
Nvidia GeForce GTX 460
Publié le 12/07/2010 par Damien Triolet



Débit de trianglesEtant donné lévolution apportée par Nvidia au niveau du traitement de la géométrie, nous nous sommes évidemment penchés de plus près sur le sujet. Tout dabord nous nous sommes penchés sur les débits de triangles dans deux cas de figure : quand tous les triangles sont affichés et quand ils sont tous rejetés (parce quils tournent le dos à la caméra) :
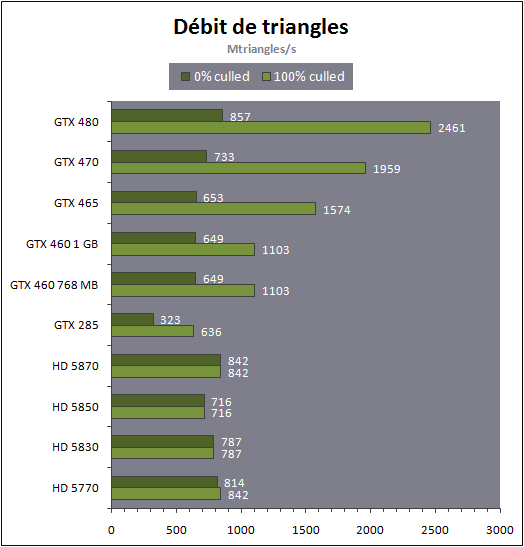
La GeForce GTX 480 savère ici très rapide et dépasse bien le débit dun triangle par cycle. Dès quil sagit déjecter des triangles du rendu via le culling, aucun autre GPU narrive à sa cheville. La GeForce GTX 460 sapproche dun débit dun triangle affiché par cycle et est également très rapide pour éjecter les triangles à travers le culling.
Nous sommes cependant loin des maximums théoriques de 4 triangles par cycle pour le GF100 et de 2 triangles par cycle pour le GF104. Quelque chose les limite sans que nous sachions exactement de quoi il sagit. Nous savons par contre que cette limitation nexiste pas sur les futurs dérivés Quadro.
Ensuite nous avons effectué un test similaire mais en utilisant la tessellation. Cet outil de test nest pas encore finalisé et optimisé pleinement de manière à pouvoir atteindre des rendements optimaux. Il permet cependant déjà de comparer les solutions entre elles :
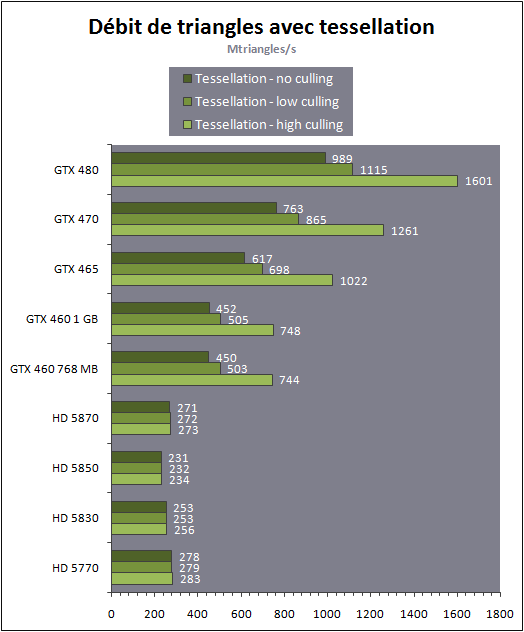
Lavantage des GeForce sur les Radeon est ici évident. Ces dernières semblent limitée à 1 triangle tous les 3 cycles quand la tessellation est utilisée. AMD nous a indiqué que ce nétait pas le cas et que lunité de tessellation était bien capable de débiter 1 triangle par cycle. Un cas que nous ne sommes pas encore parvenus à reproduire, les Radeons étant très vite dépassée lorsque trop de triangles sont générés. Notez cependant quavec 270 millions de triangles par seconde il y a déjà de quoi rendre des scènes très complexes !
AMD et Nvidia ont des approches très différentes. Alors que les Radeon affichent des performances identiques à ce niveau, les GeForce affichent un débit qui varie suivant les performances de la carte. Nous avons également noté d'énormes gains du côté des GeForce lorsque les GPUs doivent charger plusieurs vertices par primitive. Le GF100 et le GF104 continuent de tourner très vite même s'il doivent en charger 2 ou 3 alors que les autres GPUs voient leurs débits chuter puisqu'ils ne peuvent charger qu'un vertex par cycle.
Displacement mappingNous avons testé la tessellation avec une démo dAMD intégrée par Microsoft à son SDK de DirectX. Cette démo permet de comparer le bump mapping, le parallax occlusion mapping (la technique de bump mapping la plus avancée utilisée dans les jeux) et le displacement mapping qui exploite la tessellation.
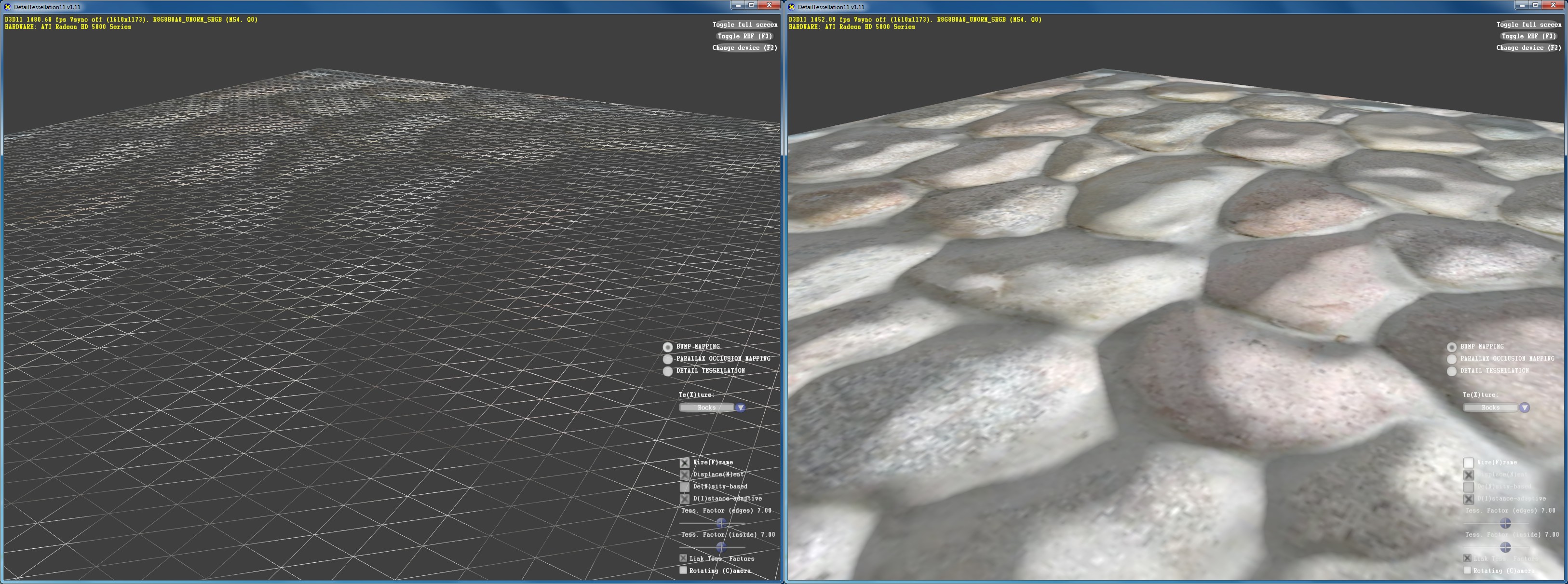
Le bump mapping basique.
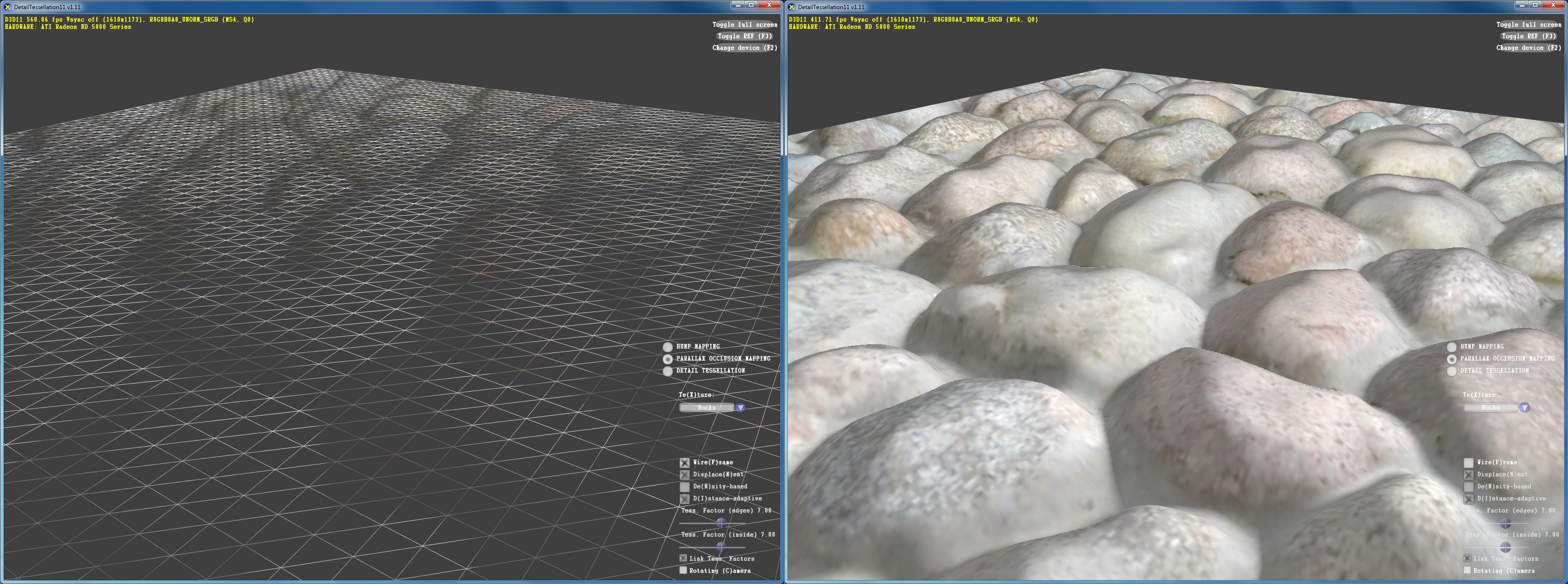
Le parallax occlusion mapping.
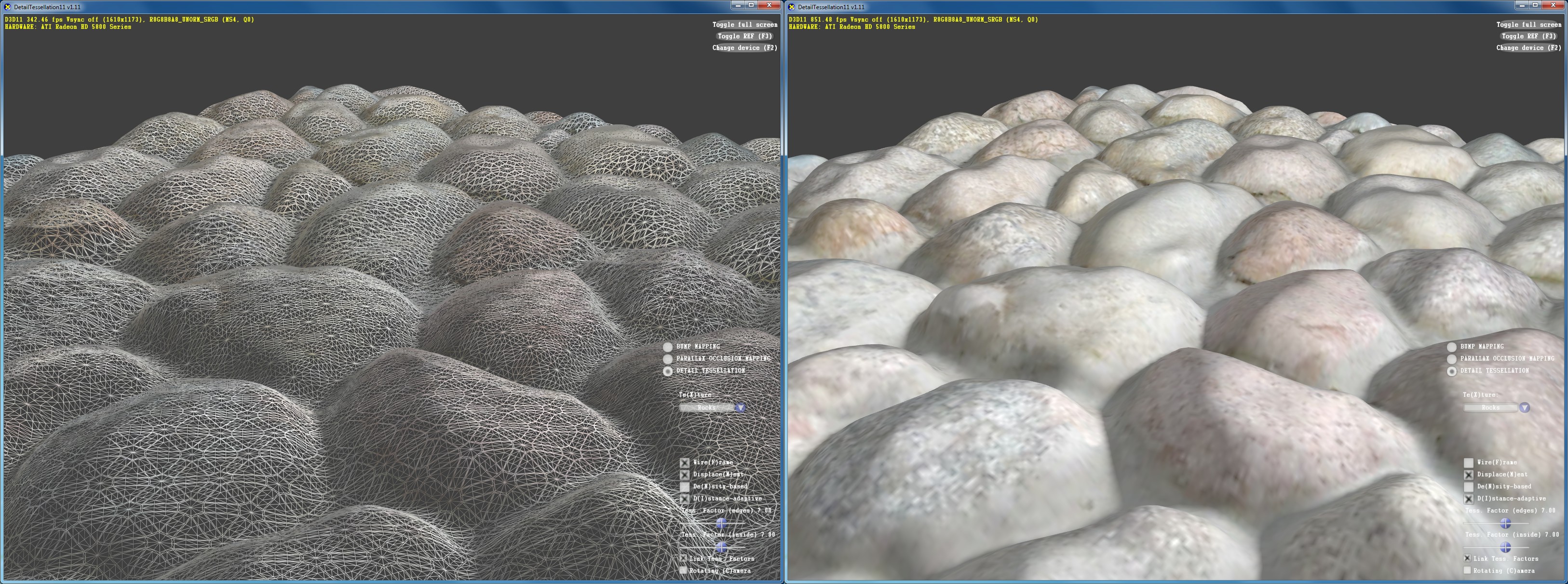
Le displacement mapping avec tessellation adaptative.
En créant de la vraie géométrie supplémentaire, le displacement mapping affiche une qualité nettement supérieure. Nous avons activé ici lalgorithme adaptatif qui permet déviter de générer de la géométrie inutile et trop de petits triangles qui ne vont pas remplir de quad et donc gâche beaucoup de ressources.
Nous avons également mesuré les performances obtenues avec les différentes techniques :
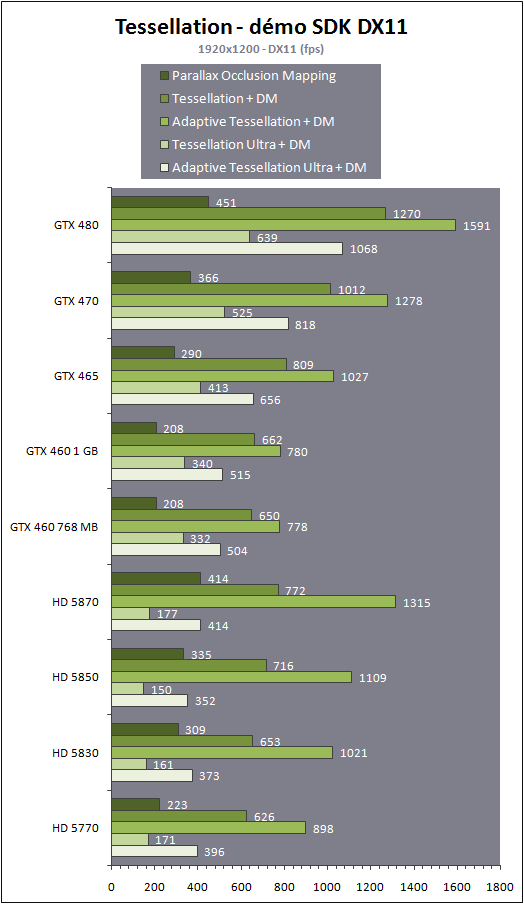
Il est intéressant de remarquer que la tessellation ne se contente pas daméliorer la qualité du rendu, mais également les performances ! Le parallax occlusion mapping est en fait très gourmand puisquil repose sur un algorithme complexe qui essaye de simuler la géométrie dune manière réaliste. Malheureusement il génère beaucoup daliasing et le trucage est démasqué aux bords des objets ou des surfaces qui lutilisent.
Notez cependant que dans le cas présent lalgorithme de displacement mapping est bien aidé par le fait quil sagit dune surface plane à la base. Sil faut lisser les contours de la géométrie et en même temps appliquer le displacement mapping, le coût sera bien entendu plus élevé.
Les GeForce GTX 400 encaissent ici beaucoup mieux la charge liée à la tessellation que les Radeon HD 5000. Avec un niveau de tessellation extrême, la GeForce GTX 460 est presque deux fois plus rapide que la Radeon HD 5870 dans ce test. Lutilisation dun algorithme adaptatif qui va réguler le niveau de tessellation suivant les zones qui vont recevoir plus ou moins de détails, suivant la distance ou encore suivant la résolution de lécran permet dans tous les cas des gains significatifs et sont plus représentatifs de ce que vont faire les développeurs. Lécart entre les GeForce et les Radeon se réduit alors, mais la GeForce GTX 400 conservent une avance significative.
Sommaire
1 - Introduction
2 - Architecture Fermi pour les joueurs
3 - Architecture (suite), spécifications
4 - Tests théoriques - pixels
5 - Tests théoriques - géométrie
6 - Les cartes
7 - Consommation, bruit
8 - Températures
9 - Overclocking, protocole de test
10 - Need for Speed Shift
11 - ArmA 2
12 - Anno 1404
2 - Architecture Fermi pour les joueurs
3 - Architecture (suite), spécifications
4 - Tests théoriques - pixels
5 - Tests théoriques - géométrie
6 - Les cartes
7 - Consommation, bruit
8 - Températures
9 - Overclocking, protocole de test
10 - Need for Speed Shift
11 - ArmA 2
12 - Anno 1404
Vos réactions
Contenus relatifs
- [+] 10/04: Nvidia : fin du support Fermi et 32...
- [+] 12/03: Nvidia lance les GeForce 800M avec ...
- [+] 08/10: Comparatif : les super GeForce GTX ...
- [+] 24/03: Nvidia répond à AMD avec la GeForce...
- [+] 17/03: Nvidia GeForce GTX 550 Ti et Asus D...
- [+] 11/03: EVGA lance une bi-GTX 460
- [+] 28/02: Nvidia annonce CUDA 4.0
- [+] 01/02: Nvidia lance une autre GeForce GT 4...
- [+] 25/01: GeForce GTX 560 Ti contre Radeon HD...
- [+] 24/01: Comparatif : 14 GeForce GTX 460 1 G...