
Actualités informatiques du 23-04-2014
- 16-FinFET plus et 10nm chez TSMC
- GPU AMD 20nm en 2014 ou 2015 ?
- Flash en 15nm pour Toshiba et SanDisk
- Celeron N2830 pour le NUC DN2820FYKH (MAJ)
- VESA DSC: transfert d'images compressées vers l'écran
| Avril 2014 | ||||||
|---|---|---|---|---|---|---|
| L | M | M | J | V | S | D |
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | ||||
16-FinFET plus et 10nm chez TSMC



Lors de sa conférence concernant ses résultats financiers, TSMC a donné quelques détails sur ses process de fabrication courants et à venir.
Pour le 20nm tout d'abord, TSMC a confirmé que la production du 20-SoC a bel et bien commencé en janvier. La société a cependant indiqué que le ramp up du process aura été le plus rapide de son histoire sous entendant des yields un peu en avance sur les prévisions, sans plus de détails. La question du coût des wafers est toujours un point important pour les clients du fabricant, le 20nm engendrant une augmentation assez importante de par l'usage du double patterning. Les estimations du cout des wafers chez TSMC parlent d'environ 2200-2600$ pour le 28nm, le 20nm ajoutant un surcout de plus de 20% par wafer (sans prendre en compte les différences de yields qui augmentent significativement la différence sur le cout final par puce fonctionnelle). Pour l'instant, le 20nm n'entre pas encore dans les revenus financiers de TSMC mais devrait entrer pour une petite partie au prochain trimestre.
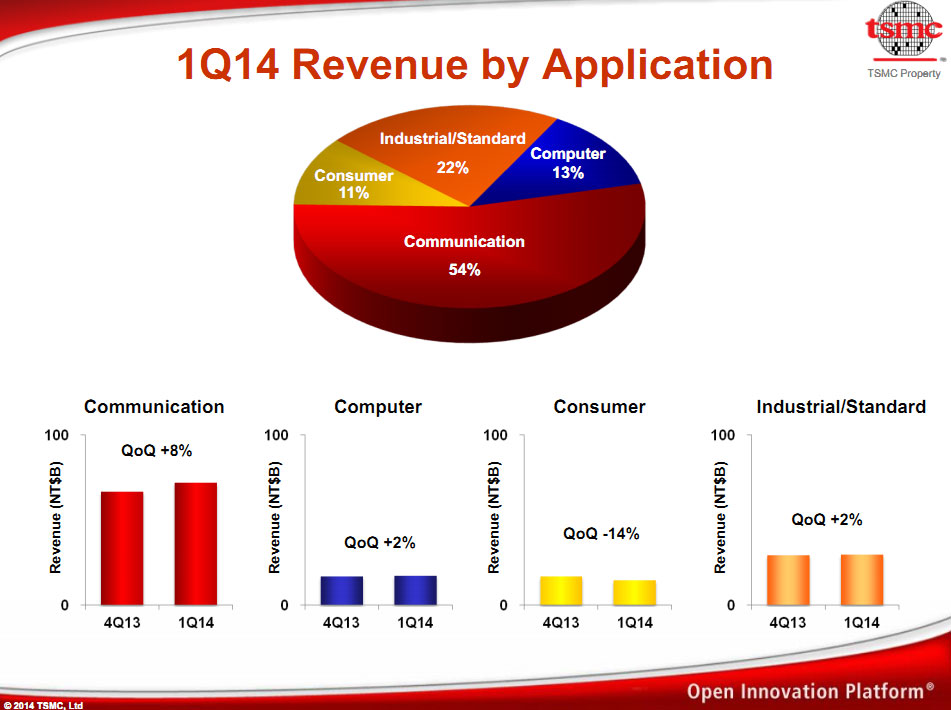
L'importance des SoC/modems pour smartphones dans les revenus de TSMC (colonne « Communication ») est assez facilement illustrée par ce graphique, par rapport aux revenus informatiques et GPU que l'on retrouve dans la colonne « Computer ».
Concernant le 16nm, le constructeur a annoncé une seconde version de son process. En sus du 16-FinFET déjà annoncé et censé entrer en production en février prochain, TSMC annonce une version « plus » de son process. Il s'agira en quelque sorte d'une version optimisée du 16nm basé sur des optimisations non dévoilées, les règles de design restant les mêmes entre le 16-FinFET et le 16-FinFET plus. La stratégie n'est pas très différente de ce que proposeront Samsung et GlobalFoundries sur ce point avec le 14LPE et le 14LPP qui sera proposé dans un second temps.
Contrairement à Samsung, TSMC livre quelques chiffres sur son process 16-FinFET plus qui apportera, par rapport à la première version, un gain au choix de 15% de vitesse à consommation égale, ou de 30% de gain de consommation à vitesse égale. Des gains qui sont loin d'être négligeables. Côté timing, le constructeur évoque une qualification de son process en septembre de cette année suivis de quelques « tape-outs » (15 en 2014) et une production en volume « courant » 2015.
TSMC a également parlé de son process 10nm, baptisé 10-FinFET, indiquant qu'il est en cours de développement. Le 10-FinFET est qualifié de troisième génération de FinFET par la société sans plus de détails. Quelques chiffres ont été livrés comparant au 16-FinFET plus avec une amélioration de la densité de 2.2x, et 25% de vitesse à consommation égale, ou 45% de gain de consommation à vitesse égale. D'un point de vue implémentation technique, le seul détail donné concerne l'EUV (une source lumineuse avec une longueur d'onde de 13nm, contrairement aux actuelles sources 193nm) qui, sans trop de surprise, ne sera toujours pas prêt pour le 10nm. TSMC laisse la porte ouverte pour l'utilisation de l'EUV plus tard dans la vie du process. TSMC devrait donc utiliser d'une manière plus forte le multiple patterning, augmentant potentiellement les couts. Un point sur lequel il est pour l'instant un peu trop tôt pour se prononcer.
GPU AMD 20nm en 2014 ou 2015 ?
Alors qu'on attendait l'arrivée de GPU 20nm au cours du second semestre, Lisa Su (SVP et General Manager de la division Global Business Units d'AMD) a donné quelques précisions sur l'arrivée de cette nouvelle finesse de gravure au sein des produits AMD lors de la séquence de questions/réponses :
« So what we've said in the past is certainly this year all of our products are in 28-nanometer across both, you know, graphics client and our semi-custom business. We are, you know, actively in the design phase for 20-nanometer and that will come to production. And then clearly we'll go to FinFET. »A la question d'un analyste sur les process, Lisa Su indique que pour cette année 2014 les GPU sont en 28nm alors que les puces 20nm sont actuellement en cours de mise au point.

Une position réaffirmée lorsqu'un autre analyste financier a clairement demandé s'il y aurait un GPU 20nm cette année ou si il fallait attendre l'année prochaine :
« we are 28 this year, we have 20-nanometer in design, and then FinFET thereafter. »La réponse n'est pas claire concernant le 20nm, et on peut en déduire qu'il ne faut pas s'attendre à l'arrivée de GPU 20nm en volume chez AMD cette année, alors que le Radeon HD 7970 en 28nm est arrivée en janvier 2012, deux ans et demi après le Radeon HD 4770 lancé en avril 2009.
Si l'absence de GPU 20nm, au moins chez AMD, en 2014 venait à se confirmer c'est probablement du côté de TSMC qu'il faut en chercher la cause. Même si la production a débuté en janvier, c'est surtout au cours du second semestre que le volume sera là. Comme l'indique le nom du process, 20SoC, les GPU ne semblent plus avoir la primeur chez TSMC et la bataille est rude pour réserver les capacités de production entre tous les fabricants de GPU d'une part et les fabricants de SoC d'autre part.
Flash en 15nm pour Toshiba et SanDisk
Toshiba et Sandisk, associés au sein de la joint-venture Flash Forward, viennent d'annoncer qu'ils allaient débuter la fabrication de NAND Flash en 15nm dès la fin du mois d'avril. Il s'agit en l'occurrence d'une puce de 128 Gbits en MLC, mais le process sera ensuite utilisé à compter de juin sur une puce TLC (3 bits par cellule).

La taille de la puce n'est toutefois pas indiquée, pour rappel les premières puces de Toshiba / Sandisk en 19nm avaient en fait des cellules de 19nmx26nm contre 20nmx20nm chez Micron et 19x19.5nm pour la dernière génération de cellules Toshiba / Sandisk (A19nm). Reste que du fait d'une partie de la puce Flash destinée aux cellules mémoire plus importantes, les puces 64 Gbits 19nm et A19nm mesurent respectivement 113mm² et 94mm², contre 118mm² pour une puce 64 Gbits 20nm de Micron.
Des puces en MLC en 16nm ont été annoncées en 2013 chez Micron et SK Hynix, mais elles n'ont pas encore fait leur apparition dans des SSD et tout comme pour ces 15nm la surface des puces n'est pas communiquée. Il faut rappeler qu'à terme la diminution de la finesse de gravure va permettre de faire baisser le coût de production au Go, avec toutefois des problématiques accrues au niveau de l'endurance des cellules Flash.
Celeron N2830 pour le NUC DN2820FYKH (MAJ)
Le marché des PC petit format est en croissance et Intel s'en taille une belle part avec ses NUC, malgré la présence d'autres acteurs actifs tels que Gigabyte ou encore historiques comme Shuttle ou Zotac.

L'une des références les plus courues ces derniers temps est le DN2820FYKH, qui a souffert du fait de son succès d'une rupture de stock de près d'un mois. Il est basé sur un processeur Intel Celeron N2820, un Bay Trail dual core utilisant l'architecture Silvermont dont la fréquence varie entre 2,13 et 2,39 GHz, contre 313 à 756 MHz pour la partie graphique, le tout dans un TDP de 7,5 watts seulement. De quoi se faire un HTPC abordable par exemple, même si on notera l'absence de support de l'audio HD en bistream sous Windows (mais cela fonctionne sous OpenELEC).
Intel vient de mettre à jour les spécifications techniques de la carte mère intégrée dans ce NUC afin de préciser qu'elle pourra désormais être accompagnée soit d'un Intel Celeron N2820 de stepping B3, soit d'un Intel Celeron N2830 de stepping C0. Ce nouveau stepping améliore notamment la gestion de l'USB 3 en sortie de veille et permet de disposer d'une intensité plus importante sur l'USB 2 pour le chargement de périphériques.
Intel en profite au passage pour activer le support de la DDR3L-1333 sur le N2830 alors que le N2820 se limitait à la DDR3L-1066, alors que le Quick Sync, un encodage H.264 matériel, est désormais supporté. Il est à ce sujet difficile de savoir d'où venait l'absence de prise en charge de Quick Sync sur le N2820, puisque le Celeron J1800 qui est également un Bay Trail le supporte alors qu'il existe en stepping B3 comme C0. Les spécifications officielles font également état de quelques petites variations au niveau fréquence, avec désormais 2.16 à 2.41 GHz pour le CPU et 313 à 750 MHz pour l'iGPU.
Voilà donc des apports intéressants pour cette nouvelle version du DN2820FYKH, mais on ne peut que regretter qu'Intel n'ai pas pris la peine de changer la dénomination du produit afin de permettre aux acquéreurs de savoir ce qu'ils achètent !
Mise à jour du 23/04/2014 : A défaut de changement de nom du produit, il sera possible de savoir si il est équipé d'un N2830 avec le numéro de version qui se trouve sur l'étiquette de la boite (en bas de celle-ci, à droite de la date de fabrication). Il passe ainsi de H22962-xxx pour les versions en N2820 à H24582-xxx pour celles en N2830.
VESA DSC: transfert d'images compressées vers l'écran
VESA et MIPI viennent d'annoncer la finalisation et l'adoption de la technologie de compression DSC, un nouveau standard destiné à faire face au challenge grandissant que représente le transfert vers les écrans de flux d'images en résolutions 4K et 8K. La solution passe par la compression.
Les résolutions d'affichage sont en progression constante avec les formats UHD 4K, et bientôt 8K, qui poussent les débits toujours plus haut, à respectivement 13 Gbps et 50 Gbps en 60 Hz. De quoi poser des problèmes en termes de connectique adaptée (le DisplayPort 1.2 plafonne à 17 Gbps utiles, le futur DP 1.3 à +/- 26 Gbps), de taille des buffers pour les écrans et de consommation, ce dernier point étant particulièrement important pour les périphériques mobiles. Sans solution technique idéale à l'horizon, le standard DSC, pour Display Stream Compression, propose d'avoir recours à la compression du flux vidéo destiné à l'affichage.
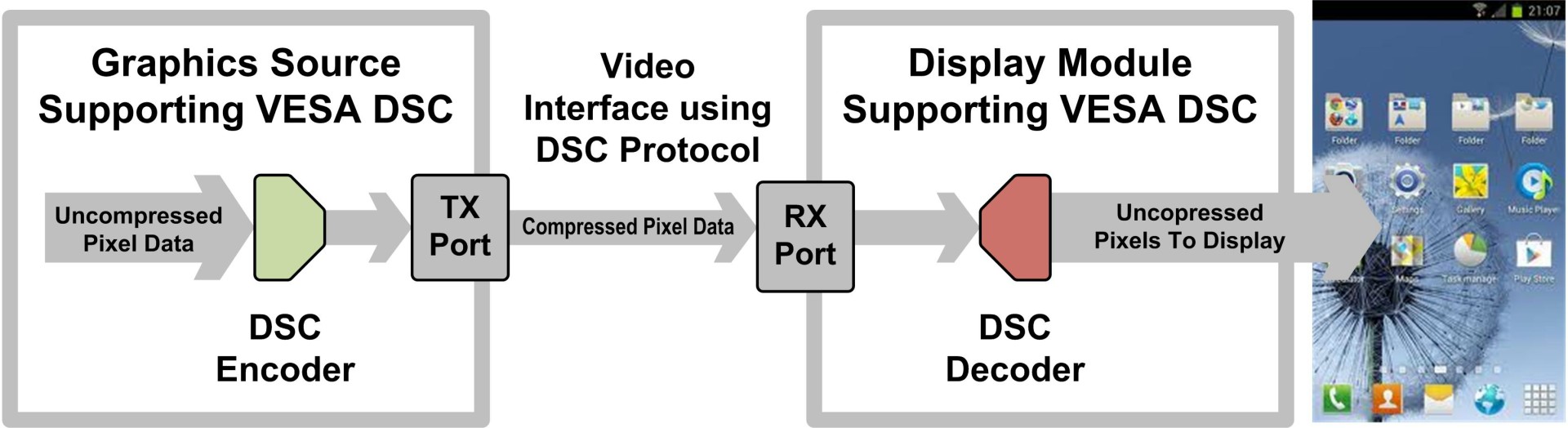
Une approche qui n'est pas aussi simple qu'il n'y paraît. Pourquoi ne pas simplement transférer un flux H.264 vers l'écran ? Pour plusieurs raisons, les plus importantes étant la qualité insuffisante, le débit variable et la complexité trop élevée de l'encodage et du décodage. Les interfaces tant au niveau de l'envoi du flux vidéo que de sa réception doivent rester aussi simples que possible pour des raisons de coûts mais également pour ne pas annuler les gains en consommation.
A noter qu'en pratique, dans le cas de l'affichage d'une vidéo H.264 ou H.265, cela veut donc dire qu'elle sera décodée, traitée, réencodée en DSC, transférée à l'écran via une connectique standard et enfin décodée à nouveau en vue de l'affichage. Nous pouvons supposer qu'à terme, pour ces cas particuliers, une évolution logique sera de rendre possible de transférer directement le flux original aux écrans.
Pour le DSC, VESA indique avoir dû opter pour un compromis qui permette d'obtenir un rendu sans perte apparente (visually lossless) jusqu'à un résultat de 8 bits par pixel, un débit constant après compression, la possibilité de ne mettre à jour que des parties de l'image, le support de différents formats vidéo, un faible coût d'implémentation et la possibilité de supporter le décodage sur base d'anciennes technologies.
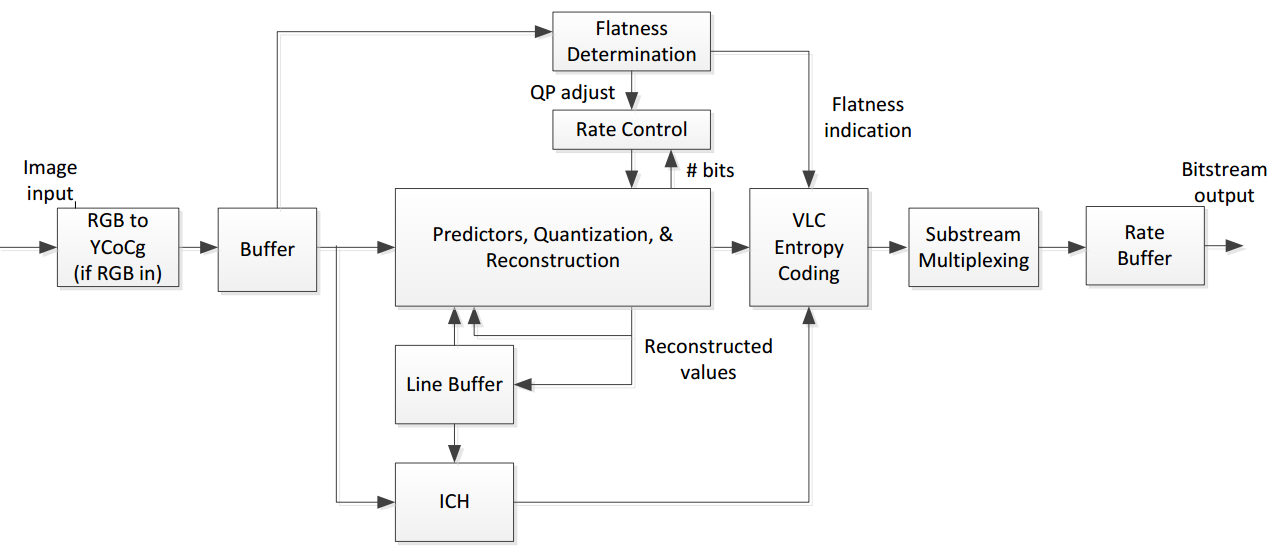
Schéma de l'encodeur DSC
L'algorithme retenu travaille sur base d'une seule ligne de pixels et est annoncé capable de réduire le débit par 3 dans sa version 1.0. A sa base, un moteur d'encodage DPCM (differential pulse-code modulation) avec buffer ICH (indexed color history), un codeur entropique et, en sortie, un buffer destiné à garantir le débit fixe. Le niveau de remplissage de ce dernier déterminera les paramètres qui régissent la qualité de la compression. Vous pourrez retrouver quelques détails de plus dans le whitepaper qui a été rendu public par VESA .
A noter en ce qui concerne la capacité de compression, que le support d'un des 3 modes de prédiction du DSC (par blocs) sera optionnel au niveau du décodeur. Cette information sera transmise au moteur d'affichage avec les autres informations liées à l'écran ou à la dalle. De quoi autoriser des contrôleurs plus simples pour les panneaux d'affichage mais avec un niveau de qualité ou de compression plus faible. Les écrans pourront ainsi être amenés à se différencier sur la qualité même de l'image.
Parmi les détails techniques, il y en a un qui n'est pas abordé : la latence d'affichage et son augmentation supposée. Cette hausse pourrait être insignifiante mais elle pourrait également être gênante dans le cadre du jeu vidéo. Là aussi, les contrôleurs et les écrans devraient pouvoir se différencier avec des décodeurs suffisamment rapides pour que le tout soit indolore dans le cas des "bons" écrans PC.
Le DSC est adopté conjointement par VESA et MIPI, organisme chargé de la définition de standards divers et variés liés au monde mobile. Le DSC pourra ainsi être utilisé à travers l'eDP 1.4 (embedded DisplayPort de VESA) et le DSI 1.2 (Display Serial Interface de MIPI). Dans un premier temps, les smartphones, tablettes et ordinateurs portables seront donc la cible principale, mais VESA précise que les écrans externes ne seront pas oubliés. Nous pouvons donc supposer que le DSC sera supporté à partir du futur DisplayPort 1.3.
A noter que d'autres initiatives dans ce sens ont été engagées dans l'industrie mais avec des résultats mitigés soit au niveau de la qualité soit au niveau de l'adoption suite à un format propriétaire. Qualcomm a par exemple mis au point une telle approche, qui était en démonstration au CES. A termes, si la compression DSC tient ses promesses de qualité, nous pouvons supposer que l'ensemble de l'industrie se concentrera sur ce format dont l'utilisation est gratuite pour les membres VESA et représente un coût négligeable pour les autres (350$).