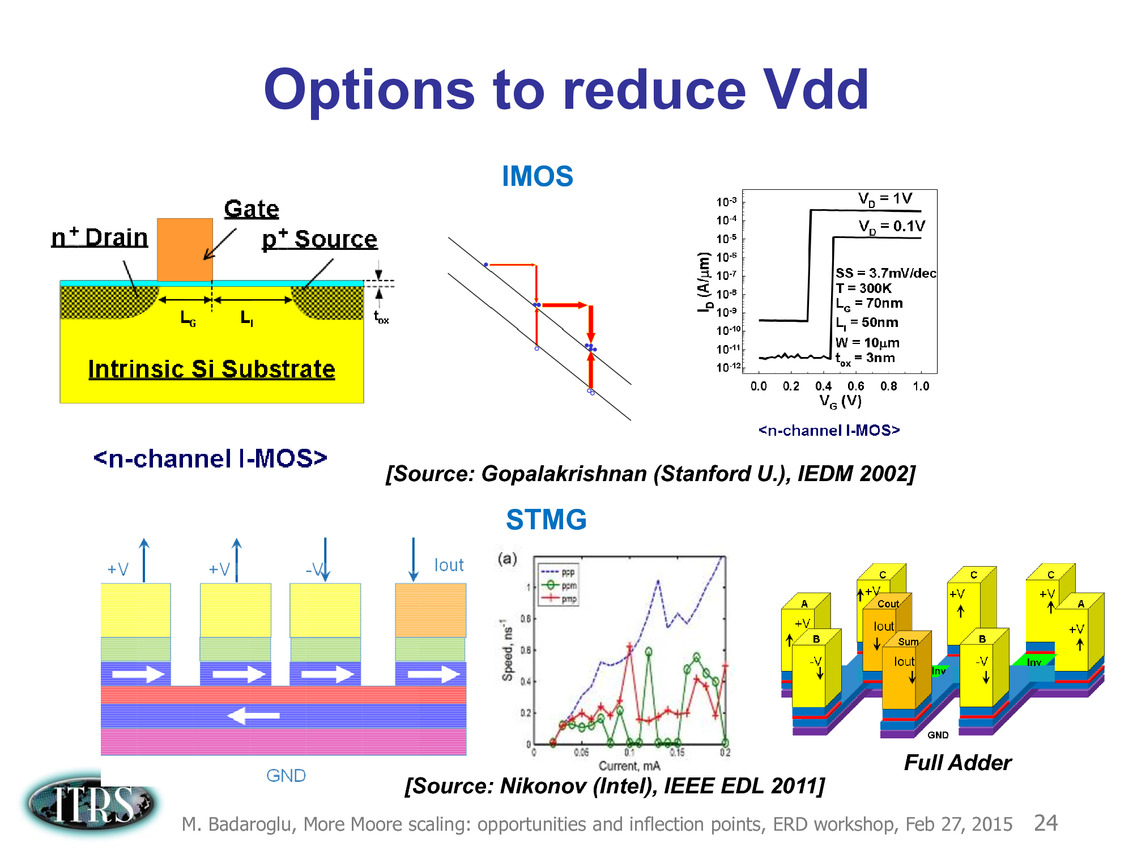
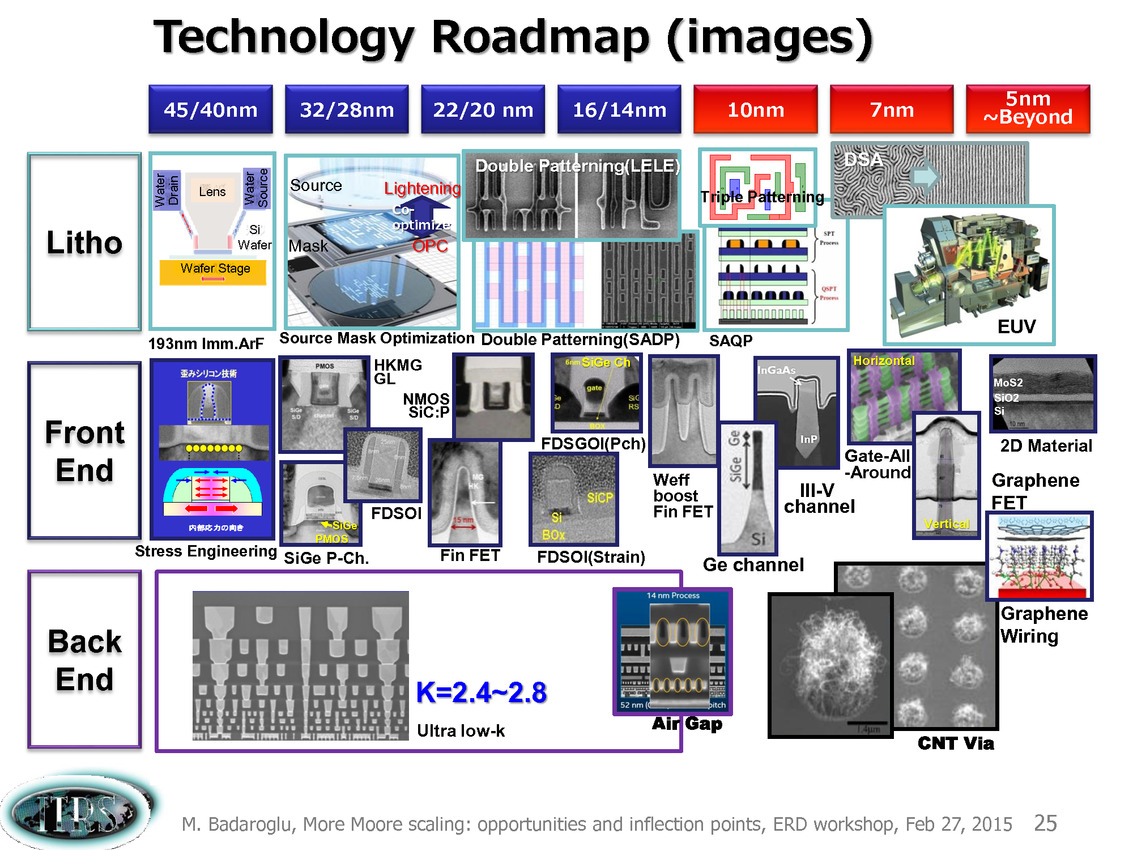

Une présentation intéressante qui évoque de multiples pistes et où l'on trouve un début de roadmap que nous avons remis ci-dessous :
En pratique, après l'ère de la mise à l'échelle géométrique, et l'ère des équivalences, l'ITRS évoque l'ère du "3D Power Scaling" dont les meilleurs représentants sont la NAND 3D ou des technologies comme la mémoire HBM. Des techniques complexes à appliquer aux puces logiques même si la présentation évoque quelques pistes et alternatives.
On attendra donc le mois prochain pour en savoir un peu plus !
3 architectures 10nm pour Intel ?
Alors qu'Intel a indiqué lors de ses résultats trimestriels avoir pour objectif de revenir au rythme habituel de 2 ans entre deux process de fabrication, il ne semble que ce retour à la normale ne soit pas prévu pour le passage à 7nm.
A l'instar de ce qui se passe sur le 14nm qui va voir passer successivement Broadwell, Skylake et Kaby Lake, ce sont ainsi trois architectures qui seraient prévues en 10nm selon Fool.com : Cannonlake pour le second trimestre 2017, Icelake un an plus tard et finalement Tigerlake au second semestre 2019. L'arrivée des produits en 7nm ne se ferait ainsi pas avant 2020, soit par rapport au planning annoncé en 2010 1 an de retard pour le 14nm, 2 ans pour le 10nm et 3 ans pour le 7nm.
Si Intel aime annoncer une densité supérieure de son 14nm par rapport aux process 14/16nm concurrents, ce que contredisent bien entendu ces derniers, l'arrivée de produits 7nm en 2020 mettrait tout le monde d'accord puisque côté TSMC on devrait voir des puces 7nm sortir des chaines de fabrication avant la fin 2018.
Un tel décalage peut paraître étonnant puisque c'est ASML qui équipe principalement toutes les fonderies, il est très probable qu'il découle en fait de choix différent entre d'un côté attendre l'EUV, ce que fera peut-être Intel pour le 7nm, ou faire appel à de plus en plus de multiple patterning et de parties de process communes avec le node précédent afin de repousser l'EUV au 5nm, ce qui est l'option prise par TSMC. L'avenir nous dira quels choix vont être faits et lequel sera le bon !