
Actualités informatiques du 23-02-2015
- La HBM 128 Go /s fait bien 1 Go, quid d'AMD Fiji ? MAJ
- Intel densifie sa SRAM 14nm et parle du 10 et 7nm
| Février 2015 | ||||||
|---|---|---|---|---|---|---|
| L | M | M | J | V | S | D |
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | |
La HBM 128 Go /s fait bien 1 Go, quid d'AMD Fiji ? MAJ



Ce contenu a été actualisé le 23/02/2015 après une première publication le 20/02/2015
Depuis le troisième trimestre 2014, le catalogue mémoire SK Hynix fait mention de mémoire HBM (High Bandwith Memory). La dernière version de ce catalogue corrige une erreur qui était présente jusqu'alors, la capacité de cette puce HBM est bien de 1 Go et non 1 Gb (soit 128 Mo).

Pour rappel ce type de mémoire est composé d'un die logique de contrôleurs mémoire ainsi que de multiples dies de mémoire, ici 4, le tout étant relié les uns aux autres par des TSV (Through Silicon Vias), littéralement de petits trous dans les puces pour laisser passer des fils afin de connecter les dies entre eux.
L'avantage de la HBM se situe au niveau de la bande passante sur une même puce du fait d'un bus externe très large de 1024-bit. Malgré une vitesse de seulement 1 GT/s, cela permet à la H5VR8GESM4R-20C d'atteindre 128 Go /s. A titre de comparaison, une puce GDDR5 à 8 GT/s en 32-bit atteint 32 Go /s, mais sur les cartes graphiques plusieurs puces sont adressées en parallèle sur un bus de 128 à 512-bit, ce qui permet d'atteindre en théorie jusqu'à 512 Go /s.
Si la HBM Hynix est affichée depuis le troisième trimestre 2014 comme disponible sur son catalogue, il s'agit de plus probablement d'une erreur puisque dans une présentation datée d'octobre ce dernier indiquait avoir débuté l'échantillonnage pour qualification auprès de ses clients en septembre 2014 avec une production en volume lancée au premier trimestre 2015.
Les rumeurs vont bon train sur Internet concernant l'utilisation de HBM par le prochain GPU haut de gamme d'AMD, Fiji, dont on attend l'arrivée pour la mi-2015. Celles-ci ont parfois tendance à s'auto-alimenter comme c'est souvent le cas sur le net, autant faire un point sur le sujet. En premier lieu elles ont eu pour source le fait que la HBM est un standard JEDEC initialement co-développé par AMD et SK Hynix, AMD ayant été historiquement très actif dans dans le domaine de la mémoire graphique et d'ailleurs le premier à utiliser la GDDR5, et que la production en volume de la première génération est donc imminente chez SK Hynix. S'ajoute à ceci quelques rapports Sandra (certains datant d'Octobre ) mentionnant un GPU à 64 CU et bus 4096-bit. Enfin en début d'année 2015 un ingénieur AMD avait indiqué sur sa fiche LinkedIn qu'il avait participé au développement d'un GPU 300W "2.5D" utilisant de la HBM et un silicon interposer.
Ce faisceau d'indice qui grossit est-il suffisant pour envisager l'utilisation de HBM dès Fiji avec certitude ? Pas complètement. Tout d'abord, AMD est loin d'avoir utilisé toutes les capacités de la GDDR5 jusqu'alors puisqu'il ne fait appel qu'à de la GDDR5 à 5 GT/s sur les R9 290X. Avant de partir sur la HBM, il dispose donc d'une marge de manuvre côté bande passante en conservant un bus 512-bit GDDR5, avec de la mémoire pouvant être 40% plus rapide en configuration 4 Go (16x256 Mo à 7 GT/s) et 60% plus rapide en 8 Go (16x512 Mo à 8 GT/s). Au mieux on pourrait ainsi atteindre 8 Go à 512 Go /s.
Si cette première génération de puces HBM est une étape importante, la combinaison de sa capacité et de son débit fait que son utilisation sur un GPU haut de gamme ne semble pas être si pertinente qu'elle peut y paraître au premier abord. Les rumeurs font ainsi état d'un énorme bus 4096-bit sur Fiji, mais cela ne permettrais finalement "que" d'adresser 4 puces HBM en parallèle et d'atteindre donc une capacité de 4 Go à une vitesse de... 512 Go /s. Quel est l'intérêt de partir sur une technologie qui en est encore à ses débuts, avec les surcoûts et risques que cela induit, si la bande passante n'augmente pas alors que la mémoire vidéo est bloquée à 4 Go, ce qui peut poser des problèmes notamment pour une déclinaison FirePro ?
L'efficacité énergétique de cette HBM de 1ère génération est supérieure à celle de la GDDR5 pour une telle bande passante, mais il n'est pas certain que ce soit un avantage décisif par rapport à la gourmandise d'un GPU haut de gamme. Les watts de gagnés au niveau des contrôleurs mémoire pourront être utilisés pour pousser plus loin le reste du GPU, mais en contrepartie les puces mémoire seront positionnées au niveau du packaging GPU ce qui va complexifier le refroidissement du tout. Est-ce pour cette raison, en sus des 300W mentionnés plus haut, que AMD envisagerais selon la rumeur de faire appel à un watercooling AIO pour Fiji ?
D'autres bruits de couloir font par ailleurs état d'une exclusivité d'AMD sur la HBM auprès de SK Hynix sur cette première génération, et il est possible que AMD souhaite dans tous les cas l'utiliser ne serait-ce que pour l'aspect marketing, voire soit obligé contractuellement d'acheter la HBM de 1ère génération à SK Hynix.
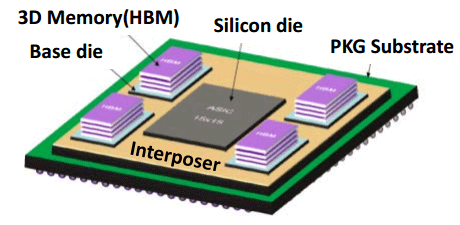
C'est surtout la seconde génération de HBM qui devrait s'imposer sans discussion possible sur les GPU haut de gamme. Les débits seront alors doublés, avec 256 Go /s par puce, et les capacités atteindront 4 et même 8 Go par puce... multipliez par 4 et les chiffres font rêver ! Alors que la GDDR5 pourrait suffire pour les GPU haut de gamme de 2015 si elle est pleinement exploitée, la HBM deviendra par contre essentielle pour tirer pleinement parti du saut de puissance attendu en 2016 avec l'arrivée du 14nm.
Une utilisation de la HBM de 1ère génération par Fiji est bien entendu possible, mais dans ce cas nous sommes impatients de savoir ce qui le justifiera par rapport à la GDDR5. Quoi qu'il en soit nous préférons ne pas avoir d'attente particulière côté mémoire et être agréablement surpris, par exemple avec une HBM qui serait plus rapide que ce qu'annonce Hynix à son catalogue (un des rapports Sandra parle de "1.25 GHz"), qu'être "déçus" si finalement Fiji se "contentait" de GDDR5... même si ce sont bien entendu les performances finales qui importent !
Intel densifie sa SRAM 14nm et parle du 10 et 7nm
Intel profite de la conférence ISSCC (International Solid-State Circuits Conference) qui se tient cette semaine à San Francisco pour effectuer plusieurs annonces autour de ses process de fabrication. Le constructeur a donné à la presse un avant-goût de ses annonces, deux d'entre elles ont particulièrement retenu notre attention.
En premier lieu on retiendra la présentation d'un bloc de SRAM particulièrement optimisé pour la densité avec une taille de cellule de seulement 0.0500 µm², un record. Il s'agit d'une amélioration importante par rapport à la dernière présentation du constructeur qui évoquait des tailles de cellules de 0.0588 µm² lors du dernier IEDM fin 2014.
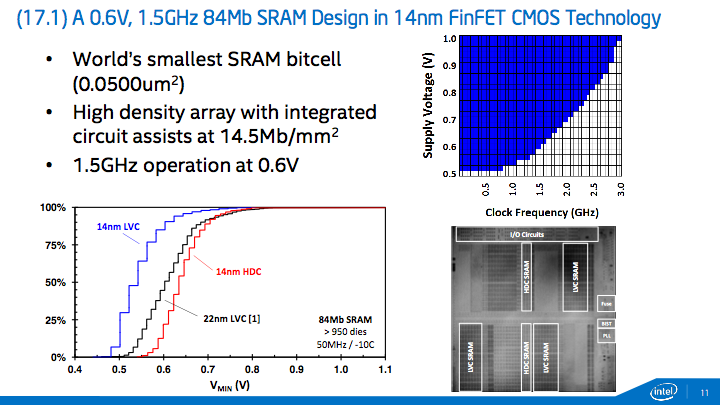
Il s'agit en pratique d'une puce de 84 Mbit (10,5 Mo) de SRAM optimisée pour un fonctionnement à 1.5 GHz à 0.6 Volts, même si en montant la tension d'activation à 1 Volt on peut atteindre 3 GHz. Si elle montre le bond en avant en densité lié au process, cette annonce tient surtout de la performance technique, le constructeur annonçant souvent des cellules de SRAM spécialisées et différentes de ce que l'on retrouve dans les produits commerciaux. Le constructeur avait ainsi annoncé pour le node 22 nm des cellules de 0.092 µm² optimisées pour la densités, mais ce sont des cellules de 0.108 µm² optimisées cette fois ci pour leur rapport performance/puissance qui sont utilisées dans les processeurs.
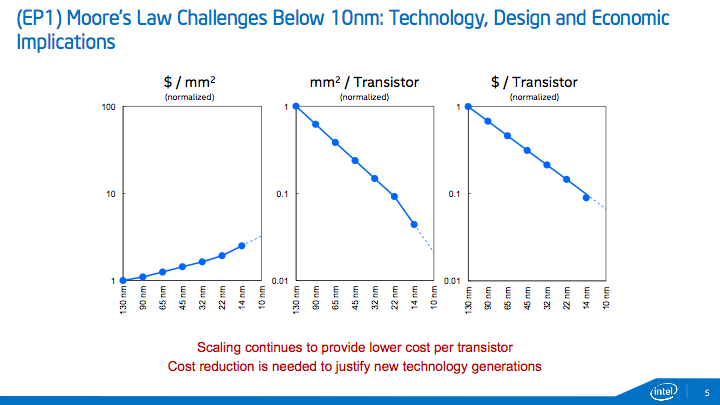
On retiendra enfin la description des challenges rencontrés au delà du 10 nm. Intel se félicite tout d'abord d'avoir atteint un coût par transistor plus faible qu'attendu sur le 14 nm, un chiffre toujours difficile à mettre en perspective qui plus est cette fois-ci avec les retards engendrés et les lancements décalés !


En ce qui concerne le 10nm, il semblerait que le constructeur ait - sans surprise - opté pour sa solution à lithographie à immersion « classique » en 193nm, et non pour une solution EUV comme Mark Bohr nous l'avait déjà indiqué en 2012 à l'occasion d'une interview. En fin d'année dernière TSMC avait également indiqué que l'EUV ne serait pas a l'heure pour leur propre process 10 nm.
Intel ne s'est pas encore étendu sur les changements techniques de son process 10 nm mais il avait été évoqué précédemment un recours plus fort au multiple patterning (exposition multiples). Déjà utilisé sporadiquement sur certaines couches critiques, son utilisation devrait être généralisée.
En ce qui concerne le 7 nm, un changement de la forme des structures (remplacer par exemple les FinFET par des microfils) et des matériaux utilisés (par exemple Arséniure de Gallium-Indium [InGaAs] ou Phosphure d'Indium [InP]) est envisagée mais Intel n'est pas encore prêt a livrer les détails de sa recherche.
On notera enfin que le constructeur indique avoir appris de ses problèmes concernant le 14 nm en ajoutant de nouvelles procédures internes pour détecter les problèmes rencontrés, particulièrement autour des masques qui semblent avoir posé beaucoup de problèmes au constructeur et être en partie coupable des retards. Le fondeur annonce qu'il a pour objectif d'avoir une transition vers le 10nm deux fois plus rapide que celle du 14nm, mais vu l'introduction de produits 14nm au compte-goutte 18 à 24 mois après le passage au 22nm on ne sait pas vraiment quels sont l'intervalle et la date de départ pris en compte pour le 14nm. Toujours est-il que le 10nm devrait pour sa part débarquer en 2016 !