
Nvidia CUDA : l'heure de la concrétisation ?
Publié le 26/07/2008 par Damien Triolet



GT200L'arrivée de son nouveau GPU, le GT200, est importante pour Nvidia pour tout ce qui concerne le GPU Computing, en témoigne le lancement simultané des GeForce GTX 200 et des Tesla 2. Le GT200 présente une évolution de l'architecture des puces G8x et G9x. Evolution dont le rendement est discutable du côté grand public puisque les GeForce GTX 200 se sont fait surprendre par les Radeon HD 4800, plus efficaces. Si la GeForce GTX 280 conserve une courte tête d'avance, cela se fait au prix d'un GPU énorme de pas moins de 1.4 milliards de transistors, soit le double d'une puce telle que le G80 des GeForce 8800 GTX.

Le die énorme du GT200.
Dès lors il est légitime de se poser la question de savoir si Nvidia n'aurait pas privilégié le côté GPU Computing plus que le côté rendu 3D. De notre côté nous ne pensons pas que ce soit le cas. Le développement d'un tel GPU se prépare longtemps à l'avance, et à ce moment il aurait été étonnant de voir Nvidia parier sur un marché qui n'existait pas encore au détriment de son business principal. Nous estimons donc que les choix principaux de l'architecture du GT200 ont été faits par rapport à ce que Nvidia pensait être la meilleure solution pour le marché de la carte graphique haut de gamme. Des choix qui ont cependant été faits en sous-estimant, probablement avec un petit peu d'arrogance, la capacité de la concurrence à être compétitifs.
Ceci étant dit, Nvidia a bel et bien introduit quelques petites touches spécifiques au GPU Computing dans ce GT200 et bien que les choix principaux aient été opérés en priorité par rapport au rendu 3D, cela ne les rends pas inintéressants pour d'autres domaines, bien au contraire !
Plus d'unités de calculLa principale amélioration provient de l'augmentation des unités de calcul ou processeurs qui travaillent chacun sur des threads différents. Ces processeurs sont organisés par groupes de 8, appelés multiprocesseurs, et exécutent des suites d'instructions (kernels) sur des groupes de 32 threads, appelés warps, en 4 cycles. Alors que le G80 et le G92 reposaient sur 16 multiprocesseurs, le GT200 en embarque pas moins de 30. La puissance de calcul fait donc un gros bond en avant, tout du moins à fréquence égale puisque si le GT200 fonctionne à une fréquence proche de celle du G80 à son introduction, il faut rappeler que le G92 peut, lui, monter beaucoup plus haut, près de 50% plus haut.
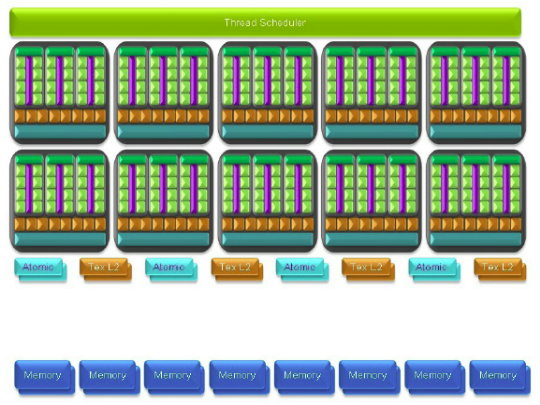
En mode rendu 3D, un détail important concerne l'organisation de ces multiprocesseurs puisqu'ils sont 3 à partager une unité de texturing contre seulement 2 auparavant. Le débit relatif d'accès aux textures est donc revu à la baisse, mais ce n'est pas très important en GPU Computing.
Plus de registresUn changement important apporté à l'architecture est le doublement des registres généraux qui n'apporte pas de gros avantages dans les jeux actuels qui ont été optimisés pour tenir dans les limites des GPUs les plus répandus. Par contre cela peut faire une énorme différence en GPU Computing.
Chaque multiprocesseur dispose d'un espace de registres qui lui est propre. Ces registres doivent accueillir un certain nombre de threads. Plus le nombre de threads en vol dans chaque multiprocesseur est élevé, mieux le GPU peut masquer les différentes latence et maximiser son débit. Il en faut d'ailleurs au minimum 192 pour masquer complètement la latence des unités de calcul et bien entendu beaucoup plus pour masquer la latence de plus de 400 cycles des accès à la mémoire globale (mémoire vidéo).
Cependant, tous ces threads doivent se partager les registres généraux. Dans le cas du GT200 ils sont de 16384 contre 8192 auparavant. Cet espace registre plus grand permet au GT200 d'accueillir plus de threads par multiprocesseur pour mieux masquer les latences ou permet d'utiliser plus de registres pour obtenir un code plus efficace. L'intérêt principal est également ailleurs : avec une pression réduite sur les registres, les développeurs auront moins besoin d'essayer d'optimiser en détail leur code pour obtenir des performances élevées.
Sommaire
Vos réactions
Contenus relatifs
- [+] 09/02: Nvidia lance les Quadro Pascal dont...
- [+] 05/04: GTC: Nvidia Tesla P100: 10 Tflops, ...
- [+] 15/12: GPUOpen, la réponse d'AMD à GameWor...
- [+] 16/11: AMD et HPC: nouveaux outils, suppor...
- [+] 09/07: AMD lance la FirePro S9170: Hawaii ...
- [+] 08/12: Nvidia lance la Tesla K80: double G...
- [+] 02/12: IBM Power9 et Nvidia Volta : 100+ p...
- [+] 25/11: Nvidia annonce la Tesla K40 et CUDA...
- [+] 13/11: APU13: HSA: nouveaux membres, Oracl...
- [+] 06/05: AMD hUMA: la mémoire unifiée trouve...