
Actualités informatiques du 25-03-2014
- GTC: Tegra: Kit Jetson TK1, SoC Erista en 2015
- GTC: GeForce GTX Titan Z, 3000$, bi-GK110 en avril
- GTC: Nvidia annonce Pascal: NVLink, stacked DRAM, 2016
- Corsair lance l'Obsidian 450D
- GDC: Nvidia met en avant son pilote Direct3D 11
| Mars 2014 | ||||||
|---|---|---|---|---|---|---|
| L | M | M | J | V | S | D |
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 | ||||||
GTC: Tegra: Kit Jetson TK1, SoC Erista en 2015



L'intégration d'un GPU Kepler dans le SoC Tegra K1 lui permet de débarquer dans l'univers de CUDA et du calcul massivement parallèle. Avec la plateforme Kayla annoncée l'an passé, Nvidia avait clairement annoncé la couleur et son ambition d'amener CUDA dans le monde de l'embarqué.

La version finale de cette initiative se nomme Jetson TK1 et correspond à un kit de développement articulé autour du SoC Tegra K1 et de son GPU qui propose 192 unités de calcul FMA 32-bit pour une puissance de calcul de 326 Gflops. Nvidia ne précise pas de quelle version du Tegra K1 il s'agit, mais nous pouvons supposer qu'il est question de la v1, qui repose sur des cores Cortex-A15, et que la v2 équipée de 2 cores Denver ARMv8 ne viendra que plus tard.

Cette plateforme intègre 2 Go de mémoire, de l'USB 3.0, du HDMI 1.4, du Gigabit Ethernet, de l'audio, du SATA, du mini-PCIe et un emplacement pour carte SD. Notez qu'en pratique un ventirad est placé sur le SoC, mais il était absent des photos officielles et de l'échantillon présenté lors de la keynote.
De quoi proposer un kit de développement relativement polyvalent et potentiellement ouvrir de nouvelles portes à Nvidia dans l'embarqué, principalement pour des solutions mobiles, compactes et/ou peu gourmandes. Ce kit Jetson K1 sera disponible sous peu (il est en précommande à partir de ce jour) à un tarif de 192$. En Europe, il sera distribué par Zotac, SECO et Avionic Design.
Comme d'habitude, le passage Tegra de la keynote principale de GTC a été l'occasion pour le CEO de Nvidia de présenter une roadmap mise à jour :
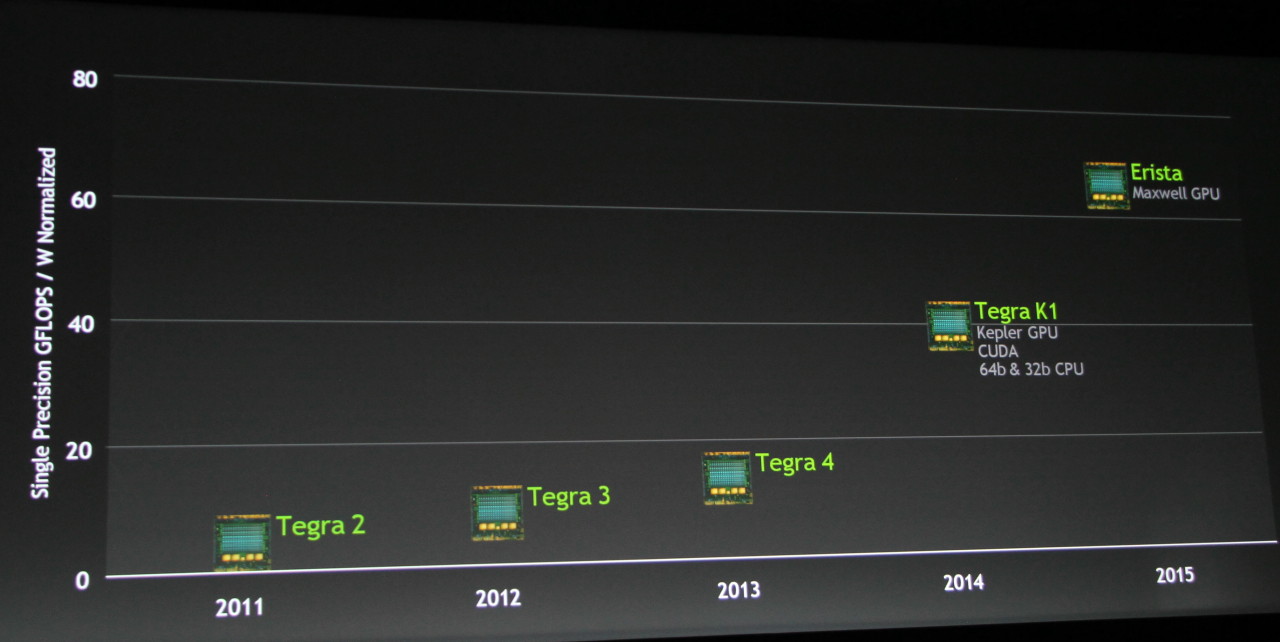
Nous n'apprendrons cependant que très peu de détails si ce n'est que le prochain SoC Tegra, qui succèdera au Tegra K1 (nom de code Logan), intégrera un GPU Maxwell, augmentera le rendement énergétique d'un peu plus de 50% et se prénommera Erista. Encore une fois il s'agit d'une référence aux superhéros de l'univers Marvel puisque Erista y représente le fils de Logan, alias Wolverine. A voir s'il disposera également de quelques pouvoirs
Tout comme pour le GPU Volta, le SoC Parker, annoncé l'an passé par Nvidia, a été repoussé et Erista est une solution intermédiaire. Parker était pour rappel prévu pour 2015 avec un GPU Maxwell, des cores Denver et l'exploitation d'un procédé de fabrication à base de FinFET. Nous ne savons pas à l'heure actuelle quelle est la différence entre ce le projet Parker et ce nouveau projet Erista.
GTC: GeForce GTX Titan Z, 3000$, bi-GK110 en avril

Nvidia profite de la GTC pour annoncer la GeForce GTX Titan Z. Le fabricant explique avoir été surpris par le succès des GeForce GTX Titan et GTX Titan Black, malgré leur tarif de 1000$ / 1000, autant auprès des joueurs (fortunés) qu'auprès des amateurs de GPU computing qui ont besoin d'un maximum de puissance de calcul mais ne désirent pas investir dans des cartes Quadro ou Tesla. Dans ce cas, les GeForce GTX Titan s'intercalent ainsi assez bien entre les GeForce classiques et les cartes professionnelles.
Nvidia retente l'expérience avec la GeForce GTX Titan Z qui reprend le principe des cartes GTX Titan précédentes mais passe au bi-GPU. Elle est équipée de 2 GPU GK110 totalement fonctionnels pour un total de 5760 unités de calcul FMA 32-bit et 1920 unités de calcul FMA 64-bit. De quoi atteindre une puissance de calcul de 8 Tflops en simple précision. Chaque GPU dispose de sa propre mémoire de 6 Go interfacée en 384-bit et le système de refroidissement reprend le design haut de gamme cher à la marque. Il a cependant été quelque peu musclé pour l'occasion et semble passer de 2 à 2.5 slots d'épaisseur.

Par rapport à une GeForce GTX 690 en bi-GK104 (300W), le TDP a vraisemblablement dû être revu à la hausse mais Nvidia ne donne pas de précision à ce sujet. 350W ? 400W ? Nous ne devrions pas tarder à en savoir plus puisque la disponibilité est annoncée pour début avril avec un tarif de 3000$ ! Il s'agit d'un nouveau record pour une carte non-issue d'une gamme professionnelle et nous sommes curieux de savoir si cette GeForce GTX Titan Z pourra réellement trouver son public, aussi réduit soit-il...
GTC: Nvidia annonce Pascal: NVLink, stacked DRAM, 2016
Le forum technologique GTC de Nvidia commence fort avec l'annonce du successeur de Maxwell. Prénommé Pascal et prévu pour 2016, ce GPU intégrera une nouvelle technologie d'interconnexion, NVLink, ainsi que le support de la mémoire 3D.

Jen Hsun Huang, le CEO de Nvidia présente le premier prototype du GPU Pascal.
L'an passé, Nvidia nous avait présenté une roadmap qui mettait en avant l'arrivée des GPU Maxwell en 2014, nous y sommes, ainsi que des GPU Volta en 2016. Pour Maxwell, Nvidia mentionnait alors le support de la mémoire unifiée et pour Volta de la mémoire 3D ou stacked DRAM, qui consiste à empiler plusieurs puces mémoire pour former un module dont la bande passante va exploser.
A noter que dans ces présentations, le nom de l'architecture ou de la génération représente toujours le plus gros GPU de la famille. La nouvelle roadmap de Nvidia est quelque peu différente :

DirectX 12 est rentré dans l'air du temps et dorénavant mis en avant comme le point de communication principal pour la génération Maxwell. Etrangement la mémoire unifiée passe vers la génération suivante qui change de nom. Exit Alessandro Volta, bonjour Blaise Pascal. La génération Volta a en réalité été repoussée et une génération intermédiaire introduite. Avec Pascal, Nvidia entend s'attaquer aux goulets d'étranglements des GPU actuels, au moins sur 2 fronts.

Tout comme cela était mis en avant pour Volta, Pascal bénéficie du DRAM stacking pour faire exploser la bande passante de sa mémoire locale. Nvidia précise avoir recours à la technique "3D chip-on-wafer integration" et estimer pouvoir atteindre une bande passante de 1 To par seconde en 2016. La quantité de mémoire pourra également progresser significativement, il est question de 2.5x plus de mémoire qu'aujourd'hui, soit probablement 10 Go dans le cas des GeForce et près de 30 Go dans le cas des cartes professionnelles. Tout ceci se ferait avec une progression de 4x de l'efficacité énergétique liée à la mémoire et à son interface.

L'autre point sur lequel Nvidia travaille pour Pascal est l'interconnexion. Le bus PCI Express représente une limitation importante au niveau de la communication avec le CPU et entre GPU. Dans le cas d'une utilisation grand public, ce n'est pas un problème, mais cela peut le devenir dans d'autres situations liées au GPU computing.
Pour contourner ce problème et avoir le contrôle de sa propre interconnexion, Nvidia a mis au point NVLink. Il s'agit d'un bus de communication dont les protocoles sont annoncés similaires à ceux du PCI Express, prévus pour la mémoire unifiée et la cohérence des caches dès la génération 2.0, probablement pour le successeur de Pascal. NVLink pourra offrir 5 à 12X la bande passante du PCI Express, probablement avec une latence réduite. Dans un sens, NVLink peut être vu commme une version musclée et plus flexible du lien SLI.
NVLink pourra être implémenté pour la communication entre GPU, le schéma de Nvidia indique qu'au moins 4 GPU pourront ainsi disposer d'une connexion directe. Il sera également possible d'utiliser NVLink pour offrir au GPU un accès plus performant au CPU. Nvidia précise d'ailleurs avoir collaboré avec IBM lors du développement du NVLink et que ce dernier sera implémenté dans de futurs CPU POWER. Nous pouvons également raisonnablement estimer que Nvidia proposera ce support sur ses futurs SoC/CPU dérivés de ses propres cores ARMv8 Denver. Il est par contre improbable qu'Intel propose un jour une connexion NVLink sur ses Xeon.

Pour terminer, Nvidia indique déjà disposer dans ses labos des premiers prototypes de Pascal. Une plateforme relativement compacte dont nous ne savons cependant pas si elle est réellement fonctionnelle. Nous pouvons y apercevoir 4 modules de stacked DRAM et Nvidia précise que cette carte Pascal lui permet de travailler sur NVLink. Sur la face avant du PCB, aucune interconnexion n'est cependant visible, celle-ci étant probablement au dos. Rien ne dit cependant que c'est ce format qui sera retenu pour la version commerciale de Pascal.
La guerre s'annonce rude entre Pascal et les futurs Xeon Phi !
Corsair lance l'Obsidian 450D
Après des modèles Micro-ATX (Obsidian 350D) et grande tour (Obsidian 750D), Corsair lance un boitier moyen tour dans sa gamme Obsidian, le 450D. Mesurant 49.4cm x 21 x 49.7cm (L x l x H) pour un poids de 7 Kg, le boitier reprend le look des derniers modèles de la gamme dans une version plus compacte. On retrouvera à l'extérieur deux ports USB 3.0 en façade et deux baies 5.25 pouces disponibles.

A l'intérieur on retrouvera une cage amovible pour trois disques durs pouvant recevoir à la fois des disques 3.5 pouces et 2.5 pouces. Le constructeur propose également deux slots horizontaux à l'arrière de la plaque de fixation de la carte mère pour y fixer deux SSD.

Côté ventilation, on retrouvera en façade deux ventilateurs AF140L (140mm) et un AF120L à l'arrière, le boitier pouvant accueillir jusque huit ventilateurs en tout (trois 120mm ou deux 140mm en haut et deux 120mm en bas). Les filtres à poussières en haut, à l'avant et en bas du boitier sont également présents sur ce modèle. La disponibilité est annoncée pour le mois d'avril pour 119 dollars outre atlantique.
GDC: Nvidia met en avant son pilote Direct3D 11
Durant la GDC, Nvidia n'a pas seulement parlé de Direct3D 12 mais a également tenu à revenir sur le travail qui a été fait au niveau de son pilote Direct3D 11, de manière à réduire autant que possible le coût de la gestion des commandes de rendu. Nvidia estime qu'il disposait depuis longtemps d'un petit avantage sur ce point par rapport à la concurrence et l'annonce de Mantle l'a incité à aller plus loin dans ce sens.
Ses ingénieurs ont ainsi mis les bouchées doubles pour réduire le coût de plusieurs fonctions de Direct3D 11 mais également pour peaufiner l'implémentation des "deferred contexts". Pour rappel, ceux-ci permettent aux développeurs d'implémenter un support du multi-threading au niveau de la préparation des commandes de rendu. Malheureusement, ils sont peu efficaces et difficiles à implémenter compte tenu des interactions hors de contrôle entre l'application, l'API et les pilotes.

Nvidia a cependant estimé qu'il y avait moyen de mieux faire. Sa première implémentation des "deferred contexts" était très sommaire mais fonctionnelle et un peu plus performante que l'émulation proposée directement par l'API en cas de non intégration dans les pilotes comme cela serait le cas du côté d'AMD. Même si l'implémentation de Nvidia restait supérieure, ses résultats n'étaient pas très enthousiasmants pour les développeurs, ce qui explique la mauvaise réputation de cette fonctionnalité de Direct3D 11 auprès des développeurs. La deuxième implémentation de Nvidia serait par contre nettement plus efficace et rendrait la fonctionnalité enfin réellement bénéfique, si bien entendu les développeurs y font appel.
Nvidia nous a présenté quelques slides qui mettent en avant des gains observés en interne, autrement dit à prendre avec des pincettes même si la tendance affichée est probablement réaliste :
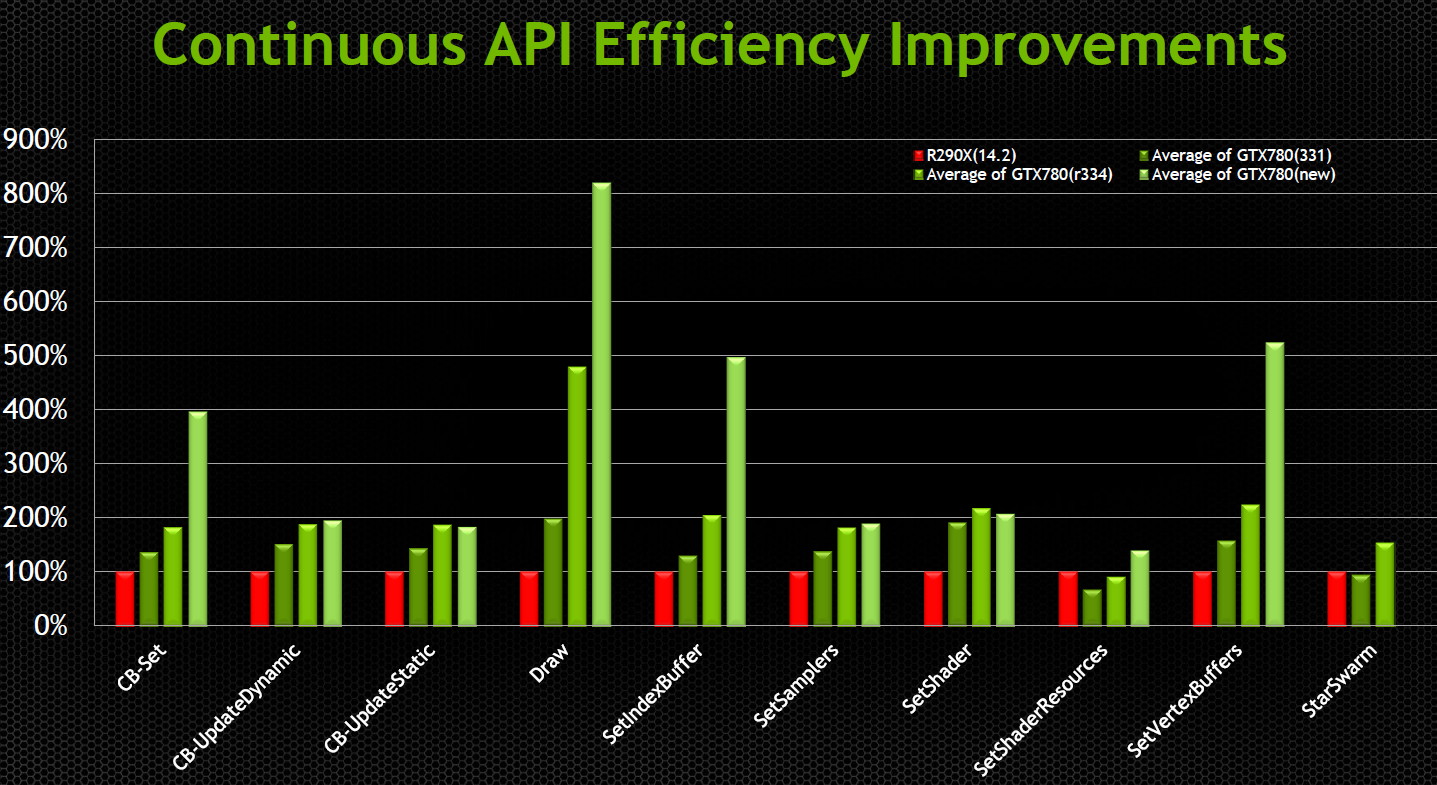
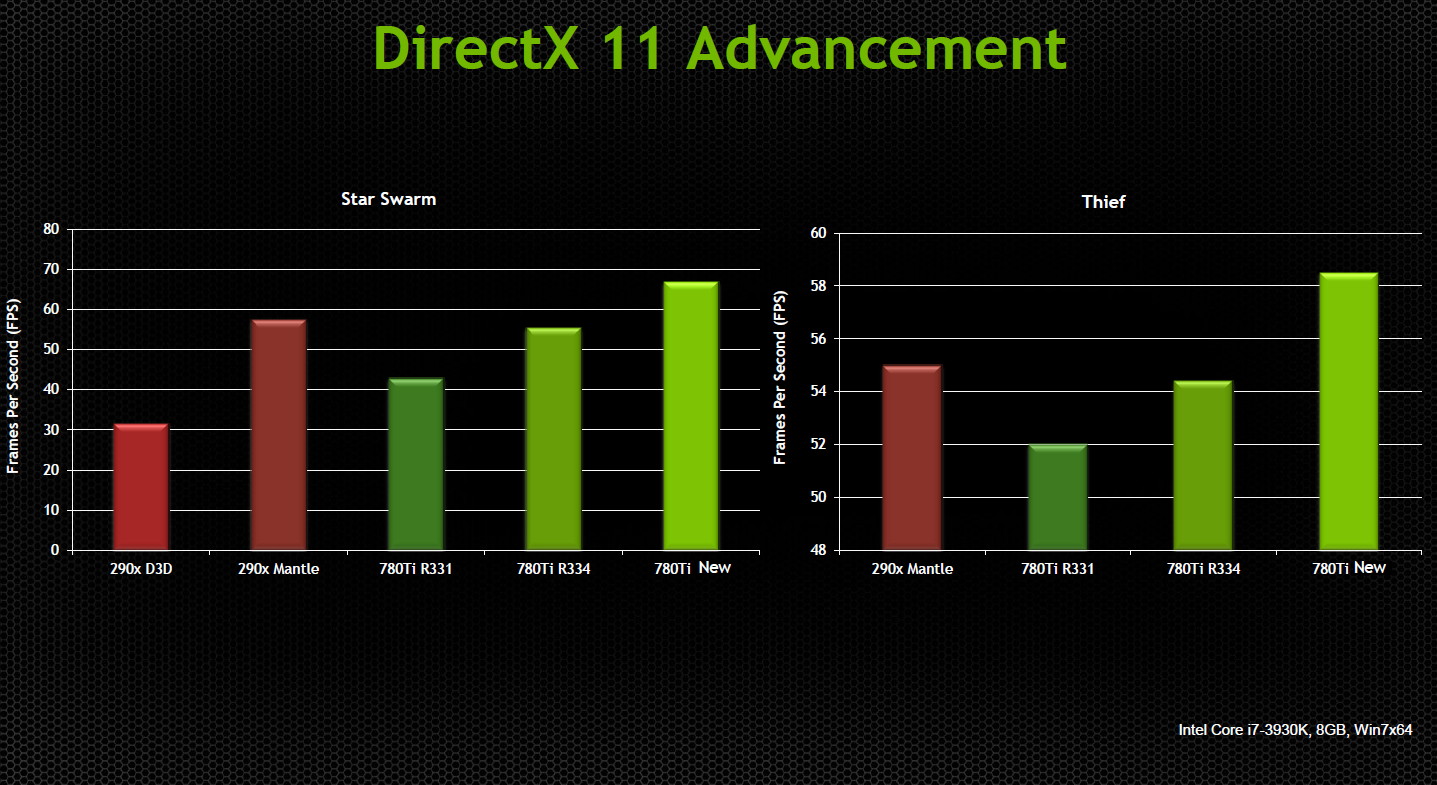
Ces slides comparent les pilotes Catalyst 14.2 aux pilotes r331, r334 ainsi qu'à une nouvelle version de ses pilotes qui ne devrait plus tarder à sortir (r336 ?). Suite à ces différentes évolutions, Nvidia met en avant des réductions du coût CPU de plusieurs fonctions de D3D11 de l'ordre de 2x, 4x, 5x, voire 8x dans le cas le plus favorable.
Avec ces gains associés à l'amélioration du support des "deferred contexts", Nvidia estime pouvoir même surpasser la solution d'AMD en version Mantle dans Star Swarm et Thief. Bien entendu il s'agit probablement ici de cas très favorables plus que de moyennes représentatives, mais force est de constater que Nvidia a entrepris un réel effort au niveau de ses pilotes Direct3D 11. Mantle aura décidemment été bénéfique pour tous !