
Les derniers contenus liés au tag GP100
GTC: N'attendez pas de GeForce en GP100 !
GTC: Nvidia Tesla P100: 10 Tflops, HBM2...
Nvidia lance les Quadro Pascal dont une GP100
GTC: Nvidia annonce CUDA 8, prêt pour Pascal
GTC: Supermicro premier sur le Tesla P100 ?
GTC: Tesla P100: débits PCIe et NVLink mesurés
GTC: Nvidia DGX-1: 8 Tesla P100 pour 129.000$
Nvidia lance les Quadro Pascal dont une GP100



Après deux premiers modèles lancés cet été, Nvidia vient de dévoiler toute une famille de Quadro de génération Pascal qui vont pousser vers le haut puissance de calcul et efficacité énergétique. Un lancement qui permet par ailleurs à Nvidia d'introduire le GPU GP100 et sa mémoire HBM2 sur une carte graphique.

Cet été, Nvidia avait débuté le renouvellement de sa gamme de cartes graphiques professionnelles avec l'introduction de deux nouvelles Quadro, les P6000 et P5000 respectivement basées sur les GPU Pascal GP102 (Titan X) et GP104 (GTX 1080). D'autres modèles étaient bien entendu au programme et viennent d'être dévoilés : les Quadro GP100, P4000, P2000, P1000, P600 et P400. En voici les spécifications :
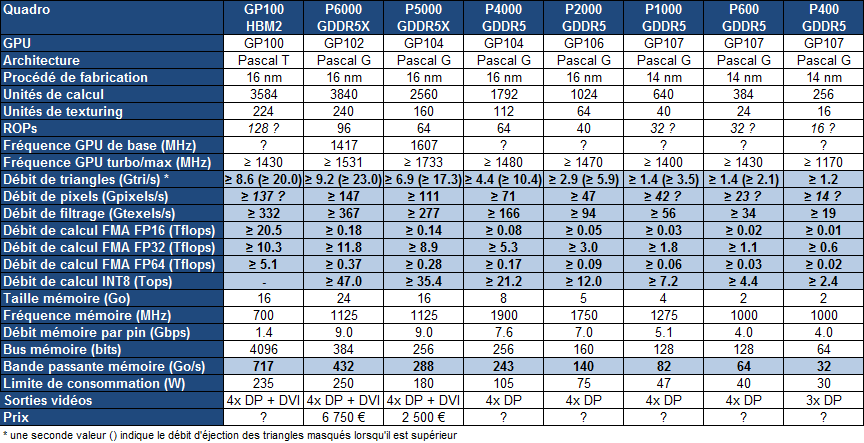
La Quadro GP100 est bien entendu la nouvelle venue la plus intéressante, mais avant d'en parler en plus de détails, intéressons-nous aux autres modèles de la famille que Nvidia positionne de la sorte :


La Quadro P6000, dont nous avions omis de parler à sa sortie, est basée sur un GPU GP102 complet et équipée de 24 Go de GDDR5X, contrairement à la Titan X qui embarquait le même GPU mais castré et avec "seulement" 12 Go de mémoire. La Quadro P6000 représente l'offre de Nvidia la plus élevée en terme de puissance de calcul en simple précision et de quantité de mémoire embarquée. Elle affiche une puissance brute 70% plus élevée que celle de la M6000 24 Go qu'elle remplace. Elle vise donc les applications de rendu les plus lourdes ou encore le GPGPU.
En-dessous, la Quadro P5000 vise des applications similaires mais est un peu moins véloce. Il s'agit d'une version professionnelle de la GeForce GTX 1080 mais équipée de 16 Go de mémoire GDDR5X. La puissance brute a cette fois été doublée par rapport à la M5000.
Les nouvelles Quadro P4000, P2000, P1000, P600 et P400 remplacent les M4000, M2000, K1200, K620 et K420, ces dernières n'ayant pas profité du passage à l'architecture Maxwell. Excepté pour la P2000 qui passe à 5 Go au lieu de 4 Go, la quantité de mémoire n'évolue pas, Nvidia faisant en sorte de forcer une forte segmentation sur ce point.
La P4000 repose sur un GPU GP104 fortement castré qui permet à Nvidia de limiter sa consommation à 105W et de proposer un format simple slot. Sa puissance de calcul est doublée par rapport la M4000.
La P2000 embarque de son côté un GPU GP106, comme sur la GeForce GTX 1060, mais castré tant au niveau des unités actives que du bus mémoire, raison pour laquelle elle embarque un ensemble inhabituel de 5 Go de mémoire. Sa puissance de calcul profite d'un boost de 65% par rapport à la M2000.
Dans l'entrée de gamme, les P1000, P600 et P400 sont toutes trois basées sur le GPU GP107 (GTX 1050) plus ou moins castré. Leur puissance de calcul est donc plutôt limitée même si elle est doublée par rapport à la génération précédente. Ce type de Quadro est plutôt utile pour profiter des pilotes professionnels dans certaines applications que pour leur puissance de calcul.

De quoi en arriver à la Quadro GP100 qui nous intéresse particulièrement. Sa nomenclature l'indique sans ambiguïté, il s'agit d'une carte à part, qui vise autant les applications traditionnelles des Quadro et que le GPU Computing qui a besoin de plus que la simple précision. Pour rappel, le GPU GP100 qui lui donne son nom est le premier à embarquer la mémoire HBM2, pour une bande passante plus élevée, ainsi qu'une interconnexion de nouvelle génération : NVLink.
Jusqu'ici, le GP100 n'était exploité qu'en format serveur, soit de type PCI Express passif, soit de type module mezzanine. Nous pouvions donc nous demander si Nvidia avait réellement équipé ce GPU de tout l'attirail nécessaire pour en faire une carte graphique, notamment le moteur d'affichage et les sorties vidéo, puisqu'il est avant tout destiné au calcul massivement parallèle. Une interrogation qui trouve donc une réponse avec son arrivée dans une Quadro au format carte graphique classique.
Au niveau de la puissance brute en simple précision (FP32), cette Quadro GP100 n'est pas impressionnante. Sur ce point, le GP100 n'est pas mieux armé que le GP102 et Nvidia a décidé de castrer le GP100 de la Quadro GP100 alors que le GP102 de la Quadro P6000 est complet. Cette dernière est ainsi 15% plus véloce à peu près à tous les niveaux liés au rendu 3D. Le GP100 est probablement équipé de 128 ROP contre 96 pour le GP102, mais ses 6 moteurs de rastérisation ne peuvent en débiter plus de 96. Par ailleurs, il faut se contenter de seulement 16 Go de mémoire contre 24 Go pour la P6000.

Pour de nombreuses applications le choix entre ces deux Quadro sera pour le moins délicat. Là où le GP100 se démarque c'est avec un support très performant de la double précision (FP64) et de la demi-précision (FP16), et bien entendu au niveau de la bande passante mémoire largement supérieure avec 717 Go/s. Autre avantage, mais dont il est difficile d'estimer l'intérêt en pratique, la Quadro GP100 voit ses connecteurs SLI remplacés par 2 liens NVLink. Ceux-ci vont permettre de coupler 2 Quadro GP100 en donnant à chaque GPU un accès plus performant à la mémoire de l'autre.
En équipant sa nouvelle Quadro de cette connectique, Nvidia en fait notamment une solution de développement très utile pour la plateforme Tesla puisqu'il est possible de l'utiliser pour faire du développement sur station de travail en vue d'en déploiement sur serveur par la suite.
La Quadro GP100 se retrouvera dans quelques mois en face de la Radeon Instinct MI25 qui devrait profiter d'une puissance de calcul légèrement supérieure mais d'une bande passante inférieure. Comme pour le reste des nouvelles Quadro, la disponibilité de la Quadro GP100 est prévue pour mars, à un tarif qui n'a pas encore été communiqué.
Terminons par un petit mot sur ce que cela implique du côté des cartes graphiques destinées au moins en partie aux joueurs. La Quadro GP100 laisse penser que le GP100 pourrait également se retrouver dans une nouvelle Titan. De quoi pouvoir envisager le remplacement de la Titan X 12 Go actuelle par une version GP100 16 Go en même temps que le lancement d'une éventuelle GeForce GTX 1080 Ti en GP102 ?
GTC: Nvidia annonce CUDA 8, prêt pour Pascal
Comme souvent, l'arrivée d'une nouvelle architecture est associée à une révision majeure de CUDA, l'environnement logiciel de Nvidia destiné au calcul massivement parallèle. Ce sera évidemment le cas pour les GPU Pascal qui pourront profiter dès cet été d'un CUDA 8 taillé sur mesure. Au menu : un support plus évolué de la mémoire unifiée, un profilage plus efficace et un compilateur plus rapide.

La principale nouveauté de CUDA 8 sera le support complet de l'architecture Pascal et particulièrement du GP100 qui équipe l'accélérateur Tesla P100. Déjà introduit avec CUDA 7.5 pour permettre aux développeurs de s'y préparer, le support de la demi-précision (FP16) sera finalisé et pourra permettre des gains conséquents pour les algorithmes qui peuvent s'en contenter. Dans le cas du GP100, CUDA 8 ajoutera évidemment le pilotage des accès mémoire à travers les liens NVLink.
La plus grosse évolution est cependant à chercher du côté de la mémoire unifiée qui va faire un bond en avant avec Pascal, ou tout du moins avec le GP100 puisque nous ne sommes pas certains que les autres GPU Pascal en proposeront un même niveau de support. Si vous avez l'impression qu'on vous a annoncé le support de cette mémoire unifiée avec chaque nouveau GPU, ne vous inquiétez pas, vous n'avez pas rêvé, nous avons la même impression.
Elle est en fait supportée depuis CUDA 6 pour les GPU Kepler et Maxwell mais de façon limitée, que nous pourrions qualifier d'émulée. Pour ces GPU, l'espace de mémoire unifié est en fait dédoublé dans la mémoire centrale et dans la mémoire physiquement associée au GPU. L'ensemble logiciel CUDA se charge de piloter et de synchroniser ces deux espaces mémoires pour qu'ils n'en représentent qu'un seul du point de vue du développeur. De quoi faciliter sa tâche mais au prix de sérieuses limitations : la zone de mémoire unifiée ne peut dépasser la quantité de mémoire rattachée au GPU, le CPU et le GPU ne peuvent y accéder simultanément et de nombreuses synchronisations systématiques sont nécessaires pour forcer la cohérence entre les copies CPU et GPU de cette mémoire.
Pour proposer un support plus avancé de la mémoire unifiée, des modifications matérielles étaient nécessaires au niveau du GPU, ce qui explique pourquoi nous estimons possible que cela soit spécifique au GP100. Tout d'abord l'extension de l'espace mémoire adressable à 49-bit pour permettre de couvrir l'espace de 48-bit des CPU ainsi que la mémoire propre à chaque GPU du système. Ensuite la prise en charge des erreurs de page qui permet d'éviter les coûteuses synchronisations systématiques. Si un kernel essaye d'accéder à une page qui ne réside pas dans la mémoire physique du GPU, il va produire une erreur qui va permettre suivant les cas soit de rapatrier localement la page en question, soit d'y accéder directement à travers le bus PCI Express ou un lien NVLink.
La cohérence peut ainsi être garantie automatiquement, ce qui permet aux CPU et aux GPU d'accéder simultanément à la zone de mémoire unifiée. Sur certaines plateformes, la mémoire allouée par l'allocateur de l'OS sera par défaut de la mémoire unifiée, et il ne sera plus nécessaire d'allouer une zone mémoire spécifique. Nvidia indique travailler à l'intégration de ce support avec Red Hat et la communauté Linux. Par ailleurs, CUDA 8 étend également le support de la mémoire unifiée à Mac OS X.

Ce support plus avancé de la mémoire unifiée va faciliter le travail des développeurs et surtout rendre plus abordable leurs premiers pas sur les GPU tout en maintenant un relativement bon niveau de performances. Tout du moins si le pilote et le runtime CUDA font leur travail correctement puisque c'est à ce niveau que tout va se jouer. A noter que les développeurs plus expérimentés conservent la possibilité de gérer explicitement la mémoire.
Parmi les autres nouveautés, Nvidia introduit une première version de la librairie nvGRAPH (limitée au mono GPU) qui fournit des routines destinées à accélérer certains algorithmes spécifiques au traitement des graphes. Traiter rapidement les opérations sur ces structures mathématique prend de plus en plus d'importance, que ce soit pour les moteurs de recherche, la publicité ciblée, l'analyse des réseaux ou encore la génomique. Faciliter l'exécution de ces opérations sur le GPU est donc important pour leur ouvrir la porte à de nouveaux marchés potentiels.
Une autre évolution importante est à chercher du côté des outils de profilages qui vont dorénavant fournir une analyse des dépendances. De quoi par exemple permettre de mieux détecter que les performances sont limitées par un kernel qui bloque le CPU trop longtemps. Ces outils revus prennent également en compte NVLink et la bande passante utilisée à ce niveau.
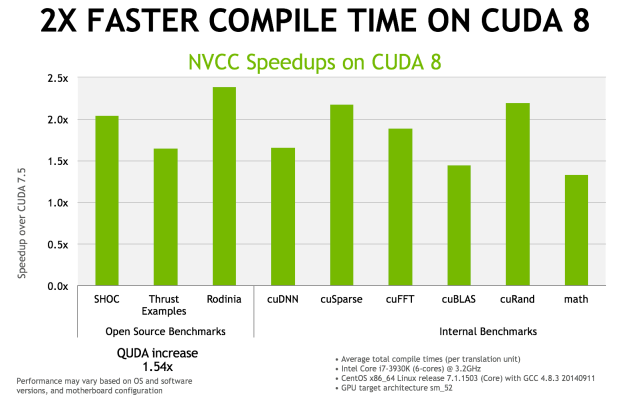
Enfin, le compilateur NVCC 8.0 a reçu de nombreuses optimisations pour réduire le temps de compilation. Nvidia annonce qu'il serait réduit de moitié, voire plus, dans de nombreux cas. Ce compilateur étend également le support expérimental des expressions lambda de C++11.
La sortie de CUDA 8.0 est prévue pour le mois d'août mais une release candidate devrait être proposée dès le mois de juin.
GTC: Supermicro premier sur le Tesla P100 ?
Supermicro exposait à la GTC un prototype non fonctionnel de serveur 1U à base de Tesla P100. Celui-ci est prévu pour embarquer 4 de ces accélérateurs ainsi qu'une configuration bi-Xeon et une carte graphique ou un autre accélérateur au format PCI Express 16x. Le fabricant taiwanais explique que le nouveau format de type mezzanine et les liens NVLink ont demandé pas mal de travail lors de la conception du serveur.

C'est notamment le cas au niveau du refroidissement qui est un challenge évident compte tenu de la consommation qui monte à 300W par Tesla P100 alors que la densité progresse compte tenu de la compacité de cette solution. Supermicro a ainsi décidé de placer ces 4 accélérateurs, surmontés d'imposants radiateurs, côte à côte juste après l'entrée d'air frais, ce qui permet de les refroidir tous de la même manière.

Supermicro précise que certains concurrents ont opté pour une autre organisation, avec par exemple un "carré" de Tesla P100, et que d'après ses essais, il y a beaucoup de risques que les GPU les plus éloignés de l'entrée d'air en souffrent, par exemple en atteignant plus rapidement leur limite de température.
Malgré l'état de la solution exposée, Supermicro nous a confirmé être très proche de la finalisation de ce serveur et s'attendre à être le premier sur le marché, tout du moins si Nvidia ne tarde pas à livrer les Tesla P100.
GTC: Tesla P100: débits PCIe et NVLink mesurés
Lors d'une session de la GTC consacrée à GPUDirect, qui regroupe les techniques de communications entre GPU et avec d'autres éléments d'un système, nous avons pu en apprendre un peu plus sur les performances du GP100 au niveau de ses voies de communication.
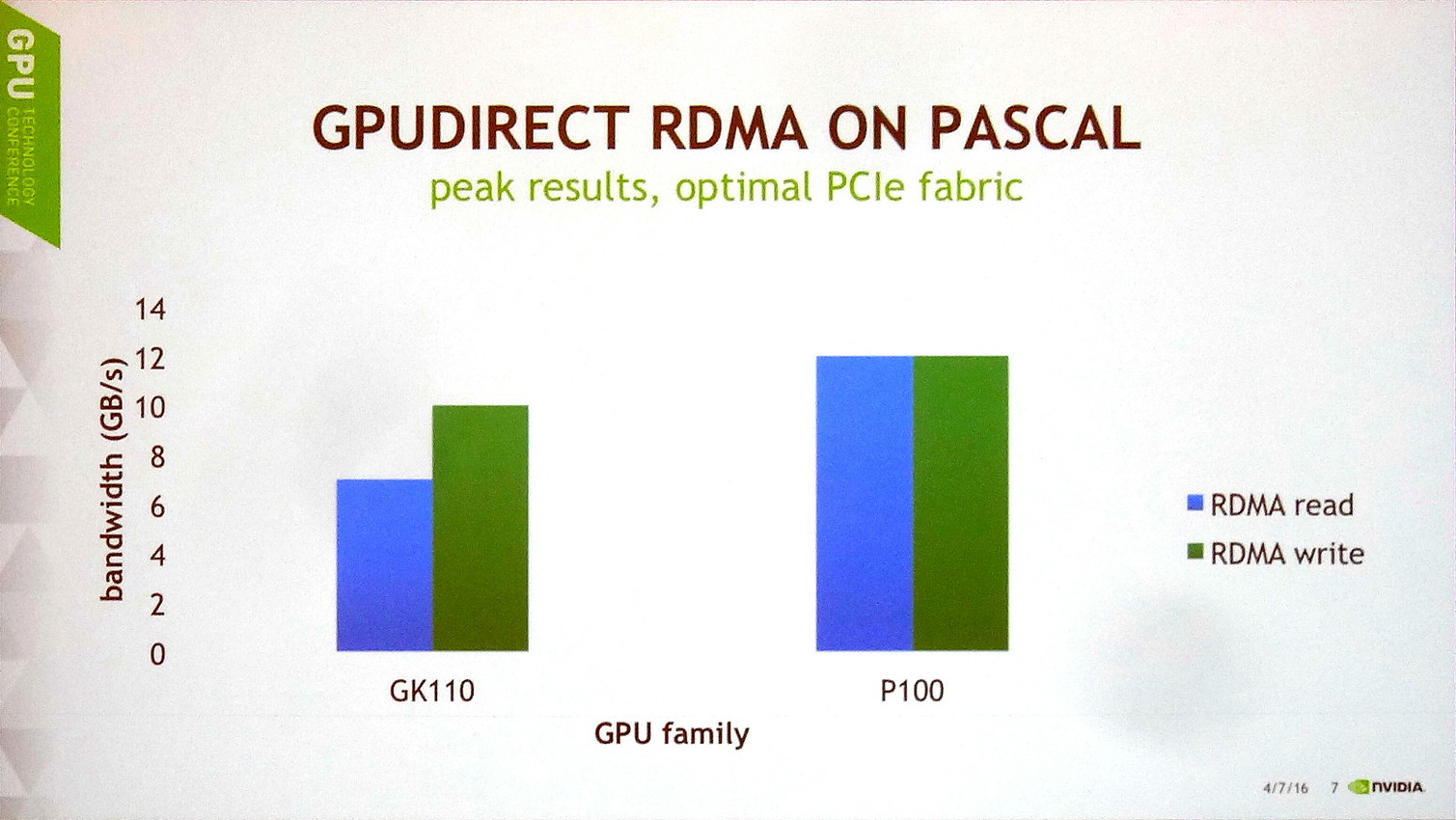
Il y a tout d'abord des progrès au niveau du PCI Express. Nvidia explique que les GPU Kepler et Maxwell souffraient de quelques limitations et devaient se contenter d'à peu près 10 Go/s en écriture et de 7 Go/s en lecture. Cela change avec Pascal dont le tissu PCI Express est dorénavant optimal pour une interface 16x 3.0, ce qui lui permet d'atteindre 12 Go/s dans les deux sens, soit à peu près le maximum théorique.
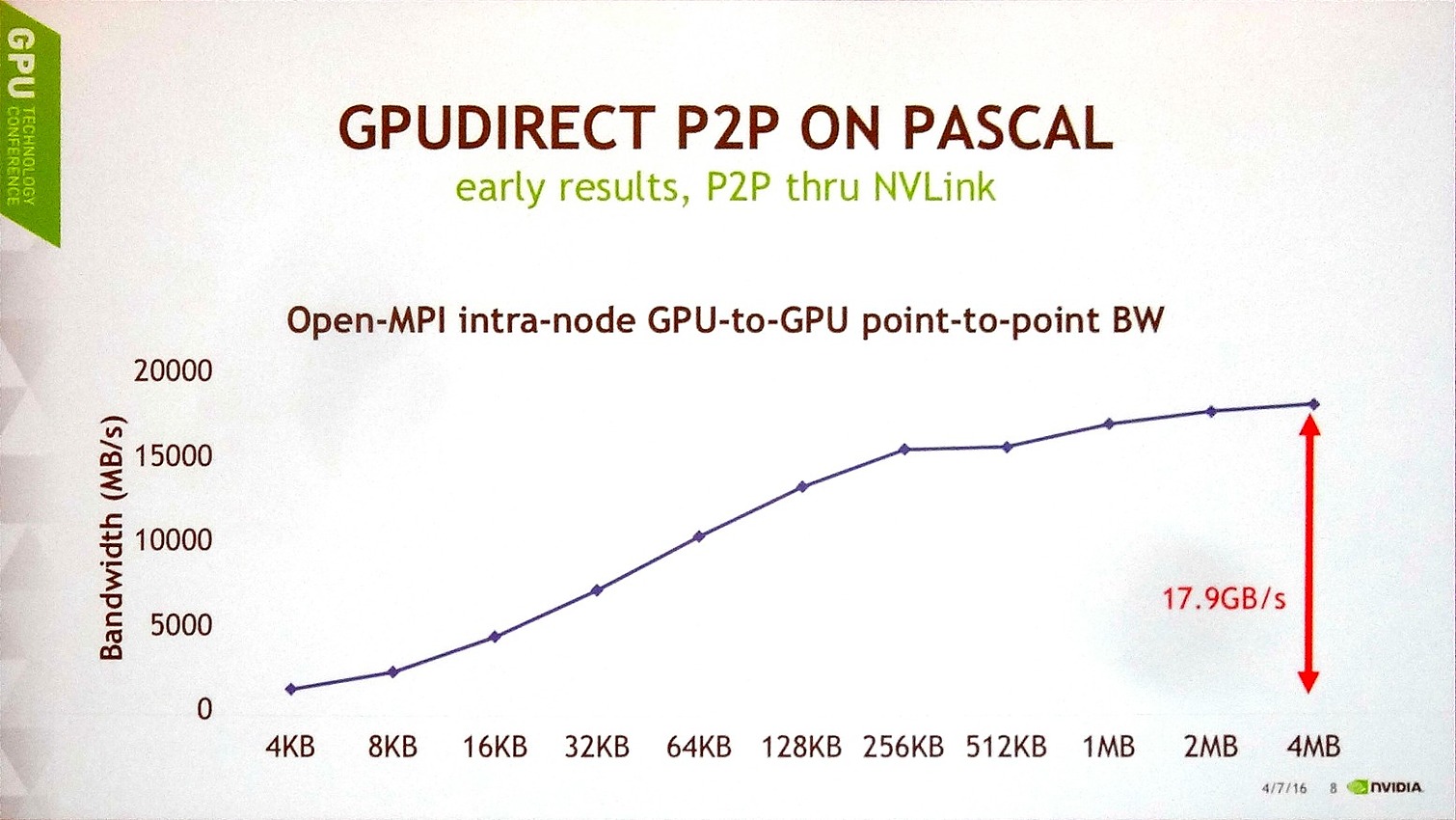
Ensuite, Nvidia a publié les premiers chiffres de débits obtenus pour les liens NVLink en communication point-à-point entre 2 GP100, tout en précisant que toutes les optimisations n'avaient pas encore été mises en place. Pour ce test, un seul lien NVLink est ici exploité et le transfert est unidirectionnel.
Avec des blocs de 4 Mo, le GP100 parvient à monter à 17.9 Go/s, ce qui est plutôt pas mal compte tenu du fait que l'interface est spécifiée à 20 Go/s dans chaque direction. Le débit reste supérieur à 15 Go/s avec des blocs de 256 Ko, mais plonge rapidement sous cette valeur, ce qui est un résultat attendu pour toute voie de communication compte tenu du surcoût par transfert. Ces premiers résultats sont donc plutôt encourageants et Nvidia explique qu'ils sont obtenus grâce à l'intégration de moteurs de copies pour chaque lien NVLink.
GTC: Nvidia DGX-1: 8 Tesla P100 pour 129.000$
Lors de la keynote d'ouverture de la GTC, Jen-Hsun Huang ne s'est pas contenté d'annoncer l'accélérateur Tesla P100, mais a également dévoilé un nouveau serveur qui sera commercialisé sous sa propre marque : le DGX-1. Orienté deep learning, ce supercalculateur embarque pas moins de 8 Tesla P100 pour un tarif de 129.000$ HTVA.

On n'est jamais aussi bien servi que par soi-même. C'est probablement ce qu'a dû se dire Nvidia pour accélérer la disponibilité du Tesla P100 sur un marché qui peut prendre du temps à bouger de lui-même, d'autant plus quand la compétition est rude et quand la plateforme change significativement. Après quelques expériences avec les serveurs GRID VCA (Visual Computing Appliance) et Quadro VCA, Nvidia propose ainsi un supercalculateur orienté vers le deep learning, un domaine en pleine explosion et pour lequel l'architecture Pascal a été optimisée.
Le DGX-1 est un serveur 3U capable d'atteindre 170 Tflops FP16, mode de calcul basse précision qui peut être exploité par les algorithmes de deep learning. Il atteint également 85 Tflops en FP32 et 42 Tflops en FP64 grâce à l'intégration de GPU Pascal. De quoi permettre à Nvidia de mettre en avant un gain de 75x au niveau de la vitesse d'entrainement d'un réseau de neurones artificiels par rapport à un serveur qui se conterait de CPU classiques.

Ce supercalculateur très dense embarque pas moins de 8 accélérateurs Tesla P100, chacun équipé de 16 Go de mémoire HBM2. Ceux-ci sont pilotés par 2 Xeon E5-2698 v3 (16 coeurs à 2.3 GHz), chacun associé à 256 Go de DDR4 2133. Nvidia a également opté pour un stockage plutôt costaud avec 4 SSD de 1.92 To en RAID 0. De quoi pouvoir prendre en charge de larges datasets. Si le DGX-1 est relativement compact au vu de la puissance de calcul qu'il embarque, il n'est par contre pas léger avec 60 kg sur la balance, ce qui s'explique en partie par l'alimentation et le refroidissement qui sont prévus pour encaisser 3200W, dont 2400W rien que pour les 8 Tesla P100.
Nvidia a bien entendu prévu le DGX-1 pour profiter pleinement de la connectique NVLink. Pour rappel, chaque GPU GP100 intègre 4 de ces liens qui offrent chacun une bande passante bidirectionnelle de 40 Go/s . Voici la topologie qui a été retenue et que Nvidia nomme NVLink Hybrid Cube Mesh :
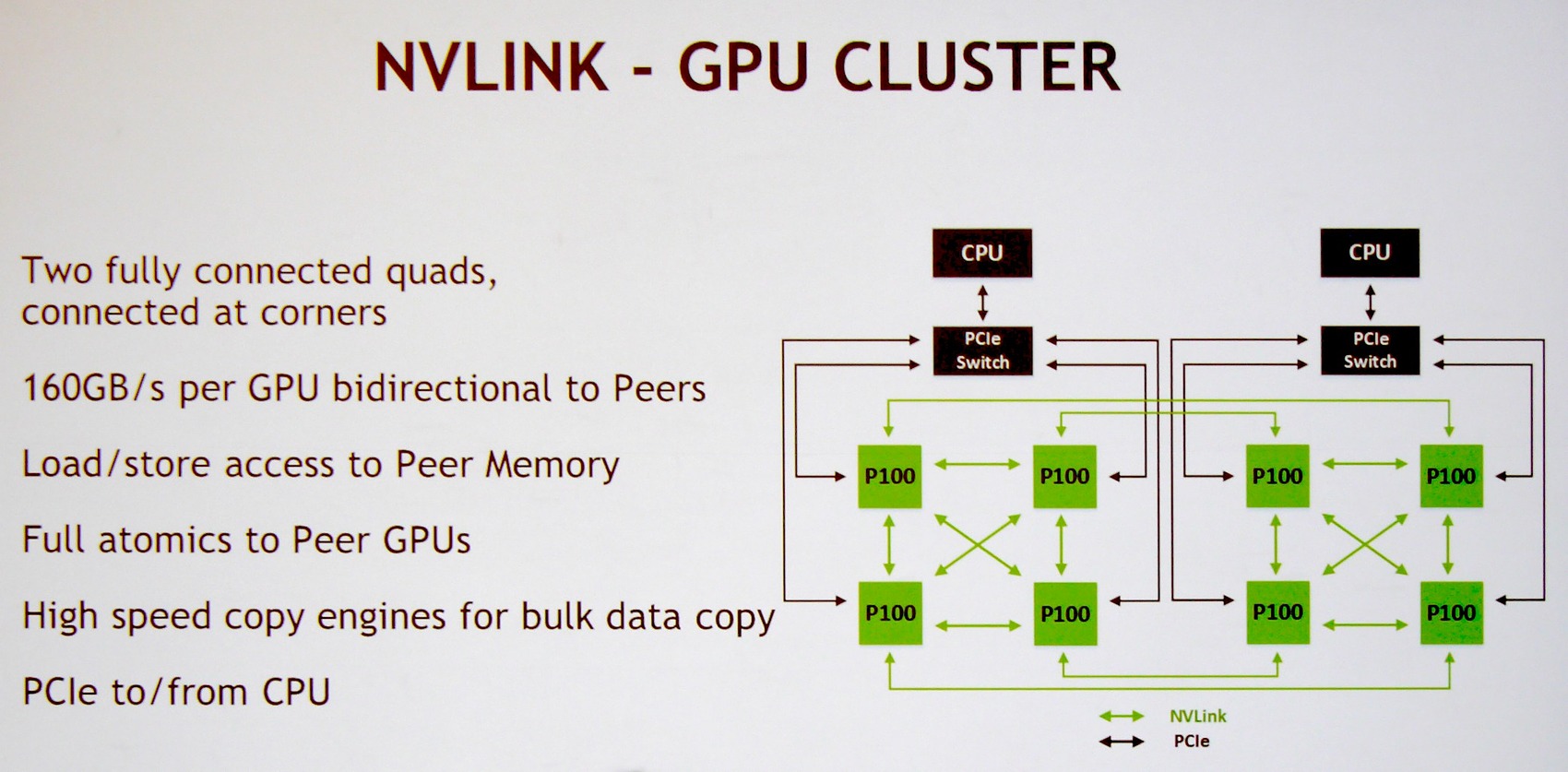
Assez logiquement 4 Tesla P100 sont reliés à chaque CPU via des liens PCI Express qui passent par un switch. Ensuite ces 4 GPU sont reliés entre eux via 3 de leurs liens NVLink. Enfin, leur quatrième lien est exploité pour les relier à l'un des GPU du second groupe de 4 Tesla P100. Il y aura donc quelques limitations au niveau de la communication entre ces 2 groupes de Tesla P100, mais elle est maintenue possible par cette topologie.
Nvidia annonce une disponibilité dès le mois de juin pour le DGX-1, ce qui semble très rapide, même si dans un premier temps cela ne concernera que les Etats-Unis. Il faudra en effet attendre le troisième trimestre pour une disponibilité plus globale.
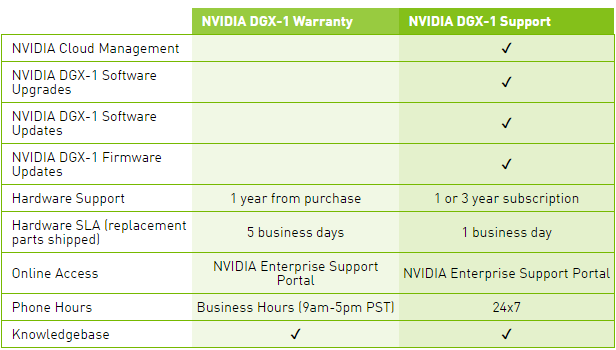
Le tarif communiqué par Nvidia monte à pas moins de 129.000$ HTVA, et ce pour le package basique, Warranty, qui n'inclus aucune mise à jour pour la suite logicielle, ce qui est étrange compte tenu de l'évolution très rapide et continuelle de ses outils dédiés au deep learning. Pour avoir accès à ces mises à jour, il faudra ajouter une cotisation annuelle pour passer au package Support.
Une politique tarifaire qui nous laissent penser que l'accélérateur Tesla P100 seul sera commercialisé à un prix très élevé. Nous ne serions pas étonnés de voir Nvidia atteindre la barre symbolique des 10.000$.