
Nvidia CUDA : l'heure de la concrétisation ?
Publié le 26/07/2008 par Damien Triolet



Contrôleur mémoire plus efficaceLes puces de type G8x et G9x accèdent à la mémoire par morceaux de 64 (pour des données de 32 bits) ou 128 octets (pour des données de 64 ou 128 bits) et ce d'une manière très rigide. Il est évident que pour remplir un accès mémoire de 64 ou 128 octets, il faut que plusieurs threads y participent. En mode GPU Computing, les accès à la mémoire globale de 16 threads (soit un demi warps) peuvent ainsi être combinés. Si 16 threads ont besoin d'une donnée de 32 bits, cela remplit un accès mémoire de 64 octets. Cependant pour que cela soit possible il faut obligatoirement que les 16 threads accèdent d'une manière séquentielle, contiguë et alignée à des données contenues dans un bloc mémoire de 64 octets. Si ce n'est pas le cas, un accès mémoire par thread doit être exécuté, ce qui allonge nettement la latence (puisque les threads sont exécutés en même temps il faut attendre que tous les threads aient récupéré leur donnée avant de continuer leur traitement) et gaspille beaucoup de bande passante mémoire (puisqu'un bloc de 64 octets est rapatrié pour n'en utiliser que 32 bits).
Le contrôleur mémoire du GT200 a été revu de manière à gagner en efficacité, en plus d'avoir été étendu à 512 bits. Tout d'abord en plus des accès mémoire à des blocs de 64 et 128 octets, il peut se contenter de 32 octets. Il est capable de combiner des accès non-séquentiels effectués à l'intérieur d'un même bloc mémoire, de combiner des accès non alignés ou non contigus dans le bloc mémoire de taille supérieure (par exemple 1 accès de 128 octets pour 64 octets de données au lieu de 16 accès de 64 octets précédemment) et de réduire la taille des accès mémoire autant que possible quand plusieurs sont nécessaires. Les gains d'efficacité seront donc conséquents dans ces situations.
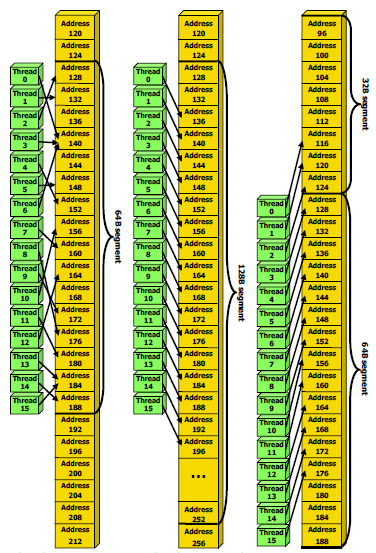
3 exemples d'accès mémoire qui profitent grandement au GT200. Le premier est réalisé avec un seul accès de 64 octets, le second avec un seul de 128 octets et le dernier avec un accès de 64 octets et un de 32 octets. Ces 3 exemples ont besoin de 16 accès de 64 octets sur un GPU antérieur au GT200 !
En détail qui nous était passé inaperçu est que les puces G9x ont introduit une communication plus efficace entre le CPU et le GPU puisqu'il est devenu possible d'envoyer des données au GPU ou à celui-ci d'en envoyer pendant que son cur d'exécution est au travail. Sur une puce G80 ce n'est pas possible et le GPU ne peut pas exécuter de kernel pendant les transferts de données vers ou depuis la mémoire centrale. Le GT200 reprend bien entendu cette capacité. Notez que Nvidia nous a indiqué que la génération suivant qui arrivera l'an prochain, sera capable de recevoir des données et d'en envoyer tout en exécutant un kernel.
Support des doublesLa nouveauté qui a été le plus mise en avant avec le GT200 dans le domaine du GPU Computing est sans aucun doute le support des doubles soit du calcul en 64 bits sur les flottants. Ce support a été introduit via l'ajout d'une unité dédiée dans chaque multiprocesseur.
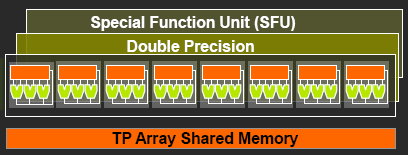
Pour être précis nous devons rappeler que chaque multiprocesseur contient 8 processeurs FMAD principaux + 8 processeurs MUL partagés avec les unités en charge des fonctions spéciales (sin, cos, exp etc.). Un processeur FMAD 64 bits vient s'y ajouter. La puissance de calcul en 64 bits est donc nettement moindre, 8x plus faible dans le cas d'instructions FMAD, 16x plus faible dans le cas d'instructions FMUL.
Ce support du 64 bits reste cependant intéressant à plus d'un titre, puisqu'il peut ne concerner qu'un morceau du code ou être utilisé pour développer des applications qui seront utilisées sur les futures générations de GPUs qui recevront plus qu'un processeur 64 bits par multiprocesseur ou mieux, verront tous leurs processeurs évoluer de 32 à 64 bits.
Chaque multiprocesseur étant dual issue, il peut traiter 2 instructions non dépendantes en même temps et ainsi débiter par cycle :
8 FMAD 32 bits + 8 FMUL 32 bits
8 FMAD 32 bits + 2 fonctions spéciales 32 bits
8 FMAD 32 bits + 1 FMAD 64 bits
1 FMAD 64 bits + 2 fonctions spéciales 32 bits
Ces 2 dernières combinaisons ne sont cependant pas exploitables à l'heure actuelle et Nvidia évalue toujours l'intérêt de leur implémentation dans le compilateur. Concernant les avantages de l'implémentation du FP64 de Nvidia, nous noterons la gestion à pleine vitesse des nombres dénormalisés. Par contres les flags ne sont pas du tout supportés.
Sommaire
Vos réactions
Contenus relatifs
- [+] 09/02: Nvidia lance les Quadro Pascal dont...
- [+] 05/04: GTC: Nvidia Tesla P100: 10 Tflops, ...
- [+] 15/12: GPUOpen, la réponse d'AMD à GameWor...
- [+] 16/11: AMD et HPC: nouveaux outils, suppor...
- [+] 09/07: AMD lance la FirePro S9170: Hawaii ...
- [+] 08/12: Nvidia lance la Tesla K80: double G...
- [+] 02/12: IBM Power9 et Nvidia Volta : 100+ p...
- [+] 25/11: Nvidia annonce la Tesla K40 et CUDA...
- [+] 13/11: APU13: HSA: nouveaux membres, Oracl...
- [+] 06/05: AMD hUMA: la mémoire unifiée trouve...