
Reportage : IDF Automne 2007
Publié le 28/09/2007 par Damien Triolet



La programmation parallèleUn des défis majeurs lié à l'évolution des processeurs vers le multicore est la manière de programmer pour les exploiter correctement. Exploiter 2 cores ce n'est pas toujours simple, 4 encore que moins. Que dire alors de 8, 16 ou plus ? Il est donc temps de chercher, de proposer et de tester des solutions.
STMC'est ce que fait Intel avec la mémoire transactionnelle, qu'Intel invite déjà à tester via STM (software transactional memory), un nouveau compilateur beta basé sur le compilateur Intel classique et qui permet aux développeurs de commencer à jouer avec de nouvelles possibilités.
Cette mémoire transactionnelle repose en quelque sorte sur une espèce de policier qui s'assure de l'intégrité des données lorsque plusieurs cores/threads travaillent en même temps. Un problème courant est qu'un core peut vouloir accéder à une zone mémoire avant qu'un autre core y ait inscrit la donnée qu'il attend ou un core peut écraser une valeur avant qu'elle n'ait été lue par un autre. Cela rend les résultats aléatoires et cause de nombreux bugs. La solution est de bloquer (lock) le CPU autour des fonctions sensibles de manière à ce qu'un autre core/thread ne puisse pas interférer. Cela empêche le CPU de profiter de tous ses cores et l'impact est néfaste sur les performances.

La mémoire transactionnelle permet de ne bloquer que les zones mémoires sensibles, en transformant les fonctions en fonctions atomiques. Le processeur peut aller exécuter d'autres opérations, la seule contrainte étant "pas touche à ma donnée". L'avantage est évident, et ce genre d'évolution était attendue depuis longtemps, autrement dit : merci Intel ! Notez que Nvidia a intégré la même possibilité aux GeForce 8600 (elle n'était pas présente dans les GeForce 8800), vu que la programmation avec CUDA souffre des mêmes contraintes.
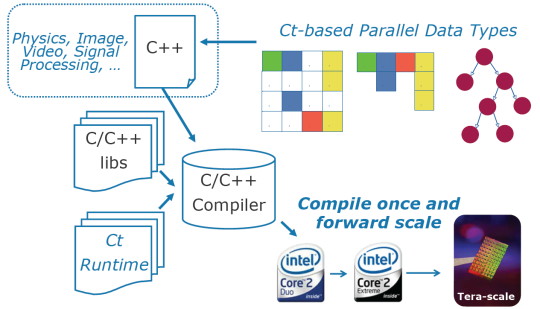
CtDeuxième point présenté par Intel : Ct. Il s'agit d'extensions au C/C++ qui permettent au développeur de mettre en place des opérations parallèles tout en restant dans une optique "série". Cela permet donc de simplifier l'exploitation des architectures parallèles, principalement via de nouveaux opérateurs et de nouveaux types de structures de données. Ce code serait ensuite traité (via un runtime) pour être adapté à l'architecture du CPU visé avant d'être envoyé vers un compilateur classique. Le but étant d'avoir un code capable d'exploiter différents types de processeurs.
ExoLe dernier point, Exo (pour accelerator exoskeleton), est lié aux accélérateurs de tout type. Bien entendu on peut y voir Larrabee et la 3D mais encore une fois cela impliquerait un développement spécial pour Larrabee que les développeurs ne sont pas encore prêts à faire.
Exo consiste à ne pas passer par un driver et/ou une API pour exploiter l'accélérateur mais simplement à inclure le code qui lui est destiné directement dans le reste du code, le compilateur se chargeant de répartir le code entre CPU et accélérateur. De quoi encore une fois simplifier le développement et mieux utiliser ces accélérateurs qui seraient ainsi exposés aux développeurs à la manière d'une unité de multimédia.
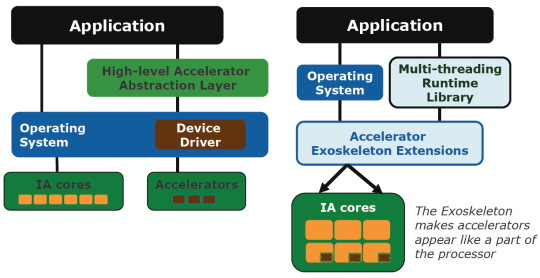
Le modèle actuel à gauche, et Exo à droite.
Ct et Exo correspondent grossièrement à ce que Nvidia fait avec CUDA. A la différence près qu'Intel résout ici le problème d'une manière générale et non pour une utilisation bien spécifique. Un travail bien plus important donc, d'autant plus que la compatibilité doit rester assurée.
Sommaire
Vos réactions
Contenus relatifs
- [+] 09/12: Guide : Les PC HardWare.fr !
- [+] 14/11: Qualcomm dit non à Broadcom
- [+] 13/11: Thermaltake lance une chaise venti...
- [+] 11/09: Microsoft confirme des problèmes de...
- [+] 30/08: PCI Express 5.0 pour 2019, débit do...
- [+] 01/08: Les taux de retour des composants (...
- [+] 11/07: Le minage consommerait plus que Par...
- [+] 04/07: ASUS XG-C100C, le 10GBASE-T à 120
- [+] 26/06: Computex et le PC : changement et c...
- [+] 24/03: Corsair lance ses PC One avec deux ...