
Nvidia CUDA : l'heure de la concrétisation ?
Publié le 26/07/2008 par Damien Triolet



CUDA 2.0CUDA est un environnement de développement mis au point par Nvidia qui consiste en quelques extensions au langage C, des librairies, un compilateur et un pilote. CUDA demande au développeur d'organiser la masse de travail à exécuter par le GPU en un assemblage de blocs de threads. Chaque bloc peut contenir jusqu'à 512 threads. Plusieurs blocs peuvent être actifs en même temps dans un même multiprocesseur.
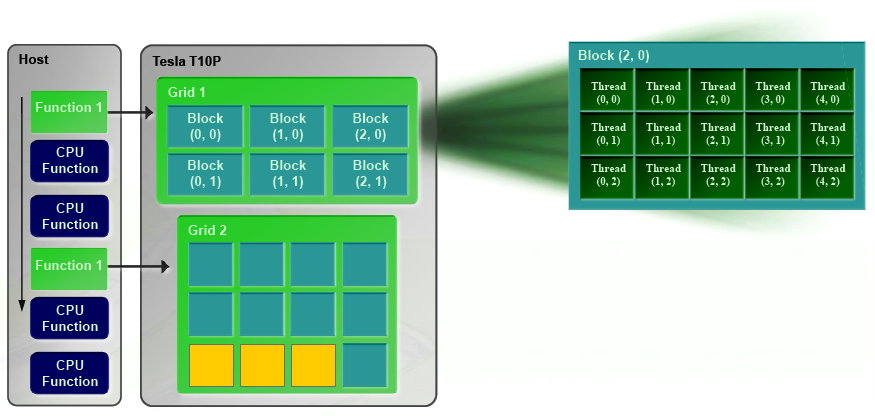
Chaque thread peut communiquer avec les autres threads d'un même bloc à travers une mémoire locale de 16 Ko appelée shared memory. Celle-ci est organisée en 16 banques et les accès qui y sont faits sont soumis à plusieurs contraintes pour être effectués à pleine vitesse. Malgré tout elle permet d'éviter de repasser par la mémoire globale pour passer des données d'un thread à l'autre et est donc un élément important de CUDA.
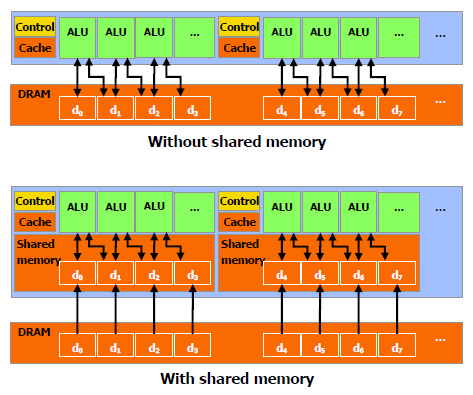
C'est souvent autour de cet élément que les développeurs devront organiser les threads. Plus il y en a en vol, plus ils sont nombreux à pouvoir communiquer entre eux, mais de plus petites données. Si de petits blocs sont utilisés à plusieurs pour remplir un multiprocesseur, la shared memory accessible à chacun est alors réduite. Il faudra donc souvent expérimenter diverses organisations de threads pour savoir laquelle est la plus efficace, d'autant plus quand la shared memory est utilisée. Un point sensible que Nvidia n'a d'ailleurs pas voulu modifier avec de plus récents GPUs puisque tous utilisent une même mémoire de 16 Ko.
Parallèlement à l'arrivée du GT200, CUDA 2.0 montre le bout de son nez. Actuellement en version beta, cette nouvelle mouture de l'environnement de développement apporte plusieurs avancées. Premièrement, elle supporte bien entendu les fonctionnalités nouvelles apportées par le GT200, à savoir plus de registres, les doubles etc. Voici un résumé des différentes révisions hardware spécifiques à CUDA affichées par les GPU compatibles :
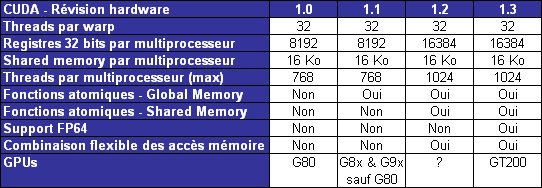
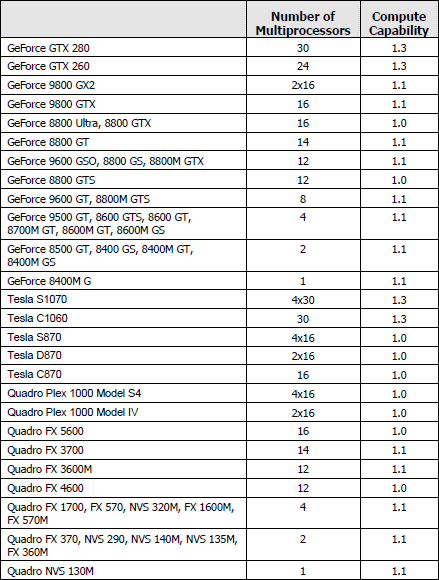
Comme vous pouvez le constater, il n'existe à ce jour aucun GPU et aucune carte graphique de révision 1.2. Cela peut s'expliquer par 2 raisons : premièrement, au départ, Nvidia avait envisagé de limiter le support du FP64 aux produits Tesla et Quadro haut de gamme, du coup une GeForce GTX 200 serait retombée dans la révision 1.2 au lieu de la 1.3. Ce revirement de situation est dû au changement de stratégie qui a été opéré et qui consiste à privilégier l'utilisation de CUDA plutôt que la vente des produits Tesla. Une stratégie qui pourrait se révéler plus intéressante à long terme pour Nvidia.
CUDA et le x86 multicoreC'est selon nous l'information la plus intéressante dévoilée par Nvidia : l'ajout dans le compilateur CUDA d'un profil optimisé pour les CPUs x86 multicores !
Actuellement, le code CUDA est séparé en 2 parties : une partie traitée par le CPU et redirigée vers un compilateur classique (du choix du développeur) et une autre partie spécifique au GPU, dont s'occupe le compilateur CUDA. La nouveauté est qu'il sera dorénavant possible de compiler cette partie spécifique au GPU pour le CPU, de manière à ce que la totalité du code CUDA tourne sur ce dernier. L'exploitation automatique du multicore sera réalisée via, grossièrement, la transformation d'un bloc de threads GPU en un thread CPU.
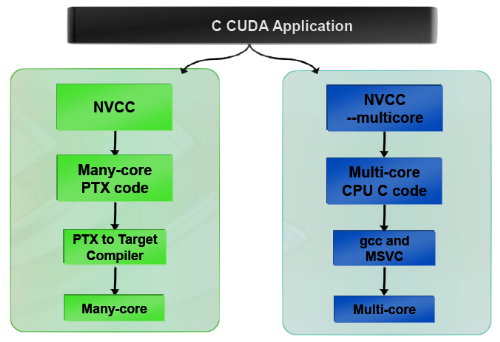
Une nouvelle version beta de CUDA 2.0 qui supporte cette possibilité sera rendue publique sous peu. Actuellement, nous ne savons pas quel sera le niveau d'efficacité réel de la compilation pour le CPU. Il sera intéressant de vérifier ce point quand le tout sera mûr.
Ce nouveau positionnement est dû à plusieurs raisons. La volonté de Nvidia, encore une fois, d'essayer de rendre l'utilisation de CUDA aussi répandue que possible, quitte à ce qu'il soit utilisé en partie sur un CPU plutôt que sur un GPU. Ensuite Nvidia répond à une demande des utilisateurs actuels ou potentiels de CUDA qui désirent des garanties avant de se lancer dans l'aventure. Développer un code spécifique à un GPU est plus risqué qu'un développer un compatible avec le GPU et avec le CPU. S'il arrivait un problème aux GPUs dans le futur il serait ainsi possible de passer facilement sur un CPU, quitte à ce que ce soit plus lent.
Bien entendu la question qui vient immédiatement à l'esprit est CUDA sur Larrabee ? Pour rappel, Larrabee sera un processeur Intel équipé de 32 cores et dédié à l'accélération des problèmes massivement parallèles. Bref un concurrent direct du GPU mais qui sera x86. CUDA sur Larrabee sera donc sauf surprise possible. Il sera là aussi intéressant d'observer les performances !
Sommaire
Vos réactions
Contenus relatifs
- [+] 09/02: Nvidia lance les Quadro Pascal dont...
- [+] 05/04: GTC: Nvidia Tesla P100: 10 Tflops, ...
- [+] 15/12: GPUOpen, la réponse d'AMD à GameWor...
- [+] 16/11: AMD et HPC: nouveaux outils, suppor...
- [+] 09/07: AMD lance la FirePro S9170: Hawaii ...
- [+] 08/12: Nvidia lance la Tesla K80: double G...
- [+] 02/12: IBM Power9 et Nvidia Volta : 100+ p...
- [+] 25/11: Nvidia annonce la Tesla K40 et CUDA...
- [+] 13/11: APU13: HSA: nouveaux membres, Oracl...
- [+] 06/05: AMD hUMA: la mémoire unifiée trouve...