
Nvidia Fermi : la révolution du GPU Computing
Publié le 01/10/2009 par Damien Triolet



16 multiprocesseurs musclésNous entrons maintenant dans la partie consacrée au cur de calcul, qui a lui aussi subit de gros changements. Dans le GT200 et les puces précédentes, les multiprocesseurs étaient groupés par 3 (ou 2) dans une partition nommée TPC. Une organisation liée au mode graphique puisque les unités de texturing se retrouvaient à ce niveau. Nous avions donc en tout 3 niveaux pour le scheduler hiérarchique, le GPU, le TPC et le multiprocesseur. Une structure complexe que Nvidia a décidé de remettre à plat. Le TPC disparait ainsi et ne restent que les multiprocesseurs. Une autre manière de voir les choses est de se dire que le TPC contient maintenant un unique multiprocesseur.
Alors que le GT200 disposait de 10 TPC équipés chacun de 3 multiprocesseurs, Fermi dispose de 16 multiprocesseurs. 16 contre 30, la catastrophe ? Pas du tout puisquils sont totalement différents.
Dans le GT200 et tous les GPUs G8x, chaque multiprocesseur dispose dun unique scheduler qui fonctionne à une fréquence basse, 1x (différente de la fréquence de base du GPU !) et de 4 blocs dexécution qui fonctionnent à la fréquence haute, 2x (la fréquence des « shaders ») :
- une unité SIMD 8-way (les 8 « cores ») : 8 MAD FP32, 8 ADD INT32 ou 8 MUL INT24
- une unité SFU double : 2 fonctions spéciales FP32, 8 interpolations ou 8 MUL FP32
- une unité FMA FP64 (GT200 seulement)
- une unité Load/Store 8-way 32 bits
Etant donné que les multiprocesseurs travaillent sur des warps de 32 threads, il faut, par exemple, 4 cycles pour traiter une opération de type MAD FP32 et 16 cycles pour une fonction spéciale. Du point de vue du scheduler qui fonctionne à une fréquence réduite de moitié, cela veut dire 2 et 8 cycles, ce qui lui donne la possibilité de faire du dual issue entre une instruction FP32 et une fonction spéciale qui peuvent donc être traitées en parallèle. Théoriquement il est également possible de traiter en MAD FP32 et un MUL FP32 en même temps, mais en pratique ce nest pas évident compte tenu de limitations au niveau du nombre dopérandes qui peuvent être transmises à chaque cycle. Nvidia utilisait cependant cette possibilité pour booster sa puissance de calcul théorique de manière à être moins largué par AMD à ce niveau.
Une unité FMA FP64 a été ajoutée avec le GT200. Celle-ci permet de traiter des opérations en double précision mais 8x moins vite que la simple précision puisquelle est seule et unique.
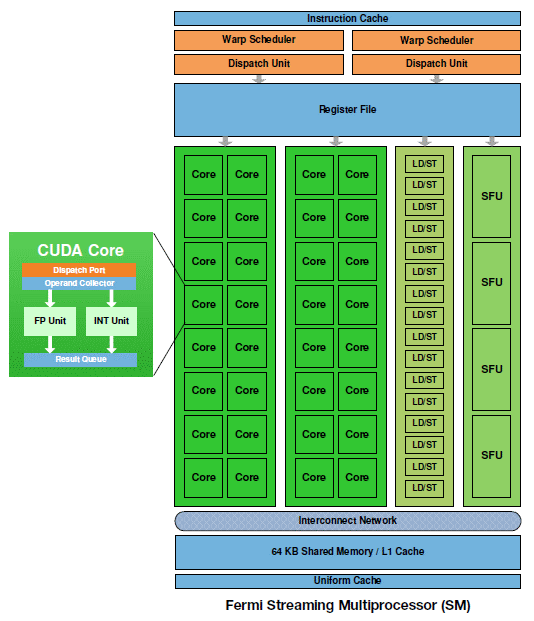
Dans Fermi, chacun des 16 multiprocesseurs dispose dun double scheduler qui fonctionne toujours à la fréquence basse et de 4 blocs dexécutions qui fonctionnent à la fréquence haute :
- deux unités SIMD 16-way (les 32 « cores ») : 32 FMA FP32, 32 ADD INT32, 16 MUL INT32, 16 FMA FP64
- une unité SFU quadruple : 4 fonctions spéciales FP32 ou 16 interpolations
- une unité Load/Store 16-way 32 bits
Les deux unités SIMD 16-way sont distinctes et travaillent sur un warp et une instruction différents. La première unité peut ainsi exécuter 16 FMA FP32 alors que la seconde traite 16 ADD INT32. Etant donné que les warps sont toujours de 32 threads, ils sont exécutés en 1 cycle du point de vue du scheduler qui a donc dû être doublé pour pouvoir profiter du dual-issue. Lunité SFU quadruple est découplée et le scheduler peut donc émettre des instructions aux 2 unités SIMD une fois quelle est au travail, ce qui permet donc de faire travailler les SFUs en même temps que les SIMDs sur un maximum de cycles.
Il semblerait cependant que les SIMDs ne soient pas découplées et donc que le scheduler ne soit pas libéré après une instruction plus lente, en 64 bits. Nous devrions cependant préciser les schedulers puisque Nvidia précise qualimenter les instructions 64 bits monopolise lensemble des ressources au niveau de laccès aux registres, ce qui veut dire que le dual-issue nest pas possible en double précision. Nous ne savons cependant pas si au niveau de limplémentation une seule SIMD se charge de toutes les opérations sur les doubles ou si les 2 SIMDs travaillent de concert à demi vitesse, Nvidia se refusant à rentrer dans ces détails.
Pour les opérations sur les entiers, Nvidia a implémenté un pipeline dédié à lintérieur de chaque SIMD. Il a été implémenté de manière à pouvoir calculer des précisions supérieures efficacement, par étapes successives. Les nouvelles instructions de DirectX11 ont également fait leur apparition à ce niveau.
Comparer Fermi à Cypress est compliqué compte tenu des architectures complètement différentes. Cypress dispose de 20 SIMDs chacun équipés de 16 unités vec4+1. La partie vec4 est capable de traiter 4 FMA FP32, 4 ADD INT24, 4 MUL INT24, 2 ADD FP64, 1 MUL FP64 ou 1 FMA FP64 alors que la partie +1 prend en charge une fonction spéciale ou un FMA FP32 par cycle. Il ny a pas de multi-issue géré ici au niveau du scheduler, mais il revient au compilateur dessayer de trouver 5 instructions non dépendantes qui peuvent sexécuter dans ce modèle vec4+1, ce qui nest pas toujours possible et réduit lefficacité de ce type darchitecture, qui permet cependant de placer plus dunités de calcul et donc de puissance de calcul brute dans une même surface.
Des registres en hausse et en baisseParadoxalement, si le nombre de registres 32 bits passe de 16384 à 32768 du GT200 à Fermi, leur nombre est en fait divisé par 2 par rapport au nombre de « cores ». Cela signifie que la latence que Fermi est capable de masquer sera 2 à 3x plus faible que dans le GT200, malgré le fait que 1536 threads peuvent y résider contre 1024 auparavant. Difficile de dire cependant si ces latences maximales quil est possible de masquer vont jouer un rôle dans les performances, dautant plus que la nouvelle structure de cache et la GDDR5 plus rapide va compenser.
Du côté de Cypress, le nombre de registres par SIMD reste identique par rapport au RV770 : 16384 registres de 128 bits.
Sommaire
5 - Parallel DataCache
6 - 16 multiprocesseurs musclés
7 - IEEE754-2008 et puissance de calcul
8 - Conclusion
6 - 16 multiprocesseurs musclés
7 - IEEE754-2008 et puissance de calcul
8 - Conclusion
Vos réactions
Contenus relatifs
- [+] 10/04: Nvidia : fin du support Fermi et 32...
- [+] 09/02: Nvidia lance les Quadro Pascal dont...
- [+] 05/04: GTC: Nvidia Tesla P100: 10 Tflops, ...
- [+] 15/12: GPUOpen, la réponse d'AMD à GameWor...
- [+] 16/11: AMD et HPC: nouveaux outils, suppor...
- [+] 09/07: AMD lance la FirePro S9170: Hawaii ...
- [+] 08/12: Nvidia lance la Tesla K80: double G...
- [+] 02/12: IBM Power9 et Nvidia Volta : 100+ p...
- [+] 12/03: Nvidia lance les GeForce 800M avec ...
- [+] 25/11: Nvidia annonce la Tesla K40 et CUDA...