
Les contenus liés au tag Zen
Afficher sous forme de : Titre | FluxRésultats AMD pour le troisième trimestre
Les 1331 pins du socket AM4 en photo
Chipset X370 pour les Zen Summit Ridge
AMD détaille l'architecture de Zen
SK Hynix et Samsung parlent de HBM
Ryzen, une (petite) partie de Zen dévoilée



La communication d'AMD autour de ses futurs CPU Zen s'accélère. Au cours d'une conférence intitulée New Horizon, et conçue avant tout pour les utilisateurs "enthousiastes", AMD vient de dévoiler la marque commerciale des versions grand public. Le nom de code Zen laisse ainsi sa place à Ryzen.

Pour marquer ce qui est attendu comme son grand retour dans le monde du CPU et faire table rase du passé, AMD avait besoin d'un changement de marque. Ce sera Ryzen, qui permet de conserver la sonorité de Zen, probablement en s'inspirant de Rise ou encore de Horizon. La dénomination complète n'est pas encore connue, mais selon les rumeurs elle devrait être de type Ryzen SR7/SR5/SR3 suivi de la référence exacte.

Après avoir détaillé son architecture cet été, AMD profite de l'occasion pour dévoiler quelques informations de plus concernant ces futurs CPU. Tout d'abord AMD confirme que le fer de lance de la gamme sera bien un modèle 8 coeurs / 16 threads, sera cadencé à plus de 3.4 GHz en fréquence de base, aura un TDP de 95W et profitera de 20 Mo de cache, ce qui correspond à 16 Mo de L3 et 8x 512 Ko de L2.
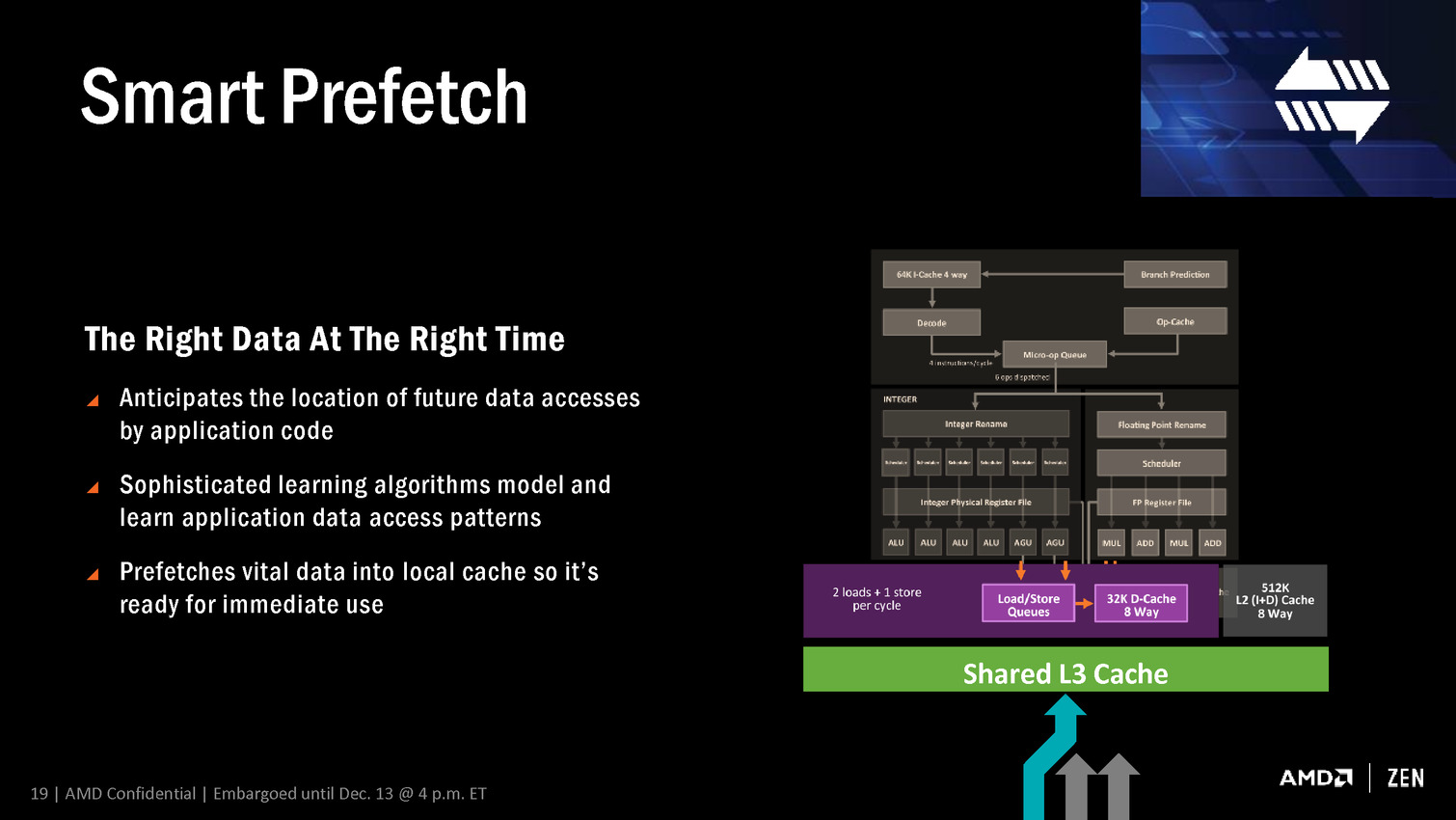
Les détails de plus communiqués par AMD sont regroupés sous la dénomination SenseMI Technology qui regroupe différentes approches pour contrôler et augmenter l'efficacité des CPU Ryzen. Ne vous attendez cependant pas à des détails techniques très poussés, il s'agit avant tout pour AMD de présenter des éléments de communication qui seront utilisés pour mettre en avant ses nouveaux CPU.


Un ensemble de techniques qui se nomment :
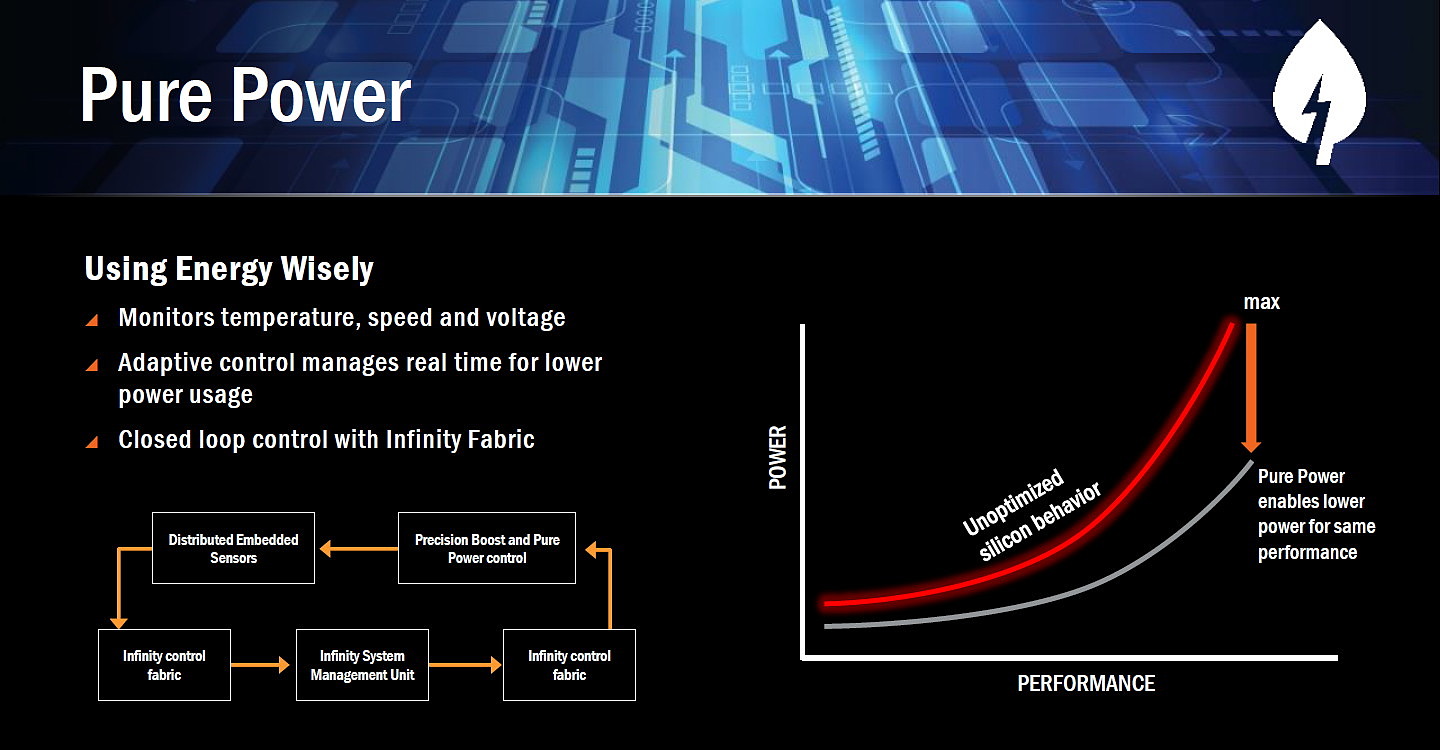
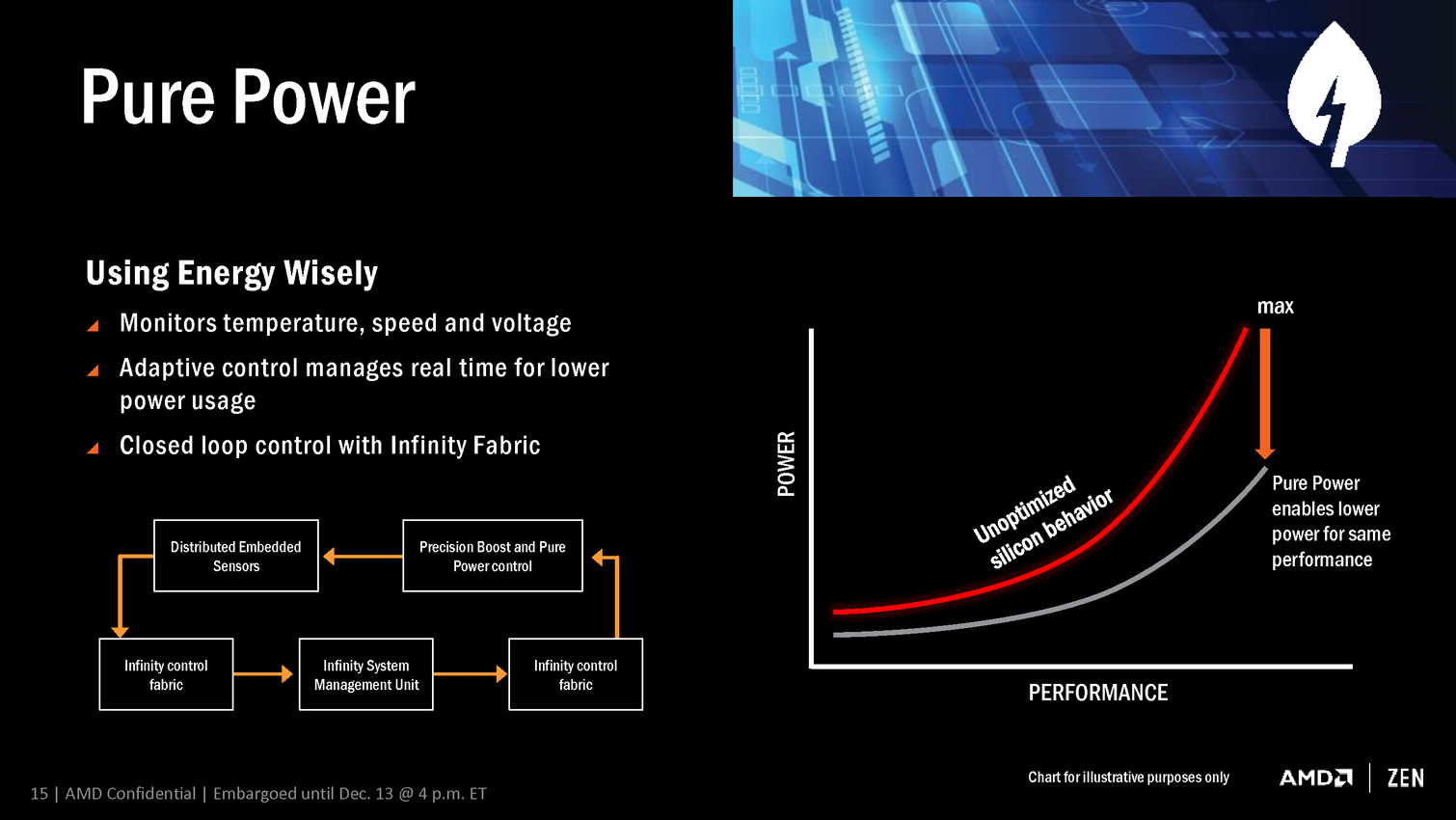
- Pure Power
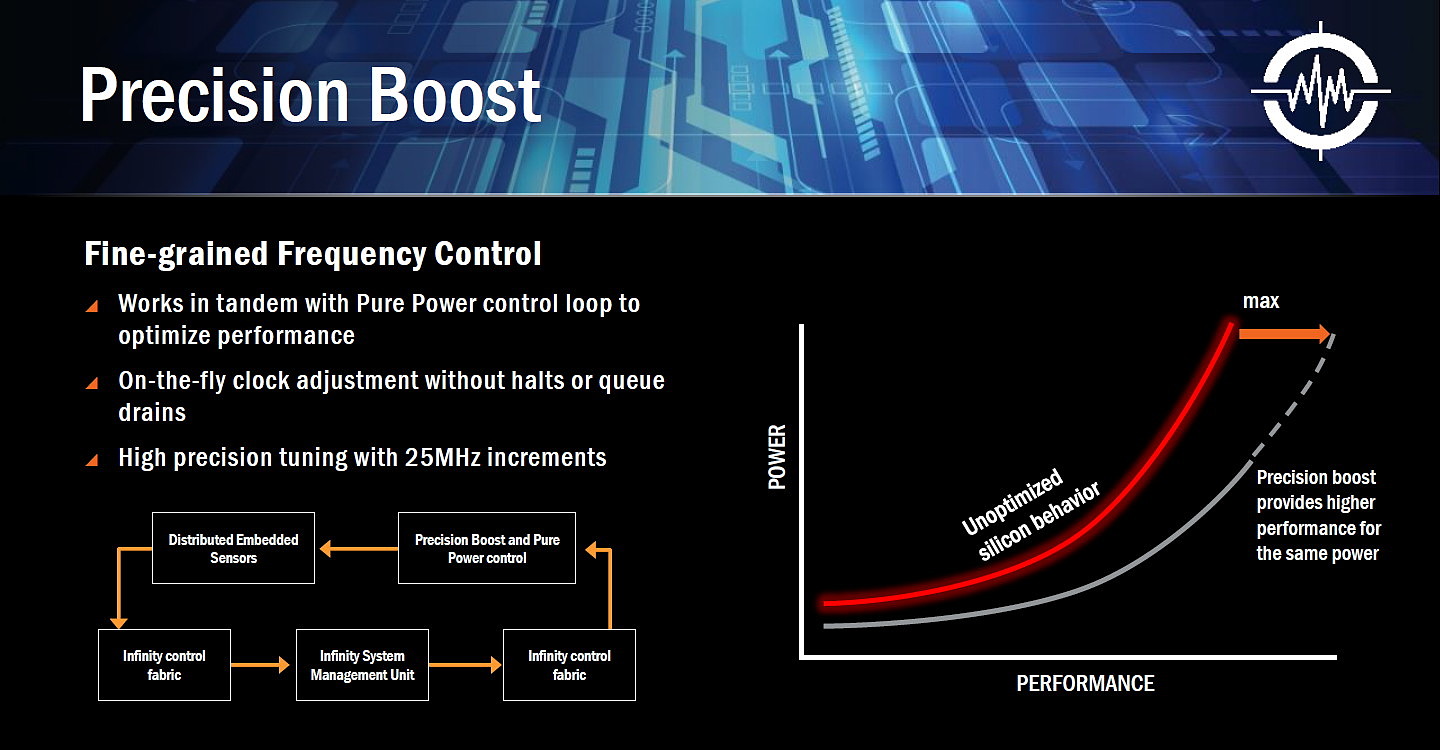
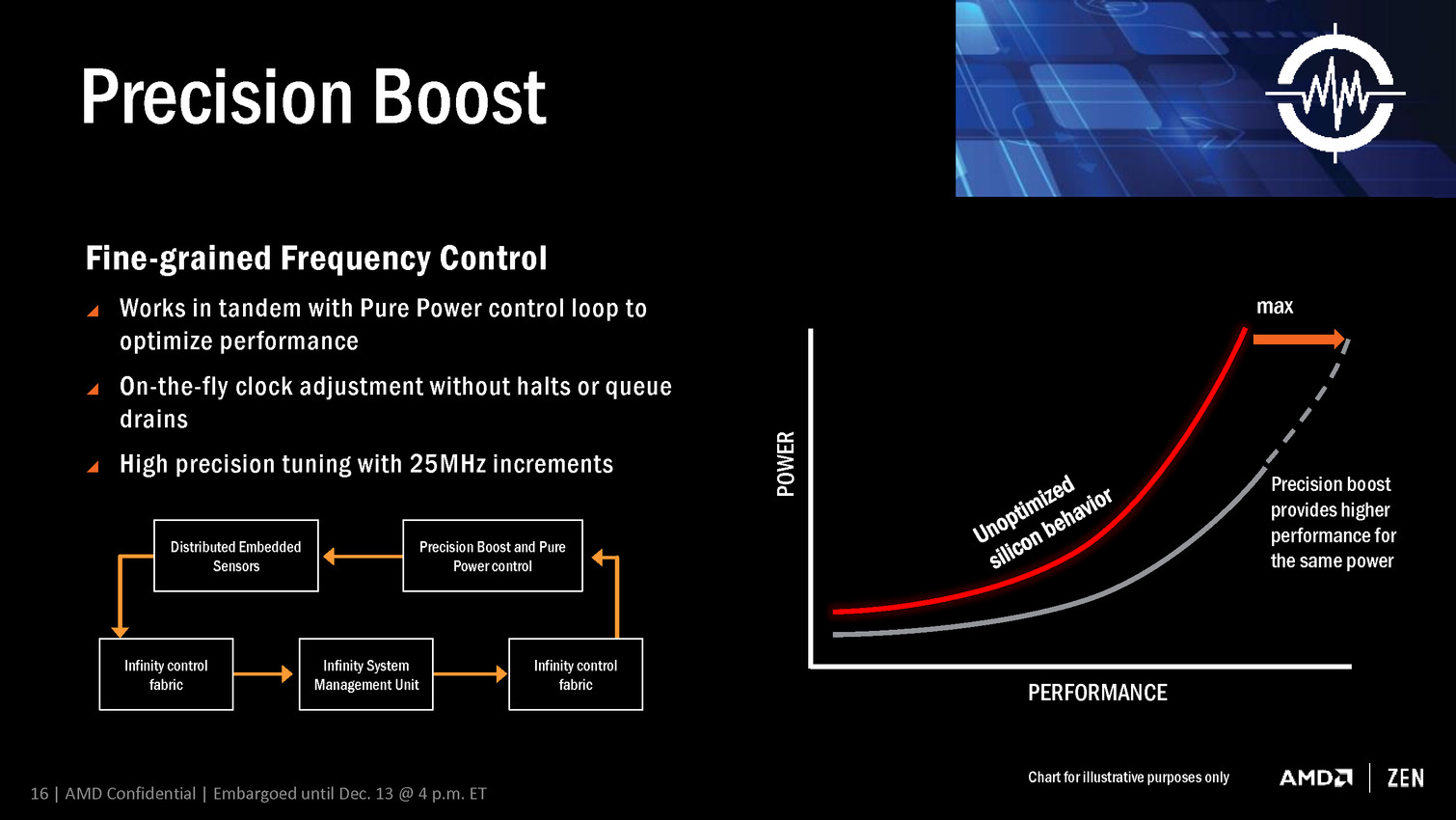
- Precision Boost
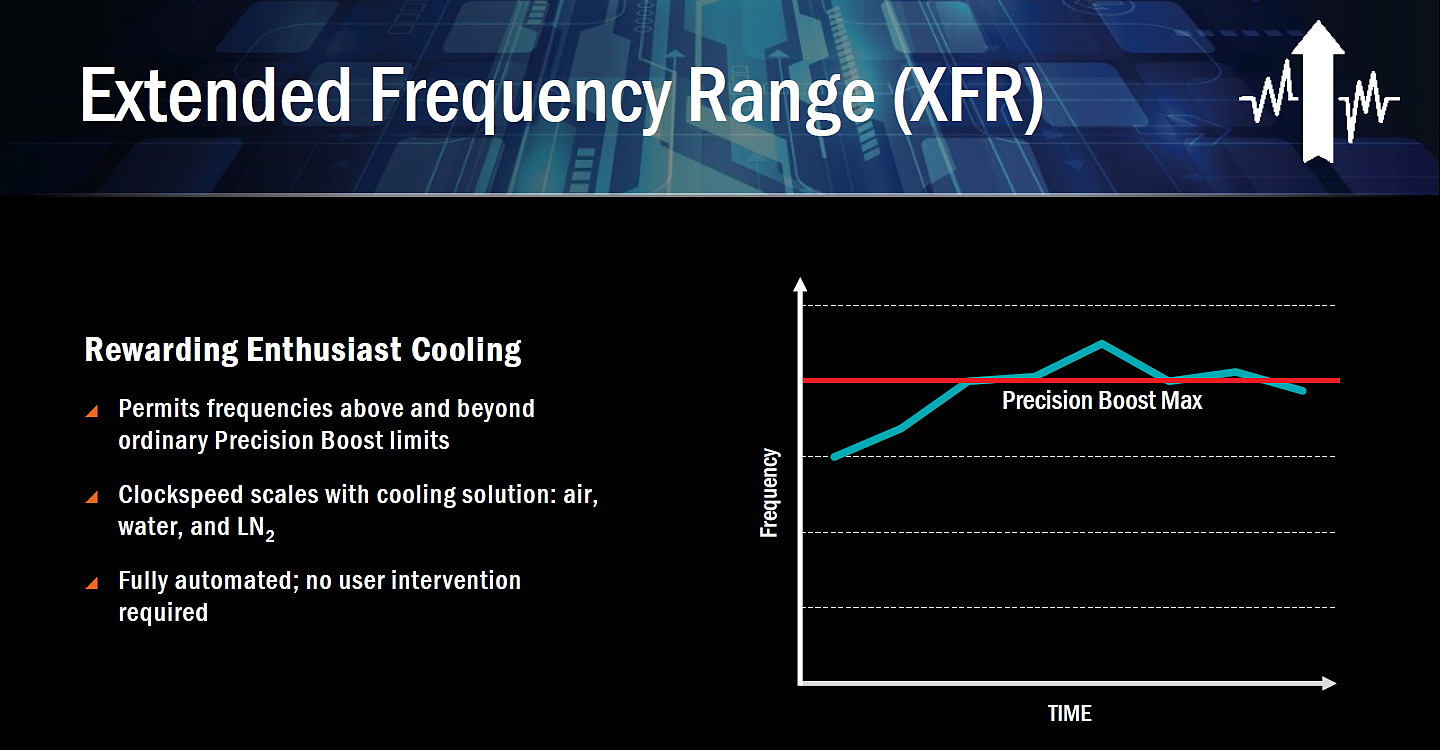
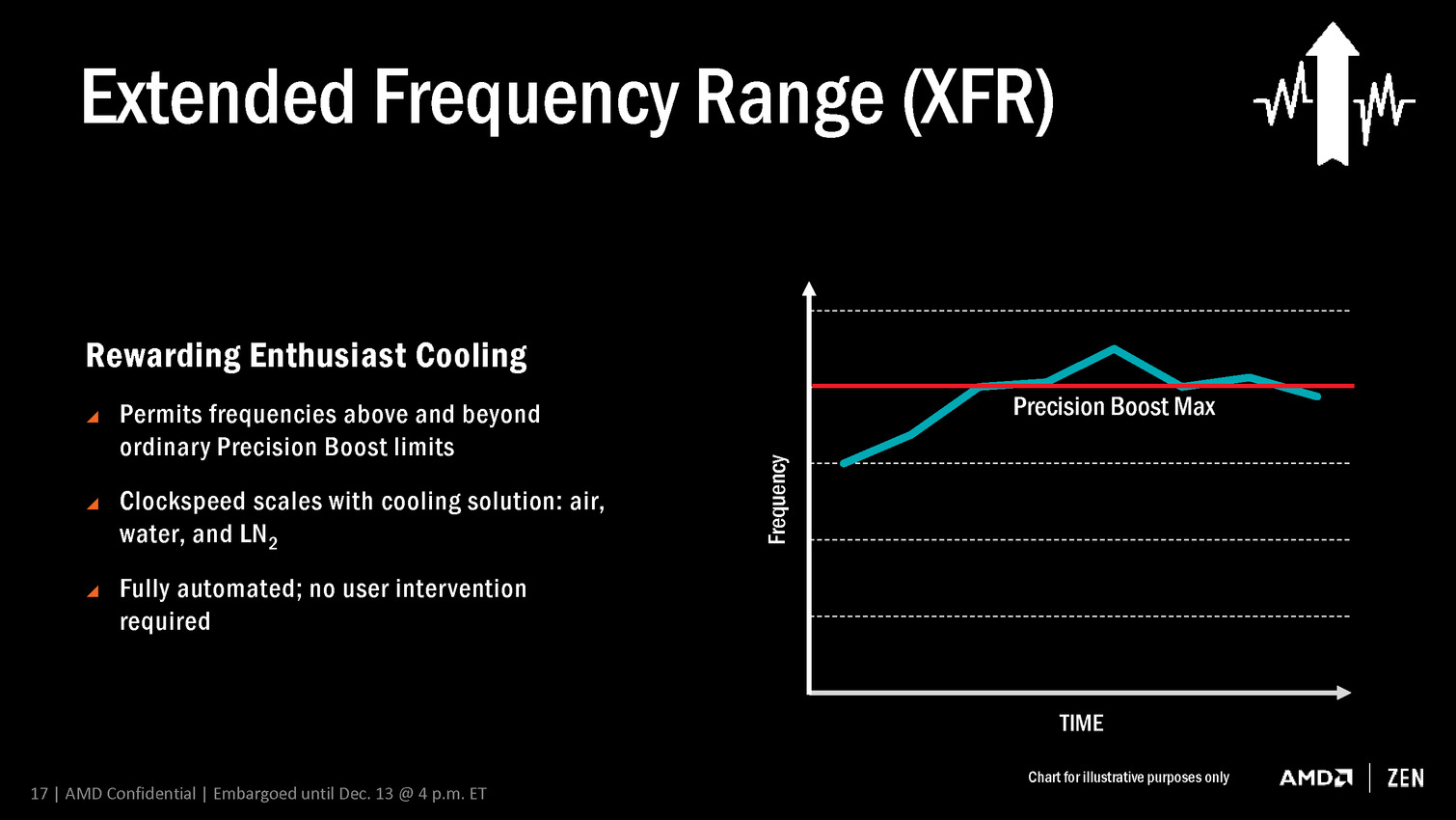
- Extended Frequence Range (XFR)
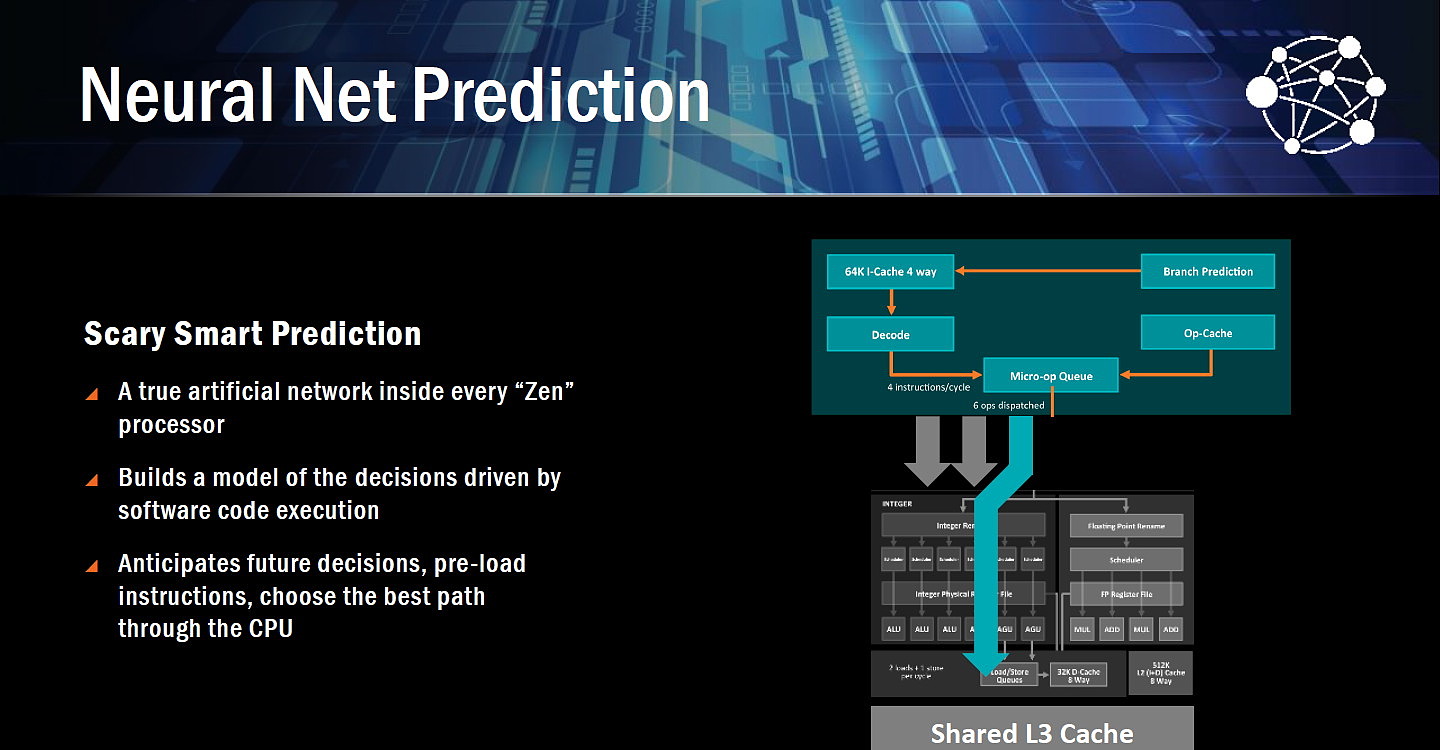
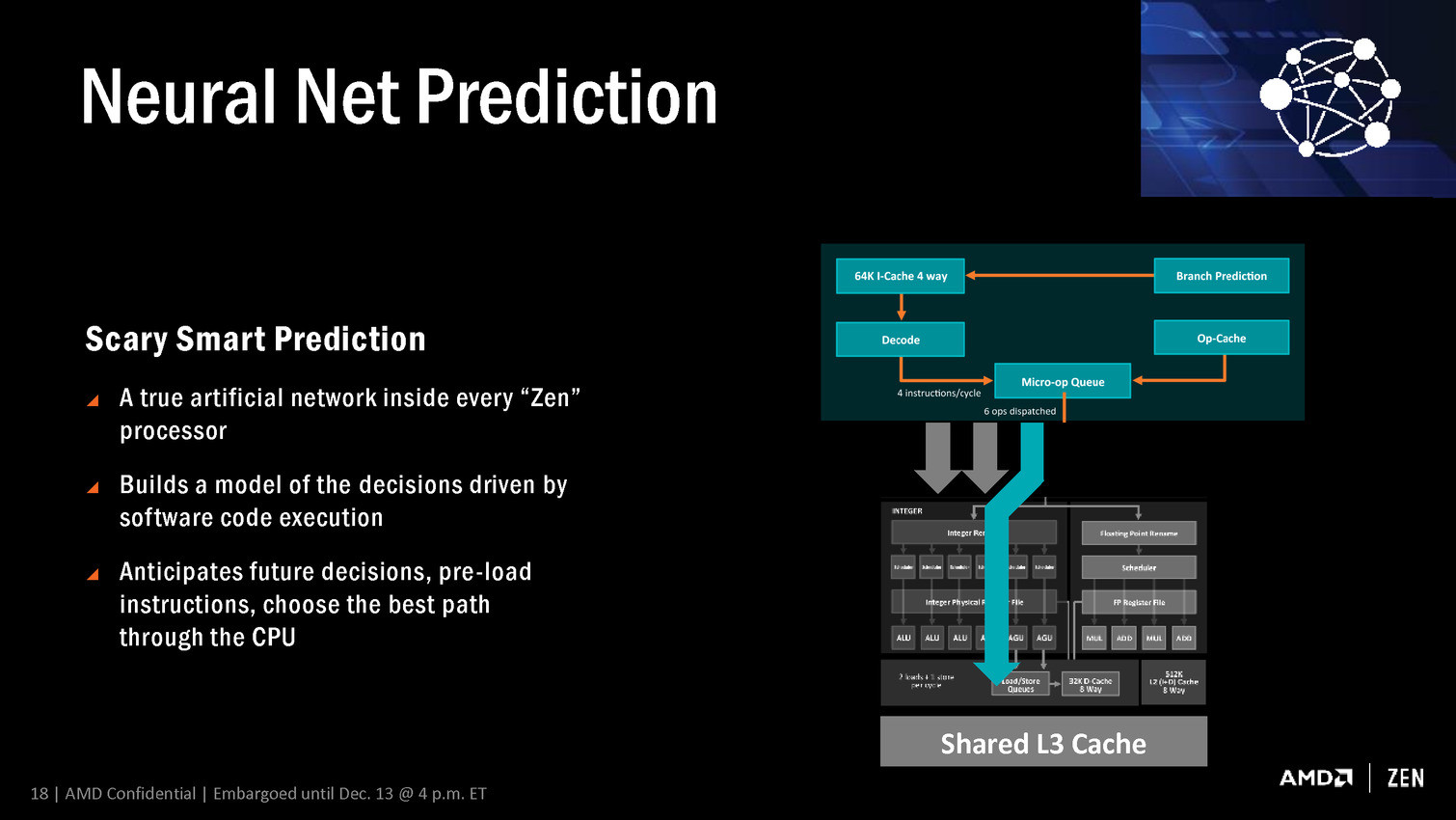
- Neural Net Prediction
- Smart Prefetch
De quoi s'agit-il ? Pure Power et Precision Boost représentent les systèmes de gestion de la courbe de fréquences. Comme sur tous les CPU ou GPU récents ces mécanismes sont cruciaux pour améliorer le rendement énergétique et profiter d'un maximum de performances dans une enveloppe thermique donnée. Difficile de savoir exactement ce qui a été amélioré par AMD en dehors de ces nouveaux noms commerciaux, mais nous pouvons noter plusieurs référence à l'Infinity Fabric, un tissu de communication qui semble avoir un rôle important. L'information la plus important concerne cependant une gestion de la fréquence par pas de 25 MHz, contre au moins 100 MHz pour les CPU actuels. AMD n'explique cependant pas comment cela a été implémenté.
Extendend Frequence Range, ou XFR, permet d'aller un peu plus loin sur la courbe des fréquences, au-delà de la fréquence turbo qui sera communiquée par AMD, mais uniquement sous certaines conditions liées au refroidissement. Grossièrement il s'agit pour AMD d'offrir un petit overclocking automatique aux "enthousiastes". La fréquence pourra ainsi progresser un petit peu avec un gros ventirad, encore un petit peu plus avec un système de watercooling et atteindra un maximum avec de l'azote liquide. Nous pouvons supposer que la fréquence turbo maximale sera ainsi une fonction de la température CPU. AMD précise que tout cela sera automatique et actif par défaut.
Neural Net Prediction et Smart Prefetch représentent comme vous l'aurez probablement deviné les noms commerciaux des systèmes de prédiction et de prefetch de Zen qui ont été améliorés. AMD indique exploiter un réseau de neurones artificiels plus évolué que les mécanismes classiques mais n'en dit pas plus, ce qui ne permet donc pas de juger à quel point la prédiction et le prefetch ont progressés en efficacité.
Bien entendu, AMD a également effectué quelques démonstrations lors de cette conférence, mais également lors de son Tech Summit qui s'est tenu la semaine passée. Nous avons notamment pu observer un Ryzen 8 coeurs / 16 threads cadencé à 3.4 GHz (fixe sans turbo) égaler un Core i7-6900K (3.5 GHz en Turbo sur les 8 coeurs) sous HandBrake ou encore Blender, et ce avec une consommation légèrement inférieure : 187 contre 191 watts. On notera par contre la consommation élevée au repos sur les deux plateformes à 93 watts chez AMD contre 106 chez Intel, les systèmes d'économie d'énergie des CPU étaient probablement désactivés de part et d'autre car pas encore pleinement fonctionnels sur Ryzen. Une comparaison a également lieu entre ces deux CPU avec une paire de Titan X en 4K sous Battelfield 1 pour mettre en avant le fait qu'ils offrent une expérience similaire pour une plateforme de jeu haut de gamme, mais sans mesure de framerate.
Tout ceci manque bien entendu de benchs non sélectionnés côté applicatif et de précision côté jeu, un domaine ludique dans lequel les CPU Ryzen auront probablement fort à faire face aux derniers CPU 4 coeurs d'Intel, suivant l'exploitation plus ou moins poussée de tous les coeurs. Nul besoin cependant d'égaler Intel sur tous les fronts. En plus de repartir sur une meilleure base au niveau de l'IPC, AMD compte évidemment se démarquer avec un tarif par coeur plus intéressant et dans ce sens le Core i7-6900K à 1200 est une cible de choix. Reste bien entendu à voir quelles seront les fréquences finales : la seule information officielle est que le fer de lance aura une fréquence de base supérieure à 3.4 GHz.
Les premiers CPU Ryzen sont annoncés pour Q1 2017, mais compte tenu de l'état beta des plateformes, avec notamment un système de gestion et de turbo qui n'est pas encore totalement fonctionnel, il est raisonnable de tabler plutôt sur mars que sur janvier. Plus que quelques mois de patience !
Vous pourrez retrouver l'intégralité de la présentation d'AMD ci-dessous :



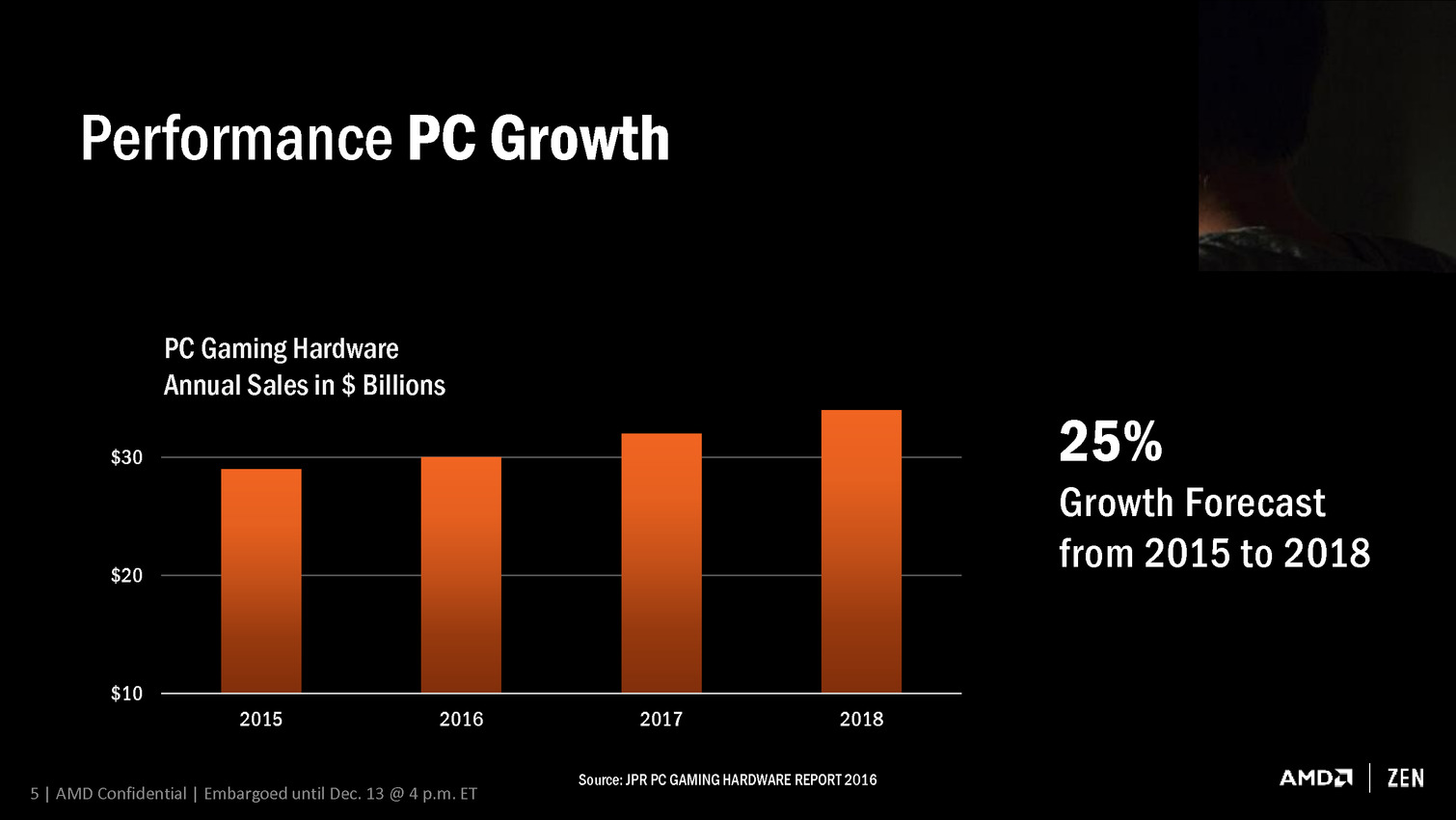
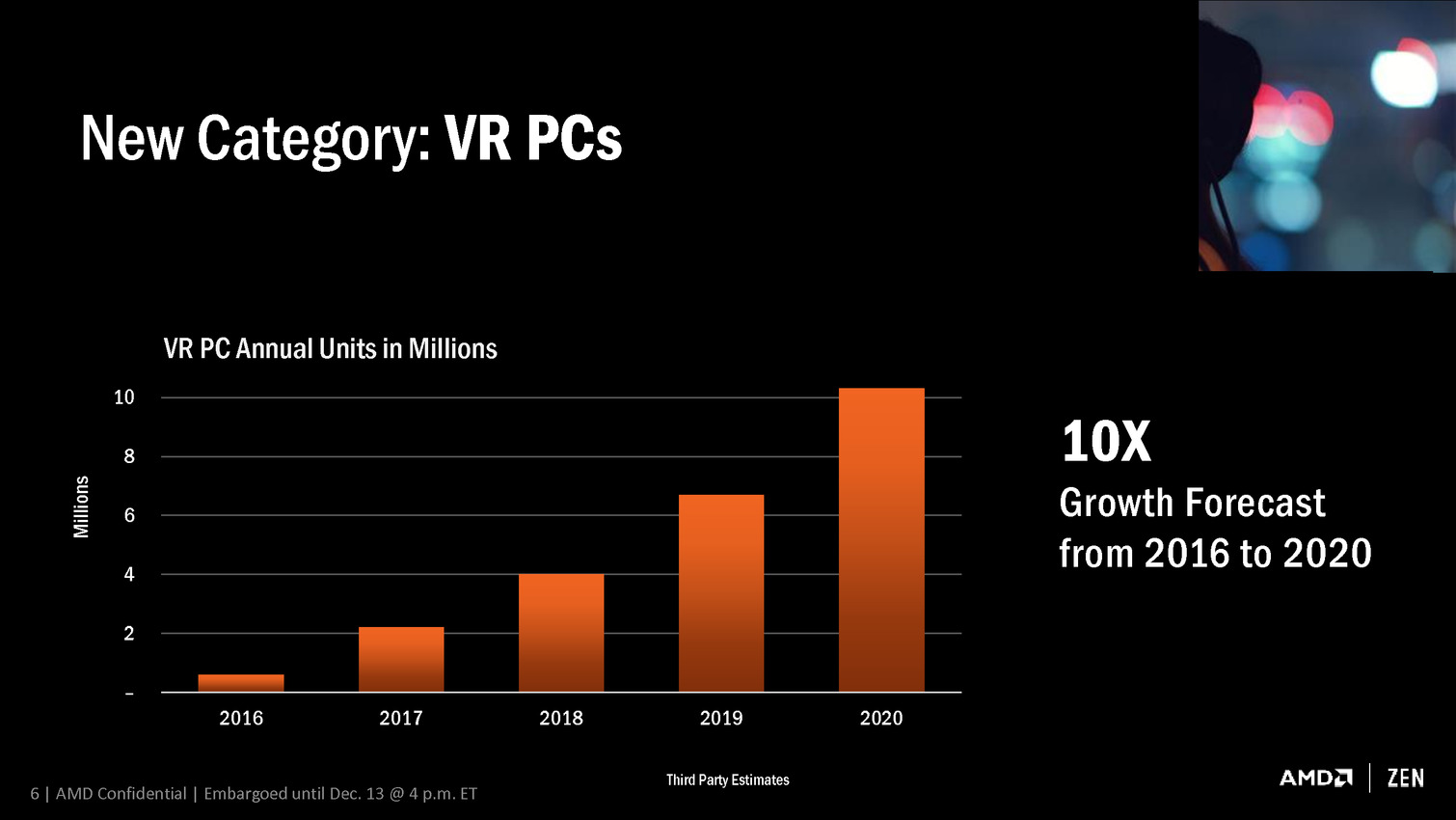
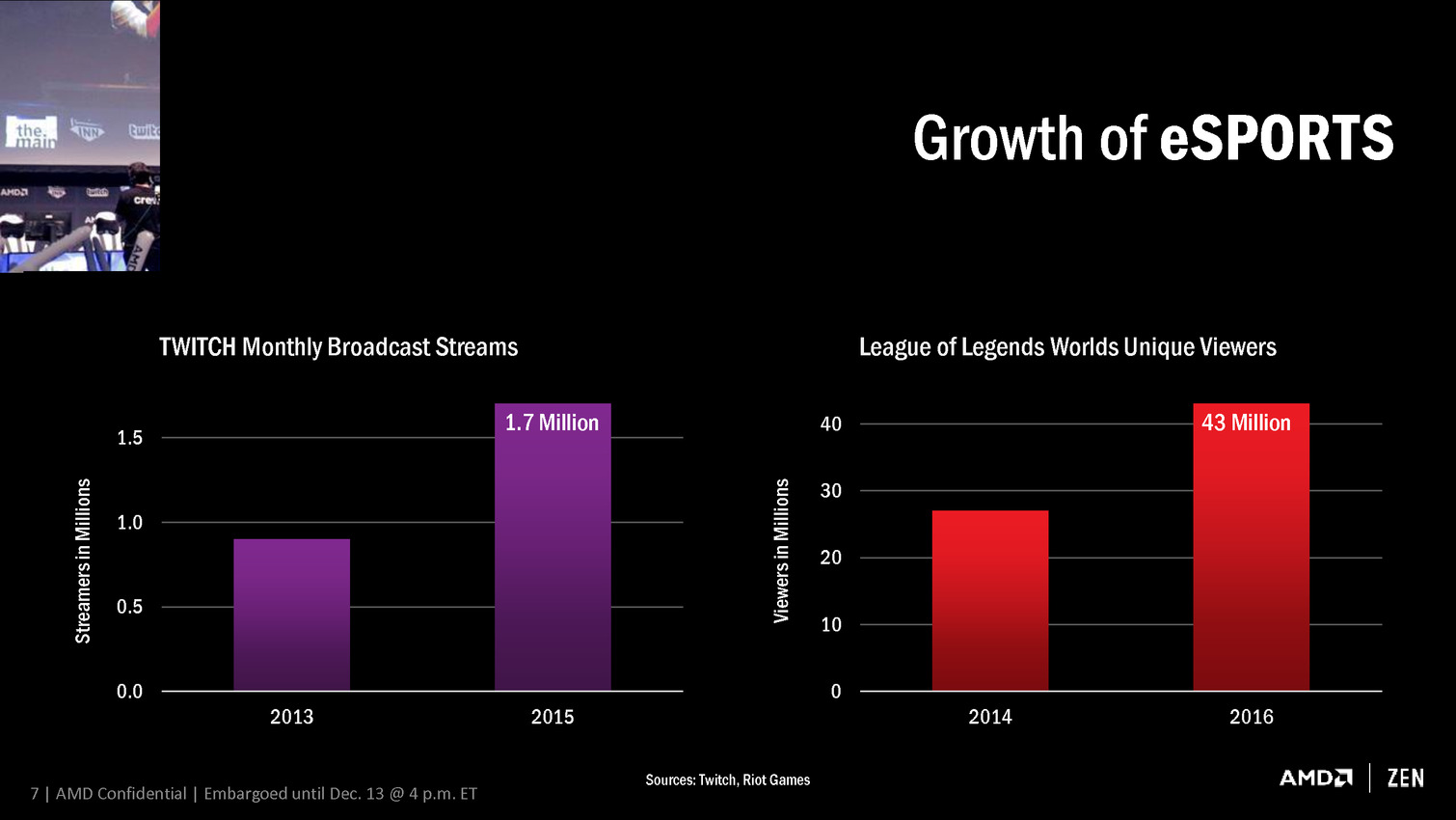





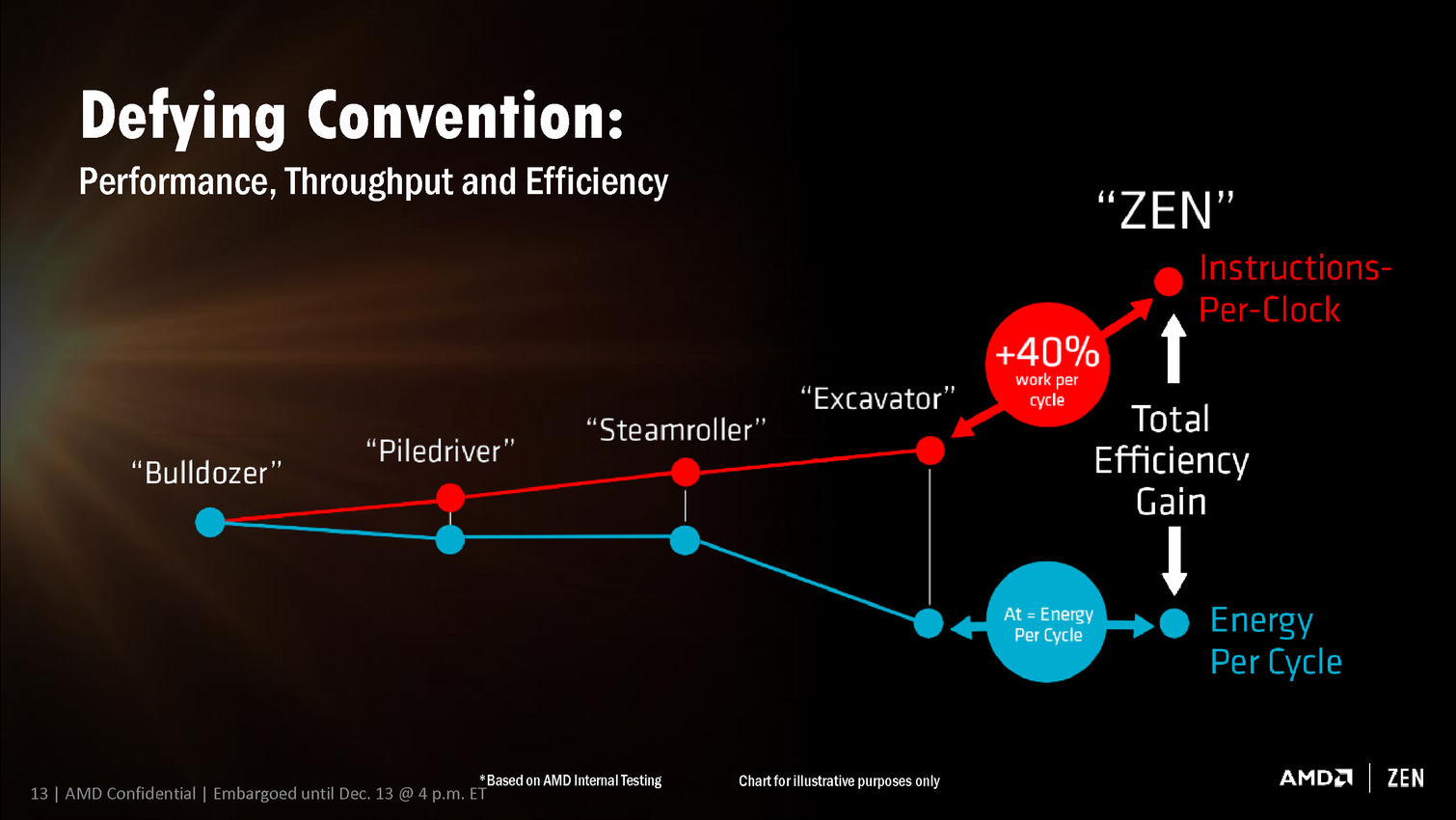








Naples : l'énorme CPU Zen 32 coeurs en photo
A l'occasion de l'AMD Tech Summit, nous avons pu apercevoir Naples, un futur "Opteron" (ou nouvelle marque). Basé sur Zen, il embarque pour rappel pas moins de 32 coeurs / 64 threads et est prévu dans un premier temps pour une plateforme 2P telle que celle exposée :


Le CPU, à priori composé de multiples dies, prend la forme d'un packaging énorme. Il supporte 8 canaux de DDR4 (la mémoire a été cachée par AMD) et devrait afficher un TDP de 180W. Sa disponibilité est attendue pour le second trimestre 2017.
Radeon Instinct et Vega : AMD mise sur l'IA
AMD a décidé de suivre la voie de Nvidia en mettant en place une stratégie spécifique pour conquérir le marché émergent de l'intelligence artificielle. La société compte pour cela sur un écosystème ouvert, sa future architecture GPU Vega et sur des synergies avec la plateforme serveur Zen.

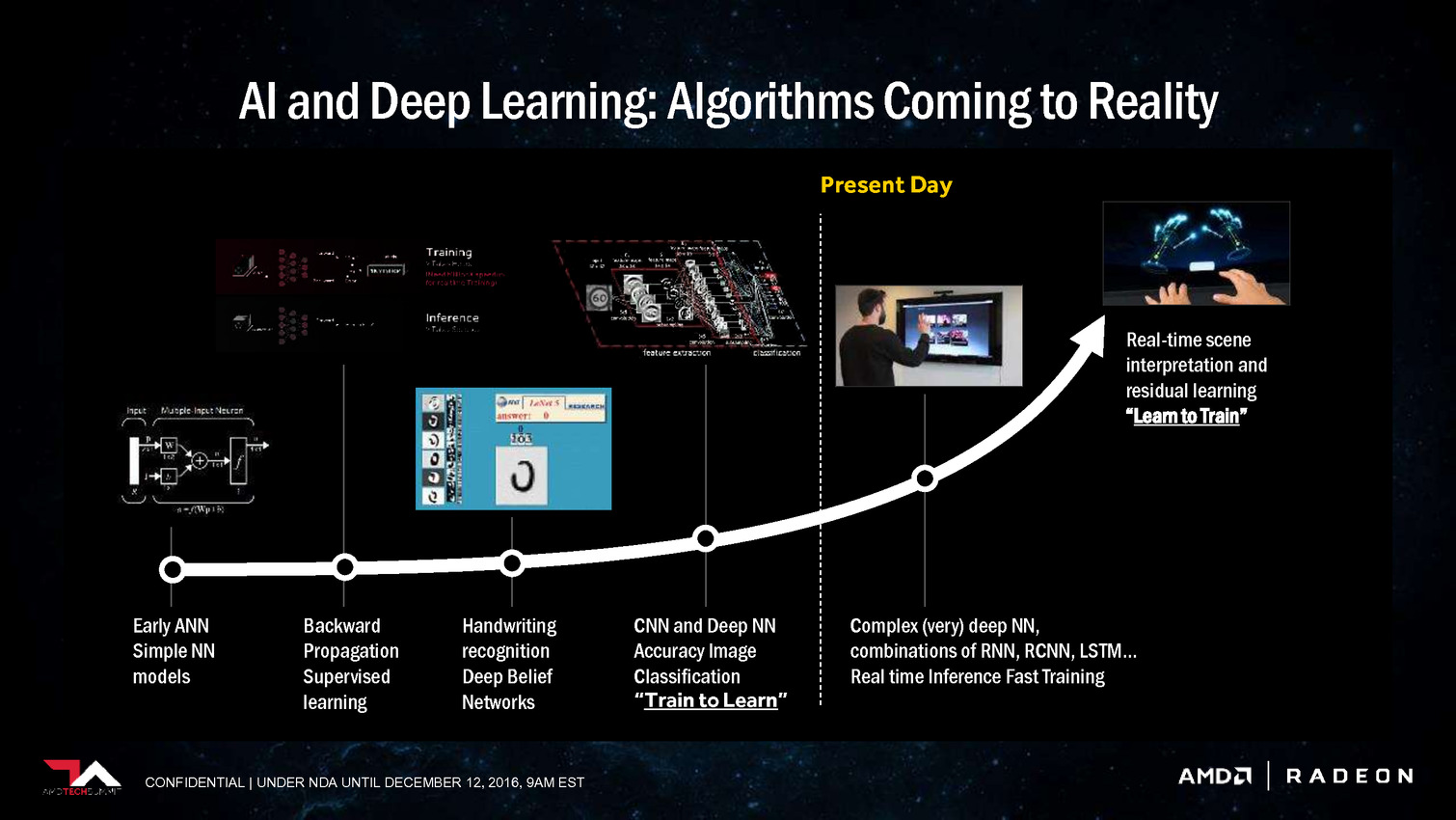
Lors de l'AMD Tech Summit qui s'est tenu la semaine passée, AMD a présenté sa stratégie par rapport au marché émergent de l'intelligence artificielle, ou intelligence machine, qui passe en l'état actuel des choses principalement par le deep learning. Nous en avons déjà parlé à plusieurs reprises, rappelons simplement qu'il s'agit d'une part d'entraîner un réseau de neurones numériques (par exemple à faire la différence entre en chien et un chat en cherchant des points commun entre des milliers de photos identifiées) et d'autre part de déployer ce réseau en vue d'une exploitation pratique (par exemple ne distribuer de la nourriture qu'aux chiens).
L'entraînement d'un réseau tout comme son exploitation, ou inférence, a besoin de puissance de calcul et représente une opportunité pour les accélérateurs de tous types dont bien entendu les GPU. L'accélération du deep learning est d'ailleurs actuellement dominée par Nvidia qui, en plus d'un écosystème logiciel complet, propose des produits spécifiques pour l'entraînement et pour l'inférence, particulièrement dans le cadre de la conduite automatisée qui représente un débouché prometteur.
Les GPU proposés par AMD sont également adaptés à ces tâches, et sont déjà exploités dans une certaine mesure, mais pour aller plus loin une initiative spécifique était nécessaire. C'est là qu'intervient Radeon Instinct avec de nouveaux accélérateurs positionnés vers ce marché, un écosystème logiciel plus complet et une future architecture GPU, Vega, qui va proposer quelques optimisations utiles.

Grossièrement la gamme de Radeon Instinct s'inscrit dans la continuité des FirePro S, les accélérateurs dédiés aux serveurs, mais avec un positionnement stratégique retravaillé pour coller à un marché en pleine explosion. Les 3 nouvelles cartes dédiées à l'accélération prennent ainsi les noms de Radeon Instinct MI6, MI8 et MI25, MI étant une référence à Machine Intelligence et le nombre qui suit une référence à leur puissance de calcul. Serveur oblige il s'agit dans tous les cas de solutions passives.
La Radeon Instinct MI6 est équivalente à une Radeon RX 480 avec un GPU Polaris 10, une puissance de calcul de 5.7 Tflops, une bande passante de 224 Go/s et une consommation annoncée à moins de 150W. Le modèle MI8 est pour sa part dérivé de la Radeon Nano et propose 8.2 Tflops et 512 Go/s pour une consommation de moins de 175W.
C'est bien entendu la Radeon Instinct MI25 qui est la plus intéressante, même si elle ne sera pas disponible directement puisqu'il s'agit d'un futur accélérateur basé sur le GPU Vega 10. Cet accélérateur offrira une puissance de calcul de 25 Tflops, mais attention, il s'agit de calcul au format FP16 via le support du packed math.
Tout comme Nvidia le fait sur le GP100 et le Tesla P100, AMD a conçu ses nouvelles unités de calcul de manière à ce qu'elles puissent exécuter au choix soit des instructions FP32, soit un vecteur de 2 instructions FP16. De quoi doubler la puissance de calcul lorsqu'une précision réduite est suffisante, en opposition aux Radeon récentes qui ne supportent le format FP16 qu'au niveau du stockage dans les registres, mais pas au niveau des unités d'exécution.
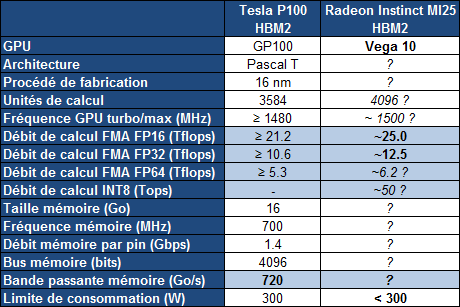
AMD parle également de High Bandwidth Cache and Controller. Sachant que Vega supportera la mémoire HBM2, cela semble indiquer qu'elle sera exploitée en tant que cache et donc possiblement en complément d'un autre type de mémoire, le tout piloté par un nouveau contrôleur.
Enfin, AMD donne une première information concernant la consommation de ce futur GPU haut de gamme. Il est question de moins de 300W mais au vu des chiffres communiqués pour les autres Radeon Instinct, c'est à priori 300W et pas moins pour Vega 10. C'est similaire au Tesla P100 et il restera à voir si les déclinaisons orientées vers les joueurs pousseront la limite de consommation vers le haut comme pour la Radeon Fury X, ou la limiteront comme pour la (GeForce) Titan X.
Pour atteindre 25 Tflops en FP16, et donc 12.5 Tflops en FP32, plusieurs options sont possibles, mais la plus probable est un GPU composé de 4096 unités de calcul cadencée à +/- 1.5 GHz. Enfin, lors de la présentation de ces cartes, Liam Madden de Xilinx a précisé voir beaucoup d'intérêt dans le format 8-bit, ce qui laisse penser qu'un certain niveau de support est présent à ce niveau, comme le fait Nvidia sur ses GPU Pascal dédiés à l'inférence (autres que le GP100). A noter qu'AMD mentionne des NCU, ce qui signifie probablement New Compute Unit et d'autres améliorations peuvent donc être au programme.

Pour accompagner ces accélérateurs, l'aspect logiciel est évidemment crucial. AMD se base à ce niveau sur sa plateforme ROCm dédiée au calcul hétérogène et qui est déjà en partie optimisée pour l'accélération des frameworks principaux dédiés au deep learning, tels que Caffe, entre autre grâce à la prise en charge depuis quelques temps du code CUDA (via des outils de portage). AMD proposera également MIOpen au premier trimestre 2017, une réponse au cuDNN de Nvidia et donc une librairie dédiée à l'accélération par ses GPU des routines les plus courantes liées au deep learning. Autant pour ROCm que pour MIOpen, AMD insiste sur une approche open source pour convaincre les développeurs.
Enfin, AMD fait part de son intérêt pour les interconnexions nouvelles qui vont permettre d'aller au-delà des limitations du PCI Express 3.0, et sur la possibilité de fournir une plateforme complète sur base de serveurs Zen. De tels serveurs sont déjà prévus chez SuperMicro (SYS 1028GQ-TRT), Inventec (G888, 100 Tflops avec 4 MI25 et rack de 3 petaflops avec 120 MI25) et Falconwitch (PS1816, 400 Tflops avec 16 MI25).

Nous avons profité de notre présence sur place pour interroger Raja Koduri sur l'opportunité d'apporter des modifications spécifiques pour le deep learning à l'architecture de ses GPU. Comme à son habitude le chef de file du Radeon Technology Group s'est montré très pragmatique. Si quelques petites touches peuvent être utiles, les algorithmes évoluent beaucoup trop rapidement pour des modifications de grande ampleur.
Et de préciser que face à une approche très brute force du deep learning il n'est pas impossible de découvrir un beau matin une technique totalement différente qui réduira à néant certains travaux précédents. Face à cela, Raja Koduri estime que la flexibilité et les performances de base de son architecture, et surtout de son compilateur, restent garants de la pertinence de ses GPU dans le domaine de l'intelligence machine. Si des architectures spécifiques à certains algorithmes ont été développées par différents acteurs, il ne pense pas que cela ira plus loin que des implémentations de type FPGA, tout du moins à court et moyen termes.

Enfin, terminons par préciser qu'un prototype de Radeon Instinct était déjà en démonstration la semaine passée et était occupé à entraîner un réseau. Impossible cependant d'observer la carte de plus près que ce que n'offre notre cliché, AMD ayant pris soin de camoufler la moindre ouverture du boîtier qui l'embarquait.
Aucune information précise n'a été communiquée sur la disponiblité du GPU Vega 10 et de la Radeon Instinct MI25, AMD se contentant de parler du premier semestre 2017, ce qui revient en général à exclure le premier trimestre. Il faudra donc patienter encore quelques mois avant de voir débarquer ce GPU très attendu, même si d'ici là quelques aspects techniques devraient être dévoilés.
Vous pourrez retrouver l'intégralité de la présentation d'AMD ci-dessous :



























AMD va parler de Zen le 13 décembre
Tout le monde attend Zen de pied ferme, AMD en a conscience et en attendant son lancement prévu pour le premier trimestre le constructeur annonce un streaming ce 13 décembre. Difficile de savoir quelles seront les choses concrètes qui seront dévoilées lors de cette "fan-focused preview", mais AMD parle d'une démonstration des performances.Lisa Su, CEO d'AMD, devrait notamment intervenir. Pour les curieux et impatients il faudra passer par ici , pour les autres rendez-vous peu après pour un récapitulatif !

Des détails sur le 7nm à l'ISSCC 2017
La conférence ISSCC (International Solid-State Circuits Conference) se tiendra pour son édition 2017 du 5 au 9 février à San Francisco, et nos confrères d'EEtimes ont eu accès à l'avant programme.
Comme tous les ans les acteurs du milieu des semi conducteurs y présenterons leurs nouveautés, et l'on notera que TSMC et Samsung présenterons leurs cellules SRAM (utilisées notamment pour la mémoire cache dans les puces). L'année dernière, Samsung avait proposé deux versions distinctes pour son process 10nm, optimisées pour la densité ou les performances, de 0.040 µm² et 0.049 µm².
D'après nos confrères, TSMC présentera une cellule SRAM 7nm de seulement 0.027µm², tandis que Samsung présentera une cellule SRAM 7nm de 0.030µm², mais fabriquée en EUV. D'après Samsung, l'EUV permettrait de diminuer la tension minimale nécessaire de 39.9mV (TSMC indique aussi des optimisations basse tension, on attendra la conférence pour comparer l'impact ou non de l'EUV).
La SRAM est un composant fondamental des puces et sa taille permet en général de se donner une bonne idée des process. Cependant il faut être assez méfiant, les constructeurs annonçant parfois des "records" de densité qu'ils n'utilisent pas forcément en production. Nous avons rapporté dans le tableau ci dessous les chiffres les plus bas (correspondant aux bibliothèques "hautes densité") pour TSMC, Samsung et Intel :
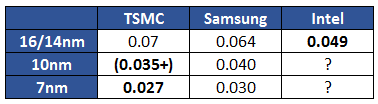
Par rapport au tableau, on notera qu'Intel n'utilise pas cette SRAM haute densité dans ses processeurs, mais de la SRAM 0.059 µm². Même en prenant cela en compte, Intel garde la meilleure densité à 16/14nm pour la SRAM. Le constructeur ne fournit pas encore d'infos sur ses futurs process.
TSMC n'a pas donné non plus de chiffre exact pour son 10nm, estimant simplement 50% de réduction par rapport à son 16nm sur la SRAM, ce qui nous vaut un chiffre entre parenthèses. Selon toutes vraisemblances, et conformément aux autres annonces sur la densité (2.1x d'après le constructeur), on estimera que TSMC devrait avoir une SRAM d'une taille légèrement inférieure à celle de Samsung.
Intel ne devrait pas effectuer d'annonce sur ce sujet lors de l'ISSCC, ce qui est assez dommage. Le constructeur devrait présenter les FPGA Altera Stratix 10 (14nm) tandis qu'AMD proposera une présentation plus en détails de Zen.

On notera aussi que Western Digital/Toshiba, ainsi que Samsung, présenterons des puces 3D NAND 512 Gbit TLC 64 couches. Dans le cas de Samsung, cette puce avait été annoncée cet été, plus de détails techniques devraient être disponibles. Pour Western Digital/Toshiba, cette puce avait été évoquée cet été comme objectif.
On notera que nos confrères pointent à raison un grand absent : une fois de plus, ni Intel, ni Micron, n'effectueront de présentation technique de leur mémoire 3D Xpoint !