
Preview : NVIDIA GeForce 6800 Ultra
Publié le 14/04/2004 par Damien Triolet et Marc Prieur



Les pixel pipelines : le problèmeLe problème des pixels pipelines se pose de cette manière : il faut qu´un GPU dispose d´un maximum de pixels pipelines intégrant un maximum d´unités de calcul polyvalentes, n´ayant pas de limite de registres et capables de monter en fréquence. Bien entendu il n´y a pas de solution idéale et réalisable à ce problème. Il s´agit donc de trouver le meilleur compromis par rapport à un moment donné car celui-ci évolue avec le temps.
GeForce Serie 6 : la solution ?NVIDIA a essayé d´y trouver une réponse qui soit la plus satisfaisante possible avec la nouvelle architecture qui équipera la gamme GeForce Serie 6 en faisant ses premiers pas avec la GeForce 6800 Ultra qui fait l´objet de cet article.
NVIDIA a bien compris que le nombre de pipeline était important, le nombre de pixels simples étant encore très important dans les jeux actuels et à venir prochainement. Les calculer plus rapidement n´est pas possible via des pipelines complexes, et le seul moyen est donc de disposer de plus de pipelines. Qui plus est, 2*X pipelines de complexité 1 seront toujours au moins aussi performantes que X pipelines de complexité 2. Il y a donc tout à gagner à utiliser un nombre élevé de pipelines quitte à ce qu´elles soient plus simples. Le GeForce 6800 Ultra dispose ainsi de pas moins de 16 pipelines complets arrangés en 4 groupes SIMD de 4 pipelines que nous nommerons quad pipelines.
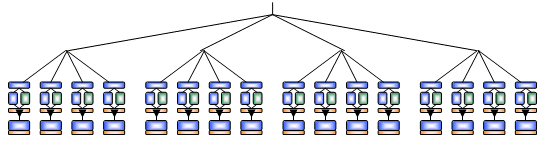
 Mais ce n´est pas tout. NVIDIA aurait pu se contenter de pipelines fortement simplifiés, mais il a décidé de mettre le paquet et de proposer un nombre important de pipelines complexes. Ils sont ainsi plus complexes encore que ceux utilisés actuellement.
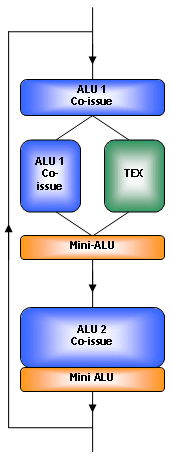
Mais ce n´est pas tout. NVIDIA aurait pu se contenter de pipelines fortement simplifiés, mais il a décidé de mettre le paquet et de proposer un nombre important de pipelines complexes. Ils sont ainsi plus complexes encore que ceux utilisés actuellement.Ils disposent toujours d´une grosse unité capable de traiter toutes les instructions y compris les instructions de texturing. Cette unité pourrait ressembler à celle des GeForce FX ... mais de loin uniquement, puisqu´elle a été entièrement revue. Cette fois elle ne peut plus piloter qu´une unité de texturing au lieu de 2 auparavant. Par contre elle peut exécuter certaines instructions en même temps que le pilotage de l´unité de texturing. Lorsqu´elle ne fait pas de texturing elle est capable d´exécuter une instruction sur les 4 composantes d´un pixel ou 2 instructions en co-issue (c´est-à-dire en 2+2 ou en 3+1 comme le co-issue d´ATI). NVIDIA a supprimé le gestion native de SINCOS de cette unité.
Selon NVIDIA cette possibilité n´était utilisée que dans des démos technologiques et n´avait donc plus sa place. NVIDIA en a profité pour la remplacer par la gestion native d´une autre instruction : NRM (pour normaliser une valeur). Cette instruction peut donc se faire "gratuitement" indépendamment du reste des opérations traitées par l´unité de calcul. La seule contrainte et que cette gestion native de NRM se limite à la version FP16.
Ensuite vient une mini-ALU semblable à celle d´ATI. Elle est donc capable de traiter les modifiers et les déplacements de données.
En 3ème position se trouve une autre grosse unité de calcul semblable à la première si ce n´est qu´elle ne peut pas piloter d´unité de texturing. Tout comme elle, elle est capable d´effectuer une instruction ou 2 instructions que se partagent les composantes. L´unité 1 et l´unité 2 peuvent fonctionner dans des modes différents. Par exemple en 3+1 pour la première et en 2+2 pour la seconde. NVIDIA appelle cette possibilité dual-issue.
Et enfin une seconde mini-ALU prend place. Les 2 mini-ALU ne peuvent réellement fonctionner que grâce à des arrangements au code apporté par le compiler intégré aux drivers. Il reste donc très important bien que dorénavant il ne servira plus à courir derrière les performances mais bien à en offrir plus en bonus. La différence est subtile mais importante à noter.
Sommaire
Vos réactions
Contenus relatifs
- [+] 04/05: Nvidia abandonne son GeForce Partne...
- [+] 27/04: AMD Vega 7nm en labo, Zen 2 échanti...
- [+] 18/04: ASUS AREZ, l'effet GeForce Partner ...
- [+] 10/04: Nvidia : fin du support Fermi et 32...
- [+] 27/03: Pilotes Radeon et GeForce pour Far ...
- [+] 20/03: Pilotes GeForce 391.24 pour Sea of ...
- [+] 20/03: Microsoft annonce DirectX Raytracin...
- [+] 20/03: Radeon Software 18.3.3 beta avec Vu...
- [+] 08/03: 3 millions de GPU vendus pour le mi...
- [+] 08/03: Radeon Software 18.3.1 optimisé pou...